论文笔记之《Event Extraction via Dynamic Multi-Pooling Convolutional Neural Network》
1. 文章内容概述
- 本人精读了事件抽取领域的经典论文《Event Extraction via Dynamic Multi-Pooling Convolutional Neural Network》,并作出我的读书报告。这篇论文由中科院自动化所赵军、刘康等人发表于ACL2015会议,提出了用CNN模型解决事件抽取任务。
- 在深度学习没有盛行之前,解决事件抽取任务的传统方法,依赖于较为精细的特征设计已经一系列复杂的NLP工具,并且泛化能力较低。针对此类问题,这篇论文提出了一个新颖的事件抽取方法,能够在不借助NLP工具的帮助下,自动抽取词汇级别与句子级别的特征。该方法采用了基于CNN的神经网络结构,对句子级别的数据进行处理。但是普通的CNN是能获取句子最重要的信息,因此当其处理包含多个事件的句子时,会丢失掉一些重要的事实信息。基于上述考虑,这篇文章提出了一个动态多池化的卷积神经网络(DMCNN),具体的多池化操作是对事件的触发词(trigger)与论元(argument)执行的,这么做可以保留更多的关键信息。
- 事件抽取认识的目的是发现事件触发词和于触发词相关的论元。过去最好的方法是利用文本分析与语言学知识提取特征得以实现。一般把特征分为词汇特征和上下文特征。
- 词汇特征包含了词性、实体信息、以及形态学特征,能够捕获词语所蕴含的语义特征。本质上赋予模型更多的先验知识,而不是将每个词语看成简单的个体,那样只能够学习到形式上的差异。
- 上下文特征能够考虑全局信息,将事件相关的各个论元联系在一起,共同作为一个事件抽取的结果,例如句法特征。但是使用这种传统的依存句法特征,很难去发现目标论元,因为某些目标论元与触发词之间,并未存在一条边。而且引入这种句法特征,需要借助于现存的NLP工具,但是这些工具生成的结果也不一定完全正确,会引入更多的错误信息,造成传播误差。
- 目前的研究已经证明,CNN能够有效地捕获句子间词语的语法信息和语义信息。典型的CNN包含了一个最大池化层,能够从整个句子的角度发现最有用的表示信息。但是,对于事件抽取而言,一个句子可能包含两个到三个事件,同时可能有论元在不同的事件中扮演着不同的角色。如果直接使用最大池化层的话,它只会获得句子中最重要的信息,这就有可能令模型只捕获到一个事件的关键信息,而丢弃掉同一个句子的不同事件信息。在这篇文章所采用的数据集中,大约有27.3%的句子级别数据,同时包含了多个事件信息。因此这种现象不可以被忽略,需要设计一个新模型能够很好地解决这类问题。
- 基于上述考虑,这篇文章提出了动态多池化卷积神经网络(DMCNN),能够解决上述问题,在不借助复杂的NLP工具情况下,能够捕获句子级别的信息,并且动态地保留多个重要信息。设计一个动态多池化层,能够保留句子中各个部分的最大值,而每个部分的划分是由句子中触发词与论元的位置所决定。
- 本事件抽取任务所采用的数据集是ACE数据,这里介绍一下ACE数据中的一些专业术语,能够更好地理解这个任务:
- Event mention:描述事件信息的短语或者句子,即同时包含了触发词和论元。
- Event trigger: 短语或者句子中,最能表示一个事件出现的单词,在ACE数据中,这个词通常是动词或名词。
- Event argument:短语或者句子中,包含的实体、时间表达式、或者数值。
- Argument role: 一个论元在事件中扮演的角色。
- 从上述术语定义中可以发现,事件抽取依赖于名实体识别的结果,而名实体识别是ACE评测中另一个比较困难的任务,并不包含于事件抽取任务中。因此这篇文章直接使用了句子中的实体标注结果,只关注于实现事件抽取模型。
2. 阅读评述
-
本文将事件抽取任务定义为包含两个阶段的多分类任务。第一个阶段是触发词分类,利用DMCNN模型对句子中的每个单词进行识别,判断是否为触发词。如果一个句子中包含了触发词,那么开始执行第二个阶段;第二个阶段是论元分类,这里使用了相似的DMCNN模型,对句字中除了触发词以外的所有实体论元进行判别,识别出与该触发词存在关系的论元以及该论元所扮演的论元角色。由于这两个阶段的模型结构基本相同,前者是后者的简化版本,因此对第二阶段的模型进行详细介绍,之后阐述第一阶段模型对第二阶段模型的不同之处。
-
图1-论元分类模型结构
![]()
-
图1描述了论元分类的模型结构,主要包含了以下四个组件:
- 词嵌入学习,以一个无监督的方式学习到单词的嵌入向量。
- 词汇级特征表示,利用词嵌入向量捕获词汇特征信息
- 句子级特征抽取,利用DMCNN模型学习句子的上下文语义特征。
- 论元分类器输出,计算论元可能所属的每个候选论元角色的置信度得分。
-
接下来详细介绍上述4个模型组件。
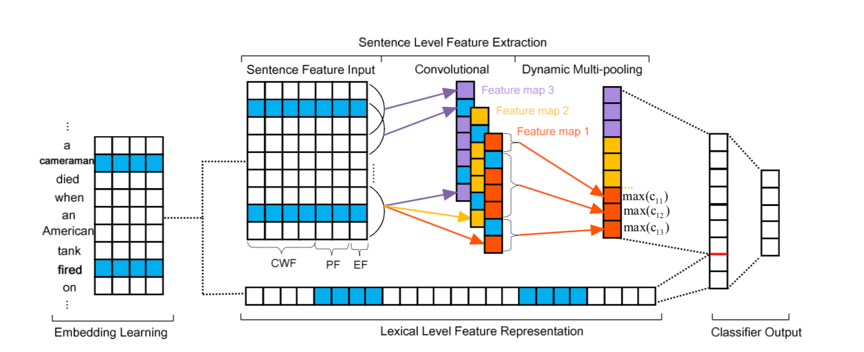
2.1 词嵌入学习和词汇级特征表示
- 词汇级特征是事件抽取中至关重要的线索信息。传统提取词汇特征的方法难以取得令人满意的结果。随着今年来词嵌入方法的提出,人们发现词嵌入可以很好的从大量无监督数据中捕获到每个单词的语义信息。因此本文以预训练的词嵌入向量为基础,从中选择候选单词的词向量,以及候选单词上下文的词向量,将这些所有向量进行拼接以得到整体的词汇级特征向量。其中候选单词指的是待分类的单词,上下文指的是候选单词左边的词语和候选单词右边的词语,而用于构建词嵌入向量的方法是Skip-gram模型。
2.2 句子级特征抽取
-
带有最大池化层的CNN是一个捕获句子中长距离语义信息的很好的选择。但是,正如上文所说的那样,传统CNN模型没有办法处理事件抽取任务中,一个句子包含多个事件的情况。为了更好地解决这种问题,文章提出了DMCNN模型去抽取句子特征信息。相较于传统CNN模型,DMCNN模型将最大池化层改进为动态多池化层,这样能够捕获到句子中不同部分的最重要的信息,而不是只捕获全局最重要的信息。其中句子的每个部分是依据事件触发词和事件论元所在的位置动态地划分(即把一个句子分为三个部分)。
-
首先介绍DMCNN模型的输入,虽然本任务从本质上属于多分类任务,但是在模型的输入上有很大的不同。传统的分类模型,只需要将句子的词嵌入矩阵作为输入,模型对于句子中的每个单词再输入阶段都是无差别对待的。而对于本任务来说,希望识别句子中某一单词的在某一事件中的具体角色,某一单词指的就是实体论元,某一事件指的是事件触发词所对应的事件类型,所以DMCNN模型再输入阶段应该区别对待论元单词与事件触发词。如果不引入这种输入信息,对于同一个句子,它对应的类别永远是同一个,这不符合事件抽取任务的需求。基于这种考虑,DMCNN所使用的输入信息有:
-
上下文单词特征(CWF, Context Word Feature):将整个句子中的所有单词看作上下文,因此CWF就是每个单词的词嵌入向量。
-
位置特征(PF, Postion Feature):在论元分类任务中,强调句子中哪些单词是触发词或候选论元是十分重要的。因此在输入中添加位置信息,表示每个单词分别与触发词、候选论元的相对距离。为了编码位置特征,每个距离数值都被表示为一个嵌入向量。这个向量在网络中随机初始化,并通过网络的反响传播进行优化。
-
事件类型特征(EF,Event-type Feature):在论元分类任务中,触发词所属的事件类型也是十分重要的,因此我们在触发词分类任务中,对事件类型进行编码,并将其应用于论元分类任务中。
-
-
在实际的网络构建过程中,我们将每个单词的词嵌入向量、与触发词相对距离向量、与候选论元相对距离向量、事件类型向量进行级联。将四个向量拼成一个长向量,作为单词的最终表示。
2.3 卷积
- 卷积层的目标是捕获整个句子的语义信息,并通过特征图语义信息进行压缩。通常来讲,\(x _ { i : i + j }\)令表示单词\(x _ { i } , \quad x _ { i + 1 } , \quad \ldots , \quad x _ { i + j }\)的级联矩阵。一个卷积操作包含一个过滤器w \in \mathbb { R } ^ { h \times d },\(h\)是过滤器的维度大小,\(d\)是每个单词的向量维度。过滤器的维度大小也就是卷积操作的窗口大小,由\(h\)个单词共同计算出一个新的特征向量\(c_i\),计算公式如下:
-
其中\(b\)是偏置,为实数。\(f\)是非线性函数。通过窗口移动,是的该操作对每个单词都执行一遍。
-
实际情况当然不可能只使用一个过滤器,一般用多个过滤器去获取不同层面的特征值,需要注意的是这些过滤器的窗口大小是相同的。我们使用了个过滤器,因此最后生成的特征矩阵\(C \in \mathbb { R } ^ { m \times ( n - h + 1 ) }\)。
2.4 动态多池化
-
如前文所说,为了能够抽取句子中的不同部分的重要信息,本文设计了一个动态多池化层。因为在事件抽取任务中,一个句子可能包含多个事件,并且一个候选论元相对于不同触发词可能扮演不同的角色。为了得到一个更加准确的预测,应该让模型捕获到触发词、候选词变化的信息。因此在论元分类任务中,我们将卷积得到的特征图分为三个部分,按照触发词、候选论元所在的位置进行切分。之后使用每个部分的特征最大值作为最终提取的特征,而不是像max-pooling那样使用一个全局最大值表示整个句子的特征,这样可以避免丢失掉很多对事件抽取任务有帮助的信息。
-
从数学的角度上讲,另一个特征向量为\(c_I\),根据触发词、候选论元所在位置,将其划分三段特征向量c _ { i 1 } , \quad c _ { i 2 } , \quad c _ { i 3 },然后进行如下的动态多池化操作,其中\(1 \leq j \leq 3\):
- 之后我们将生成的\(p _ { i 1 } , \quad p _ { i 2 } , \quad p _ { i 3 }\)级联,得到新的向量\(\mathrm { P } \in \mathbb { R } ^ { 3 m }\),把其看作为句子级别的高层次特征表示。
2.5 输出
-
通过上述三个组件,我们已经得到了每个单词的词汇级特征\(L\)和句子级特征\(P\),将这两个特征向量进行级联,得到了每个单词的最终表示向量\(F = [ L , P ]\),之后通过常用的全连接层进行分类。类别数量是所有论元角色的数量,包括None角色。
-
通过上述流程,我们描述了第二阶段任务——论元分类的整个模型结构,现在介绍一下第一阶段任务——触发词分类的模型结构的不同之处。
-
对于第一阶段任务,只需要找到句子中的触发词即可,任务难度较低,因此我们采用一个简化版的DMCNN。首先我们只使用触发词与其左边和右边的单词构建词汇级特征\(L\),在提取句子级上下文特征时,使用和论元分类相同的处理方式,不过只根据候选触发词的位置,将句子切分为两个部分。之后的处理流程完全相同,都是当作一个分类任务处理。
2.6 实验
-
本文使用ACE2005语料库作为实验数据。根据前人的工作,采用如下标准来衡量预测结果:
-
如果事件类型与候选触发词在句子中的偏移量正确,则认为触发词识别正确。
-
如果事件类型和候选论元在句子中的偏移量正确,则认为论元识别正确。
-
如果事件类型、候选论元偏移量和论元角色正确,则认为论元正确分类。
-
-
使用准确率、召回率、F1值作为评价指标。
-
在触发词分类任务中,卷积操作的过滤器窗口大小为3,过滤器数量为200,batch size大小为170,位置特征PF的维度为5。在论元分类任务中,过滤器窗口大小为3,过滤器数量为300,batch size大小为20,位置特征PF和事件类型特征EF的维度都为5。训练过程中使用Adadelta作为优化器,dropout的大小为0.5。词嵌入向量使用Skig-gram算法在NYT语料库上训练。
-
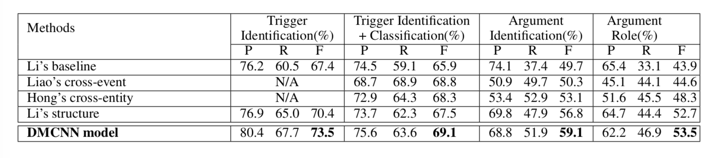
表1-实验结果
![]()
-
表1记录了本文提出的DMCNN模型在测试数据集上的效果。从结果可以看出,与其他模型相比DMCNN模型取得了最好的效果。其他模型有的引入了人工编写的特征,而本模型的特征全部由模型自动抽取得到的,这也从另一方面证明的该模型抽取的特征有一定的实际意义。
3. 总结
- 这篇文章提出了一个新颖的事件抽取方法,能够不借助其他复杂的NLP工具,自动从原文本中抽取词汇级与句子级的特征。利用词嵌入模型的组合捕获词汇级特征,利用DMCNN模型编码句子级语义信息。通过实验可以证明该方法是十分有效的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号