zipkin的工作原理
基本思想:在服务调用的请求和响应中加入trace ID,标明上下游请求的关系。利用这些信息,可视化地分析服务调用链路和服务间的依赖关系,保存下来进行展示。
时序图:
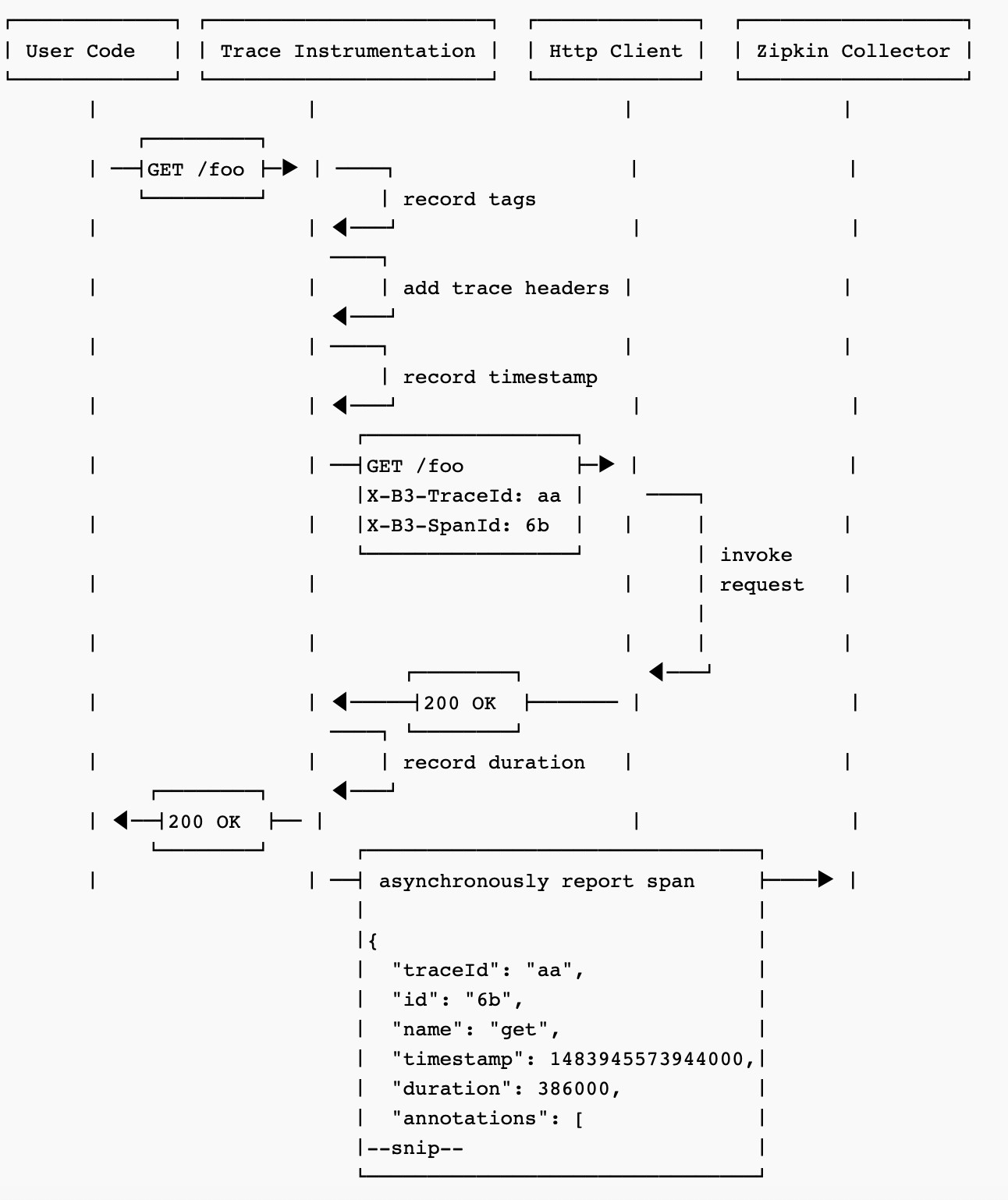
首先是User code,表示的是我们的应用程序代码。
当我们的应用程序接收到请求/foo时,并不会立即执行,而是交由跟踪仪器来处理。

然后是Trace Instrumentation,跟踪仪器,它负责记录标签、添加跟踪头、记录时间戳,此时会产生新的请求,该请求会交给http客户端。
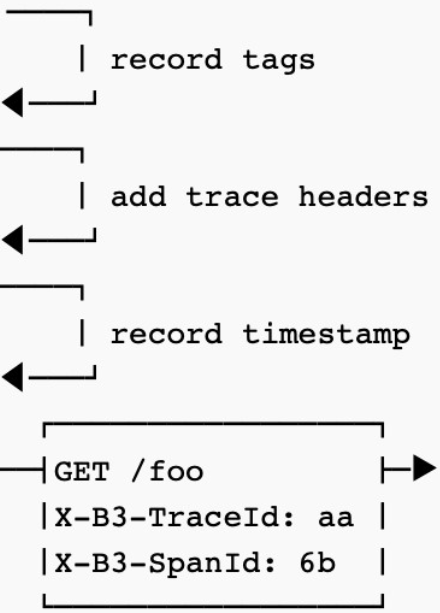
然后是http client,这里用requests,http client会发起新的请求,请求结束后,结果会返回给追踪仪器,然后由追踪仪器分析请求耗费的时间。
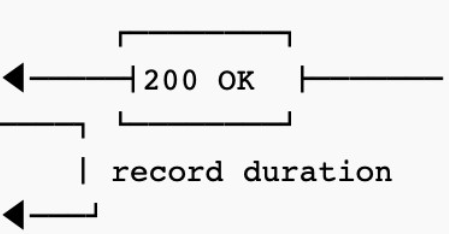
追踪仪器在返回结果给user code的同时,会异步将刚才的请求信息以span的形式报告给zipkin server。
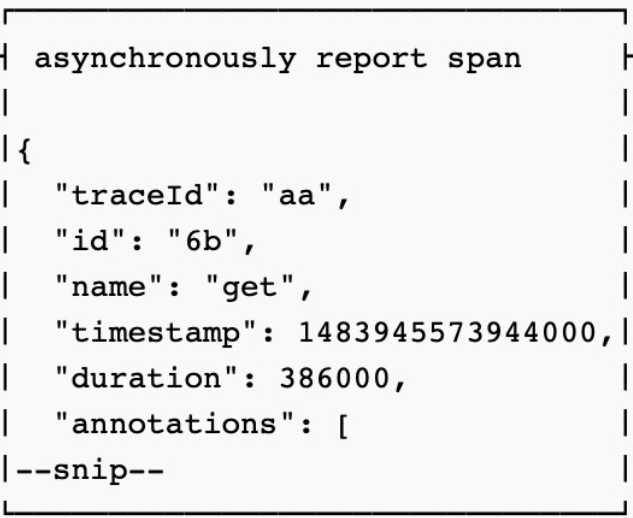
以上就是zipkin在应用程序中扮演的角色。
以代码形式表现zipkin的作用:
1、首先运行zipkin,以docker形式
docker run -d -p 9411:9411 openzipkin/zipkin
访问zipkin
http://192.168.0.105:9411
2、然后编写简单flask应用
这里的python版本为3.9
先安装要使用的包
pip install flask py_zipkin pymysql requests
程序如下:
首先编写文件app.py,内容为:
import time import requests from flask import Flask from py_zipkin.zipkin import zipkin_span, create_http_headers_for_new_span app = Flask(__name__) app.config.update({ "ZIPKIN_HOST": "192.168.0.105", "ZIPKIN_PORT": 9411, "APP_PORT": 5000 }) def do_stuff(): time.sleep(2) headers = create_http_headers_for_new_span() requests.get("http://localhost:6000/service1/", headers=headers) return "OK" def http_transport(encoded_span): body = encoded_span zipkin_url = "http://192.168.0.105:9411/api/v1/spans" headers = {"Content-Type": "application/x-thrift"} r = requests.post( zipkin_url, data=body, headers=headers ) print(type(encoded_span), encoded_span, body, r, r.content) @app.route('/') def index(): with zipkin_span(service_name='webapp', span_name='index', transport_handler=http_transport, port=5000, sample_rate=100): with zipkin_span(service_name='webapp', span_name='do_stuff'): do_stuff() time.sleep(1) return 'OK', 200 if __name__ == '__main__': app.run(host='0.0.0.0', port=5000, debug=True)
然后是文件server1.py,内容为:
from flask import request import requests from flask import Flask from py_zipkin.zipkin import zipkin_span, ZipkinAttrs import time import pymysql app = Flask(__name__) app.config.update({ "ZIPKIN_HOST": "192.168.0.105", "ZIPKIN_PORT": "9411", "APP_PORT": 5000, }) def do_stuff(): time.sleep(2) with zipkin_span(service_name='service1', span_name='service1_db_search'): db_search() return 'OK' def db_search(): # 打开数据库连接 db = pymysql.connect(host="127.0.0.1", user="root", password="123456", database="mysql", charset='utf8') # 使用cursor()方法获取操作游标 cursor = db.cursor() # 使用execute方法执行SQL语句 cursor.execute("SELECT VERSION()") # 使用 fetchone() 方法获取一条数据 data = cursor.fetchone() print("Database version : %s " % data) # 关闭数据库连接 db.close() def http_transport(encoded_span): body = encoded_span zipkin_url = "http://192.168.0.105:9411/api/v1/spans" headers = {"Content-Type": "application/x-thrift"} requests.post(zipkin_url, data=body, headers=headers) @app.route('/service1/') def index(): with zipkin_span( service_name='service1', zipkin_attrs=ZipkinAttrs( trace_id=request.headers['X-B3-TraceID'], span_id=request.headers['X-B3-SpanID'], parent_span_id=request.headers['X-B3-ParentSpanID'], flags=request.headers['X-B3-Flags'], is_sampled=request.headers['X-B3-Sampled'], ), span_name='index_service1', transport_handler=http_transport, port=6000, sample_rate=100, ): with zipkin_span(service_name='service1', span_name='service1_do_stuff'): do_stuff() return 'OK', 200 if __name__ == '__main__': app.run(host="0.0.0.0", port=6000, debug=True)
然后启动app.py
python app.py
然后启动server1.py
python server1.py
其中app.py模拟请求入口,server1.py模拟被请求的服务。
开始访问http://127.0.0.1:5000/
在zipkin中看到的结果为:
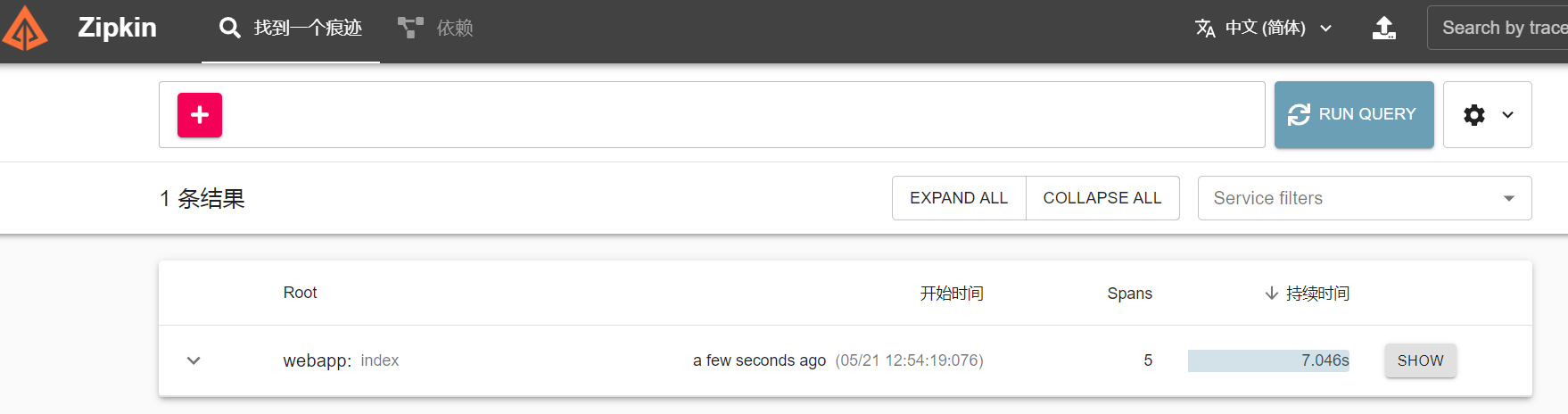
我们点击show,查看具体的信息。
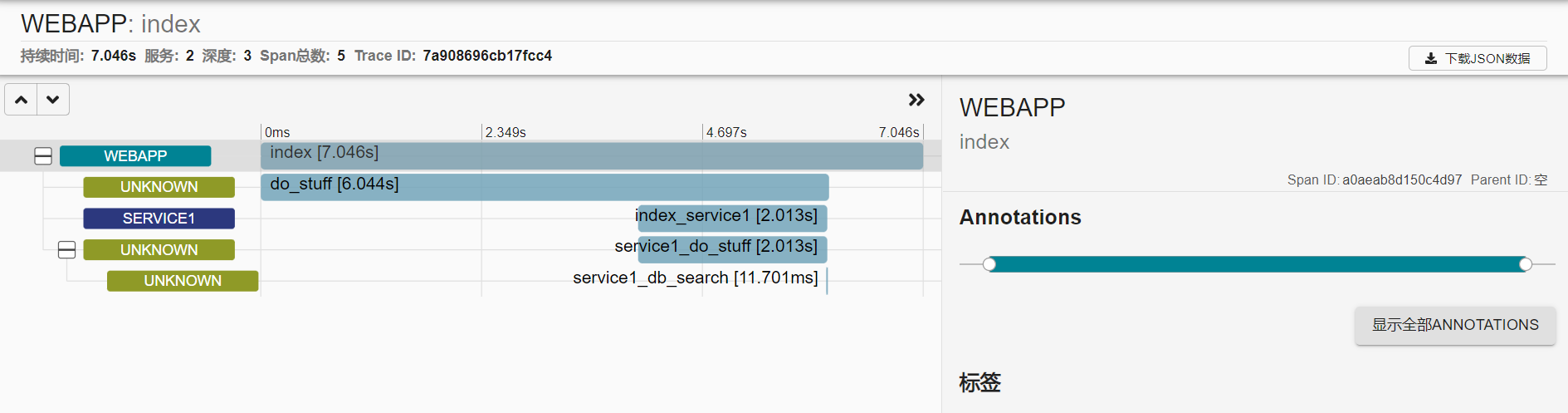
可以看到请求的整个链路调用情况。
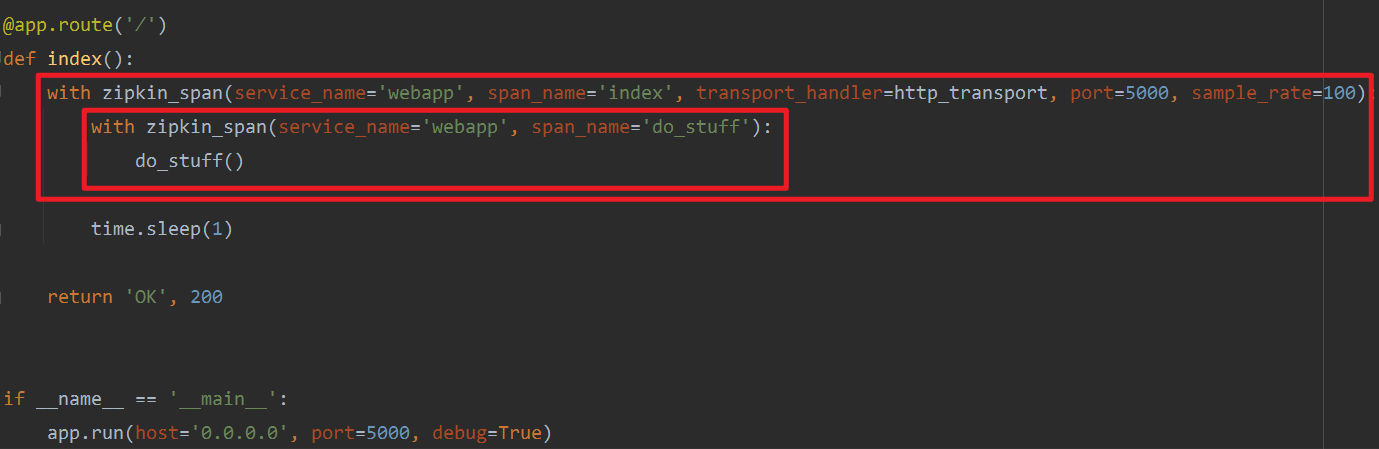
外层的zipkin_span是为index而生成的。
内层的zipkin_span是为do_stuff()而生成的。
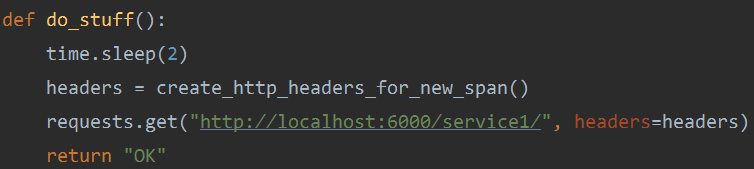
do_stuff首先会生成新的头,然后用requests去请求其他服务。
监听在6000端口的server1.py在接收到请求后,也需要做相应操作。
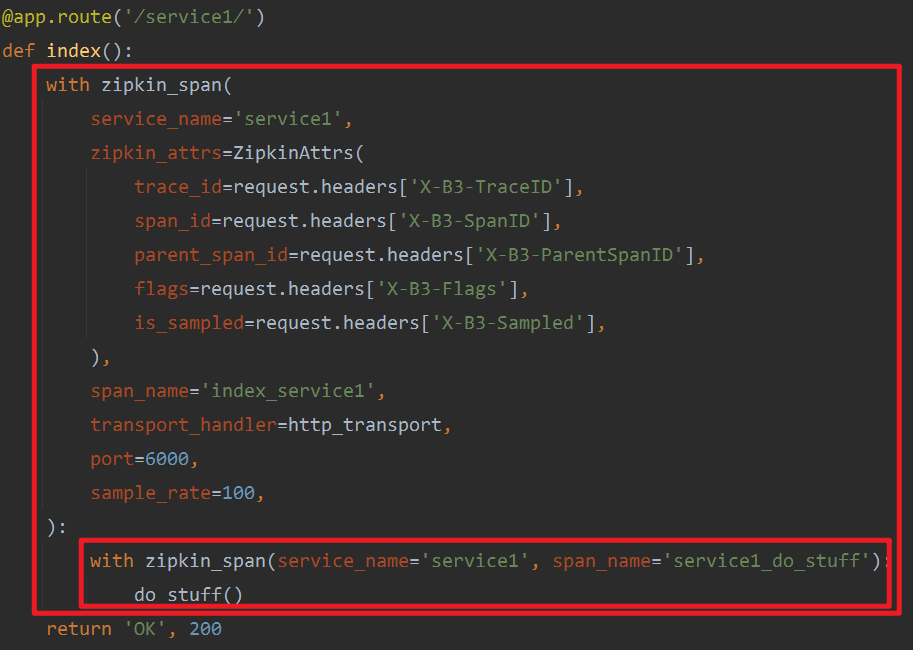
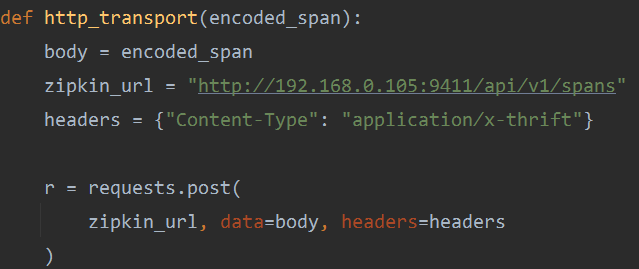
在zipkin_span中的transport_handler就是一个上报地址,即zipkin的服务地址。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号