
数学一|概统|七、参数估计
考试要求
- 理解参数的点估计、估计量与估计值的概念;
- 掌握矩估计法(一阶矩、二阶矩)和最大似然估计法.
- 了解估计量的无偏性、有效性(最小方差性)和一致性(相合性)的概念,并会验证估计量的无偏性;
- 理解区间估计的概念,会求单个正态总体的均值和方差的置信区间,会求两个正态总体的均值差和方差比的置信区间;
1. 点估计
设总体
- 从总体
- 用上述估计量对
因为
1.1 最大似然估计(
1.1.1 似然函数
假设
-
当
-
当
当
1.1.2 最大似然估计
接下来我们将正式定义一个参数下的最大似然估计。直观上来说,最大似然估计的结果就是使得观测数据出现的概率最大的
假设
因为要求似然函数的最大值,而求最大值一般涉及到求极值,求极值的方法中又需要求导并且似然函数是连乘的可用对数法简化求导的过程,而且对数函数是单调递增的,所以在取对数后得到的
与未取对数前的得到的 相同
注意
下面是一个简单的例子。假设
-
首先构造似然函数,
-
然后求似然函数的最大值:求极值,确定极值点,将极值点和端点进行比较得到最大值。
为什么
求
- 构造似然函数或对数似然函数;
- 求使得似然函数达到最大值的参数;
- 有时还需要验证(但我们不考虑);
1.1.3 最大似然估计例子
例一、
-
构造似然函数,取对数,
-
求最大值点。求出可能的极值点然后和端点一起比较,得出最大值,
由泊松分布的图像可得,在其定义区间内,只存在一个极大值点,所以该点同时也为最大值点。
例二、
-
构造似然函数,取对数,
-
求最大值点。求出可能的极值点然后和端点一起比较,得出最大值,
例三、
-
构造似然函数,取对数。因为均匀分布的密度函数是分段函数,我们需要利用分段函数将其化简为一个表达式,
求最大值点。求出可能的极值点然后和端点一起比较,得出最大值。
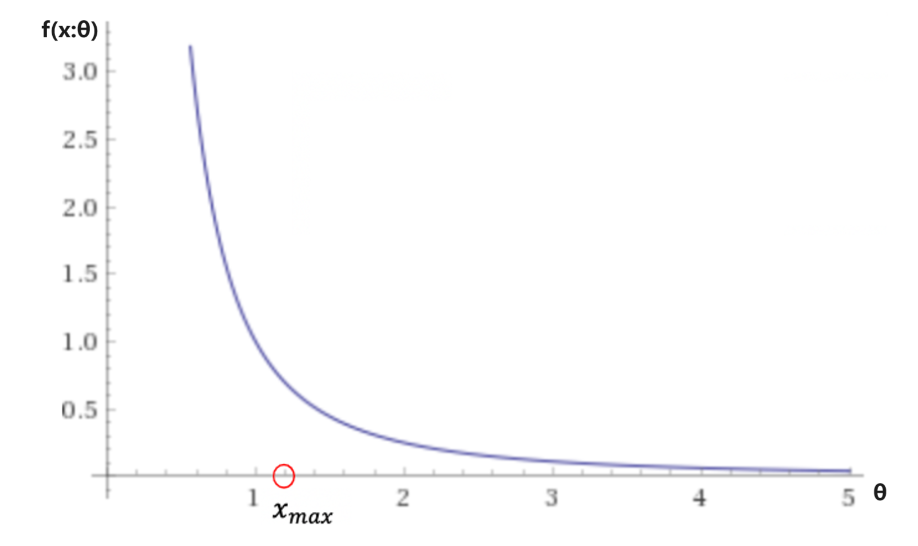 函数图像
函数图像从上面的图片可以得到,
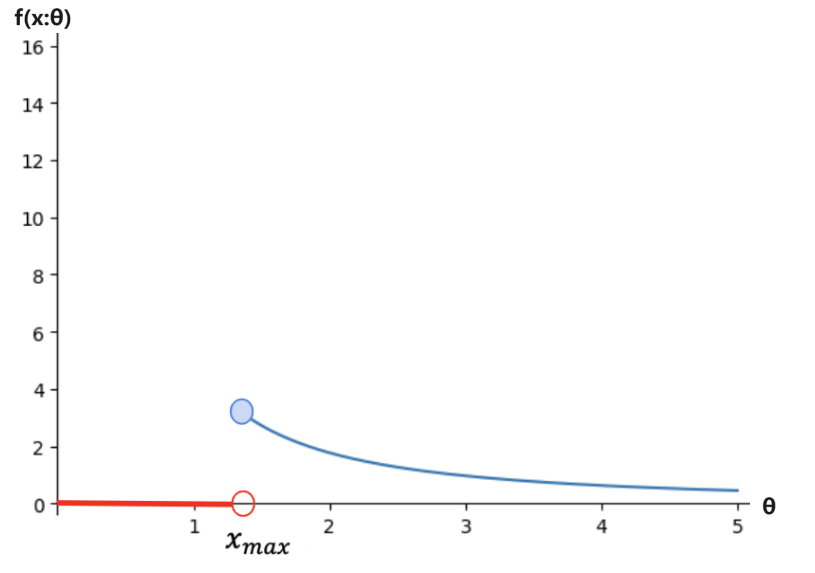 似然函数的图像
似然函数的图像所以
例三只是一个特殊的均匀分布的例子,因为均匀分布的范围一般由两个变量决定
1.2 矩估计(Method of Moments, MoM)
矩估计的基本思想是用样本矩估计总体矩。首先回顾一下矩的概念,然后引出样本矩。
接下来定义样本矩,
考试中的矩估计一般只会用到一阶或二阶
1.2.1 矩估计思想
假设我们只需要估计一个参数

联想一下之前学的大数定理可以发现上面的结果显然正确。
当有两个参数的时候该如何解决?令一阶真实矩等于一阶样本矩(就像我们上面做的那样),再令二阶真实矩等于二阶样本矩然后解方程,解得的结果记得加帽子,表示这是一个估计量。当我们有


了解矩估计的思想,会解题即可,一个参数的矩估计可用大数定理证明,两个及
个参数的矩估计都可以用大数定理进行证明,应该可以用归纳法进行证明
1.3 估计量的评选标准
-
无偏性:若
-
有效性:设
-
一致性(相合性):设
无偏性和有效性是在样本容量
固定的前提下,对 的优劣评判,当样本容量无限增大时,估计量越来越接要估计的未知参数的真值,这就是估计量的一致性
2. 区间估计
置信区间是经典统计下的区间估计;可信区间是贝叶斯统计下的区间估计。
2.1 置信区间
2.1.1 置信区间引入
由点估计
下述是这个区间三种等价的描述方法:
特别注意第一个和第三个(交换了
2.1.2 置信区间
置信区间定义:假设有一个带未知参数
如何理解置信区间——以
错误理解:
正确理解:如果我们多次重复这个过程(每次得到
2.2 单个正态总体的均值和方差的置信区间
设
2.2.1 正态总体
由
对其进行标准化,
令
2.2.2 正态总体
2.2.3 正态总体
由
注:卡方分布不是对称的,但是由于习惯,在选择上侧分位数的时候仍然使用
2.2.4 正态总体
当
简单理解记忆:用
代替 ,使新的枢轴变量中多出一个约束(方程)。联系线性方程组的知识点,多一个方程就少一个自由未知量,因此自由度就比下面的少1。
联想样本方差,对
2.3 两个正态总体的均值差和方差比的置信区间
设
相互独立。
2.3.1 均值差
- 当
由此可转换为单个正态总体当
此处
-
当
-
当
因为
引入
若
利用上式构造
其中
个人理解:
-
其余情况现阶段不需要考虑;
2.3.2 方差比
注意:与


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通