二维数组访问的性能问题
背景
这是一个基本问题,经常会出现在面试中,考察面试者对内存存储和CPU访问的理解
问题
仔细看下面两段代码,它们运行速度有何差异,为什么?
Version1
using System;
class Program
{
static void Main()
{
int i, j;
int[,] x = new int[4000, 4000];
for (i = 0; i < 4000; i++)
{
for (j = 0; j < 4000; j++)
{
x[j, i] = i + j;
}
}
}
}
Version2
using System;
class Program
{
static void Main()
{
int i, j;
int[,] x = new int[4000, 4000];
for (j = 0; j < 4000; j++)
{
for (i = 0; i < 4000; i++)
{
x[j, i] = i + j;
}
}
}
}
答案
C# 语言以及大多数语言中,Version2 速度会比 Version1 快。
为什么?
为什么强调语言,因为不同语言对于多维数组的内存布局方式可能不一样。
主要有行优先和列优先

大多数编程语言会选择行优先存储,少数则会列优先,比如Fortran。
存储示意如下图:
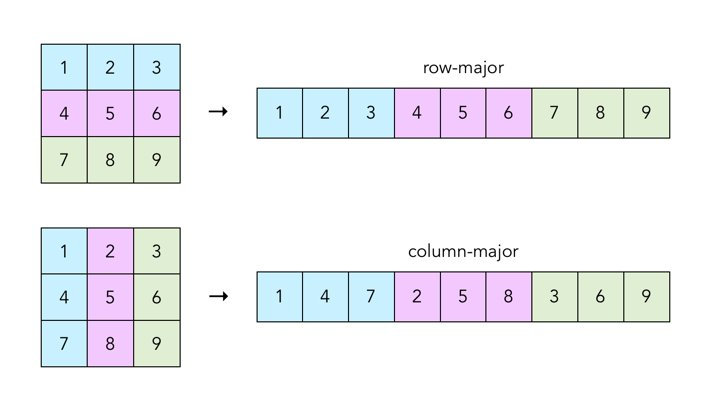
图源 https://craftofcoding.wordpress.com/2017/02/03/column-major-vs-row-major-arrays-does-it-matter/
可以看到二维数组在内存中按照"规则"在内存中的存储。
在读数据的时候,如果数据量特别小,差异自然不大。
但是如果数据量很大的情况下,因为CPU的局部性原理,Version 2会有效的命中Cache,减少CPU读取内存的次数,从而减少运行时间。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号