

本文使用google翻译,未修正!
具体请参照 原文: https://www.wireshark.org/docs/wsug_html/
Wireshark用户指南
版本3.1.0
目录
- 前言
- 1.简介
- 2.构建和安装Wireshark
- 3.用户界面
- 4.捕获实时网络数据
- 5.文件输入,输出和打印
- 6.使用捕获的数据包
- 7.高级主题
- 8.统计
- 9.电话
- 10.无线
- 11.定制Wireshark
- 12.伴侣
- A. Wireshark消息
- B.文件和文件夹
- C.协议和协议字段D.相关的命令行工具
- 13.本文件的许可证(GPL)
数字清单
- 1.1。Wireshark捕获数据包并让您检查其内容。3.1。主窗口3.2。菜单3.3。“文件”菜单3.4。“编辑”菜单3.5。“查看”菜单3.6。“开始”菜单3.7。“捕获”菜单3.8。“分析”菜单3.9。“统计”菜单3.10。“电话”菜单3.11。“工具”菜单3.12。“帮助”菜单3.13。“主”工具栏3.14。“过滤器”工具栏3.15。“数据包列表”窗格3.16。“数据包详细信息”窗格3.17。“数据包字节”窗格3.18。带有选项卡的“数据包字节”窗格3.19。初始状态栏3.20。带有加载的捕获文件的状态栏3.21。具有配置配置文件菜单的状态栏3.22。具有所选协议字段的状态栏3.23。状态栏带有显示过滤器消息4.1。Microsoft Windows上的“捕获接口”对话框4.2。Unix / Linux上的“捕获接口”对话框4.3。“捕获选项”对话框4.4。“编辑接口设置”对话框4.5。“编译结果”对话框4.6。“添加新接口”对话框4.7。“添加新接口 - 管道”对话框4.8。“添加新接口 - 本地接口”对话框4.9。“添加新接口 - 远程接口”对话框4.10。“远程捕获接口”对话框4.11。“远程捕获设置”对话框4.12。“接口详细信息”对话框4.13。捕获输出选项4.14。“捕获信息”对话框5.1。在Microsoft Windows上“打开”5.2。“开放” - Linux和UNIX5.3。在Microsoft Windows上“保存”5.4。在Linux和UNIX上“保存”5.5。Microsoft Windows上的“合并”5.6。在Linux和UNIX上“合并”5.7。“从十六进制转储导入”对话框5.8。“列出文件”对话框5.9。“导出为纯文本文件”对话框5.10。“导出为PostScript文件”对话框5.11。“导出为PSML文件”对话框5.12。“导出为PDML文件”对话框5.13。“导出所选数据包字节”对话框5.14。“导出对象”对话框5.15。“打印”对话框5.16。“数据包范围”框架5.17。“数据包格式”框架6.1。Wireshark选择了一个TCP数据包进行查看6.2。在单独的窗口中查看数据包6.3。“数据包列表”列标题的弹出菜单6.4。“数据包列表”窗格的弹出菜单6.5。“数据包详细信息”窗格的弹出菜单6.6。“数据包字节”窗格的弹出菜单6.7。过滤TCP协议6.8。“过滤器表达式”对话框6.9。“捕获过滤器”和“显示过滤器”对话框6.10。“查找数据包”工具栏6.11。“转到数据包”工具栏6.12。Wireshark显示时间参考数据包7.1。“Follow TCP Stream”对话框7.2。“专家信息”对话框7.3。“Colorized”协议详细说明了树7.4。“专家”数据包列表列7.5。“TCP分析”包详细信息项7.6。“数据包字节”窗格,其中包含重新组合的选项卡8.1。“捕获文件属性”窗口8.2。“协议层次结构”窗口8.3。“对话”窗口8.4。“端点”窗口8.5。“IO图表”窗口8.6。“Compute DCE-RPC statistics”窗口8.7。“DCE-RPC Statistic for ...”窗口8.8。“HTTP请求序列”窗口9.1。“LTE MAC流量统计”窗口9.2。“LTE RLC流量统计”窗口9.3。“RTP流分析”窗口10.1。“WLAN流量统计”窗口11.1。“着色规则”对话框11.2。一个颜色选择器11.3。使用Wireshark的彩色滤镜11.4。“启用协议”对话框11.5。“解码为”对话框11.6。“解码为:显示”对话框11.7。首选项对话框11.8。界面选项对话框11.9。配置配置文件对话框
表格列表
- 1. 印刷约定3.1。键盘导航3.2。文件菜单项3.3。编辑菜单项3.4。查看菜单项3.5。内部菜单项3.6。去菜单项目3.7。捕获菜单项3.8。分析菜单项3.9。统计菜单项3.10。电话菜单项3.11。工具菜单项3.12。帮助菜单项3.13。主工具栏项3.14。过滤工具栏项3.15。相关包符号4.1。捕获选项选择的捕获文件模式6.1。“数据包列表”列标题弹出菜单的菜单项6.2。“数据包列表”弹出菜单的菜单项6.3。“数据包详细信息”弹出菜单的菜单项6.4。“数据包字节”弹出菜单的菜单项6.5。显示过滤比较运算符6.6。显示过滤器逻辑操作6.7。显示过滤器功能7.1。一些示例专家信息7.2。UTC到达时间的时区示例(无DST)B.1。配置文件概述
实例清单
Wireshark是世界上最重要的网络协议分析器,但丰富的功能集对于不熟悉的人来说可能是令人生畏的。本文档是Wireshark团队努力改进Wireshark可用性的一部分。我们希望您发现它有用并期待您的意见。
本书的目标受众是使用Wireshark的任何人。
本书解释了Wireshark的所有基本功能和一些高级功能。由于Wireshark已成为一个非常复杂的程序,因此本书中并未解释所有功能。
本书不是为了解释一般的网络嗅探,也不提供有关特定网络协议的详细信息。有关这些主题的大量有用信息可以在Wireshark Wiki上找到,网址为https://wiki.wireshark.org/。
通过阅读本书,您将学习如何安装Wireshark,如何使用图形用户界面的基本元素(例如菜单)以及一些乍一看并不总是显而易见的高级功能背后的内容。它有望引导您解决一些常见问题,这些问题经常出现在新的(有时甚至是高级的)Wireshark用户身上。
作者要感谢整个Wireshark团队的帮助。特别是,作者要感谢:
- Gerald Combs,负责启动Wireshark项目并为此文档提供资金。
- Guy Harris,在审阅本文档时提供了许多有用的提示和极大的耐心。
- 吉尔伯特拉米雷斯,一路鼓励和有用的提示。
作者还要感谢以下人员对本文档的有益反馈:
- Pat Eyler,关于改进生成回溯的例子的建议。
- 马丁雷格纳,他的各种建议和更正。
- Graeme Hewson,进行了许多语法修正。
作者要感谢Wireshark项目的那些手册页和README作者,他们从这篇文章的各个部分借了很多钱:
- Scott Renfro的
mergecap手册页D.8节,“ mergecap:将多个捕获文件合并为一个”。 - Ashok Narayanan来自其
text2pcap手册页D.9节,“ text2pcap:将ASCII hexdumps转换为网络捕获”。
这本书最初由Richard Sharpe开发,由Wireshark Fund提供资金。它由Ed Warnicke更新, 最近由Ulf Lamping重新设计和更新。
它最初是用DocBook / XML编写的,并由Gerald Combs转换为AsciiDoc。
可以在https://www.wireshark.org/docs/上找到该文档的最新副本 。
如果您对本文档有任何反馈意见,请通过wireshark-dev [AT] wireshark.org发送给作者。
下表显示了本指南中使用的印刷约定。
表1.印刷约定
| 样式 | 描述 | 例 |
|---|---|---|
|
斜体 |
文件名,文件夹名称和扩展名 |
C:\ Development \ wireshark。 |
|
|
命令,标志和环境变量 |
CMake的 |
|
|
应由用户运行的命令 |
跑 |
|
|
对话框和窗口按钮 |
按 |
|
键 |
键盘快捷键 |
按Ctrl + 向下移动到下一个数据包。 |
|
|
菜单项 |
选择 |
重要和值得注意的项目标记如下:
![[警告]](https://www.wireshark.org/docs/wsug_html/wsug_graphics/warning.svg) |
这是一个警告 |
|---|---|
|
您应该注意警告,否则可能会丢失数据。 |
![[注意]](https://www.wireshark.org/docs/wsug_html/wsug_graphics/note.svg) |
这是一张纸条 |
|---|---|
|
注意事项将指出常见的错误和可能不明显的事情。 |
![[小费]](https://www.wireshark.org/docs/wsug_html/wsug_graphics/tip.svg) |
这是一个提示 |
|---|---|
|
提示对使用Wireshark的日常工作很有帮助。 |
Bourne shell,普通用户。
$#这是评论
$ git config --global log.abbrevcommit true
Bourne shell,root用户。
##这是评论
#ninja安装
命令提示符(cmd.exe)。
> rem这是评论
> cd C:\ Development
电源外壳。
PS $>#这是评论
PS $> choco list -l
C源代码。
#include“config.h” / *这个方法解析foos * / static int dissect_foo_message(tvbuff_t * tvb,packet_info * pinfo _U_,proto_tree * tree _U_,void * data _U_) { / * TODO:实施您的解剖代码* / return tvb_captured_length(tvb); }
Wireshark是一个网络数据包分析器。网络数据包分析器将尝试捕获网络数据包并尝试尽可能详细地显示该数据包数据。
您可以将网络数据包分析器视为用于检查网络电缆内部发生情况的测量设备,就像电工使用电压表来检查电缆内部发生的情况一样(当然,更高级别)。
过去,这些工具要么非常昂贵,要么专有,或者两者兼而有之。然而,随着Wireshark的出现,情况发生了变化。Wireshark是免费提供的,是开源的,是当今最好的数据包分析器之一。
以下是人们使用Wireshark的一些原因:
- 网络管理员使用它来解决网络问题
- 网络安全工程师使用它来检查安全问题
- QA工程师使用它来验证网络应用程序
- 开发人员使用它来调试协议实现
- 人们用它来学习网络协议内部
Wireshark在许多其他情况下也很有帮助。
以下是Wireshark提供的众多功能中的一部分:
- 适用于UNIX和Windows。
- 从网络接口捕获实时数据包数据。
- 打开包含使用tcpdump / WinDump,Wireshark和许多其他数据包捕获程序捕获的数据包数据的文件。
- 从包含十六进制数据包数据的文本文件导入数据包。
- 显示数据包与非常详细的协议信息。
- 保存捕获的数据包数据
- 以多种捕获文件格式导出部分或全部数据包。
- 根据许多标准过滤数据包。
- 按许多标准搜索数据包。
- 基于过滤器着色数据包显示。
- 创建各种统计数据。
- ......还有更多!
但是,要真正欣赏它的力量,你必须开始使用它。
图1.1,“Wireshark捕获数据包并让你检查它们的内容。”显示Wireshark捕获了一些数据包并等待你检查它们。

Wireshark可以捕获来自许多不同网络媒体类型的流量,包括以太网,无线LAN,蓝牙,USB等。支持的特定媒体类型可能受到多种因素的限制,包括您的硬件和操作系统。有关支持的媒体类型的概述,请访问https://wiki.wireshark.org/CaptureSetup/NetworkMedia。
Wireshark可以从大量捕获程序中打开数据包捕获。有关输入格式的列表,请参见第5.2.2节“输入文件格式”。
Wireshark可以以多种格式保存捕获的数据包,包括其他捕获程序使用的数据包。有关输出格式的列表,请参见第5.3.2节“输出文件格式”。
对于许多协议,存在协议解析器(或解码器,因为它们在其他产品中已知):参见附录C,协议和协议字段。
Wireshark是一个开源软件项目,根据 GNU通用公共许可证(GPL)发布。您可以在任何数量的计算机上自由使用Wireshark,而无需担心许可证密钥或费用等。此外,所有源代码均可在GPL下免费获取。因此,人们很容易将新协议添加到Wireshark,无论是作为插件还是内置到源代码中,他们经常这样做!
Wireshark所需的资源量取决于您的环境以及您正在分析的捕获文件的大小。对于不超过几百MB的中小型捕获文件,下面的值应该没问题。较大的捕获文件将需要更多的内存和磁盘空间。
|
繁忙的网络意味着大量的捕获 |
|---|---|
|
繁忙的网络可以产生巨大的捕获文件。即使在100兆网络上捕获也可以在短时间内产生数百兆的捕获数据。具有快速处理器,大量内存和磁盘空间的计算机始终是个好主意。 |
如果Wireshark内存不足,它将崩溃。有关详细信息和解决方法,请参阅https://wiki.wireshark.org/KnownBugs/OutOfMemory。
尽管Wireshark使用单独的进程来捕获数据包,但数据包分析是单线程的,并且不会从多核系统中获益。
Wireshark应该支持仍在其扩展支持生命周期内的任何Windows版本 。在撰写本文时,这包括Windows 10,8,7,Server 2019,Server 2016,Server 2012 R2,Server 2012和Server 2008 R2。它还需要以下内容:
- 通用C运行时。这包含在Windows 10和Windows Server 2019中,如果启用了Microsoft Windows Update,则会自动安装在早期版本上。否则,您必须安装 KB2999226或 KB3118401。
- 任何现代64位AMD64 / x86-64或32位x86处理器。
- 500 MB可用内存。较大的捕获文件需要更多RAM。
- 500 MB可用磁盘空间。捕获文件需要额外的磁盘空间。
- 任何现代展示。建议使用1280×1024或更高分辨率。Wireshark将使用HiDPI或Retina分辨率(如果有)。高级用户会发现多个监视器很有用。
-
用于捕获的受支持的网卡
- 以太网。Windows支持的任何卡都应该可以使用。有关可能影响您的环境的问题,请参阅有关以太网捕获和 卸载的Wiki页面。
- 802.11。请参阅Wireshark wiki页面。没有特殊设备,捕获原始802.11信息可能很困难。
- 其他媒体。请参阅https://wiki.wireshark.org/CaptureSetup/NetworkMedia。
不再支持Microsoft的扩展生命周期支持窗口之外的旧版Windows。由于我们无法控制的情况,通常很难或不可能支持这些系统,例如我们所依赖的第三方库,或者由于仅在较新版本的Windows中出现的必要功能,例如强化安全性或内存管理。
- Wireshark 2.2是支持Windows Vista和Windows Server 2008的最后一个版本(非R2)
- Wireshark 1.12是支持Windows Server 2003的最后一个发行版分支。
- Wireshark 1.10是官方支持Windows XP的最后一个发布分支。
有关更多详细信息,请参阅Wireshark发布生命周期页面。
Wireshark可在大多数UNIX和类UNIX平台上运行,包括macOS和Linux。系统要求应与上面列出的Windows值相当。
二进制包可用于大多数Unices和Linux发行版,包括以下平台:
- 高山Linux
- Apple macOS
- Canonical Ubuntu
- Debian GNU / Linux
- FreeBSD的
- Gentoo Linux
- HP-UX
- Mandriva Linux
- NetBSD的
- OpenPKG
- Oracle Solaris
- 红帽企业Linux / CentOS / Fedora
如果您的平台没有二进制包,您可以下载源并尝试构建它。请将您的经验报告给 wireshark-dev [AT] wireshark.org。
您可以从Wireshark网站https://www.wireshark.org/download.html获取该程序的最新副本 。下载页面应自动突出显示适用于您平台的相应下载,并引导您到最近的镜像。官方Windows和macOS安装程序由Wireshark Foundation签署。
一个新的Wireshark版本通常每个月或两个月都可用。
如果您想获得有关新Wireshark版本的通知,您应该订阅wireshark-announce邮件列表。您将在第1.6.5节“邮件列表”中找到更多详细信息 。
1997年底,Gerald Combs需要一个工具来追踪网络问题,并希望了解更多有关网络的信息,因此他开始编写Ethereal(Wireshark项目的原始名称)作为解决这两个问题的方法。
Ethereal最初是在1998年7月开发的几个停顿后发布的,版本为0.2.0。几天内,补丁,错误报告和鼓励的话语开始到来,Ethereal正在走向成功。
不久之后,吉尔伯特·拉米雷斯看到了它的潜力并为它做出了一个低级别的解剖器。
1998年10月,Guy Harris正在寻找比tcpview更好的东西,因此他开始向Ethereal应用补丁和解剖器。
1998年底,正在开设TCP / IP课程的Richard Sharpe看到了这些课程的潜力,并开始研究它是否支持他所需的协议。虽然在那时没有新的协议可以轻松添加。所以他开始提供解剖器和贡献补丁。
从那时起,为该项目做出贡献的人员名单已经变得很长,而且几乎所有这些人都开始使用他们需要Wireshark或者尚未处理的协议。因此,他们复制了现有的解剖器,并将代码贡献给了团队。
2006年,该项目移动了房屋,并以一个新名称重新出现:Wireshark。
2008年,经过十年的发展,Wireshark终于到了1.0版本。此版本是第一个被认为完整的版本,实现了最低限度的功能。它的发布恰逢第一届Wireshark开发者和用户大会,名为Sharkfest。
2015年,Wireshark 2.0发布,其中包含一个新的用户界面。
Wireshark最初由Gerald Combs开发。Wireshark的持续开发和维护由Wireshark团队负责,该团队是一群松散的人员,负责修复错误并提供新功能。
还有很多人为Wireshark提供协议解析器,预计这将继续下去。您可以通过查看Wireshark的about对话框或Wireshark网站上的作者页面找到为Wireshark贡献代码的人员列表 。
Wireshark是一个开源软件项目,并在 GNU通用公共许可证(GPL)版本2下发布。所有源代码都可以在GPL下免费获得。欢迎您修改Wireshark以满足您自己的需求,如果您将改进贡献给Wireshark团队,我们将不胜感激。
通过将您的改进贡献给社区,您可以获得三项好处:
- 其他发现您的贡献有用的人会欣赏他们,并且您会知道您以与Wireshark的开发人员帮助您相同的方式帮助了人们。
- Wireshark的开发人员可以进一步改进您的更改或在代码之上实现其他功能,这也可能使您受益。
- Wireshark的维护者和开发人员将维护您的代码,在API更改或进行其他更改时修复它,并且通常与Wireshark发生的事情保持一致。因此,当Wireshark更新时(通常是这样),您可以从网站上获得新的Wireshark版本,您的更改将被包含在内,而无需您的任何额外努力。
适用于某些平台的Wireshark源代码和二进制工具包均可在Wireshark网站的下载页面上找到:https://www.wireshark.org/download.html。
如果您遇到问题或需要Wireshark的帮助,可能会有几个地方感兴趣(当然除了本指南)。
您可以在Wireshark主页https://www.wireshark.org/上找到许多有用的信息 。
通过https://wiki.wireshark.org/撰写的Wireshark Wiki 提供了与Wireshark和数据包捕获相关的广泛信息。您将找到许多不属于本用户指南的信息。例如,它包含如何在交换网络上捕获的解释,构建协议引用的持续努力,特定于协议的信息等等。
最重要的是,如果您想提供有关特定主题(可能是您熟悉的网络协议)的知识,可以使用Web浏览器编辑Wiki页面。
Wireshark问答网站https://ask.wireshark.org/提供了一个资源,其中的问题和答案汇集在一起。您可以搜索之前提出的问题,并查看了解问题的人员给出的答案。答案排名,所以你可以轻松挑选出最好的答案。如果您之前没有讨论过您的问题,可以自行发布。
“常见问题解答”列出了常见问题及其相应答案。
|
阅读常见问题 |
|---|---|
|
在将任何邮件发送到下面的邮件列表之前,请务必阅读常见问题解答。它经常回答您可能遇到的任何问题。这将为自己和他人节省大量时间。请记住,很多人都订阅了邮件列表。 |
您可以通过单击菜单项“帮助/内容”并在显示的对话框中选择“常见问题”页面,在Wireshark中找到常见问题解答。
Wireshark网站上提供了在线版本,网址为 https://www.wireshark.org/faq.html。您可能更喜欢这个在线版本,因为它通常更新,HTML格式更容易使用。
有几个特定Wireshark主题的邮件列表:
- Wireshark的通告
- 此邮件列表将通知您有关新程序的发布,通常每4-8周出现一次。
- Wireshark的用户
- 此列表适用于Wireshark的用户。人们发布有关构建和使用Wireshark的问题,其他人(希望)提供答案。
- Wireshark的-dev的
- 此列表适用于Wireshark开发人员。如果要开始开发协议解析器,请加入此列表。
您可以从Wireshark网站订阅这些列表中的每一个:https: //www.wireshark.org/lists/。从那里,您可以通过单击相关列表标题下的“订阅/取消订阅/选项”按钮来选择要订阅的邮件列表。归档的链接也包含在该页面上。
|
列表已存档 |
|---|---|
|
您可以在列表存档中搜索,看看是否有人在之前的某个时间问过同一个问题并且可能已经得到答案。这样你就不必等到有人回答你的问题了。 |
|
注意 |
|---|---|
|
在报告任何问题之前,请确保您已安装最新版本的Wireshark。 |
在报告Wireshark问题时,请提供以下信息:
- Wireshark的版本号以及与之链接的依赖库,例如Qt或GLib。你可以从Wireshark的关于框或命令wireshark -v获得这个。
- 有关您运行Wireshark的平台的信息(Windows,Linux等,以及32位,64位等)。
- 您问题的详细说明。
- 如果收到错误/警告消息,请复制该消息的文本(如果有的话,还要在其前后几行),以便其他人可以找到出错的地方。请不要给出类似的内容:“我在做x时会收到警告”,因为这不会让人知道在哪里看。
|
不要发送大文件 |
|---|---|
|
不要将大文件(> 1 MB)发送到邮件列表。而是提供下载链接。对于错误和功能请求,您可以在Bugzilla上创建问题 并在那里上传文件。 |
|
不要发送机密信息! |
|---|---|
|
如果您将捕获文件发送到邮件列表,请确保它们不包含任何敏感或机密信息,如密码或个人身份信息(PII)。 |
报告与Wireshark发生崩溃时,如果您提供回溯信息以及“报告问题”中提到的信息,则会很有帮助。
您可以在UNIX或Linux上使用以下命令获取此回溯信息(请注意反引号):
$ gdb`whereis wireshark | cut -f2 -d:| cut -d'' - f2` core>&backtrace.txt 回溯 ^ d
如果您没有可用的gdb,则必须检查操作系统的调试器。
将backtrace.txt邮寄至wireshark-dev [AT] wireshark.org。
Windows发行版不包含符号文件(.pdb),因为它们非常大。您可以在https://www.wireshark.org/download/win32/all-versions/和 https://www.wireshark.org/download/win64/all-versions/下载它们 。
目录
与所有事情一样,必须有一个开端,因此Wireshark也是如此。要使用Wireshark,您必须先安装它。如果您运行的是Windows或macOS,可以从https://www.wireshark.org/download.html下载正式版本,安装它,并跳过本章的其余部分。
如果您正在运行其他操作系统,例如Linux或FreeBSD,则可能需要从源安装。一些Linux发行版提供Wireshark软件包,但它们通常提供过时的版本。到目前为止,还没有其他版本的UNIX提供Wireshark。因此,您需要知道从哪里获取最新版本的Wireshark以及如何安装它。
本章介绍如何获取源代码和二进制包以及如何从源代码构建Wireshark(如果您选择这样做)。
以下是您将使用的一般步骤:
- 根据您的需求下载相关软件包,例如源代码或二进制文件。
- 如果需要,将源编译为二进制文件。这可能涉及构建和/或安装其他必要的包。
- 将二进制文件安装到最终目标中。
您可以从Wireshark网站获取源代码和二进制分发:https://www.wireshark.org/download.html。选择下载链接,然后选择所需的二进制或源包。
|
下载所有必需的文件 |
|---|---|
|
如果您从源代码构建Wireshark,一般情况下,除非您之前已经下载过Wireshark,否则如果您从源代码构建Wireshark,则很可能需要下载多个源代码包。这将在下面详细介绍。 |
下载相关文件后,您可以继续下一步。
Windows安装程序名称包含平台和版本。例如,Wireshark-win64-3.1.0.exe为64位Windows安装Wireshark 3.1.0。Wireshark安装程序包含数据包捕获所需的Npcap。
只需从https://www.wireshark.org/download.html下载Wireshark安装程序 并执行即可。官方包裹由Wireshark基金会签署。您可以选择安装多个可选组件,然后选择已安装软件包的位置。建议大多数用户使用默认设置。
在安装程序的“选择组件”页面上,您可以从以下选项中进行选择:
- Wireshark - 我们都知道并且最喜欢的网络协议分析器。
- TShark - 命令行网络协议分析器。如果你还没有尝试过,你应该这样做。
-
插件和扩展 - Wireshark和TShark解剖引擎的附加功能
-
工具 - 用于处理捕获文件的其他命令行工具
- Editcap - 读取捕获文件并将部分或全部数据包写入另一个捕获文件。
- Text2Pcap - 读入ASCII十六进制转储并将数据写入pcap捕获文件。
- Reordercap - 按时间戳重新排序捕获文件。
- Mergecap - 将多个已保存的捕获文件合并到一个输出文件中。
- Capinfos - 提供有关捕获文件的信息。
- Rawshark - 原始数据包过滤器。
- 用户指南 -用户指南的本地安装。如果未在本地安装用户指南,则大多数对话框上的“帮助”按钮将需要Internet连接才能显示帮助页面。
- 开始菜单快捷方式 - 添加一些开始菜单快捷方式。
- 桌面图标 - 将Wireshark图标添加到桌面。
- 快速启动图标 - 将一个Wireshark图标添加到Explorer快速启动工具栏。
- 将文件扩展名关联到Wireshark - 将标准网络跟踪文件关联到Wireshark。
默认情况下,Wireshark安装%ProgramFiles%\Wireshark在32位Windows和%ProgramFiles64%\Wireshark64位Windows上。这扩展到C:\Program Files\Wireshark大多数系统。
Wireshark安装程序包含最新的Npcap安装程序。
如果您没有安装Npcap,您将无法捕获实时网络流量,但您仍然可以打开已保存的捕获文件。默认情况下,将安装最新版本的Npcap。如果您不希望这样做或者您想重新安装Npcap,可以根据需要检查安装Npcap框。
有关Npcap的更多信息,请参阅https://nmap.org/npcap/和 https://wiki.wireshark.org/Npcap。
对于特殊情况,有一些命令行参数可用:
/S使用默认值静默运行安装程序或卸载程序。静默安装程序不会安装Npcap。/desktopicon安装桌面图标,=yes- 强制安装,=no- 不安装,否则使用默认设置。此选项对静默安装程序很有用。/quicklaunchicon安装快速启动图标,=yes- 强制安装,=no- 不安装,否则使用默认设置。/D设置默认安装目录($ INSTDIR),覆盖InstallDir和InstallDirRegKey。它必须是命令行中使用的最后一个参数,即使路径包含空格,也不得包含任何引号。/NCRC禁用CRC校验。我们建议不要使用此标志。
例:
> Wireshark-win64-wireshark-2.0.5.exe / NCRC / S / desktopicon = yes / quicklaunchicon = no / D = C:\ Program Files \ Foo
不带任何参数运行安装程序会显示正常的交互式安装程
如上所述,Wireshark安装程序负责安装Npcap。仅当您要使用与Wireshark安装程序中包含的版本不同的版本时,才需要以下内容,例如,因为发布了新的Npcap版本。
其他Npcap版本(包括较新的alpha或beta版本)可以从主要的Npcap站点下载,网址为https://nmap.org/npcap/。在Windows安装支持现代的Windows操作系统。
默认情况下,官方Windows软件包将检查新版本并在可用时通知您。如果您已禁用“ 检查更新”首选项,或者如果您在隔离环境中运行Wireshark,则应该订阅wireshark-announce邮件列表。有关订阅此列表的详细信息,请参见第1.6.5节“邮件列表”。
Wireshark的新版本通常每四到六周发布一次。更新Wireshark的方式与安装相同。只需下载并启动安装程序exe。通常不需要重新启动,所有个人设置都保持不变。
新版本的Npcap。您可以在Npcap网站https://nmap.org/npcap/找到Npcap更新说明。安装新的Npcap版本后,您可能必须重新启动计算机。
您可以使用“ 程序和功能”控制面板卸载Wireshark 。选择“Wireshark”条目以启动卸载过程。
Wireshark卸载程序提供了几种删除选项。默认设置是删除核心组件,但保留您的个人设置。默认情况下,如果其他程序需要Npcap,则会保留Npcap。
官方macOS包作为包含应用程序安装程序的磁盘映像(.dmg)进行分发。要安装Wireshark,只需打开磁盘映像并运行随附的安装程序。
安装程序包包括Wireshark,其相关的命令行实用程序以及在系统启动时调整捕获权限的启动守护程序。有关更多详细信息,请参阅随附的自述文件。
构建Wireshark需要适当的构建环境,包括编译器和许多支持库。有关详细信息,请参阅https://www.wireshark.org/docs/上的开发人员指南 。
使用以下常规步骤在UNIX或Linux下从源构建Wireshark:
-
从压缩
tar文件中解压缩源代码。如果您使用的是Linux,或者您的UNIX版本使用GNUtar,则可以使用以下命令:$ tar xaf wireshark-2.9.0.tar.xz在其他情况下,您将不得不使用以下命令:
$ xz -d wireshark-2.9.0.tar.xz $ tar xf wireshark-2.9.0.tar -
创建一个目录来构建Wireshark并更改为它。
$ mkdir build $ cd build -
配置源代码,以便为您的UNIX版本正确构建。您可以使用以下命令执行此操作:
$ cmake ../wireshark-2.9.0如果此步骤失败,您将不得不查看日志并纠正问题,然后重新运行
cmake。第2.7节“在Unix上构建和安装期间的故障排除”中提供了故障排除提示。 -
建立资源。
$ make一旦你用
make上面的构建Wireshark ,你应该能够通过输入来运行它run/wireshark。 -
将软件安装在最终目的地。
$ make install
一旦你在make install上面安装了Wireshark ,你应该可以通过输入来运行它wireshark。
通常,在您的UNIX版本下安装二进制文件将特定于您的UNIX版本使用的安装方法。例如,在AIX下,您将使用smit来安装Wireshark二进制包,而在Tru64 UNIX(以前称为Digital UNIX)下,您将使用setld。
从Wireshark的源代码构建RPM会产生几个包(大多数发行版遵循相同的系统):
- 该
wireshark软件包包含核心Wireshark库和命令行工具。 - 的
wireshark或wireshark-qt包中包含基于Qt的GUI。
许多发行版使用yum或类似的包管理工具使软件(包括其依赖项)的安装更容易。如果您的发行版使用yum,请使用以下命令将Wireshark与Qt GUI一起安装:
yum install wireshark wireshark-qt
如果您已经从Wireshark源构建了自己的RPM,则可以通过运行来安装它们,例如:
rpm -ivh wireshark-2.0.0-1.x86_64.rpm wireshark-qt-2.0.0-1.x86_64.rpm
如果上述命令因缺少依赖性而失败,请先安装依赖项,然后重试上述步骤。
如果您只需从存储库安装即可使用
$ aptitude安装wireshark
能力应该为您处理所有依赖性问题。
使用以下命令在Debian下安装下载的Wireshark debs:
$ dpkg -i wireshark-common_2.0.5.0-1_i386.deb wireshark_wireshark-2.0.5.0-1_i386.deb
dpkg不会处理所有依赖项,但会报告缺少的内容。
|
捕获需要特权 |
|---|---|
|
通过安装Wireshark软件包,非root用户将无法自动获取捕获数据包的权限。要允许非root用户捕获数据包,请遵循/usr/share/doc/wireshark-common/README.Debian中描述的过程 |
使用以下命令在Gentoo Linux下安装Wireshark并具有所有额外功能:
$ USE =“c-ares ipv6 snmp ssl kerberos threads selinux”emerge wireshark
在构建和安装过程中可能会发生许多错误。这里提供了解决这些问题的一些提示。
如果cmake阶段失败,您将需要找出原因。您可以检查文件CMakeOutput.log并CMakeError.log在构建目录中找出失败的内容。此文件的最后几行应该有助于确定问题。
标准问题是您的系统上没有必需的开发包,或者开发包不够新。请注意,安装库包是不够的。您还需要安装其开发包。cmake如果您的系统上没有libpcap(至少是必需的包含文件),也会失败。
如果您无法确定问题所在,请发送电子邮件至 wireshark-dev邮件列表,说明您的问题。包括cmake您认为相关的输出 和其他任何内容,例如make舞台的痕迹 。
我们强烈建议您使用Windows的二进制安装程序,除非您想在Windows平台上开始开发Wireshark。
有关如何从源代码构建Wireshark for Windows的更多信息,请参阅https://www.wireshark.org/docs/上的开发人员指南。
您可能还想查看Development Wiki(https://wiki.wireshark.org/Development)以获取最新的开发文档。
目录
到目前为止,您已经安装了Wireshark,并且很可能热衷于开始捕获您的第一个数据包。在接下来的章节中,我们将探讨:
- Wireshark用户界面如何工作
- 如何在Wireshark中捕获数据包
- 如何在Wireshark中查看数据包
- 如何在Wireshark中过滤数据包
- ......还有很多其他的东西!
您可以从shell或窗口管理器启动Wireshark。
|
高级用户提示 |
|---|---|
|
启动Wireshark时,可以使用命令行指定可选设置。有关详细信息,请参见第11.2节“从命令行启动Wireshark”。 |
在接下来的章节中,将展示Wireshark的大量屏幕截图。由于Wireshark在许多不同的平台上运行,有许多不同的窗口管理器,应用了不同的样式,并且使用了不同版本的底层GUI工具包,因此您的屏幕可能与提供的屏幕截图有所不同。但由于功能上没有真正的差异,因此这些屏幕截图应该仍然可以理解。
我们来看看Wireshark的用户界面。图3.1“主窗口”显示了Wireshark,就像捕获或加载一些数据包后通常会看到的一样(后面将介绍如何执行此操作)。
Wireshark的主窗口包含许多其他GUI程序中常见的部分。
- 该菜单(参见第3.4节“菜单”)用于开始行动。
- 在主工具栏(见第3.15节“‘主’工具栏”)提供快速访问常用从菜单中使用的物品。
- 该过滤器的工具栏(见章节3.16“的‘过滤器’工具栏”)提供了一种直接操纵当前使用的显示过滤器(参见 第6.3节“浏览时过滤包”)。
- 的分组列表窗格(见章节3.17,“该‘包列表’窗格”)显示捕获的每个分组的摘要。通过单击此窗格中的数据包,您可以控制其他两个窗格中显示的内容。
- 该数据包详细信息窗格(参见第3.18节“的‘包详细信息’窗格”)显示更详细的数据包列表窗格中选择的包。
- 的包字节窗格(见章节3.19,“该‘包字节’窗格”)从在分组列表窗格中选择的包显示数据,并突出显示在所述分组的信息窗格中选择的字段。
- 所述状态栏(见章节3.20,“状态栏”)示出了有关当前程序状态和所捕获的数据的一些详细的信息。
|
小费 |
|---|---|
|
可以通过更改首选项设置来自定义主窗口的布局。有关详细信息,请参见第11.5节“首选项”! |
数据包列表和详细信息导航可以完全通过键盘完成。 表3.1“键盘导航”显示了一个击键列表,可让您快速移动捕获文件。有关其他导航键击,请参见表3.6“转到菜单项”。
表3.1。键盘导航
| 加速器 | 描述 |
|---|---|
|
Tab或 Shift + Tab |
在屏幕元素之间移动,例如从工具栏到数据包列表到数据包详细信息。 |
|
↓ |
移至下一个数据包或详细信息项。 |
|
↑ |
移至上一个数据包或详细信息项。 |
|
Ctrl + ↓或 F8 |
即使数据包列表未聚焦,也要移至下一个数据包。 |
|
Ctrl + ↑或 F7 |
即使数据包列表未聚焦,也请移至上一个数据包。 |
|
Ctrl +。 |
移至会话的下一个数据包(TCP,UDP或IP)。 |
|
Ctrl +, |
移至对话的上一个数据包(TCP,UDP或IP)。 |
|
Alt + →或 Option + →(macOS) |
移至选择历史记录中的下一个数据包。 |
|
Alt + ←或 Option + ←(macOS) |
移至选择历史记录中的上一个数据包。 |
|
← |
在数据包详细信息中,关闭所选的树项。如果它已经关闭,则跳转到父节点。 |
|
→ |
在数据包详细信息中,打开选定的树项。 |
|
Shift + → |
在数据包详细信息中,打开所选树项及其所有子树。 |
|
按Ctrl + → |
在数据包详细信息中,打开所有树项。 |
|
Ctrl + ← |
在数据包详细信息中,关闭所有树项。 |
|
退格 |
在数据包详细信息中,跳转到父节点。 |
|
返回或输入 |
在数据包详细信息中,切换选定的树项。 |
Wireshark的主菜单位于主窗口的顶部(Windows,Linux)或主屏幕的顶部(macOS)。一个例子 如图3.2“菜单”所示。
|
注意 |
|---|---|
|
如果相应的功能不可用,某些菜单项将被禁用(灰显)。例如,如果尚未捕获或加载任何数据包,则无法保存捕获文件。 |

主菜单包含以下项目:
- 文件
- 此菜单包含打开和合并捕获文件,保存,打印或导出全部或部分捕获文件以及退出Wireshark应用程序的项目。请参见 第3.5节“”文件“菜单”。
- 编辑
- 此菜单包含用于查找数据包,时间参考或标记一个或多个数据包,处理配置配置文件以及设置首选项的项目; (目前尚未实施剪切,复制和粘贴)。请参见第3.6节“”编辑“菜单”。
- 视图
- 此菜单控制捕获数据的显示,包括数据包的着色,缩放字体,在单独的窗口中显示数据包,在数据包详细信息中展开和折叠树,.... 请参见第3.7节“”视图“菜单”。
- 走
- 此菜单包含要转到特定数据包的项目。请参见第3.8节“”Go“菜单”。
- 捕获
- 此菜单允许您启动和停止捕获以及编辑捕获过滤器。请参见 第3.9节“”捕获“菜单”。
- 分析
- 此菜单包含用于操作显示过滤器,启用或禁用协议剖析,配置用户指定的解码以及遵循TCP流的项目。请参见第3.10节“分析”菜单“。
- 统计
- 此菜单包含显示各种统计窗口的项目,包括已捕获的数据包摘要,显示协议层次结构统计信息等等。请参见第3.11节“”统计“菜单”。
- 电话
- 此菜单包含显示各种电话相关统计窗口的项目,包括媒体分析,流程图,显示协议层次结构统计等等。请参见第3.12节“电话”“电话”菜单。
- 无线
- 此菜单中的项目显示蓝牙和IEEE 802.11无线统计信息。
- 工具
- 此菜单包含Wireshark中提供的各种工具,例如创建防火墙ACL规则。请参见第3.13节“”工具“菜单”。
- 救命
- 此菜单包含帮助用户的项目,例如访问一些基本帮助,各种命令行工具的手册页,在线访问某些网页以及通常的对话框。请参见第3.14节“”帮助“菜单”。
以下各节将更详细地介绍这些菜单项中的每一个。
|
快捷方式让生活更轻松 |
|---|---|
|
最常见的菜单项有键盘快捷键。例如,您可以同时按下Control(或Strg in German)和K键以打开“Capture Options”对话框。 |
Wireshark文件菜单包含表3.2“文件菜单项”中显示的字段。
表3.2。文件菜单项
| 菜单项 | 加速器 | 描述 |
|---|---|---|
|
|
Ctrl +O. |
这将显示文件打开对话框,允许您加载捕获文件以供查看。第5.2.1节“打开捕获文件”对话框中将对此进行更详细的讨论。 |
|
|
这使您可以打开最近打开的捕获文件。单击其中一个子菜单项将直接打开相应的捕获文件。 |
|
|
|
此菜单项允许您将捕获文件合并到当前加载的文件中。第5.4节“合并捕获文件”对此进行了更详细的讨论。 |
|
|
|
此菜单项将打开导入文件对话框,允许您将包含十六进制转储的文本文件导入新的临时捕获。第5.5节“导入十六进制转储”将对此进行更详细的讨论。 |
|
|
|
Ctrl +W |
此菜单项关闭当前捕获。如果您尚未保存捕获,则会首先要求您执行此操作(可以通过首选项设置禁用此操作)。 |
|
|
Ctrl +S. |
此菜单项保存当前捕获。如果您尚未设置默认捕获文件名(可能使用-w <capfile>选项),Wireshark会弹出“将捕获文件另存为”对话框(将在第5.3.1节“将捕获文件另存为”中进一步讨论)“对话框”)。 如果您已保存当前捕获,则此菜单项将显示为灰色。 捕获正在进行时,您无法保存实时捕获。您必须停止捕获才能保存。 |
|
|
Shift+ Ctrl+ S. |
此菜单项允许您将当前捕获文件保存到您想要的任何文件。它弹出Save Capture File As对话框(将在第5.3.1节“将捕获文件另存为”对话框中进一步讨论)。 |
|
|
此菜单项允许您显示文件集中的文件列表。它会弹出Wireshark列表文件集对话框(将在第5.6节“文件集”中进一步讨论 )。 |
|
|
|
如果当前加载的文件是文件集的一部分,请跳转到该集合中的下一个文件。如果它不是文件集的一部分或仅是该集合中的最后一个文件,则此项目将显示为灰色。 |
|
|
|
如果当前加载的文件是文件集的一部分,请跳转到该组中的上一个文件。如果它不是文件集的一部分或只是该集合中的第一个文件,则此项目将显示为灰色。 |
|
|
|
此菜单项允许您将捕获文件中的所有(或部分)数据包导出到文件。它弹出Wireshark Export对话框(将在第5.7节“导出数据”中进一步讨论)。 |
|
|
|
Ctrl +H. |
这些菜单项允许您将数据包字节窗格中当前选定的字节导出为多种格式的文本文件,包括plain,CSV和XML。第5.7.7节“导出所选数据包字节”对话框中将进一步讨论。 |
|
|
这些菜单项允许您将捕获的DICOM,HTTP,IMF,SMB或TFTP对象导出到本地文件中。它弹出一个相应的对象列表(将在第5.7.8节“导出对象”对话框中进一步讨论) |
|
|
|
Ctrl +P. |
此菜单项允许您打印捕获文件中的所有(或部分)数据包。它会弹出Wireshark Print对话框(将在第5.8节“打印数据包”中进一步讨论 )。 |
|
|
Ctrl +Q. |
此菜单项允许您从Wireshark退出。如果您之前没有保存捕获文件,Wireshark会要求保存您的捕获文件(这可以通过首选项设置禁用)。 |
Wireshark Edit菜单包含表3.3“编辑菜单项”中显示的字段。

表3.3。编辑菜单项
| 菜单项 | 加速器 | 描述 |
|---|---|---|
|
|
这些菜单项将数据包列表,数据包详细信息或当前所选数据包的属性复制到剪贴板。 |
|
|
|
Ctrl + F. |
此菜单项会打开一个工具栏,允许您按许多条件查找数据包。有关查找数据包的更多信息,请参见 第6.8节“查找数据包”。 |
|
|
Ctrl + N. |
此菜单项尝试查找与“查找数据包...”中的设置匹配的下一个数据包。 |
|
|
Ctrl + B. |
此菜单项尝试查找与“查找数据包...”中的设置匹配的上一个数据包。 |
|
|
按Ctrl + M. |
此菜单项标记当前选定的数据包。有关详细信息,请参见 第6.10节“标记数据包”。 |
|
|
Shift + Ctrl +M. |
此菜单项标记所有显示的数据包。 |
|
|
Ctrl + Alt + M. |
此菜单项取消标记所有显示的数据包。 |
|
|
Shift + Alt + N. |
找到下一个标记的数据包。 |
|
|
Shift + Alt + B. |
找到以前标记的数据包。 |
|
|
Ctrl + D. |
此菜单项将当前选定的数据包标记为已忽略。有关详细信息,请参见 第6.11节“忽略数据包”。 |
|
|
Shift + Ctrl +D. |
此菜单项将所有显示的数据包标记为已忽略。 |
|
|
Ctrl + Alt + D. |
此菜单项取消标记所有忽略的数据包。 |
|
|
Ctrl + T. |
此菜单项设置当前所选数据包的时间参考。有关时间引用数据包的更多信息,请参见第6.12.1节“数据包时间引用”。 |
|
|
Ctrl + Alt + T. |
此菜单项删除数据包的所有时间参考。 |
|
|
Ctrl + Alt + N. |
此菜单项尝试查找下一次引用的数据包。 |
|
|
Ctrl + Alt + B. |
此菜单项尝试查找上一次引用的数据包。 |
|
|
Ctrl + Shift + T. |
打开“时间转换”对话框,该对话框允许您调整部分或全部数据包的时间戳。 |
|
|
打开“数据包注释”对话框,该对话框允许您向单个数据包添加注释。请注意,保存数据包注释的能力取决于您的文件格式。例如pcapng支持注释,pcap不支持。 |
|
|
|
这将允许您添加捕获注释。请注意,保存捕获注释的能力取决于您的文件格式。例如pcapng支持注释,pcap不支持。 |
|
|
|
Shift + Ctrl + A. |
此菜单项会显示一个用于处理配置文件的对话框。第11.6节“配置文件”中提供了更多详细信息。 |
|
|
Shift + Ctrl + P或 Cmd +,(macOS) |
此菜单项会弹出一个对话框,允许您为控制Wireshark的许多参数设置首选项。您还可以保存首选项,以便Wireshark在下次启动时使用它们。更多细节在 第11.5节“首选项”中提供。 |
Wireshark视图菜单包含表3.4“查看菜单项”中显示的字段。

表3.4。查看菜单项
| 菜单项 | 加速器 | 描述 |
|---|---|---|
|
|
此菜单项隐藏或显示主工具栏,请参见第3.15节“主”“工具栏”。 |
|
|
|
此菜单项隐藏或显示过滤器工具栏,请参见第3.16节“过滤器”工具栏“。 |
|
|
|
此菜单项隐藏或显示无线工具栏。可能在某些平台上不存在。 |
|
|
|
此菜单项隐藏或显示状态栏,请参见第3.20节“状态栏”。 |
|
|
|
此菜单项隐藏或显示数据包列表窗格,请参见第3.17节“”数据包列表“窗格”。 |
|
|
|
此菜单项隐藏或显示数据包详细信息窗格,请参见第3.18节“”数据包详细信息“窗格”。 |
|
|
|
此菜单项隐藏或显示数据包字节窗格,请参见第3.19节“数据包字节”窗格“。 |
|
|
|
选择此选项可告知Wireshark以日期和时间格式显示时间戳,请参见第6.12节“时间显示格式和时间参考”。 字段“时间”,“日期和时间”,“自捕获开始后的秒数”,“自上次捕获的数据包以来的秒数”和“自上次显示的数据包以来的秒数”是互斥的。 |
|
|
|
选择此选项可告知Wireshark以时间格式显示时间戳,请参见第6.12节“时间显示格式和时间参考”。 |
|
|
|
选择此项将告知Wireshark自1970-01-01 00:00:00以秒为单位显示时间戳,请参见第6.12节“时间显示格式和时间参考”。 |
|
|
|
选择此选项可告知Wireshark自捕获格式开始以秒为单位显示时间戳,请参见第6.12节“时间显示格式和时间参考”。 |
|
|
|
选择此选项可告知Wireshark显示自上次捕获的数据包格式以来的秒数,请参见第6.12节“时间显示格式和时间参考”。 |
|
|
|
选择此选项可告知Wireshark显示自上次显示的数据包格式以来的秒数,请参见第6.12节“时间显示格式和时间参考”。 |
|
|
|
选择此选项可告知Wireshark以所使用的捕获文件格式给出的精度显示时间戳,请参见第6.12节“时间显示格式和时间参考”。 “自动”,“秒”和“......秒”字段是互斥的。 |
|
|
|
选择此项将告知Wireshark显示精度为1秒的时间戳,请参见第6.12节“时间显示格式和时间参考”。 |
|
|
|
选择此选项可告知Wireshark显示精度为1秒,秒,厘秒,毫秒,微秒或纳秒的时间戳,请参见第6.12节“时间显示格式和时间参考”。 |
|
|
|
选择此选项可告知Wireshark以秒为单位显示时间戳,包括小时和分钟。 |
|
|
|
此项允许您仅触发当前数据包的名称解析,请参见第7.9节“名称解析”。 |
|
|
|
此项允许您控制Wireshark是否将MAC地址转换为名称,请参见第7.9节“名称解析”。 |
|
|
|
此项允许您控制Wireshark是否将网络地址转换为名称,请参见第7.9节“名称解析”。 |
|
|
|
此项允许您控制Wireshark是否将传输地址转换为名称,请参见第7.9节“名称解析”。 |
|
|
|
此项允许您控制Wireshark是否应该对数据包列表着色。 在捕获或加载捕获文件时,启用着色将减慢新数据包的显示速度。 |
|
|
|
此项允许您指定Wireshark应在新数据包进入时滚动数据包列表窗格,因此您始终查看最后一个数据包。如果不指定此项,Wireshark只会将新数据包添加到列表末尾,但不会滚动数据包列表窗格。 |
|
|
|
Ctrl+ + |
放大数据包数据(增加字体大小)。 |
|
|
Ctrl+ - |
缩小数据包数据(减小字体大小)。 |
|
|
Ctrl+ = |
将缩放级别设置回100%(将字体大小设置回正常)。 |
|
|
Shift+Ctrl+ R. |
调整所有列宽,以使内容适合它。 调整大小可能会花费大量时间,尤其是在加载大型捕获文件时。 |
|
|
此菜单项折叠出所有已配置列的列表。现在可以在数据包列表中显示或隐藏这些列。 |
|
|
|
Shift+ → |
此菜单项在数据包详细信息树中展开当前选定的子树。 |
|
|
Shift+ ← |
此菜单项折叠数据包详细信息树中当前选定的子树。 |
|
|
按Ctrl+ → |
Wireshark保留了所有扩展的协议子树的列表,并使用它来确保在显示数据包时扩展正确的子树。此菜单项可扩展捕获中所有数据包中的所有子树。 |
|
|
Ctrl+ ← |
此菜单项折叠捕获列表中所有数据包的树视图。 |
|
|
此菜单项将显示一个子菜单,允许您根据当前所选数据包的地址为数据包列表窗格中的数据包着色。这使得易于区分属于不同对话的分组。第11.3节“分组着色”。 |
|
|
|
这些菜单项根据当前选定的对话启用十个临时颜色过滤器中的一个。 |
|
|
|
此菜单项清除所有临时着色规则。 |
|
|
|
此菜单项打开一个对话窗口,可在其中根据当前选定的对话创建新的永久着色规则。 |
|
|
|
此菜单项会弹出一个对话框,允许您根据所选的过滤器表达式为数据包列表窗格中的数据包着色。它对于发现某些类型的数据包非常有用,请参见第11.3节“数据包着色”。 |
|
|
|
有关各种内部数据结构的信息。有关详细信息,请参阅下面的表3.5“内部菜单项”。 |
|
|
|
在单独的窗口中显示选定的数据包。单独的窗口仅显示数据包详细信息和字节。有关详细信息,请参见图6.2“在单独的窗口中查看数据包”。 |
|
|
|
Ctrl+ R. |
此菜单项允许您重新加载当前捕获文件。 |
Wireshark Go菜单包含表3.6“Go菜单项”中显示的字段。

表3.6。去菜单项目
| 菜单项 | 加速器 | 描述 |
|---|---|---|
|
|
Alt + ← |
跳转到数据包历史记录中最近访问过的数据包,非常类似于Web浏览器中的页面历史记录。 |
|
|
Alt + → |
跳转到数据包历史记录中的下一个访问数据包,非常类似于Web浏览器中的页面历史记录。 |
|
|
Ctrl + G. |
打开一个窗口框架,允许您指定数据包编号,然后转到该数据包。有关详细信息,请参见第6.9节“转至特定数据包”。 |
|
|
转到当前所选协议字段的相应数据包。如果所选字段与数据包不对应,则此项目将显示为灰色。 |
|
|
|
Ctrl + ↑ |
移至列表中的上一个数据包。即使数据包列表没有键盘焦点,这也可用于移动到上一个数据包。 |
|
|
Ctrl + ↓ |
移动到列表中的下一个数据包。即使数据包列表没有键盘焦点,这也可用于移动到上一个数据包。 |
|
|
Ctrl +Home |
跳转到捕获文件的第一个数据包。 |
|
|
Ctrl +End |
跳转到捕获文件的最后一个数据包。 |
|
|
Ctrl +, |
移至当前对话中的上一个数据包。即使数据包列表没有键盘焦点,这也可用于移动到上一个数据包。 |
|
|
Ctrl +。 |
移至当前对话中的下一个数据包。即使数据包列表没有键盘焦点,这也可用于移动到上一个数据包。 |
Wireshark Capture菜单包含表3.7“捕获菜单项”中显示的字段。
表3.7。捕获菜单项
| 菜单项 | 加速器 | 描述 |
|---|---|---|
|
|
Ctrl+ I |
此菜单项会弹出一个对话框,显示Wireshark知道的网络接口的内容,请参见第4.4节“捕获接口”对话框“)。 |
|
|
Ctrl+K. |
此菜单项将显示“捕获选项”对话框(在第4.5节“捕获选项”对话框中进一步讨论“),并允许您开始捕获数据包。 |
|
|
Ctrl+ E. |
立即开始使用与上次相同的设置捕获数据包。 |
|
|
Ctrl+ E. |
此菜单项停止当前正在运行的捕获,请参见第4.14.1节“停止正在运行的捕获”)。 |
|
|
Ctrl+ R. |
此菜单项停止当前正在运行的捕获并使用相同的选项再次启动,这只是为了方便起见。 |
|
|
此菜单项会弹出一个对话框,允许您创建和编辑捕获过滤器。您可以命名过滤器,您可以保存它们以备将来使用。有关此主题的更多详细信息,请参见第6.6节“定义和保存过滤器” |
Wireshark Analyze菜单包含表3.8“分析菜单项”中显示的字段。
表3.8。分析菜单项
| 菜单项 | 加速器 | 描述 |
|---|---|---|
|
|
此菜单项会弹出一个对话框,允许您创建和编辑显示过滤器。您可以命名过滤器,您可以保存它们以备将来使用。有关此主题的更多详细信息,请参见第6.6节“定义和保存过滤器” |
|
|
|
此菜单项会弹出一个对话框,允许您创建和编辑显示过滤器宏。您可以命名过滤器宏,并可以保存它们以供将来使用。有关此主题的更多详细信息,请参见第6.7节“定义和保存过滤器宏” |
|
|
|
此菜单项将数据包详细信息窗格中的所选协议项作为列添加到数据包列表中。 |
|
|
|
这些菜单项将更改当前显示过滤器并立即应用更改的过滤器。根据所选的菜单项,当前显示过滤器字符串将被数据包详细信息窗格中的所选协议字段替换或附加。 |
|
|
|
这些菜单项将更改当前显示过滤器,但不会应用更改的过滤器。根据所选的菜单项,当前显示过滤器字符串将被数据包详细信息窗格中的所选协议字段替换或附加。 |
|
|
|
Shift +Ctrl +E. |
此菜单项允许用户启用/禁用协议解析器,请参见第11.4.1节“启用协议”对话框“ |
|
|
此菜单项允许用户强制Wireshark将某些数据包解码为特定协议,请参见第11.4.2节“用户指定的解码” |
|
|
|
此菜单项允许用户强制Wireshark将某些数据包解码为特定协议,请参见第11.4.3节“显示用户指定的解码” |
|
|
|
此菜单项将显示一个单独的窗口,并显示捕获的与所选数据包位于同一TCP连接上的所有TCP段,请参见第7.2节“遵循协议流” |
|
|
|
与“跟随TCP流”相同的功能,但对于“UDP”流。 |
|
|
|
与“跟随TCP流”功能相同,但适用于TLS或SSL流。有关提供TLS密钥的说明,请参阅SSL上的Wiki页面。 |
|
|
|
与“跟随TCP流”功能相同,但适用于HTTP流。 |
|
|
|
打开一个对话框,显示有关捕获的数据包的一些专家信 信息量将取决于协议,并且从非常详细到不存在。XXX - 添加一个关于此的新部分并从此处链接 |
|
|
|
在此菜单中,您可以找到各种协议的会话过滤器。 |
Wireshark Statistics菜单包含表3.9“Statistics菜单项”中显示的字段。

所有菜单项都会显示一个显示特定统计信息的新窗口。
表3.9。统计菜单项
| 菜单项 | 加速器 | 描述 |
|---|---|---|
|
|
显示有关捕获文件的信息,请参见第8.2节“捕获文件属性”窗口“。 |
|
|
|
||
|
|
显示协议统计信息的分层树,请参见第8.4节“协议层次结构”窗口“。 |
|
|
|
显示对话列表(两个端点之间的流量),请参见第8.5.1节“对话”窗口“。 |
|
|
|
显示端点列表(到/来自地址的流量),请参见第8.6.1节“端点”窗口“。 |
|
|
|
请参见第8.7节“数据包长度” |
|
|
|
显示用户指定的图形(例如,过程中的数据包数量),请参见第8.8节“I / O图形窗口”。 |
|
|
|
显示请求与相应响应之间的时间,请参见第8.9节“服务响应时间”。 |
|
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
请参见第8.16节“DNS” |
|
|
|
请参见第8.17节“流程图” |
|
|
|
||
|
|
||
|
|
HTTP请求/响应统计信息,请参见第8.20节“HTTP统计信息” |
|
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
Wireshark Telephony菜单包含表3.10“电话菜单项”中显示的字段。
所有菜单项将显示一个新窗口,显示与特定电话相关的统计信息。
Wireshark工具菜单包含表3.11“工具菜单项”中显示的字段。

Wireshark帮助菜单包含表3.12“帮助菜单项”中显示的字段。
表3.12。帮助菜单项
| 菜单项 | 加速器 | 描述 |
|---|---|---|
|
|
F1 |
此菜单项显示基本帮助系统。 |
|
|
此菜单项启动Web浏览器,显示本地安装的html手册页之一。 |
|
|
|
此菜单项启动一个Web浏览器,显示以下网址:https://www.wireshark.org/。 |
|
|
|
此菜单项启动Web浏览器,显示各种常见问题解答。 |
|
|
|
此菜单项启动一个Web浏览器,显示来自以下网址的下载:https://www.wireshark.org/download.html。 |
|
|
|
此菜单项启动一个Web浏览器,显示首页:https://wiki.wireshark.org/。 |
|
|
|
此菜单项启动Web浏览器,显示以下示例:https : //wiki.wireshark.org/SampleCaptures。 |
|
|
|
此菜单项打开一个信息窗口,在Wireshark上提供各种详细信息项,例如它是如何构建的,加载的插件,使用的文件夹,...... |
|
注意 |
|---|---|
|
您的Wireshark版本可能不支持打开Web浏览器。如果是这种情况,将隐藏相应的菜单项。 如果在您的计算机上调用Web浏览器失败,或者浏览器未启动但未显示任何页面,请查看首选项对话框中的Web浏览器设置。 |
主工具栏提供从菜单中快速访问常用项目。此工具栏无法由用户自定义,但如果需要屏幕上的空间来显示更多数据包数据,则可以使用“视图”菜单对其进行隐藏。
工具栏中的项目将启用或禁用(灰色),类似于相应的菜单项。例如,在下图中显示了打开文件后的主窗口工具栏。启用了各种与文件相关的按钮,但由于捕获不在进行中,因此禁用了停止捕获按钮。

表3.13。主工具栏项
| 工具栏图标 | 工具栏项目 | 菜单项 | 描述 |
|---|---|---|---|
|
|
|
|
使用与上次捕获相同的选项开始捕获数据包,如果没有设置,则开始捕获默认选项(第4.3节“开始捕获”)。 |
|
|
|
|
停止当前正在运行的捕获(第4.3节“开始捕获”)。 |
|
|
|
|
重新启动当前捕获会话。 |
|
|
|
|
打开“捕获选项”对话框。有关详细信息,请参见第4.3节“开始捕获”。 |
|
|
|
|
打开文件打开对话框,允许您加载捕获文件以供查看。第5.2.1节“打开捕获文件”对话框中将对此进行更详细的讨论。 |
|
|
|
|
将当前捕获文件保存到您想要的任何文件。有关详细信息,请参见第5.3.1节“将捕获文件另存为”对话框“。如果您当前打开了临时捕获文件,则会显示“保存”图标。 |
|
|
|
|
关闭当前捕获。如果您尚未保存捕获,则会要求您先保存它。 |
|
|
|
|
重新加载当前捕获文件。 |
|
|
|
|
根据不同的标准查找数据包。有关详细信息,请参见第6.8节“查找数据包”。 |
|
|
|
|
跳回数据包历史记录。按住Alt键(macOS上的选项)返回选择历史记录。 |
|
|
|
|
在数据包历史记录中向前跳转。按住Alt键(macOS上的选项)以在选择历史记录中前进。 |
|
|
|
|
转到特定数据包。 |
|
|
|
|
跳转到捕获文件的第一个数据包。 |
|
|
|
|
跳转到捕获文件的最后一个数据包。 |
|
|
|
|
在进行实时捕获时自动滚动数据包列表(或不)。 |
|
|
|
|
着色数据包列表(或不)。 |
|
|
|
|
放大数据包数据(增加字体大小)。 |
|
|
|
|
缩小数据包数据(减小字体大小)。 |
|
|
|
|
将缩放级别设置回100%。 |
|
|
|
|
调整列的大小,使内容适合它们。 |
过滤器工具栏可让您快速编辑和应用显示过滤器。有关显示过滤器的更多信息,请参见第6.3节“查看时过滤数据包”。

表3.14。过滤工具栏项
| 工具栏图标 | Name | 描述 |
|---|---|---|
|
|
书签 |
管理或选择保存的过滤器。 |
|
|
过滤输入 |
输入或编辑显示过滤器字符串的区域,请参见第6.4节“构建显示过滤器表达式”。在键入时,会对您的过滤字符串进行语法检查。如果输入不完整或无效的字符串,背景将变为红色,输入有效字符串时,背景将变为绿色。 在此字段中更改了某些内容后,请不要忘记按“应用”按钮(或“输入/返回”键),将此过滤器字符串应用于显示。 此字段也是显示当前应用过滤器的位置。 |
|
|
明确 |
重置当前显示过滤器并清除编辑区域。 |
|
|
应用 |
将编辑区域中的当前值应用为新的显示过滤器。 在大型捕获文件上应用显示过滤器可能需要很长时间。 |
|
|
最近 |
从最近应用的过滤器列表中进行选择。 |
|
|
过滤表达式 |
打开一个对话框,允许您从协议字段列表中编辑显示过滤器,如第6.5节“过滤器表达式”对话框中所述 |
|
|
添加按钮 |
添加新的过滤器表达式按钮。 |
|
|
表情按钮 |
示例过滤器表达式按钮名为“Squirrels”。 |
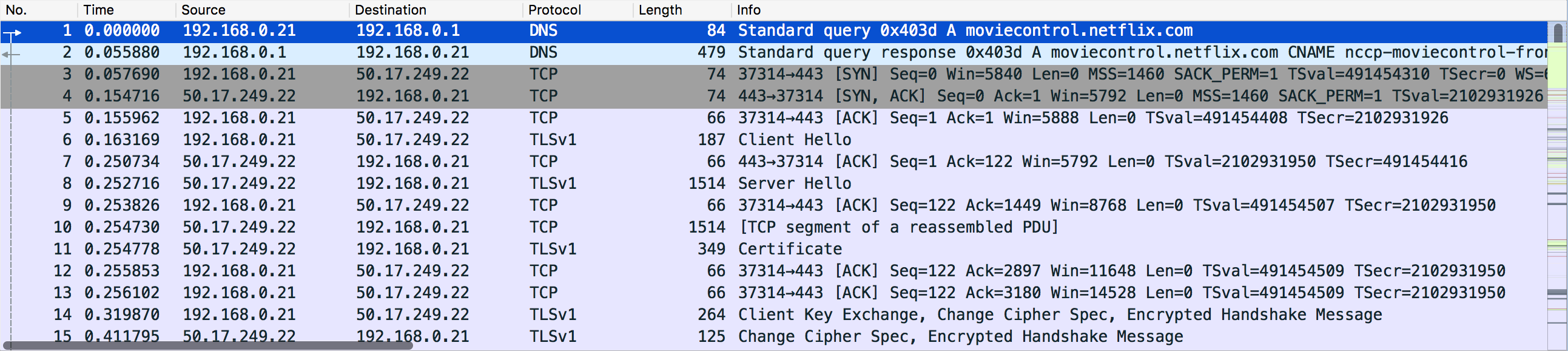
数据包列表窗格显示当前捕获文件中的所有数据包。
包列表中的每一行对应于捕获文件中的一个包。如果在此窗格中选择一行,则“数据包详细信息”和“数据包字节”窗格中将显示更多详细信息。
在解析数据包时,Wireshark会将协议解析器中的信息放入列中。由于更高级别的协议可能会覆盖较低级别的信息,因此通常只会从最高级别查看信息。
例如,让我们看一下以太网数据包中包含TCP内部TCP的数据包。以太网解剖器将写入其数据(例如以太网地址),IP解析器将自己覆盖它(例如IP地址),TCP解析器将覆盖IP信息,等等。
有很多不同的专栏可供选择。可以通过首选项设置选择显示哪些列,请参见第11.5节“首选项”。
默认列将显示:
第一列显示每个数据包如何与所选数据包相关。例如,在上面的图像中,选择第一个数据包,这是一个DNS请求。Wireshark显示请求本身的向右箭头,然后是数据包2中响应的向左箭头。为什么有虚线?进一步向下使用相同端口号的DNS数据包更多。Wireshark将它们视为属于同一个对话并绘制一条连接它们的线。
表3.15。相关包符号
|
|
对话中的第一个数据包。 |
|
|
所选对话的一部分。 |
|
|
不属于所选对话的一部分。 |
|
|
对话中的最后一个数据包。 |
|
|
请求。 |
|
|
响应。 |
|
|
所选数据包确认此数据包。 |
|
|
所选数据包是此数据包的重复确认。 |
|
|
所选择的分组以某种其他方式与该分组相关,例如作为重组的一部分。 |
数据包列表有一个智能滚动条,显示附近数据包的微缩映射。 滚动条的每个栅格线对应一个数据包,因此地图中显示的数据包数量取决于您的物理显示和数据包列表的高度。高分辨率(“Retina”)显示屏上的高数据包列表将显示相当多的数据包。在上图中,滚动条显示超过500个数据包的状态以及数据包列表本身中显示的15个数据包。
右键单击将显示上下文菜单, 如图6.4“数据包列表”窗格的“弹出菜单”中所述。
数据包详细信息窗格以更详细的形式显示当前数据包(在“数据包列表”窗格中选择)。
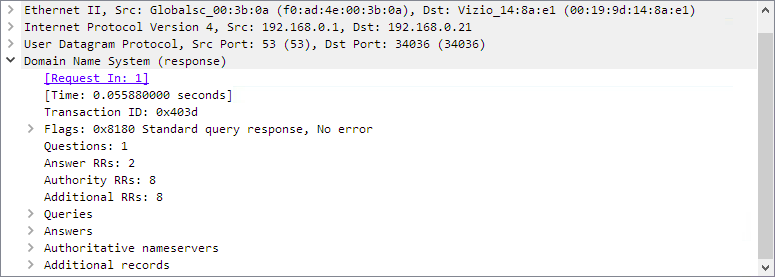
此窗格显示在“数据包列表”窗格中选择的数据包的协议和协议字段。树中显示的数据包的协议和字段,可以展开和折叠。
有一个上下文菜单(鼠标右键单击)可用。请参 见图6.5“分组详细信息”窗格的“弹出菜单”中的详细信息。
一些协议字段具有特殊含义。
- 生成的字段。Wireshark本身将生成附加的协议信息,这些信息在捕获的数据中不存在。该信息用方括号括起来(“[”和“]”)。生成的信息包括响应时间,TCP分析,IP地理定位信息和校验和验证。
- 链接。如果Wireshark检测到捕获文件中与另一个数据包的关系,它将生成指向该数据包的链接。链接带有下划线并以蓝色显示。如果双击链接,Wireshark将跳转到相应的数据包。
数据包字节窗格以hexdump样式显示当前数据包的数据(在“数据包列表”窗格中选择)。
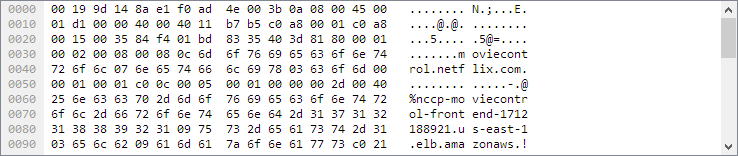
“Packet Bytes”窗格显示分组数据的规范 十六进制转储。每行包含数据偏移量,十六个十六进制字节和十六个ASCII字节。非printalbe字节被句点(“。”)替换。
根据数据包数据,有时可以使用多个页面,例如,当Wireshark将某些数据包重新组合成一个数据块时。(有关详细信息,请参见 第7.8节“数据包重组”)。在这种情况下,您可以通过单击窗格底部的相应选项卡来查看每个数据源。
附加页面通常包含从多个数据包或解密数据重组的数据。
选项卡标签的上下文菜单(单击鼠标右键)将显示所有可用页面的列表。如果窗格中的大小对于所有选项卡标签来说太小,这会很有用。
状态栏显示信息性消息。
通常,左侧将显示上下文相关信息,中间部分将显示有关当前捕获文件的信息,右侧将显示所选配置配置文件。拖动文本区域之间的手柄以更改大小。

在没有加载捕获文件的情况下显示此状态栏,例如,当启动Wireshark时。

- 左侧的彩色项目符号显示当前加载的捕获文件中找到的最高专家信息级别。将鼠标悬停在此图标上将显示专家信息级别的文本描述,单击该图标将显示“专家信息”对话框。有关专家信息的详细说明,请参见第7.4节“专家信息”。
- 左侧显示有关捕获文件的信息,其名称,大小以及捕获时的已用时间。将鼠标悬停在文件名上将显示其完整路径和大小。
-
中间部分显示捕获文件中的当前数据包数。将显示以下值:
- 数据包:捕获的数据包数。
- 显示:当前显示的数据包数。
- 标记:标记数据包的数量(仅在标记数据包时显示)。
- 丢弃:丢弃的数据包数量(仅在Wireshark无法捕获所有数据包时显示)。
- 忽略:忽略的数据包数(仅在忽略数据包时显示)。
- 加载时间:加载捕获所需的时间(挂钟时间)。
- 右侧显示所选的配置文件。单击状态栏的这一部分将显示包含所有可用配置配置文件的菜单,从该列表中选择将更改配置配置文件。

有关配置配置文件的详细说明,请参见第11.6节“配置配置文件”。

如果您从“数据包详细信息”窗格中选择了协议字段,则会显示此信息。
|
小费 |
|---|---|
|
括号之间的值(在此示例中为“ipv6.src”)可用作显示过滤器,表示所选的协议字段。 |

如果您尝试使用可能具有意外结果的显示过滤器,则会显示此信息。有关详细说明,请参见 第6.4.7节“常见错误”。
目录
捕获实时网络数据是Wireshark的主要功能之一。
Wireshark捕获引擎提供以下功能:
- 从不同类型的网络硬件捕获,如以太网或802.11。
- 停止对不同触发器的捕获,例如捕获的数据量,已用时间或数据包数。
- 在Wireshark捕获时同时显示已解码的数据包。
- 过滤数据包,减少要捕获的数据量。请参见 第4.13节“捕获时过滤”。
- 在进行长期捕获时将数据包保存在多个文件中,可选择旋转固定数量的文件(“ringbuffer”)。请参见 第4.11节“捕获文件和文件模式”。
- 从多个网络接口同时捕获。
捕获引擎仍然缺乏以下功能:
- 根据捕获的数据停止捕获(或执行一些其他操作)。
将Wireshark设置为首次捕获数据包可能会非常棘手。有关“如何设置捕获”的综合指南,请访问https://wiki.wireshark.org/CaptureSetup。
以下是一些常见的陷阱:
- 您可能需要特殊权限才能开始实时捕获。
- 您需要选择正确的网络接口来捕获数据包数据。
- 您需要在网络中的正确位置捕获以查看要查看的流量。
如果您在设置捕获环境时遇到任何问题,请查看上面提到的指南。
可以使用以下方法开始使用Wireshark捕获数据包:
- 您可以双击主窗口中的界面。
- 你可以使用“捕捉接口”对话框(可用接口的概述
- 您可以使用当前设置立即开始捕获,方法是选择
- 如果您已经知道捕获接口的名称,则可以从命令行启动Wireshark:
$ wireshark -i eth0 -k
这将启动接口eth0上的Wireshark捕获。更多细节可以在第11.2节“从命令行启动Wireshark”中找到。
当您选择
|
您和您的操作系统都可以隐藏接口 |
|---|---|
|
此对话框仅显示Wireshark可以访问的本地接口。它还将隐藏第11.5.1节“接口选项”中标记为隐藏的接口。由于Wireshark可能无法检测到所有本地接口,并且无法检测到可用的远程接口,因此可能存在比列出的更多捕获接口。 |
可以选择多个接口并同时从中捕获。


- 设备(仅限Unix / Linux)
- 接口设备名称。
- 描述
- 操作系统提供的接口描述,或第11.5.1节“接口选项”中添加的用户定义注释。
- IP
- Wireshark可以为此接口找到的第一个IP地址。您可以单击该地址以循环分配给它的其他地址(如果可用)。如果找不到地址,将显示“无”。
- 包
- 自此对话框打开以来从此接口捕获的数据包数。如果在最后一秒没有捕获数据包,将会显示为灰色。
- 包/秒
- 最后一秒捕获的数据包数。如果在最后一秒没有捕获数据包,将会显示为灰色。
- 停止
- 停止当前正在运行的捕获。
- 开始
- 如果未设置任何选项,则使用上次捕获中的设置或默认设置立即在所有选定接口上开始捕获。
- 选项
- 使用选定的标记接口打开“捕获选项”对话框。请参见 第4.5节“”捕获选项“对话框”。
- 详细信息(仅限Microsoft Windows)
- 打开一个对话框,其中包含有关界面的详细信 请参见 第4.10节“”接口详细信息“对话框”。
- 救命
- 显示此帮助页面。
- 关
- 关闭此对话框。
当您选择

|
小费 |
|---|---|
|
如果您不确定在此对话框中选择哪个选项,请尝试保留默认值,因为在许多情况下这应该可以正常工作。 |
该表显示了所有可用接口的设置:
- 接口名称及其IP地址。如果无法从系统中解析地址,则将显示“无”。
|
注意 |
|---|---|
|
Loopback接口在Windows平台上不可用。 |
- 链路层标头类型。
- 启用或禁用默认模式的信息。
- 将为每个数据包捕获的最大数据量。默认值设置为262144字节。
- 保留内核缓冲区的大小以保留捕获的数据包。
- 是否以监控模式捕获数据包的信息(仅限Unix / Linux)。
- 选择的捕获过滤器。
通过标记第一列中的复选框,可以选择从中捕获接口。通过双击界面上的“编辑界面设置”对话框,如图4.4所示,将打开“编辑界面设置”对话框。
- 捕获所有接口
- 由于Wireshark可以在多个接口上捕获,因此可以选择在所有可用接口上捕获。
- 以混杂模式捕获所有数据包
- 此复选框允许您指定Wireshark在捕获时应将所有接口置于混杂模式。
- 捕获过滤器
-
此字段允许您为当前选定的所有接口指定捕获筛选器。在此字段中输入过滤器后,新选择的接口将继承过滤器。第4.13节“捕获时过滤”更详细地讨论了捕获过滤器。它默认为空,或者没有过滤器。
您还可以单击“
- 编译选定的BPF
- 此按钮允许您将捕获过滤器编译为BPF代码,并弹出一个窗口,显示生成的伪代码。这有助于理解您创建的捕获过滤器的工作。“
|
小费 |
|---|---|
|
Linux高级用户提示 |
通过执行打开BPF JIT,可以在Linux上加速BPF的执行
$ echo 1> / proc / sys / net / core / bpf_jit_enable
如果它尚未启用。要使更改持久,您可以使用 sysfsutils。
- 管理界面
- 该
有关捕获文件用法的说明,请参见第4.11节“捕获文件和文件模式”。
- 文件
-
此字段允许您指定将用于捕获文件的文件名。默认情况下,此字段为空。如果该字段留空,则捕获数据将存储在临时文件中。有关详细信息,请参见第4.11节“捕获文件和文件模式”。
您还可以单击此字段右侧的按钮以浏览文件系统。
- 使用多个文件
- 如果达到特定的触发条件,Wireshark将自动切换到新文件,而不是使用单个文件。
- 使用pcapng格式
- 此复选框允许您指定Wireshark以pcapng格式保存捕获的数据包。这种下一代捕获文件格式目前正在开发中。如果选择多个接口进行捕获,则默认设置此复选框。有关pcapng的更多详细信息,请参阅https://wiki.wireshark.org/Development/PcapNg。
- 每n兆字节的下一个文件
- 仅限多个文件。在捕获给定数量的字节/千字节/兆字节/千兆字节后切换到下一个文件。
- 每n分钟下一个文件
- 仅限多个文件:在给定的秒数/分钟/小时/天之后切换到下一个文件。
- 带n个文件的环形缓冲区
- 仅限多个文件:使用给定数量的文件形成捕获文件的环形缓冲区。
- n个文件后停止捕获
- 仅限多个文件:在切换到给定次数的下一个文件后停止捕获。
- ... n个数据包之后
- 捕获给定数量的数据包后停止捕获。
- ...在n兆字节之后
- 在捕获了给定数量的字节/千字节/兆字节/千兆字节后停止捕获。如果选择“使用多个文件”,则此选项显示为灰色。
- ...... n分钟后
- 在给定的秒数/分钟/小时/天之后停止捕获。
- 实时更新数据包列表
- 此选项允许您指定Wireshark应实时更新数据包列表窗格。如果不指定,则在停止捕获之前,Wireshark不会显示任何数据包。检查时,Wireshark会在单独的进程中捕获并将捕获信息提供给显示进程。
- 实时捕捉中的自动滚动
- 此选项允许您指定Wireshark应在新数据包进入时滚动数据包列表窗格,因此您始终查看最后一个数据包。如果您未指定此Wireshark,只需将新数据包添加到列表末尾,但不会滚动数据包列表窗格。如果禁用“实时更新数据包列表”,则此选项显示为灰色。
- 启用MAC名称解析
- 此选项允许您控制Wireshark是否将MAC地址转换为名称。请参见第7.9节“名称解析”。
- 启用网络名称解析
- 此选项允许您控制Wireshark是否将网络地址转换为名称。请参见第7.9节“名称解析”。
- 启用传输名称解析
- 此选项允许您控制Wireshark是否将传输地址转换为协议。请参见第7.9节“名称解析”。
如果双击图4.3中的界面,“”捕获选项“对话框”将弹出以下对话框。

您可以在此对话框中设置以下字段:
- IP地址
- 所选接口的IP地址。如果无法从系统解析地址,则将显示“无”。
- 链路层头类型
- 除非您处于极少数情况下需要保持默认设置。有关详细说明。请参见第4.12节“链路层头类型”
- 无线设置(仅限Windows)
- 您可以在此处使用AirPCap适配器设置无线捕获的设置。有关详细说明,请参阅AirPCap用户指南。
- 远程设置(仅限Windows)
- 您可以在此处设置远程捕获的设置。有关详细说明,请参见第4.9节“远程捕获接口”对话框“
- 以混杂模式捕获数据包
- 此复选框允许您指定Wireshark在捕获时应将接口置于混杂模式。如果您未指定此Wireshark将仅捕获进出您计算机的数据包(而不是您的LAN网段上的所有数据包)。
|
注意 |
|---|---|
|
如果某个其他进程已将接口置于混杂模式,即使您关闭此选项,也可能会以混杂模式捕获。 即使在混杂模式下,您仍然不一定会看到LAN网段上的所有数据包。有关更多信息,请参阅Wireshark常见问题解答。 |
- 将每个数据包限制为n个字节
-
此字段允许您指定将为每个数据包捕获的最大数据量,有时也称为snaplen。如果禁用,则将该值设置为最大值65535,这对于大多数协议都是足够的。一些经验法则:
- 如果您不确定,请保留默认值。
- 如果您不需要或不需要数据包中的所有数据 - 例如,如果您只需要链路层,IP和TCP标头 - 您可能希望选择较小的快照长度,因为CPU较少复制数据包需要时间,数据包需要的缓冲区空间更少,因此如果流量非常大,可能会丢弃更少的数据包。
- 如果未捕获数据包中的所有数据,您可能会发现所需的数据包数据位于丢弃的部分中,或者由于缺少重组所需的数据而无法重新组装。
- 缓冲区大小:n兆字节
- 输入捕获时要使用的缓冲区大小。这是内核缓冲区的大小,它将保留捕获的数据包,直到它们被写入磁盘。如果遇到丢包,请尝试增加此值。
- 以监控模式捕获数据包(仅限Unix / Linux)
- 此复选框允许您设置无线接口以捕获它可以接收的所有流量,而不仅仅是与其关联的BSS上的流量,即使您设置了混杂模式也可能发生这种情况。此外,可能需要打开此选项,以便从捕获的帧中查看IEEE 802.11标头和/或无线电信息。
|
注意 |
|---|---|
|
在监控模式下,适配器可能会将自己与其关联的网络取消关联。 |
- 捕获过滤器
-
此字段允许您指定捕获筛选器。第4.13节“捕获时过滤”更详细地讨论了捕获过滤器。它默认为空,或者没有过滤器。
您也可以点击
- 编译BPF
- 此按钮允许您将捕获过滤器编译为BPF代码,并弹出一个窗口,显示生成的伪代码。这有助于理解您创建的捕获过滤器的工作。

作为管理接口的中心点,此对话框包含三个用于添加或删除接口的选项卡。



“本地接口”选项卡包含可用本地接口的列表,包括隐藏的接口,这些接口未在其他列表中显示。
如果添加了新的本地接口,例如,已激活无线接口,则不会自动将其添加到列表中以防止持续扫描可用接口列表中的更改。要更新列表,可以重新扫描。
隐藏界面的一种方法是更改首选项。如果激活“隐藏”复选框并单击“

在此选项卡中,可以添加远程主机上的接口。可以隐藏这些接口中的一个或多个。与本地接口相比,它们不会保存在preferences文件中。
要从列表中删除包含其所有接口的主机,必须选择它。然后单击“
有关详细说明,请参见第4.9节“远程捕获接口”对话框“
除了在本地接口上进行捕获外,Wireshark还能够通过网络到达所谓的捕获守护进程或服务进程,以便从中接收捕获的数据。
|
仅限Microsoft Windows |
|---|---|
|
此对话框和功能仅在Microsoft Windows上可用。在Linux / Unix上,您可以通过SSH隧道(安全地)实现相同的效果。 |
远程数据包捕获协议服务必须首先在目标平台上运行,然后才能连接到Wireshark。最简单的方法是在目标上从{npcap-download-url}安装Npcap。安装完成后,转到“服务”控制面板,找到“远程数据包捕获协议”服务并启动它。
|
注意 |
|---|---|
|
确保您在目标平台上具有对端口2002的外部访问权限。这是默认情况下可以访问远程数据包捕获协议服务的端口。 |
要访问“远程捕获接口”对话框,请使用“添加新接口 - 远程”对话框。请参见图4.9,“添加新接口 - 远程接口”对话框“,然后选择

您必须在此对话框中设置以下参数:
- 主办
- 输入远程数据包捕获协议服务正在侦听的目标平台的IP地址或主机名。下拉列表包含先前已成功联系的主机。通过从下拉列表中选择“清除列表”,可以清空列表。
- 港口
- 设置远程数据包捕获协议服务正在侦听的端口号。保持打开状态以使用默认端口(2002)。
- 空身份验证
- 如果您不需要进行身份验证以启动远程捕获,请选择此选项。这取决于目标平台。像这样配置目标平台会使其不安全。
- 密码验证
- 这是连接目标平台的常规方式。设置连接到远程数据包捕获协议服务所需的凭据。
远程捕获可以进一步微调,以符合您的情况。该

您可以在此对话框中设置以下参数:
- 不捕获自己的RPCAP流量
-
此选项设置捕获筛选器,以便从远程数据包捕获协议服务流回Wireshark的流量也不会被捕获,也会发回。这种递归使重复流量的链接饱和。
只有在连接回Wireshark的接口以外的接口上捕获时,才应关闭此功能。
- 使用UDP进行数据传输
- 远程捕获控制和TCP连接上的数据流。此选项允许您选择UDP流进行数据传输。
- 采样选项无
- 此选项指示远程数据包捕获协议服务发送回已通过捕获筛选器的所有捕获数据包。在带宽足够的远程捕获会话中,这通常不是问题。
- x包的采样选项1
- 此选项将远程数据包捕获协议服务限制为仅根据数据包数量发送捕获数据的子采样。这允许通过较高带宽接口的窄带远程捕获会话进行捕获。
- 每x毫秒采样选项1
- 此选项将远程数据包捕获协议服务限制为仅在时间方面发送捕获数据的子采样。这允许在较高带宽接口的窄带捕获会话上捕获。
当您从Capture Interface菜单中选择Details时,Wireshark会弹出“Interface Details”对话框,如图4.12“The Interface Details”对话框所示。此对话框显示所选接口的各种特征和统计信息。
|
仅限Microsoft Windows |
|---|---|
|
此对话框仅在Microsoft Windows上可用 |

捕获底层libpcap捕获引擎将捕获来自网卡的数据包并将数据包数据保存在(相对)小内核缓冲区中。这些数据由Wireshark读取并保存到捕获文件中。
默认情况下,Wireshark将数据包保存到临时文件中。您还可以告诉Wireshark保存到特定(“永久”)文件,并在经过给定时间或捕获给定数量的数据包后切换到其他文件。这些选项在“捕获选项”对话框的“输出”选项卡中进行控制。
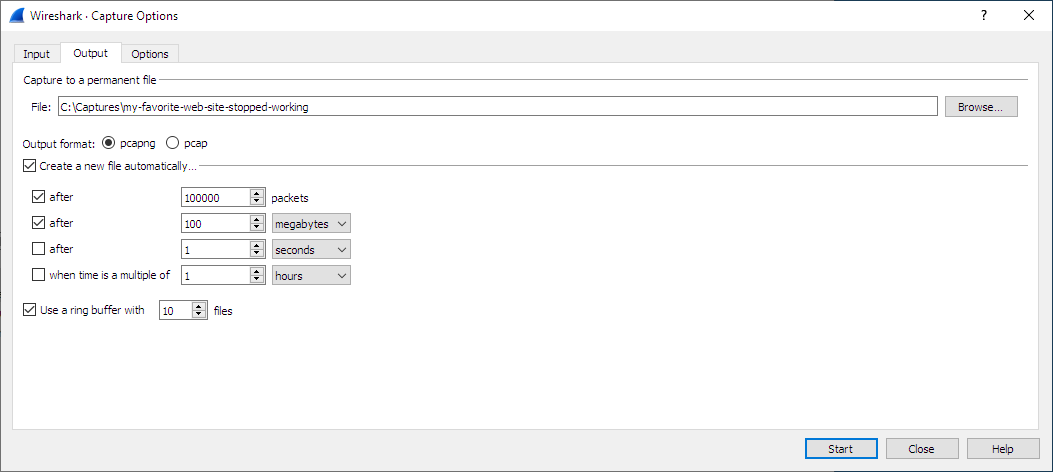
|
小费 |
|---|---|
|
使用大文件(几百MB)可能会非常慢。如果您计划从高流量网络进行长期捕获或捕获,请考虑使用“多个文件”选项之一。这会将捕获的数据包传播到几个较小的文件上,这些文件可以更愉快地使用。 |
使用多个文件可能会削减上下文相关信息 Wireshark保存加载的分组数据的上下文信息,因此它可以报告与上下文相关的问题(如流错误)并保留有关上下文相关协议的信息(例如,在建立阶段交换数据并且仅在后面的数据包中引用)。由于它仅为加载的文件保留此信息,因此使用多种文件模式之一可能会削减这些上下文。如果建立阶段保存在一个文件中,并且您希望看到的内容位于另一个文件中,则可能看不到某些有价值的上下文相关信息。
有关用于捕获文件的文件夹的信息可以在 附录B,文件和文件夹中找到。
表4.1。捕获选项选择的捕获文件模式
| 文件名 | “创建一个新文件......” | “使用环形缓冲区...” | 模式 | 结果使用的文件名 |
|---|---|---|---|---|
|
- |
- |
- |
单个临时文件 |
wiresharkXXXXXX(XXXXXX是一个唯一的号码) |
|
foo.cap |
- |
- |
单个命名文件 |
foo.cap |
|
foo.cap |
X |
- |
多个文件,连续 |
foo_00001_20190714110102.cap,foo_00002_20190714110318.cap,... |
|
foo.cap |
X |
X |
多个文件,环形缓冲区 |
foo_00001_20190714110102.cap,foo_00002_20190714110318.cap,... |
- 单个临时文件
- 将创建并使用临时文件(这是默认值)。停止捕获后,可以稍后在用户指定的名称下保存此文件。
- 单个命名文件
- 将使用单个捕获文件。如果要将新捕获文件放在特定文件夹中,请选择此模式。
- 多个文件,连续
- 与“单一命名文件”模式类似,但是在达到多个文件切换条件之一(“每个下一个文件...”值之一)之后创建并使用新文件。
- 多个文件,环形缓冲区
- 就像“多个文件连续”一样,达到多个文件切换条件之一(“每个...的下一个文件”值之一)将切换到下一个文件。如果未达到“带有n个文件的环形缓冲区”的值,则这将是新创建的文件,否则它将替换最旧的以前使用的文件(从而形成“环”)。+此模式将限制最大磁盘使用量,即使对于无限量的捕获输入数据,也只保留最新捕获的数据。
在大多数情况下,您不必修改链接层标头类型。一些例外情况如下:
如果您在以太网设备上进行捕获,则可能会选择“以太网”或“DOCSIS”。如果从Cisco Cable Modem终端系统捕获将DOCSIS流量放入要捕获的以太网的流量,请选择“DOCSIS”,否则选择“Ethernet”。
如果您在某些版本的BSD上捕获802.11设备,则可能会选择“以太网”或“802.11”。“以太网”将导致捕获的数据包具有伪(“熟”)以太网报头。“802.11”将使他们拥有完整的IEEE 802.11标头。除非需要由不支持802.11标头的应用程序读取捕获,否则应选择“802.11”。
如果您在连接到同步串行线路的Endace DAG卡上捕获,则可能会选择“PPP over serial”或“Cisco HDLC”。如果串行线路上的协议是PPP,请选择“PPP over serial”,如果串行线路上的协议是Cisco HDLC,请选择“Cisco HDLC”。
如果您在连接到ATM网络的Endace DAG卡上捕获,则可能会选择“RFC 1483 IP-over-ATM”或“Sun raw ATM”。如果捕获的唯一流量是RFC 1483 LLC封装的IP,或者如果捕获需要由不支持SunATM头的应用程序读取,请选择“RFC 1483 IP-over-ATM”,否则选择“Sun raw ATM” ”。
Wireshark使用libpcap过滤器语言来捕获过滤器。下面是语法的简要概述。完整的文档可以在pcap-filter手册页中找到。您可以在https://wiki.wireshark.org/CaptureFilters找到很多Capture Filter示例。
您可以将捕获过滤器输入到Wireshark“捕获选项”对话框的“过滤器”字段中,如图4.3“捕获选项”对话框中所示。
捕获过滤器采用通过连词(和/或)连接的一系列基本表达式的形式,并且可选地前面不是:
[not]原始[和|或[not] primitive ...]
示例4.1“用于telnet的捕获过滤器捕获与特定主机之间的流量”中显示了一个示例。
此示例捕获进出主机10.0.0.5的telnet流量,并显示如何使用两个原语和和。示例4.2“捕获所有telnet流量不是来自10.0.0.5”中显示了另一个示例,并显示了如何捕获除10.0.0.5之外的所有telnet流量。
- 原语只是以下之一:[src | dst] host <host>
- 此原语允许您筛选主机IP地址或名称。您可以选择在基元前面加上关键字src | dst,以指定您只对源地址或目标地址感兴趣。如果这些不存在,将选择指定地址显示为源地址或目标地址的数据包。
- ether [src | dst] host <ehost>
- 此原语允许您过滤以太网主机地址。您可以选择在关键字ether和host之间包含关键字src | dst, 以指定您只对源地址或目标地址感兴趣。如果这些不存在,将选择指定地址出现在源地址或目标地址中的数据包。
- 网关主机<host>
- 此原语允许您过滤使用主机作为网关的数据包。也就是说,以太网源或目标是主机,但源和目标IP地址都不是主机。
- [src | dst] net <net> [{mask <mask>} | {len <len>}]
- 此原语允许您过滤网络号。您可以选择在此原语之前加上关键字src | dst,以指定您只对源网络或目标网络感兴趣。如果这两者都不存在,则将选择在源地址或目标地址中具有指定网络的数据包。此外,您可以为网络指定网络掩码或CIDR前缀(如果它们与您自己的不同)。
- [tcp | udp] [src | dst] port <port>
-
此原语允许您过滤TCP和UDP端口号。您可以选择在此原语之前加上关键字src | dst和tcp | udp ,这些关键字允许您指定您分别只对源端口或目标端口以及TCP或UDP数据包感兴趣。关键字tcp | udp必须出现在src | dst之前。
如果未指定这些,则将为TCP和UDP协议选择数据包,并在源端口或目标端口字段中显示指定的地址。
- 更少|更大<长度>
- 此原语允许您分别对长度小于或等于指定长度或大于或等于指定长度的数据包进行过滤。
- ip | ether proto <protocol>
- 此原语允许您在以太网层或IP层上过滤指定的协议。
- ether | ip broadcast | multicast
- 此原语允许您过滤以太网或IP广播或多播。
- <expr> relop <expr>
- 此原语允许您创建复杂的过滤器表达式,以选择数据包中的字节或字节范围。有关更多详细信息,请参阅http://www.tcpdump.org/manpages/pcap-filter.7.html上的pcap-filter手册页 。
如果Wireshark正在远程运行(使用例如SSH,导出的X11窗口,终端服务器......),则必须通过网络传输远程内容,从而为实际感兴趣的流量添加大量(通常不重要的)数据包。
为了避免这种情况,Wireshark试图找出它是否是远程连接的(通过查看一些特定的环境变量)并自动创建一个匹配连接方面的捕获过滤器。
分析以下环境变量:
SSH_CONNECTION(SSH)- <远程IP> <远程端口> <本地IP> <本地端口>
SSH_CLIENT(SSH)- <远程IP> <远程端口> <本地端口>
REMOTEHOST(tcsh,其他人?)- <远程名称>
DISPLAY(X11)- [remote name]:<display num>
SESSIONNAME(终端服务器)- <远程名称>
在Windows上,它会询问操作系统是否在远程桌面服务环境中运行。
捕获正在运行时,您可能会看到以下对话框:
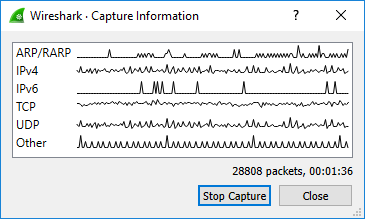
此对话框显示协议列表及其随时间变化的活动。可以通过“高级”首选项中的“capture.show_info”设置启用它。
Wireshark可以读入以前保存的捕获文件。要阅读它们,只需选择
|
使用拖放很方便 |
|---|---|
|
您只需在文件管理器中将其拖放到Wireshark的主窗口即可打开文件。但是,拖放可能并非在所有桌面环境中都可用。 |
如果您之前没有保存过当前的捕获文件,则会要求您这样做以防止数据丢失。可以在首选项中禁用此警告。
除了原生文件格式(pcapng)之外,Wireshark还可以从大量其他数据包捕获程序中读取和写入捕获文件。有关Wireshark理解的捕获格式列表,请参见 第5.2.2节“输入文件格式”。
“打开捕获文件”对话框允许您搜索包含以前捕获的数据包的捕获文件,以便在Wireshark中显示。以下部分显示了Wireshark“打开文件”对话框的一些示例。此对话框的外观取决于系统。但是,各个系统的功能应该相同。
所有系统上的常见对话行为:
- 选择文件和目录。
- 单击“
- 单击“
Wireshark对这些对话框的标准行为的扩展:
- 查看文件大小预览信息,例如文件大小和选定捕获文件中的数据包数量。
- 使用“
- 通过单击“...名称解析”检查按钮之一,指定要对所有数据包执行的名称解析类型。有关名称解析的详细信息,请参见第7.9节“名称解析”。
|
节省大量时间加载巨大的捕获文件 |
|---|---|
|
您可以稍后在查看数据包时更改显示过滤器和名称解析设置。但是,如果稍后更改这些设置,加载大量捕获文件可能会占用大量额外时间,因此在这种情况下,最好在此处预先设置至少过滤器。 |

这是常见的Windows文件打开对话框 - 加上一些Wireshark扩展。
特定于此对话框:
- “

这是常见的Gimp / GNOME文件打开对话框以及一些Wireshark扩展。
特定于此对话框:
- 使用
- 本
- 如果Wireshark无法将所选文件识别为捕获文件,则会使“
Wireshark可以打开其他捕获工具的以下文件格式:
- pcapng。libpcap格式的灵活,可扩展的后继者。Wireshark 1.8及更高版本默认将文件保存为pcapng。1.8之前的版本使用了libpcap。
- libpcap的。libpcap数据包捕获库使用的默认格式。通过使用tcpdump的,_Snort,Nmap的,的NTOP,以及许多其他工具。
- 甲骨文(以前的Sun)窥探和atmsnoop
- Finisar(以前的Shomiti)测量员捕获
- Microsoft 网络监视器捕获
- Novell LANalyzer捕获
- AIX iptrace捕获
- Cinco Networks NetXray捕获
- Network Associates基于Windows的Sniffer和Sniffer Pro捕获
- Network General / Network Associates基于DOS的Sniffer(压缩或未压缩)捕获
- AG Group / WildPackets / Savvius EtherPeek / TokenPeek / AiroPeek / EtherHelp / PacketGrabber捕获
- RADCOM的WAN / LAN分析仪可以捕获
- 网络仪器观察者版本9捕获
- Lucent / Ascend路由器调试输出
- HP-UX的nettl
- 东芝的ISDN路由器转储输出
- ISDN4BSD i4btrace实用程序
- 来自EyeSDN USB S0的迹线
- 思科安全入侵检测系统的IPLog格式
- pppd logs(pppdump格式)
- VMS的TCPIPtrace / TCPtrace / UCX $ TRACE实用程序的输出
- DBS Etherwatch VMS实用程序输出的文本
- Visual Networks的Visual UpTime流量捕获
- CoSine L2调试的输出
- Accellent的5Views局域网代理的输出
- Endace Measurement Systems的ERF格式捕获
- Linux Bluez蓝牙堆栈hcidump -w跟踪
- Catapult DCT2000 .out文件
- Gammu在Netmonitor模式下从诺基亚DCT3手机生成文本输出
- IBM系列(OS / 400)Comm跟踪(ASCII和UNICODE)
- Juniper Netscreen监听捕获
- Symbian OS btsnoop捕获
- Tamosoft CommView捕获
- Textronix K12xx 32位.rf5格式捕获
- Textronix K12文本文件格式捕获
- Apple PacketLogger捕获
- 从Aethra Telecommunications的PC108软件中获取测试仪器
不时添加新的文件格式。
根据捕获的数据包类型,可能无法读取某些格式。大多数文件格式通常支持以太网捕获,但可能无法从所有文件格式读取其他数据包类型,如PPP或IEEE 802.11。
你可以简单地使用保存捕获的数据包
并非所有信息都将保存在捕获文件中。例如,大多数文件格式不记录丢弃的数据包的数量。有关详细信息,请参见 第B.1节“捕获文件”。
“将捕获文件另存为”对话框允许您将当前捕获保存到文件。以下部分显示了此对话框的一些示例。此对话框的外观取决于系统。但是,各个系统的功能应该相同。

这是常见的Windows文件保存对话框,其中包含一些额外的Wireshark扩展。
此对话框的特定行为:
- 如果可用,“帮助”按钮将引导您进入本“用户指南”的此部分。
- 如果您没有为文件名提供文件扩展名(例如
.pcap),Wireshark将附加该文件格式的标准文件扩展名。

这是常见的Gimp / GNOME文件保存对话框,其中包含其他Wireshark扩展。
特定于此对话框:
- 单击“浏览其他文件夹”中的+将允许您浏览文件系统中的文件和文件夹。
使用此对话框,您可以执行以下操作:
- 输入要保存捕获的数据包的文件的名称,作为文件系统中的标准文件名。
- 选择要将文件保存到的目录。
- 选择要保存的数据包范围。请参见第5.9节“分组范围”帧“。
- 单击“文件类型”下拉框,指定保存的捕获文件的格式。您可以从第5.3.2节“输出文件格式”中描述的类型中进行选择 。
根据捕获的数据包类型,某些捕获格式可能不可用。
|
Wireshark可以转换文件格式 |
|---|---|
|
您可以通过读取捕获文件并使用不同的格式将捕获文件写入,将捕获文件从一种格式转换为另一种格式。 |
- 单击“
- 单击
Wireshark可以将数据包数据保存为其本机文件格式(pcapng)和其他协议分析器的文件格式,以便其他工具可以读取捕获数据。
|
不同的文件格式具有不同的时间戳精度 |
|---|---|
|
从当前使用的文件格式保存为不同的格式可能会降低时间戳的准确性; 有关详细信息,请参见第7.6节“时间戳”。 |
Wireshark可以保存以下文件格式(使用已知的文件扩展名):
- pcapng(* .pcapng)。libpcap格式的灵活,可扩展的后继者。Wireshark 1.8及更高版本默认将文件保存为pcapng。1.8之前的版本使用了libpcap。
- libpcap,tcpdump和使用tcpdump捕获格式的各种其他工具(* .pcap,* .cap,* .dmp)
- 非常好的5视图(* .5vw)
- HP-UX的nettl(* .TRC0,*。TRC1)
- Microsoft网络监视器 - NetMon(* .cap)
- Network Associates的嗅探器 - DOS(。*。CAP,*的Enc,* TRC,FDC *,* SYC)
- Network Associates Sniffer - Windows(* .cap)
- 网络仪器观察员版本9(* .bfr)
- Novell LANalyzer(* .tr1)
- Oracle(以前的Sun)snoop(* .snoop,* .cap)
- Visual Networks Visual UpTime流量(*。*)
不时添加新的文件格式。
上述工具是否比Wireshark更有用是一个不同的问题;-)
|
第三方协议分析器可能需要特定的文件扩展名 |
|---|---|
|
Wireshark检查文件的内容以确定其类型。其他一些协议分析器只查看文件扩展名。例如,您可能需要使用 |
有时您需要将多个捕获文件合并为一个。例如,如果您同时从多个接口同时捕获(例如,使用Wireshark的多个实例),这将非常有用。
使用Wireshark合并捕获文件有三种方法:
- 使用
- 使用拖放操作删除主窗口上的多个文件。Wireshark将尝试按时间顺序将数据包从已删除的文件合并到新创建的临时文件中。如果只删除单个文件,它将只替换现有的捕获。
- 使用该
mergecap工具,命令行工具来合并捕获文件。此工具提供了合并捕获文件的大多数选项。有关详细信息,请参见 第D.8节“ mergecap:将多个捕获文件合并为一个”。
此对话框允许您选择要合并到当前加载的文件中的文件。如果您当前的数据尚未保存,系统会要求您先保存。
此对话框的大多数控件的工作方式与“打开捕获文件”对话框中所述的相同,请参见第5.2.1节“打开捕获文件”对话框“。
此合并对话框的特定控件是:
- 将数据包前置到现有文件
- 在当前加载的数据包之前添加来自所选文件的数据包。
- 按时间顺序合并数据包
- 按时间顺序合并来自所选文件和当前加载文件的数据包。
- 将数据包附加到现有文件
- 在当前加载的数据包之后附加所选文件中的数据包。

这是常见的Windows文件打开对话框,其中包含其他Wireshark扩展。

这是常见的Gimp / GNOME文件打开对话框,其中包含其他Wireshark扩展。
Wireshark可以读取ASCII十六进制转储,并将描述的数据写入临时的libpcap捕获文件。它可以读取包含多个数据包的十六进制转储,并构建多个数据包的捕获文件。它还能够生成虚拟以太网,IP和UDP,TCP或SCTP报头,以便仅从应用级数据的六进制数据库构建完全可处理的数据包转储。
Wireshark了解生成的表单的hexdump od -Ax -tx1 -v。换句话说,每个字节被单独显示并用空格包围。每行以描述数据包中位置的偏移量开始,每个新数据包以0的偏移量开始,并且存在将偏移量与后续字节分开的空间。偏移量是十六进制数(也可以是八进制或十进制数),超过两个十六进制数字。这是一个可以导入的示例转储:
000000 00 e0 1e a7 05 6f 00 10 ........ 000008 5a a0 b9 12 08 00 46 00 ........ 000010 03 68 00 00 00 00 0a 2e ........ 000018 of 33 0f 19 08 7f 0f 19 ........ 000020 03 80 94 04 00 00 10 01 ........ 000028 16 a2 0a 00 03 50 00 0c ........ 000030 01 01 0f 19 03 80 11 01 ........
每行的宽度或字节数没有限制。此外,行末尾的文本转储也会被忽略。字节和十六进制数字可以是大写或小写。忽略偏移之前的任何文本,包括电子邮件转发字符>。字节串行之间的任何文本行都将被忽略。偏移量用于跟踪字节,因此偏移量必须正确。任何只有字节而没有前导偏移的行都将被忽略。偏移被识别为长于两个字符的十六进制数。忽略字节后的任何文本(例如字符转储)。此文本中的任何十六进制数也会被忽略。偏移量为零表示启动新数据包,因此具有一系列hexdumps的单个文本文件可以转换为具有多个数据包的数据包捕获。数据包前面可能有时间戳。这些是根据给定的格式解释的。如果不是第一个数据包带有当前时间的时间戳,则导入发生。写入多个数据包的时间戳各不相差1微秒。一般来说,没有这些限制,
还有一些其他特殊功能需要注意。第一个非空白字符所在的任何行都#将被忽略为注释。任何以该行开头的行#TEXT2PCAP都是一个指令,并且可以在此命令之后插入要由Wireshark处理的选项。目前没有实施指令。在将来,这些可用于对转储及其处理方式进行更细粒度的控制,例如时间戳,封装类型等.Wireshark还允许用户通过插入虚拟L2来读取应用程序级数据的转储,每个数据包之前的L3和L4标头。用户可以选择在每个数据包之前插入以太网报头,以太网和IP,或以太网,IP和UDP / TCP / SCTP报头。这允许Wireshark或任何其他全包解码器处理这些转储。
此对话框允许您选择要导入的文本文件,其中包含数据包数据的十六进制转储,并设置导入参数。

此导入对话框的特定控件分为两部分:
- 进口于
- 确定必须导入哪个输入文件以及如何解释它。
- 封装
- 确定如何封装数据。
导入参数如下:
- 文件名/浏览
- 输入要导入的文本文件的名称。您可以使用“ 浏览”浏览文件。
- 偏置
- 选择要导入的文本文件中给出的偏移的基数。这通常是十六进制的,但也支持十进制和八进制。 仅存在字节时选择“ 无”。这些将作为单个数据包导入。
- 时间戳格式
- 这是用于解析要导入的文本文件中的时间戳的格式说明符。它使用简单的语法来描述时间戳的格式,使用%H表示小时,%M表示分钟,%S表示秒,等等。简单的HH:MM:SS格式由%T涵盖。有关语法的完整定义,请查找
strptime(3)。如果要导入的文本文件中没有时间戳,请将此字段留空,并根据导入时间生成时间戳。 - 方向指示
- 如果要导入的文本文件在每个帧之前具有方向指示符,请勾选此框。它们位于每帧之前的单独一行,并以 I或i作为输入,O或o作为输出。
封装参数如下:
- 封装类型
- 您可以在此处选择要导入的帧类型。这一切都取决于要导入的转储类型。它列出了Wireshark理解的所有类型,以便将捕获文件内容传递给正确的解剖器。
- 假头
- 选择以太网封装时,您必须选择将虚拟标头添加到要导入的帧中。这些报头可以提供仿真以太网,IP,UDP,TCP或SCTP报头或SCTP数据块。选择一种虚拟标题时,将启用适用的条目,其他条目将显示为灰色并使用默认值。选择Wireshark Upper PDU导出封装后,ExportPDU选项 变为可用。这允许您输入这些帧将被定向到的解剖器的名称。
- 最大帧长
- 您可能对文本文件中的完整帧感兴趣,只是第一部分。在这里,您可以定义要导入的帧开头的数据量。如果将其保持打开状态,则将最大值设置为256kiB。
设置完所有输入和导入参数后,单击“
完成后,将有一个新的捕获文件加载从文本文件导入的帧。
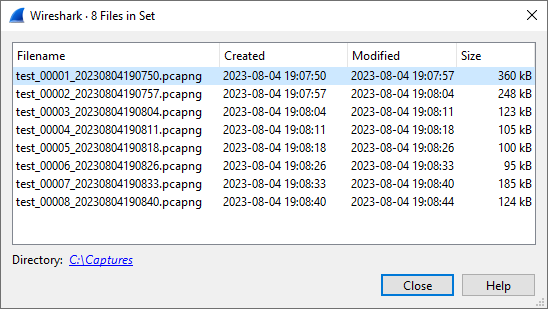
在执行捕获时使用“多个文件”选项时(请参阅: 第4.11节“捕获文件和文件模式”),捕获数据分布在多个捕获文件(称为文件集)上。
由于使用手动设置文件会变得很繁琐,因此Wireshark提供了一些方便处理这些文件集的功能。
- “列表文件”对话框将列出Wireshark已识别为当前文件集的一部分的文件。
Wireshark提供了几种导出数据包数据的方式和格式。本节介绍从Wireshark主应用程序导出数据的一般方法。有更多专门的函数可以导出其他地方描述的特定数据。
将数据包数据导出为纯ASCII文本文件,非常类似于打印数据包的格式。
|
小费 |
|---|---|
|
如果您希望能够从纯文本文件导入任何以前导出的数据包,建议您:
|

- “导出到文件:”框选择要将数据包数据导出到的文件。
- “分组范围”帧在第5.9节 “分组范围”帧中描述。
- “分组详细信息”帧在第5.10节“分组格式帧”中描述。

- 导出到文件:框架选择要将数据包数据导出到的文件。
- 该包范围帧中描述第5.9节,“该‘包范围’帧”。
- 所述包详情帧中描述第5.10节,“包格式帧”。
将数据包摘要导出为CSV,例如通过电子表格程序用于导入数据。
- 导出到文件:框架选择要将数据包数据导出到的文件。
- 该包范围帧中描述第5.9节,“该‘包范围’帧”。
将数据包字节导出到C数组中,以便将流数据导入到您自己的C程序中。
- 导出到文件:框架选择要将数据包数据导出到的文件。
- 该包范围帧中描述第5.9节,“该‘包范围’帧”。
将数据包数据导出到PSML中。这是一种基于XML的格式,仅包含数据包摘要。PSML文件规范可从以下网址获得:http://www.nbee.org/doku.php?id = netpdl:psml_specification 。

- 导出到文件:框架选择要将数据包数据导出到的文件。
- 该包范围帧中描述第5.9节,“该‘包范围’帧”。
PSML导出不包含数据包详细信息帧,因为数据包格式是由PSML规范定义的。
将数据包数据导出为PDML。这是一种基于XML的格式,包括数据包详细信息。PDML文件规范可从以下网址获得:http://www.nbee.org/doku.php?id = netpdl: pdml_specification。
|
注意 |
|---|---|
|
PDML规范尚未正式发布,Wireshark的实现仍处于早期测试状态,因此请期待未来Wireshark版本的更改。 |

- 导出到文件:框架选择要将数据包数据导出到的文件。
- 该包范围帧中描述第5.9节,“该‘包范围’帧”。
PDML导出不包含数据包详细信息框架,因为数据包格式是由PDML规范定义的。
将“Packet Bytes”窗格中选择的字节导出为原始二进制文件。
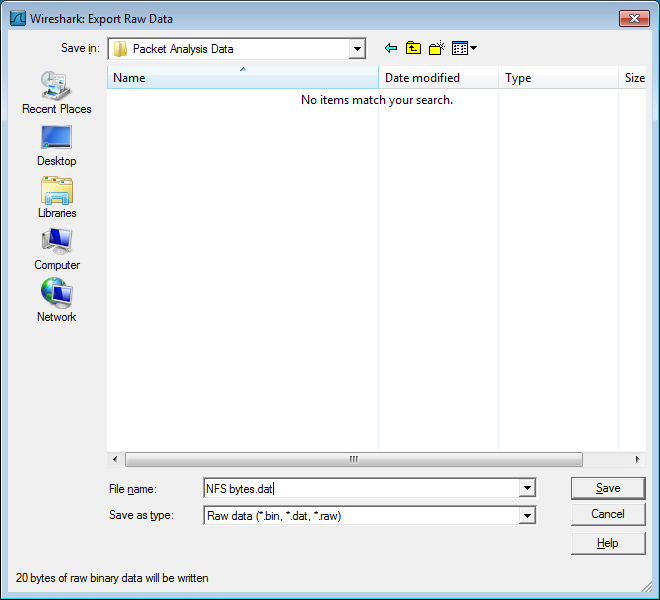
- 名称:将数据包数据导出到的文件名。
- “ 保存在文件夹:”字段允许您选择要保存到的文件夹(来自某些预定义文件夹)。
- 浏览其他文件夹提供了一种灵活的方式来选择文件夹。
此功能扫描当前打开的捕获文件中所选协议的流或运行捕获,并允许用户将重组的对象导出到磁盘。例如,如果选择HTTP,则可以将HTML文档,图像,可执行文件以及通过HTTP传输的任何其他文件导出到磁盘。如果您正在运行捕获,则此列表会每隔几秒自动更新,并显示任何新对象。然后可以独立于Wireshark打开或检查保存的对象。
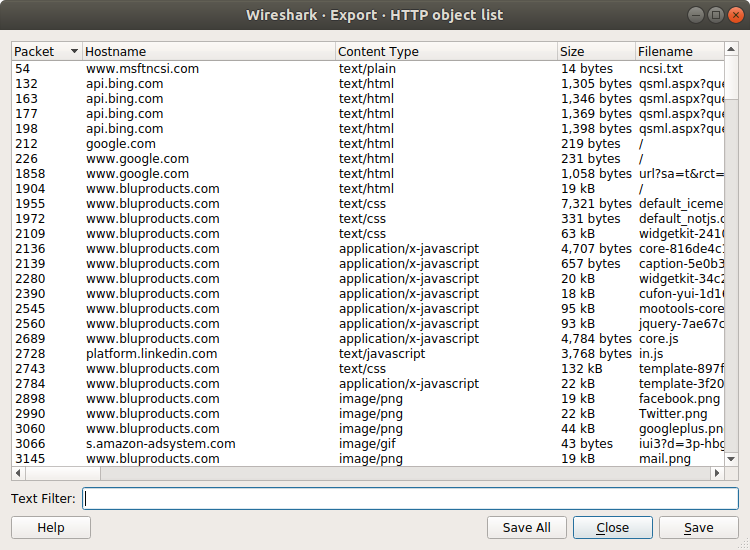
列:
- 数据包:找到此对象的数据包编号。在某些情况下,同一个数据包中可能有多个对象。
- 主机名:发送此对象的服务器的主机名。
- 内容类型:此对象的内容类型。
- 大小:此对象的大小(以字节为单位)。
- 文件名:此对象的文件名。每个协议生成不同的文件名。例如,HTTP使用URI的最后部分,IMF使用电子邮件的主题。
输入:
- 文本过滤器:仅显示包含指定文本字符串的对象。
- 帮助:打开用户指南中的“导出对象”部分。
- 全部保存:使用文件名列中的文件名保存所有对象(包括未显示的对象)。系统将询问您将目录/文件夹保存在哪个目录/文件夹中。
- 关闭:关闭“导出对象”对话框。
- 保存:将当前选定的对象保存为您指定的文件名。要保存的默认文件名取自对象列表的文件名列。
要打印包,选择

- “打印”对话框中提供以下字段:打印机
-
该字段包含一对互斥的单选按钮:
- 纯文本指定数据包打印应采用纯文本格式。
- PostScript指定数据包打印过程应使用PostScript在PostScript识别打印机上生成更好的打印输出。
-
输出到文件:指定使用在字段中输入的文件或使用浏览按钮选择对文件进行打印。
此字段是在其中输入文件打印到,如果你选择了打印到文件,或者你可以点击按钮来浏览文件系统。如果未选择“打印到文件”,则显示为灰色。
-
Print命令指定用于打印的命令。
![[注意]]()
注意! 这些打印命令字段在Windows平台上不可用。
该字段指定用于打印的命令。这通常是
lpr。如果需要打印到默认队列以外的队列,则可以将其更改为指定特定队列。一个例子可能是:$ lpr -Pmypostscript如果在上面检查输出到文件:,则此字段显示为灰色。
- 包范围
- 选择要打印的数据包,请参见第5.9节“分组范围”帧“
- 包格式
- 选择要打印的数据包的输出格式。您可以选择打印每个数据包的方式,请参见图5.17“数据包格式”帧“
包范围帧是各种输出相关对话框的一部分。它提供了选择输出功能应处理哪些数据包的选项。

如果设置了
- 所有数据包都将处理所有数据包
- 所选数据包仅处理所选数据包。
- 标记的数据包仅处理标记的数据包。
- 从第一个到最后一个标记的数据包处理从第一个到最后一个标记的数据包。
- 指定数据包范围进程用户指定的数据包范围,例如指定 5,10-15,20-将处理数据包编号5,数据包编号从十到十五(包括),每个数据包从数字二十到结束捕获。
包格式帧是各种输出相关对话框的一部分。它提供了选择数据包的哪些部分应用于输出功能的选项。

- 数据包摘要行启用摘要行的输出,就像在“数据包列表”窗格中一样。
- 数据包详细信息启用数据包详细信息树的输出。
- 全部折叠了“全部折叠”状态下“数据包详细信息”窗格中的信息。
- 显示当前状态下“数据包详细信息”窗格中的信息。
- 所有扩展了“全部展开”状态下“数据包详细信息”窗格中的信息。
- 数据包字节启用数据包字节的输出,就像在“数据包字节”窗格中一样。
- 新页面上的每个数据包都将每个数据包放在一个单独的页面上(例如,当保存/打印到文本文件时,这将在数据包之间放置一个换页符)。
目录
捕获一些数据包或打开以前保存的捕获文件后,只需单击数据包列表窗格中的数据包即可查看数据包列表窗格中显示的数据包,这将显示数据包列表窗格中的数据包。树视图和字节视图窗格。
然后,您可以展开树的任何部分,以查看每个数据包中每个协议的详细信息。单击树中的项目将突出显示字节视图中的相应字节。选择了TCP数据包的示例如图6.1“选择用于查看的TCP数据包的Wireshark”所示。它还在所选的TCP标头中具有确认编号,该编号在字节视图中显示为所选字节。

如果在“捕获首选项”对话框中选择“实时更新数据包列表”,则还可以在Wireshark捕获时以相同方式选择和查看数据包。
此外,您可以在单独的窗口中查看单个数据包, 如图6.2“在单独的窗口中查看数据包”所示。您可以通过双击数据包列表中的项目或在数据包列表窗格中选择您感兴趣的数据包并
除了双击数据包列表并使用主菜单外,还有许多其他方法可以打开新的数据包窗口:
- 按住shift键并双击数据包详细信息中的帧链接。
- 从表6.2,“数据包列表”弹出菜单的菜单项“。
- 从表6.3,“分组详细信息”弹出菜单的菜单项“。
您可以通过在相应项目上单击鼠标右键,在“数据包列表”,其列标题,“数据包详细信息”或“数据包字节”上打开弹出菜单。

下表概述了此标题中可用的功能,在主菜单中查找相应功能的位置以及每个项目的说明。

下表概述了此窗格中可用的功能,在主菜单中查找相应功能的位置以及每个项目的简短说明。
表6.2。“数据包列表”弹出菜单的菜单项
| 项目 | 对应的主菜单项 | 描述 |
|---|---|---|
|
|
|
标记或取消标记数据包。 |
|
|
|
在剖析捕获文件时忽略或检查此数据包。 |
|
|
|
设置或重置时间参考。 |
|
|
|
打开“时间转换”对话框,该对话框允许您调整部分或全部数据包的时间戳。 |
|
|
|
打开“数据包注释”对话框,该对话框允许您向单个数据包添加注释。请注意,保存数据包注释的能力取决于您的文件格式。例如pcapng支持注释,pcap不支持。 |
|
|
允许您输入要为所选地址解析的名称。 |
|
|
|
|
根据当前选定的项目准备并应用显示过滤器。 |
|
|
|
根据当前选定的项目准备显示过滤器。 |
|
|
此菜单项应用显示过滤器,其中包含来自所选数据包的地址信息。例如,IP菜单条目将设置过滤器以显示当前数据包的两个IP地址之间的流量。 |
|
|
|
此菜单项使用显示过滤器,其中包含来自所选数据包的地址信息,以构建新的着色规则。 |
|
|
|
允许您分析和准备此SCTP关联的过滤器。 |
|
|
|
|
此菜单项将显示一个单独的窗口,并显示捕获的与所选数据包位于同一TCP连接上的所有TCP段,请参见第7.2节“遵循协议流” |
|
|
|
与“跟随TCP流”相同的功能,但对于“UDP”流。 |
|
|
|
与“跟随TCP流”功能相同,但适用于TLS或SSL流。有关提供TLS密钥的说明,请参阅SSL上的Wiki页面。 |
|
|
|
与“跟随TCP流”功能相同,但适用于HTTP流。 |
|
|
将显示的摘要字段作为制表符分隔文本复制到剪贴板。 |
|
|
|
将显示的摘要字段以逗号分隔的文本复制到剪贴板。 |
|
|
|
将显示的摘要字段作为YAML数据复制到剪贴板。 |
|
|
|
根据当前选定的项目准备显示过滤器,并将该过滤器复制到剪贴板。 |
|
|
|
将数据包字节以完整的“hexdump”格式复制到剪贴板。 |
|
|
|
将数据包字节以“hexdump”格式复制到剪贴板,不带ASCII部分。 |
|
|
|
将数据包字节作为ASCII文本复制到剪贴板,不包括不可打印的字符。 |
|
|
|
将数据包字节复制到剪贴板,作为未经调整的十六进制数字列表。 |
|
|
|
将包字节作为原始二进制文件复制到剪贴板。使用MIME类型“application / octet-stream”将数据存储在剪贴板中。 |
|
|
|
调整所选协议的首选项。 |
|
|
|
|
改变或应用两个解剖器之间的新关系。 |
|
|
|
在单独的窗口中显示选定的数据包。单独的窗口仅显示数据包详细信息和字节。有关详细信息,请参见图6.2“在单独的窗口中查看数据包”。 |

下表概述了此窗格中可用的功能,在主菜单中查找相应功能的位置以及每个项目的简短说明。
表6.3。“数据包详细信息”弹出菜单的菜单项
| 项目 | 对应的主菜单项 | 描述 |
|---|---|---|
|
|
|
展开当前选定的子树。 |
|
|
|
折叠当前选定的子树。 |
|
|
|
展开捕获中所有数据包中的所有子树。 |
|
|
|
Wireshark保留了所有扩展的协议子树的列表,并使用它来确保在显示数据包时扩展正确的子树。此菜单项折叠捕获列表中所有数据包的树视图。 |
|
|
使用所选协议项在数据包列表中创建新列。 |
|
|
|
|
根据当前选定的项目准备并应用显示过滤器。 |
|
|
|
根据当前选定的项目准备显示过滤器。 |
|
|
此菜单项使用显示过滤器,其中包含来自所选协议项的信息,以构建新的着色规则。 |
|
|
|
|
此菜单项将显示一个单独的窗口,并显示捕获的与所选数据包位于同一TCP连接上的所有TCP段,请参见第7.2节“遵循协议流” |
|
|
|
与“跟随TCP流”相同的功能,但对于“UDP”流。 |
|
|
|
与“跟随TCP流”功能相同,但适用于TLS或SSL流。有关提供TLS密钥的说明,请参阅SSL上的Wiki页面。 |
|
|
|
与“跟随TCP流”功能相同,但适用于HTTP流。 |
|
|
|
复制显示的数据包详细信息。 |
|
|
|
复制显示的选定数据包详细信息及其子项。 |
|
|
|
将所选字段的显示文本复制到系统剪贴板。 |
|
|
|
将所选字段的名称复制到系统剪贴板。 |
|
|
|
将所选字段的值复制到系统剪贴板。 |
|
|
|
根据当前选定的项目准备显示过滤器并将其复制到剪贴板。 |
|
|
将数据包字节以完整的“hexdump”格式复制到剪贴板。 |
|
|
|
将数据包字节以“hexdump”格式复制到剪贴板,不带ASCII部分。 |
|
|
|
将数据包字节作为ASCII文本复制到剪贴板,不包括不可打印的字符。 |
|
|
|
将数据包字节复制到剪贴板,作为未经调整的十六进制数字列表。 |
|
|
|
将包字节作为原始二进制文件复制到剪贴板。使用MIME类型“application / octet-stream”将数据存储在剪贴板中。 |
|
|
|
将数据包字节作为C样式转义序列复制到剪贴板。 |
|
|
|
|
此菜单项与同名的“文件”菜单项相同。它允许您将原始数据包字节导出到二进制文件。 |
|
|
在Web浏览器中显示与当前所选协议对应的Wiki页面。 |
|
|
|
在Web浏览器中显示与当前所选协议对应的过滤器字段引用网页。 |
|
|
|
调整所选协议的首选项。 |
|
|
|
|
改变或应用两个解剖器之间的新关系。 |
|
|
|
如果所选字段具有相应的数据包,例如DNS响应的匹配请求,请转到该数据包。 |
|
|
|
如果所选字段具有相应的数据包(例如DNS响应的匹配请求),则在单独的窗口中显示所选数据包。有关详细信息,请参见图6.2“在单独的窗口中查看数据包”。 |

下表概述了此窗格中可用的功能以及每个项目的简短说明。
表6.4。“数据包字节”弹出菜单的菜单项
| 项目 | 描述 |
|---|---|
|
|
将数据包字节以完整的“hexdump”格式复制到剪贴板。 |
|
|
将数据包字节以“hexdump”格式复制到剪贴板,不带ASCII部分。 |
|
|
将数据包字节作为ASCII文本复制到剪贴板,不包括不可打印的字符。 |
|
|
将数据包字节复制到剪贴板,作为未经调整的十六进制数字列表。 |
|
|
将包字节作为原始二进制文件复制到剪贴板。使用MIME类型“application / octet-stream”将数据存储在剪贴板中。 |
|
|
将数据包字节作为C样式转义序列复制到剪贴板。 |
|
|
将字节数据显示为十六进制数字。 |
|
|
将字节数据显示为二进制数字。 |
|
|
用文本显示“hexdump”数据。 |
|
|
显示“hexdump”文本时使用ASCII编码。 |
|
|
显示“hexdump”文本时使用EBCDIC编码。 |
Wireshark有两种过滤语言:一种用于捕获数据包,一种用于显示数据包。在本节中,我们将探讨第二种类型的过滤器:显示过滤器。第一部分已经在 第4.13节“捕获时过滤”中进行了处理。
显示过滤器允许您专注于您感兴趣的数据包,同时隐藏当前不感兴趣的数据包。它们允许您通过以下方式选择包:
- 协议
- 场的存在
- 字段的值
- 字段之间的比较
- ......还有更多!
要根据协议类型选择数据包,只需在Wireshark窗口的过滤器工具栏中的Filter:字段中键入您感兴趣的协议,然后按Enter启动过滤器。图6.7“过滤TCP协议”显示了在过滤器字段中键入tcp时发生的情况的示例。
|
注意 |
|---|---|
|
所有协议和字段名称都以小写形式输入。此外,输入过滤器表达式后,请不要忘记按Enter键。 |

您可能已经注意到,现在只显示TCP协议的数据包(例如,数据包1-10被隐藏)。数据包编号将保持原样,因此显示的第一个数据包现在是数据包编号11。
|
注意 |
|---|---|
|
使用显示过滤器时,所有数据包都保留在捕获文件中。显示过滤器仅更改捕获文件的显示,但不更改其内容! |
您可以过滤Wireshark理解的任何协议。您还可以过滤解剖器添加到树视图的任何字段,但前提是解剖器已添加字段的缩写。这样的字段列表可在Wireshark的在添加表达式......对话框。你可以找到更多信息添加表达式...在对话框中第6.5节“的‘过滤器表达式’对话框的”。
例如,要将数据包列表窗格缩小到只有那些进出IP地址192.168.0.1的数据包,请使用ip.addr==192.168.0.1。
|
注意 |
|---|---|
|
要删除过滤器,请单击过滤器字段右侧的“ |
Wireshark提供了一种简单但功能强大的显示过滤器语言,允许您构建非常复杂的过滤器表达式。您可以比较数据包中的值以及将表达式组合成更具体的表达式。以下部分提供了有关执行此操作的详细信息。
|
小费 |
|---|---|
|
您可以在Wireshark Wiki显示过滤器页面上找到许多显示过滤器示例:https://wiki.wireshark.org/DisplayFilters。 |
您可以构建使用许多不同比较运算符比较值的显示过滤器。它们显示在表6.5“显示过滤器比较运算符”中。
|
小费 |
|---|---|
|
您可以以相同的方式使用英语和类似C的术语,甚至可以将它们混合在一个过滤字符串中。 |
表6.5。显示过滤比较运算符
| 英语 | 类似C | 描述和示例 |
|---|---|---|
|
EQ |
== |
等于。 |
|
不 |
!= |
不相等。 |
|
GT |
> |
比...更棒。 |
|
恩 |
< |
少于。 |
|
ge |
> = |
大于或等于。 |
|
le |
<= |
小于或等于。 |
|
包含 |
协议,字段或切片包含值。 |
|
|
火柴 |
~ |
协议或文本字段匹配Perl regualar表达式。 |
|
bitwise_and |
& |
比较位字段值。 |
此外,所有协议字段都有一个类型。显示过滤器字段类型提供了类型列表以及如何表达它们的示例。
显示过滤字段类型
- 无符号整数
-
可以是8位,16位,24位,32位或64位。您可以用十进制,八进制或十六进制表示整数。以下显示过滤器是等效的:
ip.len和1500ip.len和02734ip.len位于0x5dc - 有符号整数
- 可以是8位,16位,24位,32位或64位。与无符号整数一样,您可以使用十进制,八进制或十六进制。
- 布尔
-
仅当协议解码的值为真时,才会在协议解码中出现布尔字段。例如,
tcp.flags.syn仅当SYN标志出现在TCP段头中时,才存在,因此也是如此。过滤器表达式`tcp.flags.syn`将仅选择 存在此标志的数据包,即段头包含 SYN标志的TCP段。同样,要查找源路由令牌环数据包,请使用过滤器 表达式`tr.sr`。 - 以太网地址
-
6个字节用冒号(:),点(。)或短划线( - )分隔,在分隔符之间有一个或两个字节:
eth.dst == ff:ff:ff:ff:ff:ffeth.dst == ff-ff-ffeth.dst == ffff.ffff.ffff - IPv4地址
-
ip.addr == 192.168.0.1
无类别域间路由(CIDR)表示法可用于测试 IPv4地址是否在特定子网中。例如,此显示 过滤器将查找129.111 Class-B网络中的所有数据包:ip.addr == 129.111.0.0/16 - IPv6地址
-
ipv6.addr == ::1与IPv4地址一样,IPv6地址可以匹配子网。 - 文字字符串
http.request.uri == "https://www.wireshark.org/"
udp包含81:60:03
上面的示例匹配UDP头或有效负载中任何位置包含3字节序列0x81,0x60,0x03的数据包。
sip.To包含“a1762”
以上示例匹配数据包,其中SIP To-header在标头中的任何位置包含字符串“a1762”。
http.host匹配“acme \。(org | com | net)”
上面的示例匹配HTTP数据包,其中HOST头包含acme.org或acme.com或acme.net。比较不区分大小写。注意:Wireshark需要使用libpcre构建才能使用matchesresp。~运营商。
tcp.flags&0x02
该表达式将匹配包含“tcp.flags”字段的所有数据包与0x02位,即SYN位置位。
您可以使用表6.6“显示过滤器逻辑操作”中显示的逻辑运算符在Wireshark中组合过滤器表达式
Wireshark允许您以相当精细的方式选择序列的子序列。在标签之后,您可以放置一对括号[],其中包含逗号分隔的范围说明符列表。
eth.src [0:3] == 00:00:83
上面的示例使用n:m格式指定单个范围。在这种情况下,n是起始偏移量,m是指定范围的长度。
eth.src [1-2] == 00:83
上面的示例使用nm格式指定单个范围。在这种情况下,n是起始偏移量,m是结束偏移量。
eth.src [:4] == 00:00:83:00
上面的例子使用:m格式,它从序列的开头到偏移量m取得所有内容。它相当于0:m
eth.src [4:] == 20:20
上面的例子使用n:格式,它接收从偏移量n到序列末尾的所有内容。
eth.src [2] == 83
上面的示例使用n格式指定单个范围。在这种情况下,选择偏移量n的序列中的元素。这相当于n:1。
eth.src [0:3,1-2,:4,4:,2] ==
00:00:83:00:83:00:00:83:00:20:20:83
Wireshark允许您将逗号分隔列表中的单个范围串在一起,以形成如上所示的复合范围。
Wireshark允许您测试字段以获取一组值或字段中的成员资格。在字段名称之后,使用in运算符,后跟括号{}包围的设置项。
{80 443 8080}中的tcp.port
这可以被认为是一个快捷操作符,因为前面的表达式可能表示为:
tcp.port == 80 || tcp.port == 443 || tcp.port == 8080
值集还可以包含范围:
{443 4430..4434}中的tcp.port
这不仅仅是一条捷径tcp.port == 443 || (tcp.port >= 4430 && tcp.port ⇐ 4434)。当任何字段与过滤器匹配时,通常会满足比较运算符,因此具有端口80和56789的数据包将匹配此备用显示过滤器,因为它56789 >= 4430 && 80 ⇐ 4434是真的。会员运营商改为针对范围条件测试相同的字段。
集合不仅限于数字,也可以使用其他类型:
{{HEAD“”GET“}中的
http.request.method } {10.0.0.5 10.0.0.9 192.168.1.1..192.168.1.9}
{10 .. 10.5}中的frame.time_delta中的ip.addr
显示过滤器语言具有许多转换字段的功能,请 参见表6.7“显示过滤器功能”。
表6.7。显示过滤器功能
| 功能 | 描述 |
|---|---|
|
上 |
将字符串字段转换为大写。 |
|
降低 |
将字符串字段转换为小写。 |
|
只 |
返回字符串或字节字段的字节长度。 |
|
计数 |
返回帧中的字段出现次数。 |
|
串 |
将非字符串字段转换为字符串。 |
该upper和lower功能可用于强制不区分大小写的匹配: lower(http.server) contains "apache"。
查找具有长请求URI的HTTP请求:len(http.request.uri) > 100。请注意,该len函数产生的字符串长度以字节为单位,而不是(多字节)字符。
通常,IP帧只有两个地址(源和目标),但在ICMP错误或隧道传输的情况下,单个数据包可能包含更多地址。可以找到这些数据包count(ip.addr) > 2。
该string函数将字段值转换为字符串,适用于“匹配”或“包含”等运算符。整数字段将转换为其十进制表示形式。它可以与IP /以太网地址(以及其他地址)一起使用,但不能与字符串或字节字段一起使用。
例如,要匹配奇数帧数:
string(frame.number)匹配“[13579] $”
匹配子网块(172.16到172.31)中以255结尾的IP地址:
string(ip.dst)匹配“^ 172 \。(1 [6-9] | 2 [0-9] | 3 [0-1])\ .. {1,3} \。255”
在eth.addr,ip.addr,tcp.port和udp.port等组合表达式上使用!=运算符可能无法按预期工作。当您使用它时,Wireshark将显示警告“”!=“已弃用或可能有意外结果”。
通常人们使用过滤字符串来显示类似于ip.addr == 1.2.3.4 显示包含IP地址1.2.3.4的所有数据包的内容。
然后他们ip.addr != 1.2.3.4用来查看所有不包含IP地址1.2.3.4的数据包。不幸的是,这并没有做预期。
相反,对于源或目标IP地址等于1.2.3.4的数据包,该表达式甚至也适用。原因是表达式ip.addr != 1.2.3.4必须读作“数据包包含名为ip.addr的字段,其值不同于1.2.3.4”。由于IP数据报包含源地址和目标地址,因此只要两个地址中的至少一个与1.2.3.4不同,表达式就会计算为真。
如果你想要过滤掉所有包含IP数据报到IP地址1.2.3.4的数据包,那么正确的过滤器就是!(ip.addr == 1.2.3.4)它的内容“向我展示一个名为ip.addr的字段不存在的所有数据包。值为1.2.3.4“,换句话说,”过滤掉所有没有出现名为ip.addr且值为1.2.3.4的字段的数据包“。
随着协议的发展,它们有时会改变名称或被更新的标准所取代。例如,DHCP扩展并且已经在很大程度上取代了BOOTP,而TLS已经取代了SSL。如果协议解析器最初使用旧名称和字段作为协议,Wireshark开发团队可能会更新它以使用更新的名称和字段。在这种情况下,他们会将旧协议名称中的别名添加到新协议名称中,以便更轻松地进行转换。
例如,DHCP解析器最初是为BOOTP协议开发的,但是从Wireshark 3.0开始,所有“bootp”显示过滤器字段都被重命名为它们的“dhcp”等价物。您仍然可以暂时使用旧的过滤器名称,例如“bootp.type”等同于“dhcp.type”但Wireshark将显示警告“”bootp.type“已弃用或可能具有意外结果”它。将来可能会删除对已弃用字段的支持。
当您习惯使用Wireshark的过滤系统并知道您希望在过滤器中使用哪些标签时,只需键入过滤字符串即可。但是,如果您是Wireshark的新手,或者正在使用稍微不熟悉的协议,那么尝试找出要键入的内容可能会非常混乱。“过滤器表达式”对话框有助于此。
|
小费 |
|---|---|
|
“过滤器表达式”对话框是学习如何编写Wireshark显示过滤器字符串的绝佳方法。 |
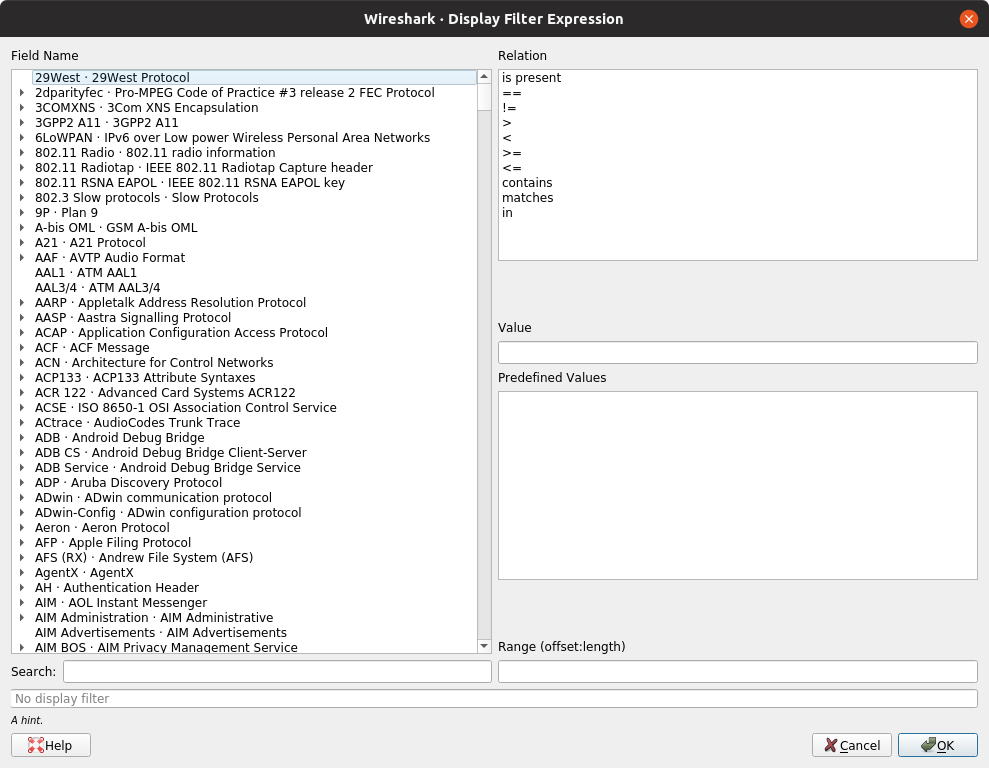
首次打开“过滤器表达式”对话框时,将显示一个按协议组织的字段名称树,以及一个用于选择关系的框。
- 字段名称
- 从协议字段树中选择协议字段。具有可过滤字段的每个协议都列在顶层。(您可以通过输入协议名称的前几个字母来搜索特定的协议条目)。通过扩展协议名称,您可以获得可用于过滤该协议的字段名称列表。
- 关系
- 从可用关系列表中选择一个关系。的是本是一个一元关系,如果所选择的字段存在于包这是真实的。所有其他列出的关系都是二元关系,需要额外的数据(例如匹配的值)才能完成。
当您从字段名称列表中选择一个字段并选择二元关系(例如等式关系==)时,您将有机会输入一个值,并可能输入一些范围信息。
- 值
- 您可以在“ 值”文本框中输入适当的值。该值也将指示值的类型字段名称您选择(如字符串)。
- 预定义的值
- 某些协议字段具有可用的预定义值,非常类似于C中的枚举。如果所选协议字段已定义了此类值,则可以在此处选择其中一个。
- 范围
- 一系列整数或一组范围,例如
1-12或39-42,98-2000。 - 好
- 构建满意的表达式后,单击“
- 取消
- 单击“
您可以使用Wireshark定义过滤器并为其提供标签供以后使用。这可以节省记住和重新键入您使用的一些更复杂的过滤器的时间。
要定义一个新的过滤器或编辑现有的,选择
定义和保存捕获过滤器和显示过滤器的机制几乎相同。这两个都将在这里描述,但这两者之间的差异将被标记为这样。
|
警告 |
|---|---|
|
您必须使用“ |

- 新
- 此按钮可将新过滤器添加到过滤器列表中。将使用当前从过滤器名称和过滤器字符串输入的值。如果这些字段中的任何一个为空,则将其设置为“new”。
- 删除
- 此按钮删除选定的过滤器。如果未选择过滤器,它将显示为灰色。
- 过滤
- 您可以从此列表中选择一个过滤器(将在对话框底部的字段中填写过滤器名称和过滤器字符串)。
- 过滤器名称:
-
您可以在此处更改当前所选过滤器的名称。
过滤器名称将仅在此对话框中用于识别过滤器以方便您使用,不会在其他地方使用。您可以添加多个具有相同名称的过滤器,但这不是很有用。
- 过滤字符串:
- 您可以在此处更改当前所选过滤器的过滤字符串。仅显示过滤器:键入时将对语法字符串进行语法检查。
- 添加表情......
- 仅显示过滤器:此按钮显示“添加表达式”对话框,该对话框有助于构建过滤器字符串。您可以在第6.5节“过滤器表达式”对话框中找到有关“添加表达式”对话框的更多信息。
- 好
- 仅显示过滤器:此按钮将选定的过滤器应用于当前显示并关闭对话框。
- 应用
- 仅显示过滤器:此按钮将选定的过滤器应用于当前显示,并使对话框保持打开状态。
- 保存
- 在此对话框中保存当前设置。附录B,文件和文件夹中说明了文件位置和格式。
- 关
- 关闭此对话框。这将丢弃未保存的设置。
捕获一些数据包或读取先前保存的捕获文件后,您可以轻松找到数据包。只需选择

您可以使用以下标准进行搜索:
- 显示过滤器
-
在文本输入字段中输入显示过滤器字符串,然后单击“
ip.src == 192.168.0.1和tcp.flags.syn == 1键入时将检查要查找的值。如果您的值的语法检查成功,输入字段的背景将变为绿色,如果失败,它将变为红色。有关更多详细信息,请参见第6.3节“查看时筛选数据包”
- 十六进制值
-
在分组数据中搜索特定的字节序列。
例如,使用“ef:bb:bf”查找包含UTF-8字节顺序标记的下一个数据包 。
- 串
- 使用各种选项在分组数据中查找字符串。
- 正则表达式
- 使用与Perl兼容的正则表达式搜索数据包数据。PCRE模式超出了本文档的范围,但在您最喜爱的搜索引擎中键入“pcre test”应返回一些可帮助您测试和探索表达式的网站。
您可以使用“

如果选择了指向捕获文件中另一个数据包的协议字段,则此命令将跳转到该数据包。
由于这些协议字段现在像链接一样工作(就像在Web浏览器中一样),只需双击字段即可跳转到相应的字段。
您可以在“数据包列表”窗格中标记数据包。无论设置了着色规则,标记的数据包都将以黑色背景显示。标记数据包对于稍后在大型捕获文件中进行分析时找到它很有用。
数据包标记不存储在捕获文件中或其他任何位置。关闭捕获文件时,所有数据包标记都将丢失。
保存,导出或打印时,可以使用数据包标记来控制数据包的输出。为此,可以使用数据包范围中的选项,请参见第5.9节“数据包范围”帧“。
有三个函数可以操作数据包的标记状态:
- 标记数据包(切换)切换单个数据包的标记状态。
- 标记所有显示的数据包设置所有显示数据包的标记状态。
- 取消标记所有数据包重置所有数据包的标记状态。
这些标记功能可从“编辑”菜单中获得,“标记包(切换)”功能也可从“数据包列表”窗格的弹出菜单中获得。
您可以忽略“数据包列表”窗格中的数据包。然后,Wireshark会假装捕获文件中不存在此数据包。无论设置了着色规则,忽略的数据包都将显示为白色背景和灰色前景。
数据包忽略标记不存储在捕获文件中或其他任何位置。关闭捕获文件时,所有“数据包忽略”标记都将丢失。
有三个函数可以处理数据包的被忽略状态:
- 忽略数据包(切换)切换单个数据包的被忽略状态。
- 忽略所有显示的数据包设置所有显示数据包的忽略状态。
- 取消忽略所有数据包重置所有数据包的忽略状态。
这些忽略功能可从“编辑”菜单中获得,“忽略数据包(切换)”功能也可从“数据包列表”窗格的弹出菜单中获得。
在捕获数据包时,每个数据包都带有时间戳。这些时间戳将保存到捕获文件中,以便以后分析。
有关时间戳,时区等的详细说明,请参见: 第7.6节“时间戳”。
可以使用“视图”菜单选择时间戳表示格式和数据包列表中的精度,请参见图3.5“”视图“菜单”。
可用的演示文稿格式为:
- 日期和时间:1970-01-01 01:02:03.123456捕获数据包的一天的绝对日期和时间。
- Time of Day:01:02:03.123456捕获数据包的绝对时间。
- 自捕获开始以来的秒数:123.123456相对于捕获文件的开始时间或此数据包之前的第一个“时间参考”的时间(请参见第6.12.1节“数据包时间参考”)。
- 自上一个捕获数据包以来的秒数:1.123456相对于先前捕获的数据包的时间。
- 自上一个显示的数据包以来的秒数:1.123456相对于先前显示的数据包的时间。
- 自大纪元以来的秒数(1970-01-01):1234567890.123456相对于纪元的时间(1970年1月1日午夜UTC)。
可用的精度(也就是显示的小数位数)是:
- 自动将使用加载的捕获文件格式的时间戳精度(默认值)。
- 秒,十秒,厘秒,毫秒,微秒或纳秒时间戳精度将强制为给定设置。如果实际可用的精度较小,则将附加零。如果精度较大,则剩余的小数位将被切断。
精度示例:如果您有时间戳并使用“Seconds Since Previous Packet”显示,则该值可能为1.123456。这将使用libpcap文件的“自动”设置(以微秒为单位)显示。如果你使用秒,它将只显示1,如果你使用纳秒,它显示1.123456000。
用户可以设置对数据包的时间参考。时间参考是所有后续数据包时间计算的起点。如果要查看相对于特殊数据包的时间值(例如新请求的开始),将会很有用。可以在捕获文件中设置多个时间参考。
时间参考不会永久保存,并且在您关闭捕获文件时将丢失。
仅当时间显示格式设置为“自捕获开始后的秒数”时,时间参考才有用。如果使用其他时间显示格式之一,则时间参考将不起作用(并且也没有意义)。
要使用时间参考,请
- 设置时间参考(切换)将当前所选数据包的时间参考状态切换为打开或关闭。
- 查找下一个在“数据包列表”窗格中查找下一次引用的数据包。
- 查找上一个在“数据包列表”窗格中查找上一次引用的数据包。

时间引用的数据包将在时间列中标记字符串* REF *(请参阅数据包编号10)。所有后续数据包将显示自上次时间参考以来的时间。
以应用层看到协议的方式查看协议会非常有帮助。也许您正在寻找Telnet流中的密码,或者您正在尝试理解数据流。也许您只需要一个显示过滤器来仅显示TLS或SSL流中的数据包。如果是这样,Wireshark遵循协议流的能力将对您有用。
只需在您感兴趣的流/连接的数据包列表中选择TCP,UDP,TLS或HTTP数据包,然后从Wireshark工具菜单中选择Follow TCP Stream菜单项(或使用数据包列表中的上下文菜单) 。Wireshark将设置一个适当的显示过滤器并弹出一个对话框,其中包含按顺序排列的TCP流中的所有数据,如图7.1“跟随TCP流”对话框所示。
|
小费 |
|---|---|
|
在协议流之后应用显示过滤器,其选择当前流中的所有分组。有些人打开“关注TCP流”对话框并立即关闭它作为隔离特定流的快速方法。如果不需要此行为,则使用“后退”按钮关闭对话框将重置显示过滤器。 |
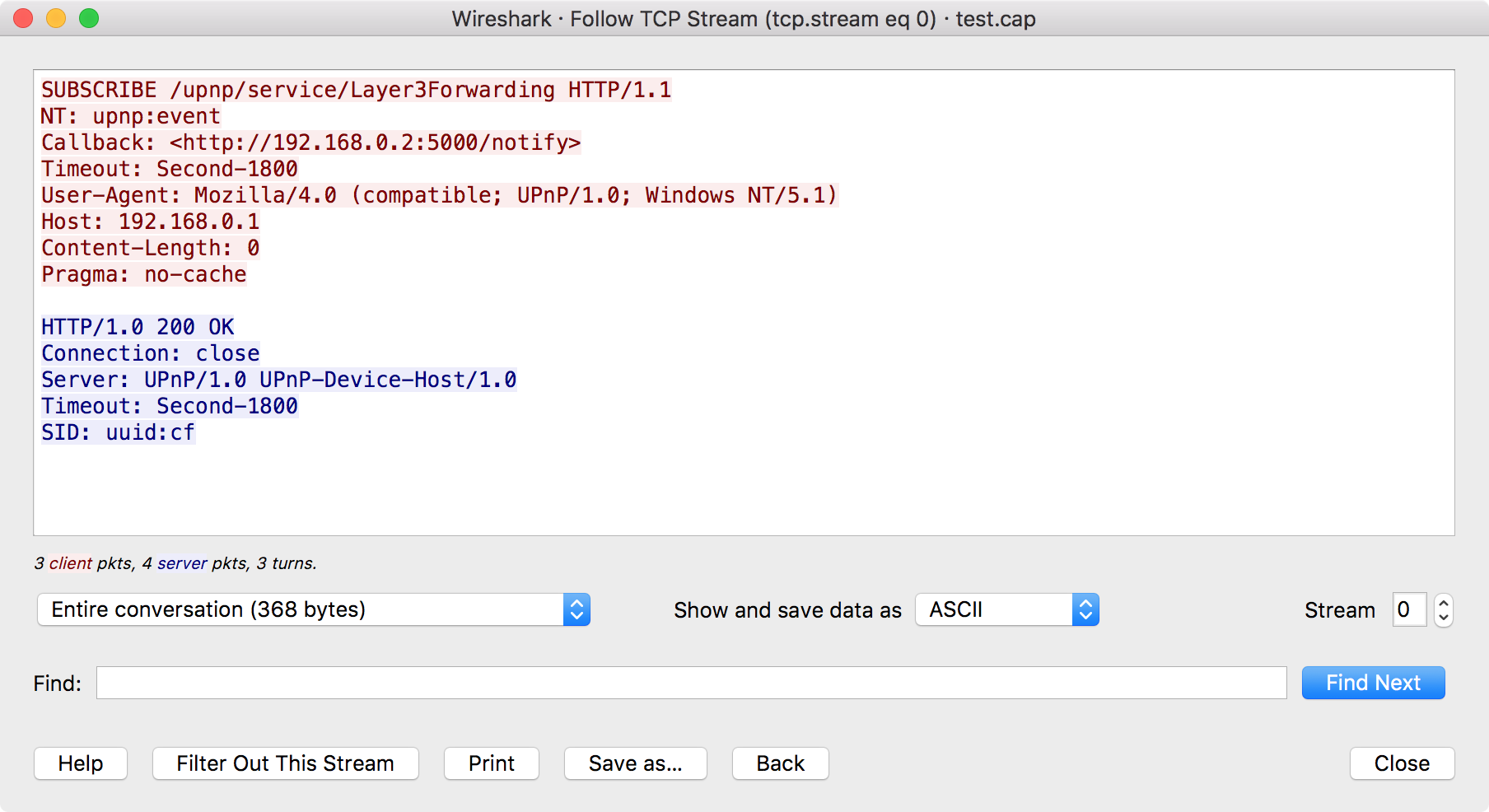
流内容以与网络上显示的顺序相同的顺序显示。从A到B的流量标记为红色,而从B到A的流量标记为蓝色。如果您愿意,可以在“首选项”对话框的“字体和颜色”页面中更改这些颜色。
不可打印的字符将被点替换。
在进行实时捕获时,不会更新流内容。要获取最新内容,您必须重新打开对话框。
您可以选择以下操作:
- 救命
- 显示此帮助。
- 过滤掉这个流
- 应用显示过滤器从显示中删除当前流数据。
- 打印
- 以当前选择的格式打印流数据。
- 另存为......
- 以当前选定的格式保存流数据。
- 背部
- 关闭此对话框并恢复以前的显示过滤器。
- 关
- 关闭此对话框,使当前显示过滤器生效。
默认情况下,显示来自两个方向的数据。您可以选择“
您可以选择以下列格式之一查看数据:
- ASCII
- 在此视图中,您将以ASCII格式查看每个方向的数据。显然最适合基于ASCII的协议,例如HTTP。
- C阵列
- 这允许您将流数据导入到您自己的C程序中。
- EBCDIC
- 对于那里的大铁怪。
- HEX转储
- 这允许您查看所有数据。这将需要大量的屏幕空间,最好与二进制协议一起使用。
- UTF-8
- 与ASCII一样,但将数据解码为UTF-8。
- UTF-16
- 与ASCII一样,但将数据解码为UTF-16。
- Yamla
- 这允许您将流加载为YAML。
- 生的
- 这允许您将未更改的流数据加载到不同的程序中以供进一步检查。显示内容与ASCII设置相同,但“另存为”将生成二进制文件。
您可以使用“Stream”选择器在流之间切换。
您可以通过在“查找”输入框中输入文本并按“
如果选定的数据包字段未显示所有字节(即它们在显示时被截断),或者它们显示为字节而不是字符串,或者如果它们需要更多格式化,因为它们包含图像或HTML,则可以使用此对话框。
此对话框还可用于解码来自base64,zlib压缩或quoted-printable的字段字节,并将解码的字节显示为可配置输出。也可以选择设置起始字节和结束字节的字节子集。
您可以选择以下操作:
- 救命
- 显示此帮助。
- 打印
- 以当前选择的格式打印字节。
- 复制
- 以当前选择的格式将字节复制到剪贴板。
- 另存为
- 以当前选择的格式保存字节。
- 关
- 关闭此对话框。
您可以选择从以下格式之一解码数据:
- 没有
- 这是默认值,不解码任何内容。
- Base64编码
- 这将从Base64解码。
- 压缩
- 这将使用zlib解压缩缓冲区。
- 引用打印
- 这将从Quoted-Printable字符串解码。
- ROT-13
- 这将解码ROT-13编码的文本。
您可以选择以下列格式之一查看数据:
- ASCII
- 在此视图中,您将字节视为ASCII。所有控制字符和非ASCII字节都替换为点。
- ASCII和控制
- 在此视图中,所有控制字符都使用UTF-8符号显示,所有非ASCII字节都用点替换。
- C阵列
- 这允许您将字段数据导入到您自己的C程序中。
- EBCDIC
- 对于那里的大铁怪。
- 十六进制转储
- 这允许您查看所有数据。这将需要大量的屏幕空间,最好与二进制协议一起使用。
- HTML
- 这允许您查看格式化为HTML文档的所有数据。支持的HTML是Qt QTextEdit类支持的。
- 图片
- 这将尝试将字节转换为图像。支持最流行的格式,包括PNG,JPEG,GIF和BMP。
- ISO 8859-1
- 在此视图中,您将字节视为ISO 8859-1。
- 生的
- 这允许您将未更改的流数据加载到不同的程序中以供进一步检查。显示屏将显示HEX数据,但“另存为”将生成二进制文件。
- UTF-8
- 在此视图中,您将字节视为UTF-8。
- UTF-16
- 在此视图中,您将字节视为UTF-16。
- Yamla
- 这将把字节显示为YAML二进制转储。
您可以通过在“查找”输入框中输入文本并按“
专家信息是Wireshark在捕获文件中发现的一种异常日志。
以下“专家信息”背后的一般思想是更好地显示“不常见”或仅仅是值得注意的网络行为。这样,与“手动”扫描数据包列表相比,新手和专家用户都希望能够更快地找到可能的网络问题。
|
专家信息只是一个提示 |
|---|---|
|
以专家信息作为暗示值得关注的内容,但不是更多。例如,没有专家信息并不一定意味着一切都好。 |
专家信息量在很大程度上取决于所使用的协议。虽然一些常见协议(如TCP / IP)将显示详细的专家信息,但大多数其他协议目前根本不会显示任何专家信息。
以下将首先描述单个专家信息的组件,然后是用户界面。
每个专家信息将包含以下内容,将在下面详细描述。
表7.1。一些示例专家信息
| 包# | 严重 | 组 | 协议 | 摘要 |
|---|---|---|---|---|
|
1 |
注意 |
序列 |
TCP |
重复的ACK(#1) |
|
2 |
聊 |
序列 |
TCP |
连接重置(RST) |
|
8 |
注意 |
序列 |
TCP |
活着 |
|
9 |
警告 |
序列 |
TCP |
快速重传(疑似) |
每个专家信息都有特定的严重性级别。使用以下严重性级别,括号中的项目将在GUI中标记:
- 聊天(灰色):有关常规工作流的信息,例如设置了SYN标志的TCP数据包
- 注意(青色):值得注意的事情,例如应用程序返回“常见”错误代码,如HTTP 404
- 警告(黄色):警告,例如应用程序返回“异常”错误代码,如连接问题
- 错误(红色):严重问题,例如[格式错误的数据包]
有一些常见的专家信息组。目前正在实施以下内容:
- 校验和:校验和无效
- 序列:协议序列可疑,例如序列不连续或检测到重传或......
- 响应代码:应用程序响应代码的问题,例如找不到HTTP 404页面
- 请求代码:应用程序请求(例如文件句柄== x),通常是聊天级别
- 未解码:剥离不全或数据不能被解码的其他原因
- 重新组装:重新组装时出现问题,例如并非所有碎片都可用或重新组装时发生异常
- 协议:违反协议规范(例如无效字段值或非法长度),可能会继续解析此数据包
- 格式不正确:格式错误的数据包或解剖器有一个错误,此数据包的解剖中止
- 调试:调试(不应该在发布版本中发生)
将来可能会添加更多组。
您可以通过选择

查找最有趣的信息(而不是使用“详细信息”选项卡)的简单快捷方法是查看每个严重性级别的单独选项卡。由于选项卡标签还包含现有条目的数量,因此很容易找到包含最重要条目的选项卡。
通常有很多相同的专家信息只在数据包编号上有所不同。这些相同的信息将组合成一行 - 计数列显示它们在捕获文件中出现的频率。单击加号可在树视图中显示各个数据包编号。
引起专家信息的协议字段被着色,例如使用青色背景作为音符严重性级别。此颜色将传播到树中的顶层协议项,因此很容易找到导致专家信息的字段。
对于上面的示例屏幕截图,IP“生存时间”值非常低(仅为1),因此相应的协议字段标有青色背景。为了更容易在数据包树中找到该项,IP协议顶级项也标记为青色。
可选的“专家信息严重性”数据包列表列可用于显示数据包的最重要严重性,如果一切正常,则保持为空。默认情况下不显示此列,但可以使用第11.5节“首选项”中所述的“首选项列”页面轻松添加该列。
默认情况下,Wireshark的TCP解析器跟踪每个TCP会话的状态,并在检测到问题或潜在问题时提供其他信息。首次打开捕获文件时,对每个TCP数据包进行一次分析。数据包按照它们在数据包列表中出现的顺序进行处理。您可以通过“分析TCP序列号”TCP解析器首选项启用或禁用此功能。
有关在TCP(例如HTTP)之上分层的数据或协议的分析,请参见 第7.8.3节“TCP重组”。
TCP分析标志被添加到“SEQ / ACK分析”下的TCP协议树中。每个标志如下所述。诸如“下一个预期序列号”和“下一个预期确认号”之类的术语是指以下“:
- 下一个预期的序列号
- 最后看到的序列号加上段长度。在没有分析标志和零窗口探测器时设置。这最初为零,并基于同一TCP流中的先前数据包计算。请注意,这可能与tcp.nxtseq协议字段不同。
- 下一个预期确认号码
- 段的最后一个序列号。在没有分析标志和零窗口探测器时设置。
- 最后看到的确认号码
- 始终设定。请注意,这与下一个预期的确认号不同。
- 最后看到的确认号码
- 始终为每个数据包更新。请注意,这与下一个预期的确认号不同。
TCP确认看不见的段
当预期的下一个确认号设置为反向并且它小于当前确认号时设置。
TCP Dup ACK <frame>#<确认号码>
满足以下所有条件时设置:
- 细分市场规模为零。
- 窗口大小不为零且未更改。
- 下一个预期的序列号和最后看到的确认号是非零的(即已建立连接)。
- 未设置SYN,FIN和RST。
TCP快速重传
满足以下所有条件时设置:
- 这不是一个keepalive数据包。
- 在正向方向上,段大小大于零或设置SYN或FIN。
- 下一个预期的序列号大于当前序列号。
- 我们在反方向上有两个以上的重复ACK。
- 当前序列号等于下一个预期确认号。
- 我们在不到20ms之前看到了最后一次确认。
取代“无序”,“虚假重传”和“重传”。
TCP Keep-Alive
当段大小为零或一时,设置当前序列号比下一个预期序列号小一个字节,并设置SYN,FIN或RST中的任何一个。
取代“快速重传”,“无序”,“虚假重传”和“重传”。
TCP Keep-Alive ACK
满足以下所有条件时设置:
- 细分市场规模为零。
- 窗口大小不为零且未更改。
- 当前序列号与下一个预期序列号相同。
- 当前确认号与最后看到的确认号相同。
- 反向最近看到的数据包是keepalive。
- 数据包不是SYN,FIN或RST。
取代“Dup ACK”和“ZeroWindowProbeAck”。
TCP无序
满足以下所有条件时设置:
- 这不是一个keepalive数据包。
- 在正向方向上,段长度大于零或设置SYN或FIN。
- 下一个预期的序列号大于当前序列号。
- 下一个预期的序列号和下一个序列号不同。
- 最后一段到达计算的RTT(默认为3毫秒)。
取代“虚假重传”和“重传”。
TCP端口号重用
设置SYN标志(不是SYN + ACK)时设置,我们使用相同的地址和端口进行现有会话,并且序列号与现有会话的初始序列号不同。
未捕获TCP上一段
当前序列号大于下一个预期序列号时设置。
TCP虚假重传
根据反方向的分析数据检查重传。满足以下所有条件时设置:
- SYN或FIN标志已设置。
- 这不是一个keepalive数据包。
- 段长度大于零。
- 此流程的数据已得到确认。也就是说,已经设置了最后看到的确认号码。
- 下一个序列号小于或等于最后看到的确认号。
取代“转发”。
TCP重传
满足以下所有条件时设置:
- 这不是一个keepalive数据包。
- 在正向方向上,段长度大于零或设置SYN或FIN标志。
- 下一个预期的序列号大于当前序列号。
TCP窗口已满
当段大小非零时设置,我们知道反向的窗口大小,并且我们的段大小反向超过窗口大小。
TCP窗口更新
满足以下所有条件时设置:
- 细分市场规模为零。
- 窗口大小不为零,不等于最后看到的窗口大小。
- 序列号等于下一个预期的序列号。
- 确认号等于最后看到的确认号。
- 没有设置SYN,FIN或RST。
TCP ZeroWindow
当窗口大小为零且未设置SYN,FIN或RST时设置。
TCP ZeroWindowProbe
当序列号等于下一个预期序列号时,设置段大小为1,反向最后看到的窗口大小为零。
如果接收器丢弃来自零窗口探测器的单个数据字节(未确认),则如果以下所有条件均为该段,则不应将后续段标记为重新传输: - 段大小大于1 。 - 下一个预期的序列号比当前序列号少一个。
这会影响“快速重传”,“无序”或“重传”。
TCP ZeroWindowProbeAck
满足以下所有条件时设置:
- 细分市场规模为零。
- 窗口大小为零。
- 序列号等于下一个预期的序列号。
- 确认号等于最后看到的确认号。
- 反向最后看到的数据包是零窗口探测器。
取代“TCP Dup ACK”。
时间戳,它们的精确度以及所有这些都可能令人困惑。本节将为您提供有关Wireshark处理时间戳时发生的情况的信息。
捕获数据包时,每个数据包在进入时都会加盖时间戳。这些时间戳将保存到捕获文件中,因此它们也可用于(稍后)分析。
那么这些时间戳从哪里来?捕获时,Wireshark从libpcap(Npcap)库中获取时间戳,然后从操作系统内核获取它们。如果捕获数据是从捕获文件加载的,那么Wireshark显然会从该文件中获取数据。
Wireshark用于保存数据包时间戳的内部格式包括日期(自1970年1月1日起的天数)和一天中的时间(自午夜起的纳秒数)。您可以调整Wireshark在数据包列表中显示时间戳数据的方式,有关详细信息,请参见第3.7节“视图”菜单中的“时间显示格式”项 。
在读取或写入捕获文件时,Wireshark会根据需要在捕获文件格式和内部格式之间转换时间戳数据。
捕获时,Wireshark使用支持微秒分辨率的libpcap(Npcap)捕获库。除非您使用专门的捕获硬件,否则此分辨率应该足够。
Wireshark知道的每种捕获文件格式都支持时间戳。特定捕获文件格式支持的时间戳精度差异很大,从一秒“0”到一纳秒“0.123456789”不等。大多数文件格式以固定的精度(例如微秒)存储时间戳,而一些文件格式甚至能够自己存储时间戳精度(无论好处是什么)。
Wireshark(以及许多其他工具)使用的常见libpcap捕获文件格式仅支持固定的微秒分辨率“0.123456”。
将数据写入捕获文件格式不能提供存储实际精度的能力将导致信息丢失。例如,如果您加载具有纳秒分辨率的捕获文件并将捕获数据存储在libpcap文件中(具有微秒分辨率),则Wireshark显然必须将精度从纳秒降低到微秒。
如果您穿越地球,时区可能会令人困惑。如果你从世界各地获得一个捕获文件时区甚至可能会更加混乱;-)
首先,有两个原因可能导致您根本不需要考虑时区:
- 您只对数据包时间戳之间的时间差感兴趣,而不需要知道捕获数据包的确切日期和时间(通常是这种情况)。
- 您不会从不同的时区获取捕获文件,因此根本没有时区问题。例如,您团队中的每个人都在与您自己在同一时区工作。
有关更多时区和DST信息, 请访问http://wwp.greenwichmeantime.com/和http://www.timeanddate.com/worldclock/。
如果您与世界各地的人们一起工作,那么将您的计算机的时间和时区设置为正确是非常有帮助的。
您应该按正确的顺序设置计算机的时间和时区:
- 将您的时区设置为当前位置
- 将计算机的时钟设置为当地时间
这样,您将告知计算机本地时间以及UTC的时间偏移。许多组织只是将其服务器和网络设备上的时区设置为UTC,以便更轻松地进行协调和故障排除。
|
小费 |
|---|---|
|
如果您环游世界,将计算机时钟的小时数调整到当地时间往往是错误的。请勿调整小时数,而是调整时区设置!对于您的计算机,时间基本上与以前相同,您只是在具有不同本地时间的不同时区。 |
通过将计算机与Internet NTP时钟服务器同步,您可以使用网络时间协议(NTP)自动将计算机调整到正确的时间。NTP客户端可用于Wireshark支持的所有操作系统(以及更多),例如,请参阅http://www.ntp.org/。
那么Wireshark和时区之间的关系究竟是什么呢?
Wireshark的本机捕获文件格式(libpcap格式)以及一些其他捕获文件格式(如Windows Sniffer,EtherPeek,AiroPeek和Sun snoop格式)将数据包的到达时间保存为UTC值。UN * X系统和“基于Windows NT”的系统在内部表示UTC时间。当Wireshark捕获时,不需要转换。但是,如果未正确设置系统时区,即使系统时钟显示正确的本地时间,系统的UTC时间也可能无法正确设置。捕获时,Npcap必须先将时间转换为UTC,然后再将其提供给Wireshark。如果未正确设置系统的时区,则无法正确完成转换。
其他捕获文件格式(如Microsoft网络监视器,基于DOS的Sniffer和网络仪器观察器格式)将数据包的到达时间保存为本地时间值。
在Wireshark内部,时间戳以UTC表示。这意味着当读取将数据包的到达时间保存为本地时间值的捕获文件时,Wireshark必须将这些本地时间值转换为UTC值。
反过来,Wireshark将始终以当地时间显示时间戳。显示计算机将它们从UTC转换为本地时间并显示此(本地)时间。对于将数据包的到达时间保存为UTC值的捕获文件,这意味着到达时间将显示为您所在时区的本地时间,这可能与数据包所在时区的到达时间不同。抓获。对于将数据包的到达时间保存为本地时间值的捕获文件,将使用您的时区与UTC和DST规则的偏移来完成到UTC的转换,这意味着转换将无法正确完成; 转换回本地时间进行显示可能会正确撤消此操作,在这种情况下,到达时间将显示为捕获数据包的到达时间。
表7.2。UTC到达时间的时区示例(无DST)
| 洛杉矶 | 纽约 | 马德里 | 伦敦 | 柏林 | 东京 | |
|---|---|---|---|---|---|---|
|
捕获文件(UTC) |
10:00 |
10:00 |
10:00 |
10:00 |
10:00 |
10:00 |
|
UTC的本地偏移量 |
-8 |
-5 |
-1 |
0 |
+1 |
+9 |
|
显示时间(当地时间) |
02:00 |
05:00 |
09:00 |
10:00 |
11:00 |
19:00 |
例如,让我们假设洛杉矶的某个人在当地正好2点钟用Wireshark捕获了一个数据包,然后向你发送这个捕获文件。捕获文件的时间戳将以UTC表示为10点钟。您位于柏林,将在您的Wireshark显示屏上看到11点钟。
现在,您可以通过电话,视频会议或Internet会议来讨论该捕获文件。由于你们都在看当地计算机上显示的时间,洛杉矶的那个人仍然会看到2点,但你们在柏林会看到11点钟。时间显示不同,因为Wireshark显示将在同一时间点显示(不同的)本地时间。
结论:除非必须确保日期/时间符合预期,否则您可能不会打扰当前查看时间戳的日期/时间。因此,如果您从不同的时区和/或DST获得捕获文件,则必须找出两个本地时间之间的时区/ DST差异,并相应地“精神调整”时间戳。在任何情况下,请确保所涉及的每台计算机都具有正确的时间和时区设置。
网络协议通常需要传输大量数据,这些数据本身是完整的,例如在传输文件时。底层协议可能无法处理该块大小(例如,网络数据包大小的限制),或者是基于流的,如TCP,它根本不知道数据块。
在这种情况下,网络协议必须自己处理块边界,并且(如果需要)将数据分布在多个分组上。显然,还需要一种机制来确定接收端的块边界。
Wireshark将此机制称为重组,尽管特定的协议规范可能会对此使用不同的术语(例如,分段,碎片整理等)。
对于Wireshark所知的一些网络协议,实现了一种机制来查找,解码和显示这些数据块。Wireshark将尝试查找此块的相应数据包,并将在“数据包字节”窗格中将组合数据显示为其他页面(有关此窗格的信息。请参见第3.19节“数据包字节数”窗格“)。
重组可能在多个协议层进行,因此可能会出现“数据包字节”窗格中的多个选项卡。
|
注意 |
|---|---|
|
您将在块的最后一个数据包中找到重新组装的数据。 |
例如,在HTTP GET响应中,返回所请求的数据(例如,HTML页面)。Wireshark将在“数据包字节”窗格的新选项卡“未压缩实体主体”中显示数据的十六进制转储。
默认情况下,在首选项中启用重组,但可以在相关协议的首选项中禁用重组。启用或禁用协议的重组设置通常需要两件事:
- 较低级别的协议(例如,TCP)必须支持重组。通常,可以通过协议首选项启用或禁用此重组。
- 更高级别的协议(例如,HTTP)必须使用重组机制来重新组合分段的协议数据。通常也可以通过协议首选项启用或禁用此功能。
更高级别协议设置的工具提示将通知您是否还必须考虑更低级别的协议设置。
HTTP或TLS等协议可能跨越多个TCP段。TCP协议首选项“允许子网段重组TCP流”(默认启用)使Wireshark可以收集连续的TCP段序列并将其移交给更高级别的协议(例如,重建完整的HTTP消息) 。除最终段之外的所有段都将在数据包列表中标记为“[重新组装的PDU的TCP段]”。
如果您只对TCP序列号分析感兴趣,请禁用此首选项以减少内存和处理开销(第7.5节“TCP分析”)。但请记住,可能会错误地解析更高级别的协议。例如,HTTP消息可以显示为“Continuation”,TLS记录可以显示为“Ignored Unknown Record”。如果在TCP连接已经启动时或TCP段丢失或无序传递时开始捕获,也可以观察到这样的结果。
要重新组合无序TCP段,除了先前的首选项之外,还必须启用TCP协议首选项“重新组装无序段”(默认情况下禁用)。如果按顺序接收所有数据包,则此首选项不会产生任何影响。否则(如果在顺序处理数据包捕获时遇到丢失的段),则假定新的和丢失的段属于同一PDU。注意事项:
- 假设丢失的数据包无序接收或稍后重新传输。应用程序通常会重新传输段,直到确认这些段为止,但如果数据包捕获丢弃数据包,则Wireshark将无法重建TCP流。在这种情况下,您可以尝试禁用此首选项,并希望进行部分剖析,而不是仅为每个TCP段看到“[重新组装的PDU的TCP段]”。
- 在监控模式(IEEE 802.11)中进行捕获时,由于信号接收问题,数据包更容易丢失。在这种情况下,建议禁用该选项。
- 如果新的和丢失的段实际上是不同PDU的一部分,则处理当前被延迟,直到不再有段丢失,即使丢失的段的开始完成了PDU。例如,假设六个段形成两个PDU
ABC和DEF。当收到时ABECDF,应用程序可以在接收后开始处理第一个PDUABEC。但Wireshark也要求D收到缺失的段。这个问题将在未来解决。 - 在GUI中和两遍解剖(
tshark -2)期间,前一个场景将在数据包中显示具有最后一个段(F)的两个PDU,而不是在具有最终丢失的PDU段的第一个数据包中显示它。这个问题将在未来解决。 - 启用后,
smb.time如果请求跟随其他无序段(这反映了应用程序行为),则SMB“请求时间”()的字段可能会更小。如果然后发生先前的场景,则请求的时间基于接收所有丢失的段的帧。
无论这两个与重组相关的首选项的设置如何,您始终可以使用“Follow TCP Stream”选项(第7.2节“遵循协议流”)以预期的顺序显示段。
名称解析尝试将某些数字地址值转换为人类可读格式。根据要执行的分辨率,有两种方法可以执行这些转换:调用系统/网络服务(如gethostname()函数)和/或从Wireshark特定配置文件中解析。有关Wireshark用于名称解析等的配置文件的详细信息,请参阅附录B,文件和文件夹。
可以为以下各节中列出的协议层单独启用名称解析功能。
使用Wireshark时,名称解析可能非常宝贵,甚至可以节省您的工作时间。不幸的是,它也有它的缺点。
- 名称解析通常会失败。要解析的名称可能只是所要求的名称服务器未知,或者服务器不可用,并且在Wireshark的配置文件中也找不到该名称。
- 已解析的名称不会存储在捕获文件中或其他位置。因此,如果稍后或在其他计算机上打开捕获文件,则可能无法使用已解析的名称。每次打开捕获文件时,它可能看起来“略有不同”,因为您无法连接到名称服务器(之前可以连接到该名称服务器)。
- DNS可能会向捕获文件添加其他数据包。您可能会在捕获文件中看到进出计算机的数据包,这是由Wireshark从中捕获的计算机的名称解析网络服务引起的。
- 已解析的DNS名称由Wireshark缓存。这是可接受性能所必需的。但是,如果在Wireshark运行时名称解析信息应该更改,则Wireshark在缓存后不会注意到名称解析信息的更改。如果在Wireshark运行时此信息发生更改,例如新的DHCP租约生效,Wireshark将不会注意到它。
填充列表时,将完成数据包列表中的名称解析。如果在将数据包添加到列表后可以解析名称,则不会更改其以前的条目。在缓存名称解析结果时,您可以使用
尝试将以太网MAC地址(例如00:09:5b:01:02:03)解析为更“人类可读”的内容。
ARP名称解析(系统服务):Wireshark将要求操作系统将以太网地址转换为相应的IP地址(例如00:09:5b:01:02:03→192.168.0.1)。
以太网代码(ethers文件):如果ARP名称解析失败,Wireshark会尝试将以太网地址转换为已知的设备名称,该名称已由用户使用 ethers文件分配(例如00:09:5b:01:02: 03→homerouter)。
以太网制造商代码(manuf文件):如果ARP或ethers都没有返回结果,Wireshark会尝试将以太网地址的前3个字节转换为缩写的制造商名称,该名称由IEEE分配(例如00:09:5b: 01:02:03→Netgear_01:02:03)
尝试将IP地址(例如216.239.37.99)解析为更“人类可读”的内容。
DNS名称解析(系统/库服务):Wireshark将使用名称解析器将IP地址转换为与其关联的主机名(例如216.239.37.99→www.1.google.com)。
DNS名称解析通常可以同步或异步执行。这两种机制都可用于将IP地址转换为某些人类可读(域)名称。像gethostname()这样的系统调用会尝试将地址转换为名称。为此,如果找到匹配的条目,它将首先询问系统主机文件(例如/ etc / hosts)。如果失败,它将向配置的DNS服务器询问该名称。
因此,当系统必须等待DNS服务器关于名称解析时,同步DNS和异步DNS之间的真正区别就出现了。系统调用gethostname()将一直等到名称解析或发生错误。如果DNS服务器不可用,则可能需要相当长的时间(几秒钟)。
|
警告 |
|---|---|
|
为了提供可接受的性能,Wireshark依赖于异步DNS库来进行名称解析。如果在编译期间没有可用功能,则该功能将不可用。 |
异步DNS服务的工作方式略有不同。它也会询问DNS服务器,但它不会等待答案。它将在很短的时间内返回Wireshark。在DNS服务器返回答案之前,实际(和以下)地址字段不会显示已解析的名称。如上所述,值被缓存,因此您可以使用
主机名解析(hosts文件):如果DNS名称解析失败,Wireshark将尝试使用用户提供的主机文件(例如216.239.37.99→www.google.com)将IP地址转换为与其关联的主机名。
尝试将TCP / UDP端口(例如80)解析为更“人类可读”的东西。
TCP / UDP端口转换(系统服务):Wireshark将要求操作系统将TCP或UDP端口转换为其众所周知的名称(例如80→http)。
多个网络协议使用校验和来确保数据完整性。如此处所述应用校验和也称为冗余校验。
Wireshark将验证许多协议的校验和,例如IP,TCP,UDP等。
它将执行与“普通接收器”相同的计算,并通过注释显示数据包详细信息中的校验和字段,例如[正确]或[无效,必须为0x12345678]。
可以针对Wireshark协议首选项中的各种协议关闭校验和验证,例如(非常轻微地)提高性能。
如果启用了校验和验证并且检测到无效校验和,则不会处理数据包重组等功能。这是可以避免的,因为不正确的连接数据可能会“混淆”内部数据库。
校验和计算可以由网络驱动程序,协议驱动程序甚至硬件完成。
例如:以太网传输硬件计算以太网CRC32校验和,接收硬件验证此校验和。如果收到的校验和错误,Wireshark甚至不会看到数据包,因为以太网硬件在内部丢弃数据包。
通过协议实现“传统地”计算更高级别的校验和,然后将完成的分组移交给硬件。
最近的网络硬件可以执行高级功能,例如IP校验和计算,也称为校验和卸载。网络驱动程序不会计算校验和本身,而只是将空(零或垃圾填充)校验和字段移交给硬件。
|
注意 |
|---|---|
|
校验和卸载经常导致混淆,因为在实际计算校验和之前,要传输的网络数据包被移交给Wireshark。Wireshark获取这些“空”校验和并将它们显示为无效,即使这些数据包在以后离开网络硬件时将包含有效的校验和。 |
校验和卸载可能会令人困惑,并且在屏幕上显示大量[无效]消息可能非常烦人。如上所述,无效的校验和可能导致未组装的数据包,使分组数据的分析更加困难。
你可以做两件事来避免这个校验和卸载问题:
- 如果此选项可用,请关闭网络驱动程序中的校验和卸载。
- 关闭Wireshark首选项中特定协议的校验和验证。由于现代硬件和操作系统中卸载的普遍性,最近发布的Wireshark默认禁用校验和验证。
目录
Wireshark提供各种网络统计信息,可通过
这些统计信息包括有关加载的捕获文件的一般信息(如捕获的数据包的数量),以及有关特定协议的统计信息(例如,有关HTTP请求数量和捕获的响应的统计信息)。
-
一般统计:
- 捕获有关捕获文件的文件属性。
- 协议捕获的数据包的层次结构。
- 对话,例如特定IP地址之间的流量。
- 端点,例如进出IP地址的流量。
- IO Graphs及时显示数据包(或类似数据)的数量。
-
协议特定统计:
- 服务响应某些协议的请求和响应之间的时间。
- 各种其他协议特定统计。
|
注意 |
|---|---|
|
协议特定统计需要有关特定协议的详细知识。除非您熟悉该协议,否则很难理解它的统计数据。 |
Wireshark有许多其他统计窗口,显示有关特定协议的详细信息,可能会在本文档的更高版本中进行描述。
其中一些统计信息在https://wiki.wireshark.org/Statistics中有所描述 。
有关当前捕获文件的常规统计信息。

- 文件:有关捕获文件的一般信息。
- 时间:捕获第一个和最后一个数据包的时间戳(以及它们之间的时间)。
- 捕获:捕获完成时的信息(仅当数据包数据是从网络捕获而不是从文件加载时才可用)。
- 接口:有关捕获接口的信息。
- 统计:网络流量的一些统计数据。如果设置了显示过滤器,您将在“捕获”列中看到值,如果标记了任何包,您将在“标记”列中看到值。Captured列中的值将保持与之前相同,而 Displayed列中的值将反映与显示中显示的数据包对应的值。“标记”列中的值将反映与标记的包对应的值。
捕获的数据包的协议层次结构。
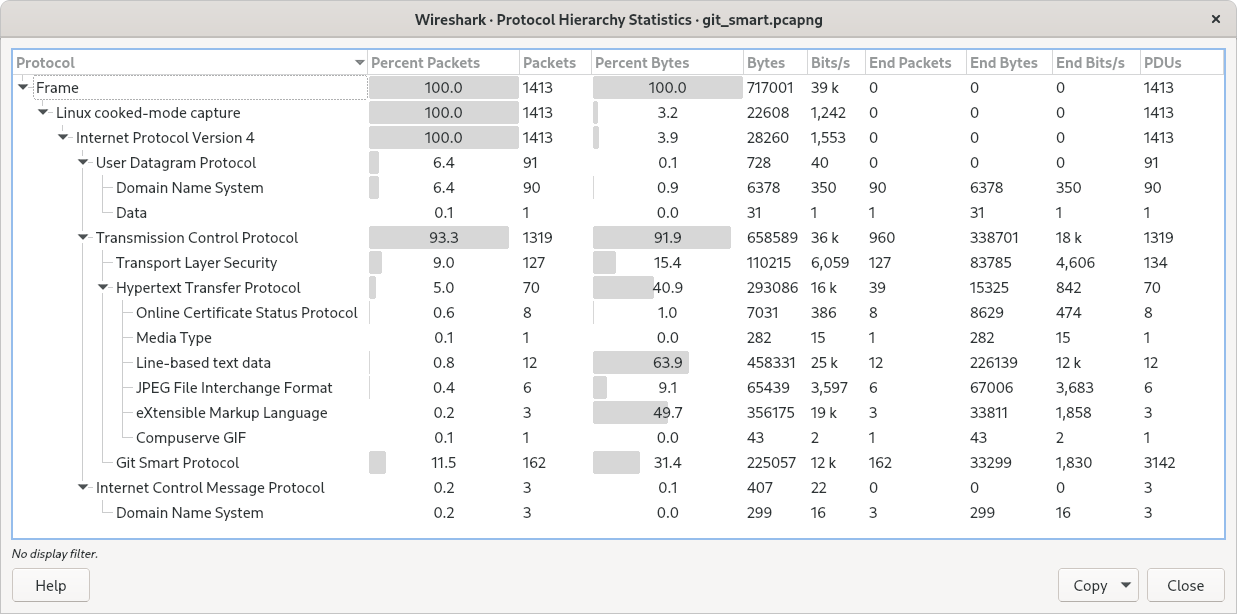
这是捕获中所有协议的树。每行包含一个协议的统计值。其中两列(Percent Packets和 Percent Bytes)作为条形图提供双重任务。如果设置了显示过滤器,它将显示在底部。
使用“
协议层次结构列
- 协议
- 这个协议的名称
- 百分比数据包
- 协议数据包相对于捕获中所有数据包的百分比
- 包
- 此协议的数据包总数
- 百分比字节
- 协议字节相对于捕获中总字节数的百分比
- 字节
- 此协议的总字节数
- 比特/秒
- 该协议的带宽相对于捕获时间
- 结束数据包
- 此协议的绝对数量,它是堆栈中的最高协议(最后解析)
- 结束字节
- 此协议的绝对字节数,它是堆栈中的最高协议(最后解析)
- 结束位
- 该协议的带宽相对于捕获时间而言是堆栈中的最高协议(最后解析)
数据包通常包含多个协议。结果,每个数据包将计算多个协议。示例:在屏幕截图中,IP有99.9%和TCP 98.5%(一起超过100%)。
协议层可以包含不包含任何更高层协议的数据包,因此所有更高层数据包的总和可能不等于协议数据包计数。示例:在屏幕截图中,TCP有98.5%,但子协议(TLS,HTTP等)的总和要少得多。这可能是由连续帧,TCP协议开销和其他未公开的数据引起的。
单个数据包可以多次包含相同的协议。在这种情况下,协议不止一次计算。例如,ICMP回复和许多隧道协议将携带多个IP报头。
网络会话是两个特定端点之间的流量。例如,IP会话是两个IP地址之间的所有流量。有关已知端点类型的说明,请参见 第8.6节“端点”。
对话窗口类似于端点窗口。有关其常用功能的说明,请参见 第8.6.1节“端点”窗口“。与地址,数据包计数器和字节计数器一起,会话窗口增加了四列:会话的开始时间(“Rel Start”)或(“Abs Start”),会话的持续时间(以秒为单位)和平均位(每个方向每秒钟不是字节数。还在“Rel Start”/“Abs Start”和“Duration”列中绘制了时间线图。
列表中的每一行都显示一个对话的统计值。
如果在窗口中选择了名称解析,并且对于特定协议层(所选以太网端点页面的MAC层)是活动的,则将完成名称解析。限制显示过滤器仅显示与当前显示过滤器匹配的对话。绝对启动时间在相对(“Rel Start”)和绝对(“Abs Start”)时间之间切换开始时间列。相对开始时间与数据包列表中的“捕获开始时间的秒数”时间显示格式相匹配,绝对开始时间与“时间”显示格式相匹配。
“
|
小费 |
|---|---|
|
此窗口将经常更新,因此即使您在进行实时捕获之前(或同时)打开它也会很有用。 |
网络端点是特定协议层的单独协议流量的逻辑端点。Wireshark的端点统计信息将考虑以下端点:
|
小费 |
|---|---|
|
如果您正在寻找其他网络工具调用主机列表的功能,这里是正确的位置。以太网或IP端点列表通常是您正在寻找的。 |
端点和会话类型
- 蓝牙
- MAC-48地址类似于以太网。
- 以太网络
- 与以太网设备的MAC-48标识符相同。
- 光纤通道
- MAC-48地址类似于以太网。
- IEEE 802.11
- MAC-48地址类似于以太网。
- FDDI
- 与FDDI MAC-48地址相同。
- IPv4的
- 与32位IPv4地址相同。
- IPv6的
- 与128位IPv6地址相同。
- IPX
- 32位网络号和48位节点地址的串联,默认为以太网接口的MAC-48地址。
- JXTA
- 一个160位SHA-1 URN。
- NCP
- 与IPX类似。
- 敬请回复
- varios RSVP会话属性和IPv4地址的组合。
- SCTP
- 主机IP地址(复数)和使用的SCTP端口的组合。因此,同一IP地址上的不同SCTP端口是不同的SCTP端点,但同一主机的不同IP地址上的相同SCTP端口仍然是相同的端点。
- TCP
- 使用的IP地址和TCP端口的组合。同一IP地址上的不同TCP端口是不同的TCP端点。
- 令牌环
- 与令牌环MAC-48地址相同。
- UDP
- 使用的IP地址和UDP端口的组合,因此同一IP地址上的不同UDP端口是不同的UDP端点。
- USB
- 与7位USB地址相同。
|
广播和多播端点 |
|---|---|
|
广播和多播流量将作为附加端点单独显示。当然,由于这些不是物理端点,因此一些或所有列出的单播端点将接收实际流量。 |
此窗口显示有关捕获的端点的统计信息。
对于每个支持的协议,此窗口中都会显示一个选项卡。每个选项卡标签显示捕获的端点数(例如,选项卡标签“Ethernet·4”告诉您已捕获四个以太网端点)。如果未捕获特定协议的端点,则选项卡标签将显示为灰色(尽管仍可以选择相关页面)。
列表中的每一行都显示正好一个端点的统计值。
如果在窗口中选择了名称解析,并且对于特定协议层(所选以太网端点页面的MAC层)是活动的,则将完成名称解析。限制显示过滤器仅显示与当前显示过滤器匹配的对话。请注意,在此示例中,我们配置了MaxMind DB,它为我们提供了额外的地理列。有关更多信息,请参见第11.10节“MaxMind数据库路径”。
“
|
小费 |
|---|---|
|
此窗口将经常更新,因此即使您在进行实时捕获之前(或同时)打开它也很有用。 |
用户可配置捕获的网络数据包的图形。
您最多可以定义五种不同颜色的图形。

用户可以配置以下内容:
-
图表
- 图1-5:启用特定图1-5(默认情况下仅启用图1)
- 颜色:图表的颜色(不能更改)
- 过滤器:此图形的显示过滤器(此图表仅考虑通过此过滤器的数据包)
- 风格:图形的样式(Line / Impulse / FBar / Dot)
-
X轴
- 刻度间隔:x方向的间隔持续(10/1分钟或10/1 / 0.1 / 0.01 / 0.001秒)
- 每个刻度的像素:每个刻度间隔使用10/5/2/1像素
- 查看时间:选择查看x方向标签作为时间而不是自捕获开始后的秒或分钟
-
和轴心
- 单位:y方向的单位(Packets / Tick,Bytes / Tick,Bits / Tick,Advanced ...)[XXX - 描述高级功能。]
- 比例:y单位的比例(Logarithmic,Auto,10,20,50,100,200,500,...)
“
“
|
小费 |
|---|---|
|
单击图形以选择所选间隔中的第一个包。 |
服务响应时间是请求和相应响应之间的时间。此信息适用于许多协议。
服务响应时间统计信息目前可用于以下协议:
- DCE-RPC
- 光纤通道
- H.225 RAS
- LDAP
- LTE MAC
- MGCP
- ONC-RPC
- SMB
作为示例,更详细地描述DCE-RPC服务响应时间。
|
注意 |
|---|---|
|
与以下描述相比,其他服务响应时间窗口将以相同的方式工作(或仅略微不同)。 |


在捕获中显示TCP流的不同可视表示。
- 时间序列(史蒂文斯)
- 这是TCP序列号随时间变化的简单图表,类似于Richard Stevens的“TCP / IP Illustrated”系列丛书中使用的图表。
- 时间顺序(tcptrace)
- 显示类似于tcptrace实用程序的TCP度量标准 ,包括转发段,确认,选择性确认,反向窗口大小和零窗口。
- 吞吐量
- 平均吞吐量和产量。
- 往返时间
- 往返时间与时间或序列号。RTT基于对应于特定段的确认时间戳。
- 窗口缩放
- 窗口大小和突出字节。
目录
Wireshark提供各种与电话相关的网络统计数据,可通过
这些统计数据包括特定信令协议,信令和媒体流分析。如果以兼容编码进行编码,则甚至可以播放媒体流。
协议特定统计窗口显示特定协议的详细信息,可能在本文档的更高版本中描述。
其中一些统计信息在https://wiki.wireshark.org/Statistics页面中进行了描述 。
“VoIP呼叫”窗口显示捕获的流量中所有检测到的VoIP呼叫的列表。它通过信号发现呼叫。
有关详细信息,请访问https://wiki.wireshark.org/VoIP_calls页面。
捕获的LTE MAC流量的统计信息。此窗口将汇总捕获中发现的LTE MAC流量。
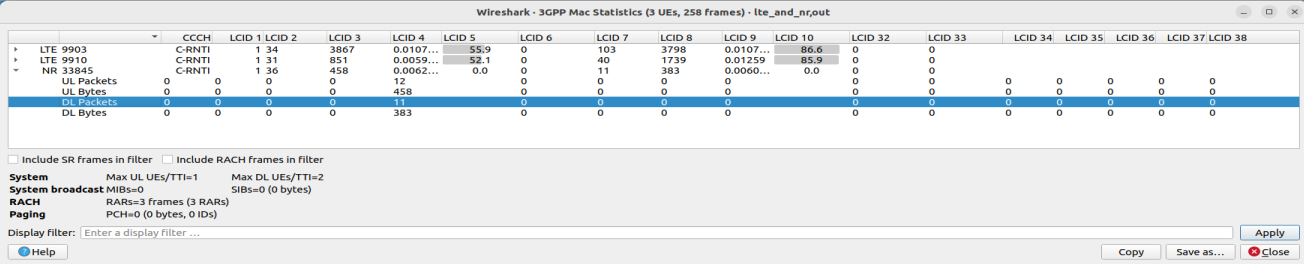
顶部窗格显示公共频道的统计信息。中间窗格中的每一行显示恰好一个UE / C-RNTI的统计集锦。在下部窗格中,您可以看到当前选定的UE / C-RNTI按单个通道分解的流量。

RTP分析功能获取所选的RTP流(如果可能,则采用反向流)并在其上生成统计列表。

从基本数据开始作为包号和序列号,根据到达时间,延迟,抖动,包大小等创建进一步的统计数据。
除了每个数据包统计信息外,下部窗格显示整体统计信息,包括增量,抖动和时钟偏差的最小值和最大值。还包括丢失分组的指示。
RTP流分析窗口还提供保存RTP有效负载的选项(作为原始数据,或者,如果是PCM编码,则保存在音频文件中)。其他选项a导出并绘制有关RTP流的各种统计信息。
RTP播放器窗口可让您播放RTP音频数据。为了使用此功能,您的Wireshark版本必须支持每个RTP流使用的音频和编解码器。
有关详细信息, 请访问https://wiki.wireshark.org/VoIP_calls页面。
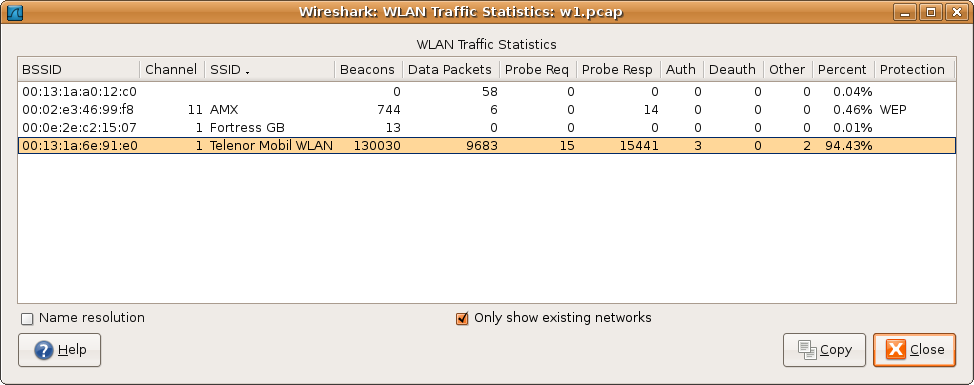
目录
Wireshark的默认行为通常很适合您的需求。但是,随着您对Wireshark的熟悉,它可以通过各种方式进行定制,以更好地满足您的需求。在本章中我们将探讨:
- 如何使用命令行参数启动Wireshark
- 如何着色包列表
- 如何控制协议解剖
- 如何使用各种首选项设置
您可以从命令行启动Wireshark,但也可以从大多数Window管理器启动它。在本节中,我们将从命令行开始。
Wireshark支持大量命令行参数。要查看它们是什么,只需输入命令wireshark -h,并打印示例11.1“Wireshark提供的帮助信息”(或类似内容)中显示的 帮助信息。
例11.1。Wireshark提供的帮助信息
Wireshark 2.1.0(来自master的v2.1.0rc0-502-g328fbc0) 交互式转储和分析网络流量。 有关更多信息,请访问https://www.wireshark.org。 用法:wireshark [options] ... [<infile>] 捕获接口: -i <interface>接口的名称或idx(def:first non-loopback) -f <capfilter | predef:> libpcap过滤器语法中的数据包过滤器或 predef:filtername - 来自GUI -s <snaplen>数据包快照长度(def:262144)的预定义filtername -p不以混杂模式 捕获-k立即开始捕获(def:什么都不做) -S更新数据包显示当捕获新数据包时 - 在-S正在使用时打开自动滚动 -I在监控模式下捕获,如果可用 -B <缓冲区大小>内核缓冲区大小(def:2MB) -y <link type> link layer type(def:first appropriate)-- time-stamp-type <type> timestamp方法,用于接口 -D打印接口列表和exit -L打印列表的链接层类型iface和exit --list- time-stamp-types打印iface和exit的时间戳类型列表 捕获停止条件: -c <数据包计数>在n个数据包后停止(def:无限) -a <autostop cond。> ... duration:NUM - 在NUM秒 文件大小后停止:NUM - 在NUM KB文件后停止此文件 :NUM - 在NUM个文件后停止 捕获输出: -b <ringbuffer opt。> ... duration :NUM - 在NUM秒 文件大小后切换到下一个文件:NUM - 在NUM KB文件后切换到下一个文件 :NUM - ringbuffer:在NUM个文件后替换 RPCAP选项: -A <user>:<password>使用RPCAP密码验证 输入文件: -r <infile>设置要读取的文件名(无管道或标准输入!) 处理: -R <读取过滤器> Wireshark中的数据包过滤器显示过滤器语法 -n禁用所有名称解析(def:全部启用) -N <名称解析标志>启用特定名称解析:“mnNtdv” -d <layer_type> == <selector>,<decode_as_protocol> ... “解码为”,有关详细信息,请参见手册页 示例:tcp.port == 8888,http --disable-protocol <proto_name> 禁用解析proto_name --enable-heuristic < short_name > 启用解释启发式协议 --disable-heuristic <short_name> 禁用启发式协议的解剖 用户界面: -C <config profile>以指定的配置文件开头 -Y <显示过滤器>以给定的显示过滤器开始 -g <包编号>在“-r” -J <跳过过滤器> 之后转到指定的包编号第一个数据包匹配(显示) 过滤器 -j向后搜索匹配数据包后面的“-J” -m <font>设置用于大多数文本的字体名称 -ta | ad | d | dd | e | r | u | ud输出格式的时间戳(def:r:rel。到第一个) -us | hms输出格式为秒(def:s:秒) -X <key>:<value> eXtension选项,有关详细信息,请参见手册 -z <statistics>显示各种统计信息,详见man页面 输出: -w <outfile | - >设置输出文件名(或' - '表示stdout) 其他: -h显示此帮助并退出 -v display version info和exit -P <key>:<path> persconf:path - 个人配置文件 persdata:path - 个人数据文件 -o <name>:<value> ...覆盖首选项或最近设置 -K <keytab>要使用的keytab文件用于kerberos解密
我们将依次检查每个命令行选项。
首先要注意的是,发出命令wireshark本身会带来Wireshark。但是,您可以根据需要包含任意数量的命令行参数。它们的含义如下(按字母顺序排列):
- -a <捕获自动停止条件>
-
指定一个标准,指定Wireshark何时停止写入捕获文件。标准是表单test:value,其中test是以下之一:
- 持续时间:价值
- 在经过秒值后停止写入捕获文件。
- 文件大小:值
- 在达到大小值千字节(其中千字节为1000字节,而不是1024字节)后停止写入捕获文件。如果此选项与-b选项一起使用,则Wireshark将停止写入当前捕获文件,并在达到filesize时切换到下一个文件。
- 文件:值
- 在写入文件的值数量后停止写入以捕获文件。
- -b <捕获环缓冲区选项>
-
如果指定了最大捕获文件大小,则此选项会使Wireshark以“环形缓冲区”模式运行,并具有指定数量的文件。在“环形缓冲区”模式下,Wireshark将写入多个捕获文件。它们的名称取决于文件的编号以及创建日期和时间。
当第一个捕获文件填满时,Wireshark将切换到写入下一个文件,依此类推。使用<command> files </ command>选项,还可以形成“环形缓冲区”。这将填充新文件,直到指定的文件数量为止,此时第一个文件中的数据将被丢弃,因此新的文件可以写。
如果指定了可选的<command> duration </ command>,则即使当前文件未完全填满,Wireshark也会在指定的秒数过后切换到下一个文件。
- 持续时间</命令>:值
- 即使当前文件未完全填满,也会在值秒后切换到下一个文件。
- 文件大小</命令>:值
- 在达到大小值千字节(其中千字节为1000字节,而不是1024字节)后切换到下一个文件。
- 文件</命令>:值
- 在写入文件的值编号后,从第一个文件开始(形成环形缓冲区)。
- -B <捕获缓冲区大小>
- 设置捕获缓冲区大小(以MB为单位,默认为1MB)。捕获驱动程序使用它来缓冲数据包数据,直到可以将数据写入磁盘。如果在捕获时遇到丢包,请尝试增加此大小。某些平台不支持。
- -c <捕获数据包计数>
- 此选项指定捕获实时数据时要捕获的最大数据包数。它将与
-k选项一起使用。 - -D
-
打印Wireshark可以捕获的接口列表,然后退出。对于每个网络接口,打印数字和接口名称,可能后跟接口的文本描述。可以将接口名称或编号提供给
-i标志以指定要捕获的接口。这对于没有列出命令的系统(例如,Windows系统或缺少的UNIX系统
ifconfig -a)非常有用。该数字在Windows上特别有用,其中接口名称是GUID。请注意,“可以捕获”意味着Wireshark能够打开该设备进行实时捕获。如果在您的系统上,必须从具有特殊权限的帐户(例如,以root用户)运行执行网络捕获的程序,那么,如果Wireshark使用该
-D标志运行且不是从此类帐户运行,则不会列出任何接口。 - -f <捕获过滤器>
- 此选项设置捕获数据包时要使用的初始捕获筛选器表达式。
- -g <包号>
- 使用-r标志读取捕获文件后,转到给定的数据包编号。
- -H
- 该
-h选项请求Wireshark打印其版本和使用说明(如上所示)并退出。 - -i <捕获接口>
-
设置用于实时数据包捕获的网络接口或管道的名称。
网络接口名称应与
wireshark -D(如上所述)中列出的名称之一匹配。wireshark -D也可以使用报道的数字。如果您正在使用UNIX,netstat -i,ifconfig -a或者ip link也可能工作获得的接口名,虽然UNIX的不是所有版本都支持的-a标志ifconfig。如果没有指定接口,Wireshark搜索接口列表,如果有任何非环回接口,则选择第一个非环回接口,如果没有非环回接口,则选择第一个环回接口; 如果没有接口,Wireshark会报告错误并且不会启动捕获。
管道名称应该是FIFO(命名管道)的名称或“ - ”以从标准输入读取数据。从管道读取的数据必须采用标准的libpcap格式。
- -J <跳过滤器>
- 使用
-r标志读取捕获文件后,跳转到与过滤器表达式匹配的第一个数据包。过滤器表达式采用显示过滤器格式。如果无法找到完全匹配,则选择之后的第一个数据包。 - -一世
- 如果可用,以监控模式捕获无线数据包。
- -j
- 在选项后使用此选项
-J可向后搜索要转到的第一个数据包。 - -k
- 该
-k选项指定Wireshark应立即开始捕获数据包。此选项要求使用该-i参数指定将从中捕获数据包的接口。 - -K <keytab文件>
- 使用指定的文件进行Kerberos解密。
- -l
- 如果数据包列表窗格在捕获期间数据包到达时自动更新(由
-S标志指定),则此选项将打开自动滚动 。 - -L
- 列出接口支持的数据链接类型并退出。
- --list-时间戳类型
- 列出可为iface和exit配置的时间戳类型
- -m <font>
- 此选项设置Wireshark显示的大多数文本所使用的字体名称。
- -n
- 禁用网络对象名称解析(例如主机名,TCP和UDP端口名称)。
- -N <名称解析标志>
- 打开特定类型的地址和端口号的名称解析。参数是一个字符串,可能包含
m用于启用MAC地址解析,n启用网络地址解析以及t启用传输层端口号解析的字母。这将覆盖-n如果两个-N和-n都存在。该字母d可以从捕获的DNS数据包中解析。该字母v可以解析从VLAN ID到名称。 - -o <首选项或最近的设置>
-
设置首选项或最近值,覆盖默认值以及从首选项或最近文件中读取的任何值。该标志的参数是一个形式为prefname:value的字符串,其中prefname是首选项的名称(与
preferencesorrecent文件中显示的名称相同), value是应该设置的值。可以在单个命令行上给出多个`-o <首选项设置>`实例。设置单个首选项的示例如下:
wireshark -o mgcp.display_dissect_tree:TRUE设置多个首选项的示例如下:
wireshark -o mgcp.display_dissect_tree:TRUE -o mgcp.udp.callagent_port:2627您可以从首选项文件中获取所有可用首选项字符串的列表。有关详细信息,请参阅附录B,文件和文件夹。
用户访问表可以使用“UAT,”后面的UAT文件名和保存文件的有效记录重写:
wireshark -o“uat:user_dlts:\”用户0(DLT = 147)\“,\”http \“,\”0 \“,\”\“,\”0 \“,\”\“”上面的例子将与作为HTTP一个libpcap的数据链接类型147剖析的分组,就像您已在DLT_USER协议偏好配置它。
- -p
- 不要将接口置于混杂模式。请注意,由于某些其他原因,界面可能处于混杂模式。因此,
-p不能用于确保捕获的唯一流量是发送到Wireshark运行的机器的流量,广播流量和组播流量到该机器接收的地址。 - -P <路径设置>
-
通常会自动检测特殊路径设置。这用于特殊情况,例如从USB记忆棒上的已知位置启动Wireshark。
标准的格式为key:path,其中key是以下之一:
- persconf:path
- 个人配置文件的路径,如首选项文件。
- persdata:路径
- 个人数据文件的路径,它是最初打开的文件夹。初始化后,最近的文件将保留上次使用的文件夹。
- -Q
- 捕获完成后,此选项会强制Wireshark退出。它可以与
-c选项一起使用。它必须与-i和-w选项一起使用。 - -r <infile>
- 此选项提供Wireshark读取和显示的捕获文件的名称。此捕获文件可以是Wireshark理解的格式之一。
- -R <读取(显示)过滤器>
- 此选项指定在从捕获文件读取数据包时应用的显示过滤器。此过滤器的语法是第6.3节“查看时过滤数据包”中讨论的显示过滤器的语法。与过滤器不匹配的数据包将被丢弃。
- -s <捕获快照长度>
- 此选项指定捕获数据包时使用的快照长度。Wireshark将仅捕获每个数据包的snaplen字节数据。
- -S
- 此选项指定Wireshark在捕获数据包时显示数据包。这是通过在一个过程中捕获并在单独的过程中显示它们来完成的。这与“捕获选项”对话框中的“实时更新数据包列表”相同。
- -t <时间戳格式>
-
此选项设置数据包列表窗口中显示的数据包时间戳的格式。格式可以是以下之一:
- [R
- Relative,指定相对于捕获的第一个数据包显示的时间戳。
- 一个
- 绝对,指定显示所有数据包的实际时间。
- 至
- 绝对日期,指定显示所有数据包的实际日期和时间。
- d
- Delta,指定时间戳相对于前一个数据包。
- 和
- Epoch,指定时间戳是自纪元以来的秒数(1970年1月1日00:00:00)
- -u <s | HMS>
- 将时间显示为秒(“s”,默认值)或小时,分钟和秒(“hms”)
- -v
- 该
-v选项请求Wireshark打印出其版本信息并退出。 - -w <savefile>
- 此选项设置用于保存捕获的数据包的文件的名称。
- -y <捕获链接类型>
- 如果从命令行启动捕获
-k,则设置捕获数据包时要使用的数据链接类型。报告-L的值是可以使用的值。 - --time-stamp-type <type>
- 如果从命令行启动捕获
-k,则设置捕获数据包时要使用的数据链接类型。报告--list-time-stamp-types的值是可以使用的值。 - -X <扩展选项>
-
指定要传递给TShark模块的选项。eXtension选项的格式为extension_key:value,其中extension_key可以是:
- lua_script:lua_script_filename,它
- 除默认的Lua脚本外,还告诉Wireshark加载给定的脚本。
- lua_script [是否]:参数
- 告诉Wireshark将给定的参数传递给num标识的lua脚本 ,这是lua_script命令的数字索引顺序。例如,如果只加载了一个脚本
-X lua_script:my.lua,则将-X lua_script1:foo字符串foo传递给my.lua脚本。如果两个脚本加载,如-X lua_script:my.lua和-X lua_script:other.lua按照这个顺序,那么-X lua_script2:bar将在字符串传递杆到第二LUA脚本,即other.lua。
- -z <statistics-string>
- 获取Wireshark以收集各种类型的统计信息,并在半实时更新的窗口中显示结果。
Wireshark中一个非常有用的机制是数据包着色。您可以设置Wireshark,以便根据显示过滤器对数据包进行着色。这允许您强调您可能感兴趣的数据包。
您可以在Wireshark Wiki着色规则页面上找到许多着色规则示例,网址为https://wiki.wireshark.org/ColoringRules。
Wireshark中有两种类型的着色规则:临时规则仅在您退出程序之前有效,而永久规则保存在首选项文件中,以便下次运行Wireshark时可用。
通过选择数据包并同时按下Ctrl 键和其中一个数字键,可以添加临时规则。这将基于当前选定的对话创建着色规则。它将首先尝试创建基于TCP的会话过滤器,然后是UDP,然后是IP,最后是以太网。 在右侧单击数据包详细信息窗格中时,也可以通过选择“
要永久上色包,选择
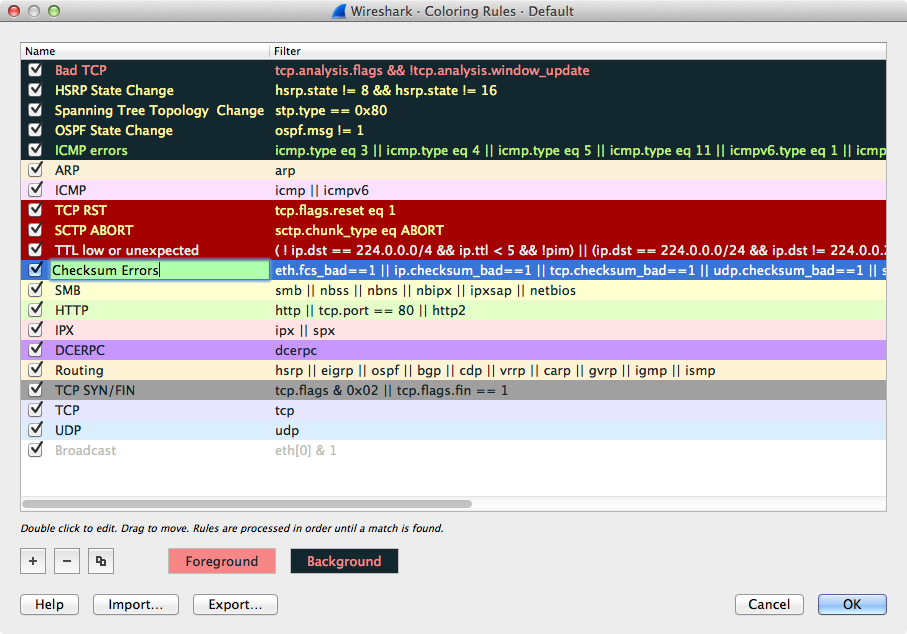
如果这是第一次使用“着色规则”对话框并且您使用的是默认配置配置文件,则应该看到默认规则,如上所示。
|
第一场比赛获胜 |
|---|---|
|
通常应在更一般的规则之前列出更具体的规则。例如,如果在DNS之前有UDP着色规则,则可能不会应用DNS规则(DNS通常通过UDP承载,UDP规则将首先匹配)。 |
您可以通过单击
您可以通过双击其名称或过滤器来编辑规则。在 图11.1中,“The Coloring Rules”对话框 “正在编辑规则”Checksum Errors“的名称。单击
颜色选择器外观取决于您的操作系统。显示了macOS颜色选择器。选择所需数据包的颜色,然后单击“
图11.3“使用Wireshark的彩色滤镜”显示了Wireshark中使用的几个彩色滤镜的示例。请注意,帧详细信息显示应用了“错误TCP”规则规则以及匹配过滤器。
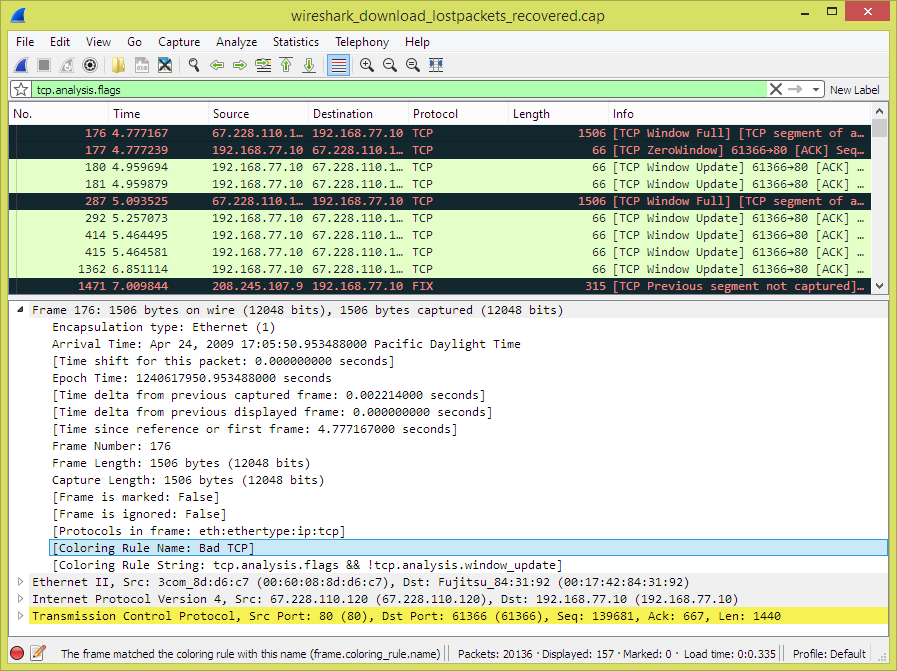
用户可以控制如何解析协议。
每个协议都有自己的解剖器,因此解剖完整的数据包通常会涉及多个解剖器。由于Wireshark试图为每个数据包找到正确的解剖器(使用静态“路由”和启发式“猜测”),它可能会在您的特定情况下选择错误的解剖器。例如,Wireshark将不知道您是否在不常见的TCP端口上使用通用协议,例如在TCP端口800上使用HTTP而不是标准端口80。
有两种方法可以控制协议解析器之间的关系:完全禁用协议解析器或暂时转移Wireshark调用解剖器的方式。
“启用协议”对话框允许您启用或禁用特定协议。默认情况下启用所有协议。禁用协议后,无论何时遇到协议,Wireshark都会停止处理数据包。
|
注意 |
|---|---|
|
禁用协议将阻止显示有关更高层协议的信息。例如,假设您禁用了IP协议并选择了包含以太网,IP,TCP和HTTP信息的数据包。将显示以太网信息,但IP,TCP和HTTP信息不会 - 禁用IP将阻止它和其他协议显示。 |
要启用或禁用协议选择
要禁用或启用协议,只需使用鼠标单击它或在突出显示协议时按空格键。请注意,在“启用的协议”对话框处于活动状态时键入协议名称的前几个字母将暂时打开搜索文本框并自动选择第一个匹配的协议名称(如果存在)。
您必须使用“
您可以选择以下操作:
- 文件和文件夹。
“解码为”功能可让您暂时转移特定协议解析。例如,如果您在网络上进行一些不常见的实验,这可能很有用。
解码由于是通过选择访问
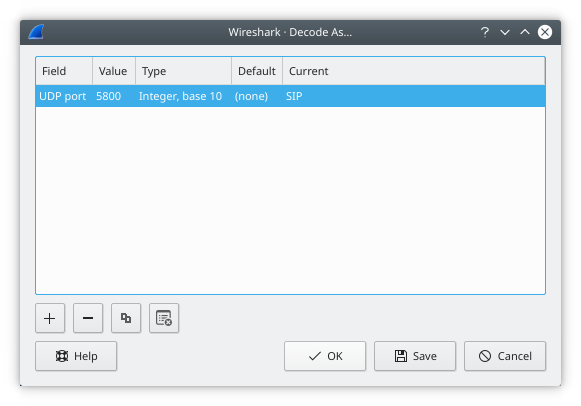
此对话框的内容取决于打开时所选的数据包。
如果您退出Wireshark的或更改个人资料,除非你保存在这些条目,这些设置将丢失指定的解码器显示用户...窗口(第11.4.3节,“显示用户指定解码器”)。

您可以设置许多首选项。只需选择
- “
- “
- “

在“捕获”首选项中,可以为计算机上可用的接口配置多个选项。选择“捕获”窗格,然后按“

每行包含计算机上可用的每个界面的选项。
- 设备:操作系统提供的设备名称。
- 描述:由操作系统提供。
- 默认链路层:每个接口可以提供多种链路层头类型。这里选择的默认链接层是您第一次启动Wireshark时使用的链接层。 当您开始捕获时,也可以在第4.5节“捕获选项”对话框中更改此值。有关详细说明,请参见 第4.12节“链路层标头类型”。
- 注释:用户提供了界面的描述。此注释将用作描述而不是操作系统描述。
- 隐藏?:启用此选项可以隐藏程序其他部分的界面。
配置文件可用于配置和使用多组首选项和配置。选择
存储在每个配置文件中的配置文件包
- 首选项(首选项)(第11.5节“首选项”)
- 捕获过滤器(cfilters)(第6.6节“定义和保存过滤器”)
- 显示过滤器(dfilters)(第6.6节“定义和保存过滤器”)
- 着色规则(colorfilters)(第11.3节“分组着色”)
- 禁用协议(disabled_protos)(第11.4.1节“”启用协议“对话框”)
-
用户可访问表:
- 自定义HTTP标头(custom_http_header_fields)
- 自定义IMF标头(imf_header_fields)
- 自定义LDAP AttributeValue类型(custom_ldap_attribute_types)
- 显示过滤器宏(dfilter_macros)(第11.8节“显示过滤器宏”)
- ESS类别属性(ess_category_attributes)(第11.9节“ESS类别属性”)
- MaxMind数据库路径(maxmind_db_paths)(第11.10节“MaxMind数据库路径”)
- K12协议(k12_protos)(第11.19节,“Tektronix K12xx / 15 RF5协议表”)
- 对象标识符名称和关联的语法(第11.12节“对象标识符”)
- PRES用户上下文列表(pres_context_list)(第11.13节“PRES用户上下文列表”)
- SCCP用户表(sccp_users)(第11.14节“SCCP用户表”)
- SNMP企业特定陷阱类型(snmp_specific_traps)(第11.17节“SNMP企业特定陷阱类型”)
- SNMP用户(snmp_users)(第11.18节“SNMP用户表”)
- 用户DLT表(user_dlts)(第11.20节“用户DLT协议表”)
- IKEv2解密表(ikev2_decryption_table)(第11.11节“IKEv2解密表”)
- 更改了解剖器分配(decode_as_entries),可以在“Decode As ...”对话框中设置(第11.4.2节“用户指定的解码”),并进一步保存在“用户指定的解码...”窗口中(第11.4节) .3,“显示用户指定的解码”)。
- 最近的一些设置(最近),例如主窗口中的窗格大小(第3.3节“主窗口”),数据包列表中的列宽(第3.17节,“”数据包列表“窗格”),所有选项都在
所有其他配置都存储在个人配置文件夹中,并且对所有配置文件都是通用的。
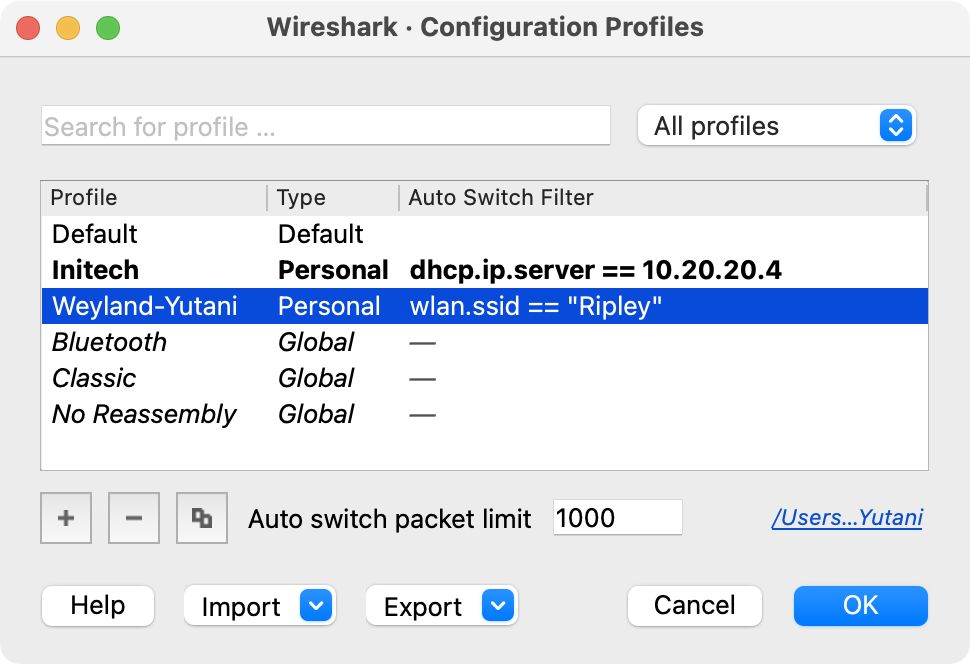
- 新(+)
- 创建新的个人资料。创建的配置文件的名称为“新配置文件”,并突出显示,以便您可以更轻松地更改它。
- 删除( - )
- 删除所选的配置文件。这包括此配置文件中使用的所有配置文件。无法删除“默认”配置文件或全局配置文件。
- 复制
- 复制所选的配置文件。这将复制列表中当前所选配置文件的配置。创建的配置文件的名称与复制的配置文件相同,文本“(复制)”并突出显示,以便您可以更轻松地更改它。
- 好
- 此按钮保存所有更改,应用选定的配置文件并关闭对话框。
- 取消
- 关闭此对话框。这将放弃未保存的设置,不会添加新配置文件,也不会删除已删除的配置文件。
- 救命
- 显示此帮助页面。
用户表编辑器用于管理wireshark中的各种表。它的主对话框与第11.3节“分组着色”的工作方式非常相似。
显示过滤器宏是一种为复杂过滤器创建快捷方式的机制。例如,定义名为tcp_conv的显示过滤器宏,其文本为
(ip.src == $ 1和ip.dst == $ 2和tcp.srcport == $ 3和tcp.dstport == $ 4)
或(ip.src == $ 2和ip.dst == $ 1和tcp.srcport == $ 4和tcp.dstport == $ 3)
将允许使用像
$ {tcp_conv:10.1.1.2; 10.1.1.3; 1200; 1400}
而不是键入整个过滤器。
显示过滤器宏可以使用用户表进行管理,如 第11.7节“用户表”中所述,方法是从菜单中选择
- Name
- 宏的名称。
- 文本
- 它的替换文本使用$ 1,$ 2,$ 3,...作为输入参数。
Wireshark使用此表将ESS安全类别属性映射到文本表示。要放在此表中的值通常位于XML SPIF中,该SPIF用于定义安全标签。
此表是一个用户表,如第11.7节“用户表”中所述,包含以下字段:
- 标记集
- 表示类别标记集的对象标识符。
- 值
- 表示类别的值(标签和证书值)。
- Name
- 值的文本表示。
如果您的Wireshark副本支持 MaxMind的 MaxMindDB库,则可以使用其数据库将IP地址与国家/地区,引用,自治系统编号和其他信息进行匹配。有些数据库是免费提供的,而其他数据库 则需要许可费。有关更多信息,请 访问MaxMind网站。
MaxMind数据库的配置是一个用户表,如第11.7节“用户表”中所述,其中包含以下字段:
- 数据库路径名
- 这指定了包含MaxMind数据文件的目录。任何以.mmdb结尾的文件都将被自动加载。
为您的数据文件的位置是你的,但/usr/share/GeoIP 和/var/lib/GeoIP上常见的Linux和C:\ProgramData\GeoIP,C:\Program Files\Wireshark\GeoIP可能是在Windows不错的选择。
以前版本的Wireshark支持MaxMind的原始GeoIP Legacy数据库格式。它们的配置类似于上面的MaxMindDB文件,除了GeoIP文件必须以Geo开头并以.dat结尾。它们不再受支持,MaxMind于2018年4月停止分发GeoLite Legacy数据库。
如果提供必要的信息,Wireshark可以解密IKEv2(Internet密钥交换版本2)数据包的加密有效负载。请注意,您只能使用此功能解密IKEv2数据包。如果要解密IKEv1数据包或ESP数据包,请分别使用ISAKMP协议首选项下的“日志文件名”设置或ESP协议首选项下的设置。
这由用户表处理,如第11.7节“用户表”中所述,包含以下字段:
- 发起人的SPI
- 启动器的IKE_SA的SPI。此字段采用不带“0x”前缀的十六进制字符串,长度必须为16个十六进制字符(表示8个八位字节)。
- 响应者的SPI
- 响应者的IKE_SA的SPI。此字段采用不带“0x”前缀的十六进制字符串,长度必须为16个十六进制字符(表示8个八位字节)。
- SK_ei
- 用于加密/解密从启动器到响应器的IKEv2数据包的密钥。该字段采用不带“0x”前缀的十六进制字符串,其长度必须满足所选加密算法的要求。
- SK_er
- 用于加密/解密从响应者到发起者的IKEv2数据包的密钥。该字段采用不带“0x”前缀的十六进制字符串,其长度必须满足所选加密算法的要求。
- 加密演算法
- IKE_SA的加密算法。
- SK_ai
- 用于计算从响应者到发起者的IKEv2数据包的完整性校验和数据的密钥。该字段采用不带“0x”前缀的十六进制字符串,其长度必须满足所选完整性算法的要求。
- SK_ar
- 用于计算从发起方到响应方的IKEv2数据包的完整性校验和数据的密钥。该字段采用不带“0x”前缀的十六进制字符串,其长度必须满足所选完整性算法的要求。
- 完整性算法
- IKE_SA的完整性算法。
许多使用ASN.1的协议使用对象标识符(OID)来唯一标识某些信息。在许多情况下,它们用于扩展机制,以便可以定义新的对象标识符(和关联的值)而无需更改基本标准。
虽然Wireshark了解许多OID及其关联值的语法,但可扩展性意味着可能遇到其他值。
Wireshark使用此表允许用户定义Wireshark不知道的对象标识符的名称和语法(例如,私有定义的X.400扩展名)。它还允许用户覆盖Wireshark确实知道的对象标识符的名称和语法(例如,将名称“id-at-countryName”更改为“c”)。
此表是一个用户表,如第11.7节“用户表”中所述,包含以下字段:
- OID
- 对象标识符的字符串表示形式,例如“2.5.4.6”。
- Name
- 解析对象标识符时Wireshark应显示的名称,例如(“c”);
- 句法
- 与对象标识符关联的值的语法。这必须是Wireshark已经知道的语法之一(例如“PrintableString”)。
当捕获不包含具有对话的表示上下文定义列表的PRES包时,Wireshark使用此表将表示上下文标识符映射到给定的对象标识符。
此表是一个用户表,如第11.7节“用户表”中所述,包含以下字段:
- 上下文ID
- 表示此关联有效的表示上下文标识符的整数。
- 语法名称OID
- 表示抽象语法名称的对象标识符,它定义通过此关联承载的协议。
Wireshark使用此表将特定协议映射到SCCP的某个DPC / SSN组合。
此表是一个用户表,如第11.7节“用户表”中所述,包含以下字段:
- 网络指标
- 表示此关联有效的网络指示符的整数。
- 被称为DPC
- 表示此关联有效的dpcs的整数范围。
- 被称为SSN
- 表示此关联有效的ssns的整数范围。
- 用户协议
- 通过此关联承载的协议
如果您的Wireshark副本支持libSMI,您可以在此处指定MIB和PIB模块的列表。COPS和SNMP解析器可以使用它们来解决OID。
- 模块名称
- 模块的名称,例如IF-MIB。
如果您的Wireshark副本支持libSMI,则可以在此处指定一个或多个MIB和PIB模块的路径。
- 目录名称
- 模块目录,例如
/usr/local/snmp/mibs。Wireshark自动为您的系统使用标准SMI路径,因此您通常不必在此处添加任何内容。
Wireshark使用此表将特定陷阱值映射到陷阱PDU中的用户定义描述。描述在分组详细信息特定陷阱元素中示出。
此表是一个用户表,如第11.7节“用户表”中所述,包含以下字段:
- 企业OID
- 表示生成陷阱的对象的对象标识符。
- 陷阱ID
- 表示特定陷阱代码的整数。
- 描述
- 要在数据包详细信息中显示的说明。
Wireshark使用此表来验证身份验证并解密加密的SNMPv3数据包。
此表是一个用户表,如第11.7节“用户表”中所述,包含以下字段:
- 引擎ID
- 如果给定此条目将仅用于引擎ID为this的数据包。此字段采用0102030405形式的十六进制字符串。
- 用户名
- 这是userName。当单个用户为不同的SNMP引擎拥有多个密码时,如果您需要捕获所有引擎ID(空),则该条目应该是最后一个,那么将采用匹配两者的第一个条目。
- 验证模型
- 使用哪种auth模型(“MD5”或“SHA1”)。
- 密码
- 验证密码。将\ xDD用于不可打印的字符。必须输入十六进制密码作为\ xDD字符序列。例如,十六进制密码010203040506必须输入为 \ x01 \ x02 \ x03 \ x04 \ x05 \ x06。该\字符必须被视为不可打印的字符,也就是说,它必须为输入\ x5C或\ x5c。
- 隐私协议
- 使用哪种加密算法(“DES”或“AES”)。
- 隐私密码
- 隐私密码。将\ xDD用于不可打印的字符。必须输入十六进制密码作为\ xDD字符序列。例如,十六进制密码010203040506必须输入为\ x01 \ x02 \ x03 \ x04 \ x05 \ x06。该\ 字符必须被视为不可打印的字符,也就是说,它必须为输入\ x5C或\ x5c。
Tektronix K12xx / 15 rf5文件格式使用辅助文件(* .stk)来识别某个接口使用的各种协议。Wireshark不读取这些stk文件,它使用一个表来帮助它识别要使用的最低层协议。
Stk文件到协议匹配由用户表处理,如第11.7节“用户表”中所述,具有以下字段:
- 匹配字符串
- 对于stk文件名的部分匹配,第一个匹配获胜,因此如果您有特定案例和一般案例,则特定案例必须首先出现在列表中。
- 协议
- 这是封装协议的名称(分组数据中的最低层),它可以是协议的名称(例如mtp2,eth_witoutfcs,sscf-nni),也可以是封装协议的名称和“应用程序”协议用冒号分隔它(例如sscop:sscf-nni,sscop:alcap,sscop:nbap,...)
当pcap文件使用其中一个用户DLT(147到162)时,wireshark使用此表来了解每个用户DLT使用哪种协议。
此表是一个用户表,如第11.7节“用户表”中所述,包含以下字段:
- DLT
- 其中一个用户dlts。
- 有效载荷协议
- 这是有效载荷协议的名称(分组数据中的最低层)。(例如,“eth”表示以太网,“ip”表示IPv4)
- 标题大小
- 如果存在标头协议(在有效载荷协议之前),则告知该标头的大小。值为0将禁用标头协议。
- 标头协议
- 要使用的标头协议的名称(默认使用“数据”)。
- 预告片大小
- 如果有一个预告片协议(在有效载荷协议之后),这将告诉该预告片的大小。值为0将禁用预告片协议。
- 预告片协议
- 要使用的预告片协议的名称(默认使用“数据”)。
MATE:Meta分析和跟踪引擎
什么是MATE?好吧,为了保持简短,使用MATE,您可以创建显示过滤器引擎的用户可配置扩展。
MATE的目标是使用户能够根据从相关帧中提取的信息或关于帧如何相互关联的信息来过滤帧。编写MATE是为了帮助解决网关和其他“使用”涉及更多协议的系统。然而,MATE也可以用于分析关于分组之间的交互的其他问题,例如响应时间,事务的不完整性,一组PDU中的某些属性的存在/不存在等。
MATE是一个Wireshark插件,允许用户指定不同的帧如何相互关联。为此,MATE从帧树中提取数据,然后使用该信息尝试根据MATE的配置方式对帧进行分组。一旦PDU相关,MATE将创建一个“协议”树,其中包含用户可以过滤的字段。对于所有相关帧,字段几乎相同,因此可以基于出现在某些相关帧中的属性来过滤包含更多协议的多个帧的完整会话。除此之外,MATE允许根据响应时间,组中PDU的数量以及更多来过滤帧。
到目前为止,MATE已被用于:
- 只知道主叫号码,使用各种协议过滤所有呼叫数据包。(MATE的最初目标)
- 根据其中一个“段”的释放原因,使用各种协议过滤所有呼叫的所有数据包。
- 从非常“密集”的捕获中推断出缓慢的事务。(查找超时请求)
- 查找未完成的交易(无回复)
- 通过更多网关/代理关注请求。
- 更多...
这些是尝试MATE的步骤:
如果一切顺利,您的数据包详细信息可能如下所示:
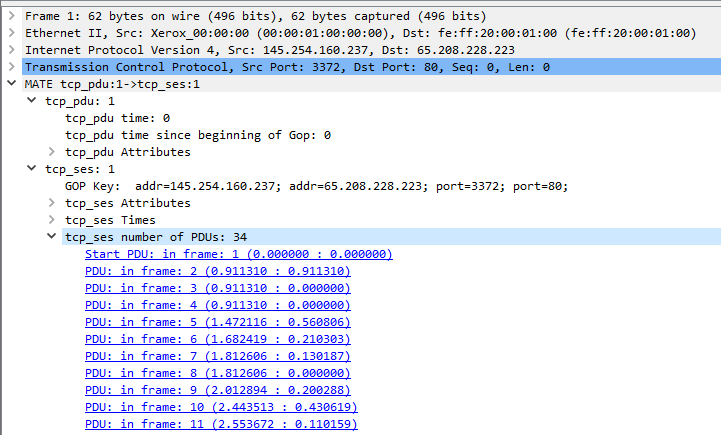
MATE基于帧中包含的信息创建可过滤树,这些帧与从其他帧获得的信息共享某些关系。这种关系的形成方式在配置文件中描述。配置文件告诉MATE什么是PDU以及如何将其与其他PDU相关联。
MATE分析每个帧以从该帧的“协议”树中提取相关信息。提取的信息包含在MATE PDU中; 这些包含从树中获取的相关属性的列表。从现在开始,我将使用术语“PDU”来指代由MATE创建的对象,其中包含从帧中提取的相关信息; 我将使用“框架”来指代由预先分析框架的各种解剖器提取的“原始”信息。
对于每个PDU,MATE检查它是否属于现有的“PDU组”(Gop)。如果是,则将PDU分配给该Gop,并将任何新的相关属性移动到Gop的属性列表中。PDU以及何时属于Gops也在配置文件中描述。
每次为Gop分配一个新PDU时,MATE将检查它是否与条件匹配,使其属于“组群”(Gog)。当然,使Gop属于Gog的条件也是从配置文件中获取的。
一旦MATE完成分析帧,它将能够基于PDU,它们所属的Gops以及前者属于的任何Gog,为每个帧创建“协议”树。
如何告诉MATE要提取什么,如何对其进行分组,然后如何关联这些组是使用AVP和AVPL。
MATE中的信息包含在属性/值对(AVP)中。AVP由两个字符串组成:名称和值。AVP用于配置中,并且它们也有运营商。有多种方法可以使用这些运算符将AVP相互匹配。
AVP被分组为AVP列表(AVPL)。PDU,Gops和Gogs各有一个AVPL。他们的AVPL将以各种方式与来自配置文件的其他人匹配。
将指示MATE如何从帧中提取AVP以便创建具有AVPL的PDU。还将指示如何将该AVPL与其他类似PDU的AVPL相匹配以便将它们相关联。在MATE中,PDU之间的关系是Gop,它也有一个AVPL。MATE将配置其他AVPL,以对Gop的AVPL进行操作,将Gops组合成Gog。
对AVP和AVPL如何工作的充分理解是理解MATE如何工作的基础。
MATE用于关联不同帧的信息包含在属性/值对(AVP)中。AVP由两个字符串组成 - 名称和值。在配置中使用AVP时,也定义了运算符。有多种方法可以使用这些运算符将AVP相互匹配。
avp_name =“avp的值”
another_name =“1234是值”
名称是一个字符串,用于表示AVP的“种类”。除非名称相同,否则两个AVP将不匹配。
不应在名称中使用大写字符,也不要在以“。”或“_”开头的名称中使用大写字符。大写的名称是为配置参数保留的(我们称之为关键字); 没有什么可以禁止你将大写字符串用于其他东西,但它可能会令人困惑。除了本文档中的关键字,参考手册,示例和基础库之外,我将避免使用大写单词。以“。”开头的名称也会非常混乱,因为在旧语法中,AVPL转换使用以“。”开头的名称来表示它们属于替换AVPL。
该值是在配置(对于配置AVP)中设置的字符串,或者是在从帧的树中提取有趣字段时由wireshark设置的字符串。从字段中提取的值使用与在过滤字符串中相同的表示,但不使用引号。
名称只能包含字母数字字符“_”和“。”。名称以运营商结束。
即使数字是数字,该值也将作为字符串处理。如果值中有任何空格,则值必须在引号“”之间。
ip_addr = 10.10.10.11,
tcp_port = 1234 ,binary_data =
01:23:45:67:89:ab:cd:ef,
parameter12 = 0x23aa,
parameter_with_spaces =“此值包含空格”
操作员描述了两个具有相同名称的AVP可能匹配的方式。请记住,除非它们的名称相同,否则两个AVP将不匹配。在MATE中,总是在从帧(称为数据AVP)和配置的AVP提取的AVP之间进行匹配操作。
目前定义的MATE的AVP匹配运算符是:
AVPL是一组可以与其他AVPL匹配的不同AVP。每个PDU,Gop和Gog都有一个包含有关它的信息的AVPL。MATE用于对Pdus和Gops进行分组的规则是AVPL操作。
在给定的AVPL中永远不会有两个相同的AVP。但是,只要它们的值不同,我们就可以在AVPL中拥有多个具有相同名称的AVP。
一些AVPL示例:
(addr = 10.20.30.40,addr = 192.168.0.1,tcp_port = 21,tcp_port = 32534,user_cmd = PORT,data_port = 12344,data_addr = 192.168.0.1)
(addr = 10.20.30.40,addr = 192.168.0.1,channel_id = 22:23,message_type = Setup,calling_number = 1244556673)
(addr = 10.20.30.40,addr = 192.168.0.1,ses_id = 01:23:45:67:89:ab:cd:ef)
(user_id = pippo,calling_number = 1244556673,assigned_ip = 10.23.22.123)
在MATE中有两种类型的AVPL:
- 数据AVPL包含从帧中提取的信息。
- 操作来自配置的AVPL,用于告诉MATE如何根据数据AVPL关联项目。
数据AVPL可以通过各种方式对操作AVPL进行操作:
- 松散匹配:如果每个AVPL的至少一个AVP匹配,则匹配。如果它匹配,它将返回一个AVPL,其中包含与操作数AVP匹配的操作数AVPL中的所有AVP。
- “每个”匹配:如果运营商AVPL的AVP都不能与操作数AVPL中的当前AVP匹配,则将匹配,即使并非所有运营商的AVP都匹配。如果它匹配,它将返回包含来自操作数AVPL的所有AVP的AVPL,其与运营商AVPL中的一个AVP匹配。
- 严格匹配:当且仅当运营商的每个AVP在操作数AVPL中至少有一个匹配时才匹配。如果匹配,它将从匹配的操作数返回包含AVP的AVPL。
- 还有一个在AVPL之间执行的合并操作,其中操作数AVPL中不存在但存在于操作数中的所有AVP将被添加到操作数AVPL中。
- 除此之外还有转换 - 匹配AVPL和AVPL的组合。
MATE对框架的分析分三个阶段进行:
- 在第一阶段,MATE尝试从帧的协议树中提取MATE Pdu。如果MATE的配置有一个Pdu声明,其中Proto包含在帧中,MATE将创建一个Pdu 。
- 在第二阶段,如果从帧中提取了Pdu,MATE将尝试通过匹配Gop声明给出的关键标准将其分组到其他Pdus到Gop(Pdus组)。如果没有Gop还没有Pdu的关键标准,MATE将尝试为它创建一个新的Gop,如果它与Gop声明中给出的Start标准相匹配 。
- 在第三阶段,如果有Pdu的Gop,MATE将尝试使用Gog声明的成员标准给出的标准将此Gop与其他Gops组合成Gog(组) 。
提取和匹配逻辑来自MATE的配置; MATE的配置文件由mate.config首选项声明。默认情况下,它是一个空字符串,表示:不配置MATE。
配置文件告诉MATE在帧中寻找什么; 如何制作PDU; PDU如何与其他类似的PDU相关联到Gops; 以及Gops如何与Gogs联系起来。
MATE配置文件是声明列表。有4种类型的声明:Transform,Pdu,Gop和Gog。
MATE将在每个帧的树中查看是否有要提取的有用数据,如果有,它将创建一个或多个包含有用信息的PDU对象。
MATE分析的第一部分是“PDU提取”; 有各种“动作”用于指示MATE必须从当前帧的树中提取到MATE的PDU中。
MATE将为帧中存在的Proto类型的每个不同原型场制作Pdu。MATE将从字段树中获取在第12.8.1节“Pdsu的配置操作”声明中定义的字段,其中帧中的初始偏移量在当前Proto的边界内以及给定的Transport和Payload语句的边界内。
Pdu dns_pdu Proto dns Transport ip {
Extract addr来自ip.addr;
从dns.id中提取dns_id;
从dns.flags.response中提取dns_resp;
};
MATE将为帧中存在的Proto类型的每个不同原型场制作Pdu。MATE将从字段树中获取在第12.8.1节“Pdsu的配置动作”AVPL 中定义的那些字段,其帧中的初始偏移在当前Proto的边界内以及各种分配的传输的边界内。
一旦MATE找到了一个Proto字段,可以从帧中创建Pdu,它将在帧中向后移动,寻找相应的Transport字段。之后,它将为声明为其值的每个字段实例创建名为AVPL其余部分中的每个AVP的AVP。
有时我们需要来自多个传输协议的信息。在这种情况下,MATE将检查向后看的帧以查找给定堆栈中的各种 传输协议。MATE将仅选择帧中每个“协议”最近的传输边界。
通过这种方式,我们将为帧中出现的每个Proto提供所有Pdus ,以匹配其相对传输。
Pdu isup_pdu Proto isup Transport mtp3 / ip {
Extract m3pc from mtp3.dpc;
从mtp3.opc中提取m3pc;
从isup.cic中提取cic;
从ip.addr中提取addr;
从isup.message_type中提取isup_msg;
};
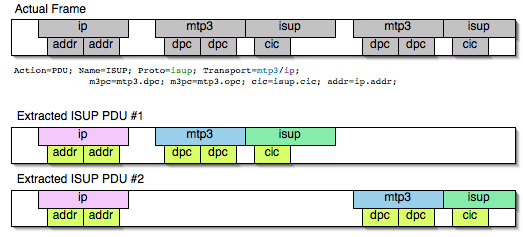
这允许将正确的传输分配给Pdu,从而避免重复的传输协议条目(例如,在通过ip隧道传输ip的情况下)。
Pdu ftp_pdu Proto ftp Transport tcp / ip {
Extract addr来自ip.addr;
从tcp.port中提取端口;
从ftp.command中提取ftp_cmd;
};
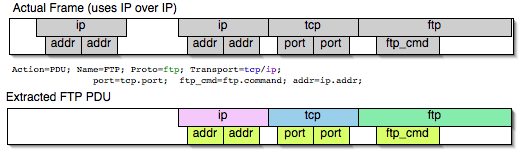
除了强制性传输之外,还有一个可选的Payload 语句,它几乎与Transport一样工作,但是指的是Proto范围之后的元素。在有效载荷协议可能不出现在Pdu中但Pdu属于同一类别的情况下,它很有用。
Pdu mmse_over_http_pdu Proto http Transport tcp / ip { Payload mmse; 从ip.addr中提取addr; 从tcp.port中提取端口; 提取方法来自http.request.method; 从http.content_type中提取内容; 从http.request中提取http_rq; 从http.response.code中提取resp; 从http.host中提取主机; 从mmse.transaction_id中提取trx; 从mmse.message_type中提取msg_type; 从mmse.status中提取notify_status; 从mmse.response_status中提取send_status; };
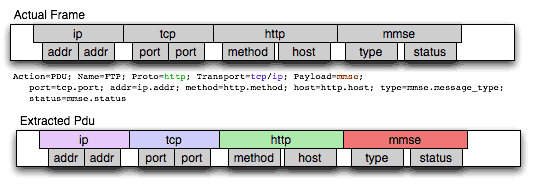
在某些情况下,我们不希望MATE创建PDU,除非某些提取的属性符合或不符合某些条件。为此,我们使用Pdu声明的Criteria语句。
Pdu isup_pdu Proto isup Transport mtp3 / ip { ... //只有当没有点代码' 1234'Mriteria Reject Strict(m3pc = 1234)时,MATE才会创建isup_pdu PDU 。 }; Pdu ftp_pdu Proto ftp Transport tcp / ip { ... //只有当他们进入我们的ftp_server 标准的端口21时,MATE才会创建ftp_pdu PDU(Addr = 10.10.10.10,port = 21); };
该标准语句给出一个动作(接受或拒绝),匹配模式(严格的,松散或每个)和AVPL针对其匹配当前所提取的一个。
一旦将字段提取到Pdu的AVPL中,MATE将对其应用任何声明的变换。应用变换的方式及其工作方式将在后面介绍。然而,知道一旦创建了Pdu的AVPL,它可能在被分析之前被转换是有用的。这样我们就可以按摩数据来简化分析。
每个成功创建的Pdu都会在框架剖析中添加一个MATE树。如果Pdu与任何Gop无关,Pdu的树将只包含Pdu的信息,如果它被分配给Gop,树也将包含Gop项目,同样适用于Gog级别。
mate dns_pdu:1
dns_pdu:1
dns_pdu time:3.750000
dns_pdu属性
dns_resp:0
dns_id:36012
addr:10.194.4.11
addr:10.194.24.35
Pdu的树包含一些可过滤的字段
- mate.dns_pdu将包含“dns_pdu”Pdu的编号
- mate.dns_pdu.RelativeTime将包含自捕获开始以来经过的时间(以秒为单位)
-
树将包含Pdu的各种属性,这些属性都是字符串(在过滤器中用作“10.0.0.1”,而不是10.0.0.1)
- mate.dns_pdu.dns_resp
- mate.dns_pdu.dns_id
- mate.dns_pdu.addr
一旦MATE创建了Pdus,它就会转到Pdu分析阶段。在PDU分析阶段,MATE将尝试将相同类型的Pdus分组为“Pdus组”(aka * Gop * s),并将一些AVP从Pdu的AVPL复制到Gop的AVPL。
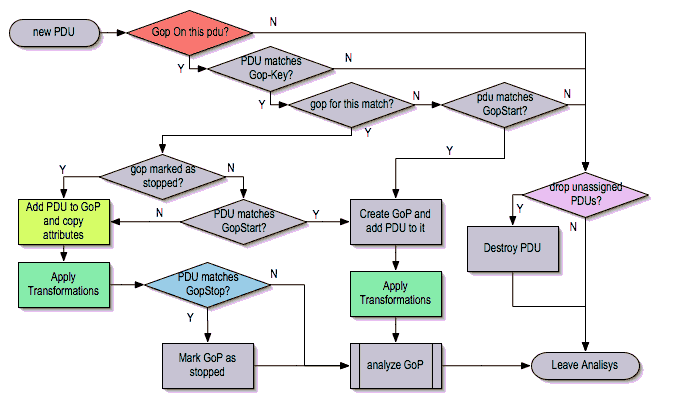
给定一个Pdu,MATE将要做的第一件事是检查给定Pdu类型的配置中是否有任何Gop声明。如果是这样,它将使用其 MatchAVPL将其与Pdu的AVPL相匹配; 如果它们不匹配,则分析阶段完成。如果存在匹配,则AVPL是Gop的候选密钥,其将用于搜索Gop的索引以用于分配当前PDU的Gop。如果没有这样的Gop并且这个Pdu 与Pdu类型的Gop声明的Start标准不匹配 ,则Pdu将保持未分配状态,并且仅进行分析阶段。
Gop ftp_ses在ftp_pdu上匹配(addr,addr,port,port);
Gop dns_req在dns_pdu上匹配(addr,addr,dns_id);
Gop isup_leg on isup_pdu Match(m3pc,m3pc,cic);
如果匹配,候选键将用于搜索Gop的索引,以查看是否已经有Gop以相同的方式匹配Gop的键。如果Gops集合中存在这样的匹配,并且PDU 与其类型的Start AVPL 不匹配,则PDU将被分配给匹配的Gop。如果是 开始匹配,MATE将检查Gop是否已经停止。如果Gop已经停止,将创建一个新的Gop并将替换Gop索引中的旧Gop。
Gop ftp_ses在ftp_pdu上匹配(addr,addr,port,port){ Start(ftp_cmd = USER); }; Gop dns_req在dns_pdu上匹配(addr,addr,dns_id){ Start(dns_resp = 0); }; Gop isup_leg On isup_pdu Match(m3pc,m3pc,cic){ Start(isup_msg = 1); };
如果没有为Gop给出Start,则其AVPL与现有Gog的键匹配的Pdu将作为Gop的开始。
一旦我们知道Gop存在且Pdu已被分配给它,MATE将复制到Gop的AVPL中所有与该密钥匹配的属性以及与Extra AVPL 匹配的Pdu的AVPL的任何AVP 。
Gop ftp_ses在ftp_pdu上匹配(addr,addr,port,port){ Start(ftp_cmd = USER); 额外的(pasv_prt,pasv_addr); }; Gop isup_leg On isup_pdu Match(m3pc,m3pc,cic){ Start(isup_msg = 1); 额外的(打电话,打电话); };
一旦将Pdu分配给Gop,MATE将检查Pdu是否与Stop匹配,如果发生,MATE将标记Gop停止。即使在停止之后,也可以为Gop分配匹配其键的新Pdus,除非这样的Pdu与Start匹配。如果是这样,MATE将改为从Pdu开始创建一个新的Gop。
Gop ftp_ses在ftp_pdu上匹配(addr,addr,port,port){ Start(ftp_cmd = USER); 停止(ftp_cmd = QUIT); //对QUIT命令的响应将分配给相同的Gop Extra(pasv_prt,pasv_addr); }; Gop dns_req在dns_pdu上匹配(addr,addr,dns_id){ Start(dns_resp = 0); 停止(dns_resp = 1); }; Gop isup_leg On isup_pdu Match(m3pc,m3pc,cic){ Start(isup_msg = 1); // IAM 停止(isup_msg = 16); // RLC Extra(调用,调用); };
如果没有为给定的Gop声明Stop标准,Gop将在创建后立即停止。但是,与任何其他Gop一样,匹配Gop密钥的Pdus仍将分配给Gop,除非它们与Start条件匹配,在这种情况下,将创建使用相同密钥的新Gop。
对于包含属于Gop的Pdu的每个帧,MATE将为该Gop创建一个树。
下面的示例表示由dns_pdu和dns_req 示例创建的树。
...
mate dns_pdu:6-> dns_req:1
dns_pdu:6
dns_pdu time:2.103063
dns_pdu自Gop开始以来的时间:2.103063
dns_req:1
dns_req属性
dns_id:36012
addr:10.194.4.11
addr:10.194.24.35
dns_req时间
dns_req开始时间:0.000000
dns_req保持时间:2.103063
dns_req持续时间:2.103063
dns_req PDU数量:2
启动PDU:帧1中
停止PDU:帧6(2.103063:2.103063)
dns_pdu属性
dns_resp:1
dns_id:36012
addr:10.194.4.11
addr:10.194.24.35
除了pdu的树之外,这个包含有关属于Gop的Pdus之间关系的信息。那样我们就有:
- mate.dns_req,其中包含此dns_req Gop的id。这将出现在属于dns_req Gops的帧中。
- mate.dns_req.dns_id和mate.dns_req.addr,表示复制到Gop中的属性的值。
-
Gop的计时器
- mate.dns_req.StartTime从捕获开始到Gop开始的时间(以秒为单位)。
- mate.dns_req。在开始Pdu和分配给该Gop的停止Pdu之间传递的时间(仅当已为Gop声明了Stop条件且匹配的Pdu已到达时才创建)。
- mate.dns_req.Duration时间在开始Pdu和分配给此Gop的最后一个Pdu之间传递。
-
mate.dns_req.NumOfPdus属于这个Gop的Pdus的数量
- 这个Gop的pdus帧号的可过滤列表
请注意,Gop有两个“计时器”:
- 时间,仅为已停止的Gops定义,并给出在 Start和 Stop Pdus之间传递的时间。
- 持续时间,为其状态的每个Gop方案定义,并给出在其开始 Pdu和分配给该Gop的最后一个Pdu之间传递的时间。
所以:
- 我们可以过滤属于已用mate.xxx.Time停止的 Gops的Pdus
- 我们可以使用mate.xxx && mate.xxx.Time过滤属于unstopped Gops的Pdus
- 我们可以使用mate.xxx.Duration过滤属于已停止的Gops的Pdus
- 我们可以过滤掉属于Gops的Pdus,它们使用mate.xxx.Time> 0.5花费更多(或更少)0.5s的时间(您可以尝试使用这些作为颜色过滤器以找出响应时间开始增长的时间)
当Gops被创建时,或者当他们的AVPL改变时,Gops被(重新)分析以检查它们是否匹配现有的一组组(Gog)或者可以创建一个新的组。Gop分析分为两个阶段。在第一阶段,检查仍然未分配的Gop以验证它是否属于已经存在的Gog或者可以创建新的Gog。第二阶段最终检查Gog并在Gogs索引中注册其键。
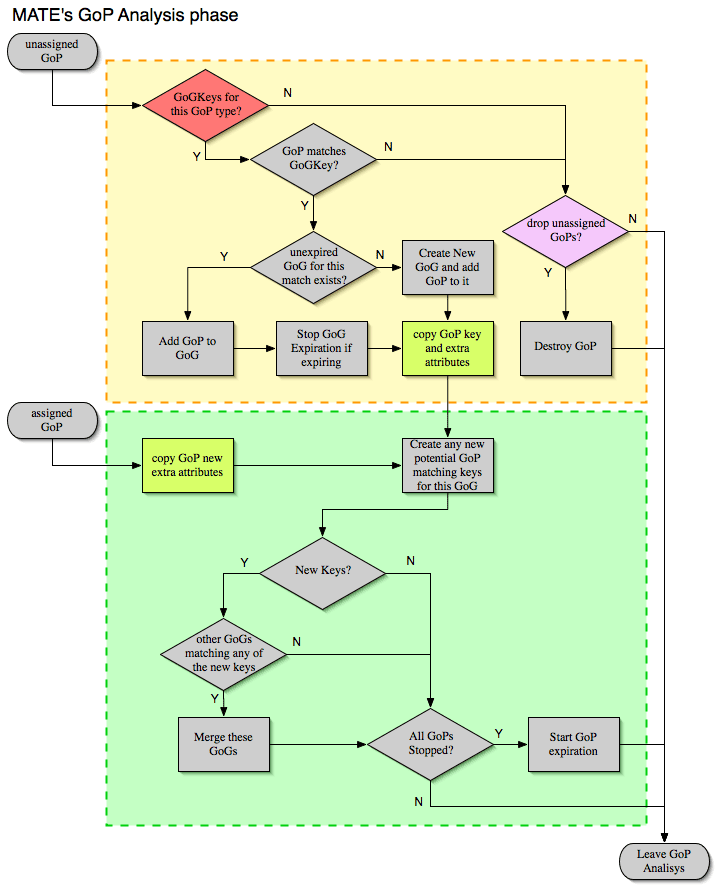
作者有几个原因认为需要重新实现此功能,因此在不久的将来可能会有很大的改变。文档的这一部分反映了截至Wirehark 0.10.9的MATE版本; 在未来的版本中,这将改变。
然后我们必须告诉MATE在候选Gops中寻找匹配的内容。
Gog web_use {
Member http_ses(host);
成员dns_req(主持人);
};
通常,除了用于匹配的属性之外的其他属性也会很有趣。为了从Gop复制到Gog其他有趣的属性,我们可能会像Gops一样使用Extra。
Gog web_use {
...
Extra(cookie);
};
伙计http_pdu:4-> http_req:2-> http_use:1
http_pdu:4
http_pdu时间:1.309847
http_pdu时间从Gop开始:0.218930
http_req:2
...(gop的树为http_req:2)..
http_use:1
http_use属性
主机:www.example.com
http_use时间
http_use开始时间:0.000000
http_use持续时间:1.309847
GOP数量:3
dns_req:1
...(dns_req的gop树:1)..
http_req:1
...(gop的http_req的树:1)..
当前帧的http_req:2
我们可以过滤:
- mate.http_use.Gog的第一帧与分配给它的最后一帧之间经过的持续时间。
-
传递给Gog的属性
- mate.http_use.host
变换是一系列匹配规则,可选地通过附加的AVPL修改匹配结果来完成。这种修改可以是插入(合并)或替换。变换可以用作帮助程序来操纵项目的AVPL,然后再进行处理。它们在几种情况下非常有用。
AVPL转换以下列方式声明:
转换名称{
Match [Strict | Every | Loose] match_avpl [Insert | Replace] modify_avpl;
......
};
该名称是AVPL转换的句柄。它用于在稍后调用时引用变换。
在比赛的声明指示MATE以及如何来匹配数据AVPL如何,如果匹配成功修改数据AVPL什么。它们将按照调用时在配置文件中出现的顺序执行。
可选匹配模式限定符(Strict,Every或Loose)用于选择匹配模式,如上所述; Strict是默认值,可以省略。
可选的修改模式限定符指示MATE如何使用修改AVPL:
- 默认值插入(其可被省略)使modify_avpl 被合并到现有的数据AVPL,
- 该替换从数据AVPL原因所有匹配的AVP被 替换由modify_avpl。
所述modify_avpl可以是空的一个; 这在某些情况下对于插入和替换修改模式都很有用。
例子:
变换insert_name_and {
Match Strict(host = 10.10.10.10,port = 2345)Insert(name = JohnDoe);
};
如果它包含host = 10.10.10.10 和 port = 2345,则将name = JohnDoe添加到数据AVPL
变换insert_name_or {
Match Loose(host = 10.10.10.10,port = 2345)Insert(name = JohnDoe);
};
如果它包含host = 10.10.10.10 或 port = 2345,则将name = JohnDoe添加到数据AVPL
变换replace_ip_address {
Match(host = 10.10.10.10)替换(host = 192.168.10.10);
};
用host = 192.168.10.10替换原来的host = 10.10.10.10
转换add_ip_address {
Match(host = 10.10.10.10)(host = 192.168.10.10);
};
将(insert)host = 192.168.10.10添加(插入)到AVPL,同时保留原始主机= 10.10.10.10
变换replace_may_be_surprising {
匹配松散(a = aaaa,b = bbbb)替换(c = cccc,d = dddd);
};
给出以下结果:
- (a = aaaa,b = eeee)变换为(b = eeee,c = cccc,d = dddd)因为a = aaaa确实匹配所以它被替换而b = eeee不匹配所以它保持原样,
- (a = aaaa,b = bbbb)变换为(c = cccc,d = dddd),因为a = aaaa和b = bbbb确实匹配。
- 可以使用Transform语句为每个Item(Pdu,Gop或Gog)提供先前声明的Transforms列表。
- 每当项目的AVPL发生变化时,它将针对给予该项目的列表上的所有变换进行操作。列表中的变换从左到右应用。
- 在每个变换中,项目的AVPL将根据Transform的Match子句从最顶端的子句开始操作,直到所有子句都被尝试或直到其中一个成功。
MATE的变换可以用于许多不同的事情,例如:
使用Transforms,我们可以为Gop添加多个启动或停止条件。
变换start_cond { Match(attr1 = aaa,attr2 = bbb)(msg_type = start); 匹配(attr3 = www,attr2 = bbb)(msg_type = start); 匹配(attr5 ^ a)(msg_type =停止); 匹配(attr6 $ z)(msg_type =停止); }; Pdu pdu ... { ... 转换start_cond; } GOP GOP ... { 启动(MSG_TYPE =开始); 停止(msg_type =停止); ... }
变换标记{ Match(addr = 10.10.10.10,user = john)(john_at_host); 匹配(addr = 10.10.10.10,user = tom)(tom_at_host); } ... Gop my_gop ... { ... 变换标记; }
之后我们可以使用显示过滤器mate.gop.john_at_host或 mate.gop.tom_at_host
Transform direction_as_text { Match(src = 192.168.0.2,dst = 192.168.0.3)替换(direction = from_2_to_3); 匹配(src = 192.168.0.3,dst = 192.168.0.2)替换(direction = from_3_to_2); }; Pdu my_pdu Proto my_proto传输tcp / ip { 从ip.src中提取src; 从ip.dst中提取dst; 从ip.addr中提取addr; 从tcp.port中提取端口; 提取从tcp.flags.syn开始; 从tcp.flags.fin中提取stop; 从tcp.flags.rst中提取stop; 变换direction_as_text; } Gop的my_gop在my_pdu匹配(地址,ADDR,端口,端口){ ... 额外(方向); }
NAT在跟踪时可能会产生问题,但我们可以通过将NATed IP地址和路由器的以太网地址转换为非NAT地址轻松解决这个问题:
变换denat { Match(addr = 192.168.0.5,ether = 01:02:03:04:05:06)替换(addr = 123.45.67.89); 匹配(addr = 192.168.0.6,ether = 01:02:03:04:05:06)替换(addr = 123.45.67.90); 匹配(addr = 192.168.0.7,ether = 01:02:03:04:05:06)替换(addr = 123.45.67.91); } Pdu my_pdu Proto my_proto transport tcp / ip / eth { Extract ether from eth.addr; 从ip.addr中提取addr; 从tcp.port中提取端口; 改变变性; }
我们将展示一个MATE配置,它首先为每个DNS和HTTP请求创建Gops,然后根据主机将Gops绑定在一个Gop中。最后,我们将分成来自不同用户的不同Gogs请求。
加载此MATE配置后,我们可以:
- 使用mate.http_use.Duration> 5.5根据从DNS请求加载完整页面所需的时间来过滤帧,以解析其名称,直到最后一个图像被加载。
- 使用mate.http_use.client ==“10.10.10.20”&& mate.http_use.host ==“www.example.com” 来隔离与某个用户访问相关的DNS和HTTP数据包。
- 使用mate.http_req.Duration> 1.5过滤所有需要1.5秒以上才能完成的HTTP请求包。
完整的配置文件在这里: web.mate
注意:在这个例子中我用dns.qry.name这是自Wireshark的版本0.10.9定义。假设您已安装了配对插件,则可以使用当前的Wireshark版本对其进行测试。
首先,我们将告诉MATE如何为每个DNS请求/响应创建一个Gop。
MATE需要知道什么是DNS PDU。我们使用Pdu声明来描述它:
Pdu dns_pdu Proto dns Transport ip {
Extract addr来自ip.addr;
从dns.id中提取dns_id;
从dns.flags.response中提取dns_resp;
};
使用Proto dns,我们告诉MATE每次找到dns时都会创建Pdus 。使用 Transport ip,我们通知MATE我们感兴趣的一些字段位于帧的ip部分。最后,我们告诉MATE进口ip.addr如 地址,dns.id作为dns_id和dns.flags.response为dns_resp。
一旦我们告诉MATE如何提取dns_pdus,我们将告诉它如何匹配请求和响应并将它们分组到Gop中。为此,我们将使用Gop声明来定义Gop,然后使用Start和Stop语句来告诉它何时Gop开始和结束。
Gop dns_req在dns_pdu上匹配(addr,addr,dns_id){
Start(dns_resp = 0);
停止(dns_resp = 1);
};
使用Gop声明,我们告诉MATE Gop的名称是dns_req,dns_pdus可以成为Gop的成员,以及用于匹配Pdus和Gop的密钥是什么。
这个Gop的关键是“addr,addr,dns_id”。这意味着为了属于同一个Gop,dns_pdus必须同时具有两个地址和 请求ID。然后,我们指示MATE,只要dns_pdu与“dns_resp = 0”匹配,dns_req就会启动,而当另一个dns_pdu 与“dns_resp = 1”匹配时,它会停止。
此时,如果我们使用此配置打开捕获文件,我们可以使用显示过滤器mate.dns_req.Time> 1来仅查看需要超过一秒钟才能完成的DNS请求数据包。
我们可以使用显示过滤器mate.dns_req &&!mate.dns_req.Time用于查找未给出响应的请求。mate.xxx.Time仅针对已停止的Gops设置。
另一个示例为每个HTTP请求创建一个Gop。
Pdu http_pdu Proto http Transport tcp / ip { Extract addr来自ip.addr; 从tcp.port中提取端口; 从http.request.method中提取http_rq; 从http.response中提取http_rs; DiscardPduData为true; }; Gop http_req On http_pdu Match(addr,addr,port,port){ Start(http_rq); 停止(http_rs); };
因此,如果我们使用此配置打开捕获
- 使用mate.http_req.Time> 1过滤将给出响应头超过一秒的所有请求
- 使用mate.http_req.Duration> 1.5进行过滤将显示完成时间超过1.5秒的请求。
你必须知道mate.xxx.Time给出了匹配GopStart的pdu和匹配GopStop的Pdu之间的秒数(是的,你可以使用它来创建计时器!)。另一方面,mate.xxx.Duration为您提供GopStart和分配给该Gop的最后一个pdu之间的时间,无论它是否为停止。在GopStop之后,匹配Gop密钥的Pdus仍将被分配给同一个Gop,只要它们与GopStart不匹配,在这种情况下将创建具有相同密钥的新Gop。
我们将绑定到单个Gog所有属于请求的HTTP数据包和对某个主机的响应以及用于使用前面示例的Pdu和Gop定义来解析其域名的dns请求和响应
为了能够将DNS和HTTP请求组合在一起,我们需要将这些协议共享的一部分信息导入到Pdus和Gops中。一旦定义了Pdus和Gops,我们就可以使用Extract(用于Pdus)和 Extract(用于Gops)语句来告诉MATE将哪些其他协议字段添加到Pdus和Gops的AVPL中。我们将以下语句添加到适当的声明中:
从http.host中提取主机; //将Pdu http_pdu作为列表
Extra(host)中的最后一个Extract ; //停止
提取主机之后的Gop http_req 来自dns.qry.name; //将Pdu dns_pdu作为列表
Extra(host)中的最后一个Extract ; //停止后到Gop dns_req
在这里,我们告诉MATE将http.host导入http_pdu,将dns.qry.name 导入dns_pdu作为主机。我们还必须告诉MATE将主机 属性从Pdus复制到Gops,我们使用Extra执行此操作。
一旦我们获得了Pdus和Gops中所需的所有数据,我们就告诉MATE是什么让不同的Gops属于某个Gog。
Gog http_use {
Member http_req(host);
成员dns_req(主持人);
到期0.75;
};
使用Gog声明,我们告诉MATE定义一个Gog类型命名为 http_use,在所有属于它的Gops被停止后,它的有效期为0.75秒。在那段时间之后,具有相同键匹配的最终新Gop将创建新的Gog,而不是添加到之前的Gog。
使用Member语句,我们告诉MATE,具有相同* host的http_req * s属于同一Gog,对于* dns_req * s则相同。
到目前为止,我们已指示配对将与会话相关的每个数据包分组到某个主机。此时如果我们打开一个捕获文件并且:
- 显示过滤器mate.http_use.Duration> 5将仅显示从DNS请求开始并以http响应的最后一个数据包结束的完成时间超过5秒的请求。
- 显示过滤器mate.http_use.host ==“www.w3c.org”将显示与指向www.w3c.org的请求相关的所有数据包(包括DNS和HTTP)
“休斯顿:我们在这里遇到了问题。”
如果用于在客户端进行捕获,但在网络中更深层次,我们会遇到真正的混乱,这种配置工作正常。许多用户的请求混合在一起成为http_uses。几乎随机创建和停止Gogs(取决于Gops开始和停止的时间)。我们如何从彼此分开的个人用户那里获得请求?
MATE有一个工具可用于解决此类分组问题。这个工具是变形。一旦定义,它们可以应用于Pdus,Gops和Gogs,它们可能会根据其中的内容替换或插入更多属性。我们将使用它们来创建一个名为client的属性,使用它我们将分隔不同的请求。
对于DNS,我们需要将请求的ip.src仅从DNS请求移入Gop。
所以我们首先告诉MATE将ip.src导入为客户端:
从ip.src中提取客户端;
接下来,我们告诉MATE 在Pdu中只用dns_resp = 1替换(dns_resp = 1,client)。这样,我们只将属性客户端保留在DNS请求Pdus中(即来自客户端的数据包)。为此,我们必须在Pdu声明之前添加一个 Transform声明(在这种情况下,只有一个子句)使用它:
变换rm_client_from_dns_resp {
匹配(dns_resp = 1,客户端)替换(dns_resp = 1);
};
接下来,我们通过 在dns_pdu Pdu 的Extract列表之后添加以下行来调用转换:
变换rm_client_from_dns_resp;
HTTP有点棘手。我们必须从响应和响应的“延续”中删除携带ip.src的属性,但由于没有任何东西需要过滤继续,我们必须先添加假属性。然后我们必须在伪属性出现时删除客户端。这是可能的,因为Transform 中的Match子句是逐个执行的,直到其中一个成功。首先,我们声明另外两个变换:
变换rm_client_from_http_resp1 { Match(http_rq); //第一次匹配获胜,因此请求将不会获取插入的not_rq属性 Match Every(addr)Insert(not_rq); //如果第一个匹配,则不会评估此行,因此not_rq不会插入到请求中 ; 变换rm_client_from_http_resp2 { 匹配(not_rq,客户端)替换(); //用“no”替换“client and not_rq”(仅在响应和最终部分中发生) };
接下来,我们向http_pdu声明添加另一个Extract语句,并以正确的顺序应用上面声明的两个Transforms:
从ip.src中提取客户端;
变换rm_client_from_http_resp1,rm_client_from_http_resp2;
在MATE中,将评估为项目列出的所有Transform_s,而在单个_Transform中,评估将在第一个成功的Match子句处停止 。这就是为什么我们首先匹配http_rq以在添加not_rq属性之前退出第一个序列。然后我们应用第二个 Transform,如果两者都存在,则删除not_rq和client。是的,_Transform_s很麻烦,但它们非常有用。
一旦我们得到了Pdus中我们需要的所有内容,我们必须告诉MATE将属性客户端从Pdus复制到相应的Gops,方法是将客户端添加到 两个Gop声明的Extra列表中:
额外(主持人,客户);
最重要的是,我们需要将Gop密钥的旧声明修改为包含客户端和主机的新声明。所以我们 通过以下方式更改Gog Member声明:
成员http_req(主持人,客户端);
成员dns_req(主持人,客户);
现在我们得到它,每一个“用法”都得到它自己的Gog。
以下是MATE的各种配置示例的集合。其中许多都没用,因为“对话”设施做得更好。无论如何,它们旨在帮助用户了解如何配置MATE。
以下示例从每个TCP会话中创建一个GoP。
Pdu tcp_pdu Proto tcp Transport ip { Extract addr来自ip.addr; 从tcp.port中提取端口; 从tcp.flags.syn中提取tcp_start; 从tcp.flags.reset中提取tcp_stop; 从tcp.flags.fin中提取tcp_stop; }; Gop tcp_ses on tcp_pdu Match(addr,addr,port,port){ Start(tcp_start = 1); 停止(tcp_stop = 1); }; 完成;
这可能在99.9%的情况下都可以,但10.0.0.1:20→10.0.0.2:22和10.0.0.1:22→10.0.0.2:20如果碰巧在时间上重叠,都会落入同一个gop。
- 使用mate.tcp_ses.Time> 1过滤将给出持续时间不到一秒的所有会话
- 使用mate.tcp_ses.NumOfPdus <5过滤将显示所有少于5个数据包的tcp会话。
- 使用mate.tcp_ses.Id == 3过滤将显示MATE找到的第三个tcp会话的所有数据包
此配置允许在单个Gog中绑定完整的被动ftp会话(包括数据传输)。
Pdu ftp_pdu Proto ftp Transport tcp / ip { 从ip.addr中提取ftp_addr; 从tcp.port中提取ftp_port; 从ftp.response.code中提取ftp_resp; 从ftp.request.command中提取ftp_req; 从ftp.passive.ip中提取server_addr; 从ftp.passive.port中提取server_port; LastPdu; }; Pdu ftp_data_pdu Proto ftp-data Transport tcp / ip { Extract server_addr from ip.src; 从tcp.srcport中提取server_port; }; Gop ftp_data在ftp_data_pdu上(server_addr,server_port){ Start(server_addr); }; Gop ftp_ctl在ftp_pdu上(ftp_addr,ftp_addr,ftp_port,ftp_port){ 开始(ftp_resp = 220); 停止(ftp_resp = 221); Extra(server_addr,server_port); }; Gog ftp_ses { Member ftp_ctl(ftp_addr,ftp_addr,ftp_port,ftp_port); 成员ftp_data(server_addr,server_port); }; 完成;
注意:无法区分ftp-data数据包使得此配置为每个ftp数据包而不是每次传输创建一个Gop。预先开始的Gops会避免这种情况。
在许多国家,除了不道德之外,对人进行间谍活动是非法的。这是一个示例,旨在解释如何执行此操作而不是邀请。当有充分的理由这样做时,由警察来做这种工作。
Pdu radius_pdu On radius Transport udp / ip { Extract addr来自ip.addr; 从udp.port中提取端口; 从radius.id中提取radius_id; 从radius.code中提取radius_code; 从radius.framed_addr中提取user_ip; 从radius.username中提取用户名; } Gop的radius_req在radius_pdu(radius_id,ADDR,ADDR,端口,端口){ 启动(radius_code {1 | 4 | 7}); 停止(radius_code {2 | 3 | 5 | 8 | 9}); 额外(user_ip,用户名); } //我们定义要过滤的smtp流量 Pdu user_smtp Proto smtp传输tcp / ip { Extract user_ip from ip.addr; 从tcp.port中提取smtp_port; 从tcp.flags.syn中提取tcp_start; 从tcp.flags.reset中提取tcp_stop; } Gop的user_smtp_ses在user_smtp(user_ip,user_ip,SMTP_PORT 25!){ 启动(tcp_start = 1); 停止(tcp_stop = 1); } //使用以下组的组我们将组合半径和smtp //我们设置一个长期到期以避免会话在长时间暂停时到期。 Gog user_mail { Expiration 1800; 成员radius_req(user_ip); 成员user_smtp_ses(user_ip); 额外(用户名); } 完成;
具有过滤捕获文件mate.user_mail.username ==“theuser”将过滤半径包和SMTP流量“theuser”。
此配置将在每次调用时创建一个Gog。
Pdu q931 Proto q931 Transport ip { Extract addr来自ip.addr; 从q931.call_ref中提取call_ref; 从q931.message_type中提取q931_msg; 提取调用来自q931.calling_party_number.digits; 提取名为From q931.called_party_number.digits; 从h225.guid中提取guid; 从q931.cause_value中提取q931_cause; }; Gop q931_leg on q931 Match(addr,addr,call_ref){ Start(q931_msg = 5); 停止(q931_msg = 90); 额外的(调用,调用,guid,q931_cuase); }; Pdu ras Proto h225.RasMessage Transport ip { Extract addr来自ip.addr; 从h225.requestSeqNum中提取ras_sn; 从h225.RasMessage中提取ras_msg; 从h225.guid中提取guid; }; Gop ras_req On ras Match(addr,addr,ras_sn){ Start(ras_msg {0 | 3 | 6 | 9 | 12 | 15 | 18 | 21 | 26 | 30}); 停止(ras_msg {1 | 2 | 4 | 5 | 7 | 8 | 10 | 11 | 13 | 14 | 16 | 17 | 19 | 20 | 22 | 24 | 27 | 28 | 29 | 31}); 额外(指导); }; Gog call { Member ras_req(guid); 会员q931_leg(guid); 额外的(叫,呼叫,q931_cause); }; 完成;
有了这个,我们可以:
- 过滤特定呼叫者的所有信令:mate.call.caller ==“123456789”
- 过滤具有特定释放原因的呼叫的所有信令:mate.call.q931_cause == 31
- 为非常短的呼叫过滤所有信令:mate.q931_leg.Time <5
在此示例中,MMS发送或接收的所有组件将绑定到单个Gog中。请注意,此示例使用Payload子句,因为MMS传递在HTTP或WSP上使用MMSE。由于不可能仅通过MMSE将检索请求与响应相关联(请求只是没有任何MMSE的HTTP GET),Gop由HTTP Pdus构成,但需要从主体中提取MMSE数据。
##警告:此示例是从“旧”MATE语法 ##中盲目翻译的,并且已经验证Wireshark接受它。但是, 由于缺少后者,它尚未针对任何捕获文件进行##测试。 变换rm_client_from_http_resp1 { Match(http_rq); 匹配每个(地址)插入(not_rq); }; 变换rm_client_from_http_resp2 { Match(not_rq,ue)Replace(); }; Pdu mmse_over_http_pdu Proto http Transport tcp / ip { Payload mmse; 从ip.addr中提取addr; 从tcp.port中提取端口; 从http.request中提取http_rq; 从http.content_type中提取内容; 从http.response.code中提取resp; 提取方法来自http.request.method; 从http.host中提取主机; 从http.content_type中提取内容; 从mmse.transaction_id中提取trx; 从mmse.message_type中提取msg_type; 从mmse.status中提取notify_status; 从mmse.response_status中提取send_status; 变换rm_client_from_http_resp1,rm_client_from_http_resp2; }; Gop mmse_over_http On mmse_over_http_pdu匹配(addr,addr,port,port){ Start(http_rq); 停止(http_rs); Extra(host,ue,resp,notify_status,send_status,trx); }; 变换mms_start { Match Loose()Insert(mms_start); }; Pdu mmse_over_wsp_pdu Proto wsp Transport ip { Payload mmse; 从mmse.transaction_id中提取trx; 从mmse.message_type中提取msg_type; 从mmse.status中提取notify_status; 从mmse.response_status中提取send_status; 转换mms_start; }; Gop mmse_over_wsp On mmse_over_wsp_pdu匹配(trx){ Start(mms_start); 停止(永远); Extra(ue,notify_status,send_status); }; Gog mms { 会员mmse_over_http(trx); 成员mmse_over_wsp(trx); 额外(ue,notify_status,send_status,resp,host,trx); 到期60.0; };
MATE库(将)包含几个协议的GoP定义。库协议包含在您的MATE配置中使用:_Action = Include; LIB = proto_name; _。
对于具有库条目的每个协议,我们将找到定义从PDU创建该协议的GoP所需的内容,最终定义任何标准和非常重要的GoP定义(即GopDef,GopStart和GopStop)。
|
注意 |
|---|---|
|
看来这段代码是用MATE的旧语法编写的。到目前为止,它尚未转录为新格式。它仍然可以构成以新格式重新创建它们的基础。 |
它将为每个TCP会话创建一个GoP,如果使用它,它应该是列表中的最后一个。TCP上的每个其他原型都应该用Stop = TRUE声明 ; 因此,在我们已经进行的情况下,不会创建TCP PDU。
行动= PduDef; NAME = tcp_pdu; 原= TCP; 交通运输= IP; ADDR = ip.addr; 端口= tcp.port; tcp_start = tcp.flags.syn; tcp_stop = tcp.flags.fin; tcp_stop = tcp.flags.reset; 行动= GopDef; NAME = tcp_session; 上= tcp_pdu; 地址; 地址; 港口; 港口; 行动= GopStart; 用于= tcp_session; tcp_start = 1; 行动= GopStop; 用于= tcp_session; tcp_stop = 1;
将创建一个包含每个请求及其响应的GoP(最终也会重新传输)。
行动= PduDef; NAME = dns_pdu; 原= DNS; 运输= UDP / IP; ADDR = ip.addr; 端口= udp.port; dns_id = dns.id; dns_rsp = dns.flags.response;
行动= GopDef; NAME = dns_req; 上= dns_pdu; 地址; 地址; 53端口!; dns_id;
行动= GopStart; 用于= dns_req; dns_rsp = 0;
行动= GopStop; 用于= dns_req; dns_rsp = 1;
每笔交易的Gop。
行动= PduDef; NAME = radius_pdu; 原=半径; 运输= UDP / IP; ADDR = ip.addr; 端口= udp.port; radius_id = radius.id; radius_code = radius.code;
行动= GopDef; NAME = radius_req; 上= radius_pdu; radius_id; 地址; 地址; 港口; 港口;
行动= GopStart; 用于= radius_req; radius_code | 1 | 4 | 7;
行动= GopStop; 用于= radius_req; radius_code | 2 | 3 | 5 | 8 | 9;
行动= PduDef; NAME = rtsp_pdu; 原= RTSP; 运输= TCP / IP; ADDR = ip.addr; 端口= tcp.port; rtsp_method = rtsp.method;
行动= PduExtra; 用于= rtsp_pdu; rtsp_ses = rtsp.session; rtsp_url = rtsp.url;
行动= GopDef; NAME = rtsp_ses; 上= rtsp_pdu; 地址; 地址; 港口; 港口;
行动= GopStart; 用于= rtsp_ses; rtsp_method = DESCRIBE;
行动= GopStop; 用于= rtsp_ses; rtsp_method = TEARDOWN;
行动= GopExtra; 用于= rtsp_ses; rtsp_ses; rtsp_url;
除非另有说明,否则此处的大多数协议定义将为每个Call Leg创建一个Gop。
行动= PduDef; NAME = isup_pdu; 原= ISUP; 交通运输= MTP3; mtp3pc = mtp3.dpc; mtp3pc = mtp3.opc; CIC = isup.cic; isup_msg = isup.message_type;
行动= GopDef; NAME = isup_leg; 上= isup_pdu; ShowPduTree = TRUE; mtp3pc; mtp3pc; CIC;
行动= GopStart; 用于= isup_leg; isup_msg = 1;
行动= GopStop; 用于= isup_leg; isup_msg = 16;
行动= PduDef; NAME = q931_pdu; 原= Q931; 停止= TRUE; 运输= TCP / IP; ADDR = ip.addr; call_ref = q931.call_ref; q931_msg = q931.message_type;
行动= GopDef; NAME = q931_leg; 上= q931_pdu; 地址; 地址; call_ref;
行动= GopStart; 用于= q931_leg; q931_msg = 5;
行动= GopStop; 用于= q931_leg; q931_msg = 90;
行动= PduDef; NAME = ras_pdu; 原= h225.RasMessage; 运输= UDP / IP; ADDR = ip.addr; ras_sn = h225.RequestSeqNum; ras_msg = h225.RasMessage;
行动= PduExtra; 用于= ras_pdu; GUID = h225.guid;
行动= GopDef; NAME = ras_leg; 上= ras_pdu; 地址; 地址; ras_sn;
行动= GopStart; 用于= ras_leg; ras_msg | 0 | 3 | 6 | 9 | 12 | 15 | 18 | 21 | 26 | 30;
行动= GopStop; 用于= ras_leg; ras_msg | 1 | 2 | 4 | 5 | 7 | 8 | 10 | 11 | 13 | 14 | 16 | 17 | 19 | 20 | 22 | 24 | 27 | 28 | 29 | 31;
行动= GopExtra; 用于= ras_leg; GUID;
行动= PduDef; 原= sip_pdu; 运输= TCP / IP; ADDR = ip.addr; 端口= tcp.port; sip_method = sip.Method; sip_callid = sip.Call-ID; 主叫= sdp.owner.username;
行动= GopDef; NAME = sip_leg; 上= sip_pdu; 地址; 地址; 港口; 港口;
行动= GopStart; 为SIP =; sip_method = INVITE;
行动= GopStop; 为SIP =; sip_method = BYE;
将在每笔交易中创建一个Gop。
将它们“绑定”到你的电话的GoG使用:Action = GogKey; NAME = your_call; 上= mgc_tr; 地址mgc_addr!; megaco_ctx;
行动= PduDef; NAME = mgc_pdu; 原= MEGACO; 交通运输= IP; ADDR = ip.addr; megaco_ctx = megaco.context; megaco_trx = megaco.transid; megaco_msg = megaco.transaction; 术语= megaco.termid;
行动= GopDef; NAME = mgc_tr; 上= mgc_pdu; 地址; 地址; megaco_trx;
行动= GopStart; 用于= mgc_tr; megaco_msg |请求|通知;
行动= GopStop; 用于= mgc_tr; megaco_msg =回复;
行动= GopExtra; 用于= mgc_tr; 长期^ DS1; megaco_ctx!选择一个;
MATE几乎可以使用AVP:保存从帧中提取的数据,以及保留配置的元素。
这些“对”(实际上是元组)由名称,值组成,并且在配置AVP的情况下,由运算符组成。名称和值是字符串。具有除“=”之外的运算符的AVP仅在配置中使用,并且用于在分析阶段匹配Pdus,GoP和GoG的AVP。
该名称是用于指代一类AVP的字符串。除非名称相同,否则两个属性将不匹配。大写字母是为关键字保留的(如果需要,可以将它们用于您的元素,但我认为不是这样)。MATE属性名称可以在Wireshark的显示过滤器中使用,与解析器提供的协议字段名称相同,但它们不仅仅是对协议字段(或别名)的引用。
该值是一个字符串。它可以在配置(用于配置AVP)中设置,也可以通过MATE设置,同时从解剖树中提取感兴趣的字段和/或稍后操作它们。从字段中提取的值使用与在过滤字符串中相同的表示。
目前只定义匹配运算符(有计划(重新)添加转换属性,但在此之前必须解决一些内部问题)。匹配操作总是在两个操作数之间执行:配置中陈述的AVP的值和从分组数据(称为“数据AVP”)中提取的AVP(或具有相同名称的几个AVP)的值。不可能将数据AVP彼此匹配。
定义的匹配运算符是:
- Equal =测试相等性,即:值字符串相同或匹配失败。
- 不等于 !仅在值字符串不相等时才匹配。
- 一 {}将匹配,如果上市值字符串中的一个等于数据AVP的字符串。花括号内的列表的各个tems使用|分隔 字符。
- 始于 ^如果配置值的字符串数据AVP的值字符串的第一个字符匹配将匹配。
- 如果配置值字符串与数据AVP的值字符串的最后一个字符匹配,则结束与$匹配。
- 如果配置值字符串与数据AVP的值字符串的字符的子字符串匹配,则包含〜将匹配。
- 低于 <如果数据AVP的值字符串超过配置值字符串语义下将匹配。
- 高于 >如果数据AVP的字符串值在语义上比配置值高的字符串匹配。
- 存在 ?(可以省略)如果AVP名称匹配,则匹配,无论值字符串是什么。
此运算符测试运算符和操作数AVP的值是否相等。
- 例
- attrib = aaa 匹配 attrib = aaa attrib = aaa 与 attrib = bbb 不匹配
如果数据AVP值等于“AVP之一”中列出的值之一,则“一个”运算符匹配。
- 例
- attrib = 1匹配attrib {1 | 2 | 3} attrib = 2匹配attrib {1 | 2 | 3} attrib = 4与attrib {1 | 2 | 3}不匹配
如果数据AVP值的第一个字符与配置AVP值相同,则“以...开头”运算符匹配。
- 例
- attrib = abcd匹配attrib ^ abc attrib = abc匹配attrib ^ abc attrib = ab与attrib不匹配^ abc attrib = abcd与attrib不匹配^ bcd attrib = abc与attrib ^ abcd不匹配
如果数据AVP值的最后字节等于配置AVP值,则运算符的末尾将匹配。
- 例
- attrib = wxyz匹配attrib $ xyz attrib = yz与attrib $ xyz attrib = abc不匹配... wxyz与attrib $ abc不匹配
如果数据AVP值包含与配置AVP值相同的字符串,则“contains”运算符将匹配。
- 例
- attrib = abcde匹配attrib~bcd attrib = abcde匹配attrib~abc attrib = abcde匹配attrib~cde attrib = abcde与attrib~xyz不匹配
如果数据AVP值在语义上低于配置AVP值,则“低于”运算符将匹配。
- 例
- attrib = abc匹配attrib <bcd attrib = 1匹配attrib <2但要注意:attrib = 10不匹配attrib <9 attrib = bcd不匹配attrib <abc attrib = bcd与attrib <bcd不匹配
BUGS
它应检查值是否为数字并以数字方式进行比较
如果数据AVP值在语义上高于配置AVP值,则“高于”运算符将匹配。
例子
attrib = bcd匹配attrib> abc attrib = 3匹配attrib> 2但要注意:attrib = 9不匹配attrib> 10 attrib = abc不匹配attrib> bcd attrib = abc与attrib> abc不匹配
BUGS
它应检查值是否为数字并以数字方式进行比较
Pdus,GoP和GoG使用AVPL来包含跟踪信息。AVPL是一组未排序的AVP,可以与其他AVPL匹配。
可以在AVPL之间执行三种类型的匹配操作。Pdu / GoP / GoG的AVPL将永远是其中一个操作数; AVPL运算符(匹配类型)和第二个操作数AVPL将始终来自 配置。注意,可以为配置AVPL中的每个AVP指定不同的AVP匹配运算符。
AVPL匹配操作返回结果AVPL。在Transform s中,结果AVPL可以被另一个AVPL替换。替换意味着丢弃现有数据AVP并且来自配置的替换AVPL 被合并到Pdu / GoP / GoG的数据AVPL。
如果至少一个数据AVP与配置AVP中的至少一个匹配,则AVPL之间的松散匹配成功。其结果AVPL包含匹配的所有数据AVP。
在对Pdu的AVPL的Extra操作中使用松散匹配将结果合并到Gop的AVPL中,并且与Gop的AVPL合并以将结果合并到Gog的AVPL中。它们也可用于 Criteria和Transform。
|
注意 |
|---|---|
|
截至当前(2.0.1),松散匹配不能如此处所述,请参阅 错误12184。只有在变换和标准中使用才会受到bug的影响。 |
松散的比赛示例
(attr_a = aaa,attr_b = bbb,attr_c = xxx)匹配松散(attr_a?,attr_c?)=⇒(attr_a = aaa,attr_c = xxx)
(attr_a = aaa,attr_b = bbb,attr_c = xxx)匹配松散(attr_a?,attr_c = ccc)=⇒(attr_a = aaa)
(attr_a = aaa,attr_b = bbb,attr_c = xxx)匹配松散(attr_a = xxx; attr_c = ccc)=⇒不匹配!
如果在数据AVPL中没有配对的AVP没有匹配,则AVPL之间的“每个”匹配成功。其结果AVPL包含匹配的所有数据AVP。
|
注意 |
|---|---|
|
截至当前(2.0.1),松散匹配不能如此处所述,请参阅 错误12184。 |
“每个”匹配示例
(attr_a = aaa,attr_b = bbb,attr_c = xxx)匹配每一个(attr_a?,attr_c?)=⇒(attr_a = aaa,attr_c = xxx)
(attr_a = aaa,attr_b = bbb,attr_c = xxx)匹配每一个(attr_a?,attr_c?,attr_d = ddd)=⇒(attr_a = aaa,attr_c = xxx)
(attr_a = aaa,attr_b = bbb,attr_c = xxx)匹配每一个(attr_a?,attr_c = ccc)=⇒不匹配!
(attr_a = aaa; attr_b = bbb; attr_c = xxx)匹配每一个(attr_a = xxx,attr_c = ccc)=⇒不匹配!
当且仅当配置AVPL中的每个AVP在数据AVPL中具有至少一个对应物并且没有AVP匹配失败时,AVPL之间的严格匹配成功。结果AVPL包含匹配的所有数据AVP。
这些用于Gop密钥(密钥AVPL)和Pdu AVPL之间。它们也可用于Criteria和Transform。
例子
(attr_a = aaa,attr_b = bbb,attr_c = xxx)匹配严格(attr_a?,attr_c = xxx)=⇒(attr_a = aaa,attr_c = xxx)
(attr_a = aaa,attr_b = bbb,attr_c = xxx,attr_c = yyy)匹配严格(attr_a?,attr_c?)=⇒(attr_a = aaa,attr_c = xxx,attr_c = yyy)
(attr_a = aaa,attr_b = bbb,attr_c = xxx)匹配严格(attr_a?,attr_c = ccc)=⇒不匹配!
(attr_a = aaa,attr_b = bbb,attr_c = xxx)匹配严格(attr_a?,attr_c?,attr_d?)=⇒不匹配!
AVPL可以合并到另一个中。这将增加后者每个AVP,前者尚未存在。
此操作已完成
- 在一场关键比赛的结果与Gop或Gog的AVPL之间,
- 在额外比赛的结果与Gop或Gog的AVPL之间,
- 在变换匹配的结果和Pdu的/ Gop的AVPL之间。如果Match子句指定的操作是Replace,则在将modify_avpl合并到其中之前,将从项目的AVPL中删除匹配的结果AVPL。
例子
(attr_a = aaa,attr_b = bbb)合并(attr_a = aaa,attr_c = xxx)前者变为(attr_a = aaa,attr_b = bbb,attr_c = xxx)
(attr_a = aaa,attr_b = bbb)合并(attr_a = aaa,attr_a = xxx)前者变为(attr_a = aaa,attr_a = xxx,attr_b = bbb)
(attr_a = aaa,attr_b = bbb)合并(attr_c = xxx,attr_d = ddd)变为(attr_a = aaa,attr_b = bbb,attr_c = xxx,attr_d = ddd)
变换是一系列匹配规则,可选地后跟一条指令,指示如何使用附加的AVPL修改匹配结果。这种修改可以是插入(合并)或替换。语法如下:
转换名称{
Match [Strict | Every | Loose] match_avpl [[Insert | Replace] modify_avpl]; //可能会多次出现,至少一次
};
有关变换的示例,请查看“ 手册”页面。
TODO:在这里迁移示例?
Transform中的Match规则列表从上到下进行处理; 一旦匹配规则成功或者所有尝试都是徒劳的,处理就会结束。
在进一步处理项目之前,变换可以用作帮助程序来操纵项目的AVPL。项声明可以包含一个Transform子句,指示先前声明的Transforms列表。无论个人转换成功还是失败,列表总是按照给定的顺序执行,即从左到右。
在MATE配置文件中,必须在声明使用它的任何项之前声明Transform。
以下配置AVPL处理PDU创建和数据提取。
在捕获的每个帧中,MATE将按照声明在其配置中出现的顺序查找源proto_name的PDU,并将创建它可以从该帧中获得的每种类型的Pdus,除非明确指示某些Pdu类型是最后一个一个在框架中寻找。如果对于给定类型被告知,MATE将提取该类型的所有Pdus以及它在帧中找到的先前声明的类型,但不提取稍后声明的类型。
Pdu的完整声明如下:各种条款的强制性顺序如图所示。
Pdu name Proto proto_name Transport proto1 [/ proto2 / proto3 [/ ...]]] {
Payload proto; //可选,无默认值
Extract属性来自proto.field; //可能多次出现,至少一次
Transform(transform1 [,transform2 [,...]]); //可选
标准[{Accept | Reject}] [{Strict | Every | Loose} match_avpl];
DropUnassigned {true | false}; // optional,default = false
DiscardPduData {true | false}; // optional,default = false
LastExtracted {true | false}; // optional,default = false
};
该名称是Pdu声明的强制属性。它是任意选择的,除了每个名称只能在MATE的配置中使用一次,无论它用于什么项目的类别。该名称用于区分不同类型的Pdus,Gops和Gogs。该名称 还用作与MATE创建的此类Pdu相关的可过滤字段名称的一部分。
但是,几个Pdu声明可能具有相同的名称。在这种情况下,所有这些都是从与其Proto,Transport和Payload子句匹配的每个源PDU创建的,而它们的声明主体可能彼此完全不同。与Accept(或Reject)子句一起,当需要根据其他源字段的内容(或仅仅存在)从不同的源字段集构建Pdu的AVPL时,此功能非常有用。
帧中协议proto_name PDU的每个实例将生成一个Pdu,其中AVP是从proto_name范围内的字段和/或传输列表指定的基础协议范围中提取的。它是Pdu声明的强制属性。该proto_name是该协议的名称作为Wireshark的显示过滤器使用。
Pdu的Proto及其传输协议列表由/告诉MATE,帧的哪些字段可以进入Pdu的AVPL。为了使MATE从帧的协议树中提取属性,表示帧的十六进制显示中的字段的区域必须在 Proto或其相对Transport的区域内。选择传输从协议区域向后移动,按照给定的顺序。
Proto http Transport tcp / ip执行您期望的操作 - 它选择最接近当前http范围的tcp范围,以及在该tcp范围之前的最近ip范围。如果在最近的一个之前存在另一个ip范围(例如,在IP隧道的情况下),则不会选择该范围。 传输 “逻辑上”应该选择封装IP头的tcp / ip / ip到目前为止还不起作用。
一旦我们选择了Proto和Transport范围,MATE将获取属于它们的协议字段,这些协议字段的提取是使用Pdu类型的Extract子句声明的 。在交通运输清单也是强制性的,如果你真的不希望使用任何传输协议,使用传输队友。(这直到0.10.9才起作用)。
除了Pdu的Proto及其传输协议之外,还有一个 Payload属性告诉MATE Proto的有效负载范围,以便将帧的字段提取到Pdu中。为了从帧的树中提取属性,十六进制显示中的字段的突出显示区域必须在Proto的相对有效载荷的区域内。按协议区域的顺序选择有效负载。 Proto http Transport tcp / ip Payload mmse将选择当前http范围之后的第一个mmse范围。一旦我们选择了Payload范围,MATE将获取属于它们的那些协议字段,其提取是使用Pdu类型的Extract子句声明的。
每个Extract子句告诉MATE要提取哪个协议字段值作为AVP值以及用作AVP名称的字符串。使用Wireshark显示过滤器中使用的名称引用协议字段。如果帧中存在多于一个这样的协议字段,则满足上述标准的每个实例被提取到其自己的AVP中。AVP名称可以任意选择,但是为了能够匹配最初来自不同Pdus的值(例如,来自DNS查询的主机名和来自HTTP GET请求的主机名),在分析后面,必须为它们分配相同的AVP名称,并且解剖器必须以相同的格式提供字段值(并非总是如此)。
该变换子句指定先前声明的清单变换所有协议字段已被提取之后的PDU的AVPL要执行秒。列表总是从左到右完全执行。相反,每个单独的Transform内的Match子句列表仅在第一次匹配成功之前执行。
该子句告诉MATE是否使用Pdu进行分析。它指定匹配AVPL,AVPL匹配类型(Strict,Every或Loose)以及匹配成功时要执行的操作(Accept或Reject)。一旦提取了每个属性并且已经执行了最终变换列表,并且如果存在 Criteria子句,则将Pdu的AVPL与匹配AVPL匹配; 如果匹配成功,则执行指定的动作,即接受或拒绝Pdu。省略相应关键字时使用的默认行为是Strict和Accept。因此,如果省略该条款,则接受所有Pdus。
如果设置为TRUE,MATE将在分析后删除Pdu的AVPL,并最终从中将一些AVP提取到Gop的AVPL中。这对于节省内存很有用(MATE使用了很多内存)。如果设置为FALSE(默认情况下未给出),MATE将保留Pdu属性。
声明一个Gop类型及其prematch候选键。
Gop名称在pduname匹配键{
Start match_avpl; //可选
Stop match_avpl; //可选
Extra match_avpl; //可选的
Transform transform_list; //可选的
到期时间; //可选的
IdleTimeout时间; //可选的
终身时间; //可选
DropUnassigned [TRUE | FALSE]; //可选
ShowTree [NoTree | PduTree | FrameTree | BasicTree]; //可选
ShowTimes [TRUE | FALSE]; //可选,默认为TRUE
};
该名称是Gop声明的强制属性。它是任意选择的,除了每个名称只能在MATE的配置中使用一次,无论它用于什么项目的类别。该名称用于区分不同类型的Pdus,Gops和Gogs。该名称 还用作与MATE创建的此类Gop相关的可过滤字段名称的一部分。
定义AVP构成Gop AVPL 的关键部分(Gop的关键 AVPL或简称Gop的关键部分)。匹配活动Gop 的关键 AVPL的所有Pdus 被分配给该Gop; 包含AVP的Pdu,其属性名称列在Gop的密钥 AVPL中,但它们并不严格匹配任何活动Gop的密钥 AVPL,将创建一个新的Gop(除非给出了一个Start子句)。创建Gop时,将从创建Pdu中复制其关键AVPL的元素。
如果给出,它会告诉MATE什么match_avpl必须与Pdu的AVPL匹配,以及匹配Gop的键,以便启动Gop。如果没有给出,任何其AVPL与Gop的关键 AVPL匹配的Pdu 将作为Gop的开始。与match_avpl匹配的Pdu的AVP不会自动复制到Gop的AVPL中。
如果给出,它告诉MATE什么match_avpl必须与Pdu的AVPL匹配,除了匹配Gop的键,以便停止Gop。如果省略,Gop将“自动停止” - 也就是说,Gop一旦创建就被标记为已停止。与match_avpl匹配的Pdu的AVP不会自动复制到Gop的AVPL中。
该变换子句指定先前声明的列表转换期从每个新PDU中的AVP后共和党的AVPL执行,通过密钥AVPL和指定的额外条款的match_avpl,已经被合并到它。列表总是从左到右完全执行。相反,每个单独的Transform内的Match子句列表仅在第一次匹配成功之前执行。
Gop 停止后的一个(浮动)秒数,在此期间,仍然会为该Gop分配与Stop ped Gop的键匹配而不是Start状态的更多Pdus 。默认值零具有无穷大的实际含义,因为它禁用此计时器,因此与Stop ped Gop键匹配的所有Pdus 将被分配给该Gop,除非它们与Start条件匹配。
从分配给Gop的最后一个Pdu开始经过的(浮动)秒数,之后Gop将被视为已释放。默认值零具有无穷大的实际含义,因为它禁用了此计时器,因此即使没有Pdus到达也不会释放Gop - 除非Lifetime计时器到期。
是否应该丢弃未分配给任何Gog的Gop。如果为TRUE,则在创建后立即丢弃Gop。如果为FALSE,则保留未分配的Gop。将其设置为TRUE有助于节省内存并加快过滤速度。
控制Gop的Pdus子树的显示:
- NoTree:完全禁止显示树
- PduTree:显示树,并显示Pdu Id的Pdus
- FrameTree:显示树,并通过它们所在的帧编号显示Pdus
- BasicTree:需要调查
声明Gog类型及其prematch候选键。
Gog名称{
Member gopname(key); //强制性,至少一个
额外的match_avpl; //可选的
Transform transform_list; //可选的
到期时间; //可选,默认2.0
GopTree [NoTree | PduTree | FrameTree | BasicTree]; //可选
ShowTimes [TRUE | FALSE]; //可选,默认为TRUE
};
该名称是Gog声明的强制属性。它是任意选择的,除了每个名称只能在MATE的配置中使用一次,无论它用于什么项目的类别。该名称用于区分不同类型的Pdus,Gops和Gogs。该名称 还用作与MATE创建的此类Gop相关的可过滤字段名称的一部分。
为每个Gop类型的gopname单独定义Gog 的关键AVPL。所有gopname类型的GOP,其键 AVPL相应匹配键的活性歌革AVPL被分配到高格; 包含AVP的Gop,其属性名称列在Gog的相应密钥 AVPL中,但它们不严格匹配任何活动Gog的密钥AVPL,将创建一个新的Gog。创建Gog时,从创建Gop复制其关键 AVPL 的元素。
虽然关键的 AVPL是针对每个成员gopname单独指定 的,但在大多数情况下它们是相同的,因为Gog的目的是将由不同类型的Pdus组成的Gops组合在一起。
在释放分配给Gog的所有Gops之后的(浮动)秒数,在此期间,仍应将匹配任何会话密钥的新Gops分配给现有Gog,而不是创建新Gog。其值可以从0.0到无穷大。默认为2.0秒。
该变换子句指定先前声明的列表转换期从每个新GOP中的AVP后的高格的AVPL要执行,按指定键 AVPL和附加条款的match_avpl,已经被合并到它。列表总是从左到右完全执行。相反,每个单独的Transform内的Match子句列表仅在第一次匹配成功之前执行。
所述设置配置元件用于传递到MATE各种操作参数。可能的参数是
分配给gog的所有gops被释放后的几秒钟内,与任何会话密钥匹配的新gops应该创建一个新的gog,而不是分配给前一个gog。其值可以从0.0到无穷大。默认为2.0秒。
是否应该在处理后删除每个Pdu的AVPL(节省内存)。它可以是TRUE或FALSE。默认为TRUE。如果您的配置不起作用,将其设置为FALSE可以避免头痛。
如果未将Pdus分配给任何Gop,是否应删除Pdus。它可以是TRUE或FALSE。默认为FALSE。如果未分配的Pdus无效,则将其设置为TRUE以节省内存。
以下设置用于调试MATE及其配置。所有级别都是整数,范围从0(仅打印错误)到9(使用垃圾邮件),默认为0。
Debug {
Filename“path / name”; //可选,无默认值
Level [0-9]; //可选的通用调试级别
Pdu Level [0-9]; // Pdu处理
Gop Level [0-9]的可选,特定调试级别; // Gop处理
Gog Level [0-9]的可选,特定调试级别; // Gog处理的可选,特定调试级别
};
{{{path / name}}}是要写入调试输出的文件的完整路径。将创建不存在的文件,现有文件将在捕获文件的每个开口处被覆盖。如果缺少该语句,则会将调试消息写入控制台,这意味着它们在Windows上不可见。
目录
Wireshark为您提供了从普通数据包数据生成的其他信息,或者可能需要指出解剖问题。Wireshark生成的消息通常放在方括号(“[]”)中。
这些消息可能出现在数据包列表中。
格式错误的数据包意味着协议解析器无法进一步剖析数据包的内容。可能有多种原因:
- 错误的解剖器:Wireshark错误地为此数据包选择了错误的协议解析器。例如,如果您使用的协议不在其众所周知的TCP或UDP端口上,则会发生这种情况。您可以尝试分析|解码为避免此问题。
- 数据包未重新组装:数据包长于单个帧且未重新组装,有关详细信息,请参见第7.8节“数据包重组”。
- 数据包格式错误:数据包实际上是错误的(格式错误),这意味着数据包的一部分不符合预期(不遵循协议规范)。
- 解剖器是错误的:相应的协议解析器只是错误或仍然不完整。
以上任何一种都是可能的。您必须查看具体情况以确定原因。您可以通过在Analyze菜单上禁用协议来禁用解剖器,然后检查Wireshark如何显示数据包。您可以(如果它是TCP)在“编辑”|“首选项”菜单中启用TCP和特定解剖器(如果可能)的重组。您可以通过读取数据包字节并将其与协议规范进行比较来自行检查数据包内容。这可能会揭示解剖器错误。或者您可以发现数据包确实是错误的。
捕获期间数据包大小有限,请参见第4.5节“捕获选项”对话框中的“将每个数据包限制为n个字节”。解剖时,当前的协议解析器只是耗尽了数据包字节而不得不放弃。除了以更高(或没有)数据包大小限制再次重复整个捕获过程之外,您现在无法做任何其他事情。
目录
要了解在捕获的数据包保存到捕获文件后哪些信息仍然可用,了解捕获文件内容有一定帮助。
Wireshark使用 pcapng文件格式作为默认格式来保存捕获的数据包。它非常灵活,但其他工具可能不支持它。
Wireshark还支持 libpcap文件格式。这是一种更简单的格式,并且已经很好地建立。但是,它有一些缺点:它不可扩展,缺少一些真正有用的信息(例如,能够在数据包中添加注释,例如“问题从这里开始”会非常好)。
除了libpcap格式,Wireshark还支持几种不同的捕获文件格式。但是,上述问题也适用于这些格式。
在每个libpcap捕获文件的开头,一些基本信息被存储为幻数,以识别libpcap文件格式。此文件的最有趣信息是链路层类型(以太网,802.11,MPLS等)。
为每个数据包保存以下数据:
- 时间戳,毫秒级分辨率
- 数据包长度,因为它是“在线上”
- 数据包长度保存在文件中
- 数据包的原始字节
有关libpcap文件格式的详细说明,请访问:https: //wiki.wireshark.org/Development/LibpcapFileFormat
您还应该知道捕获文件中未保存的内容:
- 当前选择(选择的数据包,......)
-
名称解析信息。有关详细信息,请参见第7.9节“名称解析”
Pcapng文件可以选择保存名称解析信息。Libpcap文件不能。其他文件格式具有不同级别的支持。
- 捕获时丢弃的数据包数
- 使用“编辑/标记数据包”设置的数据包标记
- 使用“编辑/时间参考”设置的时间参考
- 当前的显示过滤器
为了匹配类Unix系统和Windows的不同策略,以及在不同类Unix系统上使用的不同策略,包含配置文件和插件的文件夹在不同平台上是不同的。我们指出顶层文件夹的位置,在这些文件夹下存储配置文件和插件,为它们提供与其实际位置无关的占位符名称,并在给出配置文件和插件的文件夹位置时使用这些名称。
|
小费 |
|---|---|
|
当您从“ 帮助” 菜单中选择“ 关于Wireshark”时,可以在显示的对话框的“ 文件夹”选项卡下找到Wireshark实际使用的文件夹列表。 |
%APPDATA%是个人应用程序数据文件夹,例如: C:\ Users \ username \ AppData \ Roaming \ Wireshark(详情请参见:第B.5.1节“Windows配置文件”)。
WIRESHARK是Wireshark程序文件夹,例如: C:\ Program Files \ Wireshark。
$ XDG_CONFIG_HOME是用户特定配置文件的文件夹。它通常是 $ HOME / .config,其中 $ HOME是用户的主文件夹,通常是 $ HOME / username或 macOS上的 / Users / username。
如果您正在使用macOS,并且您正在运行作为应用程序包安装的Wireshark副本,则APPDIR是Wireshark应用程序包的顶级目录,通常为 /Applications/Wireshark.app。否则,INSTALLDIR是顶级目录,其下包含安装Wireshark组件的子目录。这通常是指/usr如果Wireshark与系统捆绑在一起(例如,作为带有Linux发行版的软件包提供)和/ usr / local,例如,如果您从源代码构建Wireshark并安装它。
Wireshark在运行时使用许多配置文件。其中一些驻留在个人配置文件夹中,用于维护Wireshark运行之间的信息,而其中一些维护在系统区域中。
配置文件的内容格式在所有平台上都是相同的。
在Windows上:
- Wireshark的个人配置文件夹是该文件夹的 Wireshark子文件夹,即%APPDATA%\ Wireshark。
- Wireshark的全局配置文件夹是Wireshark程序文件夹,也用作系统配置文件夹。
在类Unix系统上:
- 个人配置文件夹是 $ XDG_CONFIG_HOME / wireshark。为了在2.2之前向后兼容Wireshark,如果$ XDG_CONFIG_HOME / wireshark不存在且$ HOME / .wireshark存在,则将使用后者。
- 如果您使用的是macOS,并且您正在运行作为应用程序包安装的Wireshark副本,则全局配置文件夹为 APPDIR / Contents / Resources / share / wireshark。否则,全局配置文件夹是INSTALLDIR / share / wireshark。
- 的/等文件夹是系统配置文件夹。您的系统上实际使用的文件夹可能会有所不同,也许是这样的: 在/ usr / local / etc中。
表B.1。配置文件概述
| 文件夹 | 描述 |
|---|---|
|
喜好 |
“首选项”对话框中的设置。 |
|
最近 |
最近的GUI设置(例如最近的文件列表)。 |
|
cfilters |
捕获过滤器。 |
|
dfilters |
显示过滤器。 |
|
colorfilters |
着色规则。 |
|
disabled_protos |
禁用协议。 |
|
醚 |
以太网名称解析。 |
|
MANUF |
以太网名称解析。 |
|
主机 |
IPv4和IPv6名称解析。 |
|
服务 |
网络服务。 |
|
子网 |
IPv4子网名称解析。 |
|
ipxnets |
IPX名称解析。 |
|
VLAN的 |
VLAN ID名称解析。 |
|
ss7pcs |
SS7点代码分辨率。 |
文件内容
- 喜好
-
此文件包含Wireshark首选项,包括捕获和显示数据包的默认值。它是一个简单的文本文件,包含以下形式的语句:
变量:值在程序启动时,如果全局配置文件夹中有首选项文件,则首先读取它。然后,如果个人配置文件夹中有 首选项文件,则读取该文件; 如果在两个文件中都设置了首选项,则个人首选项文件中的设置将覆盖全局首选项文件中的设置。
如果按“首选项”对话框中的“保存”按钮,则所有当前设置都将写入个人首选项文件。
- 最近
-
此文件包含各种GUI相关设置,如主窗口位置和大小,最近的文件列表等。它是一个简单的文本文件,包含以下形式的语句:
变量:值它在程序启动时读取并在程序退出时写入。
- cfilters
-
此文件包含已定义和保存的所有捕获筛选器。它由一行或多行组成,每行包含以下格式:
“<过滤器名称>”<过滤器字符串>在程序启动时,如果个人配置文件夹中有cfilters文件,则会读取该文件。如果个人配置文件夹中没有cfilters文件,那么,如果全局配置文件夹中有cfilters文件,则会读取该文件。
按“捕获过滤器”对话框中的“保存”按钮时,所有当前捕获过滤器都将写入个人捕获过滤器文件。
- dfilters
-
此文件包含已定义和保存的所有显示过滤器。它由一行或多行组成,每行包含以下格式:
“<过滤器名称>”<过滤器字符串>在程序启动时,如果个人配置文件夹中有dfilters文件,则会读取该文件。如果个人配置文件夹中没有dfilters文件,那么,如果全局配置文件夹中有dfilters文件,则会读取该文件。
按“显示过滤器”对话框中的“保存”按钮时,所有当前捕获过滤器都将写入个人显示过滤器文件。
- colorfilters
-
此文件包含已定义和保存的所有滤色器。它由一行或多行组成,每行包含以下格式:
@ <filter name> @ <filter string> @ [<bg RGB(16位)>] [<fg RGB(16位)>]在程序启动时,如果个人配置文件夹中有colorfilters文件,则会读取该文件。如果个人配置文件夹中没有colorfilters文件,则如果 全局配置文件夹中有colorfilters文件,则会读取该文件。
当您按下“着色规则”对话框中的“保存”按钮时,所有当前颜色过滤器都将写入个人颜色过滤器文件。
- disabled_protos
-
此文件中的每一行都指定禁用的协议名称。以下是一些例子:
tcp udp在程序启动时,如果全局配置文件夹中有disabled_protos文件,则首先读取该文件。然后,如果个人配置文件夹中有disabled_protos文件,则读取该文件; 如果两个文件中都存在协议集条目,则个人禁用协议文件中的设置将覆盖全局禁用协议文件中的设置。
按“启用的协议”对话框中的“保存”按钮时,当前禁用的协议集将写入个人禁用的协议文件。
- 醚
-
当Wireshark尝试将硬件MAC地址转换为名称时,它首先查询个人配置文件夹中的ethers文件。如果在该文件中找不到该地址,Wireshark将查询系统配置文件夹中的ethers文件。
这些文件中的每一行由一个硬件地址和由空格分隔的名称组成。硬件地址的数字由冒号(:),短划线( - )或句点(。)分隔。以下是一些例子:
ff-ff-ff-ff-ff广播 c0-00-ff-ff-ff-ff TR_broadcast 00.2b.08.93.4b.a1 Freds_machine当要将MAC地址转换为名称时,将读入此文件中的设置,并且不会由Wireshark写入。
- MANUF
-
在程序启动时,如果全局配置文件夹中有manuf文件,则会读取该文件。
此文件中的条目用于将以太网地址的前三个字节转换为制造商名称。此文件具有与ethers文件相同的格式,但地址长度为三个字节。
一个例子是:
00:00:01 Xerox#XEROX CORPORATION此文件中的设置在程序启动时读入,并且从不由Wireshark写入。
- 主机
-
Wireshark使用hosts文件中的条目将IPv4和IPv6地址转换为名称。
在程序启动时,如果全局配置文件夹中有hosts文件,则首先读取该文件。然后,如果个人配置文件夹中有hosts文件,则读取该文件; 如果两个文件中都有给定IP地址的条目,则个人主机文件中的设置将覆盖全局主机文件中的条目。
此文件的格式与Unix系统上通常的/ etc / hosts文件相同。
一个例子是:
#注释必须以#符号为前缀! 192.168.0.1 homeserver此文件中的设置在程序启动时读入,并且从不由Wireshark写入。
- 服务
-
Wireshark使用服务文件将端口号转换为名称。
在程序启动时,如果全局配置文件夹中有服务文件,则首先读取该文件。然后,如果 个人配置文件夹中有服务文件,则读取该文件; 如果两个文件中都有给定端口号的条目,则个人主机文件中的设置将覆盖全局主机文件中的条目。
一个例子是:
mydns 5045 / udp#我自己的域名服务器 mydns 5045 / tcp#我自己的域名服务器这些文件的设置在程序启动时读入,从不由Wireshark写入。
- 子网
-
Wireshark使用子网文件将IPv4地址转换为子网名称。如果未找到来自主机文件或DNS的完全匹配,Wireshark将尝试部分匹配该地址的子网。
在程序启动时,如果个人配置文件夹中有子网文件,则首先读取该文件。然后,如果 全局配置文件夹中有子网文件,则读取该文件; 如果在两个文件中都设置了首选项,则全局首选项文件中的设置将覆盖个人首选项文件中的设置。
其中一个文件中的每一行由IPv4地址,仅由“/”分隔的子网掩码长度和由空格分隔的名称组成。虽然地址必须是完整的IPv4地址,但随后会忽略超出掩码长度的任何值。
一个例子是:
#注释必须以#符号为前缀! 192.168.0.0/24 ws_test_network部分匹配的名称将打印为“subnet-name.remaining-address”。例如,上面子网下的“192.168.0.1”将打印为“ws_test_network.1”; 如果上面的掩码长度是16而不是24,则打印的地址将是“ws_test_network.0.1”。
这些文件的设置在程序启动时读入,从不由Wireshark写入。
- ipxnets
-
当Wireshark尝试将IPX网络号转换为名称时,它首先查询个人配置文件夹中的ipxnets文件。如果在该文件中找不到该地址,Wireshark将查询系统配置文件夹中的ipxnets文件。
一个例子是:
C0.A8.2C.00 HR c0-a8-1c-00 CEO 00:00:BE:EF IT_Server1 110f FileServer3当要将IPX网络号转换为名称时,将读入此文件中的设置,并且从不由Wireshark写入。
- VLAN的
-
Wireshark使用vlans文件将VLAN标记ID转换为名称。
如果当前活动的配置文件文件夹中存在vlan文件,则使用该文件。否则,将使用个人配置文件夹中的vlans文件。
此文件中的每一行包含一个VLAN标记ID和由空格或制表符分隔的描述名称。
一个例子是:
123 Server-LAN 2049 HR-Client-LAN此文件中的设置在程序启动时或更改活动配置文件时读取,并且从不由Wireshark写入。
- ss7pcs
-
Wireshark使用ss7pcs文件将SS7点代码转换为节点名称。
在程序启动时,如果个人配置文件夹中有ss7pcs文件,则会读取该文件。
此文件中的每一行包含一个网络指示符,后跟一个破折号,后跟十进制的点代码和由空格或制表符分隔的节点名称。
一个例子是:
2-1234 MyPointCode1此文件中的设置在程序启动时读入,并且从不由Wireshark写入。
Wireshark支持各种插件。插件可以是用Lua编写的脚本,也可以是用C或C ++编写的代码,也可以编译成机器代码。
Wireshark在个人插件文件夹和全局插件文件夹中查找插件。Lua插件存储在插件文件夹中; 已编译的插件存储在插件文件夹的子文件夹中,子文件夹名称为Wireshark次要版本号(XY)。每个Wireshark库(libwireshark,libwscodecs和libwiretap)都有另一个层次结构级别。因此,例如用于libwireshark插件位置 foo.so(foo.dll在Windows上)将PLUGINDIR / XY / EPAN (libwireshark曾经被称为libepan;另一个文件夹名称的编解码器 和窃听)。
在Windows上:
- 个人插件文件夹是%APPDATA%\ Wireshark \ plugins。
- 全局插件文件夹是WIRESHARK \ plugins。
在类Unix系统上:
- 个人插件文件夹是〜/ .local / lib / wireshark / plugins。
|
注意 |
|---|---|
|
为了更好地支持二进制插件,此文件夹在Wireshark 2.5中已更改。建议使用新文件夹,但对于lua脚本,只能继续使用$ XDG_CONFIG_HOME / wireshark / plugins以实现向后兼容。这对于并排安装旧版Wireshark非常有用。如果新旧文件夹名称重复,则新文件夹获胜。 |
- 如果您在macOS上运行并且Wireshark作为应用程序包安装,则全局插件文件夹为 %APPDIR%/ Contents / PlugIns / wireshark,否则为 INSTALLDIR / lib / wireshark / plugins。
在这里,您将找到有关不同Windows版本的Wireshark中使用的文件夹的一些详细信息。
如前所述,您可以在“关于Wireshark”对话框中找到当前使用的文件夹。
Windows使用一些特殊目录来存储定义“用户配置文件”的用户配置文件。这可能会令人困惑,因为默认目录位置已从Windows版本更改为版本,并且对于英语和国际化版本的Windows可能也有所不同。
|
注意 |
|---|---|
|
如果您已升级到新的Windows版本,则您的个人资料可能会保留在以前的位置。此处提到的默认值可能不适用。 |
以下内容将引导您到正确的位置查找Wireshark的配置文件数据。
- Windows 10,Windows 8.1,Windows 8,Windows 7,Windows Vista和关联的服务器版本
- C:\ Users \ username \ AppData \ Roaming \ Wireshark。
- Windows XP,Windows Server 2003和Windows 2000 [1]
- C:\ Documents and Settings \ username \ Application Data。“文档和设置”和“应用程序数据”可能会国际化。
- Windows NT 4 [1]
- C:\ WINNT \ Profiles \ username \ Application Data \ Wireshark
- Windows ME,带有用户配置文件的Windows 98 [1]
- 在Windows ME和98中,您可以启用单独的用户配置文件。在这种情况下,使用类似C:\ windows \ Profiles \ username \ Application Data \ Wireshark 的东西。
- Windows ME,没有用户配置文件的Windows 98 [1]
- 如果未启用用户配置文件,则所有用户的默认位置为 C:\ windows \ Application Data \ Wireshark。
一些较大的Windows环境使用漫游配置文件。如果是这种情况,您使用的所有程序的配置将不会保存在本地硬盘驱动器上。它们将存储在域服务器上。
您的设置将随您一起从计算机传送到计算机,但有一个例外。您的配置文件数据中的“本地设置”文件夹(通常类似于: C:\ Documents and Settings \ username \ Local Settings)将不会传输到域服务器。这是临时捕获文件的默认值。
Wireshark使用由TMPDIR或TEMP环境变量设置的文件夹。此变量将由Windows安装程序设置。
Wireshark区分协议(例如tcp)和协议字段(例如tcp.port)。
有关所有协议和协议字段的完整列表,请参阅https://www.wireshark.org/docs/dfref/上的“显示过滤器参考”。
目录
与主应用程序一起,Wireshark附带了一系列命令行工具,可以帮助完成专门的任务。本章将介绍其中一些工具。你可以找到所有关于Wireshark的命令行工具的更多信息 的网站。
TShark是Wireshark的面向终端版本,用于在不需要或不提供交互式用户界面时捕获和显示数据包。它支持相同的选项wireshark。有关详细信息, tshark请参阅本地手册页(man tshark)或 在线版本。
TShark(Wireshark)3.1.0(v3.1.0rc0-36-g18b180c5) 转储和分析网络流量。 有关更多信息,请访问https://www.wireshark.org。 用法:tshark [options] ... 捕获接口: -i <接口>接口的名称或idx(def:第一个非环回) -f <捕获过滤器> libpcap过滤器语法中的数据包过滤器 -s <snaplen>数据包快照长度(def:适当的最大值) -p不以混杂模式 捕获-I在监控模式下捕获,如果可用 -B <缓冲区大小>内核缓冲区大小(def:2MB) -y <link type>链路层类型(def :首先适当) --time-stamp-type <type> timestamp方法,用于接口 -D打印接口列表和exit -L打印列表的链接层类型iface和exit --list-time-stamp-types打印时间戳类型列表iface和exit 捕获停止条件: -c <数据包计数>在n个数据包后停止(def:无限) -a <autostop cond。> ... duration:NUM - 在NUM秒 文件大小后停止:NUM - 在NUM KB之后停止此文件 文件:NUM - NUM个文件后停止 捕获输出: -b <ringbuffer opt。> ... duration:NUM - NUM秒后切换到下一个文件 interval:NUM - 创建NUM秒 文件大小的时间间隔:NUM - 在NUM KB文件后切换到下一个文件 :NUM - ringbuffer:在NUM个文件后替换 输入文件: -r <infile | - >设置要读取的文件名(或' - 'for stdin) 处理: -2执行两遍分析 -M <包计数>执行会话自动重置 -R <读取过滤器>包在Wireshark显示过滤器语法中读取过滤器 (需要-2) -Y <显示过滤器>在Wireshark显示过滤器 语法中的packet displaY过滤器 -n禁用所有名称解析(def:全部启用) -N <名称解析标志>启用特定名称解析:“mnNtdv” -d <layer_type> == <selector>,<decode_as_protocol> ... “解码为“,有关详细信息,请参见手册页 示例:tcp.port == 8888,http -H <hosts file>读取hosts文件中的条目列表, 然后将其写入捕获文件。(Implies -W n) -- enable -protocol <proto_name> 启用解析proto_name --disable-protocol <proto_name> 启用启发式协议的解析 - 禁用启发式<short_name> 禁用解释启发式协议 输出: -w <outfile | - >将数据包写入名为“outfile”的pcapng格式文件 (或“ - ”用于stdout) -C < config profile>以指定的配置文件开头 -F <输出文件类型>设置输出文件类型,默认为pcapng 为空“-F”选项将列出文件类型 -V add packet of packet tree(Packet Details) -O < protocols>仅显示这些协议的数据包详细信息,逗号 分离 -P打印数据包摘要,即使写入文件 -S <separator>行分隔符打印数据包 -x添加十六进制输出和ASCII转储(数据包字节) -T pdml | ps | psml | json | jsonraw | ek |标签|文|域|? 文本输出的格式(def:text) -j <protocolfilter>协议层过滤如果-T ek | pdml | json被选中 (例如“ip ip.flags text”,过滤器不会扩展子 节点,除非在子节点中也指定了子节点filter -J <protocolfilter>顶级协议过滤器,如果选择-T ek | pdml | json (例如“http tcp”,扩展所有子节点的过滤器) -e <field>字段打印如果选择-Tfields(例如tcp.port, _ws.col.Info) 此选项可以重复打印多个字段 -E < fieldsoption> = <value>在选择-Tfields时设置输出选项: bom = y | n打印UTF-8 BOM 头= y | n开关头打开和关闭 分隔符= / t | / s | <char>选择选项卡, space,可打印字符作为分隔符 出现= f | l | a打印第一个,最后一次或所有出现的每个字段 聚合器=,| / s | <char>选择逗号,空格,可打印字符为 聚合器 引用= d | s | n选择双,单,没有引号的值 -ta | ad | d | dd | e | r | u | ud |?时间戳的输出格式(def:r:rel。到第一个) -us | hms输出格式为秒(def:s:秒) -l刷新标准输出后每个数据包 -q在stdout上更安静(例如使用统计数据时) ) -Q仅将真实错误记录到stderr(比-q更安静) -g启用对输出文件的组读取访问权限 -W n如果支持,则在文件中保存额外信息。 n =写入网络地址解析信息 -X <key>:<value> eXtension选项,有关详细信息,请参见手册页 -U tap_name PDU导出模式,有关详细信息,请参见手册页 -z <statistics>各种统计信息,有关详细信息,请参见手册页 --capture-comment <comment> 为新创建的 输出文件添加捕获注释(仅适用于pcapng) -- export -objects <protocol>,<destdir>将协议的导出对象保存到 名为“destdir”的目录 - color color output text对于Wireshark GUI, 需要一个支持24位颜色的终端 还为pdml和psml格式提供颜色属性 (请注意,属性是非标准的) - no -duplicate-keys如果指定了-T json,则将对象中的重复键合并 为单个键,其值为包含所有 值的json数组 - -elastic-mapping-filter <protocols>如果指定了-G elastic-mapping,则只将 指定的协议放在映射文件中。 其他: -h显示此帮助并退出 -v display version info并退出 -o <name>:< value> ...覆盖首选项设置 -K <keytab>用于kerberos解密的密钥表文件 -G [报告]转储几个可用报告中的一个并退出 default report =“fields” 使用“-G help”获取更多帮助 Dumpcap可以从启用的BPF JIT编译器中受益可用。 您可能希望通过执行以下命令启用它: “echo 1> / proc / sys / net / core / bpf_jit_enable” 请注意,这可能会降低系统的安全性!
使用tcpdump而不是 使用捕获数据包通常更有用wireshark。例如,您可能希望进行远程捕获,或者没有GUI访问权限,或者没有在远程计算机上安装Wireshark。
tcpdump截断数据包的旧版本为68或96字节。如果是这种情况,请使用-s捕获完整大小的数据包:
$ tcpdump -i <interface> -s 65535 -w <some-file>
您必须指定正确的接口和要保存的文件的名称。此外,当您认为已捕获足够的数据包时,必须使用^ C终止捕获。
tcpdump不属于Wireshark发行版。您可以从http://www.tcpdump.org/获取它, 或者在大多数Linux发行版中作为标准包获取。有关详细信息,tcpdump请参阅本地手册页(man tcpdump)或在线版本。
Dumpcap是一种网络流量转储工具。它从实时网络捕获数据包数据并将数据包写入文件。Dumpcap的本机捕获文件格式是pcapng,也是Wireshark使用的格式。
如果没有任何选项设置,它将使用pcap库从第一个可用网络接口捕获流量,并将接收到的原始数据包数据以及数据包的时间戳写入pcapng文件。捕获筛选器语法遵循pcap库的规则。有关详细信息,dumpcap请参阅本地手册页(man dumpcap)或在线版本。
Dumpcap(Wireshark)3.1.0(v3.1.0rc0-36-g18b180c5) 捕获网络数据包并将其转储到pcapng或pcap文件中。 有关更多信息,请访问https://www.wireshark.org。 用法:dumpcap [options] ... 捕获接口: -i <接口>接口的名称或idx(def:第一个非环回), 或者用于远程捕获,使用以下格式之一: rpcap:// <host> / <interface> TCP @ <host>:<port> -f <捕获过滤器> libpcap过滤器语法中的数据包过滤器 -s <snaplen>数据包快照长度(def:适当的最大值) -p不以混杂模式捕获 -I在监控模式下捕获,如果可用 -B <缓冲区大小> MiB中内核缓冲区的大小(def:2MiB) -y <link type>链路层类型(def:第一个适当的)-- time-stamp-type <type >接口的时间戳方法 -D打印接口列表和退出 -L打印列表的iface和exit的链接层类型 --list-time-stamp-types打印iface和exit的时间戳类型列表 -d打印生成的BPF代码for wifi filter -k set channel on wifi interface: <freq>,[<type>],[<center_freq1>],[<center_freq2>] -S每秒一次打印每个接口的统计信息 -M用于-D,-L和-S,产生机器可读输出 停止条件: -c <数据包计数>在n个数据包后停止(def:无限) -a <autostop cond。> ... duration:NUM - 在NUM秒 文件大小后停止:NUM - 在NUM kB文件后停止此文件 :NUM - 在NUM个文件 包后停止:NUM - 在NUM个数据包后停止 输出(文件): - w <文件名>要保存的文件的名称(def:tempfile) -g在输出文件上启用组读取访问权限 -b <ringbuffer opt。> ... duration:NUM - 在NUM秒 间隔后切换到下一个文件:NUM - 创建NUM秒 文件大小的时间间隔:NUM - 在NUM kB 文件后切换到下一个文件:NUM - ringbuffer:replace after after NUM个文件 包:NUM - ringbuffer:在NUM包后替换 -n使用pcapng格式而不是pcap(默认) -P使用libpcap格式而不是pcapng --capture-comment <comment> 在输出文件中添加捕获注释 (仅限于pcapng) 其他: -N <packet_limit> dumpcap内缓冲的分组的最大数量 -C <byte_limit>用于缓冲数据包的最大字节数 dumpcap内 -t使用每个接口的单独的线程 -q不报告分组捕获计数 -v打印版本信息和exit -h显示此帮助并退出 Dumpcap可以从已启用的BPF JIT编译器(如果可用)中受益。 您可能希望通过执行以下命令启用它: “echo 1> / proc / sys / net / core / bpf_jit_enable” 请注意,这可能会降低系统的安全性! 示例:dumpcap -i eth0 -a duration:60 -w输出。 “从接口eth0捕获数据包直到60s传递到output.pcapng” 使用Ctrl-C随时停止捕获。
capinfos可以打印有关捕获文件的信息,包括文件类型,数据包数,日期和时间信息以及文件哈希值。信息可以以人类和机器可读格式打印。有关详细信息,capinfos请参阅本地手册页(man capinfos)或在线版本。
Capinfos(Wireshark)3.1.0(v3.1.0rc0-160-g95bf9f5e) 打印有关捕获文件的各种信息(信息)。 有关更多信息,请访问https://www.wireshark.org。 用法:capinfos [options] <infile> ... 一般信息: -t显示捕获文件类型 -E显示捕获文件封装 -I显示捕获文件接口信息 -F显示附加捕获文件信息 -H显示SHA256, RMD160和文件的SHA1哈希 -k显示捕获注释 大小信息: -c显示数据包数量 -s显示文件大小(以字节为单位) -d显示所有数据包的总长度(以字节为单位) -l显示数据包大小限制(快照长度) 时间信息: -u显示捕获持续时间(以秒为单位) - 显示捕获开始时间 -e显示捕获结束时间 -o显示捕获文件的时间顺序状态(True / False ) -S显示开始和结束时间为秒 统计信息: -y显示平均数据速率(以字节/秒为单位) -i显示平均数据速率(以位/秒为单位) -z显示平均数据包大小(以字节为单位) -x显示平均数据包速率(以包/秒为单位) 元数据信息: -n显示已解析的IPv4和IPv6地址 数-D显示解密机密数 输出格式: -L生成长报告(默认) -T生成表格报告 -M显示长报告中的机器可读值 表格报告选项: -R生成标题记录(默认) -r不生成标题记录 -B具有TAB字符的单独信息(默认) -m单独的信息用逗号(,)字符 -b单独的信息用空格字符 -N不引用信息(默认) -q引用信息用单引号(') -Q引用信息用双引号(“) 杂项: -h显示此帮助并退出 -C取消处理如果文件打开失败(默认是继续) - 生成所有信息(默认) -K禁用显示捕获注释 选项按从左到右的顺序处理,后面的选项取代 或添加到早期选项。 如果没有给出选项,则默认为以长报告 输出格式显示所有信息。
Rawshark从文件或管道中读取数据包流,并打印一行描述其输出,然后为stdout上的每个数据包打印一组匹配字段。有关详细信息,rawshark请参阅本地手册页(man rawshark)或 在线版本。
Rawshark(Wireshark)3.1.0(v3.1.0rc0-36-g18b180c5) 转储和分析网络流量。 有关更多信息,请访问https://www.wireshark.org。 用法:rawshark [options] ... 输入文件: -r <infile>设置要从 Processing中读取的管道或文件名: -d <encap:linktype> | <proto:protoname> 数据包封装或协议 -F <field>字段显示 -m虚拟内存限制,以字节为单位 -n禁用所有名称解析(def:全部启用) -N <名称解析标志>启用特定名称解析:“mnNtdv” -p使用系统' (可能有64位时间戳) -R <读取过滤器> Wireshark中的数据包过滤器显示过滤器语法 -s跳过输入上的PCAP标头 输出: -l刷新输出后每个数据包 -S格式字符串为字段 (%D - 名称, %S - stringval,%N numval) -t ad | a | r | d | dd | e时间戳的输出格式(def:r:rel。到first) 其他: -h显示此帮助并退出 -o <name >:<value> ...覆盖首选项设置 -v显示版本信息并退出
editcap是一个用于修改捕获文件的通用实用程序。它的主要功能是从捕获文件中删除数据包,但它也可用于将捕获文件从一种格式转换为另一种格式,以及打印有关捕获文件的信息。有关详细信息, editcap请参阅本地手册页(man editcap)或在线版本。
Editcap(Wireshark)3.1.0(v3.1.0rc0-160-g95bf9f5e) 编辑和/或翻译捕获文件的格式。 有关更多信息,请访问https://www.wireshark.org。 用法:editcap [options] ... <infile> <outfile> [<packet#> [ - <packet#>] ...] <infile>和<outfile>必须都存在。 可以选择单个分组或一系列分组。 数据包选择: -r保留选定的数据包; 默认是删除它们。 -A <start time>仅输出时间戳 在给定时间之后(或等于)的数据包(格式为YYYY-MM-DD hh:mm:ss)。 -B <停止时间>仅输出时间戳在...之前的数据包 给定时间(格式为YYYY-MM-DD hh:mm:ss)。 重复 删除数据包: - 在检查重复数据包之前,从数据包中删除vlan信息。 -d如果重复则删除数据包(window == 5)。 -D <dup window>如果重复则删除数据包; 可配置的<dup window>。 有效的<dup window>值为0到1000000. 注意:带有-v(详细选项)的<dup window> 0 对于打印MD5哈希很有用。 -w <dup time window>如果找到重复数据包,则删除数据包等于或 小于当前数据包之前的<dup time window>。 <dup time window>以相对秒数指定 (例如0.000001)。 注意: 除了-v之外,将“重复数据包删除”选项与其他editcap选项一起使用可能并不总是按预期工作。 具体来说, 如果与-d,-D或-w结合使用,则-r,-t或-S选项很可能不具有所需的效果。 --skip-radiotap-header在检查数据包重复时跳过radiotap标头。 当处理由多个无线电 在彼此附近的相同信道上捕获的分组时有用。 数据包操作: -s <snaplen>将每个数据包截断为最大值。<snaplen>数据字节。 -C [offset:] <choplen>按<choplen>字节对每个数据包进行切换。正数值 在数据包开始时切断,在数据 包结束时为负值。如果可选偏移量在长度之前, 则切断的字节将从该值偏移。 正偏移来自分组开始, 负偏移来自分组结束。您可以 多次使用此选项, 在数据包中最多允许2个斩波区域,条件是至少为1 choplen是积极的,至少1是消极的。 -L在切碎 和/或卡扣时调整框架(即报告的)长度。 -t <时间调整>调整每个数据包的时间戳。 <时间调整>是相对秒(例如-0.5)。 -S <严格调整>根据需要调整数据包的时间戳,以确保 严格的时间顺序递增顺序。<strict adjustment>以相对秒指定, 值为0或0.000001是最合理的。 负调整值将修改时间戳 每个数据包的增量时间是 指定调整的绝对值。值-0将 所有数据包设置为第一个数据包的时间戳。 -E <错误概率>设置 特定包字节将随机改变的概率(在0.0和1.0之间)。 -o <change offset>当与-E一起使用时,从 数据包的开头跳过一些字节。这允许保留一些 字节,以便不改变某些标题。 --seed <seed>与-E一起使用时,设置要用于的种子 伪随机数发生器。这允许人们 重复特定的错误序列。 -I <要忽略的字节> 在MD5哈希计算期间忽略帧开头的指定字节数,除非 帧太短,然后使用全帧。 用于删除在 多个路由器( 例如,不同的mac地址)上获取的重复数据包。 例如-I 26在Ether / IP的情况下将忽略 ether(14)和IP头(20 - 4(src ip) - 4(dst ip))。 -a <framenum>:<comment>为给定的帧编号添加或替换注释 输出文件: -c <每个文件的数据包>根据 统一的数据包计数将数据包输出拆分为不同的文件, 每个文件的最大数据包数为< >每个。 -i <每个文件的秒数>基于 统一的时间间隔将数据包输出拆分为不同的文件, 每个文件最多<秒/文件>。 -F <capture type>设置输出文件类型; 默认是pcapng。 空的“-F”选项将列出文件类型。 -T <encap type>设置输出文件封装类型; 与输入文件相同。空的“-T”选项将 列出封装类型。 --inject-secrets <type>,<file>从<file>插入解密秘密。列出 支持的秘密类型“--inject-secrets help”。 --discard-all-secrets 在写入输出文件时丢弃输入文件中的所有解密机密。不丢弃 “--inject-secrets”在同一 命令行中添加的秘密。 其他: -h显示此帮助并退出。 -v详细输出。 如果-v与任何“重复数据包 删除”选项(-d,-D或-w)一起使用,则数据包长度 和MD5哈希值将打印为标准错误。
editcap:“
-F ”标志的可用捕获文件类型是:5views - InfoVista 5View capture
btsnoop - Symbian OS btsnoop
commview - TamoSoft CommView
dct2000 - Catapult DCT2000 trace(.out格式)
erf - Endace ERF capture
eyesdn - EyeSDN USB S0 / E1 ISDN跟踪格式
k12text - K12文本文件
lanalyzer - Novell LANalyzer
logcat - Android Logcat二进制格式
logcat-brief - Android Logcat简短文本格式
logcat-long - Android Logcat长文本格式
logcat-process - Android Logcat进程文本格式
logcat-tag - Android Logcat标签文本格式
logcat-thread - Android Logcat Thread文本格式
logcat-threadtime - Android Logcat Threadtime文本格式
logcat-time - Android Logcat时间文本格式
modpcap - 修改tcpdump - pcap
netmon1 - Microsoft NetMon 1.x
netmon2 - Microsoft NetMon 2.x
nettl - HP-UX nettl trace
ngsniffer - Sniffer(DOS )
ngwsniffer_1_1 - NetXray,Sniffer(Windows)1.1
ngwsniffer_2_0 - Sniffer(Windows)2.00x
niobserver - 网络仪器观察者
nokiapcap - 诺基亚tcpdump - pcap
nsecpcap - Wireshark / tcpdump / ... - 纳秒pcap
nstrace10 - NetScaler Trace(版本1.0)
nstrace20 - NetScaler Trace(2.0版)
nstrace30 - NetScaler Trace(3.0版)
nstrace35 - NetScaler Trace(版本3.5)
pcap - Wireshark / tcpdump / ... - pcap
pcapng - Wireshark / ... - pcapng
rf5 - Tektronix K12xx 32位.rf5格式
rh6_1pcap - RedHat 6.1 tcpdump - pcap
snoop - Sun snoop
suse6_3pcap - SuSE 6.3 tcpdump - pcap
visual - Visual Networks流量捕获
editcap:“ - T”标志的可用封装类型是:
ap1394 - Apple IP-over-IEEE 1394
arcnet - ARCNET
arcnet_linux - Linux ARCNET登陆
- 朗讯/登高访问设备
atm-pdus - ATM PDU
atm-pdus-untruncated - ATM PDU - 未截断
atm-rfc1483 - RFC 1483 ATM
ax25 - 业余无线电AX.25
ax25-kiss - AX.25与KISS标头
bacnet-ms-tp - BACnet MS / TP
bacnet-ms-tp-with-direction - BACnet MS / TP与定向信息
- ASN.1基本编码规则
bluetooth-bredr-bb-rf - 蓝牙BR / EDR基带射频
蓝牙-h4 - 蓝牙H4
bluetooth-h4-linux - 蓝牙H4与linux头
蓝牙-hci - 蓝牙无传输层
蓝牙-le-ll - 蓝牙低功耗链路层
蓝牙-le-ll-rf - 蓝牙低功耗链路层RF
蓝牙-linux-monitor-蓝牙Linux监控器
can20b - 控制器区域网络2.0B
chdlc - Cisco HDLC
chdlc-with-direction - 思科HDLC与方向信息
余弦 - CoSine L2调试日志
dbus - D-Bus
dct2000 - Catapult DCT2000
docsis - 数据电缆服务接口规范
docsis31_xra31 -使用Excentis XRA伪标头
dpauxmon的DOCSIS - 带Unigraf伪标头的DisplayPort AUX通道
dpnss_link - 数字专用信令系统1号链路层
dvbci - DVB-CI(通用接口)
ebhscr - Elektrobit高速捕获和重放
enc - OpenBSD enc(4)封装接口
epon - 以太网无源光网络
erf - 可扩展记录格式
ether - 以太网
ether-mpacket - IEEE 802.3br mPackets
ether-nettl - 带nettl报头的以太网
fc2 - 光纤通道FC-2
fc2sof - 带帧定界符的光纤通道FC-2
fddi - FDDI
fddi-nettl - 带有nettl报头的FDDI fddi-
swapped - FDDI with位交换MAC地址
flexray - FlexRay
frelay - 帧中继
frelay-with-direction - 具有方向信息的
帧中继gcom-serial-GCOM串行
gcom-tie1-GCOM TIE1
gfp-f-ITU-T G.7041 / Y.1303通用成帧程序帧映射模式
gfp-t-ITU- T G.7041 / Y.1303通用成帧程序透明模式
gprs-llc - GPRS LLC
gsm_um - GSM Um接口
hhdlc - HiPath HDLC
i2c-linux - 具有Linux特定伪标头
ieee-802-11的I2C - IEEE 802.11无线LAN
ieee-802-11-avs - IEEE 802.11 plus AVS无线电头
ieee-802-11-netmon - IEEE 802.11 plus网络监视器无线电头
ieee-802-11-prism - IEEE 802.11 plus Prism II监控模式无线头
ieee-802-11-radio - IEEE 802.11无线局域网,带有无线电信息
ieee-802-11-radiotap-IEEE 802.11 plus radiotap radio header
ieee-802-16-mac-cps - IEEE 802.16 MAC Common Part Sublayer
infiniband - InfiniBand
ios - Cisco IOS内部
ip-ib-IP over IB
ip-over-fc-RFC 2625 IP-over-
fiber 信道
ip-over-ib-IP over InfiniBand ipfix - RFC 5655 / RFC 5101 IPFIX
ipmb-kontron - 智能平台管理总线控创伪标头
ipmi-trace - IPMI跟踪数据收集
ipnet - Solaris IPNET
irda - IrDA
isdn - ISDN
iso14443 - ISO 14443非接触式智能卡标准
ixveriwave - IxVeriWave标头和统计数据块
jfif - JPEG / JFIF
json - JavaScript对象表示法
juniper-atm1 - Juniper ATM1
juniper-atm2 - Juniper ATM2
juniper-chdlc - Juniper C-HDLC
juniper-ether - Juniper以太网
juniper-frelay - Juniper Frame-继电器
juniper-ggsn-Juniper GGSN
juniper-mlfr-Juniper MLFR
juniper-mlppp-Juniper MLPPP
juniper-ppp-Juniper PPP
juniper-pppoe-Juniper PPPoE
juniper-st-Juniper Secure Tunnel Information
juniper-svcs-Juniper Services
juniper-vn - Juniper VN
juniper-vp - Juniper Voice PIC
k12
- K12协议分析器lapb - LAPB
lapd - LAPD
layer1-event - EyeSDN第1层事件
lin - 本地互连网络
linux-atm-clip - Linux ATM CLIP
linux-lapd - LAPD with Linux pseudo-header
linux-sll - Linux cooked-模式捕获
logcat - Android Logcat二进制格式
logcat_brief - Android Logcat简短文本格式
logcat_long - Android Logcat长文本格式
logcat_process - Android Logcat进程文本格式
logcat_tag - Android Logcat标签文本格式
logcat_thread - Android Logcat线程文本格式
logcat_threadtime - Android Logcat Threadtime文本格式
logcat_time - Android的logcat的时间文本格式
环路- OpenBSD的回环
loratap - LoRaTap
ltalk -的LocalTalk
message_analyzer_wfp_capture2_v4 -信息分析世界粮食计划署为Capture2 V4
message_analyzer_wfp_capture2_v6 -信息分析世界粮食计划署为Capture2 V6
message_analyzer_wfp_capture_auth_v4 -信息分析世界粮食计划署捕获验证V4
message_analyzer_wfp_capture_auth_v6 -信息分析世界粮食计划署捕获验证V6
message_analyzer_wfp_capture_v4 -消息Analyzer WFP Capture v4
message_analyzer_wfp_capture_v6 - 消息分析器WFP Capture v6
mime - MIME
最多 - 面向媒体的系统传输
mp2ts - ISO / IEC 13818-1 MPEG2-TS
mpeg - MPEG
mtp2 - SS7 MTP2
mtp2-with-phdr - 带有伪
头mtp3的MTP2 - SS7 MTP3
mux27010 - MUX27010
netanalyzer - Hilscher
netANALYZER netanalyzer-transparent - Hilscher netANALYZER-透明
netlink - Linux Netlink
netmon_event - 网络监视器网络事件
netmon_filter - 网络监视器过滤器
netmon_header - 网络监视器标头
netmon_network_info - 网络监视器网络信息
nfc-llcp - NFC LLCP
nflog - NFLOG
nordic_ble - Nordic BLE Sniffer
nstrace10 - NetScaler Encapsulation 1.0以太网
nstrace20 - NetScaler Encapsulation 2.0 of Ethernet
nstrace30 - NetScaler Encapsulation 3.0 of Ethernet
nstrace35 - NetScaler Encapsulation 3.5 of Ethernet
null - NULL / Loopback
packetlogger -
Apple Bluetooth PacketLogger pflog - OpenBSD PF Firewall log
pflog-old - OpenBSD PF防火墙日志,3.4之前的
pktap - Apple PKTAP
ppi - Per-数据包信息头
ppp-PPP
ppp-with-direction-PPP with Directional Info
pppoes-PPP-over-Ethernet session
raw-icmp-nettl - raw ICMP with nettl headers
raw-icmpv6-nettl - raw ICMPv6 with nettl headers
raw-telnet- nettl - 原始telnet与nettl标头
rawip - 原始IP
rawip-nettl - 带有nettl头的原始IP
rawip4 - 原始IPv4
rawip6 - 原始IPv6 redback -
Redback SmartEdge
rfc7468 - RFC 7468文件
rtac-serial - RTAC串行线
ruby_marshal - Ruby marshal对象
s4607 - STANAG 4607
s5066-dpdu - STANAG 5066数据传输子层PDU(D_PDU)
sccp - SS7 SCCP
sctp - SCTP
sdh - SDH
sdjournal - systemd journal
sdlc - SDLC
sita-wan - SITA WAN数据包
单 - SLIP
套接字 - SocketCAN
赛门铁克 - 赛门铁克企业防火墙
tnef - 传输中性封装格式
tr -令牌环
tr-nettl - 具有nettl头的令牌环
tzsp - Tazmen嗅探器协议
未知 - 未知
unknown-nettl - 未知的链路层类型与nettl头
usb-darwin - 带有Darwin的USB数据包(macOS等)头
usb-freebsd - USB数据包使用FreeBSD头文件
usb-linux - 带有Linux头文件的USB数据包
usb-linux-mmap - 带有Linux头文件和填充文件的USB数据包
usb-usbpcap - 带有USBPcap头的
用户数据包user0 - USER 0
user1 - USER 1
user2 - USER 2
user3 - USER 3
user4 - USER 4
user5 - USER 5
user6 - USER
6 user7 - USER 7
user8 - USER 8
user9 - USER 9
user10 - USER 10
user11 - USER 11
user12 - USER 12
user13 - USER 13
user14 - USER 14
user15 - USER 15
v5-ef - V5 Envelope Function
vpp - Vector Packet Processing dispatch trace
vsock - Linux vsock
whdlc - Wellfleet HDLC
的Wireshark-上-PDU - Wireshark的上层PDU出口
WPAN - IEEE 802.15.4无线PAN
WPAN-nofcs - IEEE 802.15.4无线PAN与FCS不存在
WPAN-nonask-PHY - IEEE 802.15.4无线PAN非ASK PHY
WPAN -tap - 带有TAP伪标头的IEEE 802.15.4无线
x2e-serial-X2E串行线路捕获
x2e-xoraya - X2E Xoraya
x25-nettl - X.25与nettl标头
xeth - 施乐3MB以太网
Mergecap是一个程序,它将多个已保存的捕获文件组合到-w参数指定的单个输出文件中。Mergecap知道如何读取libpcap捕获文件,包括tcpdump的捕获文件。此外,Mergecap可以从snoop(包括Shomiti)和atmsnoop,LanAlyzer,Sniffer(压缩或未压缩),Microsoft网络监视器,AIX的iptrace,NetXray,Sniffer Pro,RADCOM的WAN / LAN分析器,Lucent / Ascend路由器调试输出中读取捕获文件,HP-UX的nettl,以及东芝ISDN路由器的转储输出。没有必要告诉Mergecap您正在阅读的文件类型; 它将自己确定文件类型。如果使用压缩,Mergecap还能够读取任何这些文件格式gzip。Mergecap直接从文件中识别出来; 为此目的不需要“.gz”扩展名。
默认情况下,它以pcapng格式写入捕获文件,并将输入捕获文件中的所有数据包写入输出文件。该-F标志可用于指定写入捕获文件的格式; 它可以用libpcap格式(标准的libpcap格式,一些修补版本的libpcap使用的修改格式,Red Hat Linux 6.1使用的格式,或SuSE Linux 6.3使用的格式),snoop格式,未压缩的Sniffer格式, Microsoft Network Monitor 1.x格式,以及基于Windows的Sniffer软件版本使用的格式。
除非-a指定了标志,否则输入文件中的数据包将根据每个帧的时间戳按时间顺序合并。Mergecap假设单个捕获文件中的帧已按时间顺序存储。当-a指定的标志,分组被直接从每个输入文件到输出文件,独立的每个帧的时间戳的复制。
如果该-s标志用于指定快照长度,则输入文件中具有比指定快照长度更多捕获数据的帧将仅具有写入输出文件的快照长度指定的数据量。如果要读取输出文件的程序无法处理大于特定大小的数据包(例如,Solaris 2.5.1和Solaris 2.6中的snoop版本似乎拒绝大于标准以太网MTU的以太网帧,则这可能很有用,如果使用巨型帧,则使它们无法处理千兆以太网捕获)。
如果该-T标志用于指定封装类型,则输出捕获文件的封装类型将强制为指定类型,而不是适合输入捕获文件的封装类型的类型。请注意,这只会强制输出文件的封装类型为指定类型; 数据包的数据包标头不会从输入捕获文件的封装类型转换为指定的封装类型(例如,如果读取并-T fddi指定了以太网捕获,它将不会将以太网捕获转换为FDDI捕获)。
有关详细信息,mergecap请参阅本地手册页(man mergecap)或在线版本。
Mergecap(Wireshark)3.1.0(v3.1.0rc0-36-g18b180c5)将 两个或多个捕获文件合并为一个。 有关更多信息,请访问https://www.wireshark.org。 用法:mergecap [options] -w <outfile> | - <infile> [<infile> ...] 输出: -a concatenate而不是merge文件。 default是基于帧时间戳合并。 -s <snaplen>将数据包截断为<snaplen>数据字节。 -w <outfile> | - 为stdout设置输出文件名为<outfile>或' - '。 -F <capture type>设置输出文件类型; 默认是pcapng。 空的“-F”选项将列出文件类型。 -I <IDB merge mode>设置接口描述块的合并模式; 默认为'全部'。 空的“-I”选项将列出合并模式。 其他: -h显示此帮助并退出。 -v详细输出。
合并dhcp-capture.pcapng和imap-1.pcapng进入的 简单示例outfile.pcapng如下所示。
$ mergecap -w outfile.pcapng dhcp-capture.pcapng imap-1.pcapng
在某些情况下,您希望将某些网络流量的十六进制转储转换为libpcap文件。
text2pcap是一个读取ASCII十六进制转储并将描述的数据写入pcap或pcapng捕获文件的程序。text2pcap可以读取包含多个数据包的hexdumps,并构建多个数据包的捕获文件。 text2pcap还能够生成虚拟以太网,IP,UDP,TCP或SCTP报头,以便仅从应用级数据的hexdump构建完全可处理的数据包转储。
text2pcap理解由生成的形式的hexdump od -A x -t x1。换句话说,每个字节被单独显示并用空格包围。每行以描述数据包中位置的偏移量开始,每个新数据包以0的偏移量开始,并且存在将偏移量与后续字节分开的空间。偏移量是十六进制数(也可以是八进制 - 参见-o),超过两个十六进制数字。这是一个text2pcap可以识别的示例转储:
000000 00 e0 1e a7 05 6f 00 10 ........
000008 5a a0 b9 12 08 00 46 00 ........
000010 03 68 00 00 00 00 0a 2e ....... 。
000018 EE EE 33 0F 19 08 0F 19 7F ........
000020 03 80 94 04 00 00 10 01 ........
000 028 16 00 03 A2 50 0A 00 0C ...... ..
000030 01 01 0f 19 03 80 11 01 ........
每行的宽度或字节数没有限制。此外,行末尾的文本转储也会被忽略。字节/十六进制数可以是大写或小写。忽略偏移之前的任何文本,包括电子邮件转发字符“>”。字节串行之间的任何文本行都将被忽略。偏移量用于跟踪字节,因此偏移量必须正确。任何只有字节而没有前导偏移的行都将被忽略。偏移被识别为长于两个字符的十六进制数。忽略字节后的任何文本(例如字符转储)。此文本中的任何十六进制数也会被忽略。偏移量为零表示启动新数据包,因此具有一系列hexdumps的单个文本文件可以转换为具有多个数据包的数据包捕获。数据包前面可能有时间戳。这些是根据命令行上给出的格式解释的。如果不是,则第一个数据包带有时间戳,表示转换发生的当前时间。写入多个数据包的时间戳各不相差1微秒。一般来说,没有这些限制,text2pcap 对于使用hexdumps进行读取是非常自由的,并且已经过各种错位输出的测试(包括通过电子邮件多次转发,有限的换行等)
还有一些其他特殊功能需要注意。第一个非空白字符为“#”的任何行都将被忽略为注释。以#TEXT2PCAP开头的任何行都是一个指令,可以在此命令之后插入选项以进行处理text2pcap。目前没有实施指令; 在将来,这些可用于对转储及其处理方式进行更细粒度的控制,例如时间戳,封装类型等。
text2pcap还允许用户通过在每个数据包之前插入虚拟L2,L3和L4标头来读取应用级数据的转储。可能性包括在每个数据包之前插入诸如以太网,以太网+ IP,以太网+ IP + UDP或TCP或SCTP之类的报头。这允许Wireshark或任何其他全包解码器处理这些转储。
有关详细信息,text2pcap请参阅本地手册页(man text2pcap)或在线版本。
Text2pcap(Wireshark)3.1.0(v3.1.0rc0-36-g18b180c5) 从数据包的ASCII hexdump生成捕获文件。 有关更多信息,请访问https://www.wireshark.org。 用法:text2pcap [options] <infile> <outfile> 其中<infile>指定输入文件名(使用 - 用于标准输入) <outfile>指定输出文件名(使用 - 用于标准输出) 输入: -o hex | oct | dec解析偏移量as(h)ex,(o)ctal或(d)ecimal; 默认为十六进制。 -t <timefmt>将数据包之前的文本视为日期/时间代码; 指定的参数是 strptime支持的排序格式字符串。 示例:时间“10:15:14.5476”的格式代码为 “%H:%M:%S”。 注意:必须 给出亚秒组件分隔符'。' ,但不需要模式; 剩下的 数字假定为几分之一秒。 注意:当前日期/时间的日期/时间字段 用作未指定字段的默认值。 -D数据包以I或O开头之前的文本, 表示数据包是入站或出站的。 这在生成虚拟标头时使用。 仅在输出格式为pcapng时才存储该指示。 -a启用ASCII文本转储标识。 可以识别ASCII文本转储的开始 并从分组数据中排除,即使它看起来 像HEX转储。 注意:如果输入文件不 包含ASCII文本转储,请不要启用它。 输出: -l <typenum>链路层类型号; 默认值为1(以太网)。有关 数字 列表,请访问http://www.tcpdump.org/linktypes.html 。如果您的转储是完整的,请使用此选项 封装数据包的十六进制转储,并且您希望 指定确切的封装类型。 示例:-11用于ARCNet数据包。 -m <max-packet>输出中的最大包长度; 默认值为262144 -n使用pcapng而不是pcap作为输出格式。 -N <intf-name>为pcapng文件中的接口指定名称。 前置虚头: -e <l3pid>预先添加具有指定L3PID的虚拟以太网II头(在HEX中)。 示例:-e 0x806指定ARP数据包。 -i <proto>预先添加具有指定IP协议的虚拟IP头 (在DECIMAL中)。 自动预装以太网头。 示例:-i 46 -4 <srcip>,<destip>预先添加具有指定 dest和源地址的虚拟IPv4标头。 示例:-4 10.0.0.1,10.0.0.2 -6 <srcip>,<destip>预先添加具有指定 dest和源地址的伪IPv6标头。 示例:-6 fe80 :: 202:b3ff:fe1e:8329,2001:0db8:85a3 :: 8a2e:0370:7334 -u <srcp>,<destp>预先添加具有指定 源和目标端口的虚拟UDP头(在DECIMAL中) 。 自动预装以太网和IP头。 示例:-u 1000,69使数据包看起来像 TFTP / UDP数据包。 -T <srcp>,<destp>预先添加具有指定 源和目标端口的虚拟TCP头(在DECIMAL中)。 自动预装以太网和IP头。 示例:-T 50,60 -s <srcp>,<dstp>,<tag>预先添加具有指定 源/目标端口和验证标记的虚拟SCTP标头(在DECIMAL中)。 自动预装以太网和IP头。 示例:-s 30,40,34 -S <srcp>,<dstp>,<ppi>预先添加具有指定 源/目标端口和验证标记0 的虚拟SCTP 标头。自动为具有有效负载协议标识符ppi 的虚拟SCTP DATA 组块标头添加前缀。 示例:-S 30,40,34 其他: -h显示此帮助并退出。 -d显示解析器状态的详细调试。 -q根本不生成输出(自动禁用-d)。
reordercap允许您根据数据包时间戳重新排序捕获文件。有关详细信息,reordercap请参阅本地手册页(man reordercap)或 在线版本。
Reordercap(Wireshark)3.1.0(v3.1.0rc0-36-g18b180c5) 将输入文件帧的时间戳重新排序为输出文件。 有关更多信息,请访问https://www.wireshark.org。 用法:reordercap [options] <infile> <outfile> 选项: 如果输入文件是有序的,则-n不写入输出文件。 -h显示此帮助并退出。
与Wireshark分发的原始许可证和文档一样,本文档受GNU通用公共许可证(GNU GPL)的保护。
如果您之前没有阅读过GPL,请这样做。它解释了您可以使用此代码和文档执行的所有操作。
GNU GENERAL PUBLIC LICENSE Version 2,1991年6月 版权所有(C)1989,1991 Free Software Foundation, Inc。51 Franklin Street,Fifth Floor,Boston,MA 02110-1301 USA 允许每个人复制和分发 本许可证文件的逐字副本,但不允许改变它。 序言
大多数软件的许可证旨在剥夺您共享和更改软件的自由。相比之下,GNU通用公共许可证旨在保证您共享和更改自由软件的自由- 确保该软件对所有用户免费。此通用公共许可证适用于大多数自由软件Foundation的软件以及作者承诺使用它的任何其他程序。(其他一些自由软件基金会软件也包含在GNU库通用公共许可证中。)您也可以将它应用到您的程序中。
当我们谈到自由软件时,我们指的是自由,而不是价格。我们的通用公共许可证旨在确保您可以自由分发免费软件的副本(如果您愿意,可以收取此服务的费用),您可以获得源代码,或者如果您需要可以获得它,您可以更改软件或在新的免费程序中使用它的一部分; 并且你知道你可以做这些事情。
为了保护您的权利,我们需要制定禁止的限制任何人否认你这些权利或要求你放弃这些权利。如果您分发软件的副本,或者您修改了软件的副本,这些限制将转化为您的某些责任。
例如,如果您分发此类程序的副本(无论是免费还是收费),您必须向收件人分配您拥有的所有权利。您必须确保它们也接收或可以获取源代码。你必须向他们展示这些条款,以便他们了解自己的权利。
我们通过两个步骤保护您的权利:(1)对软件进行版权保护,以及(2)向您提供此许可,授予您复制,分发和/或修改软件的法律许可。
此外,对于每位作者的保护和我们的保护,我们希望确保每个人都明白这个免费软件没有保修。如果该软件被其他人修改并传递,我们希望其收件人知道他们所拥有的不是原件,因此其他人引入的任何问题都不会反映原作者的声誉。
最后,任何免费程序都会受到软件专利的威胁。我们希望避免自由程序的再分发者单独获得专利许可的危险,实际上使程序成为专有的。为了防止这种情况,我们已经明确表示专利必须获得许可,以供所有人免费使用或根本不获许可。
下面是复制,分发和修改的准确条款和条件。
GNU通用公共许可证有关
复制,分发和修改的条款和条件
0.本许可证适用于任何包含版权所有者声明可能根据本通用公共许可证条款分发的通知的程序或其他作品。以下“计划” 是指任何此类计划或工作,“基于计划的工作” 是指本程序或版权法下的任何衍生作品:即包含本程序或部分的作品。它,逐字或修改和/或翻译成另一种语言。(在下文中,翻译包括但不限于术语“修改”。)每个被许可人被称为“你”。
本许可不包括复制,分发和修改以外的活动; 它们超出了它的范围。运行本程序的行为不受限制,只有当本程序的内容构成基于本程序的作品(独立于运行本程序时)时,才涵盖本程序的输出。这是否真实取决于该计划的作用。
1.您可以复制和分发本程序的逐字副本您在任何介质中收到的源代码,只要您在每个副本上明显且适当地发布适当的版权声明和免责声明; 保留所有涉及本许可证的通知并保证不存在任何保证; 并向本程序的任何其他收件人提供本许可证的副本以及本程序。
您可以就转让副本的实际行为收取费用,您可以根据自己的选择提供保修保护以换取费用。
2.您可以修改本程序或其任何部分的副本,从而形成基于本程序的作品,并根据第1节的条款复制和分发此类修改或工作如果您还满足以下所有条件:
a)您必须使修改后的文件带有明显的通知, 说明您更改了文件和更改日期。
b)您必须使您分发或发布的全部或部分工作全部或部分包含或源自本程序或其任何部分,根据本许可条款向所有第三方免费许可。
c)如果修改后的程序在运行时通常以交互方式读取命令,则必须使其在以最常用的方式开始运行以进行交互式使用时,打印或显示包含适当版权声明和请注意,没有保修(或者说,您提供保修),并且用户可以在这些条件下重新分发程序,并告诉用户如何查看本许可证的副本。(例外:如果程序本身是交互式的,但通常不会打印此类声明,则基于本程序的工作不需要打印公告。)
这些要求适用于整个修改过的工作。如果该工作的可识别部分不是来自本程序,并且可以合理地认为是独立的和单独的工作本身,那么本许可及其条款不适用于那些将它们作为单独的作品分发时的部分。但是,如果您将相同的部分作为整体的一部分进行分发,这是基于本程序的作品,则整体的分发必须符合本许可证的条款,其对其他被许可人的权限扩展到整个整体,因此对于每个而且无论是谁写的,都是每个部分。
因此,本部分的目的不是主张权利或反对您完全由您撰写的工作权利; 相反,其目的是行使控制基于该计划的衍生作品或集体作品的分配权。
此外,仅仅汇集不是基于该计划的其他工作在存储或分发介质的卷上使用本程序(或基于本程序的工作)不会将其他工作带到本许可证的范围内。
3.您可以根据上述第1节和第2节的条款,以目标代码或可执行形式复制和分发本程序(或根据第2节进行的工作),前提是您还要执行以下操作之一:
a)随附具有完整的相应机器可读 源代码,必须在通常用于软件交换的介质上根据上述第1 节和第2 节的条款分发; 或者,
b)附上书面要约,有效期至少三个年,给任何第三方,收取的费用不超过实际执行源代码分发的费用,相应源代码的完整机器可读副本,将根据上述第1节和第2节的条款在媒体上按惯例分发用于软件交换; 或者,
c)随附您收到的有关分发相应源代码的要约的信息。(此替代方案仅允许非商业性分发,并且只有在您收到具有此类要约的目标代码或可执行形式的程序时,才符合上述第b小节。)工作
的源代码表示工作的首选形式。对它进行修改。对于可执行工作,完整源代码表示其包含的所有模块的所有源代码,以及任何关联的接口定义文件,以及用于控制可执行文件的编译和安装的脚本。但是,作为一个特殊的例外,分发的源代码不需要包含正常分布的任何内容(源代码或二进制形式),以及运行可执行文件的操作系统的主要组件(编译器,内核等),除非该组件本身伴随可执行文件。
如果通过提供
从指定位置访问副本来分发可执行文件或目标代码,则提供等效代码
从同一个地方复制源代码的访问权限与源代码的
分发一样,即使第三方没有被
强制将源代码与目标代码一起复制。
4. 除非本许可证明确规定,否则您不得复制,修改,再许可或分发本程序。任何以其他方式复制,修改,再许可或分发本程序的行为均属无效,并将自动终止您在本许可下的权利。但是,根据本许可证收到您的副本或权利的各方,只要此类方仍然完全合规,其许可将不会被终止。
5.您不需要接受本许可证,因为您没有签了。但是,您无权修改或分发本程序或其衍生作品。如果您不接受本许可,则法律禁止这些行为。因此,通过修改或分发本程序(或基于本程序的任何工作),即表示您接受本许可,以及复制,分发或修改本程序或基于本程序的所有条款和条件。
6.每次重新分发本程序(或基于本程序的任何作品)时,收件人都会自动从原始许可人处获得许可,以根据这些条款和条件复制,分发或修改本程序。你可能不会再强加任何东西了限制接受者行使此处授予的权利。您不负责强制执行本许可证的第三方。
7.如果由于法院对专利侵权的判决或指控或任何其他原因(不限于专利问题),对您施加的条件(无论是通过法院命令,协议还是其他方式)与此条件相抵触许可证,他们不会原谅您不受本许可证条款的约束。如果您不能分发以便同时满足您在本许可下的义务和任何其他相关义务,那么您可能根本不会分发本程序。例如,如果是专利许可证不允许所有直接或间接通过您收到副本的人免费重新分发本程序,那么您唯一能够同时满足本许可证的方法就是完全避免分发本程序。
如果在任何特定情况下本节的任何部分被视为无效或不可执行,则该部分的余额旨在适用,并且该部分作为一个整体旨在适用于其他情况。
本部分的目的不是诱使您侵犯任何专利或其他财产权利要求或者质疑任何此类权利要求的有效性; 本节的唯一目的是保护自由软件分发系统的完整性,由公共许可实践实施。许多人依靠该系统的一致应用,对通过该系统分发的各种软件做出了慷慨的贡献; 由作者/捐赠者决定他或她是否愿意通过任何其他系统分发软件,并且被许可人不能强加该选择。本节旨在彻底清楚本许可证其余部分的后果。
8.如果在某些国家/地区通过专利或受版权保护的接口限制和/或使用本程序,则根据本许可证放置本程序的原始版权所有者可以添加明确的地理分布限制,不包括这些国家,因此仅允许在未被排除在外的国家/地区之间进行分发。在这种情况下,本许可证包含该限制,如同在本许可证正文中一样。
9.自由软件基金会可能会不时发布通用公共许可证的修订版和/或新版本。这些新版本在精神上与现有版本类似,但可能在细节上有所不同以解决新问题或疑虑。每一个版本都有不同的版本号。如果是该计划指定适用于此许可证的版本号和“任何更新版本”,您可以选择遵循该版本或自由软件基金会发布的任何更新版本的条款和条件。如果本程序未指定本许可证的版本号,您可以选择自由软件基金会发布的任何版本。
10.如果您希望将本程序的某些部分合并到其他分发条件不同的免费程序中,请写信给作者以征求许可。对于受自由软件基金会版权保护的软件,请写信给自由软件基金会; 我们有时为此做例外。我们的决定将遵循两个目标,即保护我们自由软件的所有衍生产品的自由状态,以及促进软件的共享和重用。
无担保
11.由于程序是免费许可的,因此在适用法律允许的范围内,对程序不作任何担保。除非另有说明,否则版权所有者和/或其他各方应“按原样”提供本程序,不附带任何明示或暗示的保证,包括但不限于对适销性和特定用途适用性的暗示保证。全部风险该计划的质量和性能与您同在。如果程序有缺陷,您应承担所有必要的维修,修理或更正的费用。
12.在任何情况下,除非适用法律或同意书面同意,否则任何版权所有者,或任何其他方可以修改和/或重新分配上述许可的程序,对您的损害,包括任何一般,特殊,由于使用或无法使用该程序而导致的偶然或间接损害(包括但不限于丢失数据或数据是由您或第三方承担的不当行为或损失,或者程序未能与任何其他人一起运行计划),即使此类持有人或其他方已被告知此类损害的可能性。
条款和条件的终止
如何将这些条款应用于您的新程序
如果您开发了一个新程序,并希望它对公众有最大的用途,那么实现这一目标的最佳方法是使其成为所有人的免费软件可以根据这些条款重新分配和更改。
为此,请将以下注意事项附加到程序中。最安全的是将它们附加到每个源文件的开头,以最有效地传达保修的排除; 并且每个文件至少应具有“copyright”行和指向完整通知所在位置的指针。
<一行给出程序的名称及其作用的简要概念。>
版权所有(C)<年份> <作者姓名>
该程序是免费软件; 您可以根据自由软件基金会发布的GNU通用公共许可证的条款重新分发和/或修改它; 许可证的第2版,或(根据您的选择)任何更高版本。
本程序的发布是希望它有用,但没有任何担保; 甚至没有适销性或特定用途适用性的暗示保证。有关更多详细信息,请参阅GNU通用公共许可证。
您应该已收到GNU通用公共许可证的副本以及这个计划; 如果没有,请写信给Free Software Foundation,Inc.,51 Franklin Street,Fifth Floor,Boston,MA 02110-1301 USA
还添加有关如何通过电子邮件和纸质邮件与您联系的信息。
如果程序是交互式的,当它以交互模式启动时,让它输出如下的简短通知:
Gnomovision版本69,版权所有(C)年份作者
Gnomovision的名称绝对没有保证; 有关详细信息,请输入`show w'。
这是免费软件,欢迎您在特定条件下重新发布; 输入`show c'了解详情。
假设命令“show w”和“show c”应该显示适当的命令通用公共许可证的一部分。当然,你使用的命令可能被称为“show w”和“show c”之外的其他命令; 它们甚至可以是鼠标点击或菜单项 - 适合您的程序。如果有必要,
您还应该让您的雇主(如果您是程序员)或您的学校(如果有的话)为该计划签署“版权免责声明” 。这是一个样本; 更改名称:
Yoyodyne,Inc。,特此声明对
James Hacker编写的“Gnomovision” 程序(由编辑器进行传递)不承认任何版权利益。
<Ty Coon的签名>,1989年4月1日
Ty Coon,副总裁
本通用公共许可证不允许将您的程序纳入专有程序。如果您的程序是子程序库,您可能会认为允许将专有应用程序与库链接更有用。如果这是您要执行的操作,请使用GNU库通用公共许可证而不是此许可证。
本文使用google翻译,未修正!
具体请参照 原文: https://www.wireshark.org/docs/wsug_html/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号