操作系统学习笔记(12)——缓冲技术和驱动调度技术
1、缓冲技术
- 缓冲技术的基本思想是:当一个进程输出数据时,先向系统申请一块内存作为输出缓冲区;然后,将输出数据高速输出到缓冲区;不断把数据填到缓冲区,直到缓冲区被装满为止;此后,进程可以继续它的计算,同时,系统将缓冲区内容写到I/O设备上。当一个进程执行读操作输入数据时,过程与此类似。
- 单缓冲
- 单缓冲是在设备和CPU之间设置一个缓冲器。
- 对于块设备而言,假定从磁盘把一块数据输入到缓冲的时间为T,操作系统将该缓冲区中的数据传送到用户区的时间为M,CPU对这一块数据计算的时间为C。如果不采用缓冲,数据直接从磁盘到用户区,每块数据的处理时间为T+C。若采用单缓冲,每块数据的处理时间为max(C, T)+M。通常来说M要远远小于C或者T,因此采用缓冲技术,输入的效率提高了很多。

- 双缓冲:为加快输入输出速度和提高设备利用率,引入了双缓冲。首先将数据送入缓冲区1,装满后使转向缓冲区2。此时操作系统可从缓冲区1中移出数据送至用户进程区,由CPU对数据进行计算。两个缓冲区交替使用,使得CPU和I/O设备、设备和设备的并行性进一步提高。在双缓冲时,系统处理一块数据的时间可粗略地认为是max(C,T)。
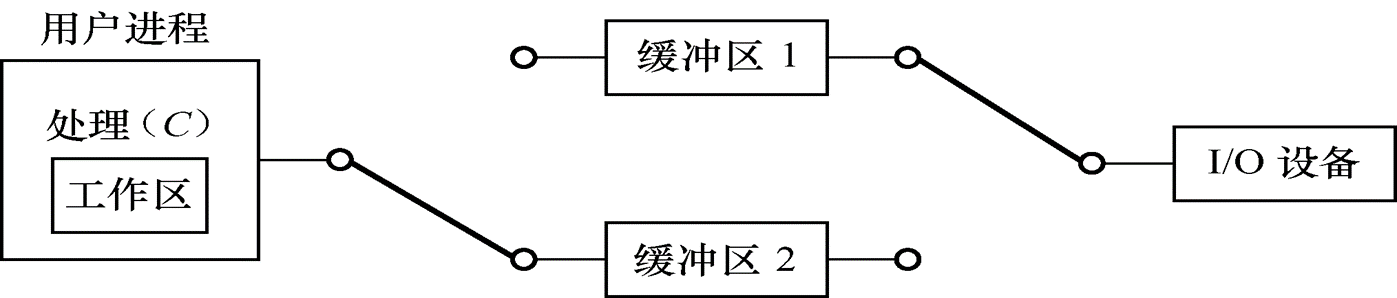
- 循环缓冲
- 使用循环缓冲的原因:当输入与输出的速度基本相匹配时,双缓冲能获得较好的效果,使输入与输出基本上能并行操作。若两者的速度相差甚远,双缓冲的作用则不够理想,不过可以增加缓冲区数量,从而改善这些问题。因此,又引入了多缓冲机制。并将多缓冲组织成循环缓冲形式。
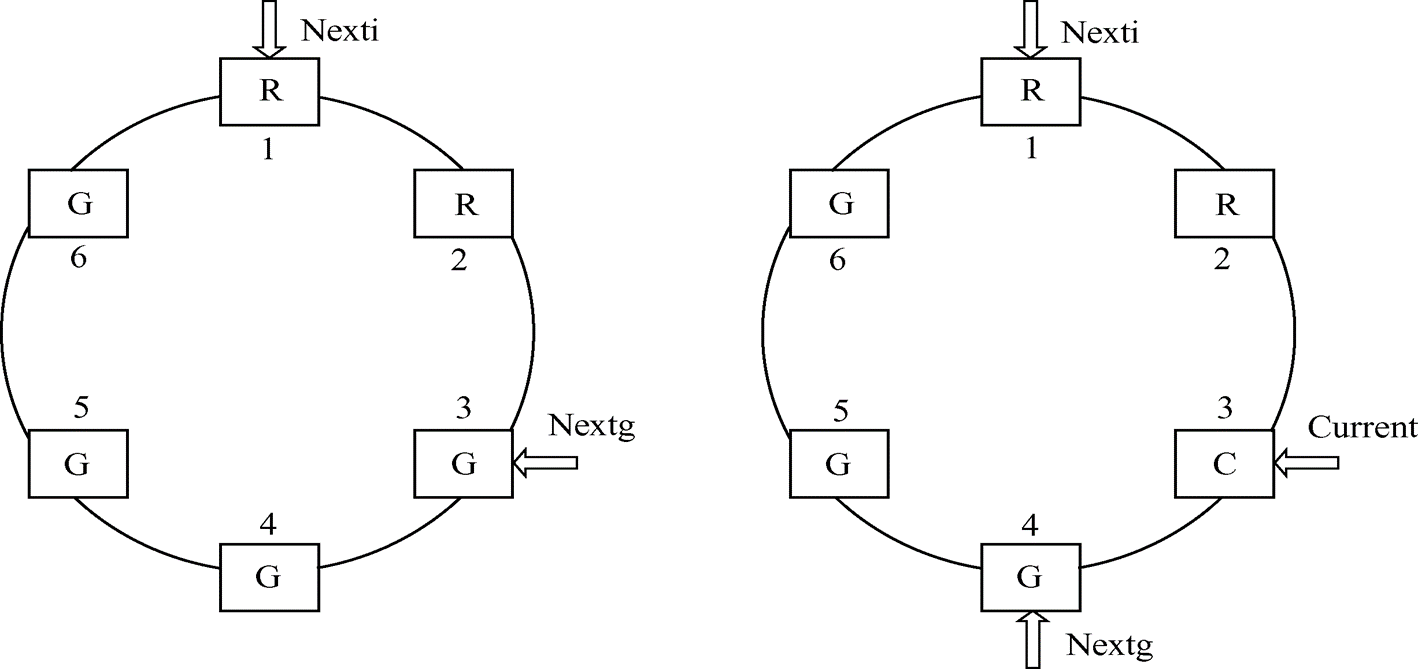
- 循环缓冲的组成:
- 多个缓冲区。在循环缓冲中包含了多个缓冲区,每个缓冲区的大小相同。缓冲区可分为三种类型:空缓冲区R;已装满数据的缓冲区G;计算进程正在使用的缓冲区C。
- 多个指针。对用于输入的多缓冲,可设置这样三个指针。Nextg指示计算进程下一个可用的缓冲区G;Nexti指示输入进程下次可用的空缓冲区R;Current指示计算进程正在使用的缓冲区C。
-
- 循环缓冲的使用
-
GetBuffer过程。对于计算进程而言,调用GetBuffer过程,通过Nextg获得要进行计算的缓冲区,相应地将该缓冲区改为C,将Current指向该缓冲区,Nextg指向下一个G缓冲区。对于输入进程而言,调用GetBuffer过程,通过Nexti获取可用的缓冲区,相应地将该缓冲区改为C,将Current指向该缓冲区,Nexti指向下一个R缓冲区。
-
ReleaseBuffer过程。当计算进程提取完毕后,当前的缓冲区空出来了,调用Release过程,将C改为R。类似输入进程输入完毕,调用Release过程,将该缓冲区改为G。
-
- 循环缓冲的使用
-
- 利用循环缓冲实现进程同步
-
指针Nexti和Nextg不断顺时针运行,可能会出现以下情况——
- Nexti指针追上Nextg指针。意味着输入进程输入数据的速度大于计算进程处理数据的速度,已把全部可用的空缓冲装满,再无缓冲区可用。此时,输入进程应该阻塞,直到有计算进程计算完毕,将某个缓冲区释放,输入进程才被唤醒。
- Nextg指针追上Nexti指针。意味着计算进程处理数据的速度大于输入进程输入数据的速度,已把所有输入数据的缓冲区处理完毕,再无有数据的缓冲区供计算进程使用。此时,计算进程应该阻塞,直到有输入进程输入数据,将某个缓冲区释放,计算进程才被唤醒。
-
- 利用循环缓冲实现进程同步
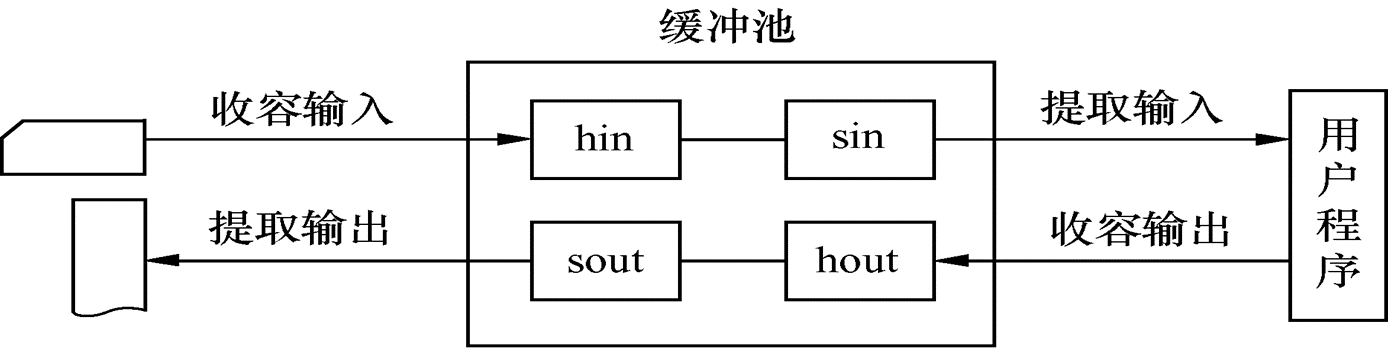
- 缓冲池
- 缓冲池的组成
-
空闲缓冲区队列emq:由空闲缓冲区所连成的队列。其队首指针F(emq)和队尾指针L(emq)分别指向该队列的首尾缓冲区
-
输入队列inq:这是由装满输入数据的缓冲区所连成的队列。其队首指针F(inq)和队尾指针L(inq)分别指向该队列的首、尾缓冲区。
-
输出队列outq:这是由装满输出数据的缓冲区所连成的队列。其队首指针F(outq)和队尾指针L(outq)分别指向该队列的首、尾缓冲区。
-
除了上述三个队列外,还应具有4种工作缓冲区。① 用于收容输入数据的工作缓冲区(hin)。② 用于提取输入数据的工作缓冲区(sin)。③ 用于收容输出数据的工作缓冲区(hout)。④ 用于提取输出数据的工作缓冲区(sout)。
-
- 缓冲池管理的基本操作 Getbuf 过程和 Putbuf 过程
- 缓冲池中两个基本操作。
- Getbuf(type):用于从type所指定的队列的队首摘下一个缓冲区。
- Putbuf(type,number):用于将由参数number所指示的缓冲区挂在type队列上。
- 需要注意的是,缓冲池是一个临界资源。在Getbuf和Putbuf过程中必须遵循进程同步的原则。
- 缓冲池的组成
- 缓冲池工作的基本方式
-
- 收容输入工作方式:在输入进程需要输入数据时,调用Getbuf(emq)过程,从空缓冲区队列emq的队首摘下一个空缓冲区,把它作为收容输入工作缓冲区hin。然后,把数据输入其中,装满后再调用Putbuf(inq,hin)过程,将该缓冲区挂在输入队列inq的队尾。
- 提取输入工作方式:当计算进程需要输入数据时,调用Getbuf(inq)过程,从输入队列取一个缓冲区作为提取输入工作缓冲区sin,计算进程从中提取数据。计算进程用完该数据后,再调用Putbuf(emq,sin)过程,将该缓冲区挂到空缓冲队列emq上。
- 收容输出工作方式:当计算进程需要输出时调用Getbuf(emq)过程,从空缓冲队列emq的队首取得一个空缓冲,作为收容输出工作缓冲区hout。当其中装满输出数据后,又调用Putbuf(outq,hout)过程,将该缓冲区挂在输出队列outq末尾。
- 提取输出工作方式:要输出时,由输出进程调用Getbuf(outq)过程,从输出队列的队首取一个装满输出数据的缓冲区,作为提取输出工作缓冲区sout。在数据提取完后,再调用Putbuf(emq,sout)过程,将它挂在空缓冲队列emq的末尾。
2、驱动调度技术
- 磁盘的物理结构:磁盘是一种直接存取存储设备,又叫随机存取存储设备。它的每个物理块有确定的位置和唯一的地址,存取任何一个物理块所需的时间几乎不依赖于此信息的位置。每个盘面有一个读写磁头,所有的读写磁头都固定在唯一的移动臂上同时移动。在一个盘面上的读写磁头的轨迹称磁道,在磁头位置下的所有磁道组成的圆柱体称柱面,一个磁道又可被划分成一个或多个物理块。文件的信息通常不是记录在同一盘面的各个磁道上,而是记录在同一柱面的不同磁道上,这样可使移动臂的移动次数减少,缩短存取信息的时间。为了访问磁盘上的一个记录,必须给出3个参数:柱面号、磁头号和块号。

- 磁盘访问时间
-
寻道时间:寻道时间(Ts)是指把磁臂(磁头)移动到指定磁道上所经历的时间。该时间是启动磁臂的时间s与磁头移动n条磁道所花费的时间之和,即——Ts=m×n +s。其中,m是一常数,与磁盘驱动器的速度有关,对一般磁盘,m=0.2;对高速磁盘,m≤0.1,磁臂的启动时间约为2ms。这样,对一般的硬盘,其寻道时间将随寻道距离的增加而增大,大体上是5~30ms。
-
旋转延迟时间:旋转延迟时间(Tτ)是指定扇区移动到磁头下面所经历的时间。对于硬盘,典型的旋转速度大多为5400r/min,每转需时11.1 ms,平均旋转延迟时间Tτ为5.55ms;对于软盘,其旋转速度为300r/min或600r/min,这样,平均Tτ为50~100ms。
-
传输时间:传输时间(Tt)是指把数据从磁盘读出或向磁盘写入。Tt的大小与每次所读/写的字节数b和旋转速度有关。
-
可将访问时间Ta表示为
-
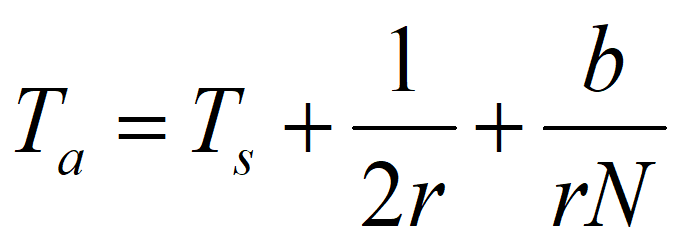
其中,r为磁盘每秒钟的转数;N为一条磁道上的字节数
- 磁盘调度
- 磁盘是可供多个进程共享的设备,当有多个进程都要求访问磁盘时,应采用一种最佳的调度算法,以使各进程对磁盘的平均访问时间最小。由于在磁盘访问的时间中,主要是寻道时间,因此,磁盘调度的目标,是使磁盘的平均寻道时间最少。
- 先来先服务:先来先服务(FCFS)是最简单的磁盘调度算法。它根据进程请求访问磁盘的先后次序进行调度。此算法的优点是公平、简单,且每个进程的请求都能依次得到处理,不会出现某一进程的请求长期得不到满足的情况。但会致使平均寻道时间长。
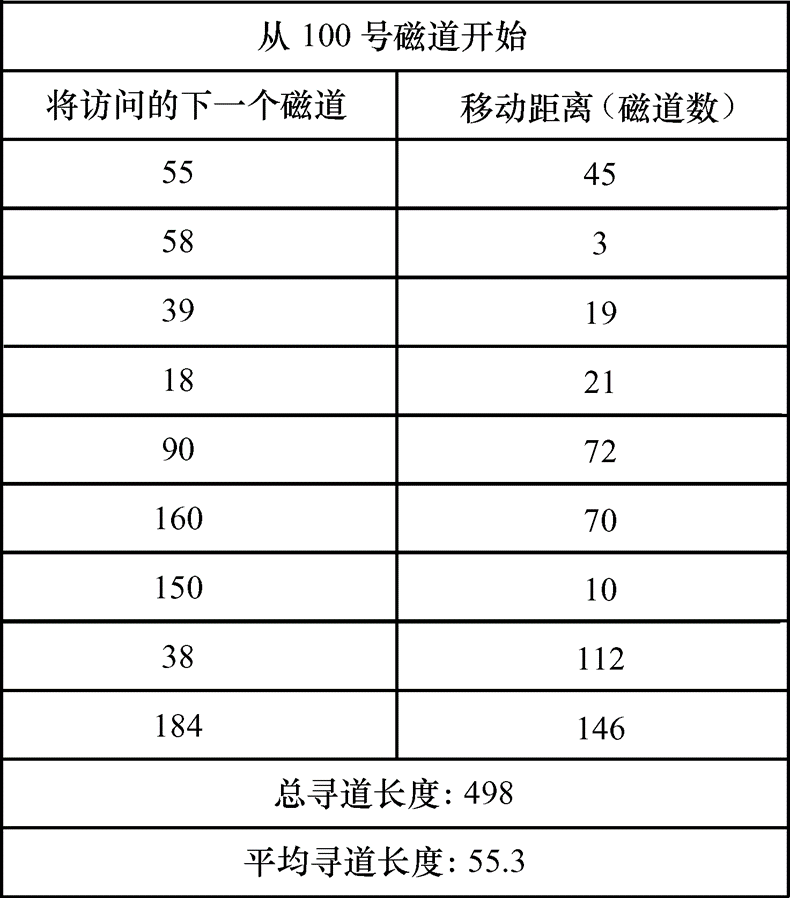
-
- 最短寻道时间优先:最短寻道时间优先(SSTF)算法总是先执行查找时间最短的那个磁盘请求。从而,较“先来先服务”算法有较好的性能。但是本算法存在“饥饿”现象,随着源源不断靠近当前磁头位置读写请求的到来,使早来的但距离当前磁头位置远的读写请求服务被无限期推迟
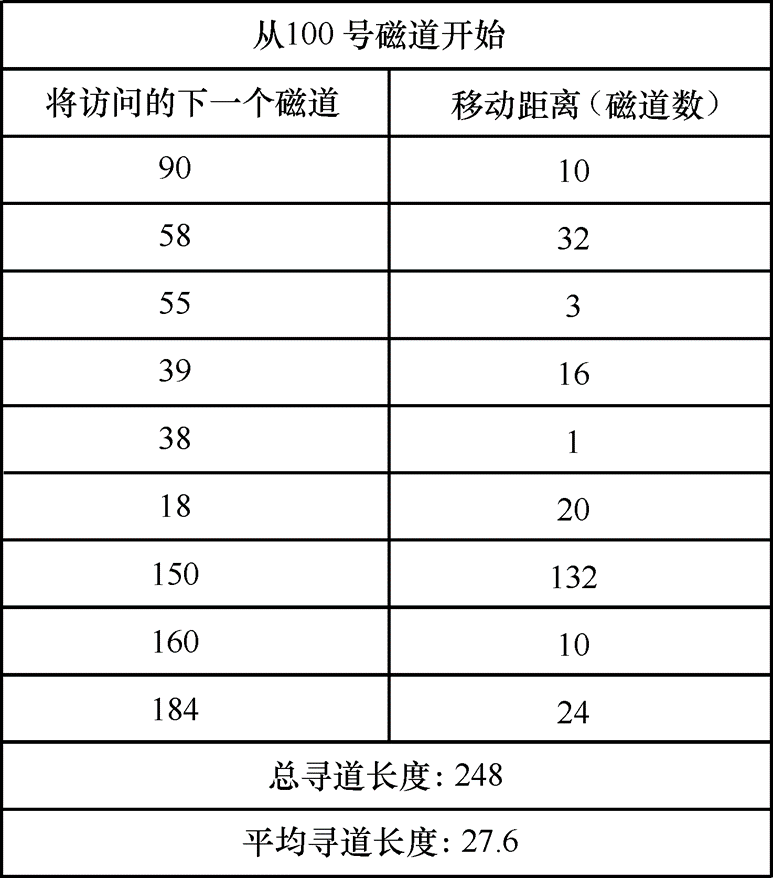
-
-
扫描算法:扫描算法(SCAN)每次总是选择沿臂的移动方向最近的那个柱面。如果沿这个方向没有访问的请求时,就改变臂的移动方向,这非常类似于电梯的调度规则。扫描算法克服了“饥饿”这一缺点。扫描算法偏爱那些最接近里面或靠外的请求,对最近扫描跨过去的区域响应会较慢。
-
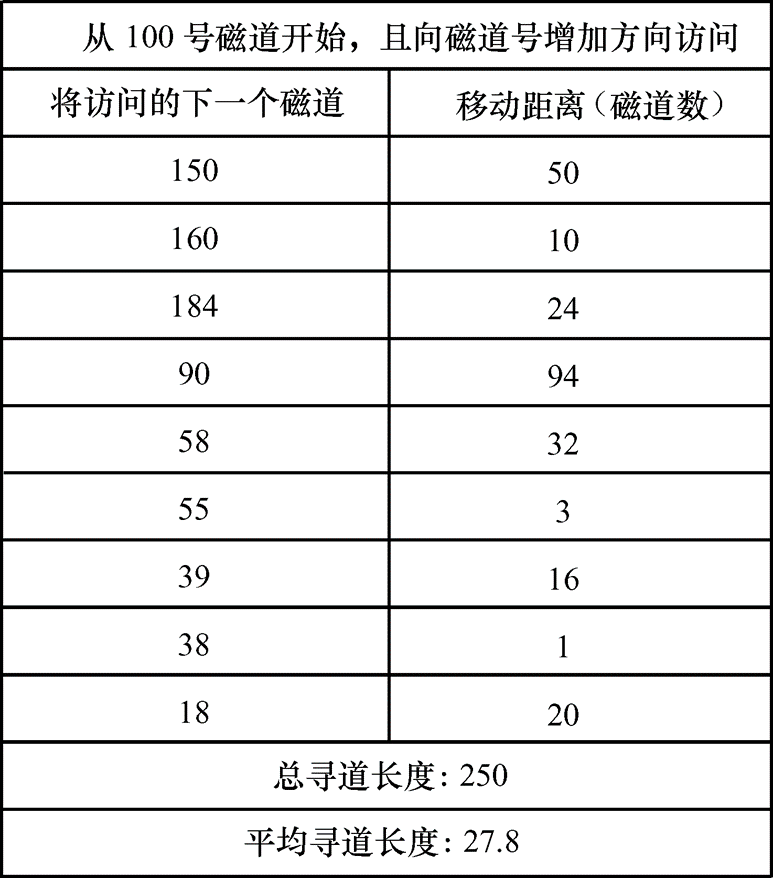
-
-
循环扫描算法(CSCAN):移动臂总是从0号柱面至最大号柱面顺序扫描,然后,直接返回0号柱面重复进行,归途中不再服务,构成了一个循环,这就减少了处理新来请求的最大延迟。CSCAN算法规定磁头单向移动。
-
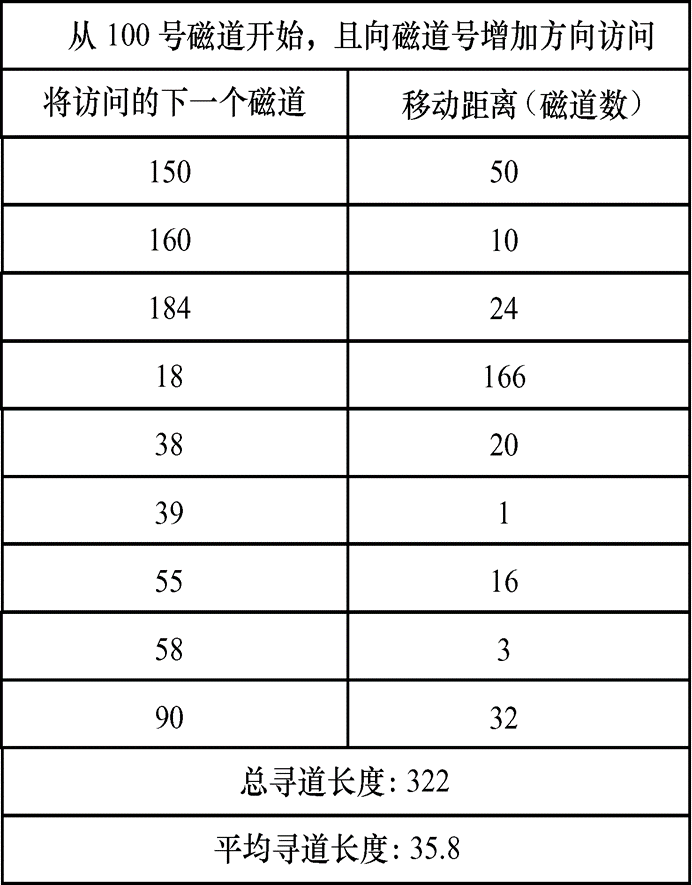
-
-
分步扫描N-Step-SCAN算法:将磁盘请求队列分成若干个长度为N的子队列,磁盘调度将按FCFS算法依次处理这些子队列。而每处理一个队列时又是按SCAN算法,对一个队列处理完后,再处理其他队列。 当正在处理某子队列时,如果又出现新的磁盘I/O请求,便将新请求进程放入其他队列,这样就可避免出现粘着现象。当N值取得很大时,会使N步扫描法的性能接近于SCAN算法的性能;当N=1时,N步SCAN算法便蜕化为FCFS算法。
-
FSCAN算法:FSCAN算法实质上是N步SCAN算法的简化, 即FSCAN只将磁盘请求队列分成两个子队列。一个是由当前所有请求磁盘I/O的进程形成的队列,由磁盘调度按SCAN算法进行处理。在扫描期间,将新出现的所有请求磁盘I/O的进程, 放入另一个等待处理的请求队列。这样,所有的新请求都将被推迟到下一次扫描时处理。
-
- 提高I/O速度的方法
- 提前读:用户经常采用顺序方式访问文件的各个盘块上的数据,在读当前盘块时已能知道下次要读出的盘块的地址,因此,可在读当前盘块的同时,提前把下一个盘块数据也读入磁盘缓冲区。这样一来,当下次要读盘块中的那些数据时,由于已经提前把它们读入了缓冲区,便可直接使用数据,而不必再启动磁盘I/O,从而,减少了读数据的时间,也就相当于提高了磁盘I/O速度。
-
延迟写:在执行写操作时,磁盘缓冲区中的数据本来应该立即写回磁盘,但考虑到该缓冲区中的数据不久之后再次被输出进程或其他进程访问,因此,并不马上把缓冲区中数据写盘,而是把它挂在空闲缓冲区队列的末尾。随着空闲缓冲区的使用,存有输出数据的缓冲区也不停地向队列头移动,直至移动到空闲缓冲区队列之首。当再有进程申请缓冲区,且分到了该缓冲区时,才把其中的数据写到磁盘上。只要存有输出数据的缓冲区还在队列中,任何访问该数据的进程,可直接从中读出数据,不必再去访问磁盘。这样做,可以减少磁盘的I/O时间。
- 虚拟盘:虚拟盘是指用内存空间去仿真磁盘。该盘的设备驱动程序可以接受所有标准的磁盘操作,但这些操作的执行,不是在磁盘上而是在内存中。操作过程对用户是透明的,即用户并不会发现这与真正的磁盘操作有什么不同,而仅仅是更快一些。虚拟盘是易失性存储器,一旦系统或电源发生故障,或重新启动系统时,原来保存在虚拟盘中的数据会丢失。因此,该盘常用于存放临时文件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号