
语音降噪论文“A Hybrid Approach for Speech Enhancement Using MoG Model and Neural Network Phoneme Classifier”的研读
最近认真的研读了这篇关于降噪的论文。它是一种利用混合模型降噪的方法,即既利用了生成模型(MoG高斯模型),也利用了判别模型(神经网络NN模型)。本文根据自己的理解对原理做了梳理。
论文是基于“Speech Enhancement Using a Mixture-Maximum Model”提出的MixMAX模型的。假设噪声是加性噪声,干净语音为x(t),噪声为y(t),则在时域带噪语音z(t)可以表示为z(t) = x(t) + y(t)。对z(t)做短时傅里叶变换(STFT)得到Z(k),再取对数谱(log-spectral)可得到Zk(k表示对数谱的第k维,即对数谱的第k个频段(frequency bin)。若做STFT的样本有L个,则对数谱的维数是 L/2 + 1)。相应的可得到Xk和Yk。MixMAX模型是指加噪后语音的每个频段上的值Zk是对应的Xk和Yk中的大值,即 = MAX(Xk, Yk)。
语音x由音素组成,设定一个音素可用一个高斯表示。假设音素有m个,则干净语音的密度函数f(x)可以表示成下式:

fi(x)表示第i个音素的密度函数。由于x是用多维的对数谱表示的,且各维向量之间相互独立,所以fi(x)可以表示成各维向量的密度函数fi,k(xk)的乘积。各维的密度函数表示如下式:
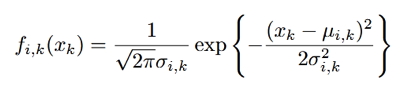
μi,k表示这一维上的均值,δi,k表示这一维上的方差。ci表示这个音素所占的权重,权重的加权和要为1。
噪声y只用一个高斯表示。同语音一样,y也是用多维的对数谱表示的,y的密度函数可以表示如下:
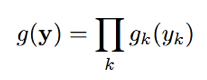
同样gk(yk)表示如下:
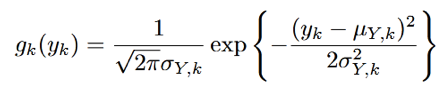
对于y每一维上的密度函数,其概率分布函数Gk(y)为:
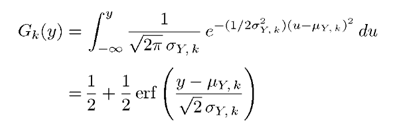
其中erf()为误差函数,表示如下:

同理可求得干净语音中每个音素的每一维上的概率分布函数,如下式:
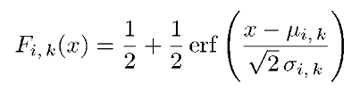
对于带噪语音Z来说,当语音音素给定时(即i给定时)其对数谱的第k维分量Zk的分布函数Hi,k(z)可以通过下式求得:

上式就是求I = i时的条件概率。由于X和Y相互独立,就变成了X和Y的第k维向量上的分布函数的乘积。对Zk的分布函数Hi,k(z)求导,就得到了的密度函数hi,k(z),表示如下:
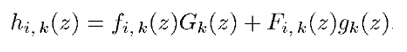
所以z的密度函数h(z)通过下式求得:
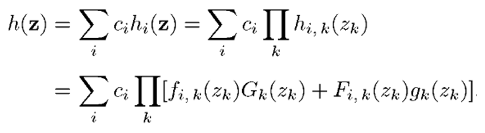
带噪语音Z已知,我们的目标是要根据带噪语音估计出干净语音X,即求出Z已知条件下的X的条件期望。基于MMSE估计,X的条件期望/估计表示如下:
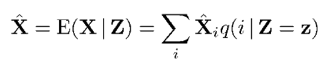
上式中X的条件期望又转换成了每个音素条件期望的加权和。条件概率q(i | Z = z)可根据全概率公式得到,如下:
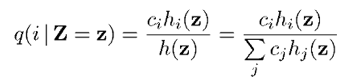
对于每个音素的条件期望,表示如下: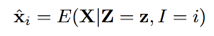 。对于每个音素的对数谱的每一维的条件期望,表示如下:
。对于每个音素的对数谱的每一维的条件期望,表示如下:
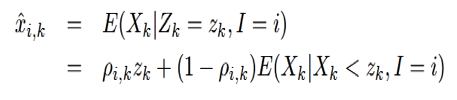
其中:

定义  ,可以推得x的对数谱的每一维上的估计如下式:
,可以推得x的对数谱的每一维上的估计如下式:

可以把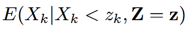 用基于谱减的
用基于谱减的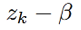 替代,其中β表示消噪程度。ρk可以看成是干净语音的概率。所以
替代,其中β表示消噪程度。ρk可以看成是干净语音的概率。所以
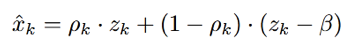
抵消掉正负项,可得:
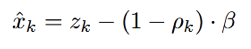
上式就是求消噪后的语音的对数谱的每维向量的数学表达式。zk可根据带噪语音求得,β要tuning,知道ρk后xk的估计就可得到了。对得到的每维向量做反变换,可得到消噪后的时域的值。
上文已给出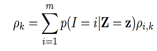 ,其中p(I = i | Z = z)表示在Z已知下是每个音素可能的概率,或者说一帧带噪语音是每个音素的可能的概率,用pi表示。pi可以通过全概率公式求出,即
,其中p(I = i | Z = z)表示在Z已知下是每个音素可能的概率,或者说一帧带噪语音是每个音素的可能的概率,用pi表示。pi可以通过全概率公式求出,即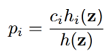 。但对每种语言来说,总的音素的个数是已知的(比如英语中有39个音素),这样求每帧是某个音素的概率是一个典型的分类问题。神经网络(NN)处理分类问题是优于传统方法的,所以可以用NN来训练一个模型,处理时用这个模型来计算每帧属于各个音素的概率,即算出pi,再和ρi,k做乘累加(ρi,k用基于MOG模型的方法求出),就可得到ρk了(
。但对每种语言来说,总的音素的个数是已知的(比如英语中有39个音素),这样求每帧是某个音素的概率是一个典型的分类问题。神经网络(NN)处理分类问题是优于传统方法的,所以可以用NN来训练一个模型,处理时用这个模型来计算每帧属于各个音素的概率,即算出pi,再和ρi,k做乘累加(ρi,k用基于MOG模型的方法求出),就可得到ρk了(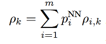 )。有了ρk,xk的估计就可求出了。可以看出NN模型的作用是替换计算pi的传统方法,使计算pi更准确。
)。有了ρk,xk的估计就可求出了。可以看出NN模型的作用是替换计算pi的传统方法,使计算pi更准确。
干净语音的高斯模型并不是用常规的EM算法训练得到的,而是基于一个已做好音素标注的语料库得到的,论文作者用的是TIMIT库。每帧跟一个音素一一对应,把属于一个音素的所有帧归为一类,算对数谱的各个向量的值,最后求均值和方差,得到这个向量的密度函数表达式,均值和方差的计算如下式:
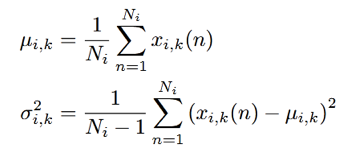
其中Ni表示属于某一音素的帧的个数。一个音素的所有向量的密度表达式相乘,就得到了这个音素的密度函数表达式。再通过属于这个音素的帧数占所有帧数的比例得到权重
(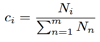 ), 这样干净语音的高斯模型就建立好了。
), 这样干净语音的高斯模型就建立好了。
对于非稳态噪声来说,噪声参数(μY,k和δY,k)最好能自适应。噪声参数的初始值可以通过每句话的前250毫秒求得(基于前250毫秒都是噪声的假设),求法同上面的干净语音的高斯模型,数学表达式如下:

噪声参数的更新基于以下算式:

其中α为平滑系数,0 < α < 1,也需要tuning。噪声参数(μY,k和δY,k)更新了,Gk(y)和gk(yk)就更新了,hi,k(z)也就更新了,从而ρi,k也更新了。
综上, 基于生成-判别混合模型的降噪算法如下:
1) 训练阶段
输入:
根据已标注好音素的语料库,得到对数谱向量z1,…zn(用于算MOG),MFCC向量v1,…,vn(用于NN训练)和每帧相对应的音素标签i1,…,in。
MoG 模型训练:
根据对数谱向量z1,…,zn算干净语音的MOG
NN模型训练:
根据(v1,i1),…(vn,…,in)训练一个基于音素的多分类模型
2) 推理阶段
输入:
带噪语音的对数谱向量以及MFCC向量
输出:
消噪后的语音
计算步骤:

为了更好的跟大家沟通,互帮互助,我建了一个讨论群。如您有兴趣,请搜weixin号 david_tym ,共同交流。谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号