

ES(Elasticsearch学习引导
前言
学习路线:
- 整理博文,记录下知识点,画思维导图。
- 实操,在项目中使用,或自己在本地创建使用demo。
学习纲领:
- 概念:要学的这个是干嘛用的?即应用场景。
- 类比:类比下自己已经会的技能,如本次主要学习的Elasticsearch,可以把它类比到数据库,其实就是用来存储,并快速查询、分析数据的工具。
- 要学习哪些?学习到什么程度?通过上一条的类比,很容易得到:
- 首先得知道安装的大体流程,
- 然后就是学习Elasticsearch的常用语法,
- 最后就是会在kibana界面使用,
- 在项目里编码使用,
- 记录使用过程中用到的问题。
搜索关键词:
- elk
- Elasticsearch
- kibana操作界面
知识点:
- Elasticsearch
- kibana:
-
- 概念
- 安装
- 常用的界面操作
- 使用中的问题记录
- Logstash
- FileBeat
下面只是简单的介绍下这几个插件的概念,具体使用可以看相关链接;关于ELK系列的简单学习可以参看下这个链接的博文:https://www.cnblogs.com/cjsblog/category/1272702.html;更权威的使用可以从官网进行学习。
一、Elk简介
1、简介
ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件。新增了一个FileBeat,它是一个轻量级的日志收集处理工具(Agent),Filebeat占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具。
- Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。主要负责将日志索引并存储起来,方便业务方检索查询。
- Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。是一个日志收集、过滤、转发的中间件,主要负责将各条业务线的各类日志统一收集、过滤后,转发给 Elasticsearch 进行下一步处理。
- Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
- Filebeat隶属于Beats。目前Beats包含四种工具:
-
- Packetbeat(搜集网络流量数据)
- Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
- Filebeat(搜集文件数据)
- Winlogbeat(搜集 Windows 事件日志数据)
2、架构图
1、架构图一:
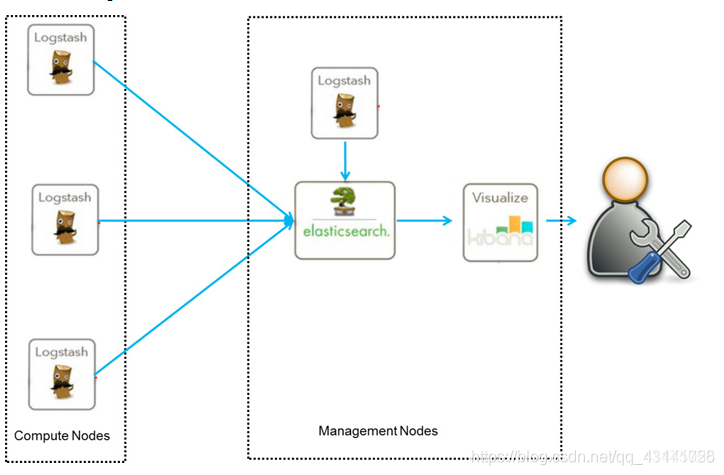
这是最简单的一种ELK架构方式。优点是搭建简单,易于上手。缺点是Logstash耗资源较大,运行占用CPU和内存高。另外没有消息队列缓存,存在数据丢失隐患。
此架构由Logstash分布于各个节点上搜集相关日志、数据,并经过分析、过滤后发送给远端服务器上的Elasticsearch进行存储。Elasticsearch将数据以分片的形式压缩存储并提供多种API供用户查询,操作。用户亦可以更直观的通过配置Kibana Web方便的对日志查询,并根据数据生成报表。
2、架构图二:
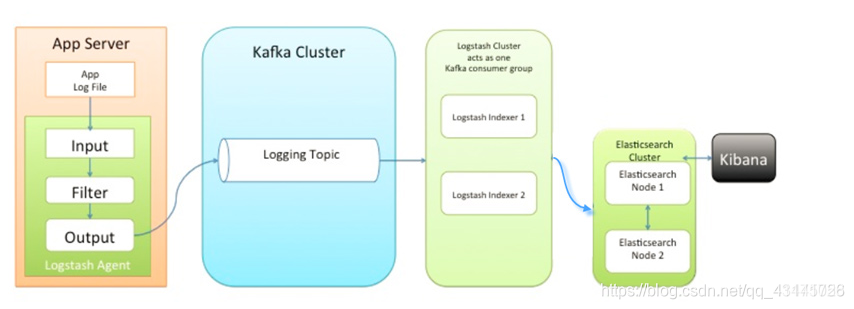
此种架构引入了消息队列机制,位于各个节点上的Logstash Agent先将数据/日志传递给Kafka(或者Redis),并将队列中消息或数据间接传递给Logstash,Logstash过滤、分析后将数据传递给Elasticsearch存储。最后由Kibana将日志和数据呈现给用户。因为引入了Kafka(或者Redis),所以即使远端Logstash server因故障停止运行,数据将会先被存储下来,从而避免数据丢失。
3、架构图三:
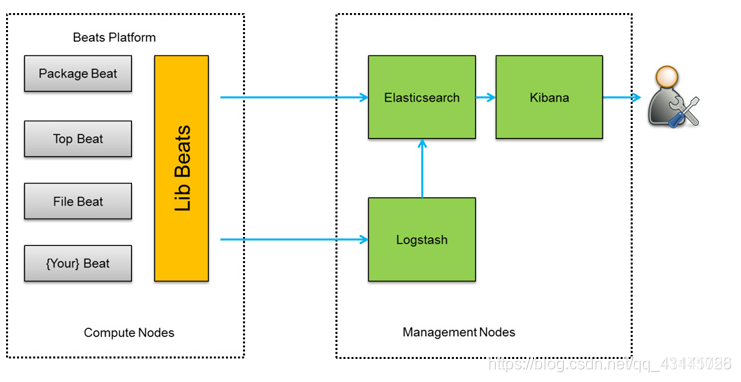
此种架构将收集端logstash替换为beats,更灵活,消耗资源更少,扩展性更强。同时可配置Logstash 和Elasticsearch 集群用于支持大集群系统的运维日志数据监控和查询。
原文链接:https://blog.csdn.net/qq_43141726/article/details/114583115
3、ELK的搭建和使用
参看链接:
- https://blog.csdn.net/weixin_47274990/article/details/116133750
- https://blog.csdn.net/qq_30614345/article/details/132240276
- https://cloud.tencent.com/developer/article/2167267
二、Elasticsearch简介及入门
- 安装部署到使用:ElasticSearch (ES从入门到精通一篇就够了)
- 有道云上有常用操作记录。
1、Elasticsearch简介
- elastic:富有弹性的
- search:搜索
- 不是SpringColud提供的,也不针对微服务的项目开发
- Elasticsearch和Redis/mysql一样,不仅服务于java开发,其他语言也可以使用
- 它的功能类似于数据库,能高效的从大量数据中搜索匹配指定关键字的内容
- 数据保存在硬盘中
2、Es的底层
- 使用了一套名为Lucene的API,这个API提供了全文搜索引擎核心操作的接口,相当于搜索引擎的核心支持,ES是在Lucene的基础上进行完善,实现了开箱即用的搜索引擎。
- 市面上和ES功能类似的软件有:Solr
3、为什么需要使用Elasticsearch?
- 数据库进行模糊查询效率严重低下
- 所有关系型数据库也有这个缺点:mysql\mariaDB\oracle\DB2等
- Elaticsearch主要是为了解决数据库模糊查询性能低下问题
- ES进行优化之后,从同样数据库的ES中查询相同条件数据,效率能够提高100倍以上
ES是一个数据库性质的软件可以执行增删改查操作,只是他操作数据不使用sql,数据的结构和关系型数据库也不同;ES启动后,ES服务可以创建多个index(索引),index可以理解为数据库中表的概念;一个index可以创建多个保存数据的document(文档),一个document理解为数据库中的一行数据。
3.1数据库的索引
所谓的索引(index) 其实就是数据目录,通常情况下,索引是为了提高查询效率的。
3.1.1索引面试题
- 1.创建索引会占用硬盘空间
- 2.创建索引之后,对该表进行增删改操作时,会引起索引的更新,所以效率会降低
- 3.对数据库进行批量新增时,先删除索引,增加完毕之后再创建
- 4.不要对数据样本少的列添加索引
- 5.模糊查询时,查询条件前模糊的情况,是无法启用索引的
- 6.每次从数据表中查询的数据的比例越高,索引的效果越低
3.1.2数据库索引分为两大类:
- 1.聚焦索引
- 2.非聚焦索引
所谓聚焦索引就是数据库保存数据的物理顺序依据,默认情况下就是主键id,所以按照id查询数据库中的数据效率非常高;
而非聚焦索引则是如果在非主键上添加索引就是非索引聚焦了;
而模糊查询时如查询'%XX',使用的就是前模糊条件,而使用索引又必须明确前面的内容是什么,所以前模糊查询是不能使用索引的,只能做全表的查询,但是查询效率低,所以当我们要做根据用户输入关键字进行模糊查询时, 需要使用全文搜索引擎来优化。
4、Elasticsearch运行原理
- 要想使用ES来提高模糊查询效率
- 要先将数据库复制到ES中
- 在新增数据到ES中,ES可以对指定的列进行分词索引保存到索引库中
- 形成倒排索引结构
5、SpringBoot操作Elasticsearch
在原生状态下,我们要使用socket访问ES,但过于繁琐所以采用SpringData框架简化,SpringData是Spring提供的一套连接第三方数据源的框架集,我们需要使用的是其中连接ES的Spring Data Elasticsearch。
首先在pom文件添加依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>cn.tedu</groupId>
<artifactId>csmall</artifactId>
<version>0.0.1-SNAPSHOT</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>cn.tedu</groupId>
<artifactId>search</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>search</name>
<description>Demo project for Spring Boot</description>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- Spring Data Elasticsearch整合SpringBoot的依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
</dependencies>
</project>
添加application.pproperties配置
# 配置ES的ip和端口
spring.elasticsearch.rest.uris=http://localhost:9200
# 设置日志门槛
logging.level.cn.tedu.search=debug
# SpringDataElasticsearch框架内部有一个输出日志信息的类,也要设置门槛
logging.level.org.elasticsearch.client.RestClient=debug
创建和ES关联的实体类,实体类(entity):
@Data
@Accessors(chain = true) // 支持链式set赋值
@AllArgsConstructor // 自动生成包含全部参数的构造方法
@NoArgsConstructor // 自动生成无参数的构造方法
// @Document注解标记当前类是ES框架对应的实体类
// 属性indexName指定ES中对应的索引名称,运行时,如果这个索引不存在,SpringData会自动创建它
@Document(indexName = "items")
public class Item implements Serializable {
// SpringData通过@Id注解来标记当前实体类的主键
@Id
private Long id;
@Field(type = FieldType.Text,
analyzer = "ik_max_word",
searchAnalyzer = "ik_max_word")
private String title;
// FieldType.Keyword类型表示当前字段是不需要分词的字符串
@Field(type = FieldType.Keyword)
private String category;
@Field(type = FieldType.Keyword)
private String brand;
@Field(type = FieldType.Double)
private Double price;
// imgPath是图片路径的属性,不会成为搜索条件,所以这个列可以不创建索引,节省空间
// index = false就是不创建索引的设置
// 所谓不创建索引,只是不为当前字段创建索引列表,但是数据是保存在ES中的
@Field(type = FieldType.Keyword,index = false)
private String imgPath;
创建操作Es的持久层
// Repository是Spring家族框架对持久层出现的类\接口的命名规范
@Repository
public interface ItemRepository extends ElasticsearchRepository<Item,Long> {
// ItemRepository接口继承SpringData框架提供的ElasticsearchRepository父接口
// 继承之后当前接口就能够使用父接口中声明的操作Es的方法了
// 父接口中的方法包含指定实体类对应ES索引的基本增删改查
// ElasticsearchRepository<[要操作的实体类],[实体类的主键类型]>
}
编写测试
@SpringBootTest
class SearchApplicationTests {
@Autowired
private ItemRepository itemRepository;
// 执行单增
@Test
void addOne() {
// 实例化Item对象
Item item=new Item()
.setId(1L)
.setTitle("罗技激光无线游戏鼠标")
.setCategory("鼠标")
.setBrand("罗技")
.setPrice(186.0)
.setImgPath("/1.jpg");
// 利用SpringDataElasticsearch框架提供的新增方法,新增到ES
itemRepository.save(item);
System.out.println("ok");
}
// 单查
@Test
void getOne(){
// SpringDataElasticsearch提供了按id查询ES中数据的方法
// 返回值是一个Optional类型对象,声明了泛型,我们理解为只能保存一个元素的集合
Optional<Item> optional = itemRepository.findById(1L);
// 从这个容器中取出元素
Item item=optional.get();
System.out.println(item);
}
// 批量增
@Test
void addList(){
// 实例化一个List,把要保存到ES中的数据添加这个集合中
List<Item> list=new ArrayList<>();
list.add(new Item(2L,"罗技激光有线办公鼠标","鼠标",
"罗技",78.0,"/2.jpg"));
list.add(new Item(3L,"雷蛇机械无线游戏键盘","键盘",
"雷蛇",268.0,"/3.jpg"));
list.add(new Item(4L,"微软有线静音办公鼠标","鼠标",
"微软",199.0,"/4.jpg"));
list.add(new Item(5L,"罗技机械有线背光键盘","键盘",
"罗技",228.0,"/5.jpg"));
itemRepository.saveAll(list);
System.out.println("ok");
}
// 全查
@Test
void getAll(){
// SpringDataElasticsearch提供的全查所有item的ES中数据的方法
Iterable<Item> items = itemRepository.findAll();
for(Item item : items){
System.out.println(item);
}
System.out.println("----------------------------------------------------");
items.forEach(item -> System.out.println(item));
}
}
参看链接:https://blog.csdn.net/weixin_43792176/article/details/129699693
三、logstash入门
四、kibana入门
- 安装部署及界面操作:kibana入门
五、fileBeat入门
在所有的矛盾中,要优先解决主要矛盾,其他矛盾也就迎刃而解。
不要做个笨蛋,为失去的郁郁寡欢,聪明的人,已经找到了解决问题的办法,或正在寻找。
