基于双向链表实现无锁队列的正确姿势(修正之前博客中的错误)
如果你认真看过我前几天写的这篇博客自己动手构建无锁的并发容器(栈和队列)的队列部分,那么我要向你表示道歉。因为在实现队列的出队方法时我犯了一个低级错误:队列的出队方向是在队列头部,而我的实现是在队列尾部。尽管代码能够正确执行,但明显不符合队列规范。所以那部分代码写作"基于双向链表的无锁队列"其实读作“基于双向链表的无锁栈”。当然,“队列是从一端入队而从另一端出队的,在一边进出的那是栈”这种常识我肯定是有的,至于为什么会犯这种低级错误思来想去只能归咎于连续高温导致的倦怠。前段时间的我,就好像一只被困在土里的非洲肺鱼,人生的全部意义都在等待雨季的来临。最近,久违的雨水带来了些许凉意,也冲走了这种精神上的疲倦,趁这个机会要好好纠正下以前的错误。代码见github上beautiful-concurrent
2. 基于双向链表实现的无锁队列
链表节点的定义如下
/**
* 链表节点的定义
* @param <E>
*/
private static class Node<E> {
//指向前一个节点的指针
public volatile Node pre;
//指向后一个结点的指针
public volatile Node next;
//真正要存储在队列中的值
public E item;
public Node(E item) {
this.item = item;
}
@Override
public String toString() {
return "Node{" +
"item=" + item +
'}';
}
}
基于双向链表实现无锁队列时,结点指针不需要被原子的更新,只需要用volatile修饰保证可见性。
2.1 入队方法
首先还是来看下队列的入队方法,这部分代码参考了Doug Lea在AQS中对线程加入同步队列这部分逻辑的实现,所以正确性是没有问题的
/**
* 将元素加入队列尾部
*
* @param e 要入队的元素
* @return true:入队成功 false:入队失败
*/
public boolean enqueue(E e) {
//创建一个包含入队元素的新结点
Node<E> newNode = new Node<>(e);
//死循环
for (; ; ) {
//记录当前尾结点
Node<E> taild = tail.get();
//当前尾结点为null,说明队列为空
if (taild == null) {
//CAS方式更新队列头指针
if (head.compareAndSet(null, newNode)) {
//非同步方式更新尾指针
tail.set(newNode);
return true;
}
} else {
//新结点的pre指针指向原尾结点
newNode.pre = taild;
//CAS方式将尾指针指向新的结点
if (tail.compareAndSet(taild, newNode)) {
//非同步方式使原尾结点的next指针指向新加入结点
taild.next = newNode;
return true;
}
}
}
}
这里分了两种情况来讨论,队列为空和队列不为空,通过队列尾指针所指向的元素进行判断:
-
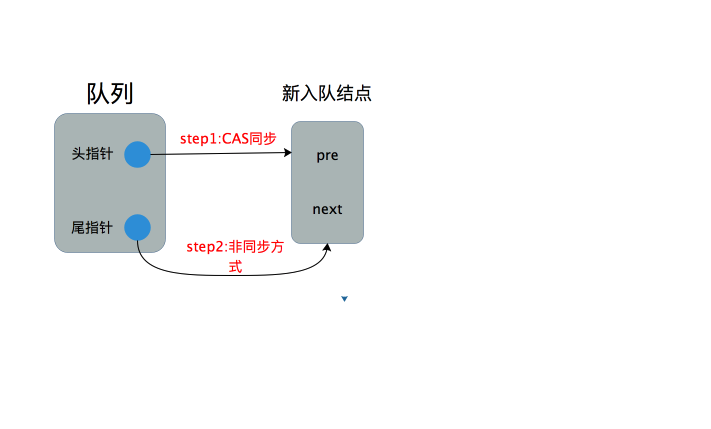
1.队列为空:队列尾指针指向的结点为null,这部分逻辑在if分句中
首先以CAS方式更新队列头指针指向新插入的结点,若执行成功则以非同步的方式将尾指针也指向该结点,结点入队成功;若CAS更新头指针失败则要重新执行for循环,整个过程如下图所示
-
2.队列不为空:队列尾指针指向的结点不为null。则分三步实现入队逻辑,整个过程如下图所示
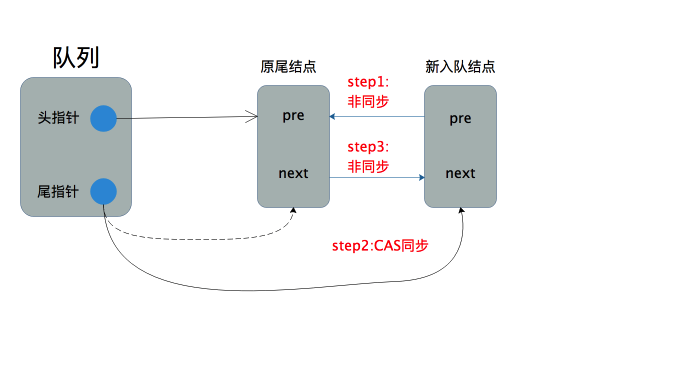
仅考虑入队情形,整个过程是线程安全,尽管有些步骤没有进行同步。我们分队列为空和不为空两种情况来进行论证:
- 1.队列为空时,执行流程将进入if分句,假设某线程执行
head.compareAndSet(null, newNode)更新头指针的操作成功,那么tail.set(newNode)这句不管其何时执行,其他线程将因为tail为null只能进入该if分句中,并且更新头指针的CAS操作必然失败,因为此时head已经不为null。所以仅就入队情形而言,队列为空时的操作是线程安全的。 - 2.队列不为空时,只要更新尾指针的CAS操作即
tail.compareAndSet(taild, newNode)执行成功,那么此时结点已经成功加入队列,taild.next = newNode;这步何时执行仅就入队的情形而言没有任何关系(但是会影响出队的逻辑实现,这里先卖个关子)。
2.2 出队方法
/**
* 将队列首元素从队列中移除并返回该元素,若队列为空则返回null
*
* @return
*/
public E dequeue() {
//死循环
for (; ; ) {
//当前头结点
Node<E> tailed = tail.get();
//当前尾结点
Node<E> headed = head.get();
if (tailed == null) { //尾结点为null,说明队列为空,直接返回null
return null;
} else if (headed == tailed) { //尾结点和头结点相同,说明队列中只有一个元素,此时要更新头尾指针
//CAS方式更新尾指针为null
if (tail.compareAndSet(tailed, null)) {
//头指针更新为null
head.set(null);
return headed.item;
}
} else {
//走到这一步说明队列中元素结点的个数大于1,只要更新队列头指针指向原头结点的下一个结点就行
//但是要注意头结点的下一个结点可能为null,所以要先确保新的队列头结点不为null
//队列头结点的下一个结点
Node headedNext = headed.next;
if (headedNext != null && head.compareAndSet(headed, headedNext))
headedNext.pre=null; //help gc
return headed.item;
}
}
}
出队的逻辑实现主要分三种情况讨论:队列为空,队列中刚好一个元素结点和队列中元素结点个数大于1。
其实上次代码中出错的部分主要是队列中结点个数大于1这种情况,而其他两种情况不管从哪边出队操作都是一样的。下面就分情况讨论下出队实现中需要注意的点
-
1.队列为空,判断标准是tail即尾指针是否指向null,因为入队的时候就是以tail指针来判断队列状态的,所以这里要保持一致性,哪怕空队列的入队过程中头指针已经成功指向新结点但没来得及更新尾指针,此时出队也会返回null。
-
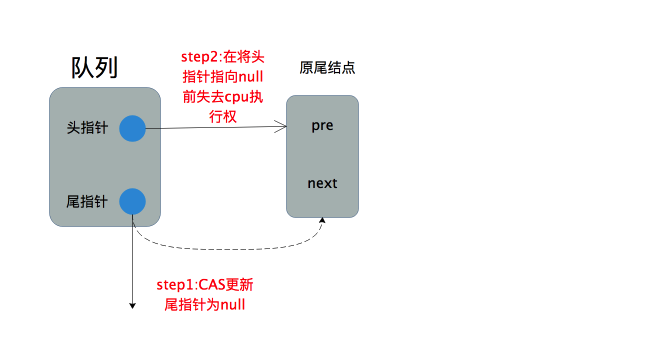
2.队列中刚好只有一个元素:头尾指针刚好指向同一个结点。首先以CAS方式更新尾指针指向null,执行成功再以正常方式设置头指针为null,这么做会有并发问题吗?考虑这种极端情形:刚好CAS更新尾指针为null然后失去了CPU执行权,如下图所示:
分两种情况讨论:
1.出队情形
因为tail已经为null,程序会判断队列为空,所以之后执行出队的线程将返回null
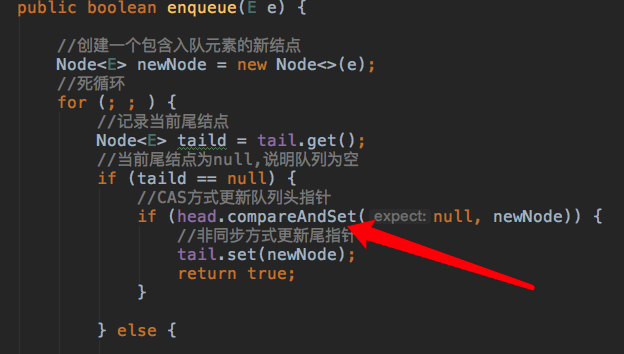
2.入队情形
因为tail为null,所以执行入队逻辑的线程会进入if分句,因为此时head不为null,所以执行图示的CAS操作时会失败并不断自旋
综上所示,队列中恰好只有一个元素结点的出队逻辑是线程安全的。
- 3.队列中元素结点的个数大于1
这时候只要将头指针以CAS方式更新为头结点的下一个结点就行了,但是要注意在这之前要执行
headedNext != null确保头结点的下一个结点不为null。你可能会问:等等,执行这部分代码的前提是队列中元素结点的个数至少为2,那么头结点的下一个结点肯定不为null啊。如果只考虑出队的情况,这么想没错,但是此时可能处于队列入队的中间状态,如下图所示
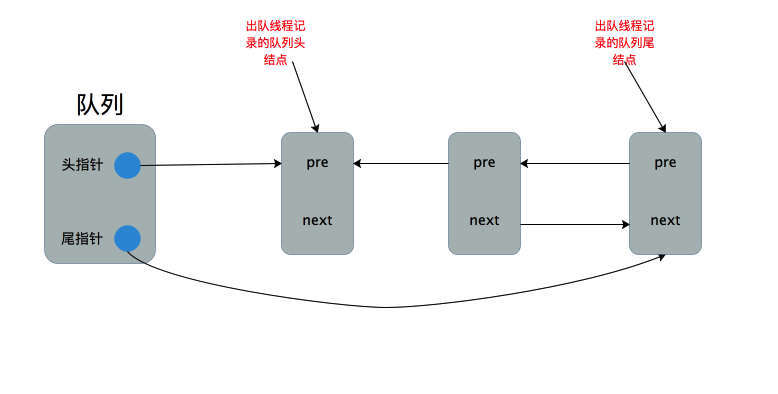
如上图所示,队列中有3个元素结点,但是负责第二个结点入队的线程已经成功执行尾指针的更新操作但没来得及更新前一个节点的next指针便失去了CPU执行权,回想下入队的流程,其实这种情况是可能存在并且允许的。如果此时没有通过headedNext != null进行判断便更新head指针指向头结点的下一个结点,那么就会出现下面这种情况
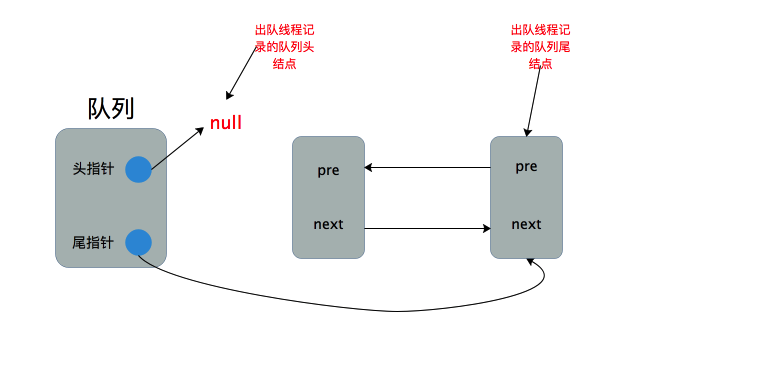
此时出队线程还是会执行最后一个else分句这部分代码,虽然此时队列不为空,但head指向了null,对其执行CAS更新操作将会抛出空指针异常,看来我们上次对head指针的更新操作太草率了,没有考虑到头结点的next指针可能为null这种入队操作导致的特殊情况。所以在对head指针进行CAS更新前要获得所记录头结点的下一个结点headedNext,并通过headedNext !=null保证更新后的头结点不为null。如果这种情况发生,出队线程将通过自旋等待,直到造成这种情况的入队线程成功执行
taild.next = newNode;,此时当前出队线程的出队过程才能执行成功,并正确设置头指针指向原队列头结点的下一个结点。
完整的代码见githubbeautiful-concurrent
3. 性能测试
开启200个线程,每个线程混合进行10000次入队和出队操作,将上述流程重复进行100次统计出执行的平均时间(毫秒),完整的测试代码已经放到github上beautiful-concurrent。测试结果如下图所示
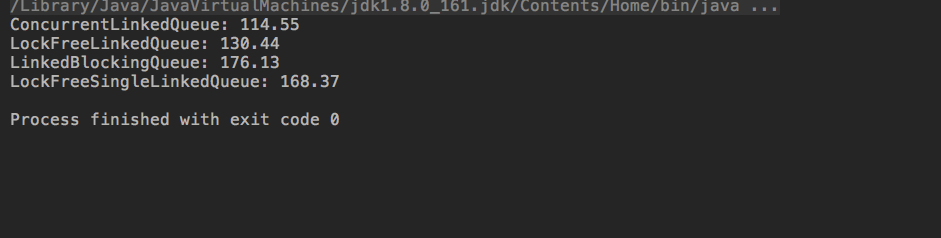
最后的测试结果真是出人意料。修复原来的队列在一端进出的bug后,性能竟然也有了很大的提高。基于双向链表实现的无锁队列LockFreeLinkedQueue在并发环境下的性能排在了第二位,超出了我们自己实现的基于单向链的无锁队列LockFreeSingleLinkedQueue很多,甚至接近于ConcurrentLinkedQueue的表现,要知道后者实现比我们的复杂了很多,经过了很多优化。原来的错误实现因为出队和入队在一端进行,所以平白无故增加了不必要的CSA竞争,导致并发性能降低这个好理解;那为什么比基于单向链表的队列表现还要好。毕竟后者没有prev指针,少了很多指针操作。关于这点,可能是因为单向链表实现时的CAS竞争过多,导致对CPU的有效利用率不高。而双向链表因其结构的特殊性,反而一定程度减少了CAS竞争。所以这也是个教训,如果能保证线程安全,尽量不要使用任何同步操作,如果不得不进行同步,那么越轻量级越好,volatile就比CAS"轻"得多。在拓宽下思路,如果我们对其进行类似于ConcurrentLinkedQueue的优化,比如不需要每次入队都更新队列尾指针,性能是否还会有飞跃,甚至超出ConcurrentLinkedQueue本身?这可能是个有意思的尝试,先挖个坑好了,以后有时间再填。
4.总结
这篇文章是对前面文章错误的修正,之所以独立成篇也是希望那些原来被我"误导"过的同学更有机会看到。这次对队列的出队过程进行了详细的图文分析,而没有像上次那样偷懒,只讲了个大概,不然也不会出现"队列在一端进出"这种低级错误,不知道上篇文章被人踩了一脚是不是这个原因,如果能在发现错误的时候在下面留言给我指出来就太感谢了。毕竟写技术博客的好处在于不仅是系统梳理技术知识自我提高的过程,也是一个和他人分享讨论共同进步的过程。而这一过程不仅需要作者自己努力,也需要读者共同参与。

