用2263份证件照图片样本测试how-old.net的人脸识别
 用2263份证件照图片样本测试how-old.net的人脸识别
用2263份证件照图片样本测试how-old.net的人脸识别
上一年也就是这个时候微软根据自己的人脸识别API推出了一个识别照片中人脸年龄和性别的网站——http://how-old.net,小伙伴们各种玩耍,一年后的今天突发“奇想”地想测试一下这个网站的识别情况。正好手里有3万多份标识有身份证信息、性别及照片拍摄时间的证件照(别问我从哪儿弄的,这玩意儿你懂的)。今天就写了个脚本来测试一下。测试识别的目标有两个:
- 性别
- 年龄
提交数据获得识别结果
寻找接口
首先,查看一下how-old.net的提交接口。

用Chrome查看一下网络请求的情况

查看一下前三个请求的数据情况:
第一个:
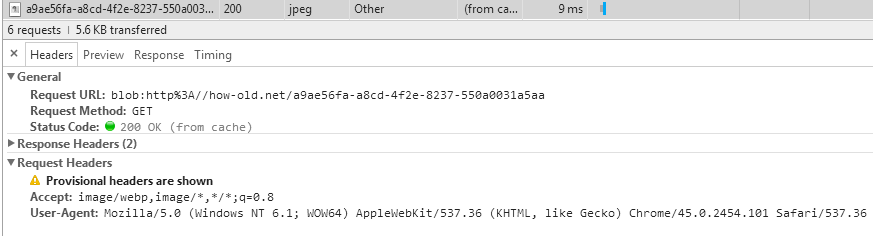
第二个:

第三个:
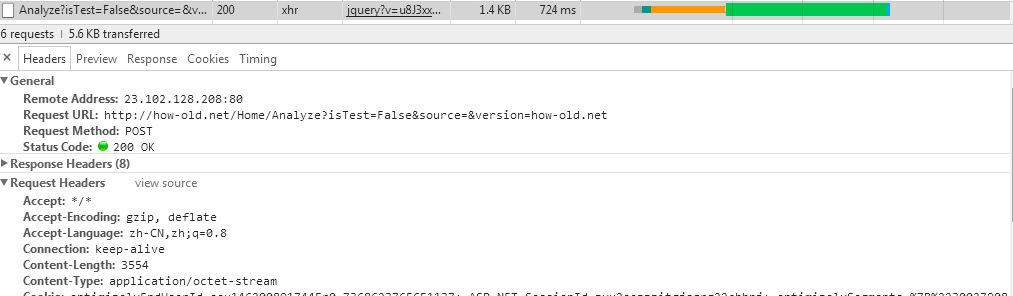

很奇怪有没有,第一个是一个bolb地址,第二个是图片的base64编码后的字符,第三个倒像是真正的请求,可查看请求中,尽然找不到对应图片的参数。再查看一下第三个请求的响应:

嗯,一个添加转移符号的json数据,我们想要的识别结果确实在里面。这就确定这个请求就是我们需要的请求接口,现在的问题是怎样上传图片数据呢?
我们不妨从头看一下这三个请求。第一个中的bolb地址和第二个请求中的base64数据是怎么个情况呢?在Stack Overflow上查找到了下面的信息:

简单来说就是,在二进制数据以流式方式提交的时候,有这样一个模式:生成一个bolb地址做本机数据访问 -> 访问具体的信息是是base64编码的的文件 -> 对指定接口以流式上传数据。也就是说前两个请求时发生在本机的,是对本地资源的访问,第三个请求才是真正的请求,只不过数据是前两个“本机请求”生成的流式数据。
上传数据获得识别结果
这样我们就得到了我们需要的访问接口及数据提交方式:
- 接口:
- 提交方式:POST流式提交
我们可以在上面第三个请求图中查看到请求参数及header,cookies等信息。使用requests库能很容易做到数据流式提交,针对此接口请求代码如下:
#访问主页获得cookie
t = requests.get("http://how-old.net",timeout=60)
_cookies = t.cookies
t.close()
#构建请求头
headers = {
"Content-Type": "application/octet-stream",
"Referer": "http://how-old.net/",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36"
}
info = None
#POST方式流式提交(pic_name是图片地址)
with open(pic_name, 'rb') as f:
r = requests.post("http://how-old.net/Home/Analyze?isTest=False&source=&version=how-old.net",
data=f,
headers=headers,
cookies=_cookies,
timeout=10)
info = r.content
将返回的识别数据存储在info中,其样式像下面这样:
"{\"AnalyticsEvent\":\"[\\r\\n {\\r\\n \\\"face\\\": {\\r\\n \\\"age\\\": 16.0,\\r\\n \\\"gender\\\": \\\"Male\\\"\\r\\n },\\r\\n \\\"event_datetime\\\": \\\"2016-04-30T11:39:30.4786437Z\\\",\\r\\n \\\"user_id\\\": \\\"ab85e356-6638-41e7-a46f-be54c1f94f97\\\",\\r\\n \\\"session_id\\\": \\\"ba5ec8e4-65e0-481d-b034-970494680bca\\\",\\r\\n \\\"submission_method\\\": \\\"Upload\\\",\\r\\n \\\"user_agent\\\": \\\"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36\\\",\\r\\n \\\"location\\\": {\\r\\n \\\"latitude\\\": 35.71,\\r\\n \\\"longitude\\\": 115.23\\r\\n },\\r\\n \\\"location_city\\\": {\\r\\n \\\"latitude\\\": 35.7,\\r\\n \\\"longitude\\\": 115.2\\r\\n },\\r\\n \\\"is_mobile_device\\\": false,\\r\\n \\\"browser_type\\\": \\\"Chrome\\\",\\r\\n \\\"platform\\\": \\\"Windows\\\",\\r\\n \\\"mobile_device_model\\\": \\\"Unknown\\\"\\r\\n }\\r\\n]\",\"Faces\":[{\"faceId\":null,\"faceRectangle\":{\"top\":29,\"left\":49,\"width\":51,\"height\":51},\"attributes\":{\"gender\":\"Male\",\"age\":16.0}}]}"
正想我们在Chrome中观测到的返回数据一样,这样通过Python提交图片并获得识别数据就成功了。
但是这样的数据我们很难使用,因为里面数据很多且有很多的转义,所以先把\r``\n``\这样的数据清洗掉,并选取其中最后面的一部分,获得下面的结构数据:
{
"Faces": [
{
"faceId": null,
"faceRectangle": {
"top": 29,
"left": 49,
"width": 51,
"height": 51
},
"attributes": {
"gender": "Male",
"age": 16
}
}
]
}
faceId是图片中识别出的脸的标号,faceRectangle是将脸部框前来的矩形左上坐标及宽高,attributes中是识别出的性别和年龄。由于证件照都是标准的一个人,网站基本都能识别出来,所以只考虑一张图片对应的一个attributes。将照片对应的信息存在一个persons列表中,样式如下:
persons = [
{
"num":num,
"real_age":real_age,
"real_gender":real_gender,
"rec_age":rec_age,
"rec_gender":rec_gender
}
]
识别结果统计
性别识别
性别识别统计很容易,直接比对一张照片对应的实际性别和识别:
toatal = len(persons)
right = 0
wrong_fm = 0
wrong_mf = 0
for person in persons:
if person["real_gender"] == person["rec_gender"]:
right += 1
elif person["real_gender"] == "Female":
wrong_fm += 1
else:
wrong_mf +=1
最终的结果是:

年龄识别
年龄的识别统计采用一个字典记录,其结构是识别{某年龄差:识别为该年龄差的个数}:
age_rec = {}
for person in persons:
tmp = person["rec_age"] - person["real_age"]
try:
age_rec[tmp] += 1
except:
pass
finally:
age_rec[tmp] = 1
最终的统计结果是:

结语
本实践统计了HOW-OLD对两千多份图片样本的识别结果,性别识别正确率很高,而年龄识别错误范围较大,且识别结果偏大的居多。我甚至觉得,这东西可以用来检测摄影师的拍照技术,识别结果越小,人物摄影技术越好:)(开个玩笑)。整个实践最麻烦的地方是找接口及上传数据的方法,最费时间的是上传数据获得结果这个过程(受网络IO的限制,用家里的小破wifi,使用多线程也没多大用,而且线程一多,就会掉线:()。

还真有人点开啊🤣随意随意😂


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 字符编码:从基础到乱码解决