


编译过程(转)
原文: https://blog.csdn.net/cainiaochufa2021/article/details/125661575
前言
在ANSI C 的任何一种实现中,存在两个不同的环境:
- 第一种是编译环境,在这个环境下源代码被转换成可执行的机器指令。
- 第二种是执行环境,这个环境用于实际执行代码。
本篇文章重点了解程序在编译(翻译)环境会执行的操作。
为了可以更清楚的演示过程:这里创建了两个文件:
程序的翻译环境
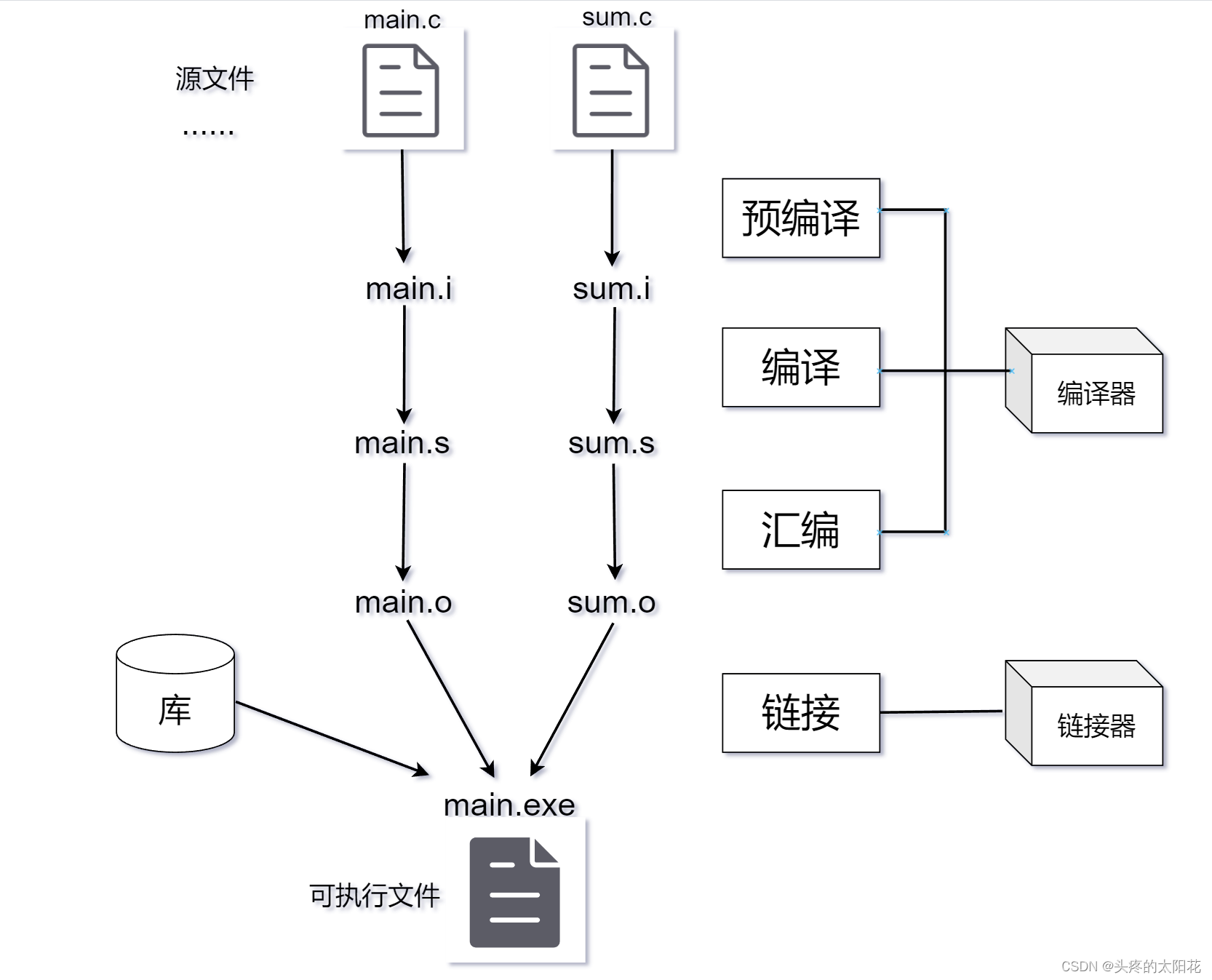
程序的编译也叫做程序的翻译,主要可以分为这四个步骤:预编译(也叫预处理)、编译、汇编、链接。
前面我们得到了一份C语言源代码,它包括了两个文件: main.c和sum.c。我们的目的是需要计算出两个数的和(也就是执行出打印出两数之和的结果)。我们将可以执行结果的文件称为可执行文件。
源文件(.c, .cpp)经过预处理、编译、汇编后,得到后缀名为 .o 的目标文件(一个源文件对应一个.o),.a文件(静态链接库),.so文件(动态链接库)是由.o目标文件集合而成,本质上与.o文件一样,
再经过链接后,生成可执行文件。(实际上链接过程可以发生在编译时、程序加载到内存时、程序运行时)
在Windows中C语言源代码生成的可执行文件的扩展名一般是.exe
在Linux中C语言源代码生成的可执行文件的扩展名一般是.out
生成.a和.so的目的是将一些常用的库代码预先编译整理起来,提供给需要的程序使用,这样那些程序就不用重复编译这些代码,节省时间和资源。
要得到可执行文件。我们需要先对每一份源文件预编译、编译、汇编。执行完这三个步骤后会得到两份目标文件(扩展名为: .o)。然后链接文件以及需要的库就能够得到对应的可执行文件。
(各阶段文件生成参考:https://blog.csdn.net/zyhse/article/details/105228959)
注意:如果有多个.c文件,那么编译器会单独处理每个源文件,生成各自的.obj文件,这些目标文件+链接库整体经过链接最终生成可执行程序 :
下面是将分别介绍这几个环节:
预编译(预处理)
预处理的细节利用Linux环境可以更方便的观察到。这里利用Linux环境去观察源文件main.c在预处理阶段执行了哪些操作。
C语言源代码和对应的头文件会被预编译成一个.i文件。预处理主要是进行一些文本级的操作,包括:
1. 展开头文件。预编译的时候会展开源文件中包含的所有头文件,例如:stdio.h

2. 符号的替换:预编译的时候会将所有定义的宏和符号替换成对应的数据。
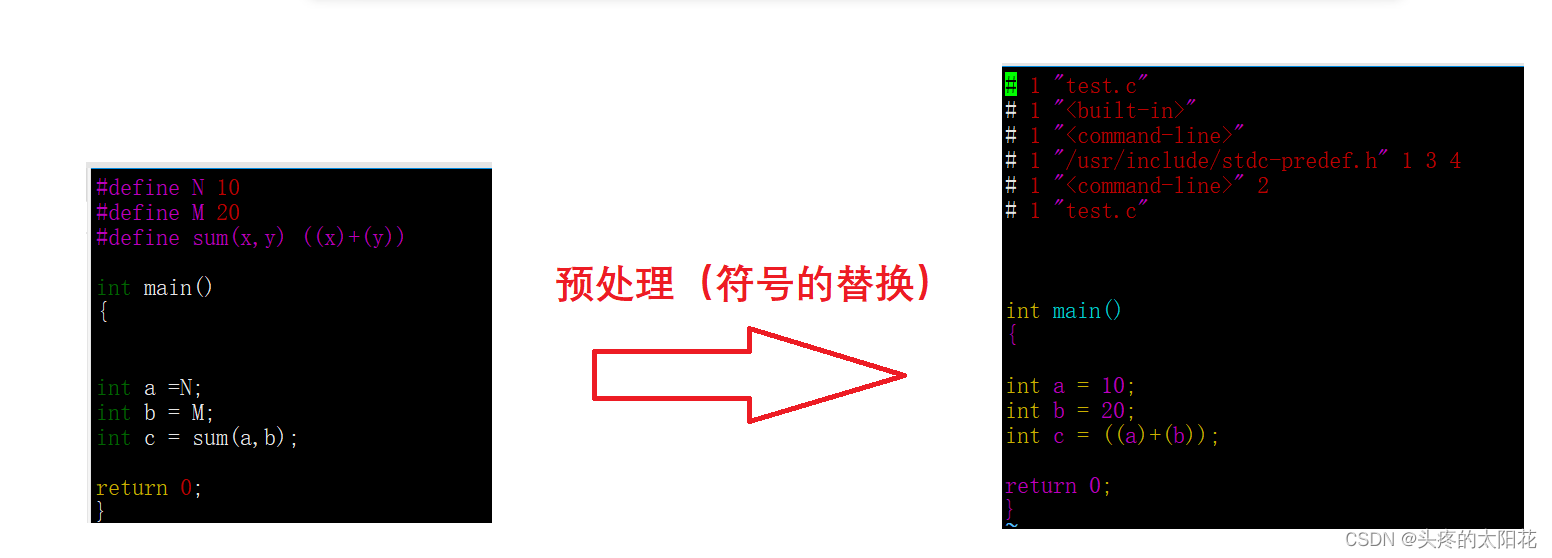
3. 删除注释

预处理后的文件不包含任何的宏定义,因为里面所有的宏都已经被替换。同样,.i文件中也已经包含了全部所需要的头文件。
编译
编译依靠的是编译器
编译过程主要进行的是:
1. 词法分析
词法分析会分析你的代码中的所有符号,然后产生一系列不同类型的记号:标识符、特殊符号(比如运算符号)、数字、字符串等。
2. 语法分析
运算符的优先级和含义也被定下来。在这个阶段,括号不匹配,缺少操作符等问题就会被编译器发现,然后报告语法错误。
3. 语义分析
编译器可以分析的语义是静态语义。包括声明和类型的匹配,类型的转换等。
/* 举例子: 当一个浮点类型的数据被赋值给整形数据时,其中隐含了一个浮点类型到整形数据的转换,语义分析的过程需要完成这个步骤。 将一个浮点值赋值给一个指针的时候,编译器会发现类型不匹配,然后报编译错误。 */
动态语义一般是值在运行的时候出现的语义相关的问题,比如0作为除数时是一个运行时语义错误。
4. 符号汇总
在词法分析的时候我们得到了很多的符号。在整个编译与链接的过程中,我们将函数名和变量名作为他们对应的符号名。
而编译的时候我们需要将特殊的符号汇总:
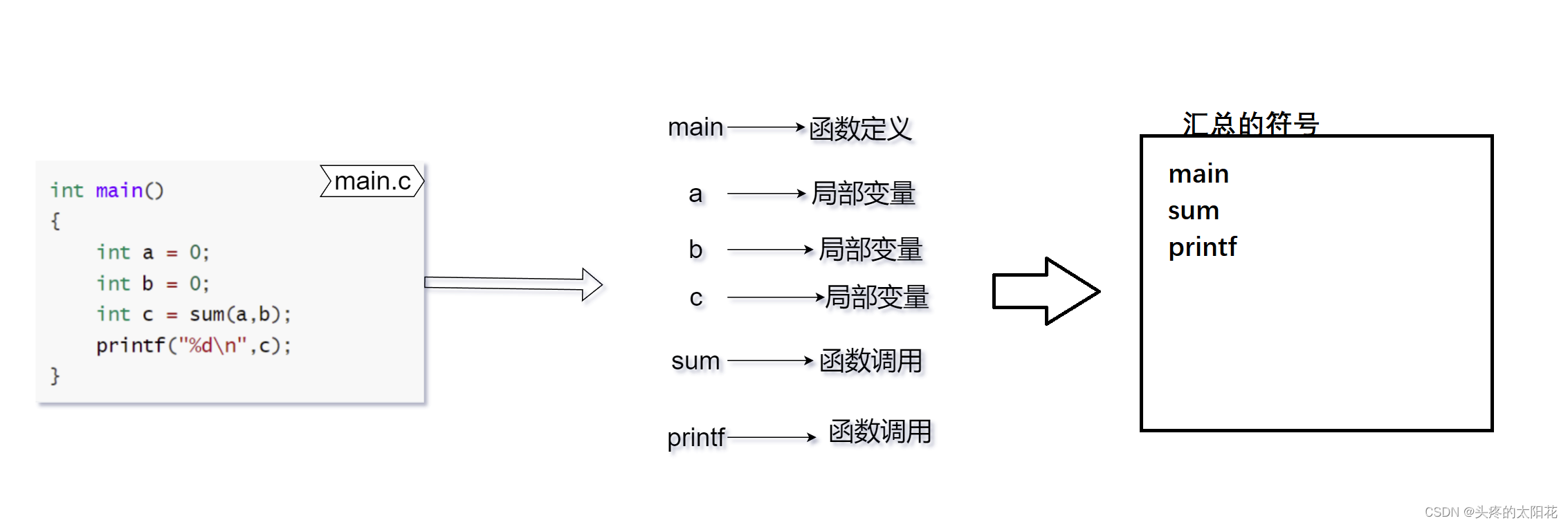
符号汇总是有一定规则的:只会汇总函数名、全局变量和静态数据。
做完这几步后,编译器会将文件中的语言格式转换成汇编代码。
汇编
汇编是利用汇编器将汇编代码转化成机器可以执行的指令。每一个汇编指令几乎都对应了一条机器指令。
汇编后得到的文件就是目标文件。
windows环境中目标文件的后缀是.obj、在linux环境目标文件是后缀是.o
目标文件就是源代码编译后但是还没有进行链接的中间文件。
目标文件中有编译后的机器指令代码,数据。除此以外,目标文件中还有链接时需要的一些信息:符号表,调试信息,字符串等。
一般目标文件将这些信息按照不同的属性,以段segment的形式存储(一般情况下,他们都表示一个一定长度的区域)。
形成符号表
这是整个编译汇编过程中十分重要的一步。每一个文件编译完后都会有一个对应的符号表存储在目标文件中。
每一个目标文件都会有一个符号表,这个表中记录了目标文件中所用到的所有符号,每一个定义的符号有一个对应的值,叫做符号值。对于函数和变量来说这个符号值就是它们的地址。
符号表中有什么?
符号表中记录了每一个被汇总的符号,以及该符号的地址。如果这个符号是一个还没有被定义的函数名,那么这个地址就不是一个游戏地址,但是符号表中仍然有这个符号的数据。
符号表的作用在链接的时候体现。
链接
链接依靠的是链接器—为了让我们使用库函数有源头。现代的编译器可以将一个源代码编译成一个未链接的目标文件,然后由链接器将这些目标文件链接起来形成一个可执行文件。
我们的两个文件在连接前是不能够运行出结果的。因为在main函数调用sum函数的时候无法找到准确的地址。而链接的作用就可以简单理解为帮助程序去找到外部符号的地址。
怎样找到外部符号的地址呢?
链接器通过符号表的合并和符号表的重定位做到这一点。
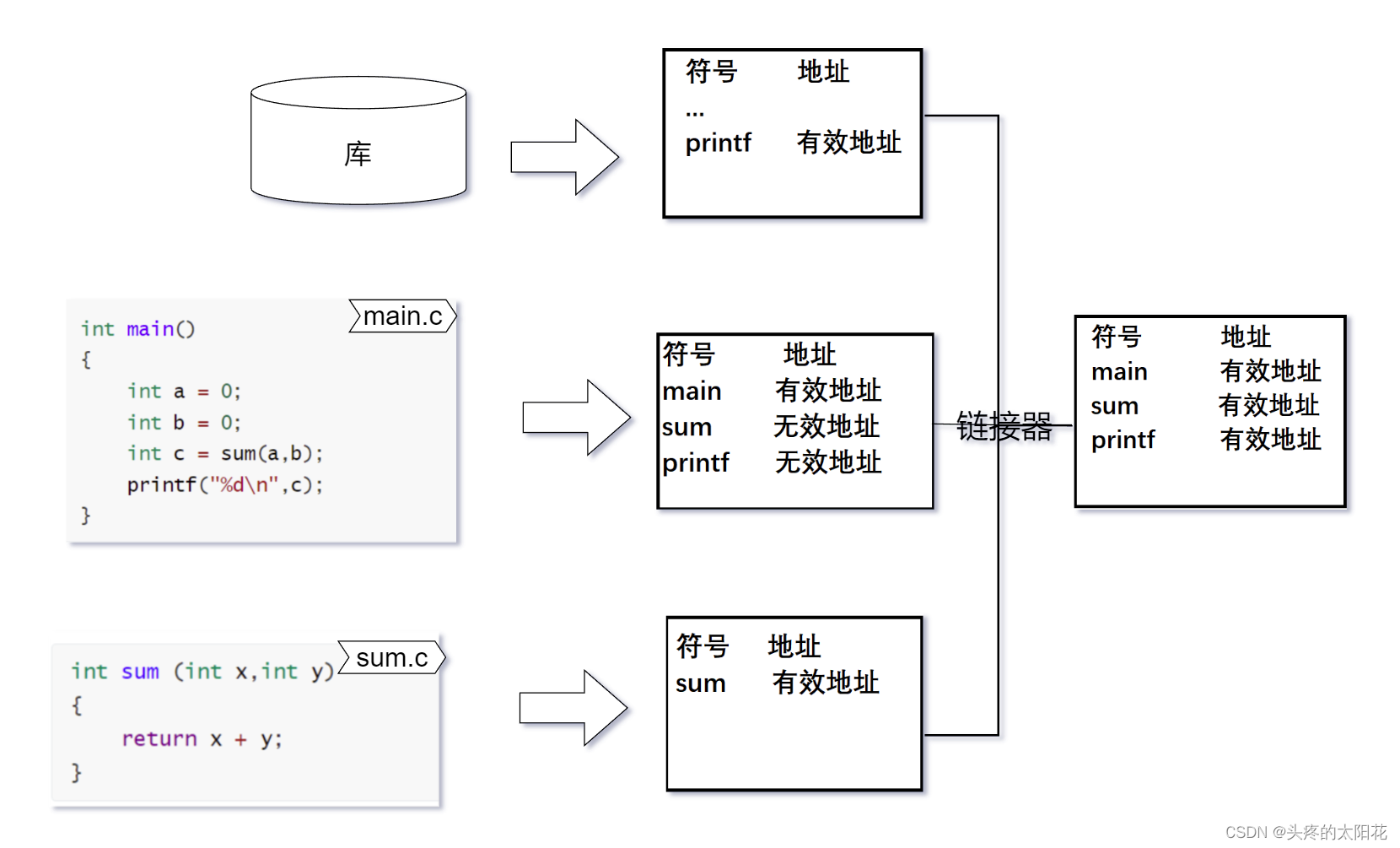
这样在调用外部符号的时候就可以找到准确的地址了。
注意:链接的过程是很复杂的:合并符号表只是其中的一部分。需要深入了解的话建议去查阅《程序员的自我修养——链接、装载与库》。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)