第六周学习笔记
第三章 Unix/Linux进程管理
3.1 多任务处理
-
多任务处理指同时执行几个独立的任务。
-
多任务处理通过在不同任务之间多路复用CPU的执行时间来实现的,即将CPU执行操作从一个任务切换到另一个任务。
-
多任务处理是所有操作系统的基础。
-
总体上说,也是并行编程的基础。
3.2 进程的概念
执行映像:包含执行代码、数据和堆栈的存储区。
进程是对映像的执行。
-
在操作系统内核中,每个进程用一个独特的数据结构表示,叫作进程控制块(PCB)或任务控制块(TCB)等。在本书中,我们直接称它为PROC结构体。
-
与包含某个人所有信息的个人记录一样,PROC结构体包含某个进程的所有信息。
typedef struct proc{ struct proc *next; // next proc pointer int *ksp; // saved sp: at byte offset 4 int pid; // process ID int ppid; // parent process pid int status; // PROC status=FREE | READY, etc. int priority; // scheduling priority int kstack [1024] ; // process execution stack }PROC;
3.3 多任务处理系统
多任务处理系统,简称MT,由以下几个部分组成。
1. type.h 文件
type.h文件定义了系统常数和表示进程的简单的PROC结构体。
#define NPROC 9 //number of PROCB
#define SSIZE 1024 //stack size= 4KB
// PROC status
#define FREE 0
#define READY 1
#define SLEEP 2
#define ZOMBIE 3
typedef struct proc{
struct proc *next; // next proc pointer
int *ksp; // saved stack pointer
int pid; // pid = 0 to NPROC-1
int ppid; // parent process pid
int status; // PROC status
int priority; // scheduling priority
int kstack [1024] ; // process stack
}PROC;
2.ts.s 文件
ts.s在32位GCC汇编代码中可实现进程上下文切换。
3.queue.c文件
queue.c文件可实现队列和链表操作函数。
enqueue() 函数按优先级将PROC输入队列中。
dequeue() 函数可返回从队列或链表中删除的第一个元素。
printList() 函数可打印链表元素。
4.t.c文件
t.c文件定义MT系统数据结构、系统初始化代码和进程管理函数。
5.多任务处理系统代码介绍
(1)虚拟CPU:MT系统在Linux下编译链接为
gcc -m32 t.c ts.s
(2)init() :当MT系统启动时,main()函数调用init()以初始化系统。
(3)P0调用kfork()来创建优先级为1的子进程P1,并将其输入就绪队列中。
(4)tswitch():tswitch()函数实现进程上下文切换。
(5)kfork():创建一个子任务并将其输入readyQueue中。
(6)body():为便于演示,所有创建的任务都执行同一个body()函数。
(7)空闲任务P0:在所有任务中具有最低的优先级。
(8)运行多任务处理(MT)系统:在Linux下,输入:
gcc -m33 t.c s.s
3.4 进程同步
进程同步是指控制和协调进程交互以确保其正确执行所需的各项规则和机制。最简单的进程同步工具是休眠和唤醒操作。
睡眠模式

唤醒操作
kwakeup(event):唤醒正处于休眠状态等待改时间值的所有程序。
3.5 进程终止
-
正常终止:进程调用exit(value),发出_exit(value)系统调用来执行在操作系统内核中的kexit(value)。
-
异常终止:进程因某个信号而异常终止。
在这两种情况下,当进程终止时,最终都会在操作系统内核中调用kexit()。
kexit() 的算法

进程家族树
PROC *child, *sibling, *parent;

等待子程序终止
在任何时候,进程可以调用内核函数
pid = kwait(int *status)
等待僵尸子进程。若成功,则返回僵尸子进程的pid,而status包含僵尸子进程的退出代码。
在kwait算法中,如果没有子进程,则进程会返回-1,表示错误。否则,他将搜索僵尸子进程。如果他找到僵尸子进程,就会收集僵尸子进程的pid和退出代码。
当进程终止时,他必须发出:
kwakeup(running->parent)
以唤醒父进程。
3.7 Unix/Linux中的进程
进程来源
- 当操作系统启动时,操作系统内核的启动代码会强行创建一个PID=0初始进程。
- 执行初始进程P0
- P0继续初始化系统,包括系统硬件和内核数据结构
- 挂载一个根文件系统,使系统可以使用文件。
- 在初始化系统之后,P0复刻出一个子进程P1,并把进程切换为以用户模式运行P1。
INIT和守护进程
当进程P1开始运行时,它将其执行映像更改为INIT程序。因此,P1通常被称为INIT进程,因为它的执行映像是init程序。P1 开始复刻出许多子进程。
P1的大部分子进程都是用来提供系统服务的。它们在后台运行,不与任何用户交互。这样的进程称为守护进程。
登陆进程
除了守护进程之外,P1还复刻了许多LOGIN进程,每个终端上一个,用于用户登录。
sh进程
当用户成功登录时,LOGIN进程会获取用户的gid和uid,从而称为用户的进程。他将目录更改为用户的主目录并执行列出的程序,通常是命令解释程序sh。
进程的执行模式
在Unix/Linux中进程以两种不同的模式执行,即内核模式和用户模式,简称Kmode和Umode。在每种执行模式下,一个进程有一个执行映像。
3.8 进程管理的系统调用
fork()
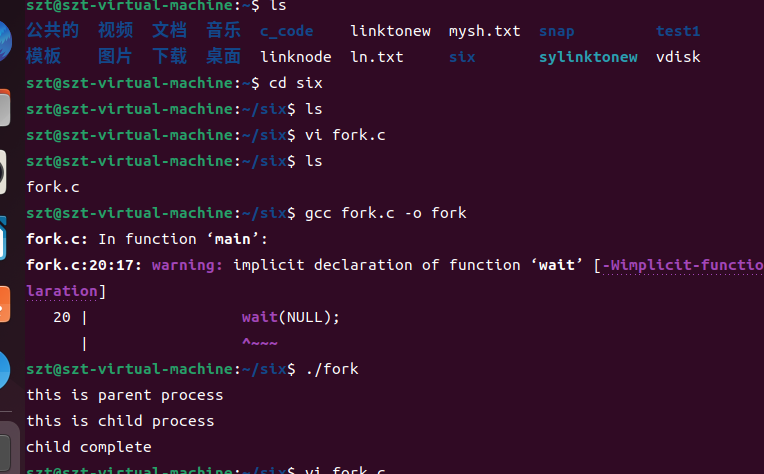
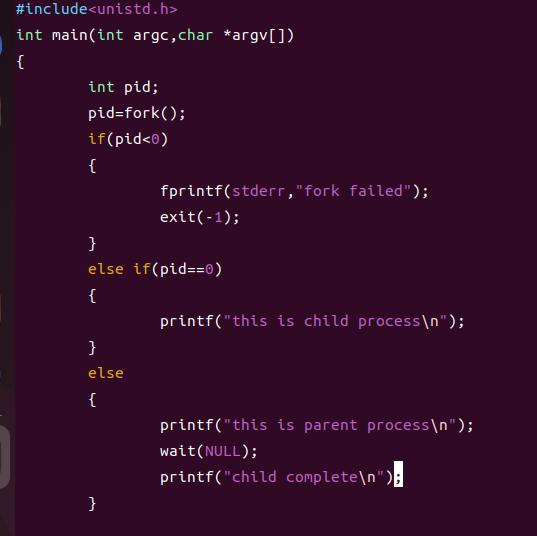
fork() 创建子进程并返回子进程的pid,如果fork()失败则返回-1。
int pid = fork();
进程执行顺序
进程终止
(1)正常终止:当内核中的某个进程终止时,他会将_exit(value)系统调用中的值记录为进程PROC结构体中的退出状态。并通知他的父进程并使该进程成为僵尸进程。父进程可通过系统调用找到僵尸子进程,获得其pid和退出状态
pid = wait(int *status);
(2)异常终止:在执行某程序时,进程可能会遇到错误,如非法指令、越权、除零等,这些错误会被CPU识别为异常。当某进程遇到异常时,它会阱人操作系统内核。内核的异常处理程序将陷阱错位类型转换为一个幻数,称为信号,将信号传递给进程,使进程终止。用户可以使用命令
kill -s signal_numeber pid
I/O重定向
sh进程有三个用于终端I/O的文件流:stdin(标准输入)、stdout(标准输出)、stderr(标准错误)。
I/O重定向符号和功能说明
[n]<&m:将标准输入或文件描述符n重定向到文件描述符m
[n]<file:将标准输入或文件描述符n重定向到文件file。特别的<file将标准输入重定向到文件file
<file:将标准输入重定向到文件file。[n]<file 的特例
[n]>&m:将标准输出或文件描述符n重定向到m。特别的2>&1将标准错误重定向到标准输出
[n]>[|]file:将标准输出或文件描述符n重定向到文件file (覆盖方式)
>file:将标准输出重定向到文件file (覆盖方式)。[n]>file的特例。
2>file:将标准错误重定向到文件file(覆盖方式)
>>file:将标准输出重定向到文件file(追加方式)
2>>file:将标准错误重定向到文件file(追加方式)
&>或>&:同时重定向标准输出和标准错误输出
<<:即时文档输入符
3.10 管道
管道是用于进程交换数据的单向进程件通信通道。管道有一个读取端和一个写入端。
管道命令处理
在Unix/Linux中,命令行cmd1 | cmd2
sh将通过一个进程运行cmd1,并通过另一个进程运行cmd2,他们通过一个管道连接在一起,因此cmd1的输出变为cmd2的输入。
命名管道
命名管道又叫做FIFO。
(1)在sh中,通过mknod命令创建一个命令管道:mknod mypipe p
(2)或在c语言中发出mknod()系统调用:int r = mknod("mypipe",s_IFIFP,0);
实践部分
fork()函数可以建立一个新进程,把当前的进程分为父进程和子进程,新进程称为子进程,而原进程称为父进程。fork调用一次,返回两次,这两个返回分别带回它们各自的返回值,其中在父进程中的返回值是子进程的PID,而子进程中的返回值则返回 0。因此,可以通过返回值来判定该进程是父进程还是子进程。