自己动手构建无锁的并发容器(栈和队列)
更新日志(2018年8月18日):这篇博客的队列部分犯了个低级错误:入队和出队在同在队列尾端进行。正确的实现方式见基于双向链表实现无锁队列的正确姿势(修正之前博客中的错误)
并发容器是线程安全的容器。它在实现容器基本功能的前提下,还提供了并发控制能力,使得容器在被多线程并发访问的情况下还能表现出正确的行为。通常我们使用独占锁的悲观策略来进行并发控制,因为其实现相对简单,正确性易于判断且绝大部分情况下都能表现出不错的性能;当然,也可以使用CAS算法来进行并发控制,这是一种无锁的乐观策略,尽管其有着实现比较复杂,正确性较难判定等缺点,但相比独占锁的方式,它至少有以下几方面的优势:
- 因为不需要加锁,根本上避免了死锁的产生。
- 避免了线程对锁的竞争产生的开销,比如阻塞,唤醒以及线程的调度。
- 加锁本质上是将部分代码的执行由并行变串行,这会导致程序的并行化比例降低;而无锁的CAS算法避免了这种情况发生。根据AMdahl定律,这意味着,随着计算资源的增加,基于CAS算法构建的并发容器往往有更好的性能提升,尽管其有因为CAS竞争失败导致的重试问题。
总的来说,无锁的并发容器更加安全,大部分情况下吞吐量也更高,但是也有着实现较为复杂不太好理解的缺点。通过自己动手实现无锁的线程安全的栈和队列,就能深刻体会到这一点。完整的代码已经放到github上beautiful-concurrent
2. 基于CAS算法构建无锁的并发栈
栈通常有两种实现方式,一种是使用数组,另一种是使用链表。首先我们定义一个无锁的栈的接口,该接口内部只有两个方法push()和pop(),如下图所示
/**
* @author: takumiCX
* @create: 2018-08-09
**/
public interface LockFreeStack<E> {
boolean push(E e);
E pop();
}
接下来我们分别就数组和链表两种实现方式,来探讨如何基于CAS算法构建无锁的并发栈。
2.1 数组实现
/**
* @author: takumiCX
* @create: 2018-08-08
*
* 基于数组实现的无锁的并发栈
**/
public class LockFreeArrayStack<E> implements LockFreeStack<E>{
//不支持扩容
final Object[] elements;
//容量,一旦确定不可更改
final int capacity;
//记录栈顶元素在数组中的下标,初始值为-1
AtomicInteger top = new AtomicInteger(-1);
public LockFreeArrayStack(int capacity) {
this.capacity = capacity;
elements = new Object[capacity];
}
/**
* 入栈
*
* @param e
* @return true:入栈成功 false:入栈失败(栈已满)
*/
public boolean push(E e) {
//死循环,保证多次CAS尝试后能得到结果
for (; ; ) {
//当前栈顶元素在数组中的下标
int curTop = top.get();
//栈已满,返回false
if (curTop + 1 >= capacity) {
return false;
} else {
//首先将元素放入栈中
elements[curTop + 1] = e;
//基于CAS更新栈顶指针,这里是top值
if (top.compareAndSet(curTop, curTop + 1)) {
return true;
}
}
}
}
/**
* 出栈
*
* @return 栈顶元素, 若栈为空返回null
*/
public E pop() {
//死循环,保证多次CAS尝试后能得到结果
for (; ; ) {
//当前栈顶元素在数组中的下标
int curTop = top.get();
//栈为空,返回null
if (curTop == -1) {
return null;
} else {
//CAS更新栈顶指针,这里是top值
if (top.compareAndSet(curTop, curTop - 1)) {
return (E) elements[curTop];
}
}
}
}
}
为了突出CAS算法实现入栈出栈的过程,同时也是为了简化代码实现的复杂度,基于数组实现的栈不支持扩容,最大容量capacity在构造函数中确定。top为栈顶元素"指针",这里为栈顶元素在数组中的下标值。因为top值的更新依赖于前值,所以这里不能使用volatile关键字,而应该使用原子变量,保证在更新top值之前top值没有被其他线程改变。栈的pop()方法实现比较简单,只要在栈不为空的情况下,原子的把top值更新为top-1;而栈的push()方法相对来说比较复杂,它包含了两步:
- 1.将入栈元素放入数组的top+1位置
- 2.然后原子的更新top值为top+1
这里可能有人会疑问:这难道不会产生并发问题吗,比如说一个线程执行了1后,另一个线程也执行了1,这不是把前面的结果覆盖了吗?我们可以画图来演绎下整个过程:
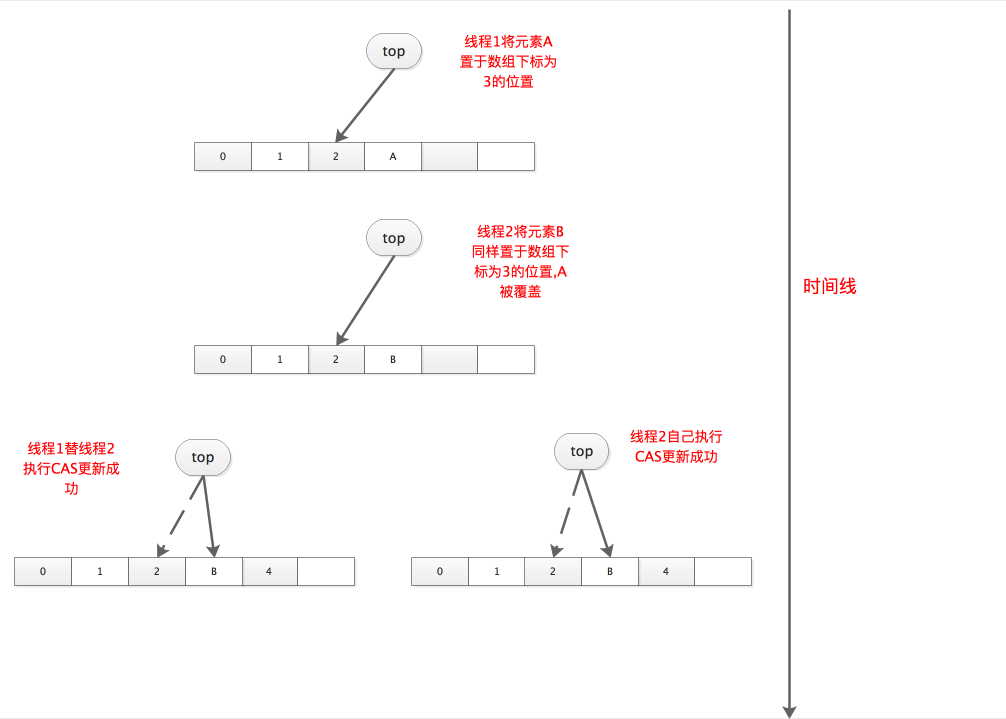
可以看到,尽管1在多线程环境下会产生元素覆盖问题,但是对于最后一个覆盖的线程而言,2的CAS更新是必然会成功的,不管这个CAS更新是由该线程自己执行还是其他线程替他执行,一旦某线程CAS更新成功,其他线程将因CAS失败重新执行for循环。
2.2 链表实现
基于链表实现无锁的栈会更灵活,不用考虑栈扩容或者栈空间满的问题,而且实现同样简单。
/**
* @author: takumiCX
* @create: 2018-08-09
*
* 基于链表实现的无锁的并发栈
**/
public class LockFreeLinkedStack<E> implements LockFreeStack<E>{
//栈顶指针
AtomicReference<Node<E>> top = new AtomicReference<Node<E>>();
/**
* @param e 入栈元素
* @return true:入栈成功 false:入栈失败
*/
public boolean push(E e) {
//构造新结点
Node<E> newNode = new Node<E>(e);
//死循环,保证CAS失败重试后能入栈成功
for (; ; ) {
//当前栈顶结点
Node<E> curTopNode = top.get();
//新结点的next指针指向原栈顶结点
newNode.next = curTopNode;
//CAS更新栈顶指针
if (top.compareAndSet(curTopNode, newNode)) {
return true;
}
}
}
/**
*
* @return 返回栈顶结点中的值,若栈为空返回null
*/
public E pop() {
//死循环,保证出栈成功
for (; ; ) {
//当前栈顶结点
Node<E> curTopNode = top.get();
//栈为空,返回null
if (curTopNode == null) {
return null;
} else {
//获得原栈顶结点的后继结点
Node<E> nextNode = curTopNode.next;
//CAS更新栈顶指针
if (top.compareAndSet(curTopNode, nextNode)) {
return curTopNode.item;
}
}
}
}
//定义链表结点
private static class Node<E> {
public E item;
public Node<E> next;
public Node(E item) {
this.item = item;
}
}
}
由定义可知,该链表为单链表,且不带哨兵。为了操作方便,新增结点的插入采用头插法。如下图所示:
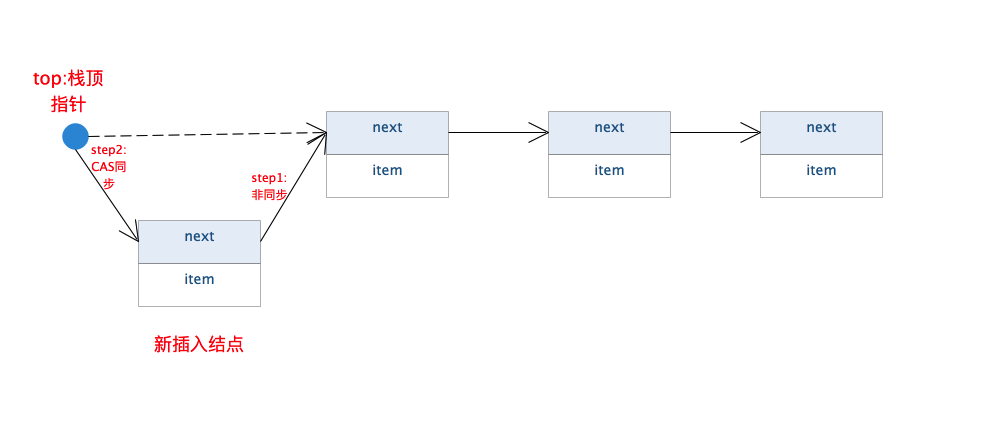
因为栈顶元素的更新依赖于前值(我们要保证更新栈顶指针前没有其他线程对其进行更改),故而使用原子引用,基于原子引用的CAS算法可以保证只有当更新前的引用为预期值时,当前更新才能成功(注意栈顶指针的初始化方式,至于为何不能直接给top赋值为null后面队列部分会解释)。其入栈出栈流程也十分简单,仅需对栈顶指针top进行CAS同步。
- 入栈时:1.获取当前栈顶结点 2.新结点的next指针指向获取的栈顶结点 3.CAS更新栈顶指针。CAS竞争失败的线程将会重复这一流程。
- 出栈时:1. 获取当前栈顶结点 2.若栈顶结点为null,说明栈为空,返回null,否则CAS更新栈顶指针为原栈顶结点的下一个结点 3.返回原栈顶结点的元素 。CAS失败的线程将会重复这一流程。
2.3 性能测试
以JDK中的Stack为基准进行性能测试,由于JDK中的Stack是线程不安全的,在测试时通过手动加锁的方式保证线程安全。
开启10个线程,每个线程混合进行10000次push和pop操作。分别以每种容器进行100次上述操作,计算出每次的平均执行时间(单位毫秒)如下。测试环境的处理器核数为4。这里就不贴测试代码了,想看的点这里github

可以看到基于CAS算法的栈确实比基于锁的栈表现出了更好的性能。
3. 基于CAS算法构建无锁的并发队列
队列其实也有数组(循环数组)和链表两种实现方式,这里为了向并发大神Doug Lea致敬(笑),仅就队列的链表实现进行讨论。栈的操作只在栈顶进行,只需要有一个栈顶指针,并保证其更新的原子性即可。但是队列是先进先出的,其入队和出队分别在队列的两端,所以必须有两个指针分别指向队列的头部和尾部,对它们的更新不仅需要保证是原子性的,还要避免其相互冲突,一旦涉及到两项CAS操作,且它们相互间又存在一定的制约关系,无锁算法的实现就会一下子变得复杂起来。不过不用急,通过合理的分析和设计,总能找到正确的办法。先来看无锁的队列的接口定义:
/**
* @author: takumiCX
* @create: 2018-08-10
*
* 队列接口,仅包含入队和出队抽象方法
**/
public interface LockFreeQueue<E> {
//入队
boolean enqueue(E e);
//出队
E dequeue();
}
该接口中仅定义了入队和出队的方法。
链表有双向链表和单向链表之分,通过前面阅读reentrantlock的源码我们知道同步队列就是一种双向链表,并且在为我们保留了更多信息的情况下实现也并不复杂,借鉴下这种经验,我们也选择双向链表来实现队列。链表的结点定义如下:
private static class Node<E> {
//指向前一个节点的指针
public volatile Node pre;
//指向后一个结点的指针
public volatile Node next;
//真正要存储在队列中的值
public E item;
public Node(E item) {
this.item = item;
}
@Override
public String toString() {
return "Node{" +
"item=" + item +
'}';
}
}
因为可能有多线程环境对结点指针的并发访问,所以pre和next指针都用volatile修饰保证可见性。
队列的头尾指针分别定义如下,我们采用了不带哨兵结点的方式,即头尾指针在初始化时指向的元素值为null,又因为我们需要原子的更新引用,故声明为AtomicReference,其内部指针指向的类型为Node
//指向队列头结点的原子引用
private AtomicReference<Node<E>> head = new AtomicReference<>(null);
//指向队列尾结点的原子引用
private AtomicReference<Node<E>> tail = new AtomicReference<>(null);
注意这里初始化的写法,AtomicReference其实也是一个对象,其内部有一个指向真正元素的引用以及一些原子方法。我们不能直接写head=tail=null来表示初始化状态,而应该声明一个AtomicReference的空对象。整个队列的结构如下图所示。

可以看到队列的头指针和尾指针分别指向的是一个AtomicReference对象,然后再由AtomicReference内部的指针去指向真正的头尾结点。AtomicReference对象不仅使我们的头尾指针间接找到了队列的头尾结点,还提供了原子的更新这种指向的方法。后面所讲的更新头尾指针其实更新的并不是真正的头尾指针,而是它们指向的AtomicReference对象内部的指针。当然思考的时候不用考虑这层抽象。
3.1 入队方法
/**
*
* @param e 要入队的元素
* @return true:入队成功 false:入队失败
*/
public boolean enqueue(E e) {
//创建一个包含入队元素的新结点
Node<E> newNode = new Node<>(e);
//死循环,保证最后都能进入队列
for (; ; ) {
//当前尾结点
Node<E> taild = tail.get();
//当前尾结点为null,说明队列为空
if (taild == null) {
//CAS方式更新队列头指针
if (head.compareAndSet(null, newNode)) {
//非同步方式更新尾指针
tail.set(newNode);
return true;
}
} else {
//新结点的pre指针指向原尾结点
newNode.pre = taild;
//CAS方式将尾指针指向新的结点
if (tail.compareAndSet(taild, newNode)) {
//非同步方式更新
taild.next = newNode;
return true;
}
}
}
}
有没有觉得这部分代码很眼熟?如果你认真阅读过AQS中线程加入同步队列等待部分的源码,就会发现只是在它的基础上做了些小改动。整个过程只有更新头尾指针时进行了CAS同步,所以并发环境下性能很好。至于为什么整个过程是线程安全的可以参考我在从源码角度彻底理解ReentrantLock(重入锁)里3.3小节的讲解。
3.2 出队方法
/**
* 将队列首元素从队列中移除并返回该元素,若队列为空则返回null
* @return
*/
public E dequeue() {
//死循环,保证最后都能出队成功
for (;;) {
//当前头结点
Node<E> tailed = tail.get();
//当前尾结点
Node<E> headed = head.get();
if (tailed == null) { //尾结点为null,说明队列为空,直接返回null
return null;
} else if (headed == tailed) { //尾结点和头结点相同,说明队列中只有一个元素,此时要更新头尾指针
//CAS方式更新尾指针为null
if (tail.compareAndSet(tailed,null)) {
// head.compareAndSet(headed, null);
//头指针更新为null
head.set(null);
return tailed.item;
}
} else { //此时队列中元素个数大于1,头尾指针指向不同结点,出队操作只需要更新尾指针
Node preNode = tailed.pre;
//CAS方式更新尾指针指向原尾结点的前一个节点
if (tail.compareAndSet(tailed, preNode)) {
preNode.next = null; //help gc
return tailed.item;
}
}
}
}
更新日志(2018年8月18日):最后一个else分句中的出队逻辑有问题:错误的在队列尾部进行出队。正确的实现方式见基于双向链表实现无锁队列的正确姿势(修正之前博客中的错误)中的2.2小节。
首先获取当前队列的头尾结点,然后根据尾结点是否为null以及头尾结点是否相等分3种情况讨论:
- 1.队列为空,此时头尾指针都不用更新,直接返回null
- 2.队列只有一个元素,需要同时更新头尾指针
- 3.队列元素个数大于1,只需更新尾指针
3.3 性能测试
以JDK中的LinkedBlockingQueue和ConcurrentLinkedQueue为基准,前者通过加锁的方式实现了线程安全,后者也是基于CAS方式实现的,不过逻辑相对复杂,因为进行了很多优化。同样开启10个线程,每个线程混合进行10000次入队和出队操作。重复进行100次上述操作计算出平均执行时间并进行比较。测试代码见github

由上面的结果可知,同样是基于CAS实现,ConcurrentLinkedQueue的性能比我们自己构建的无锁队列好不少,一个原因是其内部做了不少优化,比如尾指针并不是在每次插入时都会更新,另一个原因可能是其队列是由单链表构成,少了很多指针操作。LinkedBlockingQueue性能和LockFreeLinkedQueue差不多,如果算上因为测试需要将LockFreeLinkedQueue加了一层适配器的包装导致的方法调用的额外开销,可能后者性能稍微还要更好些。看来JDK确实对锁做了很多优化,通过加锁的方式
实现线程安全并不会导致性能下降很多,所以大部分并发容器都使用锁来保证线程安全。
4. 总结
在阅读ReentrentLock源码领略过Doug Lea精湛的并发技艺后趁热打铁,自己动手构建了无锁的线程安全的栈和队列。整个过程虽有不少挑战,但最终获益匪浅,对原子变量和CAS算法有了更深的理解,也锻炼了分析和解决问题的能力。

