1 优化思路
作为架构师或者开发人员,说到数据库性能优化,你的思路是什么样的?或者具体一点,如果在面试的时候遇到这个问题:你会从哪些维度来优化数据库,你会怎么回答?
大部分时候想要实现的目标是让我们的查询更快。一个查询的动作又是由很多个环节组成的,每个环节都会消耗时间,我们要减少查询所消耗的时间,就要从每一个环节入手。
![]()
2 连接——配置优化
第一个环节是客户端连接到服务端,连接这一块有可能会出现什么样的性能问题?
有可能是服务端连接数不够导致应用程序获取不到连接。比如报了一个 Mysql: error
1040: Too many connections 的错误。
我们可以从两个方面来解决连接数不够的问题:
1、从服务端来说,我们可以增加服务端的可用连接数。
如果有多个应用或者很多请求同时访问数据库,连接数不够的时候,我们可以:
(1)修改配置参数增加可用连接数,修改max_connections的大小:
showvariableslike 'max_connections'; -- 修改最大连接数,当有多个应用连接的时候
(2)或者,或者及时释放不活动的连接。交互式和非交互式的客户端的默认超时时
间都是28800秒,8小时,我们可以把这个值调小。
showglobalvariableslike 'wait_timeout'; --及时释放不活动的连接,注意不要释放连接池还在使用的连接
2、从客户端来说,可以减少从服务端获取的连接数,如果我们想要不是每一次执行
SQL都创建一个新的连接,应该怎么做?
这个时候我们可以引入连接池,实现连接的重用。我们可以在哪些层面使用连接池?ORM层面(MyBatis自带了一个连接池);或者使用专用的连接池工具(阿里的Druid、Spring Boot 2.x版本默认的连接池Hikari、老
牌的DBCP和C3P0)。
当客户端改成从连接池获取连接之后,连接池的大小应该怎么设置呢?大家可能会有一个误解,觉得连接池的最大连接数越大越好,这样在高并发的情况下客户端可以获
取的连接数更多,不需要排队。实际情况并不是这样。连接池并不是越大越好,只要维护一定数量大小的连接池,其他的客户端排队等待获取连接就可以了。有的时候连接池越大,效率反而越低。
Druid的默认最大连接池大小是8。Hikari的默认最大连接池大小是10。
为什么默认值都是这么小呢?在Hikari的github文档中,给出了一个PostgreSQL数据库建议的设置连接池大小的公式: https://github.com/brettwooldridge/HikariCP/wiki/About-Pool-Sizing 它的建议是机器核数乘以2加1。也就是说,4 核的机器,连接池维护9个连接就
够了。这个公式从一定程度上来说对其他数据库也是适用的。这里面还有一个减少连接池大小实现提升并发度和吞吐量的案例。为什么有的情况下,减少连接数反而会提升吞吐量呢?为什么建议设置的连接池大
小要跟CPU的核数相关呢?每一个连接,服务端都需要创建一个线程去处理它。连接数越多,服务端创建的线程数就会越多。
问题:CPU是怎么同时执行远远超过它的核数大小的任务的?时间片。上下文切换。而CPU的核数是有限的,频繁的上下文切换会造成比较大的性能开销。
3 缓存——架构优化
3.1 缓存
在应用系统的并发数非常大的情况下,如果没有缓存,会造成两个问题:一方面是会给数据库带来很大的压力。另一方面,从应用的层面来说,操作数据的速度也会受到
影响。
我们可以用第三方的缓存服务来解决这个问题,例如Redis。
![]()
运行独立的缓存服务,属于架构层面的优化。为了减少单台数据库服务器的读写压力,在架构层面我们还可以做其他哪些优化措施?
3.2 主从复制
如果单台数据库服务满足不了访问需求,那我们可以做数据库的集群方案。
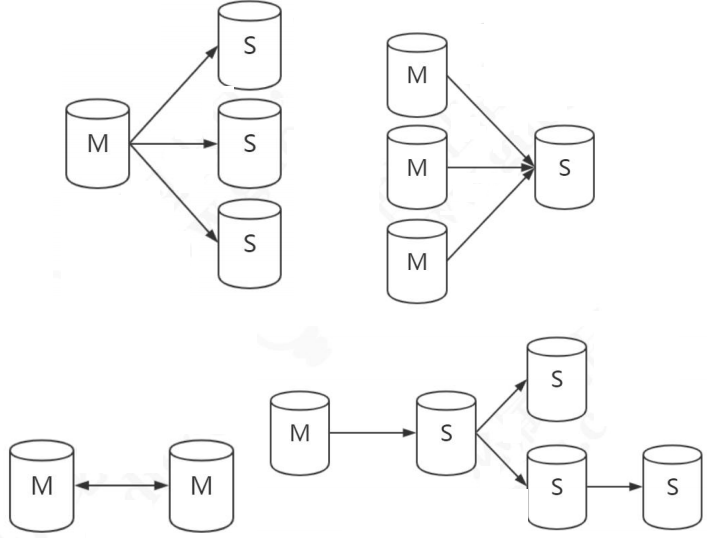
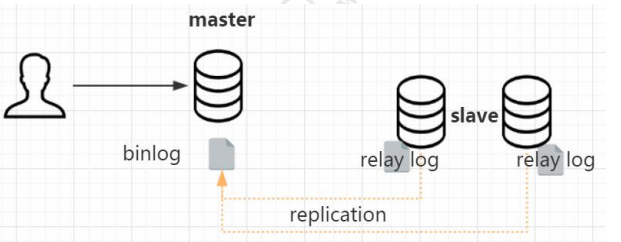
集群的话必然会面临一个问题,就是不同的节点之间数据一致性的问题。如果同时读写多台数据库节点,怎么让所有的节点数据保持一致?这个时候我们需要用到复制技术(replication),被复制的节点称为 master,复制的节点称为 slave。slave 本身也可以作为其他节点的数据来源,这个叫做级联复制。
![]()
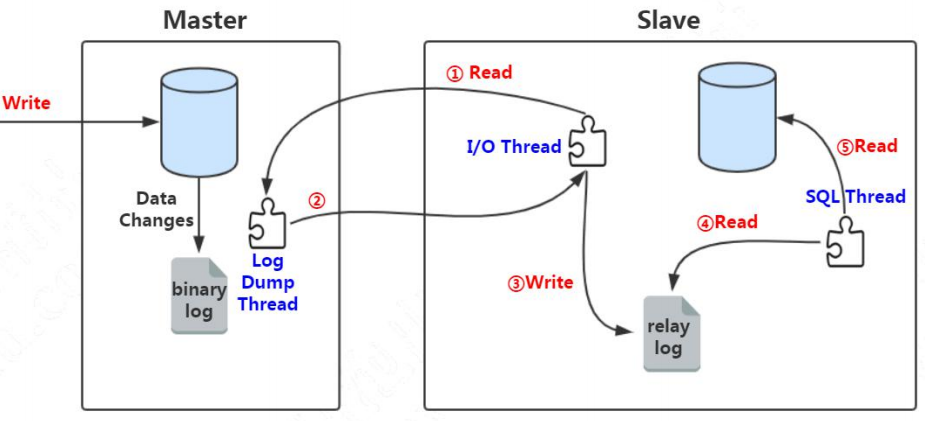
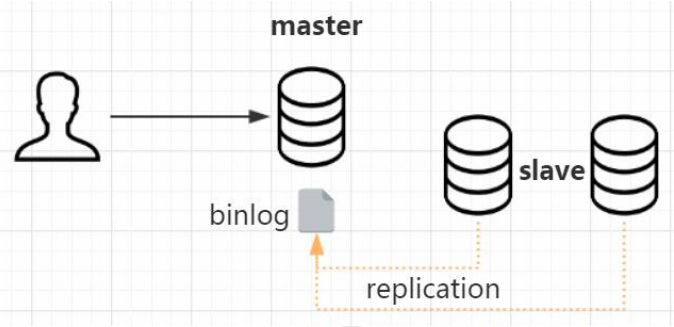
主从复制是怎么实现的呢?更新语句会记录 binlog,它是一种逻辑日志。有了这个 binlog,从服务器会获取主服务器的 binlog 文件,然后解析里面的 SQL语句,在从服务器上面执行一遍,保持主从的数据一致。
这里面涉及到三个线程,连接到 master 获取 binlog,并且解析 binlog 写入中继日志,这个线程叫做 I/O 线程。Master 节点上有一个 log dump 线程,是用来发送 binlog 给 slave 的。从库的 SQL 线程,是用来读取 relay log,把数据写入到数据库的。
![]()
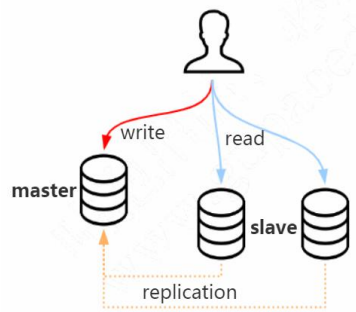
做了主从复制的方案之后,我们只把数据写入 master 节点,而读的请求可以分担到slave 节点。我们把这种方案叫做读写分离。
![]()
读写分离可以一定程度低减轻数据库服务器的访问压力,但是需要特别注意主从数据一致性的问题。如果我们在 master 写入了,马上到 slave 查询,而这个时候 slave 的
数据还没有同步过来,怎么办?
所以,基于主从复制的原理,我们需要弄明白,主从复制到底慢在哪里?
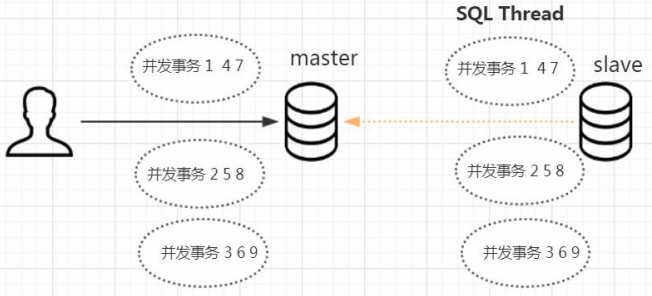
3.2.1 单线程
在早期的 MySQL 中,slave 的 SQL 线程是单线程。master 可以支持 SQL 语句的并行执行,配置了多少的最大连接数就是最多同时多少个 SQL 并行执行。而 slave 的 SQL 却只能单线程排队执行,在主库并发量很大的情况下,同步数据肯
定会出现延迟。
为什么从库上的 SQL Thread 不能并行执行呢?举个例子,主库执行了多条 SQL 语句,首先用户发表了一条评论,然后修改了内容,最后把这条评论删除了。这三条语句在从库上的执行顺序肯定是不能颠倒的。
insert into user_comments (10000009,'nice');
update user_comments set content ='very good' where id =10000009;
delete from user_comments where id =10000009;
怎么解决这个问题呢?怎么减少主从复制的延迟?
3.2.2 异步与全同步
首先我们需要知道,在主从复制的过程中,MySQL 默认是异步复制的。也就是说,对于主节点来说,写入 binlog,事务结束,就返回给客户端了。对于 slave 来说,接收到 binlog,就完事儿了,master 不关心 slave 的数据有没有写入成功。
![]()
如果要减少延迟,是不是可以等待全部从库的事务执行完毕,才返回给客户端呢?这样的方式叫做全同步复制。从库写完数据,主库才返会给客户端。
这种方式虽然可以保证在读之前,数据已经同步成功了,但是带来的副作用大家应该能想到,事务执行的时间会变长,它会导致 master 节点性能下降。
有没有更好的办法呢?既减少 slave 写入的延迟,又不会明显增加 master 返回给客户端的时间?
3.2.3 半同步复制
介于异步复制和全同步复制之间,还有一种半同步复制的方式。
半同步复制是什么样的呢?
主库在执行完客户端提交的事务后不是立刻返回给客户端,而是等待至少一个从库接收到 binlog 并写到 relay log 中才返回给客户端。master 不会等待很长的时间,但是
返回给客户端的时候,数据就即将写入成功了,因为它只剩最后一步了:就是读取 relay log,写入从库。
![]()
如果我们要在数据库里面用半同步复制,必须安装一个插件,这个是谷歌的一位工程师贡献的。这个插件在 mysql 的插件目录下已经有提供:
cd /usr/lib64/mysql/plugin/
主库和从库是不同的插件,安装之后需要启用:
-- 主库执行
INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
set global rpl_semi_sync_master_enabled=1;
show variables like '%semi_sync%';
-- 从库执行
INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
set global rpl_semi_sync_slave_enabled=1;
show global variables like '%semi%';
相对于异步复制,半同步复制提高了数据的安全性,同时它也造成了一定程度的延迟,它需要等待一个 slave 写入中继日志,这里多了一个网络交互的过程,所以,半同步
复制最好在低延时的网络中使用。
这个是从主库和从库连接的角度,来保证 slave 数据的写入。
另一个思路,如果要减少主从同步的延迟,减少 SQL 执行造成的等待的时间,那有没有办法在从库上,让多个 SQL 语句可以并行执行,而不是排队执行呢?
3.2.5 异步复制之 GTID 复制
https://dev.mysql.com/doc/refman/5.7/en/replication-gtids.html
所以,我们可以把那些在主库上并行执行的事务,分为一个组,并且给他们编号,这一个组的事务在从库上面也可以并行执行。这个编号,我们把它叫做 GTID(Global
Transaction Identifiers),这种主从复制的方式,我们把它叫做基于 GTID 的复制。
如果我们要使用 GTID 复制,我们可以通过修改配置参数打开它,默认是关闭的:
show global variables like 'gtid_mode';
无论是优化 master 和 slave 的连接方式,还是让从库可以并行执行 SQL,都是从数据库的层面去解决主从复制延迟的问题。
除了数据库本身的层面之外,在应用层面,我们也有一些减少主从同步延迟的方法。
我们在做了主从复制之后,如果单个 master 节点或者单张表存储的数据过大的时候,比如一张表有上亿的数据,单表的查询性能还是会下降,我们要进一步对单台数据
库节点的数据分型拆分,这个就是分库分表。
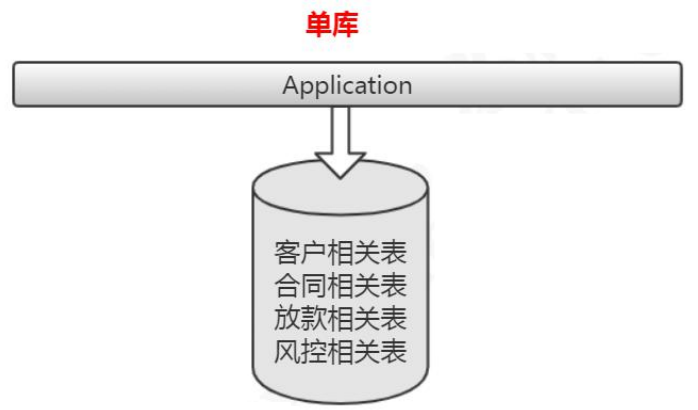
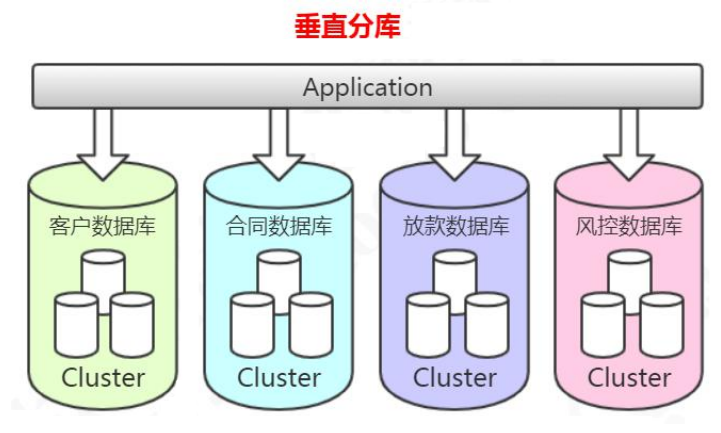
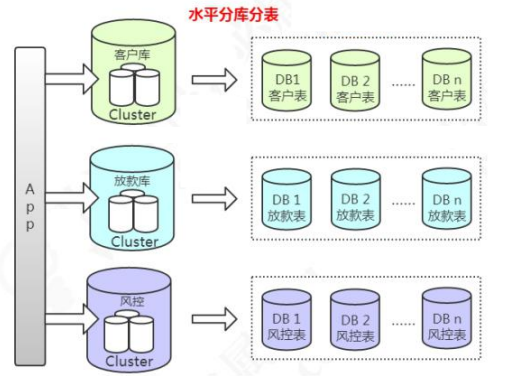
3.3 分库分表
垂直分库,减少并发压力。水平分表,解决存储瓶颈。
垂直分库的做法,把一个数据库按照业务拆分成不同的数据库:
![]()
![]()
水平分库分表的做法,把单张表的数据按照一定的规则分布到多个数据库。
![]()
通过主从或者分库分表可以减少单个数据库节点的访问压力和存储压力,达到提升数据库性能的目的,但是如果 master 节点挂了,怎么办?
所以,高可用(High Available)也是高性能的基础。
3.4 高可用方案
https://dev.mysql.com/doc/mysql-ha-scalability/en/ha-overview.html
3.4.1 主从复制
传统的 HAProxy + keepalived 的方案,基于主从复制。
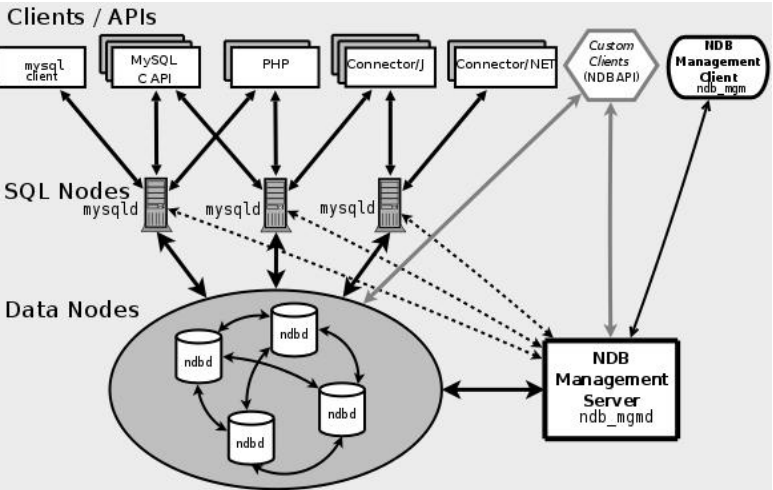
3.4.2 NDB Cluster
https://dev.mysql.com/doc/mysql-cluster-excerpt/5.7/en/mysql-cluster-overview.html
基于 NDB 集群存储引擎的 MySQL Cluster。
![]()
4 优化器——SQL 语句分析与优化
优化器就是对我们的 SQL 语句进行分析,生成执行计划。
我们的服务层每天执行了这么多 SQL 语句,它怎么知道哪些 SQL 语句比较慢呢?
第一步,我们要把 SQL 执行情况记录下来。
4.1 EXPLAIN 执行计划
我们先创建三张表。一张课程表,一张老师表,一张老师联系方式表(没有任何索引)。
DROP TABLE
IF EXISTS course;
CREATE TABLE `course` (
`cid` INT (3) DEFAULT NULL,
`cname` VARCHAR (20) DEFAULT NULL,
`tid` INT (3) DEFAULT NULL
) ENGINE = INNODB DEFAULT CHARSET = utf8mb4;
DROP TABLE
IF EXISTS teacher;
CREATE TABLE `teacher` (
`tid` INT (3) DEFAULT NULL,
`tname` VARCHAR (20) DEFAULT NULL,
`tcid` INT (3) DEFAULT NULL
) ENGINE = INNODB DEFAULT CHARSET = utf8mb4;
DROP TABLE
IF EXISTS teacher_contact;
CREATE TABLE `teacher_contact` (
`tcid` INT (3) DEFAULT NULL,
`phone` VARCHAR (200) DEFAULT NULL
) ENGINE = INNODB DEFAULT CHARSET = utf8mb4;
INSERT INTO `course`
VALUES
('1', 'mysql', '1');
INSERT INTO `course`
VALUES
('2', 'jvm', '1');
INSERT INTO `course`
VALUES
('3', 'juc', '2');
INSERT INTO `course`
VALUES
('4', 'spring', '3');
INSERT INTO `teacher`
VALUES
('1', 'qingshan', '1');
INSERT INTO `teacher`
VALUES
('2', 'jack', '2');
INSERT INTO `teacher`
VALUES
('3', 'mic', '3');
INSERT INTO `teacher_contact`
VALUES
('1', '13688888888');
INSERT INTO `teacher_contact`
VALUES
('2', '18166669999');
INSERT INTO `teacher_contact`
VALUES
('3', '17722225555');
explain 的结果有很多的字段,我们详细地分析一下。
4.3.1 id
id 是查询序列编号。
id 值不同
id 值不同的时候,先查询 id 值大的(先大后小)。
-- 查询 mysql 课程的老师手机号
EXPLAIN SELECT
tc.phone
FROM
teacher_contact tc
WHERE
tcid = (
SELECT
tcid
FROM
teacher t
WHERE
t.tid = (
SELECT
c.tid
FROM
course c
WHERE
c.cname = 'mysql'
)
);
查询顺序:course c——teacher t——teacher_contact tc。
![]()
先查课程表,再查老师表,最后查老师联系方式表。子查询只能以这种方式进行,只有拿到内层的结果之后才能进行外层的查询。
id 值相同
-- 查询课程 ID 为 2,或者联系表 ID 为 3 的老师
EXPLAIN SELECT
t.tname,
c.cname,
tc.phone
FROM
teacher t,
course c,
teacher_contact tc
WHERE
t.tid = c.tid
AND t.tcid = tc.tcid
AND (c.cid = 2 OR tc.tcid = 3);
![]()
id 值相同时,表的查询顺序是从上往下顺序执行。例如这次查询的 id 都是 1,查询的顺序是 teacher t(3 条)——course c(4 条)——teacher_contact tc(3 条)。
4.3.2 select type 查询类型
SIMPLE
简单查询,不包含子查询,不包含关联查询 union。
PRIMARY
子查询 SQL 语句中的主查询,也就是最外面的那层查询。
SUBQUERY
子查询中所有的内层查询都是 SUBQUERY 类型的。
4.3.3 type 连接类型
https://dev.mysql.com/doc/refman/5.7/en/explain-output.html#explain-join-types
所有的连接类型中,上面的最好,越往下越差。
在常用的链接类型中:system > const > eq_ref > ref > range > index > all这 里 并 没 有 列 举 全 部 ( 其 他 : fulltext 、 ref_or_null 、 index_merger 、
unique_subquery、index_subquery)。
以上访问类型除了 all,都能用到索引。
4.3.4 possible_key、key
可能用到的索引和实际用到的索引。如果是 NULL 就代表没有用到索引。
possible_key 可以有一个或者多个,可能用到索引不代表一定用到索引。
反过来,possible_key 为空,key 可能有值吗?
4.3.5 key_len
索引的长度(使用的字节数)。跟索引字段的类型、长度有关。
4.3.6 rows
MySQL 认为扫描多少行才能返回请求的数据,是一个预估值。一般来说行数越少越
好。
4.3.7 filtered
这个字段表示存储引擎返回的数据在 server 层过滤后,剩下多少满足查询的记录数
量的比例,它是一个百分比。
4.3.8 ref
使用哪个列或者常数和索引一起从表中筛选数据。
4.3.9 Extra
执行计划给出的额外的信息说明。







 浙公网安备 33010602011771号
浙公网安备 33010602011771号