
一.
re模块的使⽤过程
#coding=utf-8
# 导⼊re模块
import re
# 使⽤match⽅法进⾏匹配操作
result = re.match(正则表达式,要匹配的字符串)
# 如果上⼀步匹配到数据的话,可以使⽤group⽅法来提取数据
result.group()
二.
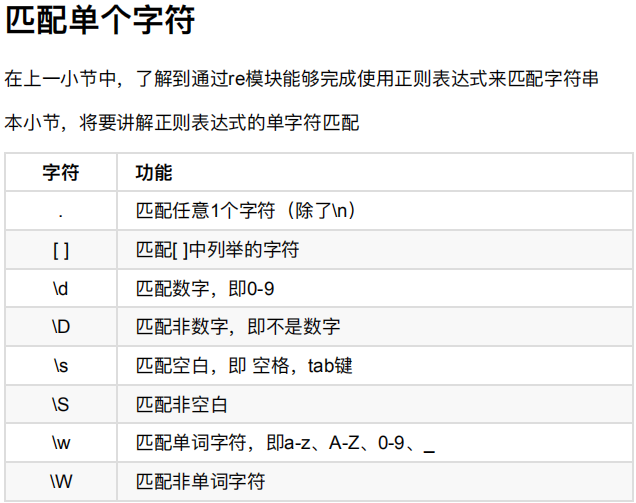
三.

示例1*
需求:匹配出,⼀个字符串第⼀个字⺟为⼤⼩字符,后⾯都是⼩写字⺟并且 这些⼩写字⺟ 可有可无
1 #coding=utf-8
2 import re
3 ret = re.match("[A-Z][a-z]*","M")
4 print(ret.group())
5 ret = re.match("[A-Z][a-z]*","MnnM")
6 print(ret.group())
7 ret = re.match("[A-Z][a-z]*","Aabcdef")
8 print(ret.group())
9 运⾏结果:
10 M
11 python⾼级
12 匹配多个字符 14
13 Mnn
14 Aabcdef
示例2:+
需求:匹配出,变量名是否有效
1 #coding=utf-8
2 import re
3 names = ["name1", "_name", "2_name", "__name__"]
4 for name in names:
5 ret = re.match("[a-zA-Z_]+[\w]*",name)
6 if ret:
7 print("变量名 %s 符合要求" % ret.group())
8 else:
9 print("变量名 %s ⾮法" % name)
10
11 运⾏结果:
12 变量名 name1 符合要求
13 变量名 _name 符合要求
14 变量名 2_name ⾮法
15 变量名 __name__ 符合要求
示例3:?
需求:匹配出,0到99之间的数字
1 #coding=utf-8
2 import re
3 ret = re.match("[1-9]?[0-9]","7")
4 python⾼级
5 匹配多个字符 15
6 print(ret.group())
7 ret = re.match("[1-9]?\d","33")
8 print(ret.group())
9 ret = re.match("[1-9]?\d","09")
10 print(ret.group())
11
12 运⾏结果:
13 7
14 33
15 0 # 这个结果并不是想要的,利⽤$才能解决
示例4:
{m} 需求:匹配出,8到20位的密码,可以是⼤⼩写英⽂字⺟、数字、下划线
1 #coding=utf-8
2 import re
3 ret = re.match("[a-zA-Z0-9_]{6}","12a3g45678")
4 print(ret.group())
5 ret = re.match("[a-zA-Z0-9_]{8,20}","1ad12f23s34455ff66")
6 print(ret.group())
7
8 运⾏结果:
9 12a3g4
10 1ad12f23s34455ff66
四.

示例1:匹配出163的邮箱地址,且@符号之前有4到 20位,例如hello@163.com
1 #coding=utf-8
2 import re
3 email_list = ["xiaoWang@163.com", "xiaoWang@163.comheihei",]
4 for email in email_list:
5 ret = re.match("[\w]{4,20}@163\.com$", email)
6 if ret:
7 print("%s 是符合规定的邮件地址,匹配后的结果是:%s" % (email, ret.group()))
8 else:
9 print("%s 不符合要求" % email)
10
11
12 运⾏结果:
13 xiaoWang@163.com 是符合规定的邮件地址,匹配后的结果是:xiaoWang@163.com
14 xiaoWang@163.comheihei 是符合规定的邮件地址,匹配后的结果是:xiaoWang@163.co.com.xiaowang@qq.com 不符合要求
五.
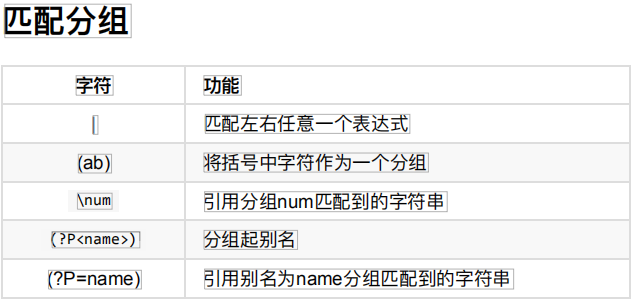
示例1:|
需求:匹配出0-100之间的数字
1 #coding=utf-8
2 import re
3 ret = re.match("[1-9]?\d","8")
4 print(ret.group()) # 8
5 ret = re.match("[1-9]?\d","78")
6 print(ret.group()) # 78
7 # 不正确的情况
8 ret = re.match("[1-9]?\d","08")
9 print(ret.group()) # 0
10 # 修正之后的
11 ret = re.match("[1-9]?\d$","08")
12 if ret:
13 print(ret.group())
14 else:
15 print("不在0-100之间")
16 # 添加|
17 ret = re.match("[1-9]?\d$|100","8")
18 print(ret.group()) # ret = re.match("[1-9]?\d$|100","78")
19 print(ret.group()) # 78
20 ret = re.match("[1-9]?\d$|100","08")
21 # print(ret.group()) # 不是0-100之间
22 ret = re.match("[1-9]?\d$|100","100")
23 print(ret.group()) # 100
示例2:
不是以4、7结尾的⼿机号码(11位)
1 import re
2 tels = ["13100001234", "18912344321", "10086", "18800007777"]
3 for tel in tels:
4 ret = re.match("1\d{9}[0-35-68-9]", tel)
5 if ret:
6 print(ret.group())
7 else:
8 print("%s 不是想要的⼿机号" % tel)
提取区号和电话号码
1 >>> ret = re.match("([^-]*)-(\d+)","010-12345678") #[^-]的意思是非-
2 >>> ret.group()
3 '010-12345678'
4 >>> ret.group(1)
5 '010'
6 >>> ret.group(2)
7 '12345678'
示例3:\
需求:匹配出 <html>hh</html>
1 #coding=utf-8
2 import re
3 # 能够完成对正确的字符串的匹配
4 ret = re.match("<[a-zA-Z]*>\w*</[a-zA-Z]*>", "<html>hh</html>")
5 print(ret.group())
6 # 如果遇到⾮正常的html格式字符串,匹配出错
7 ret = re.match("<[a-zA-Z]*>\w*</[a-zA-Z]*>", "<html>hh</htmlbalabala>")
8 print(ret.group())
9 # 正确的理解思路:如果在第⼀对<>中是什么,按理说在后⾯的那对<>中就应该是什么
10 # 通过引⽤分组中匹配到的数据即可,但是要注意是元字符串,即类似 r""这种格式
11 ret = re.match(r"<([a-zA-Z]*)>\w*</\1>", "<html>hh</html>")
12 print(ret.group())
13 # 因为2对<>中的数据不⼀致,所以没有匹配出来
14 test_label = "<html>hh</htmlbalabala>"
15 ret = re.match(r"<([a-zA-Z]*)>\w*</\1>", test_label)
16 if ret:
17 print(ret.group())
18 else:
19 print("%s 这是⼀对不正确的标签" % test_label)
20
21 运⾏结果:
22 <html>hh</html>
23 <html>hh</htmlbalabala>
24 <html>hh</html>
25 <html>hh</htmlbalabala> 这是⼀对不正确的标签
示例4:\number
需求:匹配出<html><h1>www.itcast.cn</h1></html>
1 #coding=utf-8
2 import re
3 labels = ["<html><h1>www.itcast.cn</h1></html>",<html><h1>www.itcast.cn</h2></html>"]
4 for label in labels:
5 ret = re.match(r"<(\w*)><(\w*)>.*</\2></\1>", label)
6 if ret:
7 print("%s 是符合要求的标签" % ret.group())
8 else:
9 print("%s 不符合要求" % label)
10
11 运⾏结果:
12 <html><h1>www.itcast.cn</h1></html> 是符合要求的标签
13 <html><h1>www.itcast.cn</h2></html> 不符合要求
示例5.(?P<name>) (?P=name)
需求:匹配出<html><h1>www.itcast.cn</h1></html>
1 #coding=utf-8
2 import re
3 ret = re.match(r"<(?P<name1>\w*)><(?P<name2>\w*)>.*</(?P=name2)></(?P=name1)>","<html><h1>www.itcast.cn</h1></html>")
4 ret.group()
5 ret = re.match(r"<(?P<name1>\w*)><(?P<name2>\w*)>.*</(?P=name2)></(?P=name1)>","<html><h1>www.itcast.cn</h1></html>")
6 ret.group()
六.re模块的⾼级⽤法
div>
search 需求:匹配出⽂章阅读的次数
search会从左往右依次寻找,直到不满足
1 #coding=utf-8
2 import re
3 ret = re.search(r"\d+", "阅读次数为 9999")
4 ret.group()
5
6 运⾏结果:
7 '9999'
findall
需求:统计出python、c、c++相应⽂章阅读的次数
findall 全部查找,返回列表
1 #coding=utf-8
2 import re
3 ret = re.findall(r"\d+", "python = 9999, c = 7890, c++ = 12345")
4 print(ret)
5
6 运⾏结果:
7 ['9999', '7890', '12345'
sub 将匹配到的数据进⾏替换 需求:将匹配到的阅读次数加1
相当于替换,注意格式
1 ⽅法1:
2 #coding=utf-8
3 import re
4 ret = re.sub(r"\d+", '998', "python = 997")
5 print(ret)
6
7 运⾏结果:
8 python = 998
9
10 ⽅法2:
11 #coding=utf-8
12 import re
13 def add(temp):
14 strNum = temp.group()
15 num = int(strNum) + 1
16 return str(num)
17 ret = re.sub(r"\d+", add, "python = 997")
18 print(ret)
19 ret = re.sub(r"\d+", add, "python = 99")
20 print(ret)
21
22 运⾏结果:
23 python = 998
24 python = 100
练习
练习1.从下⾯的字符串中取出⽂本
<div>
<p>岗位职责:</p>
<p>完成推荐算法、数据统计、接⼝、后台等服务器端相关⼯作</p>
<p><br></p>
<p>必备要求:</p>
<p>良好的⾃我驱动⼒和职业素养,⼯作积极主动、结果导向</p>
<p> <br></p>
<p>技术要求:</p>
<p>1、⼀年以上 Python 开发经验,掌握⾯向对象分析和设计,了解设计模式</p>
<p>2、掌握HTTP协议,熟悉MVC、MVVM等概念以及相关WEB开发框架</p>
<p>3、掌握关系数据库开发设计,掌握 SQL,熟练使⽤ MySQL/PostgreSQL 中的⼀种
<p>4、掌握NoSQL、MQ,熟练使⽤对应技术解决⽅案</p>
<p>5、熟悉 Javascript/CSS/HTML5,JQuery、React、Vue.js</p>
<p> <br></p>
<p>加分项:</p>
<p>⼤数据,数理统计,机器学习,sklearn,⾼性能,⼤并发。</p>
</div>
参考答案:
re.sub(r"<[^>]*>| |\n", "", test_str)
练习2.split 根据匹配进⾏切割字符串,并返回⼀个列表
需求:切割字符串“info:xiaoZhang 33 shandong”
#coding=utf-8
import re
ret = re.split(r":| ","info:xiaoZhang 33 shandong")
print(ret)
运⾏结果:
['info', 'xiaoZhang', '33', 'shandong']
python贪婪和⾮贪婪
Python⾥数量词默认是贪婪的(在少数语⾔⾥也可能是默认⾮贪婪),总是 尝试匹配尽可能多的字符;
⾮贪婪则相反,总是尝试匹配尽可能少的字符。 在"*","?","+","{m,n}"后⾯加上?,使贪婪变成⾮贪婪
注意:是在数量词后面加?变成非贪婪
?两种作用
^两种作用
.不能匹配\n 如需匹配要加re.DOTALL
Python中字符串前⾯加上 r 表示原⽣字符串
Do your best & enjoy your life

 浙公网安备 33010602011771号
浙公网安备 33010602011771号