

贝叶斯统计概要(待修改)
一:频率派,贝叶斯派的哲学
现在考虑一个最最基本的问题,到底什么是概率?当然概率已经是在数学上严格的,良好定义的,这要归功于30年代大数学家A.N.Kolmogrov的概率论公理化。但是数学上的概率和现实世界到底是有怎样的关系?我们在用数学理论--------概率论解决实际问题的时候,又应该用什么样的观点呢?这真差不多是个哲学问题。这个问题其实必须得好好考察一下,下面我们看看最基本的两种哲学观,分别来自频率派和贝叶斯派, 我们这里的“哲学”指的是数学研究中朴素的哲学观念,而不是很严肃的哲学讨论。
1.1.经典的统计(频率派)的哲学:
1)概率指的是频率的极限,概率是真实世界的客观性质(objective property)
2)概率分布的参数都是固定的,通常情况下未知的常数,不存在"参数$\theta$满足XXX的概率是X"这种概念。
3)统计方法应该保证具有良好的极限频率性质,例如95%区间估计应该保证当$N$足够大的时候,我们选取$N$个样本集$S_{1}$, $S_{2}$,...,$S_{N}$所计算出来的相应的区间$I_{1}$,$I_{2}$,...,$I_{N}$中将有至少95%*N个区间包含我们需要估计的统计量的真实值。
我们从上看到,经典频率派的统计是非常具有唯物主义(materialism)色彩的,而贝叶斯的哲学大不一样,据考证贝叶斯是英格兰的一名牧师,他研究数学的目的是为了论证上帝的存在,但是很可惜没有成功。神学背景可能是使他的数学具有主观唯心色彩的一个重要因素,也使得贝叶斯统计从一开始就有一定的争议。
1.2.贝叶斯哲学:
1)概率描述对某件事件发生的信念(Belief),或者称相信度的大小,所以我们可以用“概率”来描述很多实际上不存在的事件,例如"我认为希特勒赢得二战的概率是0.1",虽然希特勒是输了,但是0.1描述的是我对他获胜这件事情的信念大小,它并不是频率的极限,因为我们并不可能坐着时光旅行器穿越回二战一万次去看希特勒赢了几次,再算出他成功的概率,这里的概率再也不是客观性质,而是主观信念。
2)我们可以对概率分布的参数做概率分布假设,即使他们是固定的确定的参数。
3)我们对参数$\theta$作统计推断,不再将$\theta$看作是固定常数,而是具有某个假设分布的随机变量,所有的推断,例如点估计,区间估计,假设检验都是这样进行的。
1.3.三种“概率”:
传统的频率派的某件事件的概率指的是随机试验结果出现的频率的极限,这种概率的定义过于依赖于所谓的随机试验,具有局限性,他完全不考虑客观上"不可能发生"的事件的概率,而贝叶斯派的概率对于客观上“不可能发生”的事件也考虑其概率,这种概率在也与试验无关,而是指的是人主观上对某件事情发生的相信程度。但是这两种概率的观点都过于经验主义,真正将概率论严格化成为一门真正意义上的数学分支的还是Kolmogrov的“概率“,在那里概率只是某种测度,满足若干条公理,而实际应用中我们定义何种概率空间和概率测度完全取决于研究者问题的需要,也就是概率必须是要在一定的框架前提下谈论的事情,这样不仅以上两种基于日常经验的概率全部被包含在新的框架下,而且概率论也不再拘泥于经验认识的范畴,而与广泛的数学其他分支,如数论,动力系统,微分几何,分析等学科发生联系。
二:贝叶斯推断的基本思想
2.1.贝叶斯统计三要素
1)总体信息:总体信息包括概率空间$(\Omega,\mathcal{G},\text{P})$,定义于概率空间上的随机变量$X_{0}$,某种总体分布的信息,比如$X_{0}$满足$\times\times$分布。在贝叶斯统计中一般总体信息包含一个关于概率分布的信息,那就是$X_{0}$服从某指定概率分布族$\mathcal{P}=\lbrace P_{\theta}\rbrace_{\theta\in\Theta}$中的某一个分布,其中$\Theta$为欧式空间中的子集,我们称之为参数空间,并给定一个定义于其Borel集$\sigma$代数$\mathcal{B}_{\Theta}$的固定测度$\nu$(常见有Lebesgue测度或者计数测度),我们设其为$P_{\theta_{0}}$,它是未知的。由于$\theta_{0}$的未知性,其实我们应该另外假定已经有一族固定的随机变量$\mathcal{X}=\lbrace X_{\theta}\rbrace$,其中一个可能是$X_{0}=X_{\theta_{0}}$, 我们希望用某种估计手段估计出一个$\theta$出来,或者换句话说我们有函数:
$$X:\Omega\times\Theta\longrightarrow \mathbb{R}$$
$$X(\omega,\theta)\triangleq X_{\theta}(\omega),$$
现在假定该函数可测,相对于测度$\mathcal{G}\times\mathcal{B}_{\Theta}$与$\mathcal{B}_{\mathbb{R}}$。
在实际应用中,$\Omega$往往是我们需要研究的现实世界中的对象全体,例如$\Omega$可以是“全体中国人“,变量$X_{0}$代表“身高”,而就算$\Omega$是有限集合,$X_{0}$也仍然可以近似服从正态分布,这就是一些总体信息。
2)先验信息:先验信息是贝叶斯统计和频率派统计的最大不同,他指的是一个先验概率分布$p(\theta)$(又称为主观概率),$$\int_{\Theta}p\text{d}\nu=1$$,是对于我们在还不知道模型的参数值的情况下对于其等于$\Theta$上各点的相信程度, 例如$p(\theta)$越大的话表示我们对$\theta_{0}=\theta$这件事的相信程度就越大。先验分布一般是根据历史的统计结果,生活和实践的经验得出的,不是随便乱猜测的。
3)样本信息:实践中往往样本总体过于庞大,我们需要通过随机试验(Random experiment)抽取样本空间中的$N$个元素$\omega_{1},...,\omega_{N}\in\Omega$,再观察随机变量$X_{0}$在其上的取值:$x_{i}\triangleq X_{0}(\omega_{i}),i=1,...,N$,得到的数据$\mathcal{D}=(x_{1},...,x_{N})$,我们称$\mathcal{D}$为一个样本。事实上,在我们不确定参数值的情况下抽样的随机性可以用如下概率模型描述:
首先我们令$(\Theta,\mathcal{B}_{\Theta})$上的测度$\Pi$满足$\frac{\text{d}\Pi}{\text{d}\nu}=p$,我们构造一个新的概率空间$(\Omega^{\prime},\mathcal{G}^{\prime},\text{P}^{\prime})\triangleq (\Omega^{N}\times\Theta,\mathcal{G}^{N}\times\mathcal{B}_{\Theta},\text{P}^{N}\times\Pi)$,其中$\Omega^{N}$为$\Omega$的$N-$重笛卡尔积,相应的$\mathcal{G}^{N},P^{N}$为乘积$\sigma-$代数,测度,我们定义新的随机变量:
$$X_{i}:\Omega^{N}\times\Theta\longrightarrow \mathbb{R}$$
$$X_{i}(\omega_{1},\omega_{2},...,\omega_{N},\theta)\triangleq X(\omega_{i},\theta),$$
对$i=1,...,N$,则很容易验证对于任意的固定参数$\theta\in\Theta, X_{i}(\cdot,\theta),i=1,...,N$为一组概率空间$(\Omega^{N},\mathcal{G}^{N},\text{P}^{N})$的意义下的独立同分布随机变量,其与$X_{\theta}$同分布,而一个样本只不过是随机向量$\text{S}\triangleq (X_{1},...,X_{N})$的值域中的一个点。
2.2.贝叶斯公式
现在我们有定义在$(\Omega^{\prime},\mathcal{G}^{\prime},\text{P}^{\prime})$上的随机向量$\text{S}$,那么$\text{S}=(X_{1},...,X_{N})$与参数$\theta$自然有一个联合分布的密度函数满足:
\begin{equation}P(x_{1},...,x_{N},\theta)=p(\theta)\prod_{i=1}^{N}P_{\theta}(x_{i})\end{equation}
我们规定对任意$(x_{1},...,x_{N})\in\mathbb{R}^{N}$在这篇博文里都用花写字母$\mathcal{D}$表示,代表着某个样本,这时我们简写:
\begin{equation}P(\mathcal{D},\theta)\triangleq P(x_{1},...,x_{N},\theta),\end{equation}
\begin{equation}P(\theta\mid\mathcal{D})=\frac{P(\mathcal{D},\theta)}{P(\mathcal{D})}=\frac{P(\mathcal{D}\mid\theta)p(\theta)}{\int_{\Theta}P(\mathcal{D}\mid\beta)p(\beta)\text{d}\nu(\beta)}\end{equation}
2.3.贝叶斯统计的基本流程
1)选择一个合适的参数$\theta$分布的概率密度$p(\theta)$,我们称之其为先验分布( prior distribution);
2)选择一个概率分布模型$P(x\mid \theta)$;
3)在观测到数据$\mathcal{D}=(x_{1},...,x_{N})$之后,计算$\theta$的后验分布(posterior distribution ):
\begin{equation}P(\theta\mid \mathcal{D})\triangleq\frac{P(\mathcal{D}\mid\theta)p(\theta)}{\int_{\Theta}P(\mathcal{D}\mid\beta)p(\beta)\text{d}\nu(\beta)},\end{equation}
以更新我们对参数$\theta$分布的认知。
除了上面三个基本步骤外,3)中我们计算出后验分布以后,还可以估算出分布$P(\theta\mid \mathcal{D})$的一些统计量,主要有如下三种:
- 估算期望,这被称为后验期望估计(Expected a posteriori);
-
估算众数(Mode),被称为极大后验估计(Maximum a posteriori);
-
中位数等等,这被称为后验中位数估计(posterior median).
最终选择哪一种数作为我们模型参数的点估计,还得用所谓的贝叶斯决策论。进一步,我们还可以利用后验分布来进行区间估计和假设检验。下面重点看一下一种推断方法,也就是估计后验分布的众数,也被称为极大后验估计(maximum a posteriori estimate, MAP)。
三:极大后验估计MAP
\begin{equation}p(\theta\mid\mathcal{D})=\frac{p(\mathcal{D}\mid\theta)p(\theta)}{\int_{\Theta}p(\mathcal{D}\mid\beta)p(\beta)\text{d}\nu(\beta)}\end{equation}
点估计:
\begin{equation}\theta^{\ast}=\mathop{\arg\min}_{\theta\in\Theta}p(\theta\mid\mathcal{D})\end{equation}
3.1.极大后验估计的特点
3.1.1 众数的特殊性
极大后验估计的最基本特点是其显著依赖于先验分布的选取。尤其是在某些特殊情况下,例如当众数远远大于分布的大多数值的时候,后验分布的众数难以反映后验分布的整体情况因为众数只不过是分布的一个特殊点而已。例如如果后验分布呈现是如下情况的时候(选自[ ]):
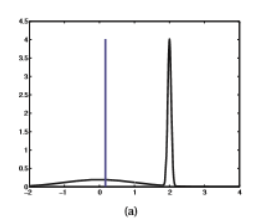
这时蓝线代表的是后验分布的期望所在的位置,在这种情况之下后验期望估计可能会更优于极大后验估计,所以先验分布的选择就显得尤为重要。
3.1.2.参数变换
另外,极大后验估计不是参数变换下不变的,这是极大后验估计的一大缺陷。具体来说,如果参数空间$\Theta$是欧式空间的某个开集,我们做一个参数变换:
\begin{equation}\theta=f(\theta^{\prime}),\end{equation}
其中$f:\Theta^{\prime}\longrightarrow\Theta$将某个开集$\Theta^{\prime}$1-1映射为$\Theta$,且$f,f^{-1}$均一阶连续。由上面的式子我们得到一个新的参数空间$\Theta^{\prime}$以及参数$\theta^{\prime}\in\Theta^{\prime}$,且新的参数也完全完全可以刻画概率分布族$p(x\mid\theta)$, 也就是$p(x\mid\theta^{\prime})=p(x\mid\text{f}(\theta^{\prime}))$。
这时候由变量替换得到:$$p(\theta)\text{d}\theta=p(\theta)\vert\det(\frac{\partial\theta}{\partial\theta^{\prime}})\vert\text{d}\theta^{\prime},$$
其中$\det(\frac{\partial\theta}{\partial\theta^{\prime}})$是$\theta$关于$\theta^{\prime}$的Jacobian行列式。有上式我们立即得到$p(\theta^{\prime})=p(\theta)\vert\det(\frac{\partial\theta}{\partial\theta^{\prime}})\vert$,由该式子出发进一步利用贝叶斯公式我们有:
\begin{equation}P(\theta^{\prime}\mid\mathcal{D})=P(\theta\mid\mathcal{D})\vert\det(\frac{\partial \theta}{\partial \theta^{\prime}})\vert\end{equation}
由于右边多出了个$\det(\frac{\partial\theta}{\partial\theta^{\prime}})$, 所以我们知道极大后验估计不是参数变换下不变的, 这是MAP大大不同于后验期望估计和后验中位数估计的地方。更多具体例子参见[1], 5.2.1.4。
3.2.极大后验估计和正则化的关系
$$P(\theta\mid\mathcal{D})\varpropto \mathcal{L}(\theta)p(\theta),$$
\begin{equation}\theta_{\text{MAP}}=\mathop{\arg\max}_{\theta\in\Theta}P(\theta\mid\mathcal{D})=\mathop{\arg\max}_{\theta\in\Theta}\mathcal{L}(\theta)p(\theta)=\mathop{\arg\min}_{\theta\in\Theta}[-\log (\mathcal{L}(\theta))-\log(p(\theta))].\end{equation}
在机器学习中很多模型是在做极大似然估计(Maximum likelihood estimate),例如线性回归,Logistic回归。这时候如果我们选取先验概率分布为某期望为$0$的高斯分布,则容易知道$-\log p(\theta)=\lambda\vert \theta\vert^{2}+C$,其中$\lambda,C>0$为常数。所以这时候:
\begin{equation}\theta_{\text{MAP}}=\mathop{\arg\min}_{\theta\in\Theta}[-\log (\mathcal{L}(\theta))+\lambda\vert \theta\vert^{2}].\end{equation}
从上可知这时候的极大后验估计只不过是L2正则化了的$极大似然估计。同理当我们取先验分布为拉普拉斯分布的时候,所得到的是L1正则化了的极大似然估计。从中看出,所谓的L1正则化,L2正则化只不过是具有特殊先验分布的MAP估计。
四.先验概率的选择(待续)
五.贝叶斯区间估计
在贝叶斯统计的框架下,我们可以光明正大地谈:$\theta$满足$\times\times\times$条件的概率是$\times$这个概念,但是在频率派那里,因为这个概念是错误的,所以“置信区间”这个概念不太好被理解,但是实际上很多人就是将频率派框架下的置信区间错误地理解为关于参数的概率。
定义:一般的,对于给定的样本$\mathcal{D}$,如果已经得到后验分布$P(\theta\mid\mathcal{D})$,且存在统计量$\theta_{L}=\theta_{L}(\mathcal{D})$和$\theta_{U}=\theta_{U}(\mathcal{D})$使得:
\begin{equation}P(\theta\in [\theta_{L},\theta_{U}])\mid\mathcal{D})\geq 1-\alpha\end{equation}
则我们称$[\theta_{L},\theta_{U}]$为$\theta$的$1-\alpha$贝叶斯可信区间(credible interval)。
我们对比一下贝叶斯可信区间和频率派置信区间的区别:
频率派的$1-\alpha$置信区间指的是对任意样本$\mathcal{D}$我们有某个区间$\text{I}_{\mathcal{D}}$,使得"区间包含固定参数值$\theta$"的概率是不小于$1-\alpha$的,注意这时候的概率是相对"抽样"这件随机事件而言的,而不是相对"参数",因为参数是个固定值,只是我们不知道它是多少而已。换句话说,正如开头所说的那样,95%区间估计应该保证当$N$足够大的时候,我们任意随机,独立地选取$N$个样本集$S_{1}$, $S_{2}$,...,$S_{N}$所计算出来的相应的区间$I_{1}$,$I_{2}$,...,$I_{N}$中将有至少95%N个区间包含我们需要估计的统计量的真实值。
而贝叶斯派的可信区间的意义就简单得多,它就是指"$\theta$属于区间的后验概率"大于等于$1-\alpha$。
在实际应用中,我们一般选取一个$1-\alpha$中心可信区间,也就是选取一个区间使得两端的尾部的概率均为$\alpha/2$,也就是说使得$P(\theta>\theta_{U}\mid\mathcal{D})=\alpha/2$以及$P(\theta<\theta_{L}\mid\mathcal{D})=\alpha/2$。当后验概率的分布函数有明确而简单的形式的时候我们可以直接方便得计算$\theta_{L}=F^{-1}(1-\alpha/2)$,$\theta_{U}=F^{-1}(\alpha/2)$,否则我们就使用蒙特卡罗法或者马尔科夫链蒙特卡罗方法进行近似计算。
六.贝叶斯决策论
下面简单介绍一下贝叶斯决策论。所谓贝叶斯决策论(Bayesian decision theory)就是一个人与自然的一种博弈策略。想象一下,人和大自然或者人类社会有一场游戏,大自然(或者神学地讲,“上帝”)或者人类社会,会以一定概率随机从某个状态空间$\Theta$中抽取某个状态$\theta\in\Theta$,然后人类随后随机抽取一满足该状态的数据$\mathcal{D}$,然后人类得猜测这个状态是多少。那么,人该怎么决策呢?
我们现在只讨论一种情形,其游戏规则如下:$\Theta$是某个概率分布$p(x\mid\theta)$的参数空间,每次我们可以得到一个样本$\mathcal{D}=(X_{1},...,X_{M})$,$X_{i}\sim p(\cdot\mid\theta)$,且:
1)我们有$\theta$的先验概率分布$p(\theta)$,是根据以往的人类对自然界或者社会类似事情的统计结果得到的,有助于决策的进行;
2)我们有一个行动集$\mathcal{A}$,一个损失函数$L:\Theta\times\mathcal{A}\longrightarrow \mathbb{R}$,以表示每次我们做出决策行动后所承担的损失,常见的损失函数有$\mathop{\text{L}}^{2}$,$\mathop{\text{L}}^{1}$,$0-1$损失函数等等。
那么我们该如何做决策呢?在贝叶斯框架下,一种自然的思路是:
\begin{equation}\delta(\mathcal{D})\triangleq\mathop{\arg\min}_{\alpha\in\mathcal{A}}\text{E}_{p(\theta\mid\mathcal{D})}(L(\theta,\alpha)),\end{equation}
其中$\text{E}_{p(\theta\mid\mathcal{D})}$表示后验分布下的期望也就是:
\begin{equation}\text{E}_{p(\theta\mid\mathcal{D})}(L(\theta,\alpha))=\int_{\Theta}L(\theta,\alpha)p(\theta\mid\mathcal{D})\text{d}\theta\end{equation}

