第十八章 全文本搜索
2016-12-18 10:38 szn好色仙人 阅读(295) 评论(0) 收藏 举报1.使用like和regexp进行文本的搜索有几个缺点: A:性能不高,通配符和正则表达式通常要求mysql尝试匹配表中所有行,由于行数多,这些搜索可能很耗时 B:使用正则表达式和通配符很难明确空值 C:虽然基于通配符和正则表达式的搜索提供了非常灵活的效率,但它们都不能提供一种智能化的选择结果 2.为了进行全文本搜索,必须索引被搜索的列,而且随着数据的改变不断重新索引。在索引之后select可与match()和against()一起使用。 3.一般在创建表时启用全文本搜索。create table语句接受fulltext子句如下:

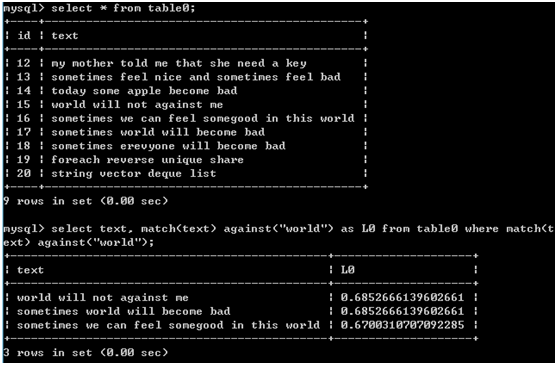
注意点:不要在导入数据时使用fulltext,而应该首先导入数据,然后定义fulltext,这样效率比较高 4.在索引之后,使用match()指定被搜索的列,against()指定要使用的搜索表达式。 传递给match的值必须与fulltext中定义的相同,而且若指定多个列,列的顺序也要正确 全文本搜索的一个重要部分是对结果排序,具有较高等级的行先返回,文中词靠前的行的等级比词靠后的行高
5.使用扩展查询(with query expansion): mysql对数据和索引进行两边扫描来完成搜索,首先找出与搜索条件匹配的所有行,其次mysql检查这些匹配行并选择所有有用的词,然后在进行一次全文本搜索,不仅使用原来的条件,而且还使用所有有用的词
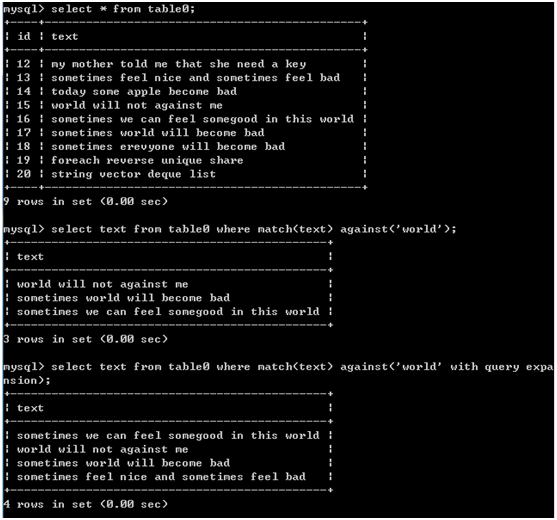
如上可知,扩展查询增加了返回的行数,但是也返回了一些没用的行 6.布尔文本搜索(in boolean mode) 以布尔方式可以提供如下内容: A:要匹配的词 B:要排斥的词 C:排列提示 D:表达式分组 E:其他内容 +: 包含,词必须存在 -: 排除,词必须不存在 >: 包含,增加等级 <: 包含,减少等级 (): 把词组成表达式 ~: 取消一个值的排序值 *: 词尾通配符 "": 定义一个短语,与单个词的列表不同,它将匹配整个短语


7.布尔搜索注意点: 在布尔方式中,不按等级值降序排序返回行,即只排列而不排序 可以在非fulltext列中进行布尔搜索,但是效率很低 8.全文本搜索说明: A:在索引全文本数据时,短词将被从索引中排除。短词定义为具有3个及以下的词(数目可更改) B:mysql带有一个内建的非用词列表,这些词在索引中总是被忽略(此表可被覆盖) C:如果一个词在行中出现的频率大于百分之50,则将其作为非用词进行忽略。此规则不用于布尔搜索中 D:仅在myisam数据库引擎中支持全文本搜索 E:对于汉语不能恰当的返回全文本搜索结果 F:忽略词中的引号,如don't索引为dont

 浙公网安备 33010602011771号
浙公网安备 33010602011771号