

SpringCloud与Dubbo的区别(七)
前言
SpringCloud:Spring公司开源的微服务框架,SpringCloud 定位为微服务架构下的一站式解决方案。
Dubbo:阿里巴巴开源的RPC框架,Dubbo 是 SOA 时代的产物,它的关注点主要在于服务的调用,流量分发、流量监控和熔断。
SpringCloud生态丰富,功能完善,更像是品牌机,Dubbo则相对灵活,可定制性强,更像是组装机。
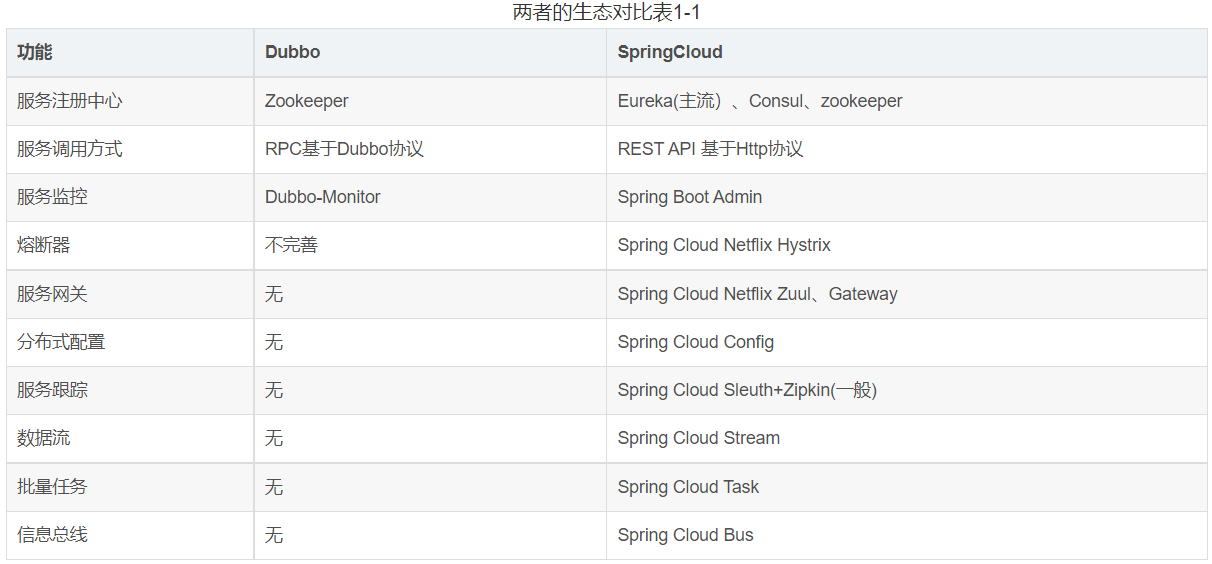
一、SpringCloud与Dubbo的区别
1.1主要区别
- 初始定位不同:SpringCloud定位为微服务架构下的一站式解决方案;Dubbo是SOA 时代的产物,它的关注点主要在于服务的调用和治理;
- 生态环境不同:SpringCloud依托于Spring平台,具备更加完善的生态体系;而Dubbo一开始只是做RPC远程调用,生态相对匮乏,现在逐渐丰富起来;
- 调用方式:SpringCloud是采用Http协议做远程调用,接口一般是Rest风格,比较灵活;Dubbo是采用Dubbo协议,接口一般是Java的Service接口,格式固定。但调用时采用Netty的NIO方式,性能较好;
- 组件差异比较多,例如SpringCloud注册中心一般用Eureka,而Dubbo用的是Zookeeper。
Spring Cloud 的功能很明显比 Dubbo 更加强大,涵盖面更广,而且作为 Spring 的旗舰项目,它也能够与 Spring Framework、Spring Boot、Spring Data、Spring Batch 等其他 Spring 项目完美融合,这些对于微服务而言是至关重要的。
使用 Dubbo 构建的微服务架构就像组装电脑,各环节选择自由度很高,但是最终结果很有可能因为一条内存质量不行就点不亮了,总是让人不怎么放心,但是如果使用者是一名高手,那这些都不是问题。
而 Spring Cloud 就像品牌机,在 Spring Source 的整合下,做了大量的兼容性测试,保证了机器拥有更高的稳定性,但是如果要在使用非原装组件外的东西,就需要对其基础原理有足够的了解。
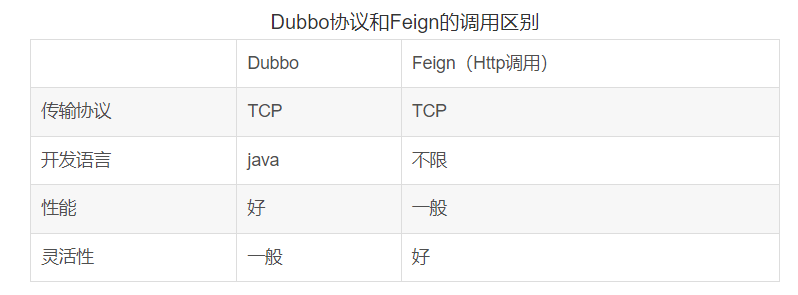
二、dubbo和Feign远程调用的差异
Feign是SpringCloud中的远程调用方式,基于成熟Http协议,所有接口都采用Rest风格。因此接口规范更统一,而且只要符合规范,实现接口的微服务可以采用任意语言或技术开发。但受限于http协议本身的特点,请求和响应格式臃肿,其通信效率相对会差一些。
Dubbo框架默认采用Dubbo自定义通信协议,与Http协议一样底层都是TCP通信。但是Dubbo协议自定义了Java数据序列化和反序列化方式、数据传输格式,因此Dubbo在数据传输性能上会比Http协议要好一些。
不过这种性能差异除非是达极高的并发量级,否则无需过多考虑。
相关资料:Dubbo采用自定义的Dubbo协议实现远程通信,是一种典型的RPC调用方案,而SpringCloud中使用的Feign是基于Rest风格的调用方式。
1)Rest风格
REST是一种架构风格,指的是一组架构约束条件和原则。满足这些约束条件和原则的应用程序或设计就是 RESTful。
Rest的风格可以完全通过HTTP协议实现,使用 HTTP 协议处理数据通信。REST架构对资源的操作包括获取、创建、修改和删除资源的操作正好对应HTTP协议提供的GET、POST、PUT和DELETE方法。
因此请求和想要过程只要遵循http协议即可,更加灵活。
SpringCloud中的Feign就是Rest风格的调用方式。
2)RPC
Remote Procedure Call,远程过程调用,就是像调用本地方法一样调用远程方法。RPC一般要确定下面几件事情:
- 数据传输方式:多数RPC框架选择TCP作为传输协议,性能比较好。
- 数据传输内容:请求方需要告知需要调用的函数的名称、参数、等信息。
- 序列化方式:客户端和服务端交互时将参数或结果转化为字节流在网络中传输,那么数据转化为字节流的或者将字节流转换成能读取的固定格式时就需要进行序列化和反序列化。
因为有序列化和反序列化的需求,因此对数据传输格式有严格要求,不如Http灵活。
Dubbo协议就是RPC的典型代表。
三、Eureka和Zookeeper注册中心的区别
SpringCloud和Dubbo都支持多种注册中心,不过目前主流来看SpringCloud用Eureka较多,Dubbo则以Zookeeper为主。
3.1先了解一下CAP理论
1998年的加州大学的计算机科学家 Eric Brewer 提出,分布式有三个指标。Consistency,Availability,Partition tolerance。简称即为CAP。Eric 提出 CAP 不能全部达到,这就是CAP定理。

C:Consistency,一致性
一致性就是说,我们读写数据必须是一摸一样的。比如一条数据,分别存在两个服务器中,server1和server2。
我们此时将数据a通过server1修改为数据b。此时如果我们访问server1访问的应该是b。当我们访问server2的时候,如果返回的还是未修改的a,那么则不符合一致性,如果返回的是b,则符合数据的一致性。
A:Availability,可用性
这个比较好理解,就是说,只要我对服务器,发送请求,服务器必须对我进行相应,保证服务器一直是可用的。
P:Partition tolerance,分区容错
一般来说,分布式系统是分布在多个位置的。比如我们的一台服务器在北京,一台在上海。可能由于天气等原因的影响。造成了两条服务器直接不能互相通信,数据不能进行同步。这就是分区容错。我们认为,
分区容错是不可避免的。也就是说 P 是必然存在的。
3.2为什么CAP只能达到 CP 或者 AP?
由以上我们得知,P是必然存在的。
如果我们保证了CP,即一致性与分布容错。当我们通过一个服务器修改数据后,该服务器会向另一个服务器发送请求,将数据进行同步,但此时,该数据应处于锁定状态,不可再次修改,这样,如果此时我们想服务器发送请求,则得不到相应,这样就不能A,高可用。
如果我们保证了AP,那么我们不能对服务器进行锁定,任何时候都要得到相应,那么数据的一致性就不好说了。
3.3两者存在较大的差异:
从集群设计来看:
Eureka集群各节点平等,没有主从关系,因此可能出现数据不一致情况;eureka集群中的各个节点是平等的地位,peer to peer对等通信。这是一种去中心化的架构,在这种架构风格中,节点通过彼此互相注册来
提高可用性,每个节点都可被视为其他节点的副本。
Zookeeper(CS结构)为了满足一致性,必须包含主从关系,一主(leader)多从(follower)。集群无主时,不对外提供服务,重新选择leader,这个选择的等待过程服务是不可用的(等待时间可能是30s,60s)
CAP原则来看:
Eureka满足AP原则,为了保证整个服务可用性,牺牲了集群数据的一致性;而Zookeeper满足CP原则,为了保证各节点数据一致性,牺牲了整个服务的可用性。
服务拉取方式来看:Eureka采用的是服务主动拉取策略,消费者按照固定频率(默认30秒)去Eureka拉取服务并缓存在本地;ZK中的消费者首次启动到ZK订阅自己需要的服务信息,并缓存在本地。然后监听服务列表变
化,以后服务变更ZK会推送给消费者。
3.4zookeeper是如何保证“一致性”呢?
当往zookeeper的leader节点写数据时,leader会对剩下的follower节点进行主从数据同步,它必须得同步超过半数的follower节点才给客户端返回写成功的信号。
所以从这点上它是保证了数据一致性,但是却不是强一致性。
另外一点就是,如果由于网络故障或是其他原因导致leader节点挂了,那么这个时候zookeeper集群就得在剩下那些follower接点中重新进行leader的选举,选出一个新leader来。但是别忘了,选举是需要时间的,哪怕30s到120秒,这一段时间之内,zookeeper集群是不能给外部提供服务的,处于不可用的状态,所以从这个角度来讲它丧失了一定的系统可用性(即CAP中的A)
3.5eureka又是如何保证“可用性”的呢?
Eureka集群中各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。而Eureka的客户端在向某个Eureka注册或时如果发现连接失败,则会自动切换至其它节点,只要有一台Eureka还在,就能保证注册服务可用(保证可用性),只不过查到的信息可能不是最新的(不保证强一致性)。因此, Eureka可以很好的应对因网络故障导致部分节点失去联系的情况,而不会像zookeeper集群那样使整个注册服务瘫痪。
四、Dubbo原理和机制详解
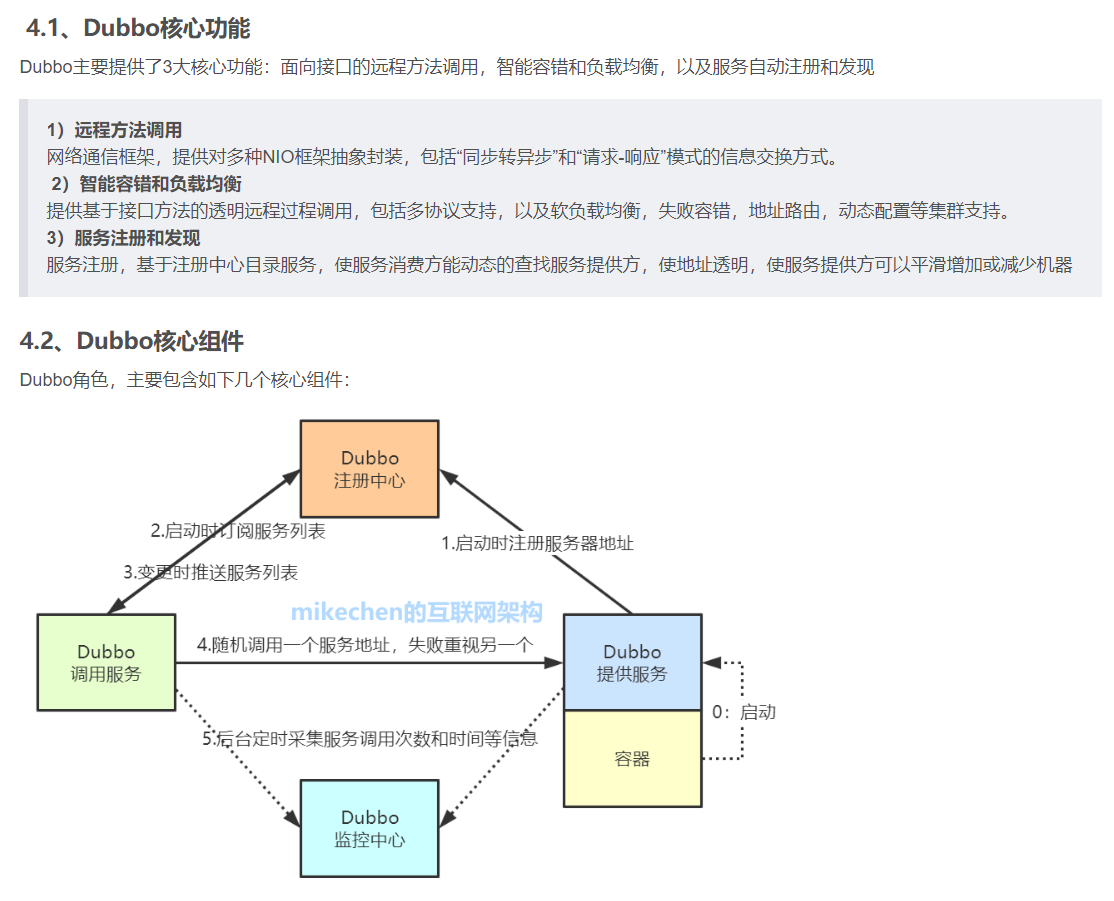


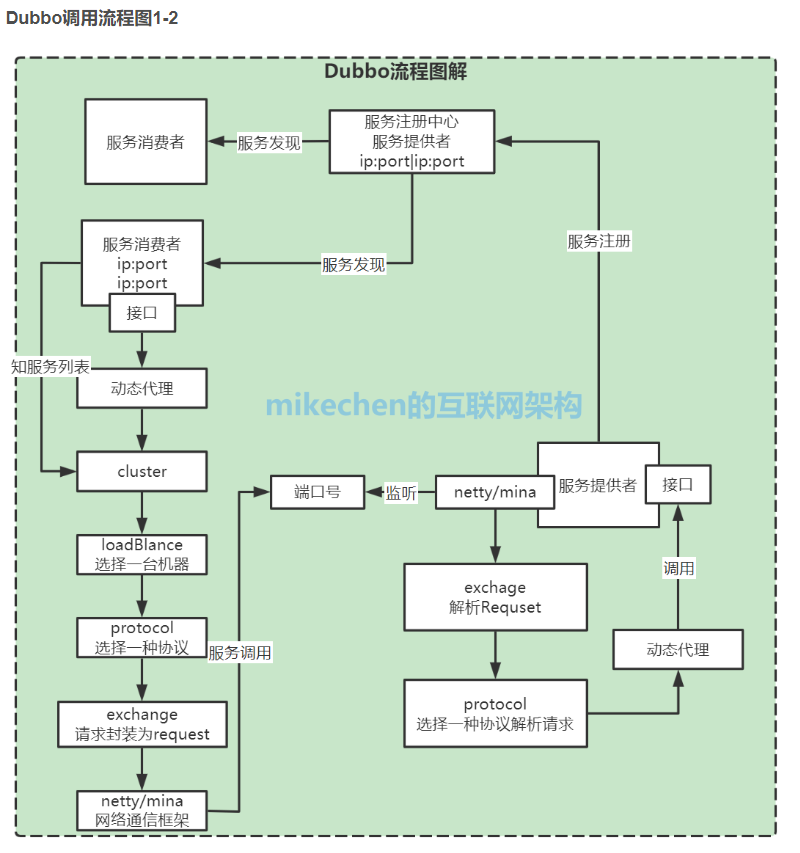
对照上面的整体架构图, Dubbo 原理及机制的详细解析,大致分为以下8大步骤:
1、服务提供者启动,开启Netty服务,创建Zookeeper客户端,向注册中心注册服务;
2、服务消费者启动,通过Zookeeper向注册中心获取服务提供者列表,与服务提供者通过Netty建立长连接;
3、服务消费者通过接口开始远程调用服务,ProxyFactory通过初始化Proxy对象,Proxy通过创建动态代理对象;
4、动态代理对象通过invoke方法,层层包装生成一个Invoker对象,该对象包含了代理对象;
5、Invoker通过路由,负载均衡选择了一个最合适的服务提供者,在通过加入各种过滤器,协议层包装生成一个新的DubboInvoker对象;
6、再通过交换成将DubboInvoker对象包装成一个Reuqest对象,该对象通过序列化通过NettyClient传输到服务提供者的NettyServer端;
7、到了服务提供者这边,再通过反序列化、协议解密等操作生成一个DubboExporter对象,再层层传递处理,会生成一个服务提供端的Invoker对象;
8、这个Invoker对象会调用本地服务,获得结果再通过层层回调返回到服务消费者,服务消费者拿到结果后,再解析获得最终结果。
参看链接:https://blog.csdn.net/huangtenglong/article/details/131144602
在所有的矛盾中,要优先解决主要矛盾,其他矛盾也就迎刃而解。
不要做个笨蛋,为失去的郁郁寡欢,聪明的人,已经找到了解决问题的办法,或正在寻找。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 单元测试从入门到精通