
轻松学习redis——第一篇
前言:
学习本是快乐的事情!!想必大家,经常在学习的时候,看到很多很难理解的概念,很多初学者都无法摸透,看完之后又忘记了。这种学习方式太不快乐了。
所以,今天,我想用一种轻松的方式,跟大伙们一起来学习redis。我会在抽象的概念中,举例子,把概念形象生动的描绘出来。让读者们轻松阅读,轻松学习。
let's go!!
正文:
1.首先给大伙提供一下,官方文档,
英文文档:https://redis.io/
中文文档:http://www.redis.cn/commands.html
我们要学会去观看文档。最好是英文文档。
官网中简单的描述了,redis是个啥东西:
Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache, and message broker. Redis provides data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes, and streams. Redis has built-in replication, Lua scripting, LRU eviction, transactions, and different levels of on-disk persistence, and provides high availability via Redis Sentinel and automatic partitioning with Redis Cluster.
翻译过来就是:
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
好了,概念很生硬。我们就理解成,redis是一个支持多数据结构类型,效率极高的存储系统即可。那么接下来就去分析这句话。
还有,在这里,我们需要先在linux操作系统中安装一下redis。可以去这里(https://www.cnblogs.com/takeyblogs/p/14316098.html)照着安装一下。
2.我们来看看,redis支持存储的5种类型的数据结构,看下图:
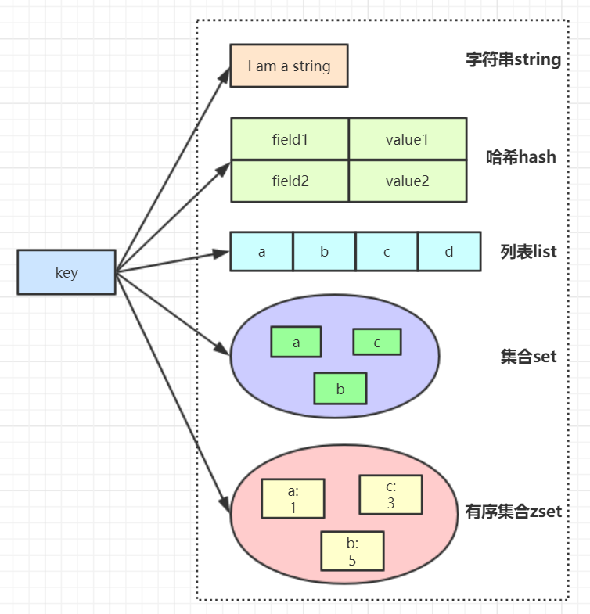
(1)第一种是,string类型。
先介绍一下,字符串结构常用的操作:
SET key value //存入字符串键值对
MSET key value [key value...] //批量存储字符串键值对
SETNX key value //存入一个不存在的字符串键值对
GET key //获取一个字符串键值
MGET key [key...] //批量获取字符串键值
DEL key [key...] //删除一个键
EXPIRE key seconds //设置一个键的过期时间(秒)
原子加减:
INCR key //将key中存储的数字值加1
DECR key //将key中存储的数字值减1
INCRBY key increment //将key所存储的值加上increment
DECRBY key decrement //将key所存储的值减去decrement
这个枯燥的指令是必须要记住的,因为这基础。接下来,我来举例子说明一下string数据结构的应用场景:
当我们对数据库查询比较频繁的时候,我们可以用redis缓存,将数据存储在缓存中,来提高查询的效率。因为查询数据库,IO操作的效率远低于redis缓存查询的效率。
如果有一个表:

(1)单值存在,我们可以利用string数据结构的set操作:SET key value
将name当作key,balance当作value,即 :
SET zhuge 1888
SET yangguo 16000
。。。
我们可以通过 GET key,来获取set入的值:
GET zhuge
我们就可以获取到1888 这个值。
这是string最常用,也是最基础的一个使用方式了。
(2)我们可以用来做简单的分布式锁:
SETNX product:10001 true //返回1代表获取锁成功
SETNX product:10001 true //返回0代表获取锁失败
。。。执行业务操作
DEL product:10001 //执行完业务后释放锁
SET prodoct:10001 true ex 10 nx //防止程序意外终止导致死锁。给key值设置一个时间
说明:例如有一个请求,先设置锁成功了,那么另一个请求就无法再设置锁,直到等待第一个请求结束去删除掉锁的时候,其他请求才可以去设置锁。
(3)计数器:我们微信观看公众号推文的时候,文章末尾总会出现一个计数器,来展示该文章有多少人看过,如图:
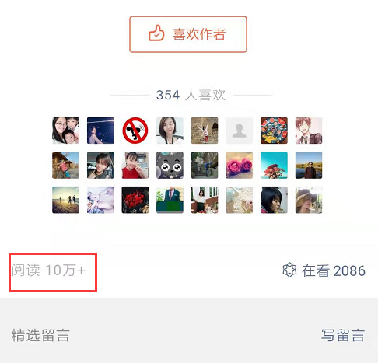
那么我们可以用redis来实现这个功能:
INCR article:readcount:{文章id} //用户每点击一次,就执行一下这个命令,去给"article:readcount:{文章id}"这个key的值加1
GET article:readcount:{文章id} //通过GET命令,去获取"article:readcount:{文章id}"这个key的值
string的数据结构存在,就讲到这里,算是比较简单的操作。技术存储键值对就可以了。
(2)第二种是Hash数据结构: hash我们并不陌生,java中常用的hashmap是键值对的存在数据结构,我们不妨可以联系在一起,进行学习。
我们先看看hash的常用操作:
HSET key field value //存储一个哈希表key的键值
HSETNX key field value //存在一个不存在的哈希表key的键值
HMSET key field value [field value ...] //在一个哈希表key中存储多个键值对
HGET key field //获取哈希表key对应的field键值
HMGET key field [field ...] //批量获取哈希表key中的field键值
HDEL key field [field...] //删除哈希表key 中的field的键值
HLEN key //返回哈希表key中field的数量
HGETALL key //返回哈希表key中所有的键值对
HINCRBY key field increment //为哈希表key中field键的值加上增量increment
好了,这些命令还是得记一记的,接下来我们举例子:
(1)如果有一个数据表:

我们可以用hash数据结构来存在对象:
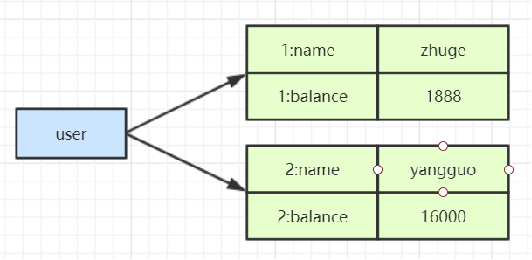
命令:HMSET user {userId}:name zhuge {userId}:balance 1888 [field value...]
具体操作:
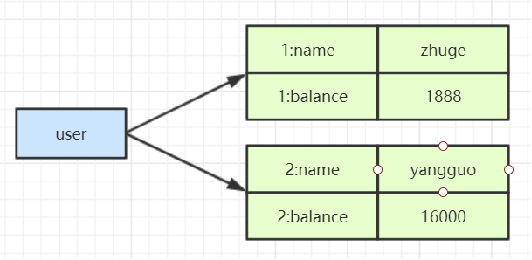
HMSET user 1:name zhuge 1:balance 1888 2:name yangguo 2:balance 16000
HMGET user 1:name 1:balance 2:name 2:balance
操作完之后,我们就已经把id为1,和2的2个对象存入hash数据结构中了,大致结构如图:
(2)电商购物车:我们对购物车并不陌生,那么购物车的功能我们也可以借助redis来实现,先看看一个购物车的图:
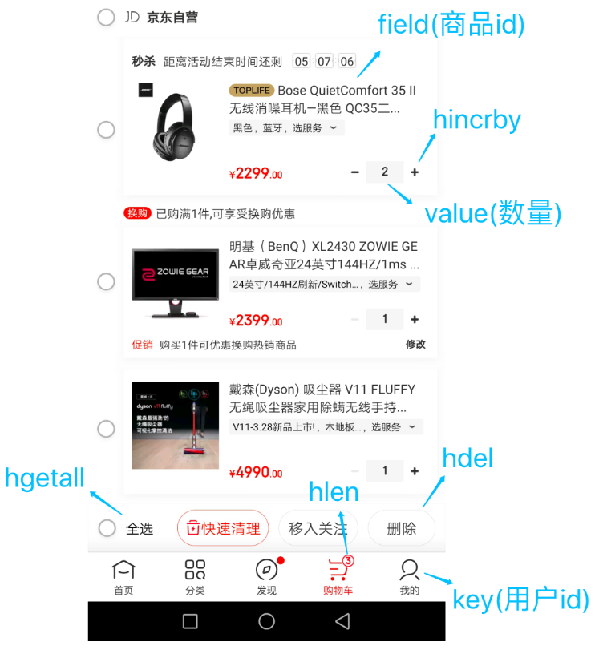
(1)我们可以以用户ID为key
(2)商品ID为field
(3)商品数量为value
购物车操作:
1)添加商品:hset cart:1001 10088 1
2) 增加数量:hincrby cart:1001 10088 1
3) 商品总数:hlen cart:1001
4) 删除商品:hdel cart:1001 10088
5) 获取购物车所有商品:hgetall cart:1001
OK,到处位置,购物车的简单功能实现就是这些,主要就是对redis hash存在结构的简单操作。
那么hash结构的优缺点是什么呢:
优点:
1)同类数据归类整合存在,方便数据管理 (如上面的购物车例子,我们可以把每个人的购物车都归类起来,即每个key值每个人的购物车,key中的filed-value键值对所代表这个人购物车下的商品及数量)
2)相比string操作消耗内存和cpu更小了
3)相比string存在更节省空间了
缺点:
1)过期功能不能使用在field上,只能使用在key上。 (存储格式,如下图,类似于一个hashMap<key,hashMap<field,aclue>>,双层hashmap结构)
2)redis集群架构下不适合大规模使用。 (因为hash结构是一个整体,原则上不能分开存储,所以如果有多台机器,我们只能存储在其中一台机器上面,这样如果hash里面存储了很大的值,就会导致存储不平衡,大多数请求都打在一台机器上,所以不太适合)

(3)List结构:
List常用操作:
LPUSH key value [value...] //将一个或者多个值value插入到key列表的表头(最左边,下图,LPUSH 指的是从列表的左边插入,L指的是left)
RPUSH key value [value...] // /将一个或者多个值value插入到key列表的表尾(最右边,下图,LPUSH 指的是从列表的右边插入,R指的是right)
LPOP key //移除并返回key的头元素
RPOP key //移除并返回key的尾元素
LRANGE key start stop //返回key列表中指定区间内的元素,区间以偏移量start和stop指定
BLPOP key [key...] timeout //从key列表表头弹出一个元素,若列表中没有元素,阻塞等待timeout秒,如果timeout=0,则一直阻塞等待。
BRPOP key [key...] timeout //从key列表表尾弹出一个元素,若列表中没有元素,阻塞等待timeout秒,如果timeout=0,则一直阻塞等待。
(B表示 BLOCK ,L表示left,R表示right。这2个命令可以当做消息队列来用。即如果有消息就消费掉,如果没有消息就处于阻塞状态)
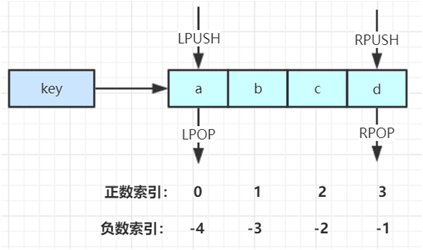
常用的数据结构:
Stack(栈,栈的特点先进后出FILO):LPUSH+LPOP。 即从队头进从队头出,就可以实现先进后出。
Queue(队列,队列的特点先进先出FIFO):LPUSH+RPOP。 即从队头进,从队尾出,就可以实现先进先出。
Blocking MQ(阻塞队列): LPUSH+BRPOP。即从队头进,从队尾阻塞出,就可以实现阻塞队列。
举例子:我们对微博和微信公众号消息流并不陌生吧。我们每天都会随手刷一刷,如下图:
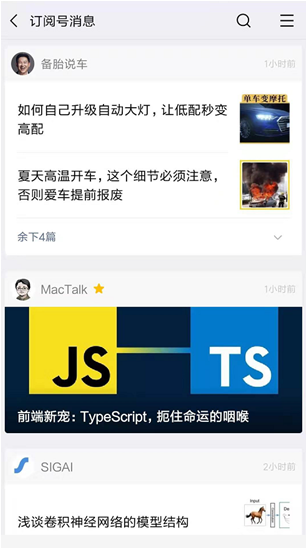
以上2张图是微博和公众号的页面。相信我们经常会看见这个页面。我们可以利用我们学习的redis知识,来实现这些功能。
就拿第二张图片来说,我关注了MacTalk和备胎说车2个大V。他们发推文的时候,我可以用一个List来存储他们的消息:
1)MacTalk发推文,消息ID为10081;
命令:LPUSH msg:{userId} 10081 //把10081这条消息插入到队列的头部
2)备胎说车发推文,消息ID10082
命令:LPUSH msg:{userId} 10082 //把10082这条消息插入到队列的头部
3)查看最新消息:
命令:LRANGE msg:{userId} 0 4 //从头部开始查询队列下标为0-4的元素
简简单单的几个命令,就可以高性能的完成这个功能。当然微博和微信公众号里面的实现逻辑不仅仅是这么简单,还需要根据功能去分析,这里只是简单的代入。还需要各位小宝贝自行脑补思考。
(4)Set结构:
常用的Set操作:
SADD key member [member ...] //往集合key中存入元素,元素存在则忽略,若集合key不存在则新建集合key
SREM key member [member...] //从集合key'中删除元素
SMEMBERS key //获取集合key中所有元素
SCARD key //获取集合key的元素个数
SISMEMBER key member //判断member元素是否在集合key中
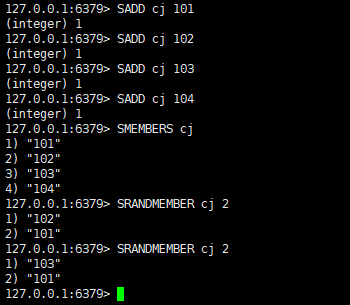
SRANDMEMBER key [count] //从集合key中选出count个元素,元素不从集合key中删除
SPOP key [count] //从集合key中选出count个元素,元素从集合key中删除
上面是Set(集合)结构的一些基操。接下来,是Set结构的一些运算操作:
SINTER key [key...] //交集运算
SINTERSTORE destination key [key...] //将交集的结构存入新集合destination中
SUNION key [key...] //并集运算
SUNIONSTORE destination key [key...] //将并集的结构存入新集合destination中
SDIFF key [key..] //差集运算
SDIFFSTORE destination key [key...] //将差集的结构存入新集合destination中
OK,概念非常生硬,这里画几个图来解释一下:
1)什么是集合运算:
例如:有3个集合,集合set1,集合set2,集合set3
集合set1通过SADD set1 a b c,执行之后通过SMEMBERS set1 查询出来集合set1 ={a,b,c}
集合set2通过SADD set2 b c d,执行之后通过SMEMBERS set2 查询出来集合set2 ={b,c,d}
集合set2通过SADD set3 c d e,执行之后通过SMEMBERS set3 查询出来集合set2 ={c,d,e}


那么我们执行 SINTER set1 set2 set3 ,我们会获得set1,set2,set3,3个集合的交集我们可以发现3个集合都有“c”,所以我们获得 {c} 
那么我们执行 SUNION set1 set2 set3 ,我们会获得set1,set2,set3,3个集合的并集,我们把集合的所有元素加起来并去除重复的,所以我们获得 {a,b,c,d,e} 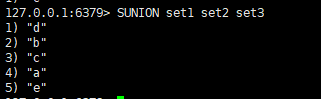
那么我们执行 SDIFF set1 set2 set3 ,我们会获得set1,set2,set3,3个集合的差集(差集我们可以用第一个减去后面的来实现),所以我们获得 {a} 
2)拿几个生活中的例子来说说Set集合的运用吧。看下图:

上图是我们经常会在微信小程序上看见的抽奖活动,
1)当我们点击“参与抽奖”时:
SADD key {userId} //我们将我们的userId存入集合key中,有则不存
2)按钮“参与抽奖”下面有一排头像,我们可以查看参与抽奖的用户:
SMEMBERS key //查看key中所有的元素
3)开奖的时候,我们可以执行:
SRANDMEMBER key [count] //获取集合key中count名用户,用户不移除,接着下轮抽奖
或者:
SPOP key [count] //获取集合key中count名用户,用户移除,下轮抽奖不参加了
3)我们日常经常会刷微博吧,细心的小伙伴们肯定会发现,微博经常给我们推荐”共同关注“朋友,”我关注的人也关注了她“,如下图:

ok,那这个功能是怎么实现的呢?
例子:假如 刘一 关注了 王二,张三,李四 即 刘一 -》 {王二,张三,李四}
王二 关注了 张三,孙五 即 王二 -》 {张三,孙五}
张三 关注了 刘一,李四,孙五 即 张三 -》 {刘一,李四,孙五}
1》 那么刘一 跟 张三 的共同关注好友,就可以利用命令:SINTER liuList zhangList ,获取到交集的结果是 =》{李四}
2》 如果刘一 来到了 孙五 的微博,系统就会给刘一展示刘一关注的人中谁关注了孙五:
我们就可以利用命令:
SISMEMBER wangList sun //查看刘一关注的王二中是否关注了孙五
SISMEMBER zhangList sun //查看刘一关注的张三中是否关注了孙五
SISMEMBER liList sun //查看刘一关注的李四中是否关注了孙五
如果存在的话,说明他们也关注了孙五。 好了,可能名字比较多,小伙伴们细品,我相信可以品清楚的。
4)我们日常中也经常刷淘宝吧,相信对下面这个图,肯定不陌生:

当我们在选择条件的时候,最终系统会快速的帮我们筛选出来满足条件的商品,那它是怎么实现的呢?
1》我们把每一个选项对应的商品都存在一个集合中,例如:
SADD brand:huawei P40 //创建一个集合 brand:huawei 把元素 P40 存入
SADD brand:xiaomi mi-10 //创建一个集合 brand:xiaomi 把元素 mi-10 存入
SADD brand:iphone iphone12 //创建一个集合 brand:iphone 把元素 iphone12 存入
SADD os:android P40 mi-10 //创建一个集合 os:android 把元素 P40 mi-10 存入
SADD cpu:brand:inter P40 mi-10 //创建一个集合 cpu:brand:inter 把元素 P40 mi-10 存入
SADD ram:8G P40 mi-10 iphone12 //创建一个集合 ram:8G 把元素 P40 mi-10 iphone12 存入
当我们选择选项为安卓系统,CPU是inter,内存是8G的时候,可以执行命令:
SINTER os:android cpu:brand:inter ram:8G ==》 {P40 mi-10} //我们求os:android cpu:brand:inter ram:8G 这3个集合的交集,为 {P40 mi-10}
好了,到此为止Set结构就讲完了,举的例子比较多,小伙伴们可以细细品味。然后结合你在公司中具体的项目,看看是否也能运用redis来操作。
(5)ZSet 有序集合结构:
常用操作:
ZADD key score member [[score member]...] //往有序集合key中存放带分值(排序的值)的元素
ZREM key member [member...] //从有序集合key中删除元素
ZSCORE key member //返回有序集合key中元素member的分值
ZINCRBY key increment member //为有序集合key中元素member的分值加上increment
ZCARD key //返回有序集合key中的元素个数
ZRANGE key start stop [WITHSCORES] //正序获取有序集合key从start下标到stop下标的元素
ZREVRANGE key start stop [WITHSCORES] //倒序获取有序集合key从start下标到stop下标的元素
集合操作:
ZUNIONSTORE destkey numkeys key [key...] //并集计算
ZINTERSTORE destkey numkeys key [key...] //交集计算
1)我们每天在刷微博热搜的时候,都是有顺序排列的,有榜一,榜二等等,如下图:

那么我们用有序集合ZSet来实现排行榜:
1》点击新闻:
ZINCRBY hotNews:20210130 1 1001 //我们给集合 hotNews:20210130 中的新闻ID为1001的新闻加1
2》展示当日排行前十:
ZREVRANGE hotNews:20210130 0 9 WITHSCORES //倒序的查询集合 hotNews:20210130 10条新闻
3》七日搜索榜单计算:
ZUNIONSTORE hotNews:20210130-20210205 7 hotNews:20210130 hotNews:20210131... hotNews:20210205
4》展示七日排行前十:
ZREVRANGE hotNews:20210130-20210205 0 9 WITHSCORES
总结:
上面就是redis中,5大数据结构的操作。希望对初学者能够有帮助,如果对你有帮助的话,请留下的赞,如果有问题可以留言,我会尽量回复哦!!!


