SQLSERVER - 性能优化
行存储和列存储#
行存储
场景:数据维护,数据检索
列存储
场景:数据分析

行存储和列存储#
行存储
场景:数据维护,数据检索
列存储
场景:数据分析

索引的了解#

聚集索引#
-
聚集索引中,叶节点包含基础表的数据页。
-
数据链内的页和行将按聚集索引键值进行排序。
-
主键通常是聚集索引,但可以不是聚集索引。

非聚集索引#
-
基础表的数据行不会根据其非聚集键按顺序排序和存储。
-
非聚集索引的叶级别是由索引页而不是由数据页组成。
-
非聚集索引的叶级别的索引页包含键列以及包含列。

包含列#
例如:
查询A2,B2,如果非聚集索引只有A2,就会使用 Key Lookup 查询B2 。
包含列的操作:把需要查询的 B2 添加到当前包含列,就会把 B2 的坐标添加到 A2 的当前索引。
优点:查询快。
缺点:增加索引体积。
建议:不要加太多,10个以下。

筛选器#
对 custId 模糊查询的时候,筛选器能更快的响应。

索引选择#
A和B字段都有索引,不是谁在前面就选谁。
根据统计信息来选择


常见的索引设计建议#
√优先选择唯一性索引
√为常作为查询条件的字段建立索引
√经常需要排序、分组和联合操作的字段建立索引
√尽量使用数据量少的索引,如果字段数据大,索引表体积相对较大,当发生索引扫描时影响比较严重√控制索引数量,索引的字段发生修改时需要更新索引,过多索引会影响表性能
√删除很少使用的索引,可以通过报表查看索引使用情况
√复合索引区分度大的字段放在前面
√区分度小的字段不建议创建索引,比如性别
√命名建议用索引的字段名作为名称,方便在查询计划中分辨,不建议添加“IX”之类的前缀,SQLServer索引名称允许跨表重名的
SQL 执行计划#
1 连线#

1、越粗表示扫描影响的行数愈多。
2、Actual Number of Rows 扫描中实际影响的的行数。
3、Estimated Number of Rows 预估扫描影响的行数。
4、Estimated row size 操作符生成的行的估计大小(字节)。
5、Estimated Data Size 预估影响的数据的大小。
2、Tooltips,当前步骤执行信息#

Note:这个tips的信息告诉我们执行的对象是什么,采用的操作操作是什么,查找的数据是什么,使用的索引是什么,排序与否,预估cpu、I/O、影响行数,实际行数等信息。具体参数清单参见msdn:显示图形执行计划 (SQL Server Management Studio) | Microsoft Learn
SQL Server查找数据记录的几种方式:#
1.Table Scan--表扫描(最慢),对表记录逐行进行检查,对于没有索引或者查询条件不走索引时会进行全表扫描;
2.Clustered Index Scan--聚集索引扫描(较慢),按聚集索引对记录逐行进行检查,对有主键/聚集索引的表进行无条件查找或者使用主键/聚集索引过滤;
3.Index Scan--索引扫描(普通),根据索引滤出部分数据在进行逐行检查;
聚集索引扫描:聚集索引的数据体积实际是就是表本身,也就是说表有多少行多少列,聚集所有就有多少行多少列,那么聚集索引扫描就跟表扫描差不多,也要进行全表扫描,遍历所有表数据,查找出你想要的数据。
非聚集索引扫描:非聚集索引的体积是根据你的索引创建情况而定的,可以只包含你要查询的列。那么进行非聚集索引扫描,便是你非聚集中包含的列的所有行进行遍历,查找出你想要的数据。
4.Index Seek--索引查找(较快),根据索引定位记录所在位置再取出记录,建立非聚集索引并把其他显示列加入索引中;
5.Clustered Index Seek--聚集索引查找(最快),直接根据聚集索引获取记录,建立非聚集索引并把其他显示列加入索引中并把聚集索引列当作条件;
聚集索引查找:聚集索引包含整个表的数据,也就是在聚集索引的数据上根据键值取数据。
非聚集索引查找:非聚集索引包含创建索引时所包含列的数据,在这些非聚集索引的数据上根据键值取数据。
6.Key Lookup--书签查找:通过非聚集索引找到所求的行,但这个索引并不包含显示的列,因此还要额外去基本表中找到这些列,所以要进行键查找,如果基本表在堆中则Key Lookup会变成RID查找。
查找与扫描在性能上完全不是一个级别的,扫描需要遍历整张表,而查找只需要通过键值直接提取数据,返回结果,性能要好。
当你查找的列没有完全被非聚集索引包含,就需要使用键值查找在聚集索引上查找非聚集索引不包含的列。
7.RID--书签查找:同上
如果有些SQL执行很慢,可以用执行计划看一下是否包含太多“扫描”操作,可以考虑为这些字段建立索引,建立索引切记不要再经常有更新操作的字段上建立,每次更新数据和插入数据都会导致重建索引的操作,会增加索引的维护成本。
跟键值查找类似,只不过RID查找,是需要查找的列没有完全被非聚集索引包含,而剩余的列所在的表又不存在聚集索引,不能键值查找,只能根据行表示Rid来查询数据。
| Showplan 运算符 | 说明 | |
|---|---|---|
 |
Table Scan | Table Scan 运算符从查询执行计划的 Argument 列所指定的表中检索所有行。 如果 WHERE:() 谓词出现在 Argument 列中,则仅返回满足此谓词的那些行。 Table Scan 既是一个逻辑运算符,也是一个物理运算符。 |
 |
Clustered Index Scan | Clustered Index Scan 运算符会扫描查询执行计划的 Argument 列中指定的聚集索引。 存在可选 WHERE:() 谓词时,则只返回满足该谓词的那些行。 如果 Argument 列包含 ORDERED 子句,则表示查询处理器已请求按聚集索引排列行的顺序返回行输出。 如果没有 ORDERED 子句,存储引擎将以最佳方式扫描索引,而无需对输出进行排序。 Clustered Index Scan 既是一个逻辑运算符,也是一个物理运算符。 |
 |
Index Scan | Index Scan 运算符从 Argument 列中指定的非聚集索引中检索所有行。 如果可选的 WHERE:() 谓词出现在 Argument 列中,则仅返回满足此谓词的那些行。 Index Scan 既是一个逻辑运算符,也是一个物理运算符。 |
 |
Index Seek | Index Seek 运算符利用索引的查找功能从非聚集索引中检索行。 Argument 列包含所使用的非聚集索引的名称。 它还包括 SEEK:() 谓词。 存储引擎仅使用索引来处理满足 SEEK:() 谓词的行。 它可能还包含一个 WHERE:() 谓词,其中存储引擎对满足 SEEK:() 谓词的所有行进行计算(不使用索引来完成)。 如果 Argument 列包含 ORDERED 子句,则表示查询处理器已决定必须按非聚集索引排序行的顺序返回行。 如果没有 ORDERED 子句,则存储引擎将以最佳方式(不保证对输出排序)搜索索引。 如果让输出保持其顺序,则效率可能低于生成非排序输出。 Index Seek 既是一个逻辑运算符,也是一个物理运算符。 |
 |
Clustered Index Seek | Clustered Index Seek 运算符可以利用索引的查找功能从聚集索引中检索行。 Argument 列包含所使用的聚集索引名称和 SEEK:() 谓词。 存储引擎仅使用索引来处理满足此 SEEK:() 谓词的行。它还包括 WHERE:() 谓词,其中存储引擎对满足 SEEK:() 谓词的所有行进行计算, 但此操作是可选的,并且不使用索引来完成此过程。 如果 Argument 列包含 ORDERED 子句,则表示查询处理器已决定必须按聚集索引排序行的顺序返回行。 如果没有 ORDERED 子句,存储引擎将以最佳方式搜索索引,而不对输出进行必要的排序。 若允许输出保持顺序,则效率可能比生成非排序输出的效率低。 出现关键字 LOOKUP 时,将执行书签查找。 在 SQL Server 2008 (10.0.x) 及更高版本中,键查找运算符提供书签查找功能。 Clustered Index Seek 既是一个逻辑运算符,也是一个物理运算符。 |
 |
Key Lookup | Key Lookup 运算符是在具有聚集索引的表上进行的书签查找。 Argument 列包含聚集索引的名称和用来在聚集索引中查找行的聚集键。 Key Lookup 通常带有 Nested Loops 运算符。 如果 Argument 列中出现 WITH PREFETCH 子句, 则表示查询处理器已决定在聚集索引中查找书签时将使用异步预提取(预读)作为最佳选择。 在查询计划中使用 Key Lookup 运算符表明该查询可能会从性能优化中获益。 例如,添加涵盖索引可能会提高查询性能。 |
 |
RID Lookup | RID Lookup 是使用提供的行标识符 (RID) 在堆上进行的书签查找。 Argument 列包含用于查找表中的行的书签标签和从中查找行的表的名称。 RID Lookup 通常带有 NESTED LOOP JOIN。 RID Lookup 是一个物理运算符。 有关书签查找的详细信息,请参阅 MSDN SQL Server 博客中的Bookmark Lookup(书签查找)。 |
数据 JOIN方式#
在SQL Server中,每个join命令,都会在内部执行时采用这几种更具体的方式来运行:
Nested Loops join:如果一个联接输入很小,而另一个联接输入很大而且已在其联接列上创建了索引, 则索引 Nested Loops 连接是最快的联接操作,因为它们需要的 I/O 和比较都最少。嵌套循环联接也称为“嵌套迭代”,它将一个联接输入用作外部输入表(显示为图形执行计划中的顶端输入),将另一个联接输入用作内部(底端)输入表。外部循环逐行处理外部输入表。内部循环会针对每个外部行执行,在内部输入表中搜索匹配行。最简单的情况是,搜索时扫描整个表或索引;这称为“单纯嵌套循环联接”。如果搜索时使用索引,则称为“索引嵌套循环联接”。如果将索引生成为查询计划的一部分(并在查询完成后立即将索引破坏),则称为“临时索引嵌套循环联接”。
如果外部输入较小而内部输入较大且预先创建了索引,则嵌套循环联接尤其有效。在小事务中(只影响较少数据的事务),索引嵌套循环联接优于合并联接和哈希联接,但在大型查询中,嵌套循环联接通常不是最佳选择。
-
Merge Join:如果两个联接输入并不小但已在二者联接列上排序(例如,如果它们是通过扫描已排序的索引获得的),则合并联接是最快的联接操作。如果两个联接输入都很大,而且这两个输入的大小差不多,则预先排序的合并联接提供的性能与哈希联接相近。但是,如果这两个输入的大小相差很大,则哈希联接操作通常快得多。合并联接要求两个输入都在合并列上排序,而合并列由联接谓词的等效 (ON) 子句定义。通常,查询优化器扫描索引(如果在适当的一组列上存在索引),或在合并联接的下面放一个排序运算符。在极少数情况下,虽然可能有多个等效子句,但只用其中一些可用的等效子句获得合并列。 -
Hash Join:哈希联接可以有效处理未排序的大型非索引输入。它们对复杂查询的中间结果很有用,因为:①.中间结果未经索引(除非已经显式保存到磁盘上然后创建索引),而且通常不为查询计划中的下一个操作进行适当的排序。②.查询优化器只估计中间结果的大小。由于对于复杂查询,估计可能有很大的误差,因此如果中间结果比预期的大得多,则处理中间结果的算法不仅必须有效而且必须适度弱化。哈希联接可以减少使用非规范化。非规范化一般通过减少联接操作获得更好的性能,尽管这样做有冗余之险(如不一致的更新)。哈希联接则减少使用非规范化的需要。哈希联接使垂直分区(用单独的文件或索引代表单个表中的几组列)得以成为物理数据库设计的可行选项。
| Showplan 运算符 | 说明 | |
|---|---|---|
 |
合并联接 Merge Join |
Merge Join 运算符执行内部联接、左外部联接、左半部联接、左反半部联接、右外部联接、右半部联接、右反半部联接和联合逻辑运算。 在 Argument 列中,如果操作执行一对多联接,则 Merge Join 运算符将包含 MERGE:() 谓词;如果操作执行多对多联接,则该运算符将包含 MANY-TO-MANY MERGE:() 谓词。 Argument 列还包含一个用于执行操作的列的列表,该列表以逗号分隔。 Merge Join 运算符要求在各自的列上对两个输入进行排序,这可以通过在查询计划中插入显式排序操作来实现。 如果不需要显式排序(例如,如果数据库内有合适的 B 树索引或可以对多个操作(如合并联接和对汇总分组)使用排序顺序),则合并联接尤其有效。 Merge Join 是一个物理运算符。 有关详细信息,请参阅理解合并联接。 |
 |
Nested Loops | Nested Loops 运算符执行内部联接、左外部联接、左半部联接和左反半部联接逻辑运算。 嵌套循环联接通常使用索引,针对外部表的每一行在内部表中执行搜索。 查询处理器根据预计的开销来决定是否对外部输入进行排序,以改进内部输入索引上的搜索定位。 将基于所执行的逻辑操作返回所有满足 Argument 列中的(可选)谓词的行。 如果 OPTIMIZED 特性设置为“True”,则表示使用了优化的嵌套循环(或批处理排序)。 Nested Loops 是一个物理运算符。 有关详细信息,请参阅了解嵌套循环联接。 |
| 无 | Hash join | 哈希联接可以有效处理未排序的大型非索引输入。 它们对复杂查询的中间结果很有用,因为: 中间结果未经索引(除非已经显式保存到磁盘上然后创建索引),而且通常不为查询计划中的下一个操作进行适当的排序。 查询优化器只估计中间结果的大小。 由于对于复杂查询,估计可能有很大的误差,因此如果中间结果比预期的大得多,则处理中间结果的算法不仅必须有效而且必须适度弱化。 哈希联接可以减少使用非规范化。 非规范化一般通过减少联接操作获得更好的性能,尽管这样做有冗余之险(如不一致的更新)。 哈希联接则减少使用非规范化的需要。 哈希联接使垂直分区(用单独的文件或索引代表单个表中的几组列)得以成为物理数据库设计的可行选项。 哈希联接有两种输入:生成输入和探测输入。 查询优化器指派这些角色,使两个输入中较小的那个作为生成输入。 哈希联接用于多种设置匹配操作:内部联接;左外部联接、右外部联接和完全外部联接;左半联接和右半联接;交集;并集和差异。 此外,哈希联接的某种变形可以进行重复删除和分组,例如 SUM(salary) GROUP BY department。 这些修改对生成和探测角色只使用一个输入。 |
 |
Hash Match | Hash Match 运算符通过计算其生成输入中每行的哈希值生成哈希表。 HASH:() 谓词以及一个用于创建哈希值的列的列表会出现在 Argument 列中。 然后,该谓词为每个探测行(如果适用)计算哈希值(使用相同的哈希函数)并在哈希表内查找匹配项。 如果存在残留谓词(由 Argument 列中的 RESIDUAL:() 标识),则还须满足此残留谓词,只有这样行才能被视为是匹配项。 行为取决于所执行的逻辑操作: - 对于联接,使用第一个(顶端)输入生成哈希表,使用第二个(底端)输入探测哈希表。 按联接类型规定的模式输出匹配项(或不匹配项)。 如果多个联接使用相同的联接列,这些操作将分组为一个哈希组。 - 对于非重复或聚合运算符,使用输入生成哈希表(删除重复项并计算聚合表达式)。 生成哈希表时,扫描该表并输出所有项。 - 对于 union 运算符,使用第一个输入生成哈希表(删除重复项)。 使用第二个输入(它必须没有重复项)探测哈希表,返回所有没有匹配项的行,然后扫描该哈希表并返回所有项。 Hash Match 是一个物理运算符。 有关详细信息,请参阅理解哈希联接。 |
Hash Match
Hash Match 有两种地方用到,一种是表关联,一种是数据聚合运算时。
再分别说这两中运算的前面,我先说说Hashing(编码技术)和Hash Table(数据结构)。
Hashing:在数据库中根据每一行的数据内容,转换成唯一符号格式,存放到临时哈希表中,当需要原始数据时,可以给还原回来。类似加密解密技术,但是他能更有效的支持数据查询。
Hash Table:通过hashing处理,把数据以key/value的形式存储在表格中,在数据库中他被放在tempdb中。
接下来,来说说Hash Math的表关联跟行数据聚合是怎么操作运算的。
表关联:

如上图,关联两个数据集时,Hash Match会把其中较小的数据集,通过Hashing运算放入HashTable中,然后一行一行的遍历较大的数据集与HashTable进行相应的匹配拉取数据。
数据聚合:当查询中需要进行Count/Sum/Avg/Max/Min时,数据可能会采用把数据先放在内存中的HashTable中然后进行运算。
SOA_APIINFO (生成输入),下一阶段是探测阶段。
----------------------------------这是已经有合适的索引,不然是
<Index Scan>--->假如,如果这里没有创建了合适的索引(SOA_APIINFO):
对每一个探测行(来自 SQA_EsbUsingRecord)计算散列值,并扫描对应的散列通,产生匹配结果,该策略就是内存散列连接。
通常,散列表在内存中产生。如果表很大,没有足够内存容纳,就需要存入磁盘,这可能造成性能降低,这是内存不足表需要处理多次。
这种情况散列表分割为内存能容纳的组,每一组作为一个单独步骤处理。散列非常大,会创建递归散列连接,这些表分区为多个步骤,每个步骤分区为多个级别。
--------------------------------如果查询出现多个散列连接--->
扩展事件(Extended Events)跟踪文件(Hash Warning 事件和在 Errors and Warnings event 类中)发现较多 Hash Warning 事件,请更新连接列的统计信息。
这样做确保服务器不会引发性能问题。连接列缺少合适索引,优化器会选择散列连接,这个可以通过向表中添加索引支持连接从而提升性能。
Nested Loops
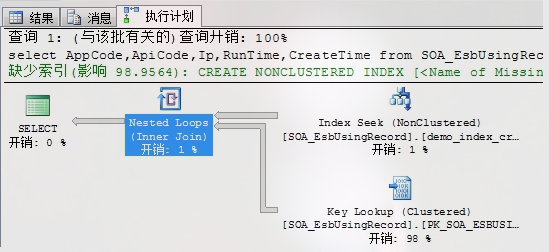
这个操作符号,把两个不同列的数据集汇总到一张表中。提示信息中的Output List中有两个数据集,下面的数据集(inner set)会一一扫描与上面的数据集(out set),知道扫描完为止,这个操作才算是完成。
嵌套循环在外层表(上面)很小,内层表(下面)很大且有序的的情况下尤为有效。
必须验证内层查询中嵌套循环查询连接存在有效的索引支撑查找,而不是使用表扫描和索引扫描。
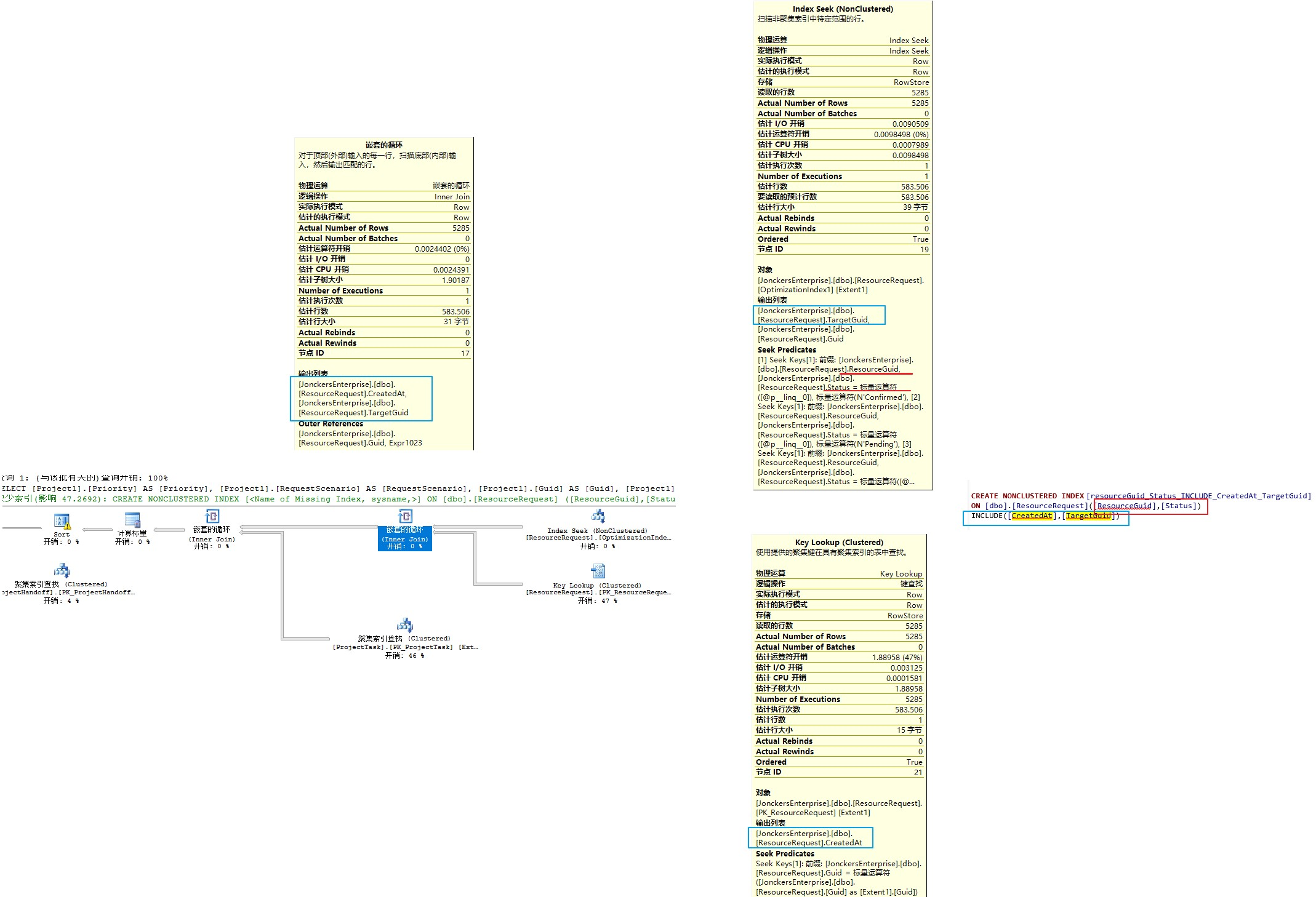
Merge Join

这种关联算法是对两个已经排过序的集合进行合并。如果两个聚合是无序的则将先给集合排序再进行一一合并,由于是排过序的集合,左右两个集合自上而下合并效率是相当快的。
两个表都有 ApiCode 列的索引,所以优化器选择合并连接。如果输入端足够小,并且能是排序成本相比散列连接或者嵌套循环连接更低,查询优化器就会这么做。
如果查询优化器选择在合并连接之前排序,就值得考虑为表添加覆盖索引,消除排序需求,从而使得查询处理更快。覆盖索引提前执行了对苏剧的排序操作,并将结果持久化,
所以当查询时,就可以使用排序后的数据。
根据执行计划优化#
1、如果select * 通常情况下聚集索引会比非聚集索引更优。
2、如果出现Nested Loops,需要查下是否需要聚集索引,非聚集索引是否可以包含所有需要的列。
3、Hash Match连接操作更适合于需要做Hashing算法集合很小的连接。
4、Merge Join时需要检查下原有的集合是否已经有排序,如果没有排序,使用索引能否解决。
5、出现表扫描,聚集索引扫描,非聚集索引扫描时,考虑语句是否可以加where限制,select * 是否可以去除不必要的列。
6、出现Rid查找时,是否可以加索引优化解决。
7、在计划中看到不是你想要的索引时,看能否在语句中强制使用你想用的索引解决问题,强制使用索引的办法Select CluName1,CluName2 from Table with(index=IndexName)。
8、看到不是你想要的连接算法时,尝试强制使用你想要的算法解决问题。强制使用连接算法的语句:select * from t1 left join t2 on t1.id=t2.id option(Hash/Loop/Merge Join)
9、看到不是你想要的聚合算法是,尝试强制使用你想要的聚合算法。强制使用聚合算法的语句示例:select age ,count(age) as cnt from t1 group by age option(order/hash group)
10、看到不是你想要的解析执行顺序是,或这解析顺序耗时过大时,尝试强制使用你定的执行顺序。option(force order)
11、看到有多个线程来合并执行你的sql语句而影响到性能时,尝试强制是不并行操作。option(maxdop 1)
12、在存储过程中,由于参数不同导致执行计划不同,也影响啦性能时尝试指定参数来优化。option(optiomize for(@name='zlh'))
13、不操作多余的列,多余的行,不做务必要的聚合,排序。
SQL 语句优化分析#
1.查看执行时间和cpu占用时间#
set statistics time on
select * from dbo.Product
set statistics time off
2.查看查询对I/0的操作情况#
set statistics io on
select * from dbo.Product
set statistics io off
扫描计数:索引或表扫描次数
逻辑读取:数据缓存中读取的页数
物理读取:从磁盘中读取的页数
预读:查询过程中,从磁盘放入缓存的页数
lob逻辑读取:从数据缓存中读取,image,text,ntext或大型数据的页数
lob物理读取:从磁盘中读取,image,text,ntext或大型数据的页数
lob预读:查询过程中,从磁盘放入缓存的image,text,ntext或大型数据的页数
如果物理读取次数和预读次说比较多,可以使用索引进行优化。
如果你不想使用sql语句命令来查看这些内容,可以使用
查询--->>查询选项--->>高级


Rows: 10 - 这是查询的估计行数。
Executes: 1 - 这是查询的估计执行次数。
StmtText: 这是SQL语句的文本,表示正在执行的查询。
StmtId: 1 - 表示这是查询中的第一个子查询或操作。
NodeId: 1 - 节点ID,用于标识执行计划中的每个节点。
Parent: 1 - 表示当前节点是执行计划中的第几个节点。
PhysicalOp: 0 - 物理操作。这里没有给出具体的物理操作,所以我们无法确定具体的执行步骤。
LogicalOp: NULL - 逻辑操作。这里没有给出具体的逻辑操作,所以我们无法确定具体的执行步骤。
Argument: NULL - 这是物理或逻辑操作的参数。这里没有给出具体的参数,所以我们无法确定具体的执行步骤。
DefinedValues: NULL - 定义的值。这里没有给出具体的定义值,所以我们无法确定具体的执行步骤。
EstimateRows: 10 - 估计的行数,这是基于查询优化器的估计。
EstimateIO: NULL - 估计的I/O成本。这里没有给出具体的值,所以我们无法确定具体的执行步骤。
EstimateCPU: NULL - 估计的CPU成本。这里没有给出具体的值,所以我们无法确定具体的执行步骤。
AvgRowSize: NULL - 平均行大小。这里没有给出具体的值,所以我们无法确定具体的执行步骤。
TotalSubtreeCost: NULL - 子树的总成本。这里没有给出具体的值,所以我们无法确定具体的执行步骤。
OutputList: NULL - 输出列表。这里没有给出具体的输出列表,所以我们无法确定具体的执行步骤。
Warnings: NULL - 警告信息。这里没有给出警告信息,所以我们无法确定是否存在任何问题或需要注意的地方。
Type: SELECT - 这表示这是一个SELECT查询操作。
Parallel: 0 - 表示是否并行执行该操作。这里为0,表示不是并行执行。
EstimateExecutions: NULL - 估计的执行次数。这里没有给出具体的值,所以我们无法确定具体的执行步骤。
总结:这个查询计划似乎是一个复杂的SELECT查询,它涉及多个表和多个条件过滤以及连接操作。由于缺少具体的物理和逻辑操作以及参数信息,因此很难提供更详细的执行计划分析。
参考:#
【bilibili】SQL Server性能优化详解 - 超超TimChen44
图标 - 显示计划逻辑运算符和物理运算符参考 - SQL Server | Microsoft Learn
图标 - 图形执行计划图标 (SQL Server Management Studio) | Microsoft Learn
索引的了解#
聚集索引#
-
聚集索引中,叶节点包含基础表的数据页。
-
数据链内的页和行将按聚集索引键值进行排序。
-
主键通常是聚集索引,但可以不是聚集索引。
非聚集索引#
-
基础表的数据行不会根据其非聚集键按顺序排序和存储。
-
非聚集索引的叶级别是由索引页而不是由数据页组成。
-
非聚集索引的叶级别的索引页包含键列以及包含列。
包含列#
例如:
查询A2,B2,如果非聚集索引只有A2,就会使用 Key Lookup 查询B2 。
包含列的操作:把需要查询的 B2 添加到当前包含列,就会把 B2 的坐标添加到 A2 的当前索引。
优点:查询快。
缺点:增加索引体积。
建议:不要加太多,10个以下。
筛选器#
对 custId 模糊查询的时候,筛选器能更快的响应。
索引选择#
A和B字段都有索引,不是谁在前面就选谁。
根据统计信息来选择
常见的索引设计建议#
√优先选择唯一性索引
√为常作为查询条件的字段建立索引
√经常需要排序、分组和联合操作的字段建立索引
√尽量使用数据量少的索引,如果字段数据大,索引表体积相对较大,当发生索引扫描时影响比较严重√控制索引数量,索引的字段发生修改时需要更新索引,过多索引会影响表性能
√删除很少使用的索引,可以通过报表查看索引使用情况
√复合索引区分度大的字段放在前面
√区分度小的字段不建议创建索引,比如性别
√命名建议用索引的字段名作为名称,方便在查询计划中分辨,不建议添加“IX”之类的前缀,SQLServer索引名称允许跨表重名的
SQL 执行计划#
1 连线#
1、越粗表示扫描影响的行数愈多。
2、Actual Number of Rows 扫描中实际影响的的行数。
3、Estimated Number of Rows 预估扫描影响的行数。
4、Estimated row size 操作符生成的行的估计大小(字节)。
5、Estimated Data Size 预估影响的数据的大小。
2、Tooltips,当前步骤执行信息#
Note:这个tips的信息告诉我们执行的对象是什么,采用的操作操作是什么,查找的数据是什么,使用的索引是什么,排序与否,预估cpu、I/O、影响行数,实际行数等信息。具体参数清单参见msdn:显示图形执行计划 (SQL Server Management Studio) | Microsoft Learn
SQL Server查找数据记录的几种方式:#
1.Table Scan--表扫描(最慢),对表记录逐行进行检查,对于没有索引或者查询条件不走索引时会进行全表扫描;
2.Clustered Index Scan--聚集索引扫描(较慢),按聚集索引对记录逐行进行检查,对有主键/聚集索引的表进行无条件查找或者使用主键/聚集索引过滤;
3.Index Scan--索引扫描(普通),根据索引滤出部分数据在进行逐行检查;
聚集索引扫描:聚集索引的数据体积实际是就是表本身,也就是说表有多少行多少列,聚集所有就有多少行多少列,那么聚集索引扫描就跟表扫描差不多,也要进行全表扫描,遍历所有表数据,查找出你想要的数据。
非聚集索引扫描:非聚集索引的体积是根据你的索引创建情况而定的,可以只包含你要查询的列。那么进行非聚集索引扫描,便是你非聚集中包含的列的所有行进行遍历,查找出你想要的数据。
4.Index Seek--索引查找(较快),根据索引定位记录所在位置再取出记录,建立非聚集索引并把其他显示列加入索引中;
5.Clustered Index Seek--聚集索引查找(最快),直接根据聚集索引获取记录,建立非聚集索引并把其他显示列加入索引中并把聚集索引列当作条件;
聚集索引查找:聚集索引包含整个表的数据,也就是在聚集索引的数据上根据键值取数据。
非聚集索引查找:非聚集索引包含创建索引时所包含列的数据,在这些非聚集索引的数据上根据键值取数据。
6.Key Lookup--书签查找:通过非聚集索引找到所求的行,但这个索引并不包含显示的列,因此还要额外去基本表中找到这些列,所以要进行键查找,如果基本表在堆中则Key Lookup会变成RID查找。
查找与扫描在性能上完全不是一个级别的,扫描需要遍历整张表,而查找只需要通过键值直接提取数据,返回结果,性能要好。
当你查找的列没有完全被非聚集索引包含,就需要使用键值查找在聚集索引上查找非聚集索引不包含的列。
7.RID--书签查找:同上
如果有些SQL执行很慢,可以用执行计划看一下是否包含太多“扫描”操作,可以考虑为这些字段建立索引,建立索引切记不要再经常有更新操作的字段上建立,每次更新数据和插入数据都会导致重建索引的操作,会增加索引的维护成本。
跟键值查找类似,只不过RID查找,是需要查找的列没有完全被非聚集索引包含,而剩余的列所在的表又不存在聚集索引,不能键值查找,只能根据行表示Rid来查询数据。
| Showplan 运算符 | 说明 | |
|---|---|---|
|
Table Scan | Table Scan 运算符从查询执行计划的 Argument 列所指定的表中检索所有行。 如果 WHERE:() 谓词出现在 Argument 列中,则仅返回满足此谓词的那些行。 Table Scan 既是一个逻辑运算符,也是一个物理运算符。 |
|
Clustered Index Scan | Clustered Index Scan 运算符会扫描查询执行计划的 Argument 列中指定的聚集索引。 存在可选 WHERE:() 谓词时,则只返回满足该谓词的那些行。 如果 Argument 列包含 ORDERED 子句,则表示查询处理器已请求按聚集索引排列行的顺序返回行输出。 如果没有 ORDERED 子句,存储引擎将以最佳方式扫描索引,而无需对输出进行排序。 Clustered Index Scan 既是一个逻辑运算符,也是一个物理运算符。 |
|
Index Scan | Index Scan 运算符从 Argument 列中指定的非聚集索引中检索所有行。 如果可选的 WHERE:() 谓词出现在 Argument 列中,则仅返回满足此谓词的那些行。 Index Scan 既是一个逻辑运算符,也是一个物理运算符。 |
|
Index Seek | Index Seek 运算符利用索引的查找功能从非聚集索引中检索行。 Argument 列包含所使用的非聚集索引的名称。 它还包括 SEEK:() 谓词。 存储引擎仅使用索引来处理满足 SEEK:() 谓词的行。 它可能还包含一个 WHERE:() 谓词,其中存储引擎对满足 SEEK:() 谓词的所有行进行计算(不使用索引来完成)。 如果 Argument 列包含 ORDERED 子句,则表示查询处理器已决定必须按非聚集索引排序行的顺序返回行。 如果没有 ORDERED 子句,则存储引擎将以最佳方式(不保证对输出排序)搜索索引。 如果让输出保持其顺序,则效率可能低于生成非排序输出。 Index Seek 既是一个逻辑运算符,也是一个物理运算符。 |
|
Clustered Index Seek | Clustered Index Seek 运算符可以利用索引的查找功能从聚集索引中检索行。 Argument 列包含所使用的聚集索引名称和 SEEK:() 谓词。 存储引擎仅使用索引来处理满足此 SEEK:() 谓词的行。它还包括 WHERE:() 谓词,其中存储引擎对满足 SEEK:() 谓词的所有行进行计算, 但此操作是可选的,并且不使用索引来完成此过程。 如果 Argument 列包含 ORDERED 子句,则表示查询处理器已决定必须按聚集索引排序行的顺序返回行。 如果没有 ORDERED 子句,存储引擎将以最佳方式搜索索引,而不对输出进行必要的排序。 若允许输出保持顺序,则效率可能比生成非排序输出的效率低。 出现关键字 LOOKUP 时,将执行书签查找。 在 SQL Server 2008 (10.0.x) 及更高版本中,键查找运算符提供书签查找功能。 Clustered Index Seek 既是一个逻辑运算符,也是一个物理运算符。 |
|
Key Lookup | Key Lookup 运算符是在具有聚集索引的表上进行的书签查找。 Argument 列包含聚集索引的名称和用来在聚集索引中查找行的聚集键。 Key Lookup 通常带有 Nested Loops 运算符。 如果 Argument 列中出现 WITH PREFETCH 子句, 则表示查询处理器已决定在聚集索引中查找书签时将使用异步预提取(预读)作为最佳选择。 在查询计划中使用 Key Lookup 运算符表明该查询可能会从性能优化中获益。 例如,添加涵盖索引可能会提高查询性能。 |
|
RID Lookup | RID Lookup 是使用提供的行标识符 (RID) 在堆上进行的书签查找。 Argument 列包含用于查找表中的行的书签标签和从中查找行的表的名称。 RID Lookup 通常带有 NESTED LOOP JOIN。 RID Lookup 是一个物理运算符。 有关书签查找的详细信息,请参阅 MSDN SQL Server 博客中的Bookmark Lookup(书签查找)。 |
数据 JOIN方式#
在SQL Server中,每个join命令,都会在内部执行时采用这几种更具体的方式来运行:
Nested Loops join:如果一个联接输入很小,而另一个联接输入很大而且已在其联接列上创建了索引, 则索引 Nested Loops 连接是最快的联接操作,因为它们需要的 I/O 和比较都最少。嵌套循环联接也称为“嵌套迭代”,它将一个联接输入用作外部输入表(显示为图形执行计划中的顶端输入),将另一个联接输入用作内部(底端)输入表。外部循环逐行处理外部输入表。内部循环会针对每个外部行执行,在内部输入表中搜索匹配行。最简单的情况是,搜索时扫描整个表或索引;这称为“单纯嵌套循环联接”。如果搜索时使用索引,则称为“索引嵌套循环联接”。如果将索引生成为查询计划的一部分(并在查询完成后立即将索引破坏),则称为“临时索引嵌套循环联接”。
如果外部输入较小而内部输入较大且预先创建了索引,则嵌套循环联接尤其有效。在小事务中(只影响较少数据的事务),索引嵌套循环联接优于合并联接和哈希联接,但在大型查询中,嵌套循环联接通常不是最佳选择。
-
Merge Join:如果两个联接输入并不小但已在二者联接列上排序(例如,如果它们是通过扫描已排序的索引获得的),则合并联接是最快的联接操作。如果两个联接输入都很大,而且这两个输入的大小差不多,则预先排序的合并联接提供的性能与哈希联接相近。但是,如果这两个输入的大小相差很大,则哈希联接操作通常快得多。合并联接要求两个输入都在合并列上排序,而合并列由联接谓词的等效 (ON) 子句定义。通常,查询优化器扫描索引(如果在适当的一组列上存在索引),或在合并联接的下面放一个排序运算符。在极少数情况下,虽然可能有多个等效子句,但只用其中一些可用的等效子句获得合并列。 -
Hash Join:哈希联接可以有效处理未排序的大型非索引输入。它们对复杂查询的中间结果很有用,因为:①.中间结果未经索引(除非已经显式保存到磁盘上然后创建索引),而且通常不为查询计划中的下一个操作进行适当的排序。②.查询优化器只估计中间结果的大小。由于对于复杂查询,估计可能有很大的误差,因此如果中间结果比预期的大得多,则处理中间结果的算法不仅必须有效而且必须适度弱化。哈希联接可以减少使用非规范化。非规范化一般通过减少联接操作获得更好的性能,尽管这样做有冗余之险(如不一致的更新)。哈希联接则减少使用非规范化的需要。哈希联接使垂直分区(用单独的文件或索引代表单个表中的几组列)得以成为物理数据库设计的可行选项。
| Showplan 运算符 | 说明 | |
|---|---|---|
|
合并联接 Merge Join |
Merge Join 运算符执行内部联接、左外部联接、左半部联接、左反半部联接、右外部联接、右半部联接、右反半部联接和联合逻辑运算。 在 Argument 列中,如果操作执行一对多联接,则 Merge Join 运算符将包含 MERGE:() 谓词;如果操作执行多对多联接,则该运算符将包含 MANY-TO-MANY MERGE:() 谓词。 Argument 列还包含一个用于执行操作的列的列表,该列表以逗号分隔。 Merge Join 运算符要求在各自的列上对两个输入进行排序,这可以通过在查询计划中插入显式排序操作来实现。 如果不需要显式排序(例如,如果数据库内有合适的 B 树索引或可以对多个操作(如合并联接和对汇总分组)使用排序顺序),则合并联接尤其有效。 Merge Join 是一个物理运算符。 有关详细信息,请参阅理解合并联接。 |
|
Nested Loops | Nested Loops 运算符执行内部联接、左外部联接、左半部联接和左反半部联接逻辑运算。 嵌套循环联接通常使用索引,针对外部表的每一行在内部表中执行搜索。 查询处理器根据预计的开销来决定是否对外部输入进行排序,以改进内部输入索引上的搜索定位。 将基于所执行的逻辑操作返回所有满足 Argument 列中的(可选)谓词的行。 如果 OPTIMIZED 特性设置为“True”,则表示使用了优化的嵌套循环(或批处理排序)。 Nested Loops 是一个物理运算符。 有关详细信息,请参阅了解嵌套循环联接。 |
| 无 | Hash join | 哈希联接可以有效处理未排序的大型非索引输入。 它们对复杂查询的中间结果很有用,因为: 中间结果未经索引(除非已经显式保存到磁盘上然后创建索引),而且通常不为查询计划中的下一个操作进行适当的排序。 查询优化器只估计中间结果的大小。 由于对于复杂查询,估计可能有很大的误差,因此如果中间结果比预期的大得多,则处理中间结果的算法不仅必须有效而且必须适度弱化。 哈希联接可以减少使用非规范化。 非规范化一般通过减少联接操作获得更好的性能,尽管这样做有冗余之险(如不一致的更新)。 哈希联接则减少使用非规范化的需要。 哈希联接使垂直分区(用单独的文件或索引代表单个表中的几组列)得以成为物理数据库设计的可行选项。 哈希联接有两种输入:生成输入和探测输入。 查询优化器指派这些角色,使两个输入中较小的那个作为生成输入。 哈希联接用于多种设置匹配操作:内部联接;左外部联接、右外部联接和完全外部联接;左半联接和右半联接;交集;并集和差异。 此外,哈希联接的某种变形可以进行重复删除和分组,例如 SUM(salary) GROUP BY department。 这些修改对生成和探测角色只使用一个输入。 |
|
Hash Match | Hash Match 运算符通过计算其生成输入中每行的哈希值生成哈希表。 HASH:() 谓词以及一个用于创建哈希值的列的列表会出现在 Argument 列中。 然后,该谓词为每个探测行(如果适用)计算哈希值(使用相同的哈希函数)并在哈希表内查找匹配项。 如果存在残留谓词(由 Argument 列中的 RESIDUAL:() 标识),则还须满足此残留谓词,只有这样行才能被视为是匹配项。 行为取决于所执行的逻辑操作: - 对于联接,使用第一个(顶端)输入生成哈希表,使用第二个(底端)输入探测哈希表。 按联接类型规定的模式输出匹配项(或不匹配项)。 如果多个联接使用相同的联接列,这些操作将分组为一个哈希组。 - 对于非重复或聚合运算符,使用输入生成哈希表(删除重复项并计算聚合表达式)。 生成哈希表时,扫描该表并输出所有项。 - 对于 union 运算符,使用第一个输入生成哈希表(删除重复项)。 使用第二个输入(它必须没有重复项)探测哈希表,返回所有没有匹配项的行,然后扫描该哈希表并返回所有项。 Hash Match 是一个物理运算符。 有关详细信息,请参阅理解哈希联接。 |
Hash Match
Hash Match 有两种地方用到,一种是表关联,一种是数据聚合运算时。
再分别说这两中运算的前面,我先说说Hashing(编码技术)和Hash Table(数据结构)。
Hashing:在数据库中根据每一行的数据内容,转换成唯一符号格式,存放到临时哈希表中,当需要原始数据时,可以给还原回来。类似加密解密技术,但是他能更有效的支持数据查询。
Hash Table:通过hashing处理,把数据以key/value的形式存储在表格中,在数据库中他被放在tempdb中。
接下来,来说说Hash Math的表关联跟行数据聚合是怎么操作运算的。
表关联:
如上图,关联两个数据集时,Hash Match会把其中较小的数据集,通过Hashing运算放入HashTable中,然后一行一行的遍历较大的数据集与HashTable进行相应的匹配拉取数据。
数据聚合:当查询中需要进行Count/Sum/Avg/Max/Min时,数据可能会采用把数据先放在内存中的HashTable中然后进行运算。
SOA_APIINFO (生成输入),下一阶段是探测阶段。
----------------------------------这是已经有合适的索引,不然是
<Index Scan>--->假如,如果这里没有创建了合适的索引(SOA_APIINFO):
对每一个探测行(来自 SQA_EsbUsingRecord)计算散列值,并扫描对应的散列通,产生匹配结果,该策略就是内存散列连接。
通常,散列表在内存中产生。如果表很大,没有足够内存容纳,就需要存入磁盘,这可能造成性能降低,这是内存不足表需要处理多次。
这种情况散列表分割为内存能容纳的组,每一组作为一个单独步骤处理。散列非常大,会创建递归散列连接,这些表分区为多个步骤,每个步骤分区为多个级别。
--------------------------------如果查询出现多个散列连接--->
扩展事件(Extended Events)跟踪文件(Hash Warning 事件和在 Errors and Warnings event 类中)发现较多 Hash Warning 事件,请更新连接列的统计信息。
这样做确保服务器不会引发性能问题。连接列缺少合适索引,优化器会选择散列连接,这个可以通过向表中添加索引支持连接从而提升性能。
Nested Loops
这个操作符号,把两个不同列的数据集汇总到一张表中。提示信息中的Output List中有两个数据集,下面的数据集(inner set)会一一扫描与上面的数据集(out set),知道扫描完为止,这个操作才算是完成。
嵌套循环在外层表(上面)很小,内层表(下面)很大且有序的的情况下尤为有效。
必须验证内层查询中嵌套循环查询连接存在有效的索引支撑查找,而不是使用表扫描和索引扫描。
Merge Join
这种关联算法是对两个已经排过序的集合进行合并。如果两个聚合是无序的则将先给集合排序再进行一一合并,由于是排过序的集合,左右两个集合自上而下合并效率是相当快的。
两个表都有 ApiCode 列的索引,所以优化器选择合并连接。如果输入端足够小,并且能是排序成本相比散列连接或者嵌套循环连接更低,查询优化器就会这么做。
如果查询优化器选择在合并连接之前排序,就值得考虑为表添加覆盖索引,消除排序需求,从而使得查询处理更快。覆盖索引提前执行了对苏剧的排序操作,并将结果持久化,
所以当查询时,就可以使用排序后的数据。
根据执行计划优化#
1、如果select * 通常情况下聚集索引会比非聚集索引更优。
2、如果出现Nested Loops,需要查下是否需要聚集索引,非聚集索引是否可以包含所有需要的列。
3、Hash Match连接操作更适合于需要做Hashing算法集合很小的连接。
4、Merge Join时需要检查下原有的集合是否已经有排序,如果没有排序,使用索引能否解决。
5、出现表扫描,聚集索引扫描,非聚集索引扫描时,考虑语句是否可以加where限制,select * 是否可以去除不必要的列。
6、出现Rid查找时,是否可以加索引优化解决。
7、在计划中看到不是你想要的索引时,看能否在语句中强制使用你想用的索引解决问题,强制使用索引的办法Select CluName1,CluName2 from Table with(index=IndexName)。
8、看到不是你想要的连接算法时,尝试强制使用你想要的算法解决问题。强制使用连接算法的语句:select * from t1 left join t2 on t1.id=t2.id option(Hash/Loop/Merge Join)
9、看到不是你想要的聚合算法是,尝试强制使用你想要的聚合算法。强制使用聚合算法的语句示例:select age ,count(age) as cnt from t1 group by age option(order/hash group)
10、看到不是你想要的解析执行顺序是,或这解析顺序耗时过大时,尝试强制使用你定的执行顺序。option(force order)
11、看到有多个线程来合并执行你的sql语句而影响到性能时,尝试强制是不并行操作。option(maxdop 1)
12、在存储过程中,由于参数不同导致执行计划不同,也影响啦性能时尝试指定参数来优化。option(optiomize for(@name='zlh'))
13、不操作多余的列,多余的行,不做务必要的聚合,排序。
SQL 语句优化分析#
1.查看执行时间和cpu占用时间#
set statistics time on
select * from dbo.Product
set statistics time off
2.查看查询对I/0的操作情况#
set statistics io on
select * from dbo.Product
set statistics io off
扫描计数:索引或表扫描次数
逻辑读取:数据缓存中读取的页数
物理读取:从磁盘中读取的页数
预读:查询过程中,从磁盘放入缓存的页数
lob逻辑读取:从数据缓存中读取,image,text,ntext或大型数据的页数
lob物理读取:从磁盘中读取,image,text,ntext或大型数据的页数
lob预读:查询过程中,从磁盘放入缓存的image,text,ntext或大型数据的页数
如果物理读取次数和预读次说比较多,可以使用索引进行优化。
如果你不想使用sql语句命令来查看这些内容,可以使用
查询--->>查询选项--->>高级
Rows: 10 - 这是查询的估计行数。
Executes: 1 - 这是查询的估计执行次数。
StmtText: 这是SQL语句的文本,表示正在执行的查询。
StmtId: 1 - 表示这是查询中的第一个子查询或操作。
NodeId: 1 - 节点ID,用于标识执行计划中的每个节点。
Parent: 1 - 表示当前节点是执行计划中的第几个节点。
PhysicalOp: 0 - 物理操作。这里没有给出具体的物理操作,所以我们无法确定具体的执行步骤。
LogicalOp: NULL - 逻辑操作。这里没有给出具体的逻辑操作,所以我们无法确定具体的执行步骤。
Argument: NULL - 这是物理或逻辑操作的参数。这里没有给出具体的参数,所以我们无法确定具体的执行步骤。
DefinedValues: NULL - 定义的值。这里没有给出具体的定义值,所以我们无法确定具体的执行步骤。
EstimateRows: 10 - 估计的行数,这是基于查询优化器的估计。
EstimateIO: NULL - 估计的I/O成本。这里没有给出具体的值,所以我们无法确定具体的执行步骤。
EstimateCPU: NULL - 估计的CPU成本。这里没有给出具体的值,所以我们无法确定具体的执行步骤。
AvgRowSize: NULL - 平均行大小。这里没有给出具体的值,所以我们无法确定具体的执行步骤。
TotalSubtreeCost: NULL - 子树的总成本。这里没有给出具体的值,所以我们无法确定具体的执行步骤。
OutputList: NULL - 输出列表。这里没有给出具体的输出列表,所以我们无法确定具体的执行步骤。
Warnings: NULL - 警告信息。这里没有给出警告信息,所以我们无法确定是否存在任何问题或需要注意的地方。
Type: SELECT - 这表示这是一个SELECT查询操作。
Parallel: 0 - 表示是否并行执行该操作。这里为0,表示不是并行执行。
EstimateExecutions: NULL - 估计的执行次数。这里没有给出具体的值,所以我们无法确定具体的执行步骤。
总结:这个查询计划似乎是一个复杂的SELECT查询,它涉及多个表和多个条件过滤以及连接操作。由于缺少具体的物理和逻辑操作以及参数信息,因此很难提供更详细的执行计划分析。
参考:#
【bilibili】SQL Server性能优化详解 - 超超TimChen44
图标 - 显示计划逻辑运算符和物理运算符参考 - SQL Server | Microsoft Learn
图标 - 图形执行计划图标 (SQL Server Management Studio) | Microsoft Learn



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 记一次.NET内存居高不下排查解决与启示
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
2015-01-16 MVC - 18.缓存