
影视资源搜索引擎的设计方案
一、项目介绍
本项目为基于影视资源的搜索引擎,项目针对需要查询影视资源的用户,帮助他们查找相关的电影,并对查找到的信息进行下载、观看等一系列的操作。
二、系统架构
本项目是一个典型的 C/S (客户-服务器)架构模式,服务器负责所有数据的存储与组织,客户端通过 HTTP 访问服务器,请求相应的数据并向用户展示出来,同时接收用户输入,与用户做交互。在客户-服务模式中,客户是主动的,服务是被动的。客户知道它向哪个服务发出请求,而服务却不知道它正在为哪个客户提供服务,甚至不知道正在为多少客户提供服务.客户-服务模式的架构风格具有典型的模块化特征,降低了系统中客户和服务构件之间耦合度,提高了服务构件的可重用性。
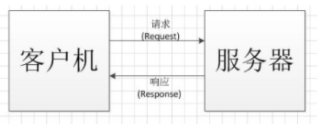
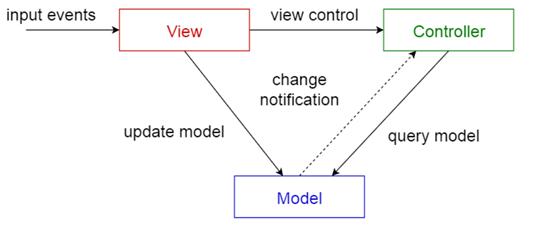
本系统采用的是MVC开发架构,即模型-视图-控制器模式。用一种业务逻辑、数据、界面显示分离的方法组织代码,将业务逻辑聚集到一个部件里面,在改进和个性化定制界面及用户交互的同时,不需要重新编写业务逻辑。MVC被独特的发展起来用于映射传统的输入、处理和输出功能在一个逻辑的图形化用户界面的结构中。它把软件系统分为三个基本部分:
模型(Model):负责存储系统的中心数据。
视图(View):将信息显示给用户(可以定义多个视图)。
控制器(Controller):处理用户输入的信息。负责从视图读取数据,控制用户输入,并向模型发送数据,是应用程序中处理用户交互的部分。负责管理与用户交互交互控制。
三、接口API
本项目采用Restful风格的API接口设计,这是一种软件架构风格、设计风格,而不是标准,只是提供了一组设计原则和约束条件。它主要用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
| 接口名称 | 接口地址 | 请求方式 | 请求参数 | 响应信息 |
| 用户注册 | user/register | post | 用户名,密码,确认密码 | 注册成功/失败 |
| 用户/管理员登录 | user/login | post | 用户名,密码 | 登录成功/失败以及权限信息 |
| 用户信息 | user/info | post | 用户Id | 用户完整信息 |
| 搜索电影 | movie/query | get | 电影名称 | 相关电影信息 |
| 收藏电影 | movie/collection | post | 用户Id,电影Id | 收藏成功/失败 |
| 取消收藏 | movie/discollection | post | 用户Id,电影Id | 取消收藏成功/失败 |
| 下载电影 | movie/download | get | 电影Id | 下载成功/失败 |
| 修改用户信息 | user/changeInfo | post | 新用户名,密码 | 修改成功/失败 |
| 查看收藏电影 | movie/showCollection | get | 用户Id | 收藏的信息 |
| 删除用户 | admin/deleteUser | post | 用户Id | 删除成功/失败 |
| 删除电影 | admin/deleteMovie | post | 电影Id | 删除成功/失败 |
| 修改电影信息 | admin/changeMovie | post | 电影ID,电影信息 | 修改成功/失败 |
| 增加电影 | admin/addMovie | post | 电影信息 | 添加成功/失败 |
三、软件系统概念原型的不同视图
该项目的UML图如下:
3.1分解视图
分解是构建软件架构模型的关键步骤,分解视图也是描述软件架构模型的关键视图,一般分解视图呈现为较为明晰的分解结构(breakdown structure)特点。分解视图用软件模块勾划出系统结构,往往会通过不同抽象层级的软件模块形成层次化的结构。
3.2依赖视图
依赖视图展现了软件模块之间的依赖关系.
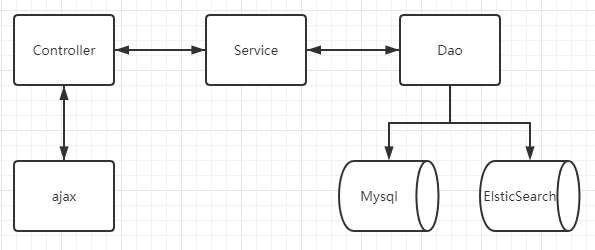
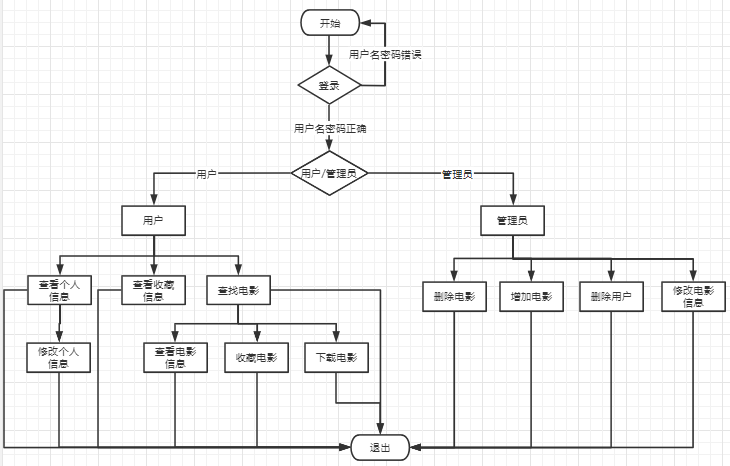
3.3执行视图
执行视图如系统流图,可以较为明显的展现了系统运行时的时序结构特点,他可以最终分解到软件的基本元素和软件的基本结构,可以对系统整体的业务逻辑有较为直观的体现。
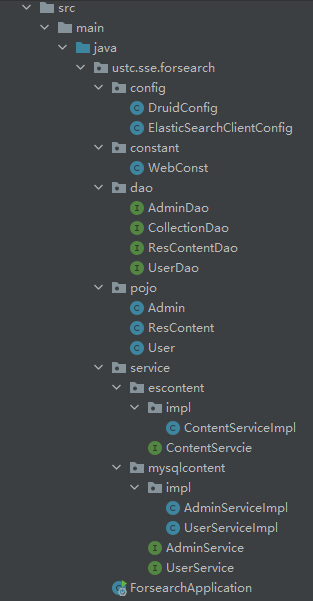
3.4实现视图
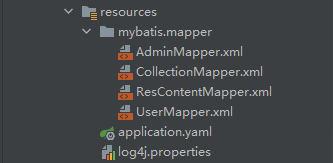
实现视图是描述软件架构与源文件之间的映射关系。比如软件架构的静态结构以包图或设计类图的方式来描述,但是这些包和类都是在哪些目录的哪些源文件中具体实现的呢?一般我们通过目录和源文件的命名来对应软件架构中的包、类等静态结构单元,这样典型的实现视图就可以由软件项目的源文件目录树来呈现。
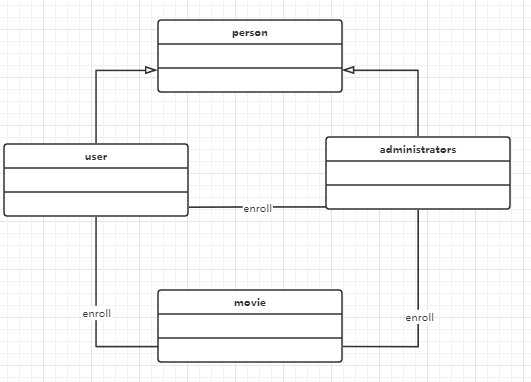
3.5泛化视图
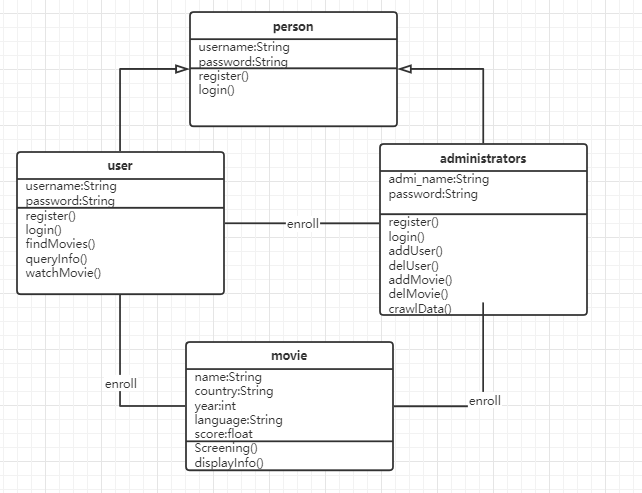
泛化视图展现了软件模块之间的一般化或者具体化的关系,典型的例子就是类之间的继承关系。如下图所示了本项目的继承关系,学生、教师和管理员这三种用户类型都继承自基本用户,并通过课程进行相互联系。这种视图有利于我们了解系统的抽象层次结构,也有利于系统功能的扩展。
3.6部署视图
部署视图是将执行实体和计算机资源建立映射关系。这里的执行实体的粒度要与所部署的计算机资源相匹配,比如以进程作为执行实体,那么对应的计算机资源就是主机,这时应该描述进程对应主机所组成的网络拓扑结构,这样可以清晰地呈现进程间的网络通信和部署环境的网络结构特点。当然也可以用细粒度的执行实体对应处理器、存储器等。部署视图有助于设计人员分析一个设计的质量属性,比如软件处理网络高并发的能力、软件对处理器的计算需求等。

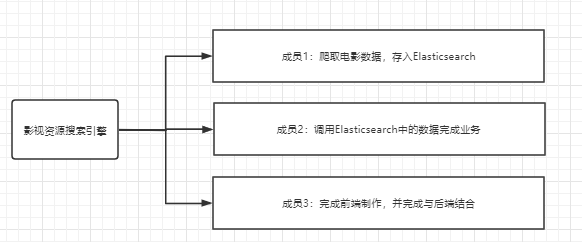
3.7工作分配视图
工作分配视图可以清晰的展现出项目分工。工作分配视图有利于跟踪不同项目团队和成员的工作任务的进度,对于不同团队成员所擅长的地方进行合适的分工可以较大限度的提升团队的工作效率。下图给出了本项目的一个工作分配视图。
四、数据库设计
用户表:
| 变量名 | 变量类型 | 描述 |
| username | varchar | 用户名(主键) |
| password | varchar | 密码 |
管理员表:
| 变量名 | 变量类型 | 描述 |
| admi_name | varchar | 管理员名(主键) |
| password | varchar | 密码 |
电影表:
| 变量名 | 变量类型 | 描述 |
| name | varchar | 电影名称(主键) |
| country | varchar | 产地国家 |
| year | int | 上映时间 |
| language | varchar | 语言 |
| score | float | 豆瓣评分 |
五、运行环境和技术选型
本项目的运行环境为window 10 下的JDK1.8环境。项目使用了SSM框架以及Springboot技术,数据库使用了Mysql和ElasticSearch。前端使用了html/css/js/vue/bootstrap技术。
六、系统概念原型的核心工作机制
每个视图都是从不同的角度对软件架构进行描述和建模,比如从功能的角度、从代码结构的角度、从运行时结构的角度、从目录文件的角度,或者从项目团队组织结构的角度。 软件架构代表了软件系统的整体设计结构,它应该是所有这些视图的集合。但我们不会将不同角度的这些视图整合起来,因为不便于阅读和更新。不过我们会有意识地将不同角度的视图之间的映射关系和重叠部分了然于胸,从而深刻理解软件架构内在的一致性和完整性,这就是系统概念原型。
基于以上分析和建模,我们可以总结出此项目的概念原型,同时对此概念模型的工作过程进行分析。
影视资源搜索引擎概念模型分为两个用例图和三个数据模型:用例图分为用户用例图和管理员用例图;数据模型分为用户,管理员和电影
管理员先进行注册,将管理员信息录入管理员表中。登录,然后运行爬虫程序对指定网站进行增量式爬虫,将爬取得到的信息存入数据库的电影表中,并可在该表中添加和删除电影信息。用户可在PC端进行注册登录,注册成功后会将用户信息存入用户表中,登录时查看用户输入的用户名密码与用户表中是否匹配,若匹配则成功登录。用户登录成功后可进行查找电影,观看电影,下载电影等操作。管理员有权删除用户表中的用户信息,使得用户无法再次登录。
七、总结
本文总结了项目设计方案中所蕴含的软件结构特点,比如设计模式、软件架构风格与策略等;并采用不同的视图来描述项目的软件系统概念原型,比如分解视图、依赖视图、泛化视图、执行视图、实现视图、部署视图、工作分配视图等。希望对工程实践项目的开展有所帮助。

