2020全国大学生数学建模C题中小微企业的信贷决策随机森林代码
2020全国大学生数学建模C题中小微企业的信贷决策(含随机森林代码)
原文链接:https://www.cnblogs.com/tablog/p/2020cumcm.html
2020全国大学生数学建模全部原题含附件:https://ricardio.lanzouw.com/b01wj9azc 密码:6p04
某银行对确定要放贷企业的贷款额度为10~100万元;年利率为4%~15%;贷款期限为1年。附件1~3 分别给出了123家有信贷记录企业的相关数据、302家无信贷记录企业的相关数据和贷款利率与客户流失率关系的2019年统计数据。我们团队需根据实际和附件中的数据信息,通过建立数学模型研究对中小微企业的信贷策略,主要帮助银行解决下列问题:
(1) 对附件1中123家企业的信贷风险进行量化分析,给出该银行在年度信贷总额固定时对这些企业的信贷策略。
(2) 在问题1的基础上,对附件2中302家企业的信贷风险进行量化分析,并给出该银行在年度信贷总额为1亿元时对这些企业的信贷策略。
(3) 企业的生产经营和经济效益可能会受到一些突发因素影响,而且突发因素往往对不同行业的企业会有不同的影响。综合考虑附件2中各企业的信贷风险和可能的突发因素对各企业的影响,给出该银行在年度信贷总额为1亿元时的信贷调整策略。
一、问题的分析
综合考虑附件2中各企业的信贷风险和新冠疫情对各企业的影响,我们首先对企业名称做文本分析,根据词频统计结果,选取了劳务、工程建筑业、文化等九个行业类别。其次,我们通过国家数据网,收集了2020年第二季度各行业GDP与上一年的同期增长率,对在突发事件下的风险值进行了修正和归一化处理,建立并求解信贷策略的非线性规划模型,最终给出了该银行在年度信贷总额为1亿元时的信贷策略,其中银行所获最大利润为232.3474万元。此问题综合考虑附件2中各企业的信贷风险和新冠疫情这一突发因素对各行业企业GDP的影响,首先对企业名称进行文本分析,在统计出附件中出现频率较高的企业类别之后,结合2020年第二季度企业GDP与上一年的同期增长率得出一个修正后的风险值 ,将其标准化后再代入信贷策略规划模型,从而给出该银行在年度信贷总额为1亿元时的信贷调整策略。
二、问题假设
1、假设信贷风险率 与所选指标 有关;
2、在这段时间内不考虑经济波动;
3、假设数据来源于随机样本;
4、假设有 个 , 因素影响 的取值;
5、因变量Y是分类变量,一般为二分类变量,我们研究的目的是在X事件发生时Y取值的条件概率。
三、随机森林
随机森林是一种集成机器学习方法,它利用随机重采样技术和节点随机分裂技术构建多棵决策树,通过投票得到最终分类结果。随机森林具有分析复杂相互作用分类特征的能力,对于噪声数据和存在缺失值的数据具有较强鲁棒性,其学习速度较快,且不容易出现过拟合。
随机森林机器学习模型选取自助法(bootstrap)进行数据集的提取,即对于每棵树而言,随机且有放回地从规模为n的训练集中的抽取n个进行训练;RF模型在抽样的基础上构造出Bagging算法,这种方法将训练集分成m个,然后在每个新训练集上构建一个模型,各自不相干,最后预测结果为这m个模型结果的整合(如图所示)。
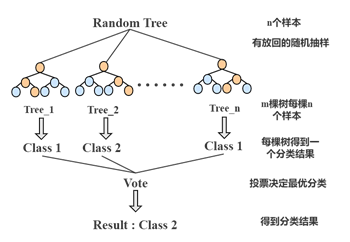
我们选择包含众多机器学习模型的Sklearn第三方模块实现随机森林模型的构建与训练。模型构建过程如下图
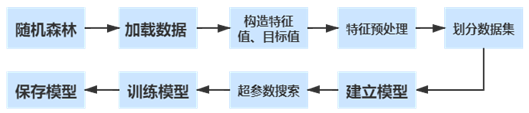
在机器学习模型中,当模型复杂度不足时,机器学习程度不足,会出现欠拟合现象;当复杂度逐渐提高到最佳模型复杂度时,将会达到最高准确度;当复杂度仍在提高,将会出现过拟合现象。因此,我们通过不断调节模型中的参数来提高训练准确度,使其尽可能地接近泛化误差最低点。随机森林模型主要的参数有n_estimators(子树的数量)和max_depth(树的最大生长深度),我们通过超参数搜索,最终确定使用n_estimators=30,max_depth=16的参数设置来预测“信誉评级”,n_estimators=30,max_depth=11来预测“是否违约”,最终训练达到了45%与85%左右的测试集与验证集准确率。
python代码(所使用的数据、及调用的文件均来自赛题)
sort.py文件(数据的预处理)处理后的文件用spss拟合
1 import pandas as pd 2 from pandas import DataFrame 3 4 #筛选无效发票 5 def ticket(): 6 data = pd.read_excel('C:/Users/yzj/Desktop/信贷风险值.xlsx', sheet_name="Sheet3")# 读取文件附件2:302家无信贷记录企业的相关数据 7 data = data[~data['发票状态'].isin(['有效发票'])] #删除作废发票 8 9 DataFrame(data).to_excel('C:/Users/yzj/Desktop/信贷风险值.xlsx', index=False, header=True) 10 11 #读取金额信息 12 def money(): 13 df=pd.read_excel("C:/Users/yzj/Desktop/第二题数据/进项有效发票.xlsx") # 读取每一个公司信息 14 print(df.groupby('企业代号')[['金额','税额','价税合计']].sum()) 15 d=df.groupby('企业代号')[['金额','税额','价税合计']].sum() 16 d.to_csv("C:/Users/yzj/Desktop/第二题数据/进项金额税额.csv",encoding='utf-8-sig',index=False, header=True) 17 18 #统计日期 19 def data(): 20 df=pd.read_excel("C:/Users/yzj/Desktop/第二题数据/进项有效发票.xlsx" ) # 读取每一个公司信息 21 d=df.groupby('企业代号')[['开票日期']].nunique() 22 print(df.groupby('企业代号')[['开票日期']].nunique()) 23 #d.to_csv("C:/Users/yzj/Desktop/第二题数据/销项日期.csv",encoding='utf-8-sig',index=False, header=True) 24 d.to_csv("C:/Users/yzj/Desktop/第二题数据/进项日期.csv",encoding='utf-8-sig',index=False, header=True) 25 26 def obj(): 27 df=pd.read_excel("C:/Users/yzj/Desktop/第二题数据/销项有效发票.xlsx" ) # 读取每一个公司信息 28 #df=pd.read_excel("C:/Users/yzj/Desktop/第二题数据/进项有效发票.xlsx" ) # 读取每一个公司信息 29 d=df.groupby('企业代号')[['购方单位代号']].nunique() 30 print(df.groupby('企业代号')[['购方单位代号']].nunique()) 31 d.to_csv("C:/Users/yzj/Desktop/第二题数据/销项供应商.csv",encoding='utf-8-sig',index=False, header=True) 32 33 #统计发票状态数量 34 def ticket_state(): 35 df=pd.read_excel("C:/Users/yzj/Desktop/第二题数据/进项有效发票.xlsx" ) # 读取每一个公司信息 36 d=df.groupby('企业代号')['发票状态'].value_counts() 37 print(df.groupby('企业代号')['发票状态'].value_counts()) 38 39 #统计发票总数 40 def ticket_count(): 41 pd.set_option('display.max_rows', 500) 42 pd.set_option('display.max_columns', 100) 43 pd.set_option('display.width', 1000) 44 df=pd.read_excel("C:/Users/yzj/Desktop/第二题数据/销项有效发票.xlsx") # 读取每一个公司信息 45 #df=pd.read_excel("C:/Users/yzj/Desktop/第二题数据/进项有效发票.xlsx") # 读取每一个公司信息 46 d=df.groupby('企业代号')['发票状态'].value_counts() 47 print(df.groupby('企业代号')['发票状态'].value_counts()) 48 d.to_csv("C:/Users/yzj/Desktop/第二题数据/销项有效发票总数.csv",encoding='utf-8-sig',index=False, header=True)
RF.py文件(随机森林代码)选取某些参数最为评定标准,预测信誉值
1 #随机森林 预测信誉值ABCD违约行为 2 import pandas as pd 3 from sklearn.externalsimport joblib 4 from sklearn.feature_extractionimport DictVectorizer 5 from sklearn.model_selectionimport train_test_split 6 from sklearn.ensembleimport RandomForestClassifier 7 from sklearn.model_selectionimport GridSearchCV 8 9 def forest(): 10 # 加载数据 11 firm= pd.read_excel("C:/Users/yzj/Desktop/国赛/C/问题一总表1.xlsx") 12 # 构造特征值和目标值 13 feature = firm[["进项发票有效率", "销项发票有效率","总销方数","总售方数",”进项年平均价税总额”,”销项年平均价税总额”]] 14 target = firm["信誉评级"] 15 #target = titan["是否违约"] 16 # 特征预处理 17 # 查看有没有缺失值 18 print(pd.isnull(feature).any()) 19 # 划分数据集 20 x_train, x_test, y_train, y_test = train_test_split(feature, target, test_size=0.25) 21 print("训练集:", x_train.shape, y_train.shape) 22 print("测试集:", x_test.shape, y_test.shape) 23 # 建立模型 24 rf = RandomForestClassifier() 25 # 超参数搜索 26 param = {"n_estimators":range(20,100,10), "max_depth":range(1,50,5)} 27 model = GridSearchCV(rf, param_grid=param, cv=10) 28 # 训练 29 model.fit(x_train, y_train) 30 print("测试集准确率:", model.score(x_test, y_test)) 31 print("验证集准确率:", model.best_score_) 32 print("最好模型参数:", model.best_params_) 33 print("最好模型模型:", model.best_estimator_) 34 #保存模型 35 joblib.dump(model, 'C:/Users/yzj/Desktop/第二题数据/model_level_change.pkl') 36 #joblib.dump(model, 'C:/Users/yzj/Desktop/第二题数据/model_obey_change.pkl') 37 def test(): 38 #引入测试数据 39 df = pd.read_excel("C:/Users/yzj/Desktop/第二题数据/问题二总表1.xlsx") 40 #数据预处理 41 X = df.drop(['是否违约'], axis=1) 42 #导入模型 43 clf = joblib.load("C:/Users/yzj/Desktop/第二题数据/model_level_change.pkl") 44 namelist = [] 45 #得到预测目标值 46 tolist = clf.predict(X) 47 for iin tolist: 48 namelist.append(i) 49 #对目标值列进行赋值 50 df['信誉评级'] = namelist 51 df.to_csv("C:/Users/yzj/Desktop/第二题数据/model_level_change.csv", encoding='utf-8') 52 print(tolist)
Statistics.py文件(一个词云图的代码)为了论文更直观、好看做的一个
1 import pandas as pd 2 # 导入扩展库 3 import re # 正则表达式库 4 import collections # 词频统计库 5 import wordcloud# 词云展示库 6 from PIL import Image # 图像处理库 7 import matplotlib.pyplotas plt# 图像展示库 8 import numpyas np 9 import jieba 10 import jieba 11 import re 12 import collections 13 from wordcloudimport WordCloud, STOPWORDS, ImageColorGenerator 14 from PIL import Image 15 import matplotlib.pyplotas plt 16 from pandas import DataFrame 17 18 corpus = pd.read_excel('C:/Users/yzj/Desktop/国赛/C/附件2:302家无信贷记录企业的相关数据.xlsx') # 得到DataFrame 19 corpus = np.array(corpus) # 转换为ndarray [[1], [2], [3]] 20 #print(corpus) 21 corpus = corpus.reshape(1, len(corpus)).tolist() # 转换成 List [[1, 2, 3]] 22 corpus = corpus[0] # 取第一个元素得到最终结果 [1, 2, 3] 23 print(corpus) 24 object_list = [] 25 for iin range(len(corpus)): 26 text = corpus[i] 27 for chin text: 28 if ch<='9'and ch>='0': 29 text = text.replace(ch, " ") 30 if ch<='Z'andch>='A': 31 text = text.replace(ch, " ") 32 33 #remove_words = ['','公司','有限','有限公司','经营','个体','个体经营','有限责任', 34 # '责任','*','经营部','营部','设备','管理','技术','咨询','建筑工程','建设工程'] # 自定义去除词库 35 remove_words = ['', '公司', '有限', '经营', '个体', 36 '责任', '*', '经营部', '营部', '建筑工程', '建设工程'] # 自定义去除词库 37 38 #得到所有单词 39 words = jieba.cut(text,cut_all=True) 40 space_wordlist = "" 41 42 for word in words: 43 if word not in remove_words: 44 object_list.append(word) 45 space_wordlist = word+space_wordlist 46 47 #统计词频 48 word_counts = collections.Counter(object_list) # 对分词做词频统计 49 word_counts_top15 = word_counts.most_common(15) # 获取前10最高频的词 50 print (word_counts_top15) # 输出检查 51 52 # 词频展示 53 #mask = np.array(Image.open('C:/Users/yzj/Desktop/wordcloud.jpg')) # 定义词频背景 54 wc = wordcloud.WordCloud( 55 font_path='C:/Windows/Fonts/simhei.ttf', # 设置字体格式 56 #mask=mask, # 设置背景图 57 #max_words=88, # 最多显示词数 58 #max_font_size=100, # 字体最大值 59 background_color= 'white', 60 margin=2 61 ) 62 63 wc.generate_from_frequencies(word_counts) # 从字典生成词云 64 plt.imshow(wc) # 显示词云 65 plt.axis('off') # 关闭坐标轴 66 plt.savefig('C:/Users/yzj/Desktop/test5.png') 67 plt.show() # 显示图像

 浙公网安备 33010602011771号
浙公网安备 33010602011771号