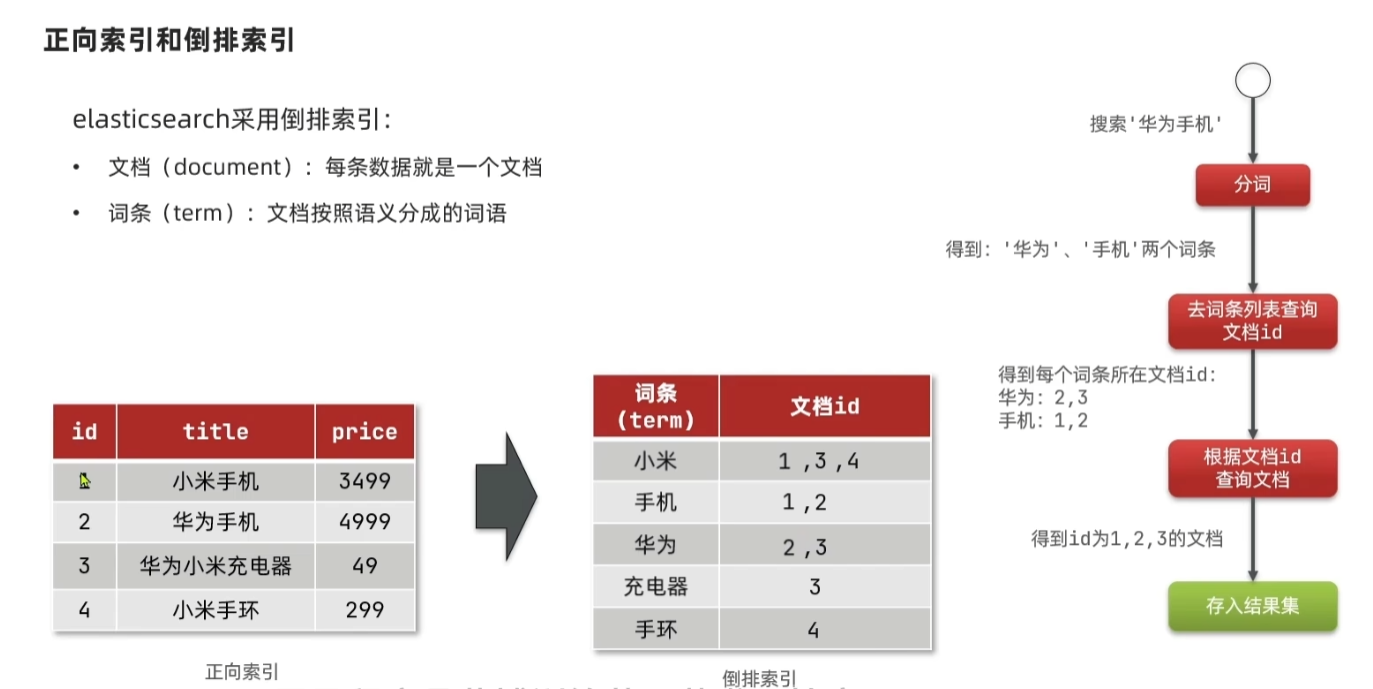
elasticsearch 基础知识
正向索引和倒排索引
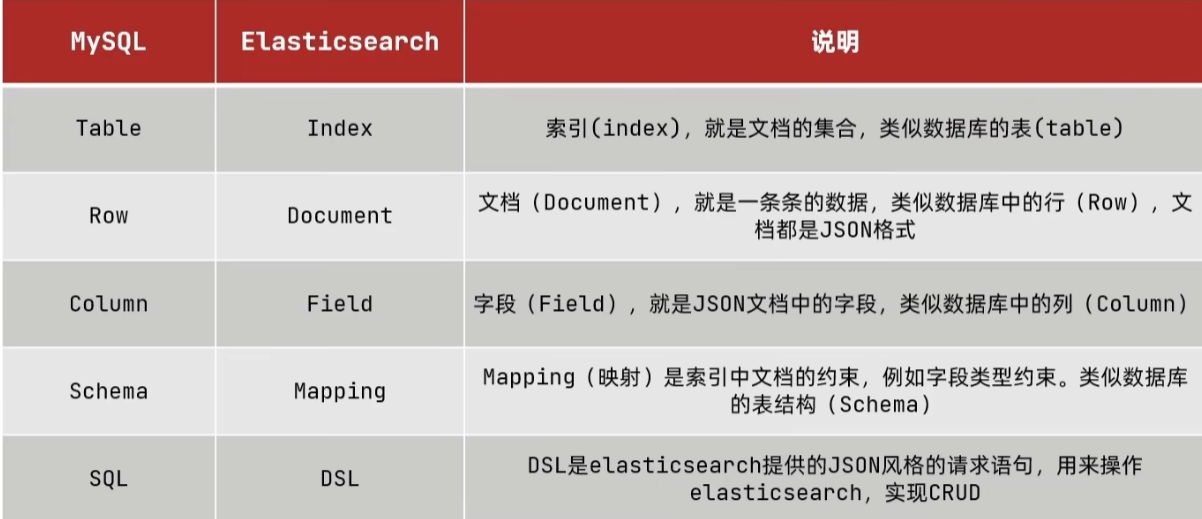
与 MYSQL 的关系
环境
下载windows版本
https://www.elastic.co/cn/downloads/elasticsearch
HTTPS报错
elastic search 报错
[2023-09-24T21:04:50,988][WARN ][o.e.h.n.Netty4HttpServerTransport] [HOMEDESKTOP-TG] received plaintext http traffic on an https channel, closing connection Netty4HttpChannel
于Windows版本的Elasticsearch,你需要在elasticsearch.yml文件中进行相关配置的修改。
elasticsearch.yml文件通常位于以下两个位置之一:
- Elasticsearch安装目录的
config文件夹下(例如:E:\elasticsearch-8.10.2\config\elasticsearch.yml)。 - Windows系统的环境变量
ES_HOME指向的目录的config文件夹下。
你可以使用文本编辑器打开该文件,根据需要进行相关的配置修改。
至于你提到的报错信息,看起来是Elasticsearch的HTTPS配置问题。Elasticsearch默认配置为只接受HTTPS连接,如果你的连接方式是HTTP,就会出现这样的警告。
如果你不想使用HTTPS连接,可以尝试关闭Elasticsearch的SSL验证。这可以通过在elasticsearch.yml文件中添加以下配置项来实现:
xpack.security.enabled: false
Kibana
exception
Root causes:
index_not_found_exception: no such index [.kibana]
好吧,是硬盘空间的问题,如果是健康 是red 的时候,就会出现这些问题
HTTP - 查询
索引
创建一个 shopping 的索引
创建索引
PUT http://localhost:9200/shopping
返回
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "shopping"
}
如果用POST
返回
{
"error": "Incorrect HTTP method for uri [/shopping] and method [POST], allowed: [GET, PUT, HEAD, DELETE]",
"status": 405
}
查询索引
GET http://localhost:9200/shopping
返回
{
"shopping": {
"aliases": {},
"mappings": {},
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"number_of_shards": "1",
"provided_name": "shopping",
"creation_date": "1695658514232",
"number_of_replicas": "1",
"uuid": "3_vwUeDVSqK2G6_eudu0pg",
"version": {
"created": "8100299"
}
}
}
}
}
删除索引
DELETE http://localhost:9200/shopping
返回
{
"acknowledged": true
}
修改索引
PUT http://localhost:9200/shopping/_setting
put /shopping/_settings
{
"index": {
"number_of_replicas": 2
}
}
修改前后对比,也可以修改 mapping 等等。

别名:多索引检索方案
1 不使用别名的情况
方式一:使用逗号
下面是搜索 students, shopping 2个索引
POST /students,shopping/_search
方式二:使用通配符*
POST /tmall_*/_search
2 使用别名的情况
新增别名
post _aliases
{
"actions": [
{
"add": {
"index": "students",
"alias": "test"
}
},
{
"add": {
"index": "shopping",
"alias": "test"
}
}
]
}
现在结果来看students下面的aliases属性是否有test,接着可以使用索引 test 去查询了。
{
"students": {
"aliases": {
"test": {}
},
"mappings": {
"properties": {
"age_range": {
"type": "integer_range"
}
}
},
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"number_of_shards": "1",
"provided_name": "students",
"creation_date": "1731680611678",
"number_of_replicas": "1",
"uuid": "Bx2UgUWTRoS2xqH0zAMwtw",
"version": {
"created": "8100299"
}
}
}
}
}
新增过滤条件的别名
post _aliases
{
"actions": [
{
"add": {
"index": "students",
"alias": "huawei",
"filter":{
"term": {
"title": "华为"
}
}
}
}
]
}
删除别名
post _aliases
{
"actions": [
{
"remove": {
"index": "students",
"alias": "huawei2"
}
}
]
}
查询索引浏览
GET http://localhost:9200/_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .kibana-observability-ai-assistant-conversations-000001 GwjgkNC5Q3OqJzgUX6jMLw 1 0 0 0 248b 248b
green open .kibana-observability-ai-assistant-kb-000001 R_ljpbbkTCK1eAqmn0Vltg 1 0 0 0 248b 248b
yellow open iot_log GBJeKhPxTMqzf78iaMevBg 1 1 0 0 248b 248b
yellow open shopping 3_vwUeDVSqK2G6_eudu0pg 1 1 0 0 226b 226b
这里的 _cat 是查询的意思
文档
创建文档 PUT/POST
POST http://localhost:9200/shopping/_doc
{
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999.00
}
结果
{
"_index": "shopping",
"_id": "pBInzYoBv9F9H8lF0S9_",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
POST 和 PUT 的区别
PUT /employee/_doc/1
{
"name": "张三",
"sex": 1,
"age": 25,
"address": "广州天河公园",
"remark": "java developer"
}
POST /employee/_doc
{
"name": "李四",
"sex": 1,
"age": 25,
"address": "广州天河公园",
"remark": "net developer"
}
get /employee/_search
结果,使用PUT的 "_id": "1",所以 PUT 可以自定义 _id。
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "employee",
"_id": "1",
"_score": 1,
"_source": {
"name": "张三",
"sex": 1,
"age": 25,
"address": "广州天河公园",
"remark": "java developer"
}
},
{
"_index": "employee",
"_id": "coMnNZMB909uvleck-ZM",
"_score": 1,
"_source": {
"name": "李四",
"sex": 1,
"age": 25,
"address": "广州天河公园",
"remark": "net developer"
}
}
]
}
}
查询文档全局 '_search'
GET http://localhost:9200/shopping/_search
返回
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "shopping",
"_id": "pBInzYoBv9F9H8lF0S9_",
"_score": 1,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
}
]
}
}
查询主键 '_doc'
"found": true 表示找到
返回
GET http://localhost:9200/shopping/_doc/pBInzYoBv9F9H8lF0S9_
{
"_index": "shopping",
"_id": "pBInzYoBv9F9H8lF0S9_",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
}
更新: 按id (PUT全量更新,不常用)
PUT http://localhost:9200/shopping/_doc/pBInzYoBv9F9H8lF0S9_
{
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 4999
}
结果,更新成功 , "result": "updated"
{
"_index": "shopping",
"_id": "pBInzYoBv9F9H8lF0S9_",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 2
}
更新: 按id (POST局部更新,常用)
POST http://localhost:9200/shopping/_update/pBInzYoBv9F9H8lF0S9_
{
"doc": {
"title": "小米手机2"
}
}
结果
{
"_index": "shopping",
"_id": "pBInzYoBv9F9H8lF0S9_",
"_version": 3,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 2
}
批量操作 _bulk

批量新增(Indexing)
自动生成_id
POST /my_index/_bulk
{"index":{}}
{"name": "document1", "description": "This is document 1", "tags": ["tag1"]}
{"index":{}}
{"name": "document2", "description": "This is document 2", "tags": ["tag2"]}
{"index":{}}
{"name": "document3", "description": "This is document 3", "tags": ["tag3"]}
- 首先,每个文档的索引操作都以
{"index":{}}开头,表明这是一个索引操作,这里没有额外指定文档 ID,Elasticsearch 会自动为每个文档生成唯一的 ID。 - 紧接着换行后就是要索引的文档内容,包含了
name、description、tags等字段及对应的值,这样就可以一次性将三个文档批量插入到my_index索引里。
结果
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "my_index",
"_id": "c4M0NZMB909uvlecf-a3",
"_score": 1,
"_source": {
"name": "document1",
"description": "This is document 1",
"tags": [
"tag1"
]
}
},
{
"_index": "my_index",
"_id": "dIM0NZMB909uvlecf-a3",
"_score": 1,
"_source": {
"name": "document2",
"description": "This is document 2",
"tags": [
"tag2"
]
}
},
{
"_index": "my_index",
"_id": "dYM0NZMB909uvlecf-a3",
"_score": 1,
"_source": {
"name": "document3",
"description": "This is document 3",
"tags": [
"tag3"
]
}
}
]
}
}
指定文档 ID 新增
POST /my_index/_bulk
{"index": {"_id": "doc1"}}
{"name": "document1", "description": "This is document 1", "tags": ["tag1"]}
{"index": {"_id": "doc2"}}
{"name": "document2", "description": "This is document 2", "tags": ["tag2"]}
{"index": {"_id": "doc3"}}
{"name": "document3", "description": "This is document 3", "tags": ["tag3"]}
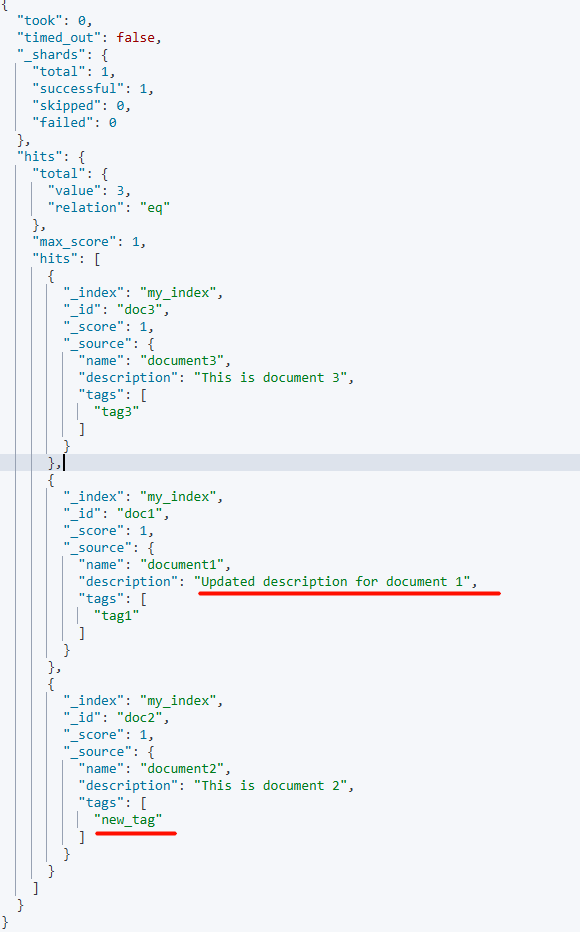
批量更新文档(Updating)
POST /my_index/_bulk
{"update": {"_id": "doc1"}}
{"doc": {"description": "Updated description for document 1"}}
{"update": {"_id": "doc2"}}
{"doc": {"tags": ["new_tag"]}}
批量删除文档(Deleting)
POST /my_index/_bulk
{"delete": {"_id": "doc1"}}
{"delete": {"_id": "doc2"}}
全文检索
查询 - 全量查询 match_all
GET http://localhost:9200/shopping/_search
{
"query": {
"match_all": {
}
}
}
查询 - 条件分词 match
GET http://localhost:9200/shopping/_search
{
"query":{
"match":{
"category":"小米"
}
}
}
查询 - 多字段查询 multi_match
get /es-test01/_search
{
"query": {
"multi_match": {
"query": "de", //关键字
"fields": ["target","other field"] //多个字段
}
}
}
加上一个"operator": "and",就必须同时满足
get /es-test01/_search
{
"query": {
"multi_match": {
"query": "el tocar",
"fields": ["target","other field"],
"operator": "and"
}
}
}
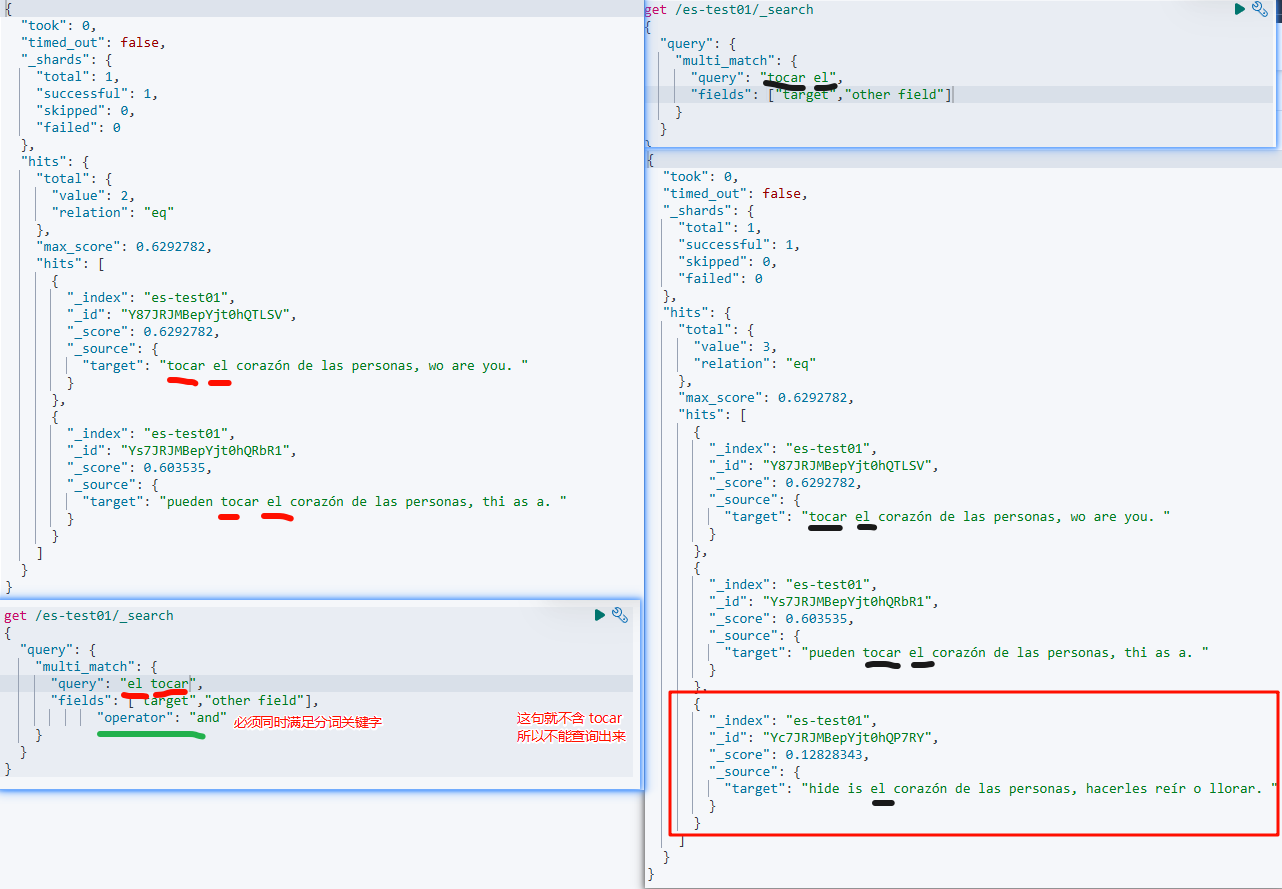
有这么多参数可以用,自己查吧":"
查询 - 短语匹配(位置) match_phrase
match_phrase 查询是一种用于精确匹配短语的查询方式,它要求查询的短语在目标字段中必须完整且连续地出现,顺序也不能改变,才能认为是匹配成功。与普通的文本查询不同,普通文本查询可能只要字段中包含查询词的部分词项就算匹配(例如使用 match 查询默认是只要有一个分词后的词项匹配上就返回结果),而 match_phrase 查询更强调短语的完整性和连续性。
这里的连续不是关键字的连续,而是分词的连续。
默认的分词,对英语类效果还可以。但是对
ik_max_word类的中文分词就不行了(可以使用参数:slop)。
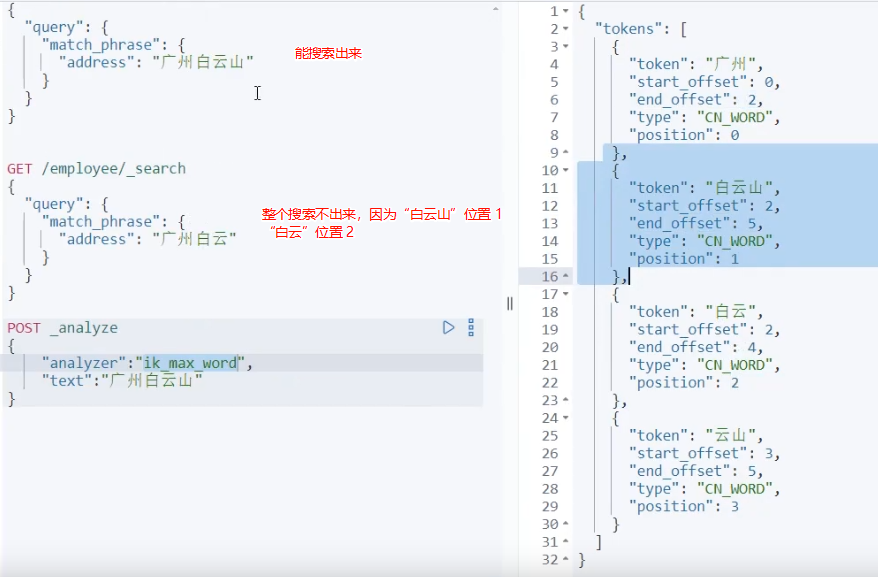
slop参数(用于控制词项间隔):
有时候,我们可能希望短语中的词项之间允许有一定的间隔,这时候可以使用slop参数来进行调整。slop参数定义了词项之间允许的最大间隔数(以词项为单位),通过它可以实现更灵活的短语匹配,在一定程度上放宽匹配的严格性。
{
"query":{
"match_phrase":{
"address":{
"query":"广州白云",
"slop": 2
}
}
}
}
查询 - query_string 查询
语法要求严格,一般用 sample_query_string
- 语法解析开销与复杂性:
由于其语法的复杂性,Elasticsearch 需要花费额外的时间来解析query_string查询语句,确保正确理解和执行其中包含的各种逻辑、通配符、模糊度等要求。每次查询时都会增加一定的性能开销,尤其是复杂的查询语句解析成本更高。而且复杂的语法组合也容易导致查询结果难以准确预估,可能出现不符合预期的匹配情况。 - 需要转义特殊字符:
在编写查询语句时,一些特殊字符(如+、-、&、|、!、(、)、{、}、[、]、^、"、~、*、?、:、/等)具有特定的语法含义,如果要将它们作为普通文本进行匹配,需要进行转义,否则可能导致查询语句解析错误。例如,如果要查找包含字符*的文本内容,要写成\\*(在 JSON 字符串中,\本身也需要转义,所以用\\表示一个实际的\字符)。
1. 基本概念与特点
query_string 查询是一种功能强大且非常灵活的查询方式,它允许使用类似搜索引擎的语法来构建查询语句,支持多种操作符和功能的组合,例如布尔逻辑(AND、OR、NOT)、通配符(* 表示匹配任意数量的字符,? 表示匹配单个字符)、模糊查询(通过 ~ 符号结合编辑距离)、范围查询(针对数值或日期类型字段)、正则表达式匹配等。用户可以通过编写复杂的查询字符串,按照自己期望的逻辑和匹配规则来检索文档。
不过,正因为其功能强大且语法灵活,所以它相对复杂,需要使用者对其语法规则有比较清晰的了解,否则容易出现查询语句编写错误或者查询结果不符合预期的情况。
语法:
{
"query": {
"query_string": {
"default_field": "your_field",
"query": "your_query_string"
}
}
}
例如,以下是一个简单的示例,对 content 字段进行包含 “Elasticsearch” 单词且同时包含 “search engine” 短语(使用布尔逻辑 AND 连接)的查询:
{
"query": {
"query_string": {
"default_field": "content",
"query": "Elasticsearch AND \"search engine\""
}
}
}
2 常用语法示例
布尔逻辑组合:
可以使用 AND、OR、NOT 来组合不同的查询词,实现更精准的逻辑匹配。例如,查找 content 字段中包含 “big data” 或者包含 “machine learning” 的文章文档:
{
"query": {
"query_string": {
"default_field": "content",
"query": "big data OR machine learning"
}
}
}
又比如,查找包含 “Elasticsearch” 但不包含 “Lucene” 的文档:
{
"query": {
"query_string": {
"default_field": "content",
"query": "Elasticsearch AND NOT Lucene"
}
}
}
通配符使用:
结合 * 和 ? 通配符进行模糊匹配,比如查找 content 字段中所有以 “data” 开头的单词所在的文档:
{
"query": {
"query_string": {
"default_field": "content",
"query": "data*"
}
}
}
模糊查询:
通过 ~ 符号结合编辑距离来进行模糊查询,例如查找 content 字段中与 “search” 单词编辑距离在 1 以内(即拼写较相近)的文档:
{
"query": {
"query_string": {
"default_field": "content",
"query": "search~1"
}
}
}
范围查询(针对数值或日期类型字段):
假设有个 publish_date 字段为日期类型,要查找发布日期在 2024 年 1 月 1 日到 2024 年 6 月 30 日之间的文章文档,可以这样写:
{
"query": {
"query_string": {
"default_field": "publish_date",
"query": "[2024-01-01 TO 2024-06-30]"
}
}
}
查询 - simple_query_string 查询
simple_query_string 查询可以看作是 query_string 查询的简化版本,它同样支持一些基本的查询功能,如布尔逻辑(AND、OR、NOT)、通配符(* 和 ? )、模糊查询等,但语法更为简单直观,对用户输入的容错性更好,不需要像 query_string 查询那样严格遵循复杂的语法规则以及对特殊字符进行大量转义操作。
它会自动忽略一些无法解析的语法部分,尽可能按照合理的方式进行查询,比较适合初学者或者在不需要使用非常复杂语法构建查询时使用。
语法
{
"query": {
"simple_query_string": {
"fields": ["your_field"],
"query": "your_query_string"
}
}
}
对 content 字段进行包含 “Elasticsearch” 单词且同时包含 “search engine” 短语(使用布尔逻辑 AND 连接)的 simple_query_string 查询示例:
{
"query": {
"simple_query_string": {
"fields": ["content"],
"query": "Elasticsearch + search engine" //等于 "Elasticsearch AND search engine",没有这么严格
}
}
}
在
simple_query_string查询中,短语不需要用双引号括起来也能被当作一个整体进行匹配处理,并且即使语法上有一些小的不规范(比如这里没有严格按照query_string那样对布尔逻辑运算符大写等),它依然能尝试进行合理的查询。
布尔逻辑组合:
同样支持使用 AND、OR、NOT 进行简单的布尔逻辑组合,例如查找 content 字段中包含 “big data” 或者包含 “machine learning” 的文章文档:
{
"query": {
"simple_query_string": {
"fields": ["content"],
"query": "big data OR machine learning"
}
}
}
通配符使用:
可以使用通配符进行模糊匹配,比如查找 content 字段中所有以 “data” 开头的单词所在的文档:
{
"query": {
"simple_query_string": {
"fields": ["content"],
"query": "data*"
}
}
}
模糊查询:
支持模糊查询功能,例如查找 content 字段中与 “search” 单词拼写较相近的文档:
{
"query": {
"simple_query_string": {
"fields": ["content"],
"query": "search~"
}
}
}
它不支持像 query_string 那样复杂的范围查询(针对数值或日期类型字段使用方括号语法等)、正则表达式匹配等功能,在一些需要精确控制查询逻辑和匹配规则的复杂场景下可能无法满足需求。
查询 - 分页 'from' 'size'
GET http://localhost:9200/shopping/_search
{
"query": {
"match_all": {
}
},
"from":0,
"size":3
}
查询 - 返回数据过滤 '_source'
只返回 title
GET http://localhost:9200/shopping/_search
{
"query": {
"match_all": {
}
},
"from":0,
"size":3,
"_source": ["title"]
}
结果
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 9,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "shopping",
"_id": "pBInzYoBv9F9H8lF0S9_",
"_score": 1,
"_source": {
"title": "小米手机2"
}
},
{
"_index": "shopping",
"_id": "es0G0ooBmBrU9yypB0AI",
"_score": 1,
"_source": {
"title": "小米手机3"
}
},
{
"_index": "shopping",
"_id": "e80G0ooBmBrU9yypJ0BY",
"_score": 1,
"_source": {
"title": "小米手机4"
}
}
]
}
}
查询 - 排序 'sort'
GET http://localhost:9200/shopping/_search
{
"query": {
"match_all": {
}
},
"from":0,
"size":3,
"_source": ["title"],
"sort":{
"price":{
"order" : "asc"
}
}
}
结果:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 9,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "shopping",
"_id": "es0G0ooBmBrU9yypB0AI",
"_score": null,
"_source": {
"title": "小米手机3"
},
"sort": [
1999
]
},
{
"_index": "shopping",
"_id": "e80G0ooBmBrU9yypJ0BY",
"_score": null,
"_source": {
"title": "小米手机4"
},
"sort": [
2199
]
},
{
"_index": "shopping",
"_id": "fM0G0ooBmBrU9yypT0AH",
"_score": null,
"_source": {
"title": "小米手机10"
},
"sort": [
2999
]
}
]
}
}
查询 - 多条件 bool 'must'
must 是 AND
shold 是 OR
GET http://localhost:9200/shopping/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "米手"
}
},
{
"match": {
"price": 2999
}
}
]
}
}
}
返回,分词查询,所以"title": "华为手机1" 也被查出来了
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1.8498011,
"hits": [
{
"_index": "shopping",
"_id": "fM0G0ooBmBrU9yypT0AH",
"_score": 1.8498011,
"_source": {
"title": "小米手机10",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 2999
}
},
{
"_index": "shopping",
"_id": "fc0G0ooBmBrU9yyptEC8",
"_score": 1.0512933,
"_source": {
"title": "华为手机1",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 2999
}
},
{
"_index": "shopping",
"_id": "fs0G0ooBmBrU9yypwkB9",
"_score": 1.0512933,
"_source": {
"title": "华为手机2",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 2999
}
}
]
}
}
查询 - 多条件 bool 'should'
must 是 AND
should 是 OR
GET http://localhost:9200/shopping/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"title": "小米"
}
},
{
"match": {
"title": "华为"
}
}
]
}
}
}
查询 - 多条件 bool 范围 'range'
范围价格超过 4000 的
gt 大于
lt 小于
GET http://localhost:9200/shopping/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"title": "小米"
}
},
{
"match": {
"title": "华为"
}
}
],
"filter":{
"range":{
"price":{
"gt": 4000
}
}
}
}
}
}
查询 - 短语完全匹配 match_phrase
短语完全匹配
GET http://localhost:9200/shopping/_search
{
"query": {
"match_phrase": {
"title": "米手"
}
}
}
查询 - 聚合分组 aggs
GET http://localhost:9200/shopping/_search
{
"aggs": { //聚合操作
"price_group": { //名字随便起
"terms": { //分组
"field": "price"
}
}
},
"size":0 //丢掉原始数据
}
返回结果
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 11,
"relation": "eq"
},
"max_score": 1,
"hits": []
},
"aggregations": {
"price_group": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 4999,
"doc_count": 4
},
{
"key": 2999,
"doc_count": 3
},
{
"key": 3999,
"doc_count": 2
},
{
"key": 1999,
"doc_count": 1
},
{
"key": 2199,
"doc_count": 1
}
]
}
}
}
查询 - 平均值 'avg'
GET http://localhost:9200/shopping/_search
{
"aggs": { //聚合操作
"price_avg": { //名字随便起
"avg": { //平均值
"field": "price"
}
}
},
"size": 0 //丢掉原始数据
}
结果
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 11,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"price_avg": {
"value": 3744.4545454545455
}
}
}
精确匹配
单字段精确查找 term (默认区分大小写)
避免对
文本字段使用查询search 文本, use the
matchquery instead匹配的是分词后的值,text被分词后,一般情况下,全文都不能匹配(除非分词后也能包含全文,例如 ik_max_word)
搜索数字
POST shopping/_search
{
"query": {
"term": {
"price": 2999
}
}
}
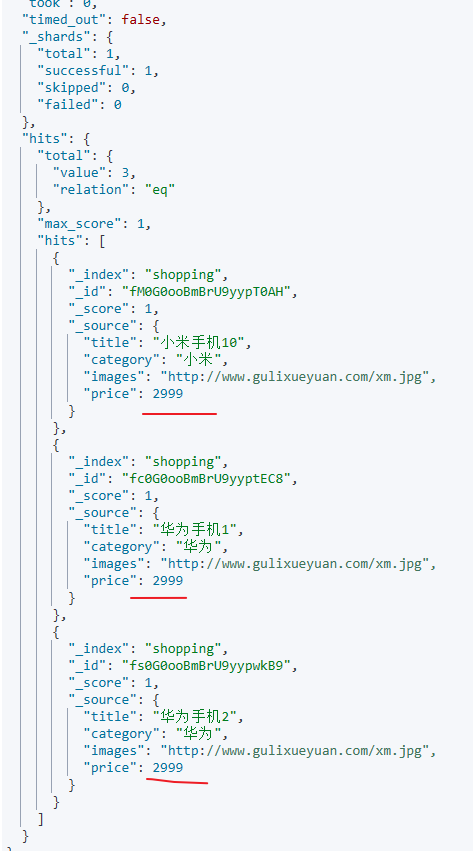
target.keyword 在查询中的含义
{ "query": { "wildcard": { "target.keyword": "hide is el corazón de las personas, hacerles reír o llorar. " } } }在你的查询语句中使用
target.keyword这种写法,通常意味着你想要基于target字段进行精确匹配查找,并且这个target字段在索引的映射(Mapping)中应该是被定义为了keyword类型。因为 Elasticsearch 默认情况下,如果对文本字段进行查询,会进行分词等文本分析操作,可能会导致匹配结果不符合期望(比如部分词匹配上就算匹配成功等情况),而通过指定target.keyword,就是明确告诉 Elasticsearch 要以整个target字段的值(也就是把它当作一个完整的、未经分词处理的词条)来和你给定的查询值(这里是"hide is el corazón de las personas, hacerles reír o llorar. ")进行精确匹配。
{
"query": {
"match": {
"title.keyword": "小米手机4"
}
}
}

批量精确查找 terms
POST shopping/_search
{
"query": {
"terms": {
"title.keyword": [
"小米手机4",
"小米手机2"
]
}
}
}
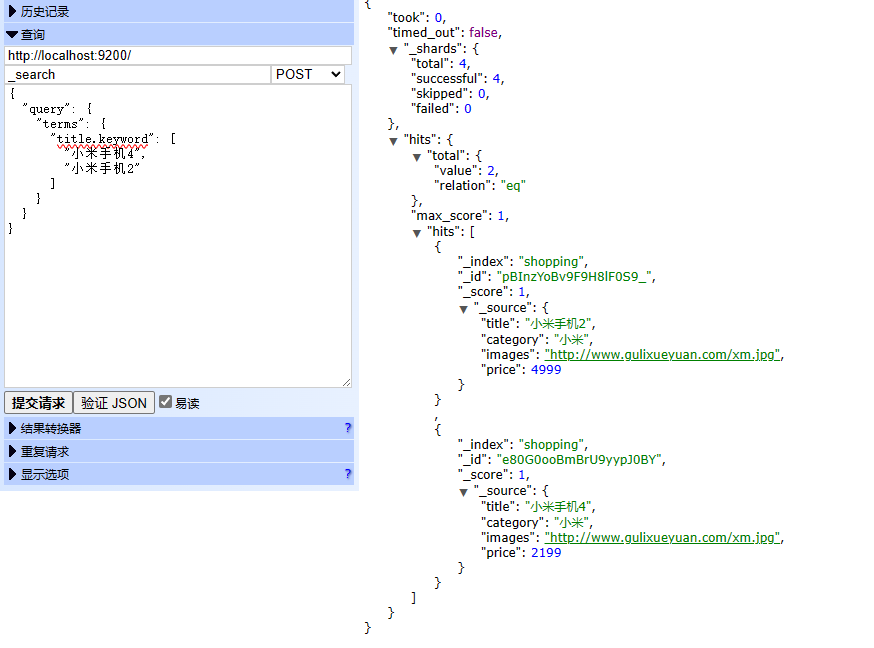
term_set 多值字段的匹配
模糊查询
假如有2条数据
{
"_index": "shopping",
"_id": "hM1C0ooBmBrU9yypO0Cw",
"_score": 1,
"_source": {
"title": "John Cleese criticizes BBC removal of ‘Fawlty Towers’ episode due to racial slurs 'We were not supporting his views,' said the 'Monty Python' star of 'Fawlty Towers",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 4999
}
},
{
"_index": "shopping",
"_id": "hc1E0ooBmBrU9yypyEBf",
"_score": 1,
"_source": {
"title": "We were not supporting his views",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 4999
}
}
wildcard 类似 like
*(星号):可以匹配任意数量(包括零个)的字符。例如,查询te*可以匹配test、tea、tell等以te开头的任意单词。?(问号):只能匹配单个字符。例如,查询t?st可以匹配test、tast等长度为 4 且第二个字符任意的单词。
和SQL的 LIKE 一样
注意,这里使用了 .keyword 后缀,这是因为我们在映射中定义了 "title" 字段的 "keyword" 子字段。在 wildcard 查询中,我们需要明确指定这个子字段。
另外,你需要注意的是,wildcard 查询是区分大小写的。如果你希望执行不区分大小写的搜索,你可能需要调整你的映射或使用其他查询类型。
{
"query": {
"wildcard": {
"title.keyword": "*We were*"
}
}
}
结果
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "shopping",
"_id": "hM1C0ooBmBrU9yypO0Cw",
"_score": 1,
"_source": {
"title": "John Cleese criticizes BBC removal of ‘Fawlty Towers’ episode due to racial slurs 'We were not supporting his views,' said the 'Monty Python' star of 'Fawlty Towers",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 4999
}
},
{
"_index": "shopping",
"_id": "hc1E0ooBmBrU9yypyEBf",
"_score": 1,
"_source": {
"title": "We were not supporting his views",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 4999
}
}
]
}
}
如果使用
{
"query": {
"wildcard": {
"title.keyword": "*We were not supporting his views,*"
}
}
}
结果
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "shopping",
"_id": "hM1C0ooBmBrU9yypO0Cw",
"_score": 1,
"_source": {
"title": "John Cleese criticizes BBC removal of ‘Fawlty Towers’ episode due to racial slurs 'We were not supporting his views,' said the 'Monty Python' star of 'Fawlty Towers",
"category": "华为",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 4999
}
}
]
}
}
忽略大小写
{
"query": {
"wildcard": {
"title.keyword":{
"value": "*we were not supporting HIS VIEWS,*",
"case_insensitive":true
}
}
}
}
一样可以搜索出来
regexp 正则匹配
regexp 查询基于正则表达式的语法规则,通过定义特定的模式来对指定字段的文本内容进行匹配查找。正则表达式本身是一种用于描述字符匹配模式的工具,具有很强的灵活性和表达力,能应对各种复杂的文本匹配需求。在 Elasticsearch 中利用 regexp 查询,可以实现诸如查找符合特定格式、包含特定字符组合、满足特定重复规则等要求的文本内容对应的文档。
例如,你可以使用正则表达式来查找所有电话号码格式符合特定要求(如手机号码为 11 位数字且以 1 开头等模式)的客户信息文档,或者查找包含特定单词变体(通过正则表达式描述单词的不同后缀、前缀等变化形式)的文章文档等。
1. 简单字符匹配示例
假设在名为 documents 的索引中有个 content 字段存储文章内容,要查找所有包含单词 “Elasticsearch” 的文档,可以使用如下正则表达式查询:
{
"query": {
"regexp": {
"content": "Elasticsearch"
}
}
}
2. 字符范围匹配示例
若要查找 content 字段中包含以字母 a 到 z 之间任意一个字母开头的单词的文档,可以使用字符范围的正则表达式模式:
{
"query": {
"regexp": {
"content": "[a-z].*"
}
}
}
3. 重复匹配示例
比如要查找 content 字段中包含连续出现至少 3 次数字的文本内容所在的文档,可以这样写:
{
"query": {
"regexp": {
"content": "\\d{3,}"
}
}
}
性能影响:
由于正则表达式的匹配逻辑相对复杂,尤其是当正则表达式模式比较复杂或者需要匹配的数据量很大时,regexp 查询可能会对性能产生较大影响。例如,使用非常宽泛、复杂的正则表达式去匹配大量文档中的长文本字段内容,可能会导致查询耗时较长,占用较多的系统资源。所以在实际使用中,尽量保证正则表达式简洁明了,并且针对具体的匹配需求进行优化,避免过度复杂的模式。
fuzzy 纠错查询
是一种误拼写时的fuzzy模糊搜索技术,用于搜索的时候可能输入的文本会出现误拼写的情况。
比如:输入”方财兄“,这时候也要匹配到“方才兄”。
一、基本概念
fuzzy 查询是 Elasticsearch 提供的一种模糊查询方式,它主要基于编辑距离(Levenshtein Distance)来判断查询字符串与目标字段中的文本值是否相似,以此实现模糊匹配。编辑距离指的是通过最少的操作次数(如插入、删除、替换字符)将一个字符串转换为另一个字符串的次数。例如,单词 “apple” 和 “appel” 的编辑距离为 1(只需将 “e” 替换为 “l”),在一定的编辑距离阈值内,fuzzy 查询就会认为它们是匹配的。
二、使用场景
- 处理拼写错误:在用户输入搜索关键词时,很可能出现拼写错误的情况。比如在搜索引擎中,用户想搜索 “elephant”,但误写成了 “elefant”,通过
fuzzy查询,只要编辑距离在设定的阈值范围内,依然可以找到包含 “elephant” 的相关文档,提升了搜索的容错性和用户体验。 - 应对不精确输入:当用户对要查找的内容记忆不太准确,输入的关键词只是大致接近正确内容时,
fuzzy查询也能发挥作用。例如,用户记得某个产品名称大概发音是 “loptop”(实际为 “laptop”),使用fuzzy查询就能匹配到正确的产品相关文档。
一般写法
{
"query": {
"fuzzy": {
"title": "computer"
}
}
}
- 自定义编辑距离阈值进行模糊查询:
(默认为2) 若希望更严格地控制模糊匹配的程度,设置编辑距离阈值为 1,查找与 “book” 拼写相近的图书标题所在的文档,可以这样写查询:
{
"query": {
"fuzzy": {
"title": {
"value": "book",
"fuzziness": 1
}
}
}
}
prefix 前缀查询
这种只支持前缀查询,属于模糊查询的子集,叫前缀查询(prefix),返回包含指定前缀的所有文档。
不会对搜索的字符串进行分词。
不会评分。
原理:
遍历所有的倒排索引,并比较每个词项(term)是否以搜索前缀开头。

