


网络爬虫入门系列(三) (Jsoup)
上一篇文章介绍了httpUrlConnection 访问网页 的java 代码
本篇文章介绍Jsoup 访问网页
首先 到官网上 https://jsoup.org/download 下载 Jsoup-1.11.2.jar
导入到项目中
新建一个类 jsoupCrawler
编写如下代码
package org.apache.crawlerType; import java.io.IOException; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; public class jsoupCrawler { public static void main(String[] args) { try { Document doc=Jsoup.connect("http://www.cnblogs.com/szw-blog/p/8565944.html") .timeout(1000) //设置超时时间 .userAgent("Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:58.0) Gecko/20100101 Firefox/58.0") //设置浏览器请求头 .header("Accept-Language", "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2") //设置请求头 .get(); System.out.println(doc.toString()); } catch (IOException e) { e.printStackTrace(); } } }
运行后的结果是
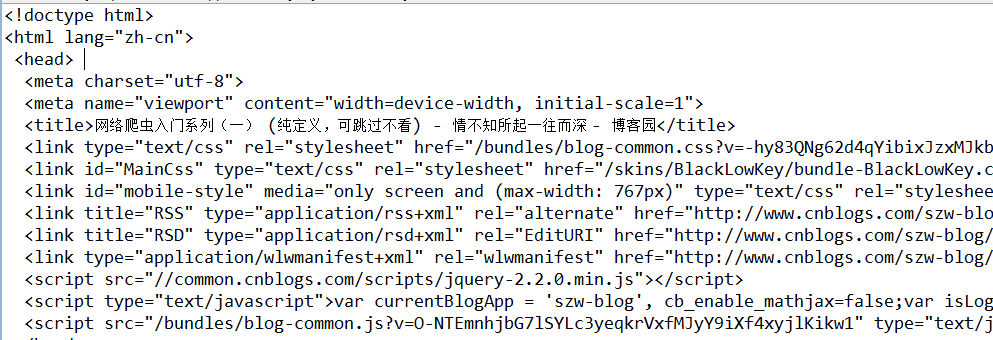
以上就是 Jsoup 访问网页的 java 代码

