



IO模型类型(转)
原文:https://blog.csdn.net/leftfist/article/details/105020228 (有改动)
IO 模型是网络编程的一个基本话题, 在互联网发展的早期, 终端设备并不多, 基本的阻塞式 IO 即可满足要求, TCP/IP 的诞生在全球范围内建立起了统一的通信体系, 尤其是上世纪 90 年代初, Tim Berners-Lee 成功利用 Internet 实现了第一次 HTTP 的传输, 互联网进入了一个新的里程碑, 在此之后, 终端设备呈现几何级数式增长, 到了九十年代末便提出了著名的 The C10K Problem, 即在单机 Web Server 上实现 10000 并发, 在相同的硬件条件下, 如何提高并发连接数、实现高性能服务器是一个值得探索的问题, 从最初的单进程顺序处理到 fork 子进程处理再到多线程处理, 后来出现了诸如 select/poll/epoll/kqueue 等多种 IO 复用机制, 在这些 IO 多路复用机制上催生了如 Nginx、libevent、libev 等诸多优秀的项目, 从广义上讲, IO 模型并不仅仅限于网络 IO, 对于磁盘 IO 来说原理都是相同的,他们都有一个文件描述符fd(file descriptor),对网络io而言,两个socket建立连接后,各自的进程都会给对方的socket分配一个fd,这样就可以像对待磁盘文件那样对这个fd进行读取/写入(对磁盘而言,fd = file.open(FileName) )。
socket通信是一种网络IO
对客户端而言,服务器收到 socket请求后发生了什么其实不用关注,无论socket具体是做什么,都是通过以下步骤完成:
客户端调用socket链接 -> 内核向服务器发起请求 -> 内核建立socket连接,等待服务器返回的数据全部到达 -> 数据从内核空间拷贝到用户空间 -> 用户线程读取数据
1,同步
所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不返回。也就是必须一件一件事做,等前一件做完了才能做下一件事。
2,异步
异步的概念和同步相对。当一个异步过程调用发出后,调用者不能立刻得到结果,但也不会等待结果,函数会立即返回。实际处理这个调用结果是在完成后,通过事件(event)状态、通知和回调来通知调用者获取数据。
(判断的关键点:同步是一个操作完成,下一个操作才能开始,而异步是上一个操作发起,不用等完成,下一个操作就可以开始)
(所以对下面讲的IO多路复用(异步阻塞IO)而言,如果等待的socket队列中一个都没准备好,那你也可以说他是同步阻塞的,但一但其中一个准备好后,它就继续往下执行了,不用等其他socket全部完成,这个时候它又成异步的了)
3,阻塞
阻塞调用是指在调用发起,内核IO操作完成并返回用户空间之前,当前线程会被挂起(线程进入阻塞状态,cpu不会给线程分配时间片,即线程暂停运行,关键点是不能再使用CPU,判断是否是阻塞就看这个线程是否还能继续用CPU)。函数只有在得到结果之后才会返回。
4,非阻塞
非阻塞和阻塞的概念相对应,指在不能立刻得到结果之前,该函数不会阻塞当前线程,线程一直处于激活状态,也不会让出CPU。
什么是IO多路复用?就是异步阻塞IO,是IO模型中的一种。目的在于提升系统效率。
服务器端编程经常需要构造高性能的IO模型,常见的IO模型有四种:
(1)同步阻塞IO(Blocking IO):即传统的IO模型。
(2)同步非阻塞IO(Non-blocking IO):默认创建的socket都是阻塞的,非阻塞IO要求socket被设置为NONBLOCK。
(3)IO多路复用(IO Multiplexing):即经典的Reactor模式(并非23种设计模式之一),有时也称为异步阻塞IO,Java中的Selector和Linux中的epoll都是这种模型。
Reactor模式称为反应器模式或应答者模式,是基于事件驱动的设计模式,拥有一个或多个并发输入源,有一个服务处理器和多个请求处理器,服务处理器会同步的将输入的请求事件以多路复用的方式分发给相应的请求处理器。 Reactor设计模式是一种为处理并发服务请求,并将请求提交到一个或多个服务处理程序的事件设计模式。(感觉像外观模式facade)
(4)异步IO(Asynchronous IO):即经典的Proactor设计模式,也称为异步非阻塞IO。
一、同步阻塞IO
用户需要等待read将socket中的数据读取到buffer后,才继续处理接收的数据。整个IO请求的过程中,用户线程是被阻塞的,这导致用户在发起IO请求时,不能做任何事情,对CPU的资源利用率不够。
(客户端用户线程调用read(系统调用)后阻塞等待两件事完成:1. 等待内核把数据准备好(也就是将数据从服务器传输到本地);2. 内核线程将内核空间的数据拷贝到指定的用户空间地址(以供用户线程读取))

二、同步非阻塞IO
用户线程发起IO请求后,立即返回;但需要不断地调用read,尝试读取socket中的数据,直到读取成功后,才继续处理接收的数据。
虽然用户线程每次发起IO请求后可以立即返回,但是为了等到数据,仍需要不断地轮询、重复请求,消耗了大量的CPU的资源。一般很少直接使用这种模型,而是在其他IO模型中使用非阻塞IO这一特性。
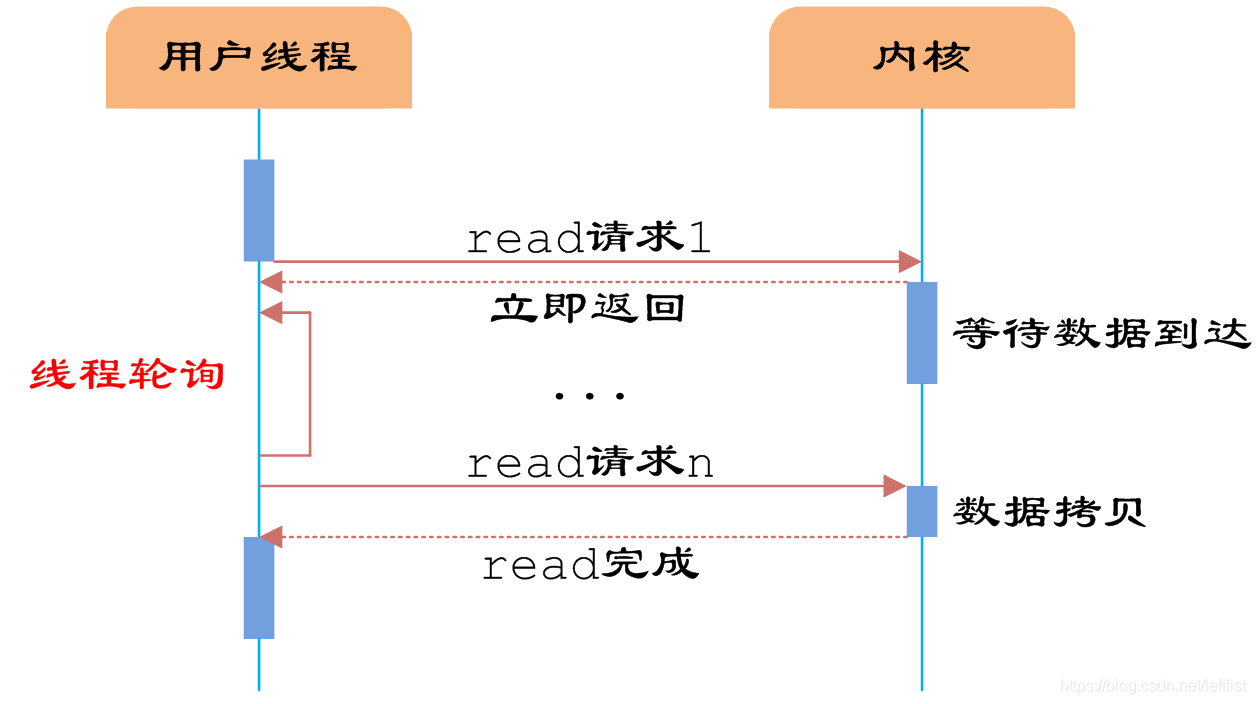
三、异步阻塞IO(IO多路复用)
异步阻塞模型使用内核提供的select函数(多路分离函数),避免同步非阻塞模型中轮询等待的问题。(除了select外还有其他系统调用方法,详见:IO多路复用基本概念:select,epoll(转))

表面上看,异步阻塞模型和同步阻塞模型没有太大的区别(同样是阻塞,即卡住不再使用CPU),甚至还多了添加监视socket,以及调用select函数的额外操作,效率更差。
但是,它最大的优势是可以在一个线程内同时处理多个IO请求:用户可以注册多个socket,然后不断地调用select来读取被激活的socket(select会轮询一个列表,列表里的每一个fd对应一个socket,一旦有个已准备就绪后就可以继续往下执行,然后再回来调用select轮询看看有没有准备好的,直到所以的IO都处理完)。
即可达到在同一个线程内同时处理多个IO请求的目的,所以又叫IO多路复用模型。(同时等待多个socket而不用像同步阻塞那样一个一个发起一个一个等,线程阻塞导致一个线程同一时刻只能发起一个IO(想要多IO的话只能建立多个线程),浪费了时间)
虽然上述方式允许单线程内处理多个IO请求,但是每个IO请求的过程还是阻塞的(在select函数上阻塞),平均时间甚至比同步阻塞IO模型还要长。
如果用户线程只注册自己感兴趣的socket或者IO请求,然后去做自己的事情,等到数据到来时再进行处理,则可以提高CPU的利用率。以下是改良版(reactor模式):
reactor模式:
(1)应用程序注册读就绪事件和相关联的事件处理器(拿socket来讲读就绪事件就是数据已经从服务器返回到本地,但是还放在内核空间,需要用户线程调用系统调用read来拷贝到用户空间);
(2)事件分离器等待事件的发生(事件分离器也就是下面的reactor);
(3)当发生读就绪事件的时候,事件分离器调用第一步注册的事件处理器(即下面的通知用户线程);
(4)事件处理器首先执行实际的读取(read)操作,然后根据读取到的内容进行进一步的处理。
说白了其实就是由下面的reactor负责托管所有线程的IO请求,当有线程有IO请求时就向reactor注册一个与读取就绪事件(可以理解为这个线程要读取的FD)关联的事件处理器(一个函数指针?我猜),然后reactor负责监控这些事件,当某一个事件发生时(也就是读取就绪了),再调用这个处理器通知相应的线程通过read系统调用来取数据

四、异步非阻塞IO(异步IO)
“真正”的异步IO需要操作系统更强的支持。在IO多路复用模型中,用户线程收到通知后,自行读取数据、处理数据。而在异步IO模型中,则由内核读取数据,并放在缓冲区,用户线程收到通知后,直接使用即可。
Proactor模式:
(1)应用程序初始化一个异步读取操作,然后注册相应的事件处理器(此时事件处理器不关注读取就绪事件,而是关注读取完成事件,这是区别于Reactor的关键);
(2)事件分离器等待读取操作完成事件;
(3)在事件分离器等待读取操作完成的时候,操作系统调用内核线程完成读取操作,并将读取的内容放入用户传递过来的缓存区中。这也是区别于Reactor的一点,Proactor中,应用程序需要传递缓存区;
(4)事件分离器捕获到读取完成事件后,激活应用程序注册的事件处理器,事件处理器直接从缓存区读取数据,而不需要进行实际的读取操作。

五、异步阻塞IO为什么叫IO多路复用
原因上面已经说了,IO多路复用其实就是异步阻塞IO,就是一个线程,可以同时处理多个IO请求(反过来不成立,一个IO请求只能对应一个线程)。

其实“I/O多路复用”这个说法之所以难以理解,可能是翻译比较坑爹。所谓的I/O多路复用在英文中其实叫 I/O multiplexing。
这里面的 multiplexing 指的是通过跟踪每一个Socket的状态来同时管理多个I/O流。其目的,在于尽量多的提高服务器的吞吐能力。
六、同步异步、阻塞非阻塞为什么和多线程、IO联系在一起?
线程为什么会和IO扯在一起?
一个线程的执行,通常需要 3 个资源,即CPU,内存和I/O。CPU负责运行,内存负责存放即时数据,I/O负责和磁盘、数据库、网络等做数据交换。
I/O,即输入/输出。Java中,常见的I/O,有文件流,数据库连接,网络连接等。
I/O的特点是每个连接单位时间内只能为一个线程服务,它不像CPU,即使是单核CPU,也可以通过时间切片的方式,执行多线程,多核CPU就更不用说了。
IO只能为单一线程服务。还有一个特点是,当一个线程在使用I/O时,一般耗时相对较长,且在这个时间段内,线程不进行计算或读写内存,换言之,线程在使用I/O时,一般不会使用CPU或内存。
这个特点很重要,这其实是多线程的重要意义之一。在一个线程使用I/O时,将CPU使用权转移给其它线程,可以更加充分的利用系统资源。
1 /* 2 编写一个程序,开启3个线程,这3个线程的ID分别为A、B、C,每个线程将自己的ID在屏幕上打印10遍, 3 要求输出结果必须按ABC的顺序显示;如:ABCABC….依次递推。 4 思路:用信号量进行各个子线程之间的互斥,创建3个信号量A、B、C。初始时A的资源数为1,B、C的资源数为0,访问A之后, 5 将B的资源数加1,访问B之后将C的资源数加1,访问C之后将A的资源数加1。创建3个子线程顺序访问资源A、B、C。 6 */ 7 #include "stdafx.h" 8 #include "stdio.h" 9 #include "stdlib.h" 10 #include <iostream> 11 #include <string> 12 #include <stack> 13 #include <windows.h> 14 #include <process.h> 15 using namespace std; 16 17 const int THREAD_NUM = 10; 18 HANDLE ga,gb,gc; 19 20 unsigned int __stdcall FunA(void *pPM) 21 { 22 Sleep(50);//some work should to do 23 printf("A\n"); 24 ReleaseSemaphore(gb, 1, NULL);//递增信号量B的资源数 (ReleaseSemaphore函数用于对指定的信号量增加指定的值) 25 26 return 0; 27 } 28 29 unsigned int __stdcall FunB(void *pPM) 30 { 31 Sleep(50);//some work should to do 32 printf("B\n"); 33 ReleaseSemaphore(gc, 1, NULL);//递增信号量C的资源数 34 35 return 0; 36 } 37 38 unsigned int __stdcall FunC(void *pPM) 39 { 40 Sleep(50);//some work should to do 41 printf("C\n"); 42 ReleaseSemaphore(ga, 1, NULL);//递增信号量A的资源数 43 44 return 0; 45 } 46 47 int main() 48 { 49 //初始化信号量 50 ga = CreateSemaphore(NULL, 1, 1, NULL);//创建一个信号量:当前1个资源,最大允许1个同时访问 51 gb = CreateSemaphore(NULL, 0, 1, NULL);//当前0个资源,最大允许1个同时访问 52 gc = CreateSemaphore(NULL, 0, 1, NULL);//当前0个资源,最大允许1个同时访问 53 54 HANDLE handle[THREAD_NUM]; 55 int i = 0; 56 while (i < THREAD_NUM) // A,B,C分别创建10个线程(每次循环A,B,C都分别会消耗一个信号量并创建一个线程,又增加一个信号量) 57 { 58 WaitForSingleObject(ga, INFINITE); //阻塞等待信号量A>0 59 handle[i] = (HANDLE)_beginthreadex(NULL, 0, FunA, &i, 0, NULL); // 创建一个线程 60 WaitForSingleObject(gb, INFINITE); //阻塞等待信号量B>0 61 handle[i] = (HANDLE)_beginthreadex(NULL, 0, FunB, &i, 0, NULL); 62 WaitForSingleObject(gc, INFINITE); //阻塞等待信号量C>0 63 handle[i] = (HANDLE)_beginthreadex(NULL, 0, FunC, &i, 0, NULL); 64 65 ++i; 66 } 67 WaitForMultipleObjects(THREAD_NUM, handle, TRUE, INFINITE); 68 69 //销毁信号量 70 CloseHandle(ga); 71 CloseHandle(gb); 72 CloseHandle(gc); 73 for (i = 0; i < THREAD_NUM; i++) 74 CloseHandle(handle[i]); 75 return 0; 76 }

