

再次回顾理解代理-分布式-集群-微服务概念(十)
前言
一定要结合着例子来理解。不然这次记住概念,理解了,过不了多久还得忘。
一、代理
1、正向代理
正向代理是针对对于服务端来说的,隐藏了客户端信息,服务端不知道真正的客户端是谁。我们通常说的代理,都是指的正向代理。例如,生活中常说的代理商,比如卖白酒的代理商,这里白酒厂家就相当于服务器,代理商,就相当于代理,而我们顾客,就是客户,对于白酒厂商(服务端)来说,他并不知道真正的客户(客户端)是谁,他只是将酒卖给了代理商(代理),那么,我们就可以说,代理商,给白酒厂商做了正向代理。我们在访问外网时也是一样,(用浏览器访问http://www.google.com 时,被残忍的block,于是你可以在国外搭建一台代理服务器,让代理帮我去请求google.com,代理把请求返回的相应结果再返回给我。)还有借呗借钱,这些都是正向代理。
2、反向代理
反向代理是针对于客户端来说的,隐藏了服务端的信息,客户端不知道真正的服务端是谁。例如,大家都有过这样的经历,拨打10086客服电话,可能一个地区的10086客服有几个或者几十个,你永远都不需要关心在电话那头的是哪一个,叫什么,男的,还是女的,漂亮的还是帅气的,你都不关心,你关心的是,你的问题能不能得到专业的解答,你只二要拨通了10086的总机号码,电话那头总会有人会回答你,只是有时慢有时快而已。那么这里的10086总机号码就是我们说的反向代理。客户不知道真正提供服务人的是谁。
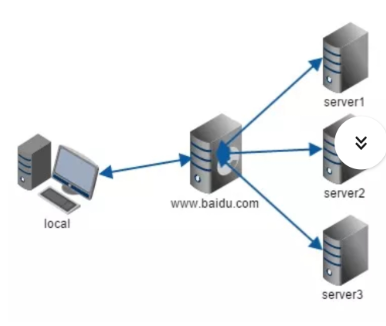
两者的区别在于代理的对象不一样:正向代理代理的对象是客户端;反向代理代理的对象服务端。
以nginx为例,
正向代理,nginx就是为一个服务器地址做代理(服务器是不知道具体的客户端是谁在访问的);
反向代理:nginx代理的是某个服务器,可能有很多的服务器,客户端是不知道现在访问的这个域名最终会指向哪个服器。
参看链接:https://www.cnblogs.com/szrs/p/13439664.html
二、分布式
参看链接:https://www.cnblogs.com/szrs/p/14407198.html
这个可以拿rbz的项目来说,有多个项目,不同项目之间有调用,属于垂直架构。因为相对来说,项目还是太少,没必要用分布式架构(即通过分布式架构如(dubbo-RPC架构))进行管理不同的服务。
拿现实来举例,就是把一件事情,拆分成不同的模块(对应不同的项目,或者说服务,相互之间调用需要通过通信协议,数据跨域调用),一件事情,拆分开,多个人来做。(现实举例:盖房拆分为地基、主体、装修三步,不同的人负责不同的模块)。这样来提高效率。
三、集群
多个人,做的都是同一件事情。(现实举例:多个人,一起来做盖房这一件事情(此时盖房是一个事件)。若跟上面的例子联系起来,其实就是地基这件事,多个人来做,这是一个集群。地基、主体、装修可以分成三个集群)。
比如电商项目,将不同的模块(商品展示、购物车、订单)拆分成不同的服务,然后通过dubbo来管理,这算是分布式架构;如果商品展示模块访问的人比较多,服务器压力比较大,那么就可以多布置几台商品展示模块服务器,这就是集群;然后可以通过nginx来对商品展示模块做反向代理,客户并不知道真正的服务端是谁(如京东),实现负载均衡(访问压力较小的服务器)。
电商项目的分布式架构,如下图:
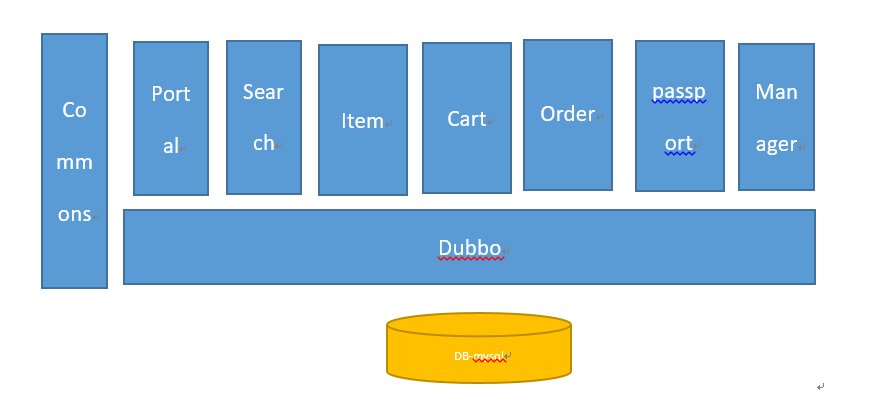
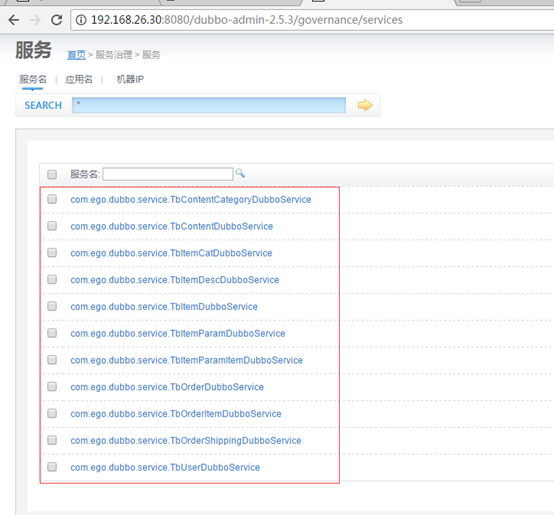
dubbo模块作为服务的提供者,提供一个一个的服务(接口及其实现),所有访问数据库的操作都在这里进行。
其余的模块都是服务消费者,需要什么服务(接口),直接通过@Reference注解来取得服务提供者的方法。
四、集群、分布式、负载均衡区别与联系
4.1、Linux集群主要分成三大类( 高可用集群, 负载均衡集群,科学计算集群)
4.1.1科学群集 、高性能集群(High performance cluster,HPC)
它是利用一个集群中的多台机器共同完成同一件任务,使得完成任务的速度和可靠性都远远高于单机运行的效果。弥补了单机性能上的不足。该集群在天气预报、环境监控等数据量大,计算复杂的环境中应用比较多;通常,这种集群涉及为群集开发并行编程应用程序,以解决复杂的科学问题。它不使用专门的超级并行计算机,而是用商业系统(如通过高速连接来链接的一组单处理器或双处理器PC),并且在公共消息传递层上进行通信以运行并行应用程序。我们常常听说一种便宜的 Linux 超级计算机问世了,大多数情况就是指这种集群系统,其处理能力与真的超级计算机相当,而其价格与上百万美元的专用超级计算机相比是相当的便宜。
4.1.2负载均衡集群(Load balance cluster, LBC)
它是利用一个集群中的多台单机,完成许多并行的小的工作。一般情况下,如果一个应用使用的人多了,那么用户请求的相应时间就会增大,机器的性能也会受到影响,如果使用负载均衡集群,那么集群中任意一台机器都能相应用户的请求,这样集群就会在用户发出服务请求之后,选择当时负载最小,能够提供最好的服务的这台机器来接受请求并相应,这样就可用用集群来增加系统的可用性和稳定性。这类集群在网站中使用较多;负载均衡群集为企业需求提供了更为实用的系统。如其名称,这种系统使负载可以在多台计算机中尽可能平均地分摊处理。负载可以是需要均衡的应用程序处理负载或网络流量负载。在系统中,每个节点都可以处理一部分负载,并且可以在节点之间动态分配负载,以实现平衡。对于网络流量也是如此。
4.1.3高可用性集群(High availability cluster,HAC)
它是利用集群中系统 的冗余,当系统中某台机器发生损坏的时候,其他后备的机器可以迅速的接替它来启动服务,等待故障机的维修和返回。最大限度的保证集群中服务的可用性。这类系统一般在银行,电信服务这类对系统可靠性有高的要求的领域有着广泛的应用。高可用性群集的出现是为了使群集的整体服务尽可能可用。如果高可用性群集中的主节点发生了故障,那么这段时间内将由次节点代替它。次节点通常是主节点的镜像,所以当它代替主节点时,它可以完全接管其身份,对用户没有任何影响。
在群集的这三种基本类型之间,经常会发生交叉、混合。比如:在高可用性的群集系统中也可以在其节点之间实现负载均衡,同时仍然维持着其高可用性。
4.2、负载均衡系统
4.3、分布式与集群
而集群指的是将几台服务器集中在一起,实现同一业务。
分布式中的每一个节点,都可以做集群。
而集群并不一定就是分布式的。
举例:就比如新浪网,访问的人多了,他可以做一个群集,前面放一个响应服务器,后面几台服务器完成同一业务,如果有业务访问的时候,响应服务器看哪台服务器的负载不是很重,就将给哪一台去完成。
而分布式,从窄意上理解,也跟集群差不多, 但是它的组织比较松散,不像集群,有一个组织性,一台服务器垮了,其它的服务器可以顶上来。
分布式的每一个节点,都完成不同的业务,一个节点垮了,哪这个业务就不可访问了。
下面这个粘贴的可以不看:



1 1. 集群(Cluster):是一组独立的计算机系统构成一个松耦合的多处理器系统,它们之间通过网络实现进程间的通信。应用程序可以通过网络共享内存进行消息传送,实现分布式计算机。 2 3 2. 负载均衡(Load Balance):先得从集群讲起,集群就是一组连在一起的计算机,从外部看它是一个系统,各节点可以是不同的操作系统或不同硬件构成的计算机。如一个提 供Web服务的集群,对外界来看是一个大Web服务器。不过集群的节点也可以单独提供服务。 4 5 3. 特点:在现有网络结构之上,负载均衡提供了一种廉价有效的方法扩展服务器带宽和增加吞吐量,加强网络数据处理能力,提高网络的灵活性和可用性。集群系统 (Cluster)主要解决下面几个问题:高可靠性(HA):利用集群管理软件,当主服务器故障时,备份服务器能够自动接管主服务器的工作,并及时切换过 去,以实现对用户的不间断服务。高性能计算(HP):即充分利用集群中的每一台计算机的资源,实现复杂运算的并行处理,通常用于科学计算领域,比如基因分 析,化学分析等。负载平衡:即把负载压力根据某种算法合理分配到集群中的每一台计算机上,以减轻主服务器的压力,降低对主服务器的硬件和软件要求。 6 7 在IDF05(Intel Developer Forum 2005)上,Intel首席执行官Craig Barrett就取消4GHz芯片计划一事,半开玩笑当众单膝下跪致歉,给广大软件开发者一个明显的信号,单纯依靠垂直提升硬件性能来提高系统性能的时代已结束,分布式开发的时代实际上早已悄悄地成为了时代的主流,吵得很热的云计算实际上只是包装在分布式之外的商业概念,很多开发者(包括我)都想加入研究云计算这个潮流,在google上通过“云计算”这个关键词来查询资料,查到的都是些概念性或商业性的宣传资料,其实真正需要深入的还是那个早以被人熟知的概念------分布式。 8 9 分布式可繁也可以简,最简单的分布式就是大家最常用的,在负载均衡服务器后加一堆web服务器,然后在上面搞一个缓存服务器来保存临时状态,后面共享一个数据库,其实很多号称分布式专家的人也就停留于此,大致结构如下图所示: 10 11 12 13 这种环境下真正进行分布式的只是web server而已,并且web server之间没有任何联系,所以结构和实现都非常简单。 14 15 有些情况下,对分布式的需求就没这么简单,在每个环节上都有分布式的需求,比如Load Balance、DB、Cache和文件等等,并且当分布式节点之间有关联时,还得考虑之间的通讯,另外,节点非常多的时候,得有监控和管理来支撑。这样看起来,分布式是一个非常庞大的体系,只不过你可以根据具体需求进行适当地裁剪。按照最完备的分布式体系来看,可以由以下模块组成: 16 17 18 19 分布式任务处理服务:负责具体的业务逻辑处理 20 21 分布式节点注册和查询:负责管理所有分布式节点的命名和物理信息的注册与查询,是节点之间联系的桥梁 22 23 分布式DB:分布式结构化数据存取 24 25 分布式Cache:分布式缓存数据(非持久化)存取 26 27 分布式文件:分布式文件存取 28 29 网络通信:节点之间的网络数据通信 30 31 监控管理:搜集、监控和诊断所有节点运行状态 32 33 分布式编程语言:用于分布式环境下的专有编程语言,比如Elang、Scala 34 35 分布式算法:为解决分布式环境下一些特有问题的算法,比如解决一致性问题的Paxos算法 36 37 因此,若要深入研究云计算和分布式,就得深入研究以上领域,而这些领域每一块的水都很深,都需要很底层的知识和技术来支撑,所以说,对于想提升技术的开发者来说,以分布式来作为切入点是非常好的,可以以此为线索,探索计算机世界的各个角落。 38 39 40 集群是个物理形态,分布式是个工作方式。 41 42 只要是一堆机器,就可以叫集群,他们是不是一起协作着干活,这个谁也不知道;一个程序或系统,只要运行在不同的机器上,就可以叫分布式,嗯,C/S架构也可以叫分布式。 43 44 集群一般是物理集中、统一管理的,而分布式系统则不强调这一点。 45 46 47 所以,集群可能运行着一个或多个分布式系统,也可能根本没有运行分布式系统;分布式系统可能运行在一个集群上,也可能运行在不属于一个集群的多台(2台也算多台)机器上。 48 49 50 布式是相对中心化而来,强调的是任务在多个物理隔离的节点上进行。中心化带来的主要问题是可靠性,若中心节点宕机则整个系统不可用,分布式除了解决部分中心化问题,也倾向于分散负载,但分布式会带来很多的其他问题,最主要的就是一致性。 51 集群就是逻辑上处理同一任务的机器集合,可以属于同一机房,也可分属不同的机房。分布式这个概念可以运行在某个集群里面,某个集群也可作为分布式概念的一个节点。 52 一句话,就是:“分头做事”与“一堆人”的区别 53 54 55 分布式是指将不同的业务分布在不同的地方。 而集群指的是将几台服务器集中在一起,实现同一业务。 56 57 分布式中的每一个节点,都可以做集群。 而集群并不一定就是分布式的。 58 59 举例:就比如新浪网,访问的人多了,他可以做一个群集,前面放一个响应服务器,后面几台服务器完成同一业务,如果有业务访问的时候,响应服务器看哪台服务器的负载不是很重,就将给哪一台去完成。 60 61 而分布式,从窄意上理解,也跟集群差不多, 但是它的组织比较松散,不像集群,有一个组织性,一台服务器垮了,其它的服务器可以顶上来。 62 63 分布式的每一个节点,都完成不同的业务,一个节点垮了,哪这个业务就不可访问了。 64 65 2:简单说,分布式是以缩短单个任务的执行时间来提升效率的,而集群则是通过提高单位时间内执行的任务数来提升效率。 66 67 例如: 68 69 如果一个任务由10个子任务组成,每个子任务单独执行需1小时,则在一台服务器上执行该任务需10小时。 70 71 采用分布式方案,提供10台服务器,每台服务器只负责处理一个子任务,不考虑子任务间的依赖关系,执行完这个任务只需一个小时。(这种工作模式的一个典型代表就是Hadoop的Map/Reduce分布式计算模型) 72 73 而采用集群方案,同样提供10台服务器,每台服务器都能独立处理这个任务。假设有10个任务同时到达,10个服务器将同时工作,1小时后,10个任务同时完成,这样,整身来看,还是1小时内完成一个任务! 74 75 集群一般被分为三种类型,高可用集群如RHCS、LifeKeeper等,负载均衡集群如LVS等、高性能运算集群;分布式应该是高性能运算集群范畴内。 76 77 78 分布式:不同的业务模块部署在不同的服务器上或者同一个业务模块分拆多个子业务,部署在不同的服务器上,解决高并发的问题 79 集群:同一个业务部署在多台机器上,提高系统可用性
参看链接:
https://www.cnblogs.com/szrs/p/13439664.html
https://www.cnblogs.com/szrs/p/14407198.html
https://www.cnblogs.com/panchangde/p/11570395.html
四、微服务
4.1Ribbon客户端实现负载均衡
什么是负载均衡器?
假设有一个分布式系统,该系统由在不同计算机上运行的许多服务组成。但是,当用户数量很大时,通常会为服务创建多个副本。每个副本都在另一台计算机上运行。此时,出现 “Load Balancer(负载均衡器)”。它有助于在服务器之间平均分配传入流量。
服务器端负载均衡器
传统上,Load Balancers(例如Nginx、F5)是放置在服务器端的组件。当请求来自 客户端 时,它们将转到负载均衡器,负载均衡器将为请求指定 服务器。负载均衡器使用的最简单的算法是随机指定。在这种情况下,大多数负载平衡器是用于控制负载平衡的硬件集成软件。
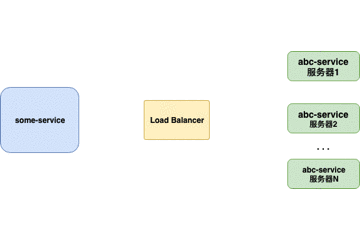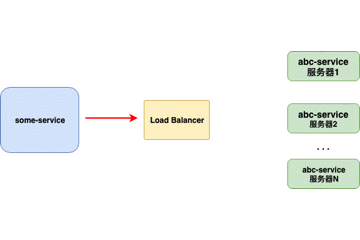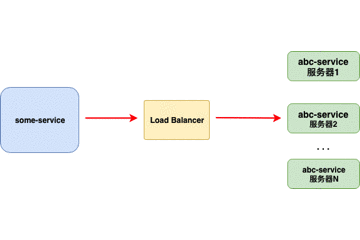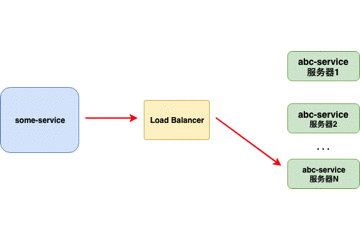
重点:
- 对客户端不透明,客户端不知道服务器端的服务列表,甚至不知道自己发送请求的目标地址存在负载均衡器。
- 服务器端维护负载均衡服务器,控制负载均衡策略和算法。
客户端负载均衡器
当负载均衡器位于 客户端 时,客户端得到可用的服务器列表然后按照特定的负载均衡策略,分发请求到不同的 服务器 。
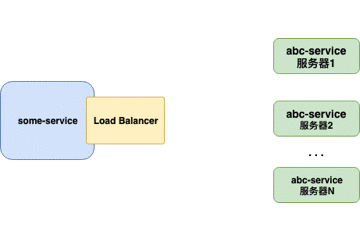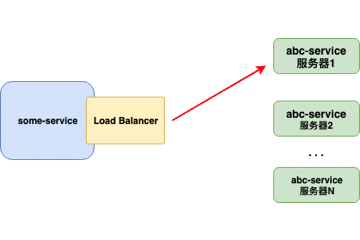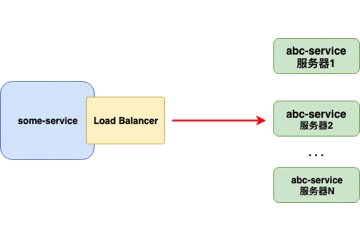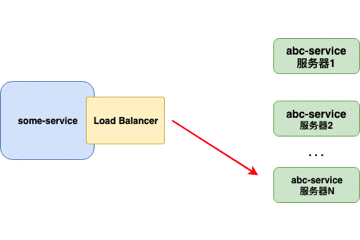
重点:
- 对客户端透明,客户端需要知道服务器端的服务列表,需要自行决定请求要发送的目标地址。
- 客户端维护负载均衡服务器,控制负载均衡策略和算法。
- 目前单独提供的客户端实现比较少( 我用过的只有Ribbon),大部分都是在框架内部自行实现。
Ribbon
简介
Ribbon是Netflix公司开源的一个客户单负载均衡的项目,可以自动与 Eureka 进行交互。它提供下列特性:
- 负载均衡
- 容错
- 以异步和反应式模型执行多协议 (HTTP, TCP, UDP)
- 缓存和批量
Ribbon中的关键组件
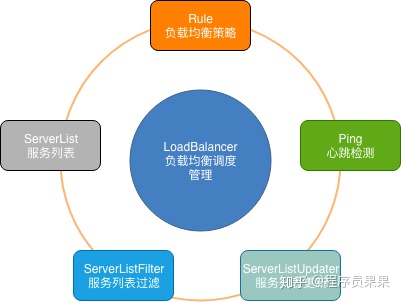
- ServerList:可以响应客户端的特定服务的服务器列表。
- ServerListFilter:可以动态获得的具有所需特征的候选服务器列表的过滤器。
- ServerListUpdater:用于执行动态服务器列表更新。
- Rule:负载均衡策略,用于确定从服务器列表返回哪个服务器。
- Ping:客户端用于快速检查服务器当时是否处于活动状态。
- LoadBalancer:负载均衡器,负责负载均衡调度的管理。
参看链接:https://zhuanlan.zhihu.com/p/66986060
在所有的矛盾中,要优先解决主要矛盾,其他矛盾也就迎刃而解。
不要做个笨蛋,为失去的郁郁寡欢,聪明的人,已经找到了解决问题的办法,或正在寻找。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 单元测试从入门到精通