


线程的地址空间问题(转)
原文:https://blog.csdn.net/qq_41148436/article/details/121684129
Linux系统把所有线程都当做进程来实现,线程作为轻量级进程(LWP)。线程仅仅被视为一个与其他进程共享某些资源的进程,
而是否共享地址空间几乎是进程和 Linux 中所谓线程的唯一区别(通常我们说创建了一个进程,其实也可以说是创建了一个线程,只是这时这个进程里面只有这一个线程,这个线程独占这个进程的所有资源)。
(我的理解:操作系统实际上不知道线程的概念,它实际上是以调度进程的方式来调度线程,有些操作系统支持线程,所以在这些操作系统中进程调度也称为线程调度,这两个概念常常交替使用。
在支持线程的系统里有内核级线程的概念(不支持的则称为内核级进程)
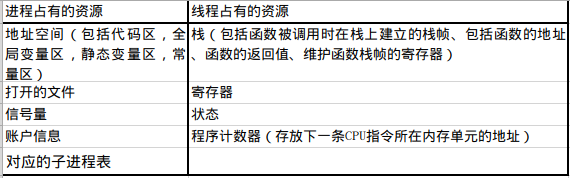
(注意线程的堆是共用进程的堆(其实也可以说是每个线程私有的,因为每个线程也不可能访问其他线程的堆地址),因为堆内存要在程序里手动申请,上表中出线程占有的资源外,其他进程资源是所有线程共享的)
(我的理解:我们说线程切换比进程快,这里的线程可以说是用户线程,也可以说是内核线程(用户线程使用用户地址空间,内核线程使用内核地址空间,因为是一对一模型,要切换肯定是两者共同切换的,也不会有两个用户线程抢占一个内核线程的说法),内核其实把内核线程也当做进程来调度,它没有线程的概念,只不过在切换同一个进程下的内核线程的时候,上表中进程占有资源一栏中的东西不用切换,这样就加快了切换速度,但跨进程的线程切换,速度还是和进程切换一样的。
不同的任务,肯定得用不同的进程来执行,但是同一个任务,如果还按照进程来细分,就没有按照线程来细分速度快,无论操作系统的进程调度算法如何,调度到一个进程时,都会分给这个进程一定的时间片,然后每个进程再分别调度自己的线程,
如果内核进程没有划分多线程(也就是多对一模型,一个进程下的多个用户线程对应一个内核线程,这种模型已淘汰),那么这个进程里的一个用户线程阻塞(比如等待I/O或者进行缺页处理),就会导致整个进程阻塞,因为操作系统内核感知不到用户线程的存在,它不知道阻塞了,还是会等到这个进程用完它的时间片,再切换到其他内核进程(但是这种多对一模型他有个优点,就是它的用户线程切换时,因为不存在内核线程切换,也就不用进行系统调用,所以切换过程只在用户态下完成,这样它的用户线程切换更快))
线程创建的时候,加上了 CLONE_VM 标记,这样线程的内存描述符 将直接指向 父进程的内存描述符,
也就是说,线程的mm_struct *mm指针变量和所属进程的mm指针变量相同。所有线程都共享一份地址空间,这不但包括text、heap和进程stack等,甚至还包括了线程stack。
注意此处表达的字面意思:
所有线程共享包括线程栈在内的地址空间,并不意味着所有线程都共享一个栈地址,而是一个线程可以访问另一个线程的栈数据
(虽然并没什么用,但确实可行,通过实验可以验证)。显然,
不同线程有不同的函数调用关系所以不能使用同一个栈
。之所以能做到线程A能访问线程B的栈数据,正是因为内核为每个线程在不同地址处分配了栈空间,从进程的全局地址空间看(cat /proc/PID/maps),每个线程的stack都位于不同的地址段。
(比如说进程地址为0-99,A线程使用地址0-9,B线程使用地址10-19,C进程使用20-29,...,有些地址比如80-99用来保存代码段,全局变量等,这部分地址空间每个线程共享)
虽然线程共享地址空间,但线程的私有数据,又是需要单独保存的,这包括了:
pthread属性相关,pthread_attr
线程栈,thread stack
线程本地存储,TLS(thread local storage)
这三种数据位于同一块内存中,是在创建线程的时候,用mmap系统调用从heap分配出来的
操作系统不知道线程的存在


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)