【JUC 并发编程】— AQS 源码探索之独占式
上篇通过 AQS 简单地实现了一个独占锁,锁最主要的方法就是 lock() 和 unlock(),那我们就从 lock 走起
public void lock() {
sync.acquire(1);
}
获取(不响应中断)
自定义组件中独占式获取便是调用同步器的模板方法 acquire(int arg),那就看看这个方法
/**
* 独占式获取,忽略中断
*/
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
这是个入口方法,现在目测这个方法的大概逻辑是:
- 尝试获取同步状态(tryAcquire 这个方法是我们自定义同步组件中需要重写的)
- 获取失败后生成一个 waiter,并把这个 waiter 请求入队
大概你很好奇 waiter 具体是啥,还记得 AQS 内部维护了一个 FIFO 队列么,队列中的节点就是这个 waiter,在源码中的体现就是 AQS 中的一个静态内部类 Node
static final class Node {
static final Node SHARED = new Node();
static final Node EXCLUSIVE = null;
/**
* 节点等待状态值
*/
/**
* 同步队列中的线程等待超时或取消,
* 需要从队列中取消等待,
* 节点进入该状态将不会变化。
*/
static final int CANCELLED = 1;
/**
* 后继节点处于等待状态,
* 而当前节点的线程如果释放了同步状态或者被取消,
* 将会通知后继节点,使得后继节点继续运行
*/
static final int SIGNAL = -1;
static final int CONDITION = -2;
static final int PROPAGATE = -3;
/**
* 节点等待状态
*/
volatile int waitStatus;
/**
* 前驱节点
*/
volatile Node prev;
/**
* 后继节点
* 需要注意:
* 入队操作只有在设置 tail 成功后才指定前驱结点的 next 属性;
* 节点的 next 节点为 null 并不意味着当前节点就是队列的末尾;
* 被取消节点的 next 指向该节点本身,而不是 null。
*/
volatile Node next;
/**
* 入队节点中的线程
* 构造的时候初始化,用完后置为null
*/
volatile Thread thread;
Node nextWaiter;
/**
* Returns true if node is waiting in shared mode
*/
final boolean isShared() {
return nextWaiter == SHARED;
}
/**
* 获取前驱结点
* 进行空指针检查,但是在使用过程中,前驱结点不可能为 null,
* 空指针检查可以去掉,但现在这么做是为了帮助 VM(不是很懂)
*
* Returns previous node, or throws NullPointerException if null.
* Use when predecessor cannot be null. The null check could
* be elided, but is present to help the VM.
*
*/
final Node predecessor() throws NullPointerException {
Node p = prev;
if (p == null)
throw new NullPointerException();
else
return p;
}
Node() { // Used to establish initial head or SHARED marker
}
Node(Thread thread, Node mode) { // Used by addWaiter
this.nextWaiter = mode;
this.thread = thread;
}
Node(Thread thread, int waitStatus) { // Used by Condition
this.waitStatus = waitStatus;
this.thread = thread;
}
}
addWaiter 添加节点
快速添加
回头再看 acquire() 中的 addWaiter() 方法
private Node addWaiter(Node mode) {
// 创建节点,Node 中的线程也就是这时候初始化
Node node = new Node(Thread.currentThread(), mode);
// Try the fast path of enq; backup to full enq on failure
// 这里尝试快速入队,乐观的做法
Node pred = tail;
// tail 节点不为 null
if (pred != null) {
// 设置前驱节点
node.prev = pred;
// CAS 设置当前节点为 tail 节点
if (compareAndSetTail(pred, node)) {
// 设置成功,再设置前驱结点的next 为当前节点
pred.next = node;
return node;
}
}
// 快速入队失败,则调用真正的入队方法
enq(node);
return node;
}
addWaiter() 方法就是入队操作,只不过在代码实现中先尝试使用快速入队方式,也就是乐观的认为头结点尾节点都已初始化好,CAS 也能成功。但是如果这种方式失败了,那么就调用真正的入队方法 enq() 进行入队。
enq 入队
接下来看看 enq() 方法
/**
* 入队操作
* @param 等待入队的节点
* @return 前驱节点
*/
private Node enq(final Node node) {
for (;;) {
Node t = tail;
// 队列还没初始化,必须先初始化
if (t == null) { // Must initialize
// CAS 设置头结点,这里可以看到头结点是个空节点
if (compareAndSetHead(new Node()))
// 初始化的时候头结点尾节点指向同一个
tail = head;
} else {
// 设置前驱节点
node.prev = t;
// CAS 设置当前节点为尾节点
if (compareAndSetTail(t, node)) {
// 设置成功,再设置前驱结点的next 为当前节点;
// 设置失败,则重试
t.next = node;
// 返回前驱节点
return t;
}
}
}
}
acquireQueued 入队后获取
enq() 方法的作用就是入队操作,如果队列还没初始化则先初始化。到现在为止我们至少知道了 addWaiter() 方法的作用,回头再看看 acquire() 中的 acquireQueued() 方法
/**
* 自旋方式尝试获取同步状态
*/
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
// 获取前驱节点
final Node p = node.predecessor();
// 前驱节点是头接待,再尝试获取
if (p == head && tryAcquire(arg)) {
// 获取成功后,设置当前节点为头结点
// 注意:setHead() 方法并没有进行同步
// 原因是只会有一个线程获取同步状态成功
// 所以这里是单线程环境
setHead(node);
// 前驱结点(上一个头结点)prev本来就为null,next = null,
// 那么该节点就没有对象与之关联,易于 GC 回收
p.next = null; // help GC
failed = false;
return interrupted;
}
// 是否需要阻塞或者被中断
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
上述代码通过让节点自旋的方式进行获取,每个节点都在自省地观察,当条件满足后,获取到同步状态,就可以从这个自旋过程中退出。
代码中还体现了只有前驱节点是头节点才能尝试获取,原因有两个:
- 头结点是成功获取到同步状态的节点,而头结点的线程释放同步状态之后,会唤醒其后继节点,后继节点被唤醒后需要检查自己的前驱节点是否为头结点。
- 维护同步队列的 FIFO 原则。
自旋过程示意图如下:
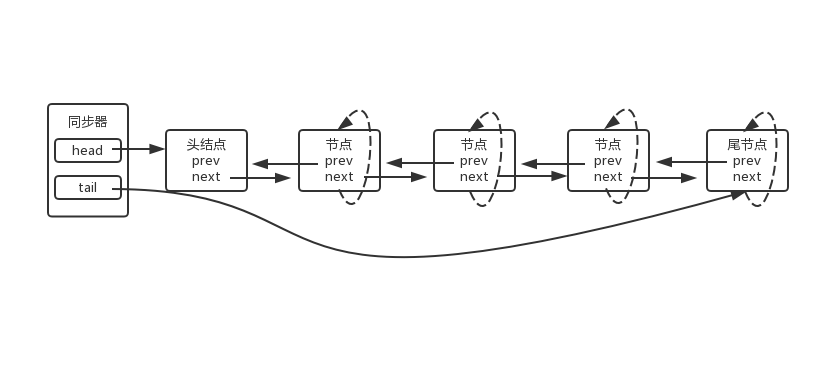
shouldParkAfterFailedAcquire 是否需要阻塞
获取同步状态失败的线程是不是会一直自旋,其实也不是。注意上面代码中 shouldParkAfterFailedAcquire() 方法,顾名思义,就是获取失败后是否应该阻塞,进到方法里面
/**
* 如果线程需要阻塞则返回 true,这个方法是自旋过程中主要的控制信号
*/
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
// 获取前驱节点的等待状态
int ws = pred.waitStatus;
// 如果状态为 SIGNAL,则安全的阻塞吧
if (ws == Node.SIGNAL)
return true;
// 大于0就是 CANCELLED 状态
if (ws > 0) {
// 跳过该节点,直到找到不是 CANCELLED 状态的前驱节点
// 这里相当于从同步队列中剔除了 CANCELLED 状态的节点
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
从上面代码中可以看到只有前驱节点的状态为 SIGNAL,当前节点才需要阻塞,否则继续自旋。
parkAndCheckInterrupt 阻塞
回头再看 acquireQueued() 方法,里面还有个 parkAndCheckInterrupt() 方法,方法名告诉我们它是阻塞线程然后检查中断,看看具体代码
/**
* 阻塞当前节点并且检查中断
* @return {@code true} if interrupted
*/
private final boolean parkAndCheckInterrupt() {
LockSupport.park(this);
return Thread.interrupted();
}
这个方法很简答,阻塞线程并检查中断,有两种情况:
- 线程没有中断,那么阻塞线程,方法返回 false;
- 线程中断,
LockSupport.park(this)直接返回,方法返回 true
然后继续尝试获取,如果获取成功,acquireQueued() 方法则返回中断状态。有个问题就是为什么返回的是中断状态,这里有两点需要注意:
- acquire() 方法是忽略中断的。
- Thread.interrupted() 和 thread.isInterrupted() 是不一样的,前者是 Thread 类的静态方法,检查中断后并清除了中断标记,也就是说线程在中断后调用这个方法,线程的中断标记就被清除了;而后者是实例方法,只是简单的检查中断,并不会清除中断标记。
再回到 parkAndCheckInterrupt() 方法,如果线程中断,这个方法返回后该线程就被清除了中断标记,但是 acquire() 方法又不响应中断,所以必须有个重新中断当前线程的操作,这也就是 acquire() 方法中 selfInterrupt() 的作用
/**
* Convenience method to interrupt current thread.
*/
private static void selfInterrupt() {
// 中断当前线程
Thread.currentThread().interrupt();
}
cancelAcquire 取消获取
如果 acquireQueued() 方法异常,则需要取消当前节点进行同步状态获取,也就是 cancelAcquire() 方法
/**
* 取消获取
*/
private void cancelAcquire(Node node) {
if (node == null)
return;
// 清空线程
node.thread = null;
// 跳过已取消的前驱节点
Node pred = node.prev;
while (pred.waitStatus > 0)
node.prev = pred = pred.prev;
Node predNext = pred.next;
// 设置等待状态为取消
node.waitStatus = Node.CANCELLED;
// 如果是尾节点,则设置前驱节点为尾节点
if (node == tail && compareAndSetTail(node, pred)) {
// 设置尾节点的后继节点为 null
compareAndSetNext(pred, predNext, null);
} else {
// 不是头结点也不是尾节点
int ws;
if (pred != head &&
((ws = pred.waitStatus) == Node.SIGNAL ||
(ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) &&
pred.thread != null) {
Node next = node.next;
if (next != null && next.waitStatus <= 0)
compareAndSetNext(pred, predNext, next);
} else {
// 头结点唤醒后继节点
unparkSuccessor(node);
}
// 取消节点后继节点指向自己
node.next = node; // help GC
}
}
唤醒后继节点 unparkSuccessor()
private void unparkSuccessor(Node node) {
// 尝试初始化节点状态
int ws = node.waitStatus;
if (ws < 0)
compareAndSetWaitStatus(node, ws, 0);
// 如果后继节点不存在或者已经取消
// 那么从尾部开始遍历找到后继节点
Node s = node.next;
if (s == null || s.waitStatus > 0) {
s = null;
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
if (s != null)
// 唤醒后继节点线程
LockSupport.unpark(s.thread);
}
响应中断获取
上文说道,acquire() 方法是不响应中断的,线程检测到中断后只是重新中断自己,如果想要响应中断怎么办?AQS 提供了响应的模板方法 acquireInterruptibly()
public final void acquireInterruptibly(int arg)
throws InterruptedException {
// 首先检测中断,如果中断,则抛异常
if (Thread.interrupted())
throw new InterruptedException();
if (!tryAcquire(arg))
doAcquireInterruptibly(arg);
}
没有中断,则尝试获取同步状态,获取失败,则执行 doAcquireInterruptibly() 方法
private void doAcquireInterruptibly(int arg)
throws InterruptedException {
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
// 区别在这里
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
区别显而易见,这个方法中,线程如果检测到异常,则直接抛出异常。
超时获取
AQS 还提供了超时获取的方法
private boolean doAcquireNanos(int arg, long nanosTimeout)
throws InterruptedException {
long lastTime = System.nanoTime();
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return true;
}
// 小于或等于0,说明已经超时
if (nanosTimeout <= 0)
return false;
if (shouldParkAfterFailedAcquire(p, node) &&
// 超时时间与自旋时间阈值比较
nanosTimeout > spinForTimeoutThreshold)
// 进行超时阻塞
LockSupport.parkNanos(this, nanosTimeout);
long now = System.nanoTime();
// 重新计算超时时间
nanosTimeout -= now - lastTime;
lastTime = now;
// 响应中断
if (Thread.interrupted())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
超时获取逻辑重点在于超时时间的判断,如果 nanosTimeout <= 0,说明已超时,直接返回;如果是需要阻塞并且 nanosTimeout <= spinForTimeoutThreshold(1000 纳秒),则进入快速自旋,因为非常短时间等待无法做到精确,所以这时候自旋会比超时等待更快更准,而且对于这么短的超时时间,粗略的估计也能够提高响应性。如果时间大于这个阈值,那么则进行超时等待。等待结束后,再重新计算 nanosTimeout。另外,超时等待获取也是能够响应中断的。
释放
说完了获取操作,再来看看释放操作
public final boolean release(int arg) {
// 释放成功
if (tryRelease(arg)) {
// 唤醒后继节点
Node h = head;
// 头结点的等待状态为0,说明队列刚初始化
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
流程图
AQS 独占式获取流程图如下图所示:
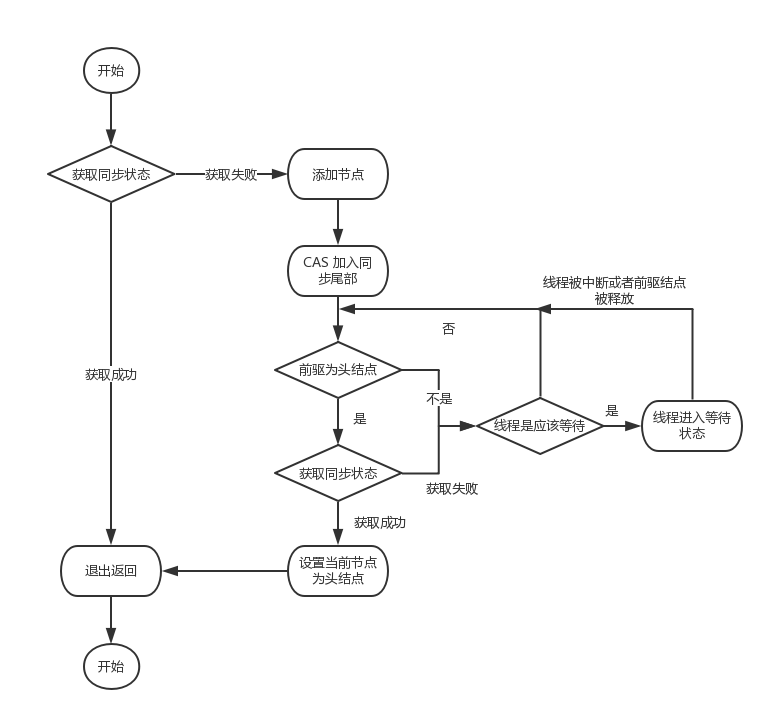
AQS 独占式获取关键点在于获取失败的节点进入队列后的操作,先是自旋检查自己的前驱结点是否为头节点,如果是,再尝试获取;如果不是,就判断自己是否应该阻塞,判断条件是前驱节点的等待状态是否为 signal。这里可能或许会纳闷,前驱节点的等待状态何时会变成 signal?在判断是否需要阻塞的方法 shouldParkAfterFailedAcquire 中有波操作如下:
- 前驱节点等待状态为 signal,直接返回 true,需要等待
- 前驱节点等待状态为大于 0,也就是取消状态,那么需要做的是找到没有取消的前驱节点,返回 false,不需等待
- 其他情况,也就是等待状态小于或等于 0,通过 CAS 设置等待状态为 signal。那下次自旋再判断的时候前驱节点状态就是 signal了,当前节点也就需要阻塞了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号