软工实践寒假作业 (2/2)
| 这个作业属于哪个课程 | 2021春软件工程实践|S班 |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 | 1.阅读《构建之法》提问 2.WordCount编程 |
| 其他参考文献 | CSDN相关博客以及博客园相关博客 |
任务一 重新阅读《构建之法》并提问
1. 问题一
4.5 结对编程 中 "结对编程让两个人所写的代码不断地处于“复审”的过程,程序员们能够不断地审核,提高设计和编码质量,可以及时发现并解决问题,避免把问题拖到后面的阶段去。 "
在本次个人作业中,我与同学也曾为了实现一个功能连着麦修改了一下午的代码,我想这也算是结对编程吧,但是在这个过程中我发现如果有一方主导意识较强,就容易将问题带入一个死结。且在这个过程中我们还产生了分歧,那么这个时候是否应该结束结对编程,各自实现自己的想法呢?还是两人应当按顺序,一起先尝试其中一个人的想法,再一起尝试另一个思路,然后对比取更优呢?
2. 问题二
3.2 软件工程师的职业发展 "迈克康奈尔把工程师分为8个级别(8—15),一个工程师要从一个级别升到另一个级别,
需要在各方面达到一定的要求。例如,要达到12级,工程师必须在三个知识领域
达到“带头人”水平。例如要到达“工程管理(知识领域)的熟练(能力)”水平,工程师必须要做到以下几点。阅读: 4—6个经典文献的深入分析和阅读工作经验: 要参与并完成6个具体的项目课程: 要参加3个专门的课程有些级别"
到目前为止我看过的关于编程的书屈指可数,在学习新技术的时候我偏向于在网络上学习,毕竟网络上的技术文章是最新的,那么,阅读经典文献的必要性在哪呢?
3. 问题三
5.2.1 主治医生模式 "在一些学校里,软件工程的团队模式往往从这一模式退化为“一个学生干活,其余学生跟着打酱油”"
这种情况的确很常见,但是如果在其他学生的水平都较低,对于那个水平高的学生来说,自己完成比教会他们再与他们合作效率不是高多了吗? 但这种模式也是合理的吧,特别是对于高年级学生来说,如果参加竞赛,对于队伍中的新生,不就应该带他们吗?
4. 问题四
11.5.1 闭门造车 "小飞:我今天真失败!在办公室里坐了10个小时,但是真正能花在开发工作上的
时间可能只有3个
小时,然后我的工作进展大概只有两个小时!
阿超:那你的时间都花到哪里去了?"
对于这个问题我深有体会,在完成个人项目的过程中,我常常一坐就是一整天,对着一个bug能改一个下午,但其实只是一个很小的错误,就很容易陷入这样的迷惑中,不独处呢,很难进入状态工作,一个人呢,又会发散了思维,那我以后去公司里工作该怎么办呢
5. 问题五
16.1 创新的迷思 "最近几年,我们整个社会似乎对创新很感兴趣,媒体上充斥了创新型的人才、创新型的学校、创新型的公司、创新型的城市、创新型的社会,等等名词。有些城市还把“创新”当作城市的精神之一,还有城市要批量生产上千名顶级创新人才。"
一直有听说前辈创业的事迹,但在进入专业学习了三年,我发现创新并不是那么容易的,你想实现的功能早就有人实现了并且已经失败了,甚至找不到创新的方向,那些自称创新型的事物,是否夸大其词了。还有就是对于那些热门的新技术方向,真正接触了发现你能够听到的新技术,其实已经有许多先行者了。
任务二 WordCount编程
1. Github项目地址:
项目地址
2. PSP表格:
| Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|
| 计划 | ||
| 预估这个任务需要多少时间 | 20 | 30 |
| 开发 | ||
| 需求分析(包括学习新技术) | 240 | 200 |
| 生成设计文档 | 30min | 20min |
| 设计复审 | 30min | 15min |
| 代码规范 | 30min | 40min |
| 具体设计 | 60min | 40min |
| 具体编码 | 1000min | 1200min |
| 代码复审 | 120min | 600min |
| 测试 | 60min | 30min |
| 测试报告 | 30min | 15min |
| 计算工作量 | 15min | 15min |
| 事后总结,并提出过程改进计划 | 30min | 10min |
| 总和 | 1665min | 2215min |
3. 代码规范制定链接
4. 设计与实现过程
- 第一阶段:复习git,复习java语法,编写了我的代码规范
这一阶段的任务由于在寒假就有复习,因此进行的比较快。同时还根据《码出高效_阿里巴巴Java开发手册》结合我本人习惯,编写我的代码规范。由于之前未使用过GithubDesktop,在这个阶段也安装下载,并学习了如何使用。
-
第二阶段:
- 程序需求分析:
- 获取文件输入
- 统计文件ascii码字符数
- 统计符合规则的单词数
- 统计文件的有效行数
- 统计出现次数最多的单词及出现次数(输出前十)
- 输出结果到文件
- 程序需求分析:
-
我的类结构:
-
WordCount
- main
-
Lib
- readTxt
-
outputToTxt
- countChar
- countLine
- sortHashMap
- findLegal
- countWordNum
-
-
解题思路:
-
文件输入
最开始我打算用BufferedReader去处理文件输入,通过readLine()方法一次读取一行,然后将读取的字符串用换行符"\n"拼接起来。但在测试中发现,读出的文本的ASCII码比预期的少,又回去仔细阅读了题目,发现文本中的换行并不是简单的"\n",还有"\r"、"\r\n"这种情况,因此如果用readLine()可能会使得文本字符变少。通过百度查找资料后,我决定采用BufferedInputStream的read()函数来读取,一次缓冲10m的文本。关键代码如下:
byte[] bytes = new byte[BUFF_SIZE]; int len; while((len=bufferedInputStream.read(bytes)) != -1){ stringBuffer.append(new String(bytes, 0,len,StandardCharsets.UTF_8)); } ... } catch (IOException e){ ... } return stringBuffer.toString(); -
统计文件ASCII码字符数
一开始没认真审题,将问题复杂化了,通过正则匹配去统计。
String regex = "\\p{ASCII}"; Pattern pattern = Pattern.compile(regex); Matcher matcher = pattern.matcher(text); while (matcher.find()){ num++; }后来发现由于题目说明给定的文本都是ASCII字符,因此只需返回读取文件的字符串的长度即可。
-
统计符合规则的单词数
- 单词的规则:至少以4个英文字母开头,跟上字母数字符号,不区分大小写
- 我想到的办法是先将文本用split方法分隔开,分隔用的正则表达式为:
[^ A-Za-z0-9_]|\\s+,得到一个不含分隔符的字符串数组。再用一次循环用正则'[1]{4,}.*'去判断是否为合法单词。
将文本分割:
public static String[] splitWord(String text){ String[] words; String regexForSplit = "[^ A-Za-z0-9_]|\\s+"; words = text.split(regexForSplit); return words; }- 判断是否合法单词
public static List<String> splitLegalWord(String[] words){ List<String> legalWords = new ArrayList<String>(); String regexForMatch = "^[a-zA-Z]{4,}.*"; for(int i=0 ; i<words.length; i++){ if(words[i].matches(regexForMatch)){ legalWords.add(words[i].toLowerCase()); } } return legalWords; } -
统计文件的有效行数
用正则表达式去匹配空白字符(三种),然后用split将文本分割,就得到了每个字符串为一行的字符串数组,然后再遍历过程中判断是否空行,这里用trim是为了防止含有空格或tab制表符的无效行被视作有效行算入行数中。
String[] lines = text.split("\r\n|\r|\n"); for(int i=0; i<lines.length; i++){ if (!lines[i].trim().isEmpty()){ num++; } } -
统计出现次数最多的单词及出现次数(输出前十)
将存放单词和单词出现次数的hashMap转换为list,然后对list进行排序,重写compare方法使得排序依据:从大到小排序,频率相同的单词,优先输出字典序靠前的单词,选取前十条记录。
public static List<Map.Entry<String, Integer>> sortHashMap(HashMap<String, Integer> hashMap){ Set<Map.Entry<String, Integer>> entry = hashMap.entrySet(); List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>(entry); Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() { @Override public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) { if(o1.getValue().equals(o2.getValue())){ return o1.getKey().compareTo(o2.getKey()); } return o2.getValue()-o1.getValue(); } }); //最多只取10条 if(list.size()>10) { return list.subList(0,10); } else{ return list; } }
- 输出结果到文件
简单地用BufferedWriteer按行写入到文件中。
bufferedWriter.write("characters:"+num1+"\r\n"); bufferedWriter.write("words:"+num2+"\r\n"); bufferedWriter.write("lines:"+line+"\r\n"); for(int i=0; i<list.size()&&i<10; i++){ String key = list.get(i).getKey(); Integer value = list.get(i).getValue(); bufferedWriter.write(key+":"+value+"\r\n"); }
5. 性能改进
-
初次性能测试:
用于测试的文本大小为:95.3mb(100,000,000 字节,用来测试的文件由该文件[GenerateText][]随机生成) 需要的运行时间为:54834ms 这个数字着实吓了我一跳,因为其他人的运行时间是远远低于我的。 使用了缓冲区后 改进时间为50212ms。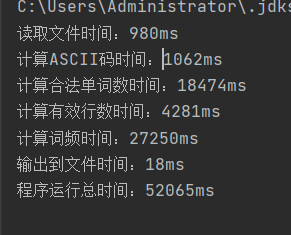
-
算法优化
在对执行各个模块的时间分析后,我发现耗时最高的是计算单词数以及统计词频,由于算法不当以及一开始对各个方法独立性的错误追求,在拆分单词处进行了重复计算,在和洋艺同学交流后发现其实计算单词的时候就可以用hashMap记录词频的
-
改进前:先用split方法提取出独立的字符串,存放在字符串数组中,然后再用 "[2]{4,}.*" 去匹配每一个字符串,用List
存放合法的单词。用的是matches方法。据星源同学所说这两个方法效率极低,否则我也没意识到在这个地方有什么可以改进的地方,非常感谢他555。 -
改进后:直接对文本字符串进行匹配,通过Matcher的find方法取出符合规则的单词,并且统计单词的出现次数,存放到HashMap<String, Integer>里。不过这样的正则表达式比较复杂,而且需要在文本字符串开头添加一个空白字符。正则表达式:"([^ a-z0-9])([a-z]{4}[a-z0-9]*)"。关键代码:
Pattern pattern = Pattern.compile(regex); Matcher matcher = pattern.matcher(text); HashMap<String, Integer> legalWords = new HashMap<String, Integer>(); //直接把单词和出现频率一起做了,放到hashMap里 while(matcher.find()){ wordNum++; String tmp = matcher.group(2).trim(); if(!legalWords.containsKey(tmp)){ legalWords.put(tmp,1); } else{ legalWords.put(tmp, legalWords.get(tmp)+1); } } return legalWords; }-
对CountLine进行了优化,毕竟用split方法实在是太耗时且占用内存了,我用大小为476 MB (500,000,000 字节)的文本去跑,程序直接崩溃了,原因是堆溢出。在经过百度以及和邹洋艺同学探讨过后,决定采用正则匹配来计算行数。
public static int countLine(String text){ int num=0; String regex = "(.*)(\\s)"; Matcher matcher = regexUtils(regex, text); while (matcher.find()){ String tmp = matcher.group(1); if(!tmp.trim().isEmpty()){ num++; } } return num; }
-
-
-
多线程执行:
发现统计单词词频和计算行数这两个工作并不重复,而且耗时也都比较长,因此想到是否可以通过多线程来执行这两个任务。由于两个方法都需要返回值,因此实现的是Callabel接口
Callable callable1 = new Callable() { HashMap<String, Integer> legalWords; @Override public HashMap<String, Integer> call() { long startTime1 = System.currentTimeMillis(); try { Thread.sleep(5); }catch (Exception e){ e.printStackTrace(); } this.legalWords = SplitWord.findLegal(content); countDownLatch.countDown(); long endTime1 = System.currentTimeMillis(); System.out.println("线程1运行时间:"+(endTime1-startTime1)+"ms"); return legalWords; } }; futureTask1 = new FutureTask<HashMap<String, Integer>>(callable1); new Thread(futureTask1).start(); //执行线程Callable callable2 = new Callable() { Integer line; @Override public Integer call() { long startTime2 = System.currentTimeMillis(); line = CountLine.countLine(content); countDownLatch.countDown(); long endTime2 = System.currentTimeMillis(); System.out.println("线程2运行时间:"+(endTime2-startTime2)+"ms"); return line; } }; futureTask2 = new FutureTask<Integer>(callable2); new Thread(futureTask2).start();coutDownLatch使主线程等待两个子线程都完成后才能继续执行。
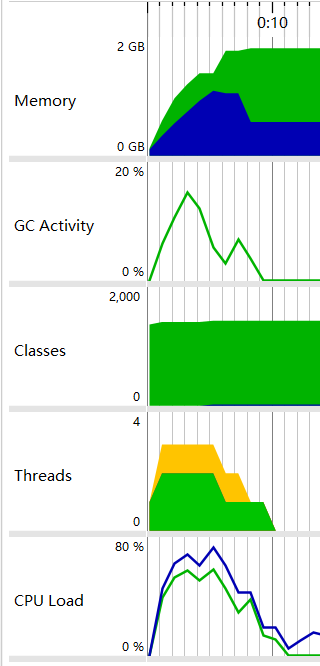
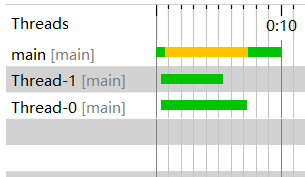
可以看到,两个线程是并行的且主线程等两个线程都执行完毕才继续执行。性能改进后,测试95.3mb(100,000,000 字节)的文件,所需要的时间为:7053ms,相对于优化之前的50000多ms有了相当大的改进。
6. 单元测试
-
最开始的单元测试是很笨的通过main方法,写好方法后在main中调用,并对方法的运行时间进行记录。后来得知可以使用JUnit插件来进行单元测试,单元测试就变得简单方便多了,也更加有针对性。在编程过程中,我进行了多次的单元测试,在确保功能正常后才进行下一步。
1.字符统计
@Test public void countChar() { String content = ReadTxt.readTxt(path+"input7.txt"); long startTime1 = System.currentTimeMillis(); System.out.println(CountAsciiChar.countChar(content)); long endTime1 = System.currentTimeMillis(); System.out.println("计算ASCII时间:"+(endTime1-startTime1)+"ms"); }- 单词计算
@org.junit.Test public void countWordNum() { num = CountWord.countWordNum(text); System.out.println(num); }- 统计频率
@Test public void sortHashMap() { list = CountFrequency.sortHashMap(legalWords); for(int i=0; i<list.size()&&i<10; i++){ String key = list.get(i).getKey(); Integer value = list.get(i).getValue(); System.out.println(key+":"+value+"\r\n"); } } -
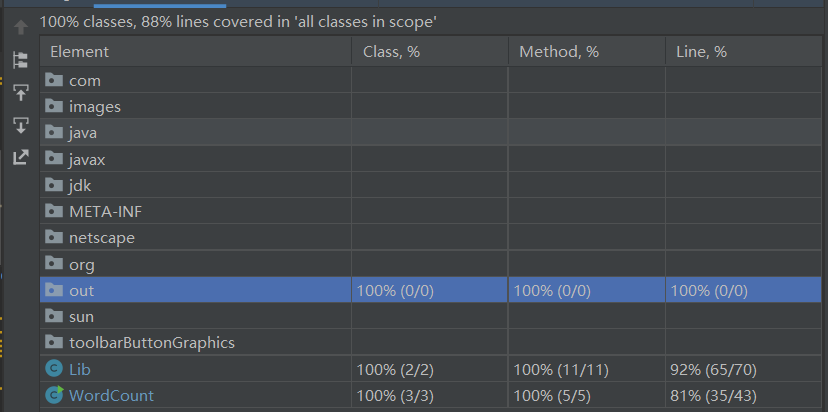
代码覆盖率测试
我的覆盖率情况为:类的覆盖率为100%,方法的覆盖率为100%,代码行覆盖率为88%。
7. 异常处理说明
程序中主要会出现的异常是文件操作以及命令行输入命令的错误。
在文件操作的相应代码中都添加了try catch结构来捕获异常
8. 心路历程与收获
- 心路历程
早就听闻软件工程实践的大名,真正上这门课的时候确实有害怕,怕自己编程能力太差,就和我一直对参加竞赛有着莫名的恐惧一样,害怕自己能力不足,无法在规定的时间内完成任务,特别是在规定时间内要完成新技术的学习,然后马上投入应用。但是既然开始了,那也就只能克服恐惧了。
本次作业是个人编程任务,看到题目的时候我有点欣喜又有点迷茫,欣喜是因为这和我们以前编过的程序功能没什么本质区别,迷茫则是作业要求里又有许多我没接触过的东西,什么 单元测试、性能改进,什么叫单元测试?又怎么去分析程序的性能呢?
刚开始的时候手忙脚乱的,虽然以前也用过git,但是并不熟练,只会简单的pull和push,于是我的commit记录里就多了一条提交测试hhhhh,这还导致我最后多commit了2次来删去之前多提交的文件。
但随着一个功能一个功能的实现我开始进入状态了,连续好几天都是从早上坐到晚上,有些代码写了改,改了删,还会有些莫名其妙的bug,记得最深刻的是BufferedStream的read函数的一个用法错误,导致我读取的文本内容产生了差错,然后那个bug我从早上改到晚上,就是没有改出来,最后发现是没有指定每次从缓冲区读取的长度,改出来的时候差点从椅子上跳起来哈哈哈哈哈,兴奋又懊恼,懊恼自己怎么会犯这么低级的错误,而且效率还这么低。 我反思了一下,是因为缺少合理的休息,一直坐在电脑前是效率底下的,coding期间必须合理地休息。
在初次实现了功能后,我以为自己的程序很可以了...直到运行了大文件,我发现我的程序崩溃了...于是接下来就是各种百度,还有和同学交流探讨,针对计算单词这个功能,我甚至和洋艺同学连着麦,我俩边交流改了一下午才改出来。看见其他同学的方法效率比我的高我就忍不住想问问如何实现的,但又怕被算作抄袭,同时时间也来不及了,就没有更深的改进。
最后完成的时候感觉心里放下了一块大石头
- 收获&不足
提高了自己的编程水平,抗压力能力也变高了不少,毕竟这几天头发没少掉,熬夜也是每天。
熟练使用git和gitdesktop,为以后的团队合作打下基础
效率过低,一个小bug由于思维误区改了一下午
没做好充分的准备就开始编写代码,导致代码复审和性能分析的时候发现自己的算法过于差劲。其实应该在动手编写代码之前先找到最佳的算法,然后再动手实现。

