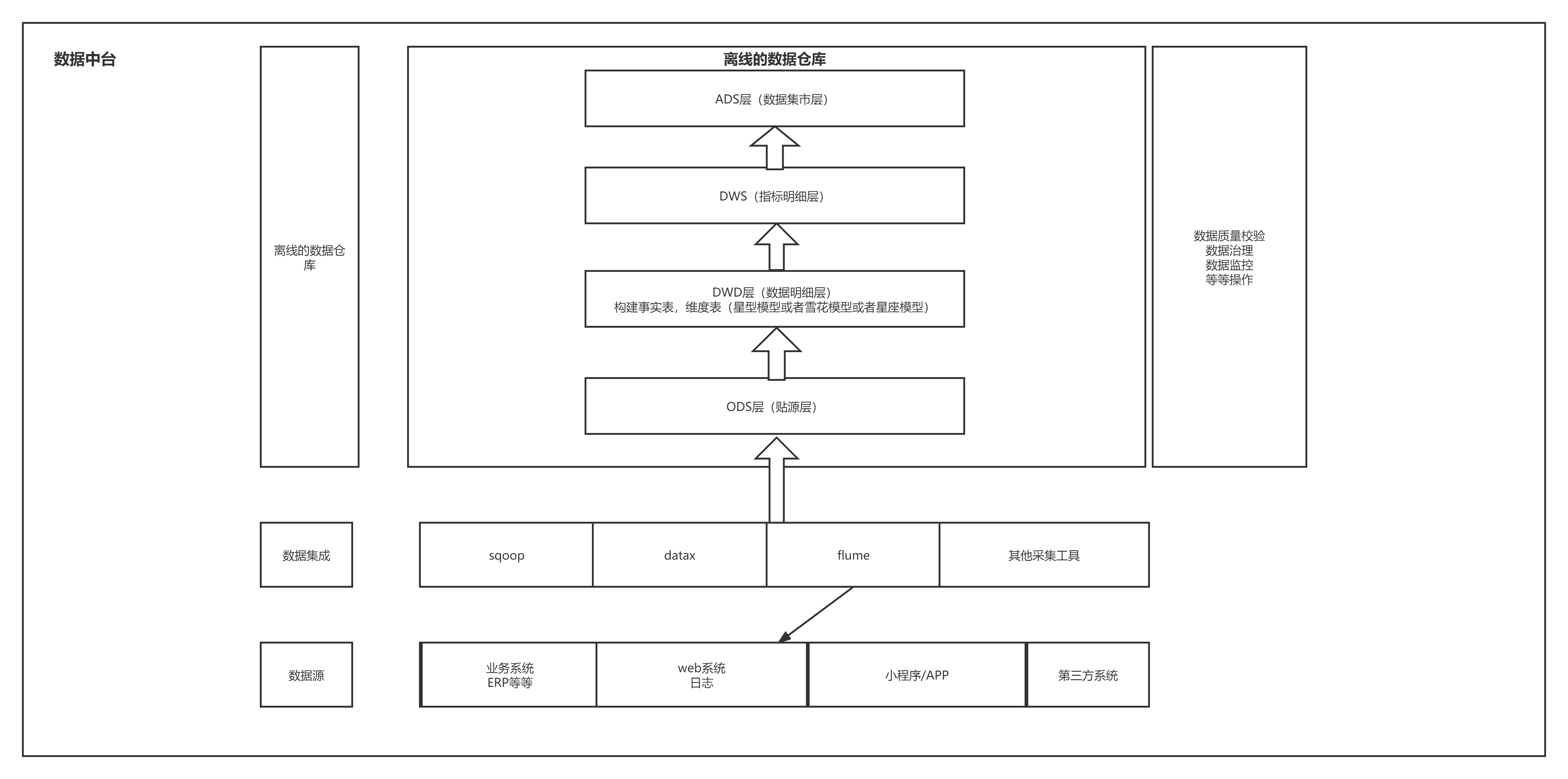
Hive(数据仓库)
Hive(数据仓库建模工具之一)
1.数据仓库概述
数据仓库之父比尔·恩门,1991年提出
定义:数据仓库是一个面向主题的,集成的,相对稳定的,反映历史变化的数据集合,用于支持管理中的决策制定。
操作型数据库
主要用于业务支撑,一个公司往往会使用并维护若干个操作型数据库,这些数据库保存着公司的日常操作数据。
分析型数据库
主要用于历史数据分析,这类数据库作为公司的单独数据存储,负责利用历史数据对公司各主题域进行统计分析。
操作性数据库vs分析型数据库
因为主导功能的不同(面向操作/面向分析),两类数据库就产生了很多细节上的差异。这就好像同样是人,但一个和尚和一个穆斯林肯定有很多行为/观念上的不同。
接下来本文将详细分析两类数据库的不同点:
1.数据组成差别 - 数据时间范围差别
一般来讲,操作型数据库只会存放90天以内的数据,而分析型数据库存放的则是数年内的数据。这点也是将操作型数据和分析型数据进行物理分离的主要原因。
2.数据组成差别 - 数据细节层次差别
操作型数据库存放的主要是细节数据,而分析型数据库中虽然既有细节数据,又有汇总数据,但对于用户来说,重点关注的是汇总数据部分。
操作型数据库中自然也有汇总需求,但汇总数据本身不存储而只存储其生成公式。这是因为操作型数据是动态变化的,因此汇总数据会在每次查询时动态生成。
而对于分析型数据库来说,因为汇总数据比较稳定不会发生改变,而且其计算量也比较大(因为时间跨度大),因此它的汇总数据可考虑事先计算好,以避免重复计算。
3.数据组成差别 - 数据时间表示差别
操作型数据通常反映的是现实世界的当前状态;而分析型数据库既有当前状态,还有过去各时刻的快照,分析型数据库的使用者可以综合所有快照对各个历史阶段进行统计分析。
4.技术差别 - 查询数据总量和查询频度差别
操作型查询的数据量少而频率多,分析型查询则反过来,数据量大而频率少。要想同时实现这两种情况的配置优化是不可能的,这也是将两类数据库物理分隔的原因之一。
5.技术差别 - 数据更新差别
操作型数据库允许用户进行增,删,改,查;分析型数据库用户则只能进行查询。
6.技术差别 - 数据冗余差别
数据的意义是什么?就是减少数据冗余,避免更新异常。而如5所述,分析型数据库中没有更新操作。因此,减少数据冗余也就没那么重要了。
现在回到开篇是提到的第二个问题"某大公司Hadoop Hive里的关系表不完全满足完整/参照性约束,也不完全满足范式要求,甚至第一范式都不满足。这种情况正常吗?",答曰是正常的。因为Hive是一种数据仓库,而数据仓库和分析型数据库的关系非常紧密(后文会讲到)。它只提供查询接口,不提供更新接口,这就使得消除冗余的诸多措施不需要被特别严格地执行了。
7.功能差别 - 数据读者差别
操作型数据库的使用者是业务环境内的各个角色,如用户,商家,进货商等;分析型数据库则只被少量用户用来做综合性决策。
8.功能差别 - 数据定位差别
这里说的定位,主要是指以何种目的组织起来。操作型数据库是为了支撑具体业务的,因此也被称为"面向应用型数据库";分析型数据库则是针对各特定业务主题域的分析任务创建的,因此也被称为"面向主题型数据库"。
3.OLTP和OLAP(重点)
OLTP(OnLine Transaction Processing 联机事务处理)
就是数据库的增删改查,要求速度快,自然数据量不可过大,其次都是高可靠的在线操作,事务都是精准操作,没有模糊概念。
OLAP(OnLine Analysis Processing 联机分析处理)
通过多个条件多个维度去满足客户需求,传统数据库无法满足的OLAP所需要的数据。
对于数据仓库的概念我们可以从两个层次予以理解:
首先,数据仓库用于支持决策,面向分析型数据处理,它不同于企业现有的操作型数据库; 其次,数据仓库是对多个异构的数据源有效集成,集成后按照主题进行了重组,并包含历史数据,而且存放在数据仓库中的数据一般不再修改。
(简单的理解,其实就是我们为了进行OLAP,把分布在各个散落独立的数据库孤岛整合在了一个数据结构里面,称之为数据仓库)
数据仓库为OLAP解决了数据来源问题,数据仓库和OLAP互相促进发展,进一步驱动了商务智能的成熟,但真正将商务智能赋予“智能”的,正是我们现在热谈的下一代技术:数据挖掘。
4.数据仓库特点(重点)
面向主题:这是数据仓库与关系型数据库的根本区别;
操作型数据库是为了支撑各种业务而建立。
而分析型数据库则是为了对从各种繁杂业务中抽象出来的分析主题(如用户、成本、商品等)进行分析而建立;所谓主题:是指用户使用数据仓库进行决策时所关心的重点方面,如:收入、客户、销售渠道等;所谓面向主题,是指数据仓库内的信息是按主题进行组织的,而不是像业务支撑系统那样是按照业务功能进行组织的。
集成性
集成性是指数据仓库会将不同源数据库中的数据汇总到一起;
具体来说,是指数据仓库中的信息不是从各个业务系统中简单抽取出来的,而是经过一系列加工、整理和汇总的过程,因此数据仓库中的信息是关于整个企业的一致的全局信息。
企业范围
数据仓库内的数据是面向公司全局的。比如某个主题域为成本,则全公司和成本有关的信息都会被汇集进来;
历史性
相比较于操作型数据库,数据仓库的时间跨度比较长,前者通常保存几个月,后者可能几年甚至几十年;
时变性
时变性时数据仓库包含来自其时间范围不同时间段的数据快照,有了这些数据快照,用户便可将其汇总,生成各历史阶段的数据分析报告;
数据仓库内的信息并不是只记录这一刻的,而是记录过去某一时刻到现在所有的数据,由此数据可以对企业以后的的发展历程和未来趋势做出定量分析和预测
5.数据仓库的趋势
实时数据仓库以满足实时化&自动化决策需求;
大数据&数据湖以支持大量复杂数据类型处理(文本,图像,音频,视频)
6.数据仓库的发展
数据仓库有两个环节:数据仓库的构建与数据仓库的应用
对数据仓库的需求可以抽象成两方面:实施产生结果,处理和保存大量异构数据
7.数据仓库的方法论
1)面向主题
从公司业务出发,是分析的宏观领域,比如供应商主题、商品主题、客户主题和仓库主题
2)为多维数据分析服务
数据报表;数据立方体,上卷、下钻、切片、旋转等分析功能。
3)反范式数据模型
以事实表和维度表组成的星型数据模型
8.什么是hive(面试题)
1:hive是基于hadoop的数据仓库建模工具之一(后面还有TEZ,Spark)。
2:hive可以使用类sql方言,对存储在hdfs上的数据进行分析和管理。传入一条交互式sql在海量数据中查询分析结果的工具。
9.Hive的理解
1)
1、Hive是基于Hadoop的一个数据仓库工具,可以将 结构化的数据文件 映射为一张表(类似于RDBMS中的表),并提供类SQL查询功能;Hive是由Facebook开源,用于解决海量结构化日志的数据统计。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL ),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL ,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
2、Hive是SQL解析引擎,它将SQL语句转译成M/R Job然后在Hadoop的yarn上的执行。
3、Hive的表其实就是HDFS的目录,按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在M/R Job里使用这些数据。
4、Hive相当于hadoop的客户端工具,部署时不一定放在集群管理节点中,可以放在某个节点上。
可以将Hive理解为一个:将 SQL 转换为 MapReduce 任务的工具
所以Hive不存储数据,自己也没有任何计算功能,只是相当于类SQL语句与Hadoop文件之间的一个解释器。他本质上只是一个对HDFS上的文件进行索引与计算的工具。他需要依赖Hadoop的Yarn来进行资源分配,也需要Hadoop的MapReduce来提供计算支持。后面我们就会知道,hive在进行数据计算时,不仅可以用MapReduce来支持,也可以集合其他更灵活,更高效的大数据计算框架(比如spark Spark SQL)
2)hive的使用场景
Hive的特点:
1、可扩展性
Hive可以自由的扩展集群的规模,一般情况下不需要重启服务
2、延伸性
Hive支持自定义函数,用户可以根据自己的需求来实现自己的函数
3、容错
即使节点出现错误,SQL仍然可以完成执行
优点:
1、操作接口采用类sql语法,提供快速开发的能力(简单、容易上手)
2、避免了去写MapReduce,减少开发人员的学习成本
3、Hive的延迟性比较高,因此Hive常用于数据分析,适用于对实时性要求不高的场合
4、Hive 优势在于处理大数据,对于处理小数据没有优势,因为 Hive 的执行延迟比较高。(不断地开关JVM虚拟机)
5、Hive 支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
6、集群可自由扩展并且具有良好的容错性,节点出现问题SQL仍可以完成执行
缺点:
1、Hive的HQL表达能力有限
(1)迭代式算法无法表达 (反复调用,mr之间独立,只有一个map一个reduce,反复开关)
(2)数据挖掘方面不擅长
2、Hive 的效率比较低
(1)Hive 自动生成的 MapReduce 作业,通常情况下不够智能化
(2)Hive 调优比较困难,粒度较粗 (hql根据模板转成mapreduce,不能像自己编写mapreduce一样精细,无法控制在map处理数据还是在reduce处理数据)
Hive和传统数据库对比
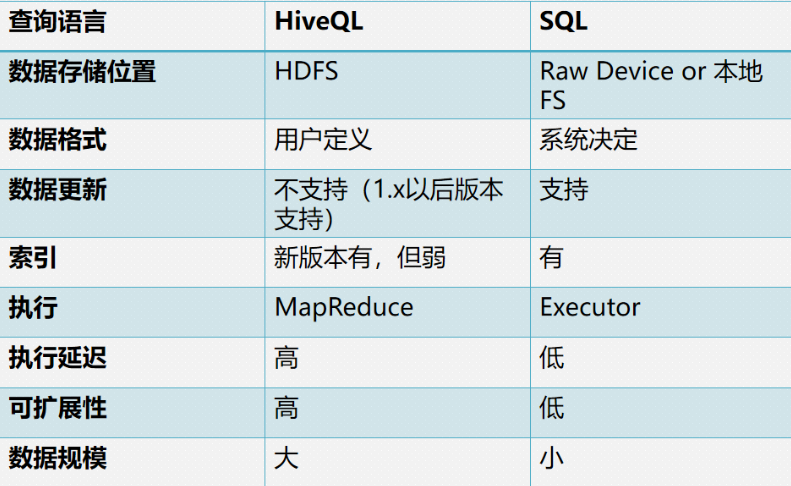
针对与优点和缺点总结:
所以,Hive通常适用于大数据的OLAP(联机分析处理)场景,做一些面向分析,允许有延迟的数据挖掘工作,并且结合其他组件也可以做一些数据清洗之类的简单数据处理工作。Hive是针对数据仓库来进行设计的,这种场景下,通常是读多写少。并且数据都是来自外部的HDFS,所以Hive中不建议做数据的修改操作,所有的数据最好是在加载的时候就已经确定好了。
Hive应用场景
日志分析:大部分互联网公司使用hive进行日志分析,如百度、淘宝等。
统计一个网站一个时间段内的pv,uv,SKU,SPU
多维度数据分析
海量结构化数据离线分析
构建数据仓库
PV(Page View)访问量, 即页面浏览量或点击量,衡量网站用户访问的网页数量;在一定统计周期内用户每打开或刷新一个页面就记录1次,多次打开或刷新同一页面则浏览量累计。
UV(Unique Visitor)独立访客,统计1天内访问某站点的用户数(以cookie为依据);访问网站的一台电脑客户端为一个访客。可以理解成访问某网站的电脑的数量。网站判断来访电脑的身份是通过来访电脑的cookies实现的。如果更换了IP后但不清除cookies,再访问相同网站,该网站的统计中UV数是不变的。如果用户不保存cookies访问、清除了cookies或者更换设备访问,计数会加1。00:00-24:00内相同的客户端多次访问只计为1个访客。
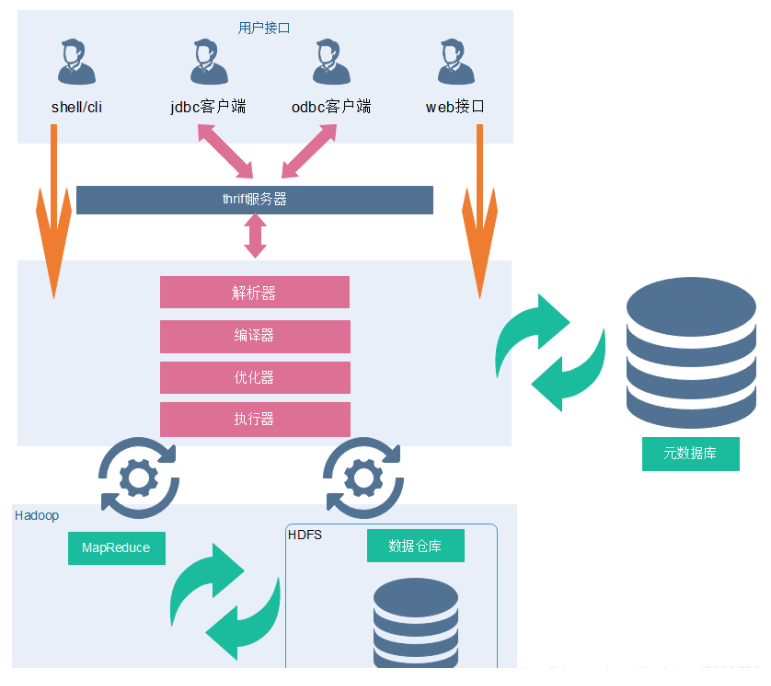
3)hive的整体框架
用户接口 CLI(Common Line Interface):Hive的命令行,用于接收HQL,并返回结果;JDBC/ODBC:是指Hive的java实现,与传统数据库JDBC类似;WebUI:是指可通过浏览器访问Hive。
Thrift Server:Hive可选组件,是一个软件框架服务,允许客户端使用包括Java、C++、Ruby和其他很多种语言,通过编程的方式远程访问Hive;
元数据管理(MetaStore) Hive将元数据存储在关系数据库中(如mysql、derby)。Hive的元数据包括:数据库名、表名及类型、字段名称及数据类型、数据所在位置等;
解释器 (SQLParser) :使用第三方工具(antlr)将HQL字符串转换成抽象语法树(AST);对AST进行语法分析,比如字段是否存在、SQL语义是否有误、表是否存在;
编译器 (Compiler) :将抽象语法树编译生成逻辑执行计划;
优化器 (Optimizer) :对逻辑执行计划进行优化,减少不必要的列、使用分区等;
执行器 (Executr) :把逻辑执行计划转换成可以运行的物理计划;
Hive通过CLI,JDBC/ODBC或HWI接受相关的Hive SQL查询,并通过Driver组件进行编译,分析优化,最后编程可执行的MapReduce任务。
Client
Hive允许client连接的方式有三个CLI(hive shell)、JDBC/ODBC(java访问hive)、WEBUI(浏览器访问 hive)。JDBC访问时中间件Thrift软件框架,跨语言服务开发。DDL DQL DML,整体仿写一套SQL语句。
1)client–需要下载安装包
2)JDBC/ODBC 也可以连接到Hive
现在主流都在倡导第二种 HiveServer2/beeline
做基于用户名和密码安全的一个校验 3)Web Gui
hive给我们提供了一套简单的web页面
我们可以通过这套web页面访问hive 做的太简陋了
Metastore
元数据包括表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是 外部表)、表的数据所在目录等。
一般需要借助于其他的数据载体(数据库)
主要用于存放数据库的建表语句等信息
推荐使用Mysql数据库存放数据
连接数据库需要提供:uri username password driver
Driver(面试题:sql语句是如何转化成MR任务的?)
元数据存储在数据库中,默认存在自带的derby数据库(单用户局限性)中,推荐使用Mysql进行存储。
1) 解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完 成,比如ANTLR;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
2) 编译器(Physical Plan):将AST编译生成逻辑执行计划。
3) 优化器(Query Optimizer):对逻辑执行计划进行优化。
4) 执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是 MR/Spark。
数据处理
Hive的数据存储在HDFS中,计算由MapReduce完成。HDFS和MapReduce是源码级别上的整合,两者结合最佳。解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。
10.Hive安装
10.1 上传压缩包并解压
tar -zxvf apache-hive-1.2.1-bin.tar.gz
10.2 修改目录名称
mv apache-hive-1.2.1-bin hive-1.2.1
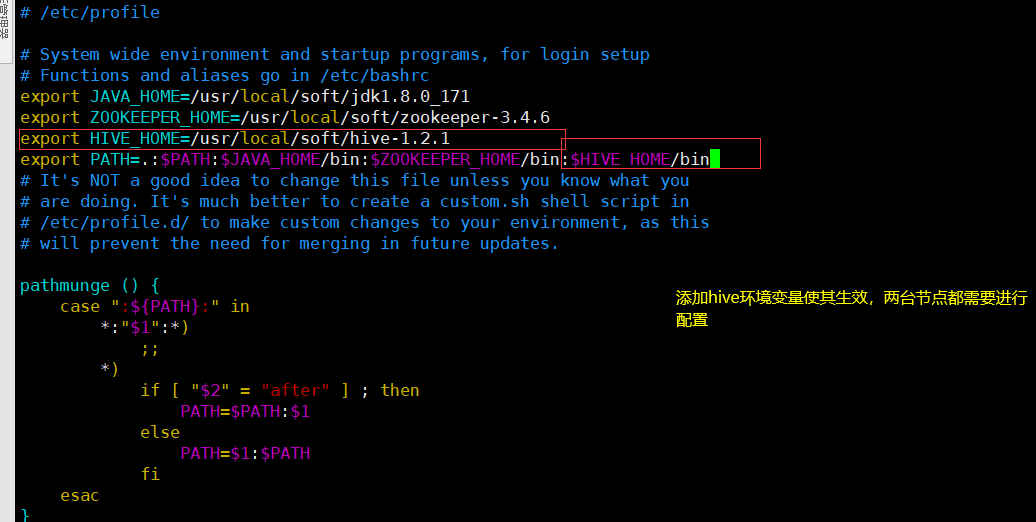
10.3 将hive的bin目录配置到环境变量中去
export HIVE_HOME=/usr/local/soft/hive-1.2.1
export PATH=.:$HIVE_HOME/bin

10.4 source命令让环境变量生效

10.5 备份配置文件
cp hive-env.sh.template hive-env.sh
cp hive-default.xml.template hive-site.xml
10.6 修改配置hive的配置文件(在conf目录下)
修改hive-env,sh
加入三行内容(大家根据自己的情况来添加,每个人安装路径可能有所不同)
HADOOP_HOME=/usr/local/soft/hadoop-2.7.6
JAVA_HOME=/usr/local/soft/jdk1.8.0_171
HIVE_HOME=/usr/local/soft/hive-1.2.1
修改hive-site.xml (找到对应的键对值进行修改,注意!!!是修改,而不是全部直接复制粘贴)
<!--数据存储位置就是我们在HDFS上看的目录-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
(注意:修改自己安装mysql的主机地址)
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.40.110:3306/hive?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=utf8&useSSL=false</value>
</property>
(固定写法,mysql驱动类的位置)
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
(mysql的用户名)
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
(mysql的用户密码)
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
(你的hive安装目录的tmp目录)
<property>
<name>hive.querylog.location</name>
<value>/usr/local/soft/hive-1.2.1/tmp</value>
</property>
(同上)
<property>
<name>hive.exec.local.scratchdir</name>
<value>/usr/local/soft/hive-1.2.1/tmp</value>
</property>
(同上)
<property>
<name>hive.downloaded.resources.dir</name>
<value>/usr/local/soft/hive-1.2.1/tmp</value>
</property>
<!--指定这个的时候,为了启动metastore服务的时候不用指定端口-->
<!--hive --service metastore -p 9083 & | hive --service metastore-->
<property>
<name>hive.metastore.uris</name>
<value>thrift://master:9083</value>
<description>thrift://master:9083</description>
</property>
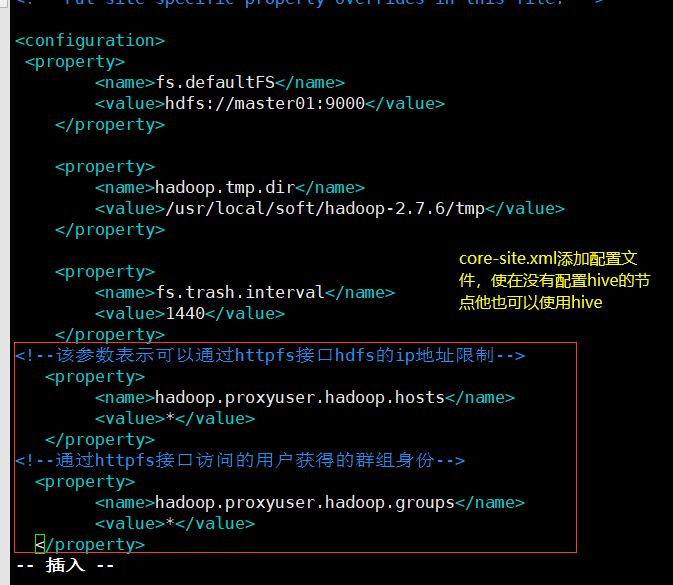
修改core-site.xml 直接改,改完重启就行,为后面beeline连接做准备(为从节点访问hive服务端做准备)
如果使hive可以在不同节点下运行,需要在master主节点添加配置文件。
接着将文件复制到node01和node02上
将hive整个拷贝到node01和node02上,并配置环境变量使其生效;


10.7 拷贝mysql驱动到$HIVE_HOME/lib目录下
cp /usr/local/soft/mysql-connector-java-5.1.49.jar ./
10.8 将hadoop的jline-0.9.94.jar的jar替换成hive的版本。
cp /usr/local/soft/hive-1.2.1/lib/jline-2.12.jar /usr/local/soft/hadoop-2.7.6/share/hadoop/yarn/lib/
10.9 拷贝到其他两个节点中去,因为可能我们会在其他的节点上当作客户端访问hive,注意,也需要配置环境变量,增加驱动jar包,将hadoop的jline-0.9.94.jar的jar替换成hive的版本
10.10 启动
启动hadoop
start-all.sh
1)第一种交互方式
启动hive
hive --service metastore
后台启动:nohup hive --service metastore >/dev/null &
hive
2)第二种交互方式
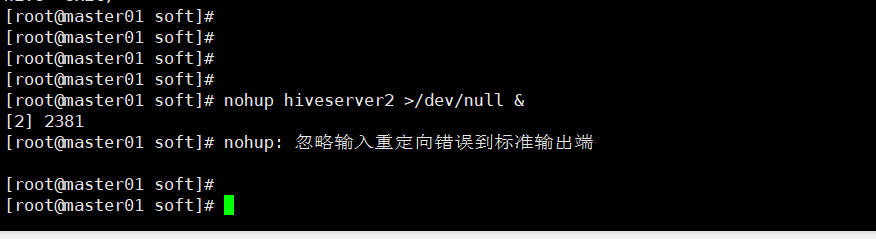
启动HiveServer2
hiveserver2
nohup hiveserver2 >/dev/null &
beeline -u jdbc:hive2://master01:10000 -n root
使用第二种方式连接hive,首先要在主节点创建一个hive服务,接着从节点进行连接(Hive启动为一个服务器,对外提供服务,其他机器可以通过客户端通过协议连接到服务器,来完成访问操作,这是生产环境用法最多的)
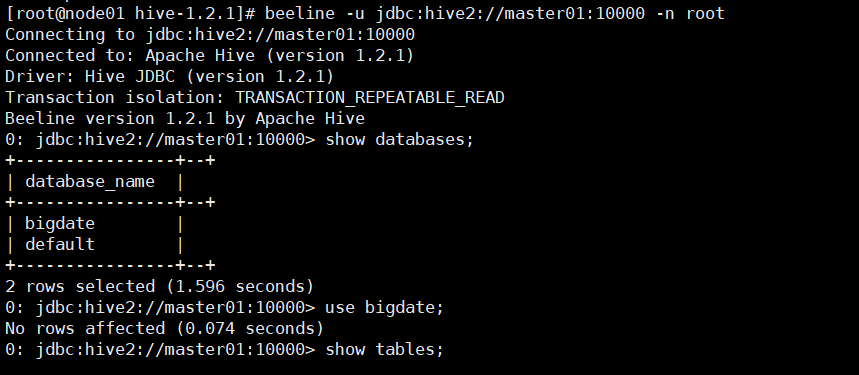
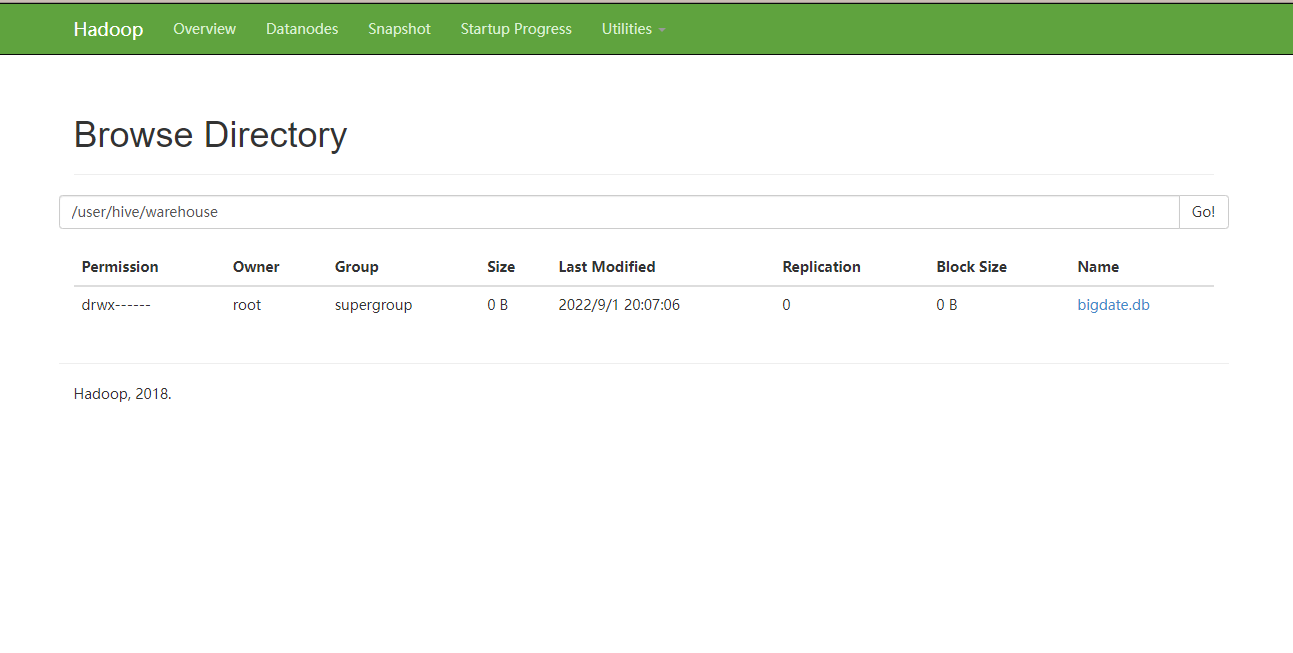
创建过后的数据在ui界面库是以目录的方式存在,表是以文件的形式存在在目录中
3)第三种交互方式
使用 –e 参数来直接执行hql的语句
bin/hive -e "show databases;"
使用 –f 参数通过指定文本文件来执行hql的语句
特点:执行完sql后,回到linux命令行。
vim hive.sql
use myhive;
select * from test;
hive -f hive.sql
4)hive cli和beeline cli的区别
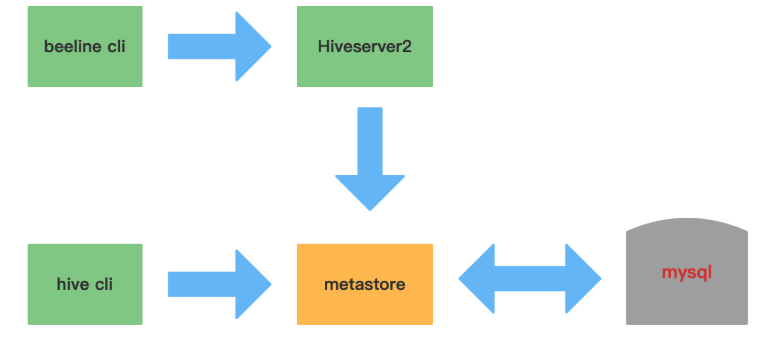
11.Hive元数据
Hive元数据库中一些重要的表结构及用途,方便Impala、SparkSQL、Hive等组件访问元数据库的理解。
1、存储Hive版本的元数据表(VERSION),该表比较简单,但很重要,如果这个表出现问题,根本进不来Hive-Cli。比如该表不存在,当启动Hive-Cli的时候,就会报错“Table 'hive.version' doesn't exist”
2、Hive数据库相关的元数据表(DBS、DATABASE_PARAMS)
DBS:该表存储Hive中所有数据库的基本信息。
DATABASE_PARAMS:该表存储数据库的相关参数。
3、Hive表和视图相关的元数据表
主要有TBLS、TABLE_PARAMS、TBL_PRIVS,这三张表通过TBL_ID关联。
TBLS:该表中存储Hive表,视图,索引表的基本信息。
TABLE_PARAMS:该表存储表/视图的属性信息。
TBL_PRIVS:该表存储表/视图的授权信息。
4、Hive文件存储信息相关的元数据表
主要涉及SDS、SD_PARAMS、SERDES、SERDE_PARAMS,由于HDFS支持的文件格式很多,而建Hive表时候也可以指定各种文件格式,Hive在将HQL解析成MapReduce时候,需要知道去哪里,使用哪种格式去读写HDFS文件,而这些信息就保存在这几张表中。
SDS:该表保存文件存储的基本信息,如INPUT_FORMAT、OUTPUT_FORMAT、是否压缩等。TBLS表中的SD_ID与该表关联,可以获取Hive表的存储信息。
SD_PARAMS: 该表存储Hive存储的属性信息。
SERDES:该表存储序列化使用的类信息。
SERDE_PARAMS:该表存储序列化的一些属性、格式信息,比如:行、列分隔符。
5、Hive表字段相关的元数据表
主要涉及COLUMNS_V2:该表存储表对应的字段信息。
12、Hive的基本操作
12.1 Hive库操作
12.1.1 创建数据库
1)创建一个数据库,数据库在HDFS上的默认存储路径是/hive/warehouse/*.db。
create database testdb;
2)避免要创建的数据库已经存在错误,增加if not exists判断。(标准写法)
create database if not exists testdb;
12.2.2 创建数据库和位置
create database if not exists dept location '/testdb.db';
12.2.3 修改数据库
数据库的其他元数据信息都是不可更改的,包括数据库名和数据库所在的目录位置。(重点关注哪些不能改,以及为什么!!)
alter database dept set dbproperties('createtime'='20220531');
12.2.4 数据库详细信息
1)显示数据库(show)
show databases;
2)可以通过like进行过滤
show databases like 't*';
3)查看详情(desc)
desc database testdb;
4)切换数据库(use)
use testdb;
12.2.5 删除数据库(将删除的目录移动到回收站中)
1)最简写法
drop database testdb;
2)如果删除的数据库不存在,最好使用if exists判断数据库是否存在。否则会报错:FAILED: SemanticException [Error 10072]: Database does not exist: db_hive
drop database if exists testdb;
3)如果数据库不为空,使用cascade命令进行强制删除。报错信息如下FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. InvalidOperationException(message:Database db_hive is not empty. One or more tables exist.)
drop database if exists testdb cascade;
12.2 Hive数据类型
12.2.1 基础数据类型
| 类型 | Java数据类型 | 描述 |
|---|---|---|
| TINYINT | byte | 8位有符号整型。取值范围:-128~127。 |
| SMALLINT | short | 16位有符号整型。取值范围:-32768~32767。 |
| INT | int | 32位有符号整型。取值范围:-2 31 ~2 31 -1。 |
| BIGINT | long | 64位有符号整型。取值范围:-2 63 +1~2 63 -1。 |
| BINARY | 二进制数据类型,目前长度限制为8MB。 | |
| FLOAT | float | 32位二进制浮点型。 |
| DOUBLE | double | 64位二进制浮点型。 |
| DECIMAL(precision,scale) | 10进制精确数字类型。precision:表示最多可以表示多少位的数字。取值范围:1 <= precision <= 38。scale:表示小数部分的位数。取值范围: 0 <= scale <= 38。如果不指定以上两个参数,则默认为decimal(10,0)。 | |
| VARCHAR(n) | 变长字符类型,n为长度。取值范围:1~65535。 | |
| CHAR(n) | 固定长度字符类型,n为长度。最大取值255。长度不足则会填充空格,但空格不参与比较。 | |
| STRING | string | 字符串类型,目前长度限制为8MB。 |
| DATE | 日期类型,格式为yyyy-mm-dd。取值范围:0000-01-01~9999-12-31。 |
|
| DATETIME | 日期时间类型。取值范围:0000-01-01 00:00:00.000~9999-12-31 23.59:59.999,精确到毫秒。 | |
| TIMESTAMP | 与时区无关的时间戳类型。取值范围:0000-01-01 00:00:00.000000000~9999-12-31 23.59:59.999999999,精确到纳秒。说明 对于部分时区相关的函数,例如cast( as string),要求TIMESTAMP按照与当前时区相符的方式来展现。 | |
| BOOLEAN | boolean | BOOLEAN类型。取值:True、False。 |
12.2.2 复杂的数据类型
| 类型 | 定义方法 | 构造方法 |
|---|---|---|
| ARRAY | array<int>``array<struct<a:int, b:string>> |
array(1, 2, 3)``array(array(1, 2), array(3, 4)) |
| MAP | map<string, string>``map<smallint, array<string>> |
map(“k1”, “v1”, “k2”, “v2”)``map(1S, array(‘a’, ‘b’), 2S, array(‘x’, ‘y’)) |
| STRUCT | struct<x:int, y:int>struct<field1:bigint, field2:array<int>, field3:map<int, int>> named_struct(‘x’, 1, ‘y’, 2)named_struct(‘field1’, 100L, ‘field2’, array(1, 2), ‘field3’, map(1, 100, 2, 200)) |
Hive有三种复杂数据类型ARRAY、MAP 和 STRUCT。ARRAY和MAP与Java中的Array和Map类似,而STRUCT与C语言中的Struct类似,它封装了一个命名字段集合,复杂数据类型允许任意层次的嵌套。还有一个uniontype< 所有类型,所有类型… > 。
数组:array< 所有类型 >;
Map < 基本数据类型,所有数据类型 >;
struct < 名:所有类型[注释] >;
uniontype< 所有类型,所有类型… >
12.3 Hive表操作
Hive的存储格式:
Hive没有专门的数据文件格式,常见的有以下几种:
TEXTFILE
SEQUENCEFILE
AVRO
RCFILE
ORCFILE
PARQUET
TextFile:
TEXTFILE 即正常的文本格式,是Hive默认文件存储格式,因为大多数情况下源数据文件都是以text文件格式保存(便于查看验数和防止乱码)。此种格式的表文件在HDFS上是明文,可用hadoop fs -cat命令查看,从HDFS上get下来后也可以直接读取。
TEXTFILE 存储文件默认每一行就是一条记录,可以指定任意的分隔符进行字段间的分割。但这个格式无压缩,需要的存储空间很大。虽然可结合Gzip、Bzip2、Snappy等使用,使用这种方式,Hive不会对数据进行切分,从而无法对数据进行并行操作。
一般只有与其他系统由数据交互的接口表采用TEXTFILE 格式,其他事实表和维度表都不建议使用。
RCFile:
Record Columnar的缩写。是Hadoop中第一个列文件格式。能够很好的压缩和快速的查询性能。通常写操作比较慢,比非列形式的文件格式需要更多的内存空间和计算量。 RCFile是一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据`列式存储`,有利于数据压缩和快速的列存取。
ORCFile:
Hive从0.11版本开始提供了ORC的文件格式,ORC文件不仅仅是一种列式文件存储格式,最重要的是有着很高的压缩比,并且对于MapReduce来说是可切分(Split)的。因此,在Hive中使用ORC作为表的文件存储格式,不仅可以很大程度的节省HDFS存储资源,而且对数据的查询和处理性能有着非常大的提升,因为ORC较其他文件格式压缩比高,查询任务的输入数据量减少,使用的Task也就减少了。ORC能很大程度的节省存储和计算资源,但它在读写时候需要消耗额外的CPU资源来压缩和解压缩,当然这部分的CPU消耗是非常少的。
Parquet:
通常我们使用关系数据库存储结构化数据,而关系数据库中使用数据模型都是扁平式的,遇到诸如List、Map和自定义Struct的时候就需要用户在应用层解析。但是在大数据环境下,通常数据的来源是服务端的埋点数据,很可能需要把程序中的某些对象内容作为输出的一部分,而每一个对象都可能是嵌套的,所以如果能够原生的支持这种数据,这样在查询的时候就不需要额外的解析便能获得想要的结果。Parquet的灵感来自于2010年Google发表的Dremel论文,文中介绍了一种支持嵌套结构的存储格式,并且使用了列式存储的方式提升查询性能。Parquet仅仅是一种存储格式,它是语言、平台无关的,并且不需要和任何一种数据处理框架绑定。这也是parquet相较于orc的仅有优势:支持嵌套结构。Parquet 没有太多其他可圈可点的地方,比如他不支持update操作(数据写成后不可修改),不支持ACID等.
SEQUENCEFILE:
SequenceFile是Hadoop API 提供的一种二进制文件,它将数据以<key,value>的形式序列化到文件中。这种二进制文件内部使用Hadoop 的标准的Writable 接口实现序列化和反序列化。它与Hadoop API中的MapFile 是互相兼容的。Hive 中的SequenceFile 继承自Hadoop API 的SequenceFile,不过它的key为空,使用value 存放实际的值, 这样是为了避免MR 在运行map 阶段的排序过程。SequenceFile支持三种压缩选择:NONE, RECORD, BLOCK。 Record压缩率低,一般建议使用BLOCK压缩。 SequenceFile最重要的优点就是Hadoop原生支持较好,有API,但除此之外平平无奇,实际生产中不会使用。
AVRO:
Avro是一种用于支持数据密集型的二进制文件格式。它的文件格式更为紧凑,若要读取大量数据时,Avro能够提供更好的序列化和反序列化性能。并且Avro数据文件天生是带Schema定义的,所以它不需要开发者在API 级别实现自己的Writable对象。Avro提供的机制使动态语言可以方便地处理Avro数据。最近多个Hadoop 子项目都支持Avro 数据格式,如Pig 、Hive、Flume、Sqoop和Hcatalog。
Hive的四大常用存储格式存储效率及执行速度对比
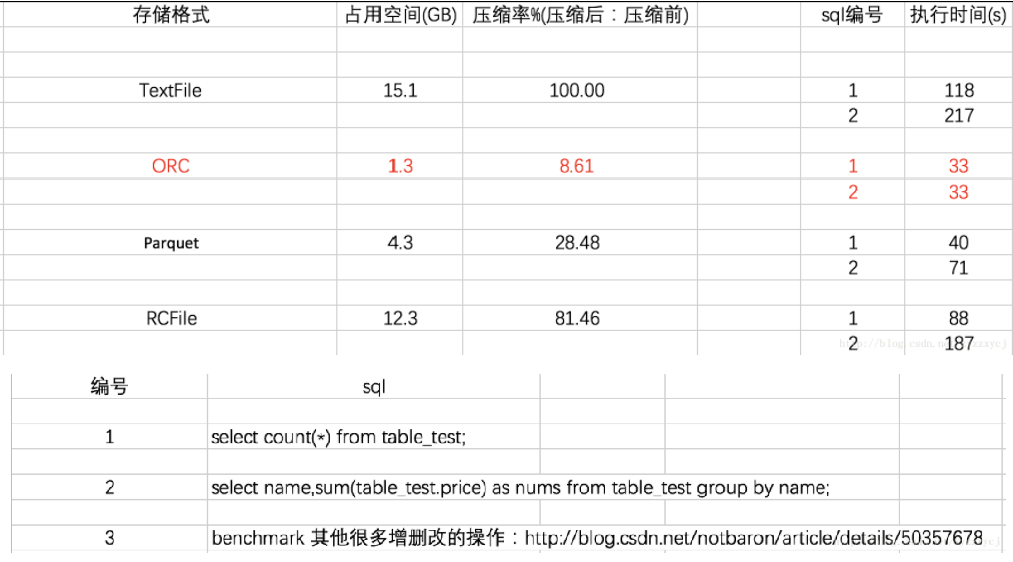
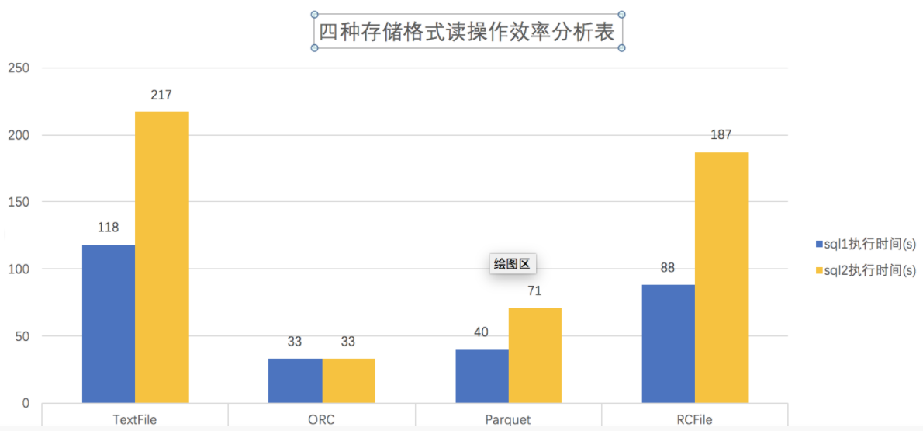
结论:ORCFILE存储文件读操作效率最高
耗时比较:ORC<Parquet<RC<Text
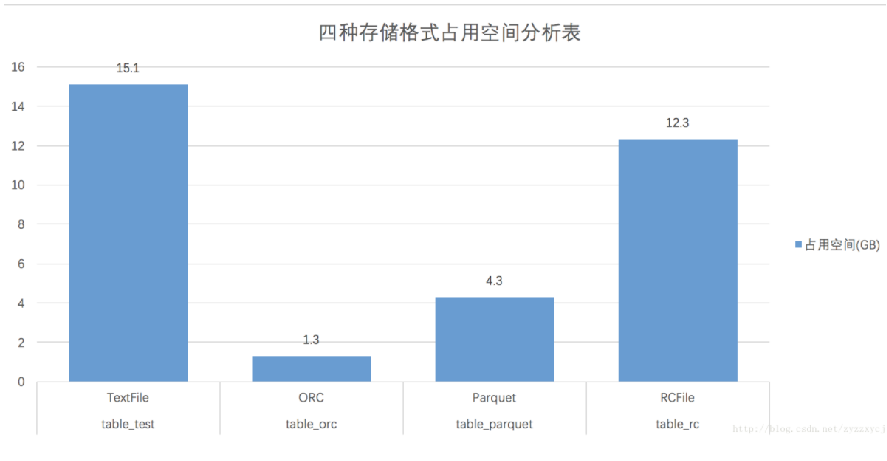
结论:ORCFILE存储文件占用空间少,压缩效率高
占用空间:ORC<Parquet<RC<Text
12.3.1 创建表
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
字段解释说明:
- CREATE TABLE
创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXISTS 选项来忽略这个异常。
- EXTERNAL
关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION)
创建内部表时,会将数据移动到数据仓库指向的路径(默认位置);
创建外部表时,仅记录数据所在的路径,不对数据的位置做任何改变。在
删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
- COMMENT:
为表和列添加注释。
- PARTITIONED BY
创建分区表
- CLUSTERED BY
创建分桶表
- SORTED BY
不常用
- ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char] | SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
用户在建表的时候可以自定义SerDe或者使用自带的SerDe。
如果没有指定ROW FORMAT 或者ROW FORMAT DELIMITED,将会使用自带的SerDe。
在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的SerDe,Hive通过SerDe确定表的具体的列的数据。
SerDe是Serialize/Deserilize的简称,目的是用于序列化和反序列化。
- STORED AS指定存储文件类型
常用的存储文件类型:SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列式存储格式文件)
如果文件数据是纯文本,可以使用STORED AS TEXTFILE。
如果数据需要压缩,使用 STORED AS SEQUENCEFILE。
- LOCATION :
指定表在HDFS上的存储位置。
- LIKE
允许用户复制现有的表结构,但是不复制数据。
建表1:全部使用默认建表方式
create table students
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; // 必选,指定列分隔符
建表2:指定location (这种方式也比较常用)
create table students2
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/input1'; // 指定Hive表的数据的存储位置,一般在数据已经上传到HDFS,想要直接使用,会指定Location,通常Locaion会跟外部表一起使用,内部表一般使用默认的location
建表3:指定存储格式
create table students3
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS rcfile; // 指定储存格式为rcfile,inputFormat:RCFileInputFormat,outputFormat:RCFileOutputFormat,如果不指定,默认为textfile,注意:除textfile以外,其他的存储格式的数据都不能直接加载,需要使用从表加载的方式。
建表4:create table xxxx as select_statement(SQL语句) (这种方式比较常用)
create table students4 as select * from students2;
建表5:create table xxxx like table_name 只想建表,不需要加载数据
create table students5 like students;
简单用户信息表创建:
create table t_user( id int, uname string, pwd string, gender string, age int ) row format delimited fields terminated by ',' lines terminated by '\n';1,admin,123456,男,18 2,zhangsan,abc123,男,23 3,lisi,654321,女,16复杂人员信息表创建:
create table IF NOT EXISTS t_person( name string, friends array<string>, children map<string,int>, address struct<street:string ,city:string> ) row format delimited fields terminated by ',' collection items terminated by '_' map keys terminated by ':' lines terminated by '\n';songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,beng bu_anhui yangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,he fei_anhui
12.3.2 显示表
show tables;
show tables like 'u';
desc t_person;
desc formatted t_person;
2.3.3 加载数据
1、使用hdfs dfs -put '本地数据' 'hive表对应的HDFS目录下'
2、使用 load data inpath
下列命令需要在hive shell里执行
// 将HDFS上的/input1目录下面的数据 移动至 students表对应的HDFS目录下,注意是 移动、移动、移动
load data inpath '/input1/students.txt' into table students;
// 清空表
truncate table students;
// 加上 local 关键字 可以将Linux本地目录下的文件 上传到 hive表对应HDFS 目录下 原文件不会被删除
load data local inpath '/usr/local/soft/data/students.txt' into table students;
// overwrite 覆盖加载
load data local inpath '/usr/local/soft/data/students.txt' overwrite into table students;
3、create table xxx as SQL语句
4、insert into table xxxx SQL语句 (没有as)
// 将 students表的数据插入到students2 这是复制 不是移动 students表中的表中的数据不会丢失
insert into table students2 select * from students;
// 覆盖插入 把into 换成 overwrite
insert overwrite table students2 select * from students;
2.3.4 修改列
查询表结构
desc students2;
添加列
alter table students2 add columns (education string);
查询表结构
desc students2;
更新列
alter table stduents2 change education educationnew string;
2.3.5 删除表
drop table students2;
2.4 Hive内外部表
面试题:内部表和外部表的区别?如何创建外部表?工作中使用外部表
2.4.1 hive内部表
当创建好表的时候,HDFS会在当前表所属的库中创建一个文件夹
当设置表路径的时候,如果直接指向一个已有的路径,可以直接去使用文件夹中的数据
当load数据的时候,就会将数据文件存放到表对应的文件夹中
而且数据一旦被load,就不能被修改
我们查询数据也是查询文件中的文件,这些数据最终都会存放到HDFS
当我们删除表的时候,表对应的文件夹会被删除,同时数据也会被删除
默认建表的类型就是内部表
// 内部表
create table students_internal
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/input2';
hive> dfs -put /usr/local/soft/data/students.txt /input2/;
2.4.1 Hive外部表
外部表说明
外部表因为是指定其他的hdfs路径的数据加载到表中来,所以hive会认为自己不完全独占这份数据
删除hive表的时候,数据仍然保存在hdfs中,不会删除。
// 外部表
create external table students_external1
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/user/hive/warehouse/bigdata01.db/';
hive> dfs -put /usr/local/soft/data/students.txt /input3/;
删除表测试一下:
hive> drop table students_internal;
Moved: 'hdfs://master:9000/input2' to trash at: hdfs://master:9000/user/root/.Trash/Current
OK
Time taken: 0.474 seconds
hive> drop table students_external;
OK
Time taken: 0.09 seconds
hive>
一般在公司中,使用外部表多一点,因为数据可以需要被多个程序使用,避免误删,通常外部表会结合location一起使用
外部表还可以将其他数据源中的数据 映射到 hive中,比如说:hbase,ElasticSearch......
设计外部表的初衷就是 让 表的元数据 与 数据 解耦
- 操作案例: 分别创建dept,emp,salgrade。并加载数据。
创建数据文件存放的目录
hdfs dfs -mkdir -p /shujia/bigdata19/dept
hdfs dfs -mkdir -p /shujia/bigdata19/emp
hdfs dfs -mkdir -p /shujia/bigdata19/salgrade
- 创建dept表
CREATE EXTERNAL TABLE IF NOT EXISTS dept (
DEPTNO int,
DNAME varchar(255),
LOC varchar(255)
) row format delimited fields terminated by ','
location '/shujia/bigdata19/dept';
10,ACCOUNTING,NEW YORK
20,RESEARCH,DALLAS
30,SALES,CHICAGO
40,OPERATIONS,BOSTON
- 创建emp表
CREATE EXTERNAL TABLE IF NOT EXISTS emp (
EMPNO int,
ENAME varchar(255),
JOB varchar(255),
MGR int,
HIREDATE date,
SAL decimal(10,0),
COMM decimal(10,0),
DEPTNO int
) row format delimited fields terminated by ','
location '/shujia/bigdata19/emp';
7369,SMITH,CLERK,7902,1980-12-17,800,null,20
7499,ALLEN,SALESMAN,7698,1981-02-20,1600,300,30
7521,WARD,SALESMAN,7698,1981-02-22,1250,500,30
7566,JONES,MANAGER,7839,1981-04-02,2975,null,20
7654,MARTIN,SALESMAN,7698,1981-09-28,1250,1400,30
7698,BLAKE,MANAGER,7839,1981-05-01,2850,null,30
7782,CLARK,MANAGER,7839,1981-06-09,2450,null,10
7788,SCOTT,ANALYST,7566,1987-07-13,3000,null,20
7839,KING,PRESIDENT,null,1981-11-17,5000,null,10
7844,TURNER,SALESMAN,7698,1981-09-08,1500,0,30
7876,ADAMS,CLERK,7788,1987-07-13,1100,null,20
7900,JAMES,CLERK,7698,1981-12-03,950,null,30
7902,FORD,ANALYST,7566,1981-12-03,3000,null,20
7934,MILLER,CLERK,7782,1982-01-23,1300,null,10
- 创建salgrade表
CREATE EXTERNAL TABLE IF NOT EXISTS salgrade (
GRADE int,
LOSAL int,
HISAL int
) row format delimited fields terminated by ','
location '/shujia/bigdata19/salgrade';
1,700,1200
2,1201,1400
3,1401,2000
4,2001,3000
5,3001,9999
2.5 Hive导出数据
将表中的数据备份
- 将查询结果存放到本地
//创建存放数据的目录
mkdir -p /usr/local/soft/shujia
//导出查询结果的数据(导出到Node01上)
insert overwrite local directory '/usr/local/soft/shujia/person_data' select * from t_person;
- 按照指定的方式将数据输出到本地
-- 创建存放数据的目录
mkdir -p /usr/local/soft/shujia
-- 导出查询结果的数据
insert overwrite local directory '/usr/local/soft/shujia/person'
ROW FORMAT DELIMITED fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
lines terminated by '\n'
select * from t_person;
- 将查询结果输出到HDFS
-- 创建存放数据的目录
hdfs dfs -mkdir -p /shujia/bigdata17/copy
-- 导出查询结果的数据
insert overwrite local directory '/usr/local/soft/shujia/students_data2' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' select * from students
- 直接使用HDFS命令保存表对应的文件夹
// 创建存放数据的目录
hdfs dfs -mkdir -p /shujia/bigdata17/person
// 使用HDFS命令拷贝文件到其他目录
hdfs dfs -cp /hive/warehouse/t_person/* /shujia/bigdata17/person
-
将表结构和数据同时备份
将数据导出到HDFS
//创建存放数据的目录 hdfs dfs -mkdir -p /shujia/bigdata17/copy //导出查询结果的数据 export table t_person to '/shujia/bigdata17/copy'; 删除表结构
drop table t_person; 恢复表结构和数据
import from '/shujia/bigdata17';注意:时间不同步,会导致导入导出失败

 浙公网安备 33010602011771号
浙公网安备 33010602011771号