结对作业二
| 这个作业属于哪个课程 | 2021春软件工程实践|S班 |
|---|---|
| 这个作业要求在哪里 | 结对作业二 |
| 结对学号 | 221801310 221801325 |
| 这个作业的目标 | 1.根据网页原型,搭建web网站 2.学习Github协作编程 3.学习网站搭建的前后端技术 4.将网站部署到云服务器 |
| 其他参考文献 | CSDN相关博客以及博客园相关博客 |
结对作业一
GitHub仓库地址
1. GitHub仓库地址
2. 代码规范
3. 项目部署地址
PSP表格
| Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|
| 计划 | ||
| 预估这个任务需要多少时间 | 45min | 30min |
| 开发 | ||
| 需求分析(包括学习新技术) | 400min | 600min |
| 生成设计文档 | 30min | 40min |
| 设计复审 | 30min | 15min |
| 代码规范 | 600min | 40min |
| 具体设计 | 80min | 40min |
| 具体编码 | 2050min | 3200min |
| 代码复审 | 60min | 30min |
| 测试 | 60min | 30min |
| 测试报告 | 30min | 30min |
| 计算工作量 | 15min | 15min |
| 事后总结,并提出过程改进计划 | 30min | 10min |
| 总和 | 2890min | 4088min |
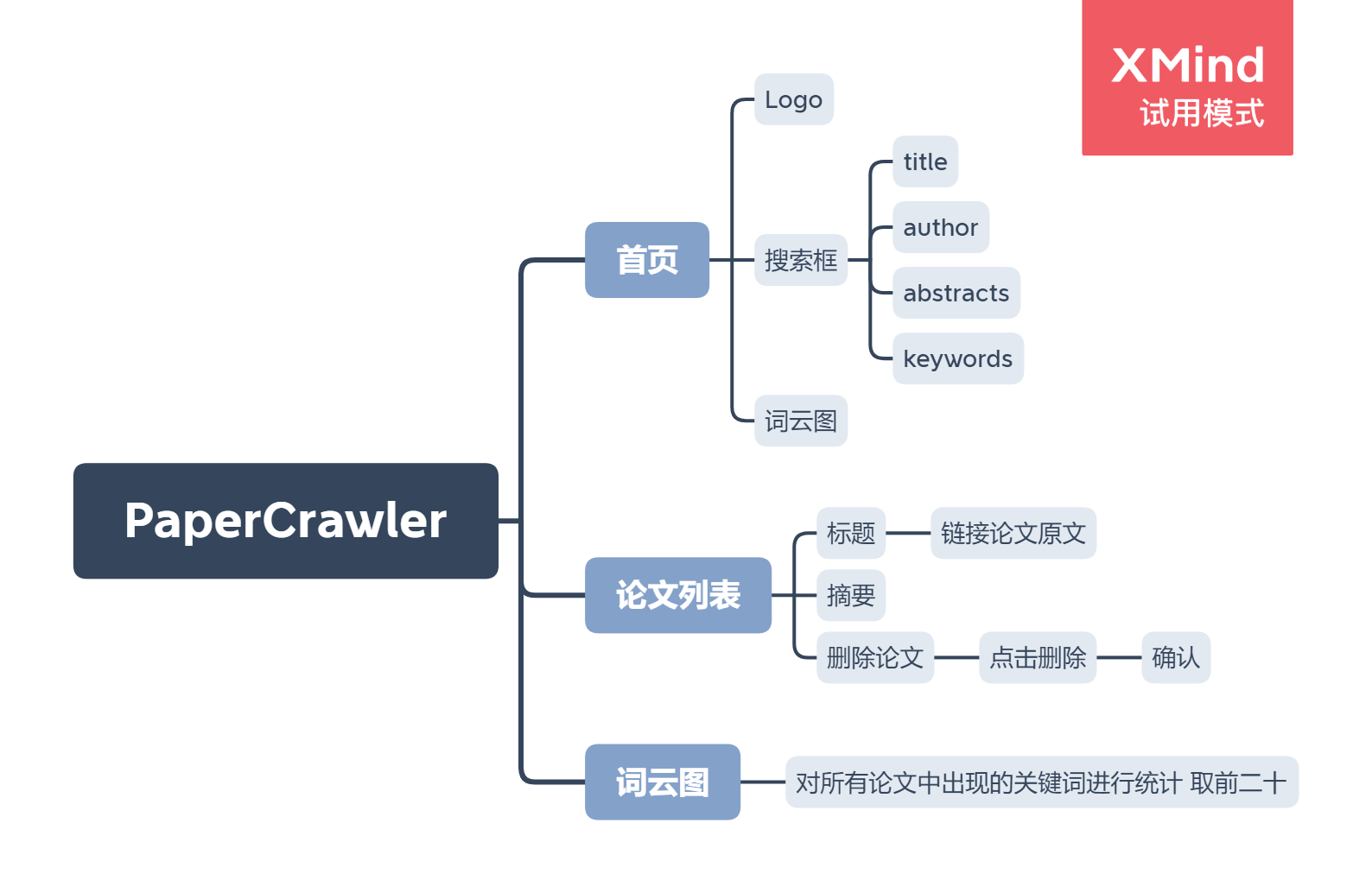
成品展示
1、首页界面采用极简风格,类似百度搜索。点击右上角,查看十大热词。左上角返回首页。
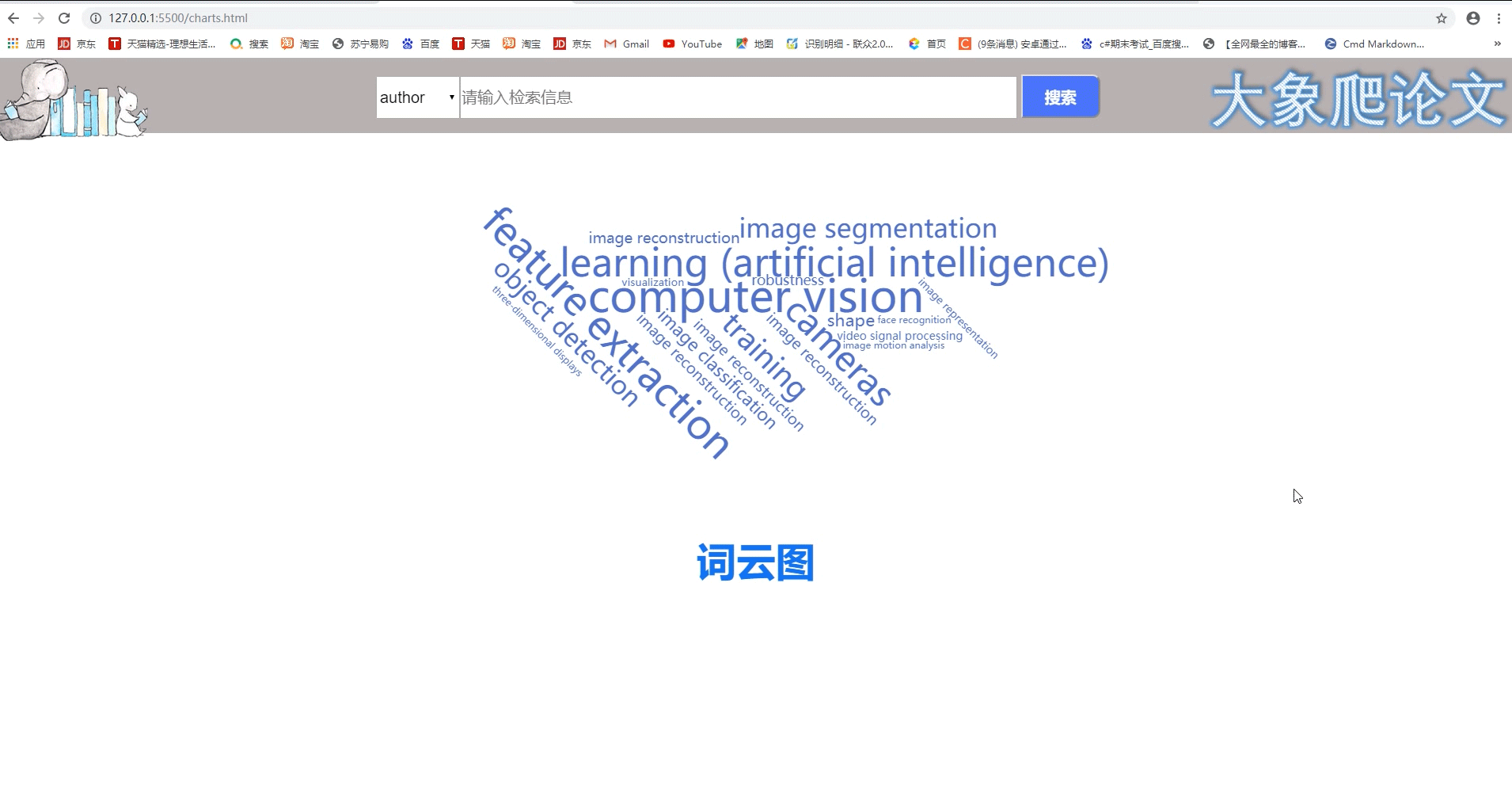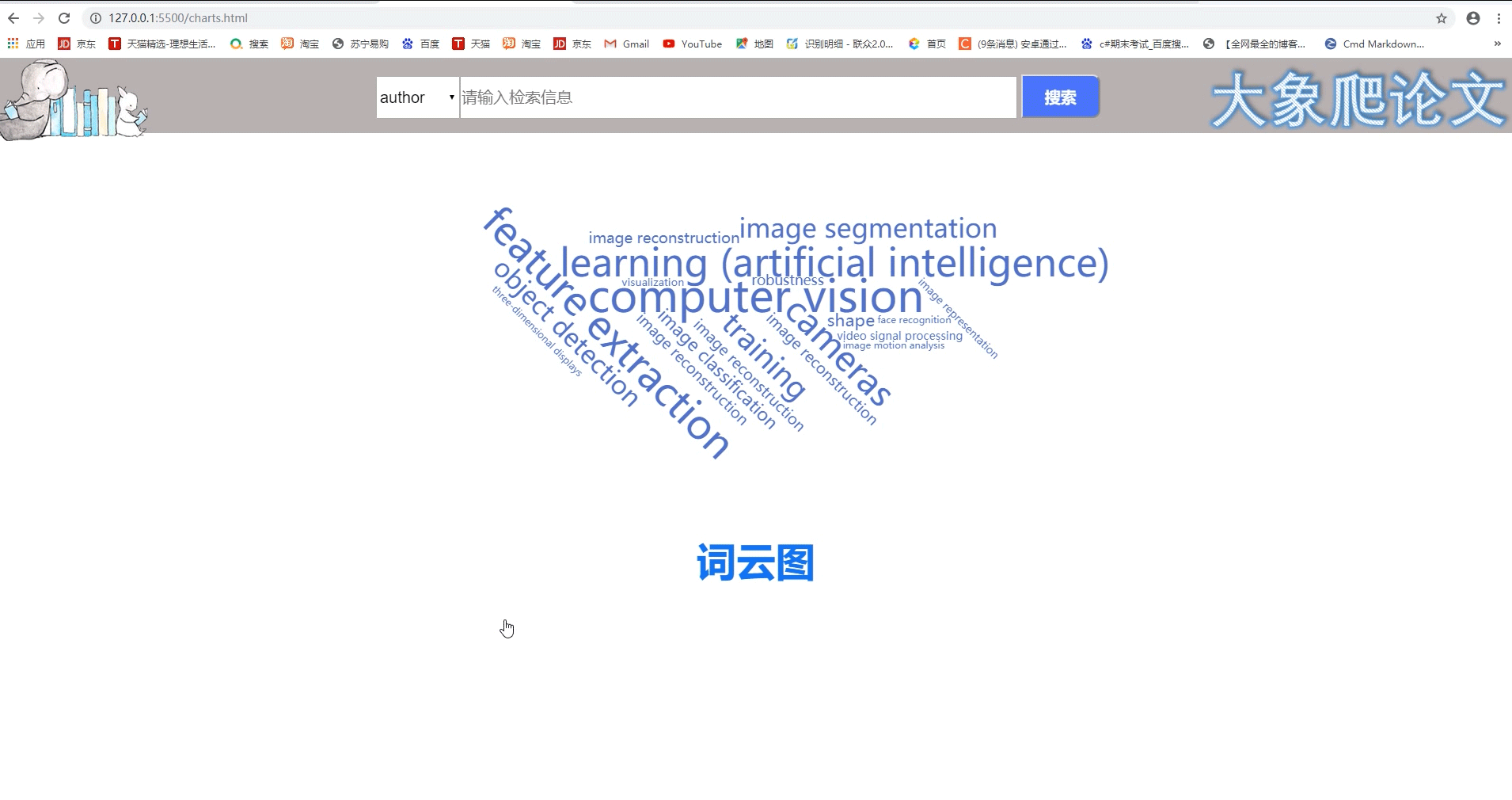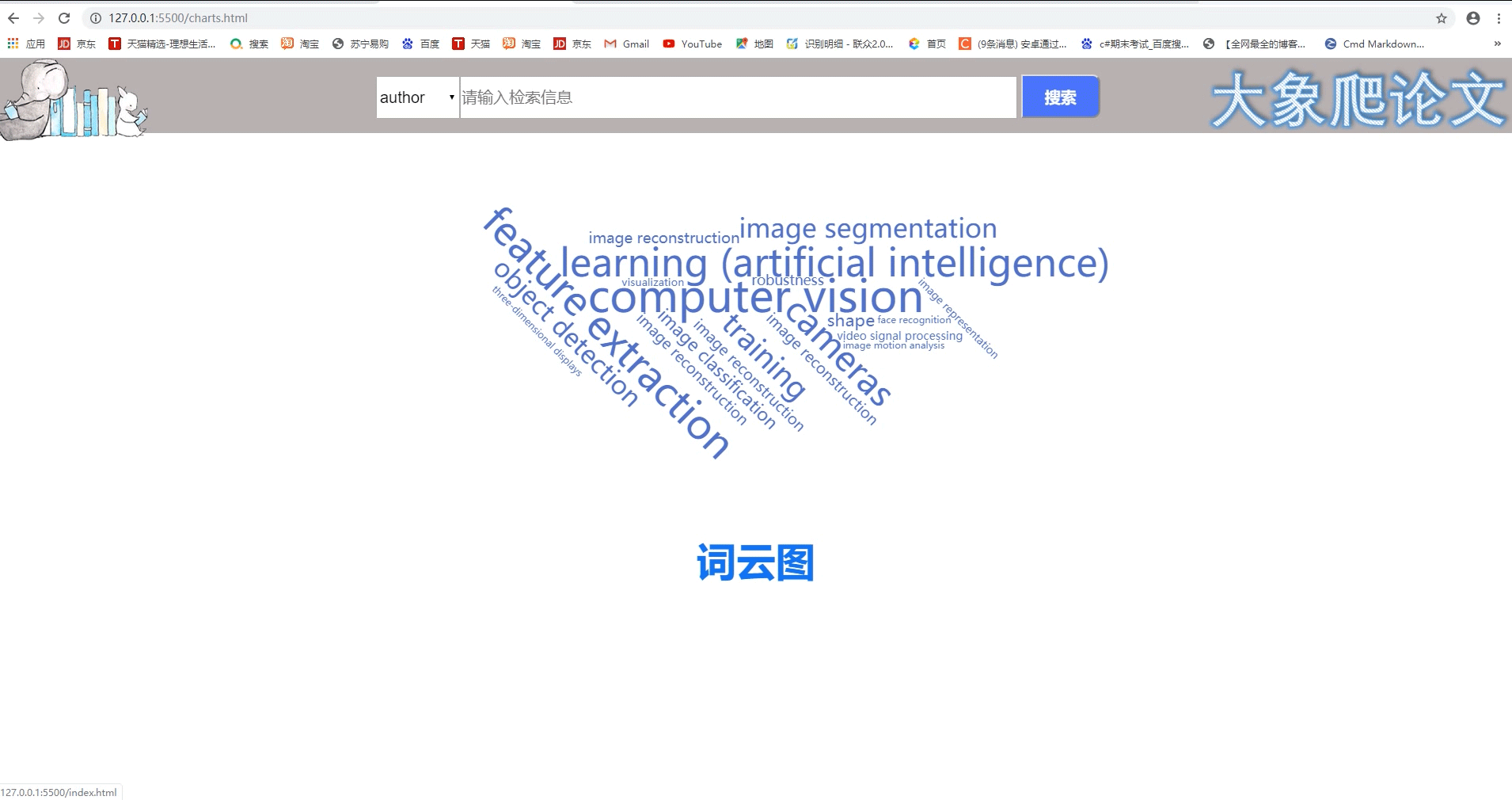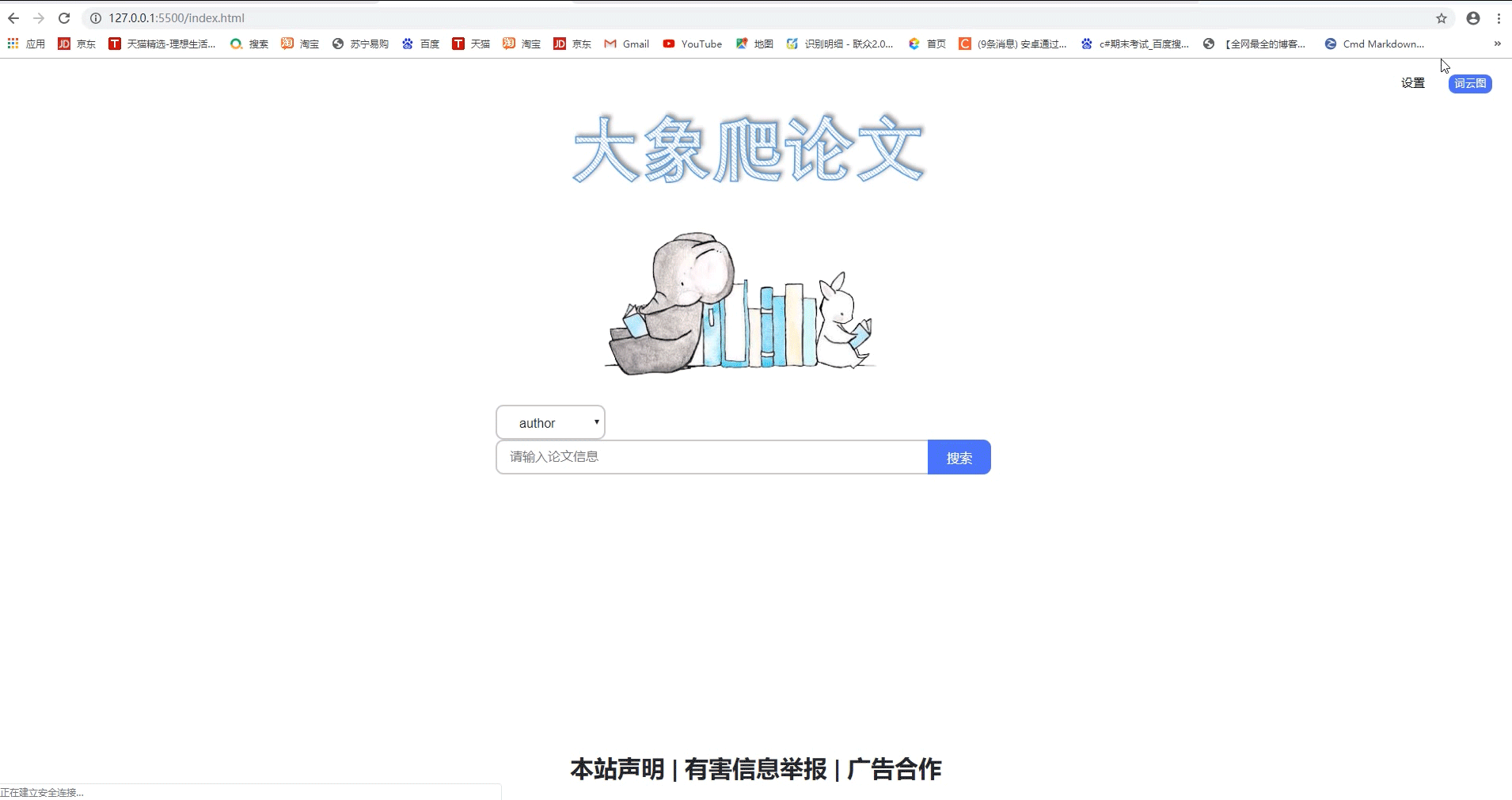
2、首页可进行搜索,有四种查找方式,关键字、作者、标题、摘要。下图演示标题搜索。对搜到的结果进行分页,一个页面包含五篇论文信息,点击标题挑转论文正文。
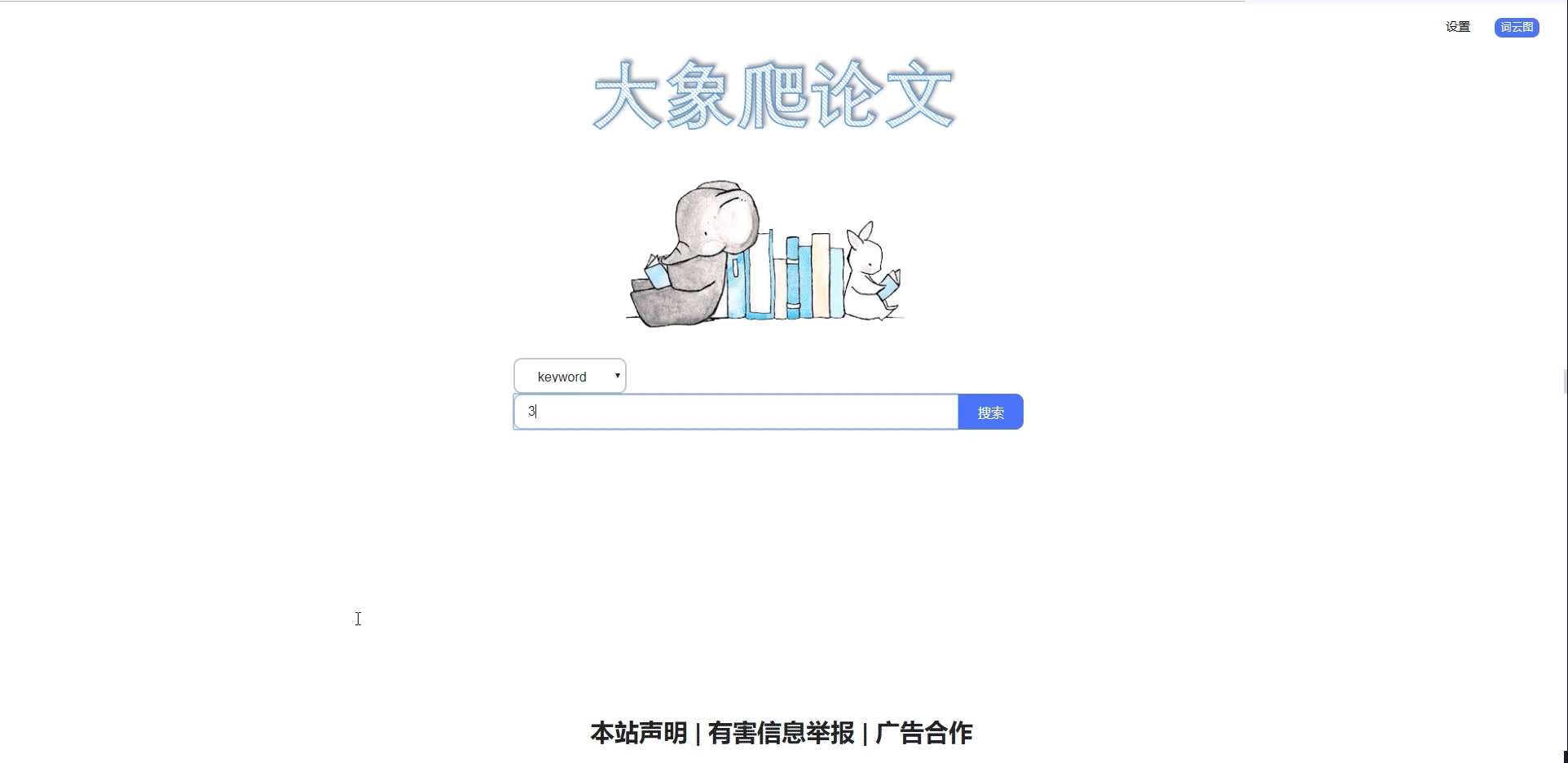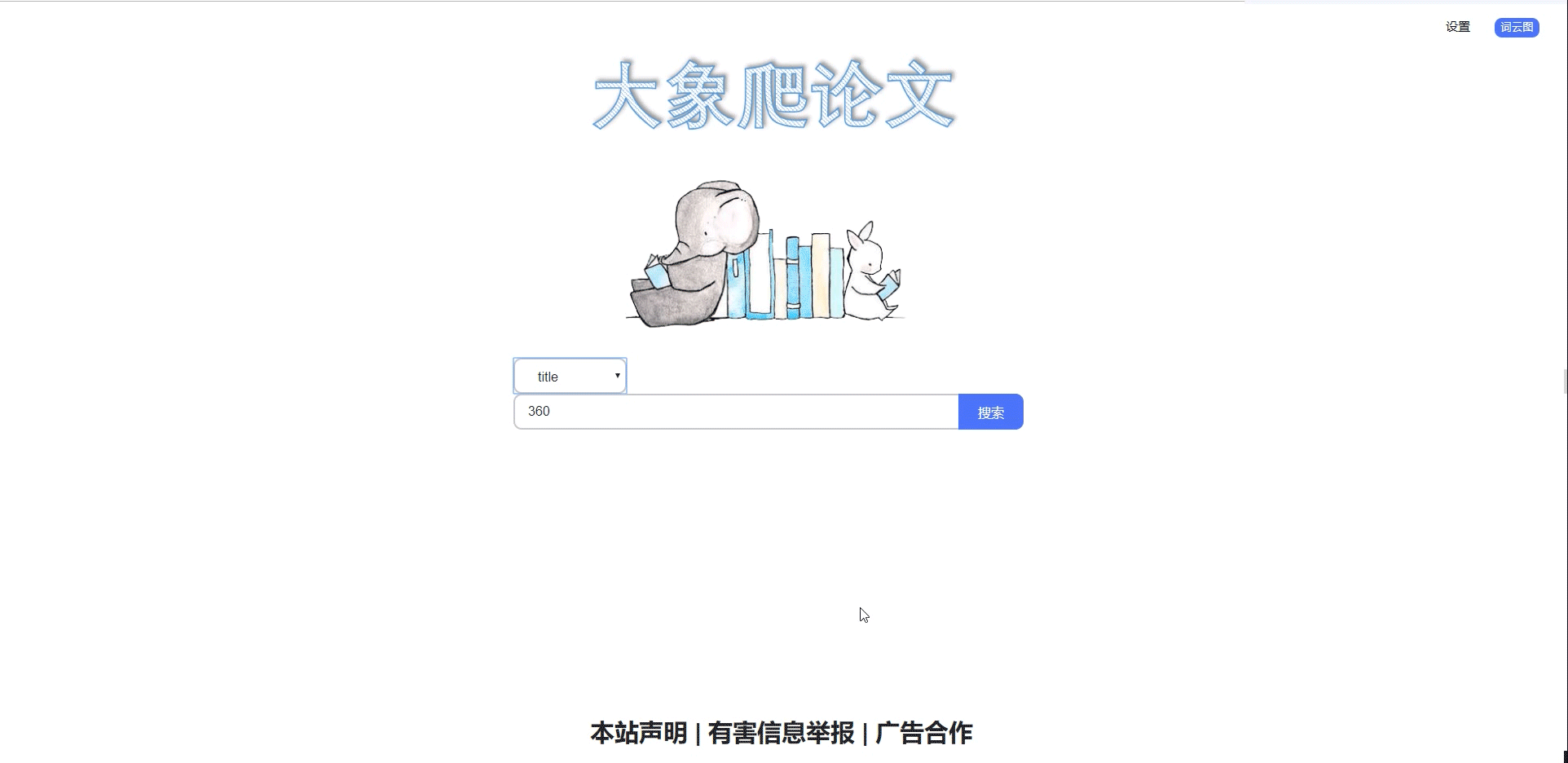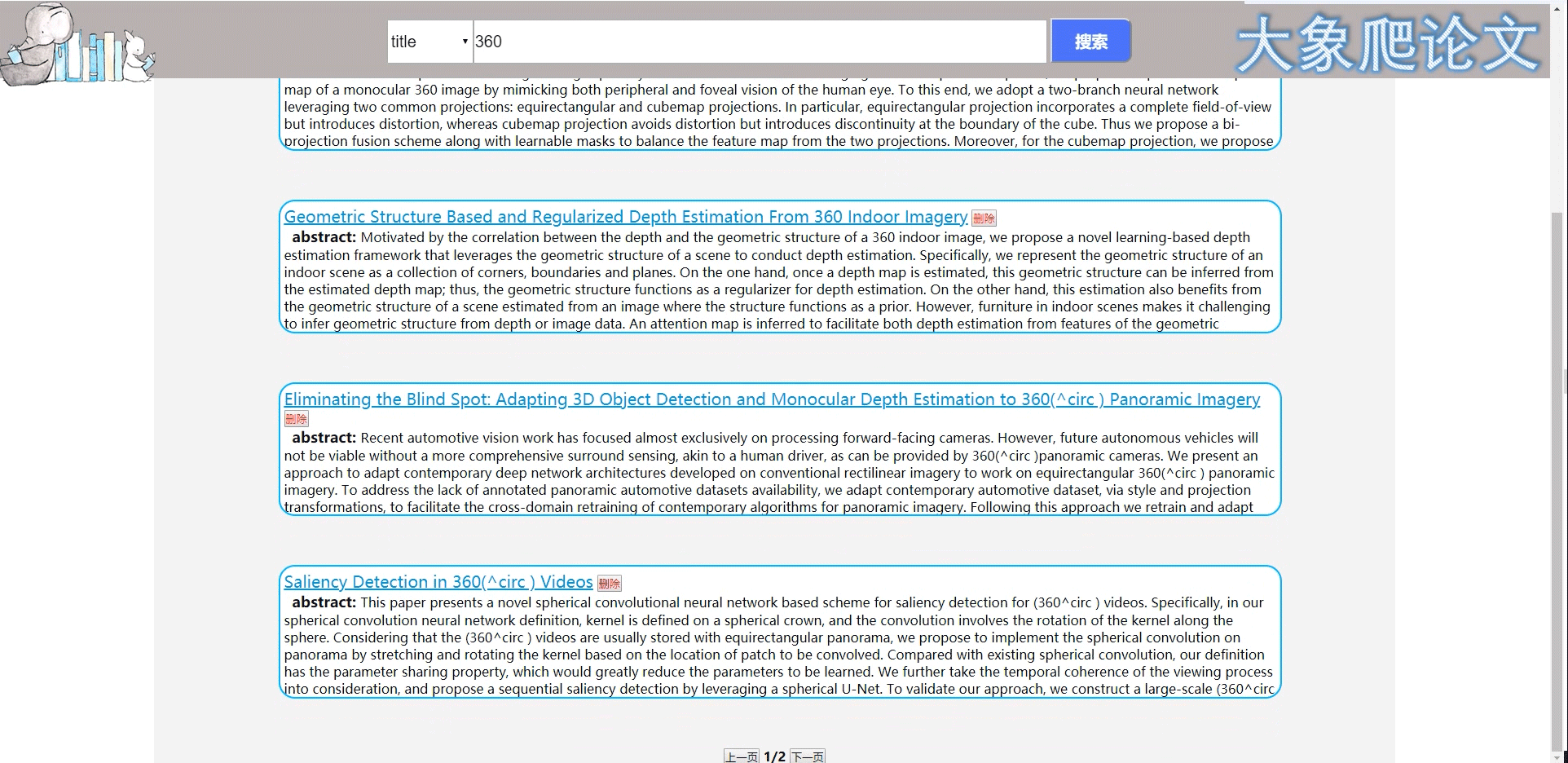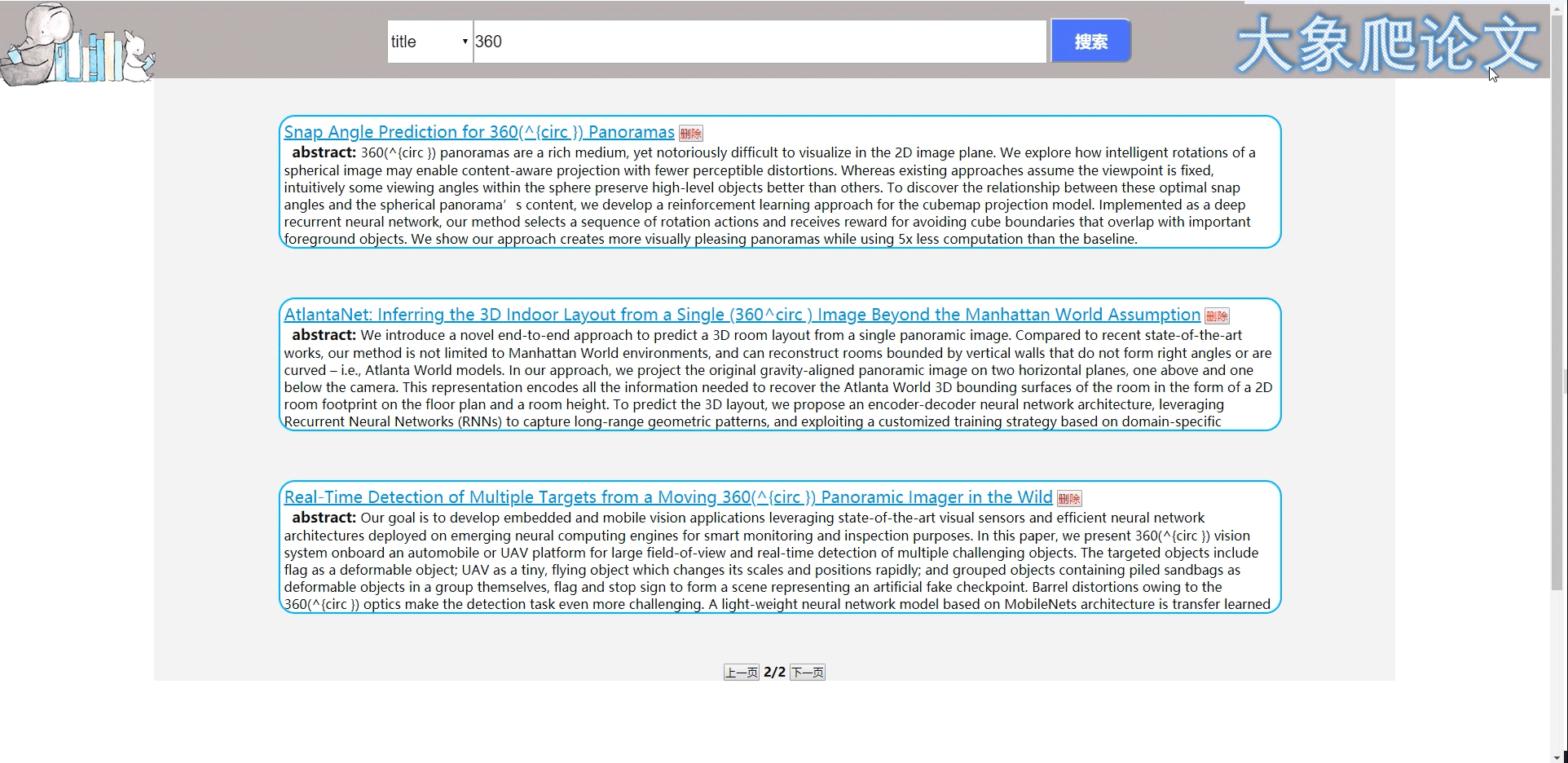
3、论文列表页也可进行搜索,下图演示关键词搜索。包含删除该篇文章功,删除后刷新界面。
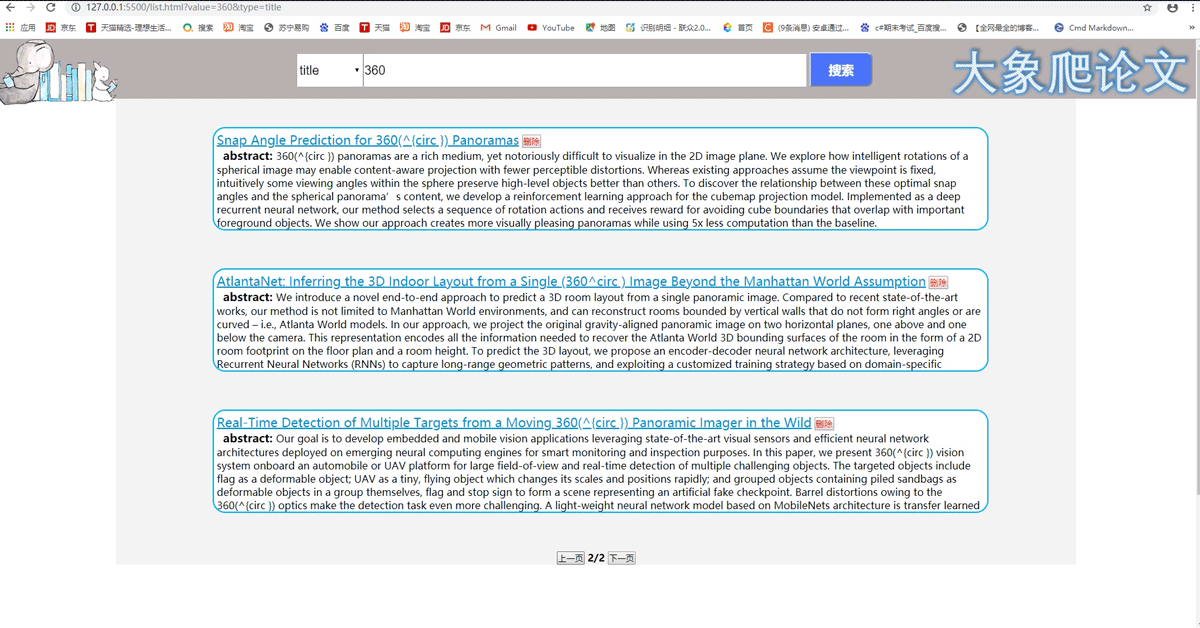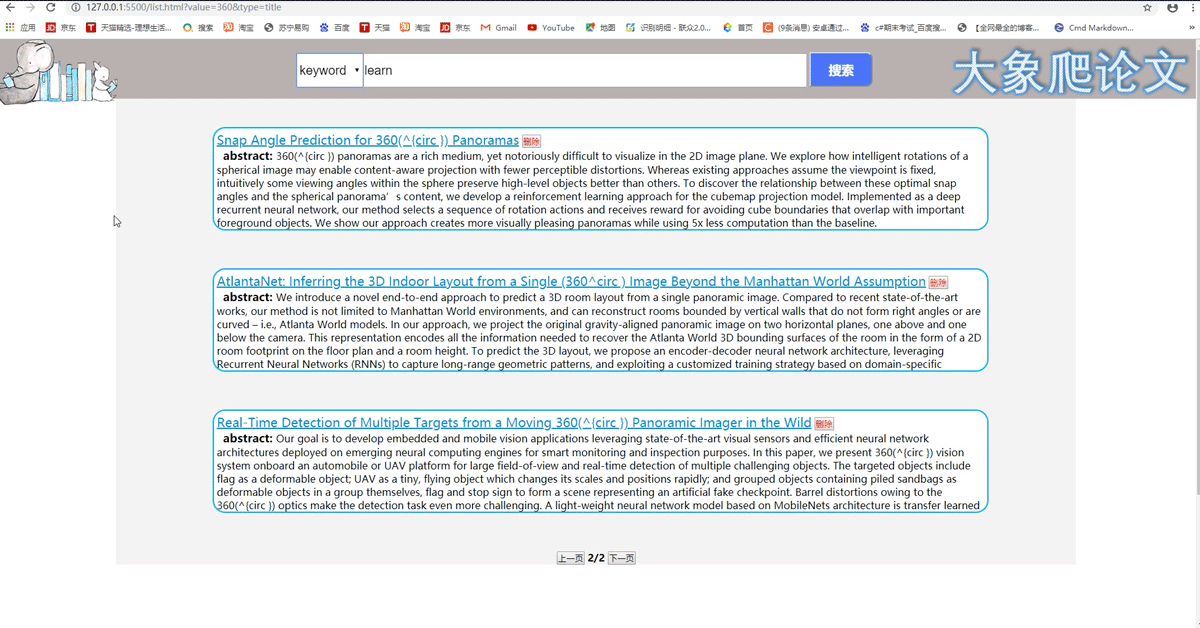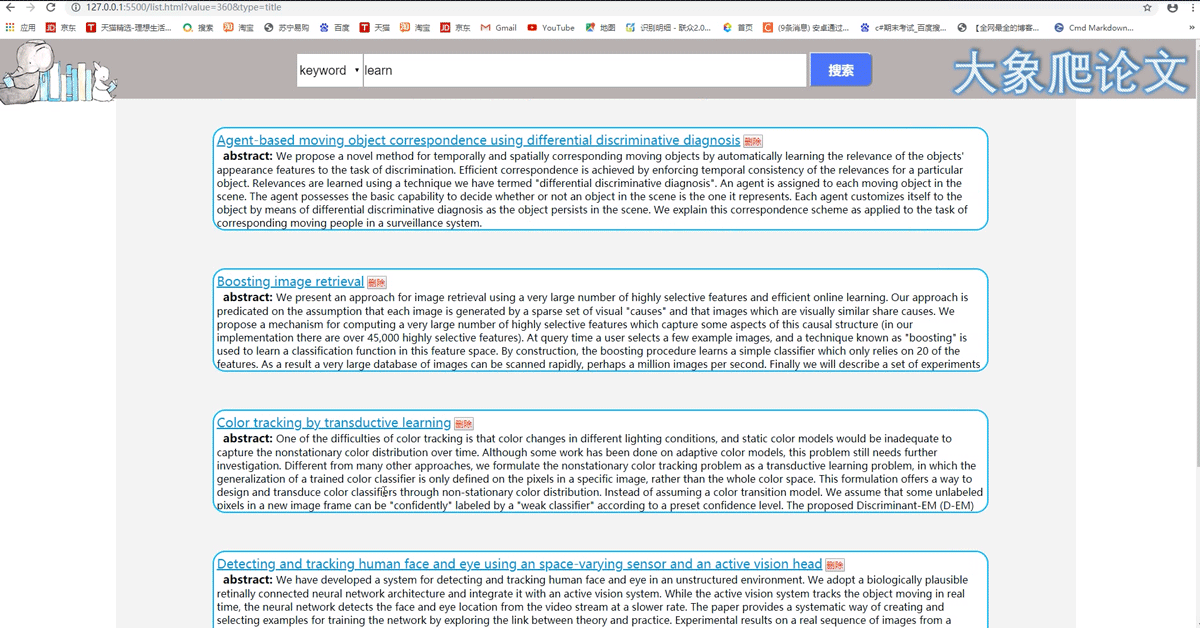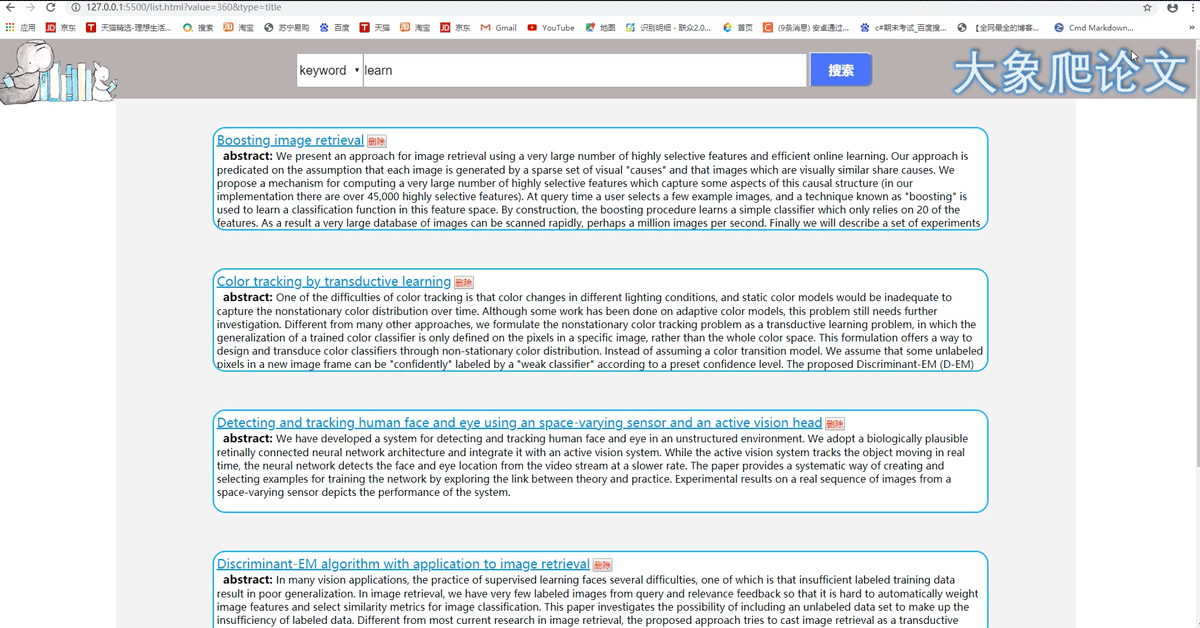
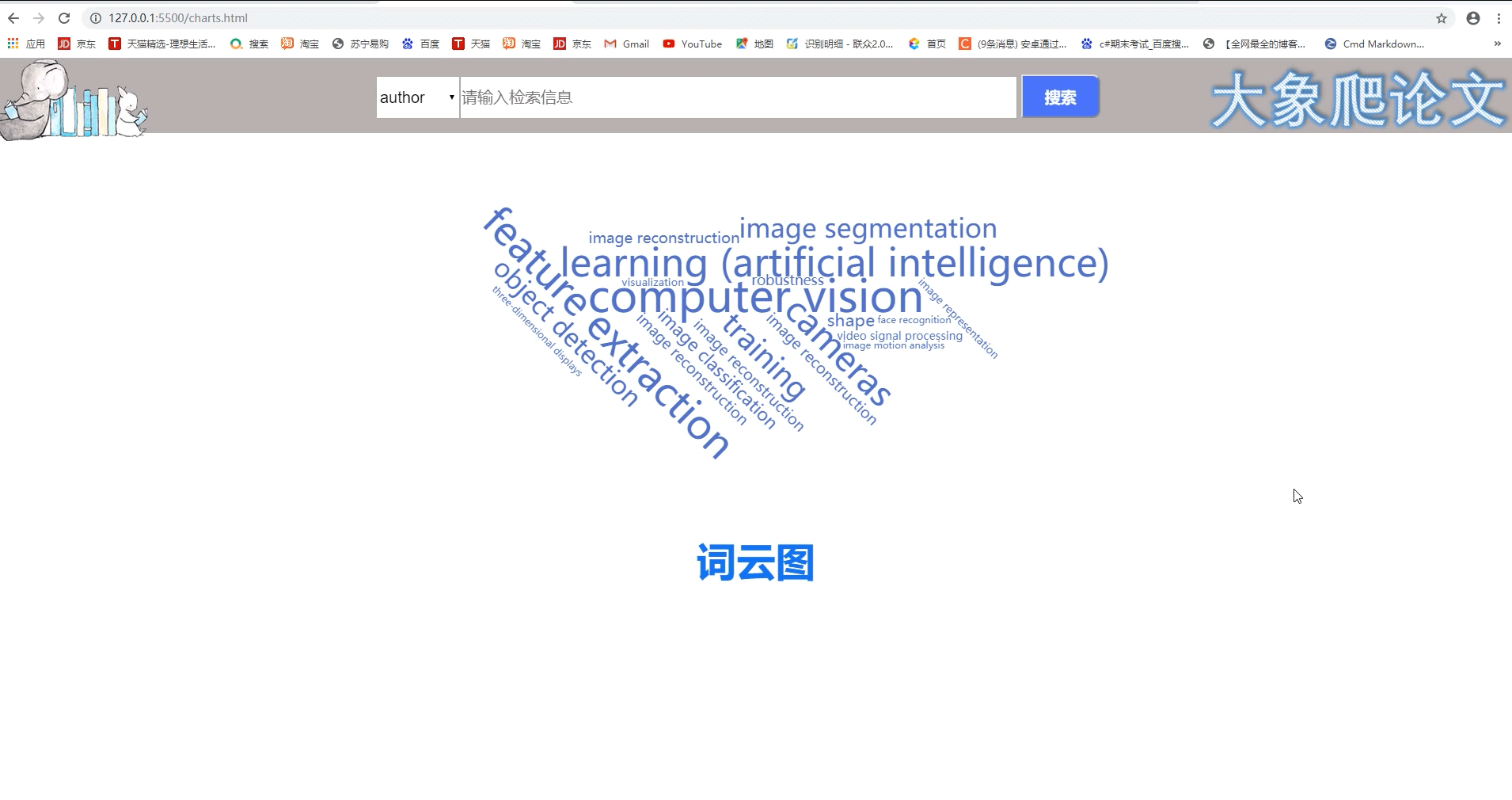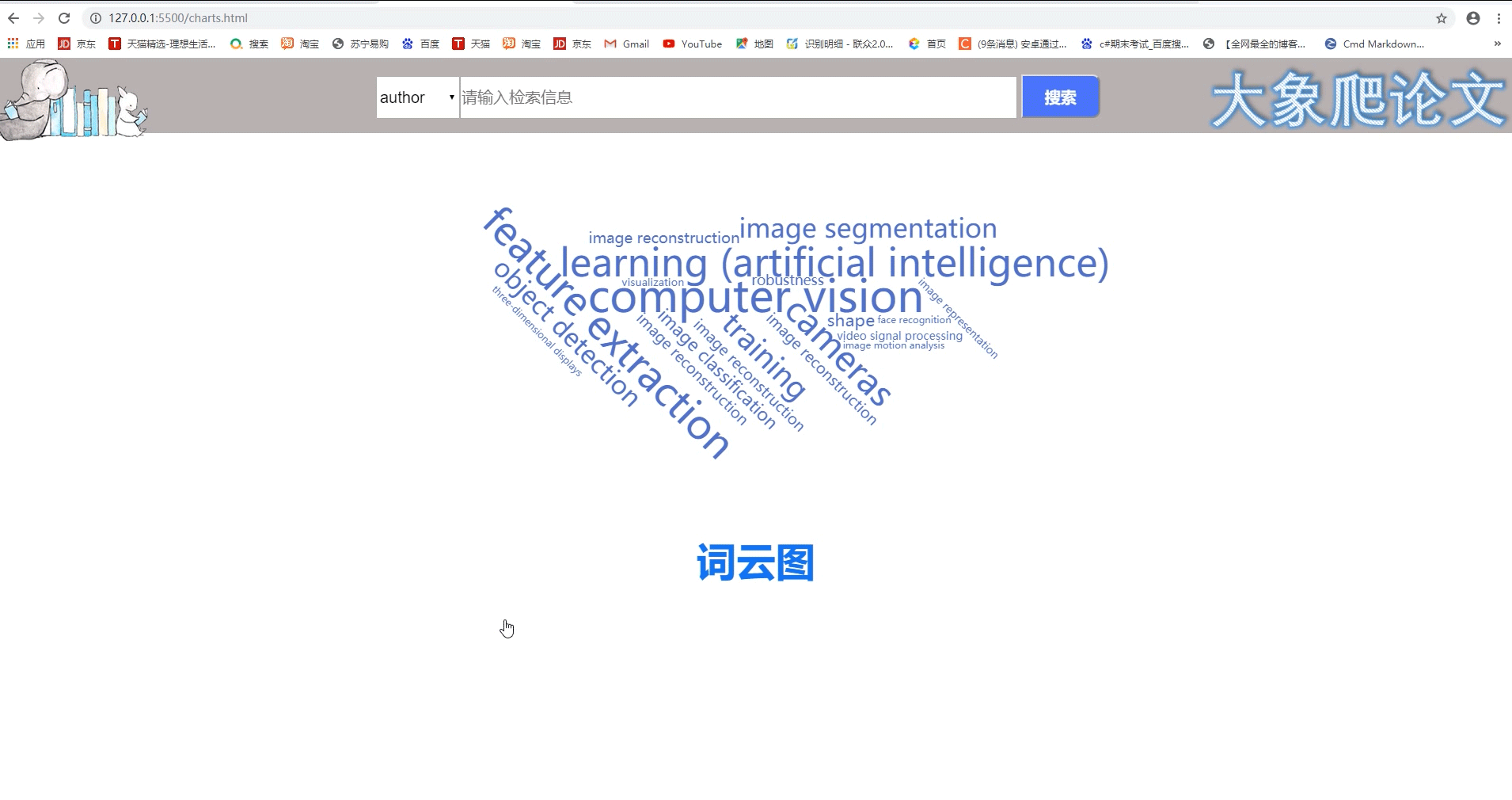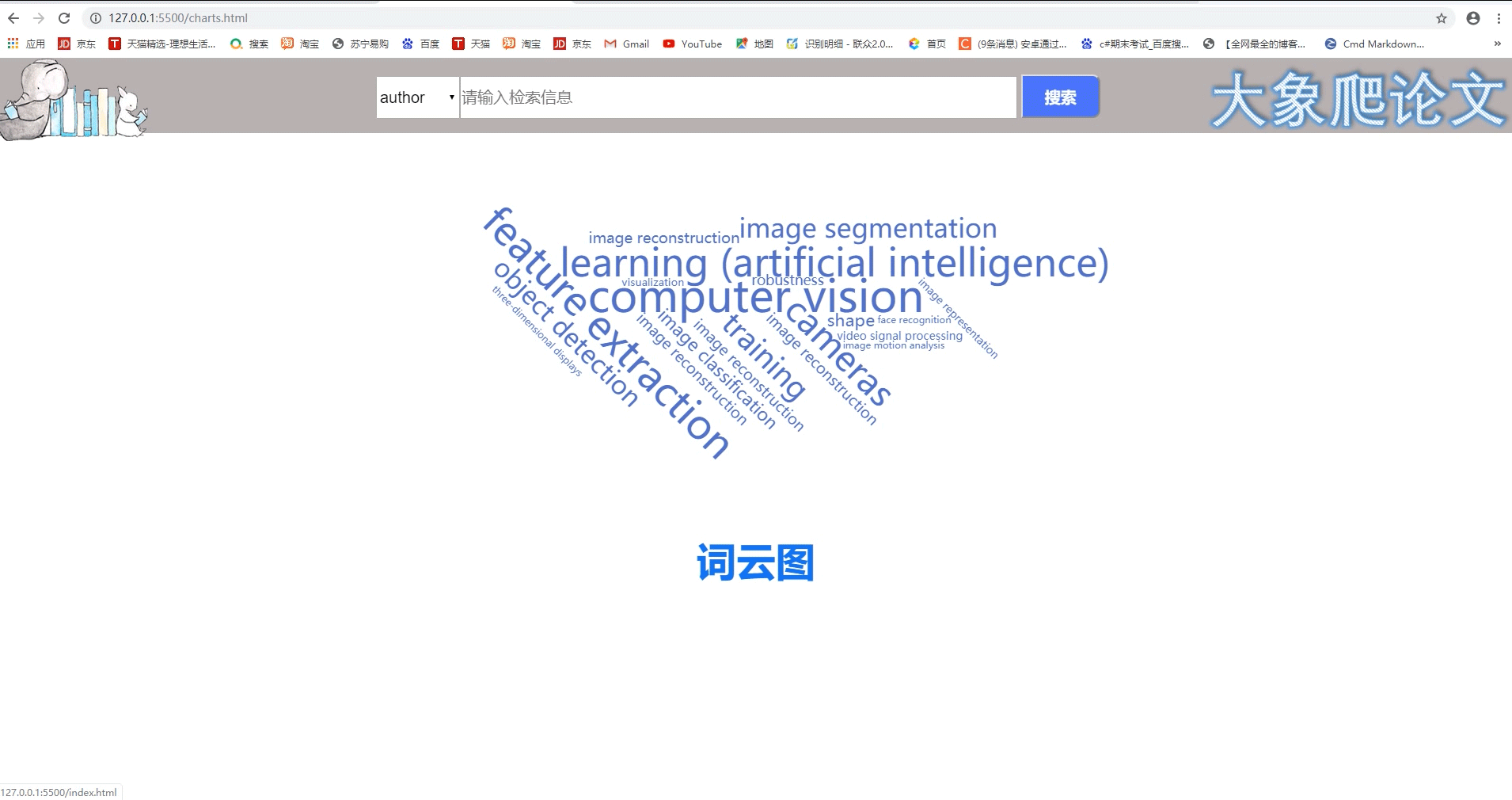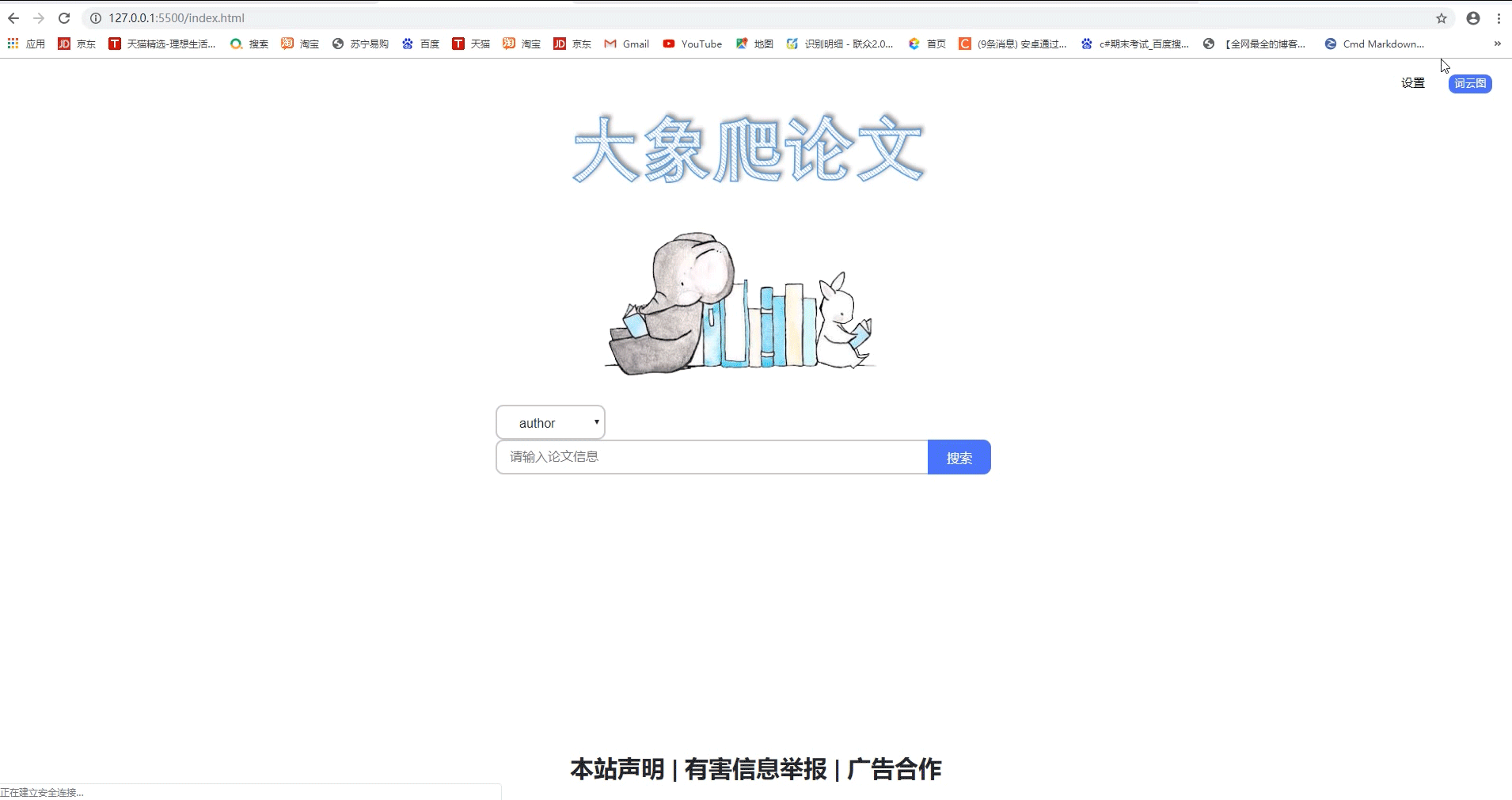
4、词云图页包含搜索功能,点击某个热词,将该热词设为关键字进行搜索,到论文列表页。
结对过程描述
-
分工
在第一次结对作业做原型的时候我们就很担心前端界面的问题,因为我们俩都没什么前端基础,只在web课程中写过一些html代码。我们结合百度加询问同学,最后决定使用Springboot做后端框架加html css js做前端
-
开发过程
前期我们分别学习技术,我学习Springboot,在学习过程中遇到了许多问题,在不断百度和看视频的过程中逐渐学会使用这个框架,洋艺学习制作前端界面和使用js交互。这期间还经历了团队的第一次项目实战,那一天我对Springboot的使用有了较大的提高,这还要多谢星源同学。
在开发过程中遇到了数不尽的bug,掉了多少头发就有多少bug...在搭建框架的过程中遇到bug,在实现功能的过程中有bug,在部署的过程中有遇到了数不尽的bug,真的太南了
由于我们是一个宿舍的,因此讨论十分方便,对前后端交接的数据格式也很方便规定,就不必写接口文档。
-
合影
交流

文件
设计实现过程
-
技术选择
前端
- Html+css+js
- 交互:vue.js
- 访问接口:axios
后端
- 框架:SpringBoot
- 语言:Java(Jdk1.8)
- 持久层框架:Mybatis
- 数据库:Mysql8.0
-
数据表设计
| 数据表 | 备注 | 字段 |
|---|---|---|
| authors | 作者-论文表 | author paperId |
| keywords | 关键词—论文表 | keyword paperId |
| papers | 论文表 | title link abstracts paperId magazine |
- 页面设计
- 功能点设计
- 可对以爬取的论文列表进行操作√
- 可对论文列表进行删除
- 可对论文列表进行查询详细信息
- 通过论文标题模糊查询
- 通过论文摘要模糊查询
- 通过出现的关键词模糊查询
- 通过作者进行查询
- 提取热门领域top20的关键词 以词云图的方式展示√
- 部署到云服务器上√
- 可对以爬取的论文列表进行操作√
代码说明
前端代码说明
-
前端交互部分使用vue.js书写,访问接口使用axios
methods:{ search:function(pageNum){ var that=this; axios.post('http://81.68.149.69:18902/search/searchPaper',{ searchType:this.type, content:this.value, pageNum:this.pageNum, pageSize:5 }) .then(function(response) { console.log(response) that.item=response.data.data.list; that.page=response.data.data; console.log(response.data.data) scrollTo(0,0); } ) .catch(function (error) { // 请求失败处理 console.log(error); }); }, -
首页与列表传参使用url传递参数
search:function(){ axios .get('http://47.100.89.20:8080/homepage/agenda') .then(response => (console.log(response) )) .catch(function (error) { // 请求失败处理 console.log(error); }); }, to:function(){ console.log(this.value) console.log(this.type) window.location.assign("list.html?value="+this.value+"&type="+this.type) } }
后端代码说明
-
搜索实现
通过Post方法访问,规定请求body为:
- RequestBody:
{ "searchType":"", "content":"", "pageNum":, "pageSize": }- ResponseMessage:
ResponseBody: { "code": 200, "message": "OK", "data": { "pageNum": 1, "pageSize": 10, "size": 1, "startRow": 1, "endRow": 1, "total": 1, "pages": 1, "list": [ { "paperId": 8, "title": "A curve evolution approach to smoothing and segmentation using the Mumford-Shah functional", "link": "https://doi.org/10.1109/CVPR.2000.855808", "abstracts": "In this work, we approach the classic Mumford-Shah problem from a curve evolution perspective. In particular we let a given family of curves define the boundaries between regions in an image within which the data are modeled by piecewise smooth functions plus noise as in the standard Mumford-Shah functional. The gradient descent equation of this functional is then used to evolve the curve. Each gradient descent step involves solving a corresponding optimal estimation problem which connects the Mumford-Shah functional and our curve evolution implementation with the theory of boundary-value stochastic processes. The resulting active contour model, therefore, inherits the attractive ability of the Mumford-Shah technique to generate, in a coupled Mumford-Shah a smooth reconstruction of the image and a segmentation as well. We demonstrate applications of our method to problems in which data quality is spatially varying and to problems in which sets of pixel measurements are missing. Finally, we demonstrate a hierarchical implementation of our model which leads to a fast and efficient algorithm capable of dealing with important image features such as triple points.", "magazine": "CVPR" } ], "prePage": 0, "nextPage": 0, "isFirstPage": true, "isLastPage": true, "hasPreviousPage": false, "hasNextPage": false, "navigatePages": 8, "navigatepageNums": [ 1 ], "navigateFirstPage": 1, "navigateLastPage": 1, "firstPage": 1, "lastPage": 1 } }- Controller层调用Service层方法,通过ResponseMessage类包装返回
@PostMapping("/searchPaper") public ResponseMessage searchPaper(@RequestBody RequestMessage requestMessage) { String type = requestMessage.getSearchType(); String content = requestMessage.getContent(); Integer pageNum = requestMessage.getPageNum(); Integer pageSize = requestMessage.getPageSize(); PageInfo<Paper> pageInfo = new PageInfo<>(); if (type.equals("author")) { pageInfo = authorService.getPaperByAuthorName(content,pageNum,pageSize); } else if (type.equals("keyword")) { pageInfo = keywordsService.getPaperByKeyword(content,pageNum,pageSize); } else if (type.equals("title")) { pageInfo = papersService.selectPaperByTitle(content,pageNum,pageSize); } else if (type.equals("abstracts")) { pageInfo = papersService.selectPaperByAbstracts(content,pageNum,pageSize); } else { return ResponseMessage.failure("请传入正确的搜索类型"); } return ResponseMessage.success(pageInfo); } -
Mapper层代码示例
- 通过配置文件将dao层的接口绑定mapper层的xml文件,就无需自己实现dao层接口,而是通过@Mapper和@Autowired注解方式调用。
<select id="selectPaperByTitle" parameterType="java.lang.String" resultMap="BaseResultMap"> SELECT papers.paperId, papers.title, papers.link, papers.abstracts, papers.magazine FROM papers WHERE title like #{title, jdbcType=VARCHAR} </select>- 自定义的mapper层返回的包装对象
<resultMap id="BaseResultMap" type="com.pair.papercrawler.models.Paper"> <constructor> <idArg column="paperId" javaType="java.lang.Integer" jdbcType="INTEGER" /> <arg column="title" javaType="java.lang.String" jdbcType="VARCHAR" /> <arg column="link" javaType="java.lang.String" jdbcType="VARCHAR" /> <arg column="abstracts" javaType="java.lang.String" jdbcType="VARCHAR"/> <arg column="magazine" javaType="java.lang.String" jdbcType="VARCHAR"/> </constructor> </resultMap>- 统计出现频数最高的top20 keyword
<select id="getTop20" resultMap="BaseResultMap"> SELECT keyword AS name , COUNT(*) AS value FROM keywords GROUP BY name ORDER BY value DESC LIMIT 20 </select>
心路历程与收获
-
邹洋艺:
通过此次作业,我学习了html、css、js相关知识,以前的学习只单纯停留在考试答题上,从来没有实际完成一个项目,因此此次的页面设计花费了我很多时间。首先我先复习了一下各种web知识,但是写完页面后我也不知道如果实现交互,特别是在获取各种json数据的时候。为此我看了很多资料,发现vue用起来比原生的js要方便,于是选择了vue.js。但短时间内很难完全学明白,所以方法略显粗糙。但是通过此次结对,我不仅发现了自己的不足,实践才能出真知。也学到了很多东西,比如服务器部署,这也是我之前从未涉及的。
-
钟煜新
最开始的时候这个作业的截止时间非常短,因此让毫无Springboot框架基础的我很焦虑,还好后来延长了时间,有了充足的时间去学习。由于之前学习过python的web框架flask和Django,因此对于Springboot后端的项目结构比较熟悉,对于各层的功能上手较快。至于git的分支操作以前曾用过,因此不成问题,但发布release版本却是第一次听说,在李庚同学的帮助下成功发布了release版本。这次还学习了如何将项目部署到服务器上,学习了简单的Linux系统的操作指令,原来Springboot的项目部署就是将打包好的jar包在云服务器上运行起来,就可以访问后端接口了。
虽然我们的项目完成的可能不是很好,但我们俩真的都很用心的在学习,每天一起熬夜到两三点疲惫睡去,虽然免不了抱怨,毕竟这个任务对于没什么完整项目经验的我俩都是一个艰巨的挑战,但在最后实现后,所带来的成就感将先前的辛苦都挤出了心底,只剩满心欢喜,为自己的进步感到开心。
评价结对队友
-
邹洋艺
煜新同学是个很好的队友,学习能力也很强。因为我之前也从来没有前端开发经验,他说他使用flask做后端,如果完成快的话后面帮我一起做前端,但是由于一些原因,我们后来使用了spingboot做后端开发,他也马上上手开始学,很快就入门了。后期开始要把项目部署到服务器上的时候,由于服务器是Ubuntu,需要全部使用命令行部署,他也是学不断尝试花了一晚上配置环境,将项目部署上。点赞!
-
钟煜新
洋艺执行力很强,也勇于挑战自己的弱项,在我们对前端都很陌生的时候他承担了这个重任,并且最后很完美的还原了我们的原型,前后端交互也是他完成的,赞。在交流的过程中条理清晰,善于发现问题,使得我们的开发过程大大简化。

