

MySQL索引的原理及使用
前言:
上篇文章中学习了MySQL库的架构以及存储引擎,了解了基本索引(普通索引,唯一索引,主键索引),着重介绍了innerDB的存储方式以及内存模型,本篇文章和大家探讨一下MySQL库中索引的原理以及索引底层的数据结构。
1. 索引是什么
1.1. 索引的定义
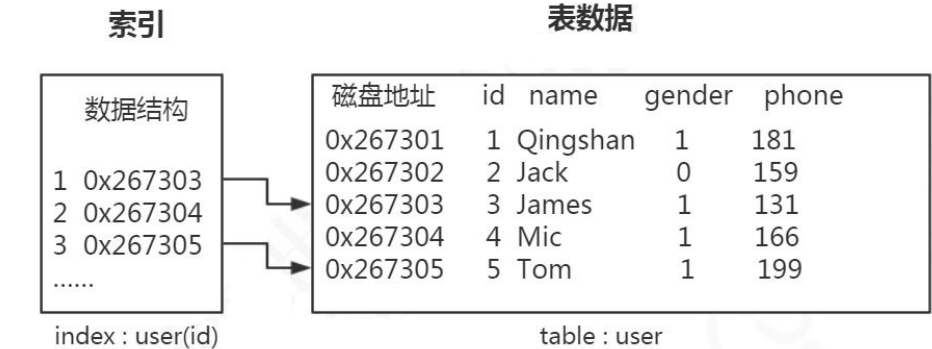
首先数据是以文件的形式存放在磁盘上面的,每一行数据都有它的磁盘地址。如果没有索引的话,要从 500 万行数据里面检索一条数据,只能依次遍历这张表的全部数据,直到找到这条数据。但是有了索引之后,只需要在索引里面去检索这条数据就行了,因为它是一种特殊的专门用来快速检索的数据结构,我们找到数据存放的磁盘地址以后,就可以拿到数据了。
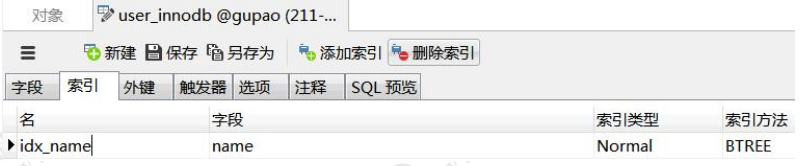
1.2.索引类型
如何创建一个索引?
2. 索引存储模型推演
2.1. 二分查找
2.2. 二叉查找树(BST Binary Search Tree)
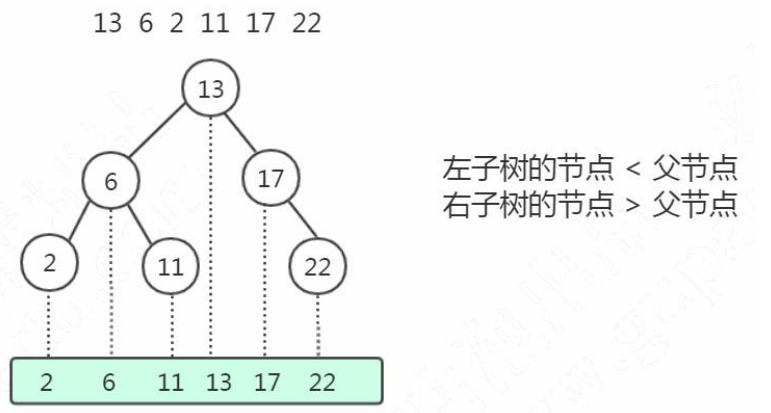
二叉查找树既能够实现快速查找,又能够实现快速插入。
但是二叉查找树有一个问题:
就是它的查找耗时是和这棵树的深度相关的,在最坏的情况下时间复杂度会退化成O(n)。

2.3. 平衡二叉树(AVL Tree)(左旋、右旋)
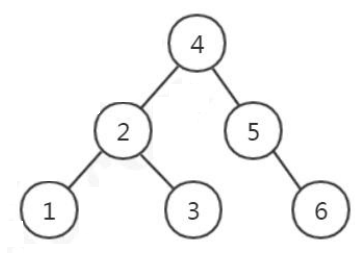
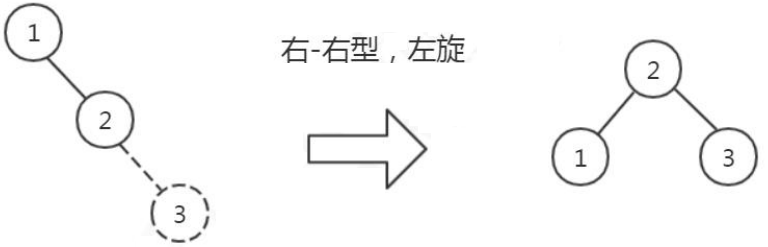

如果是这样存储数据的话,我们来看一下会有什么问题。在分析用 AVL 树存储索引数据之前,我们先来学习一下 InnoDB 的逻辑存储结构。
2.3.1.InnoDB 逻辑存储结构
官网:
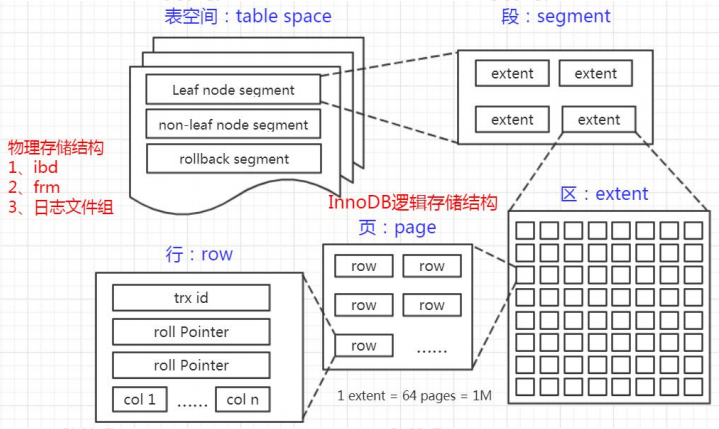
表空间 Table Space
段 Segment
簇 Extent
一个段(Segment)又由很多的簇(也可以叫区)组成,每个区的大小是 1MB(64个连续的页)。每一个段至少会有一个簇,一个段所管理的空间大小是无限的,可以一直扩展下去,但是扩展的最小单位就是簇。
页 Page

假设一行数据大小是 1K,那么一个数据页可以放 16 行这样的数据。举例:一个页放 3 行数据

如果数据不是连续的,往已经写满的页中插入数据,会导致叶页面分裂:
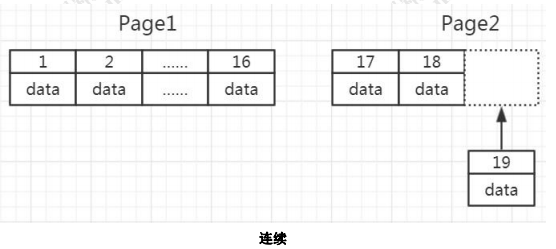
![]() 行 Row
行 Row
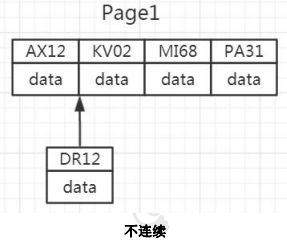 行 Row
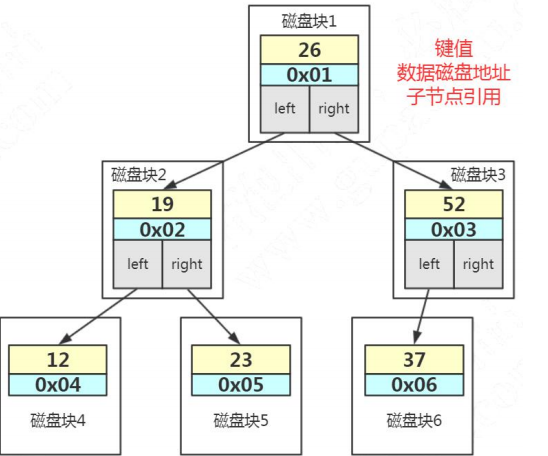
行 Row2.3.2.AVL 树用于存储索引数据
select CONCAT(ROUND(SUM(DATA_LENGTH/1024/1024),2),'MB') AS data_len, CONCAT(ROUND(SUM(INDEX_LENGTH/1024/1024),2),'MB') as index_len from information_schema.TABLES where table_schema='gupao' and table_name='user_innodb';
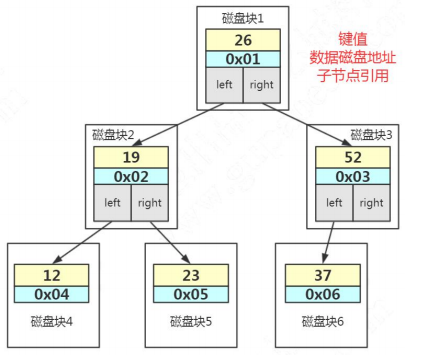
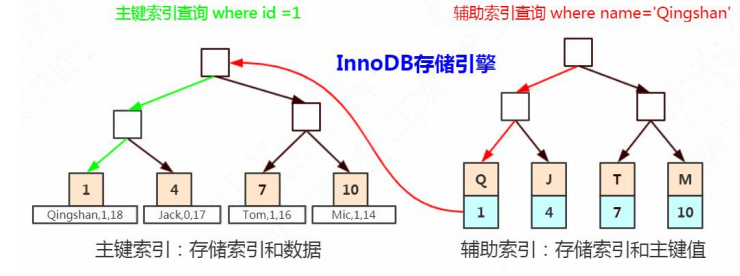
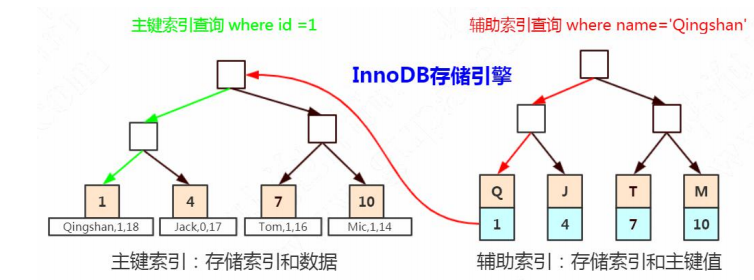
比如上面这张图,我们一张表里面有 6 条数据,当我们查询 id=37 的时候,要查询两个子节点,就需要跟磁盘交互 3 次,如果我们有几百万的数据呢?这个时间更加难以估计。
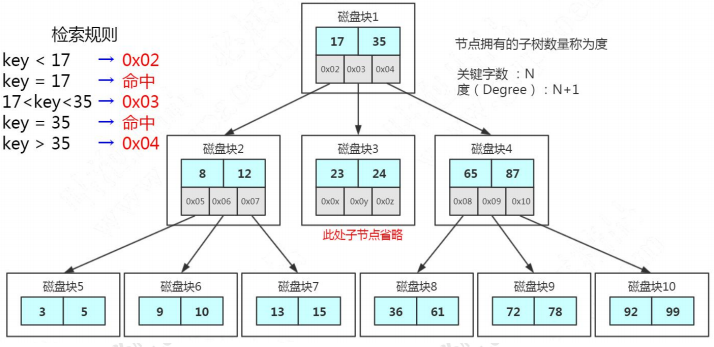
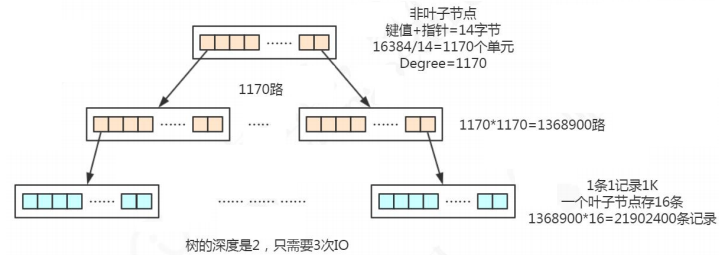
2.4. 多路平衡查找树(B Tree)(分裂、合并)

2.5. B+树(加强版多路平衡查找树)
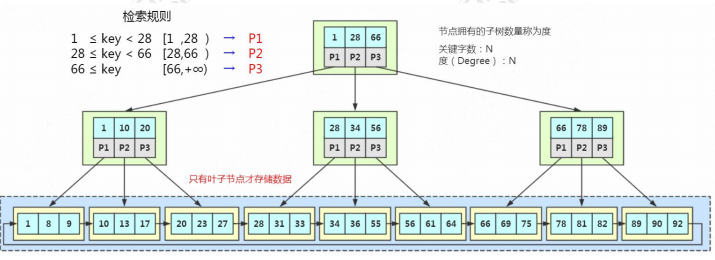
MySQL 中的 B+Tree 有几个特点:
2.6. 为什么不用红黑树?

在 Navicat 的工具中,创建索引,索引方式有两种,Hash 和 B Tree。
HASH:以 KV 的形式检索数据,也就是说,它会根据索引字段生成哈希码和指针, 指针指向数据。

哈希索引有什么特点呢?
第一个,它的时间复杂度是 O(1),查询速度比较快。因为哈希索引里面的数据不是按顺序存储的,所以不能用于排序。
第二个,我们在查询数据的时候要根据键值计算哈希码,所以它只能支持等值查询(= IN),不支持范围查询(> < >= <= between and)。另外一个就是如果字段重复值很多的时候,会出现大量的哈希冲突(采用拉链法解决),效率会降低。
InnoDB 可以在客户端创建一个索引,使用哈希索引吗?
官网:https://dev.mysql.com/doc/refman/5.7/en/innodb-introduction.html
InnoDB utilizes hash indexes internally for its Adaptive Hash Index feature
直接翻译过来就是:InnoDB 内部使用哈希索引来实现自适应哈希索引特性。
这句话的意思是 InnoDB 只支持显式创建 B+Tree 索引,对于一些热点数据页,InnoDB 会自动建立自适应 Hash 索引,也就是在 B+Tree 索引基础上建立 Hash 索引,
这个过程对于客户端是不可控制的,隐式的。我们在 Navicat 工具里面选择索引方法是哈希,但是它创建的还是 B+Tree 索引,这个不是我们可以手动控制的。
3. B+Tree 落地形式
3.1. MySQL 架构
3.2. MySQL 数据存储文件
show VARIABLES LIKE 'datadir';

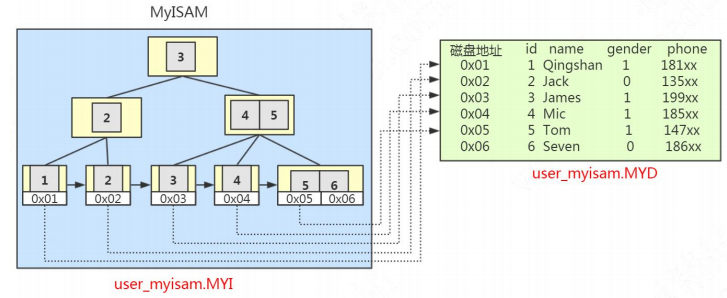
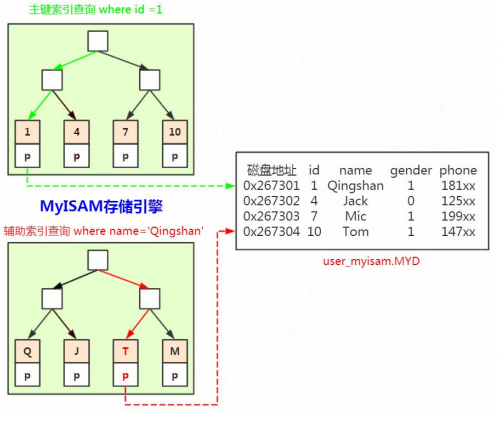
4.2.1.MyISAM
4.2.2.InnoDB
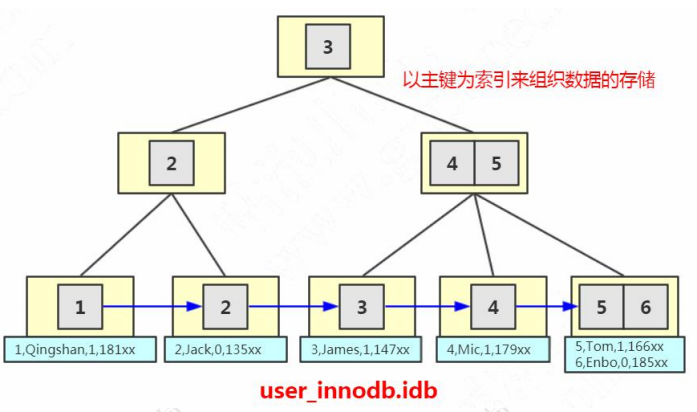
select _rowid name from t2;
4. 索引使用原则
4.1. 列的离散(sàn)度
ALTER TABLE user_innodb DROP INDEX idx_user_gender;
ALTER TABLE user_innodb ADD INDEX idx_user_gender (gender); -- 耗时比较久
EXPLAIN SELECT * FROM `user_innodb` WHERE gender = 0;

而 name 的离散度更高,比如“青山”的这名字,只需要扫描一行。

查看表上的索引,Cardinality [kɑ:dɪ'nælɪtɪ] 代表基数,代表预估的不重复的值
4.2. 联合索引最左匹配
ALTER TABLE user_innodb DROP INDEX comidx_name_phone; ALTER TABLE user_innodb add INDEX comidx_name_phone (name,phone);

5.2.1.什么时候用到联合索引
EXPLAIN SELECT * FROM user_innodb WHERE name= '权亮' AND phone = '15204661800';

2)使用左边的 name 字段,可以用到联合索引:


3)使用右边的 phone 字段,无法使用索引,全表扫描:

5.2.2.如何创建联合索引


4.3. 覆盖索引
-- 创建联合索引
ALTER TABLE user_innodb DROP INDEX comixd_name_phone;
ALTER TABLE user_innodb add INDEX `comixd_name_phone` (`name`,`phone`);
EXPLAIN SELECT name,phone FROM user_innodb WHERE name= '青山' AND phone = ' 13666666666'; EXPLAIN SELECT name FROM user_innodb WHERE name= '青山' AND phone = ' 13666666666'; EXPLAIN SELECT phone FROM user_innodb WHERE name= '青山' AND phone = ' 13666666666';
Extra 里面值为“Using index”代表使用了覆盖索引。

select * ,用不到覆盖索引。
4.4. 索引条件下推(ICP)
drop table employees; CREATE TABLE `employees` ( `emp_no` int(11) NOT NULL, `birth_date` date NULL, `first_name` varchar(14) NOT NULL, `last_name` varchar(16) NOT NULL, ` gender` enum('M','F') NOT NULL, `hire_date` date NULL, PRIMARY KEY (`emp_no`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1; alter table employees add index idx_lastname_firstname(last_name,first_name); INSERT INTO `employees` (`emp_no`, `birth_date`, `first_name`, `last_name`, `gender`, `hire_date`) VALUES (1, NULL, '698', 'liu', 'F', NULL); INSERT INTO `employees` (`emp_no`, `birth_date`, `first_name`, `last_name`, `gender`, `hire_date`) VALUES (2, NULL, 'd99', 'zheng', 'F', NULL); INSERT INTO `employees` (`emp_no`, `birth_date`, `first_name`, `last_name`, `gender`, `hire_date`) VALUES (3, NULL, 'e08', 'huang', 'F', NULL); INSERT INTO `employees` (`emp_no`, `birth_date`, `first_name`, `last_name`, `gender`, `hire_date`) VALUES (4, NULL, '59d', 'lu', 'F', NULL); INSERT INTO `employees` (`emp_no`, `birth_date`, `first_name`, `last_name`, `gender`, `hire_date`) VALUES (5, NULL, '0dc', 'yu', 'F', NULL); INSERT INTO `employees` (`emp_no`, `birth_date`, `first_name`, `last_name`, `gender`, `hire_date`) VALUES (6, NULL, '989', 'wang', 'F', NULL); INSERT INTO `employees` (`emp_no`, `birth_date`, `first_name`, `last_name`, `gender`, `hire_date`) VALUES (7, NULL, 'e38', 'wang', 'F', NULL); INSERT INTO `employees` (`emp_no`, `birth_date`, `first_name`, `last_name`, `gender`, `hire_date`) VALUES (8, NULL, '0zi', 'wang', 'F', NULL); INSERT INTO `employees` (`emp_no`, `birth_date`, `first_name`, `last_name`, `gender`, `hire_date`) VALUES (9, NULL, 'dc9', 'xie', 'F', NULL); INSERT INTO `employees` (`emp_no`, `birth_date`, `first_name`, `last_name`, `gender`, `hire_date`) VALUES (10, NULL, '5ba', 'zhou', 'F', NULL);
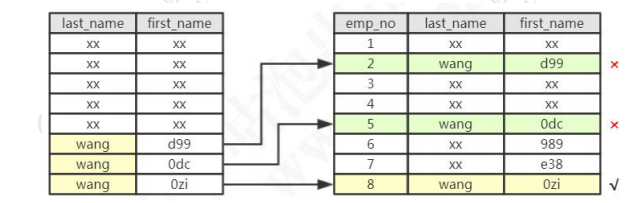
select * from employees where last_name='wang' and first_name LIKE '%zi' ;
explain select * from employees where last_name='wang' and first_name LIKE '%zi' ;


把 first_name LIKE '%zi'下推给存储引擎后,只会从数据表读取所需的 1 条记录。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号