python函数
import math def add(a): result=(a.real**2+a.imag**2)**0.5 return result def angle(a): result=math.atan(a.imag/a.real) return result add(3+4j) print(add(3+4j)) print(angle(3+4j))
def abc(a,b,c): delt=b**2-4*a*c if delt>=0: x1=(-b+delt**0.5)/(2*a) x2 = (-b - delt ** 0.5) / (2 * a) print(x1) print(x2) else: print("无解") abc(2,-5,-10)
cities_dict = { '海口': 19.97, '广州': 23.11, '深圳': 22.54, '福州': 26.08, '杭州': 30.27, '上海': 31.23, '南京': 32.04, '武汉': 30.58, '长沙': 28.21, '南昌': 28.68, '合肥': 31.86, '郑州': 34.76, '济南': 36.67, '北京': 39.90, '天津': 39.13, '石家庄': 38.03, '沈阳': 41.80, '长春': 43.88, '哈尔滨': 45.75, '呼和浩特': 40.82, } user_input = input("请输入你想要比较的城市(用空格分隔):") selected_cities = user_input.split() selected_cities_with_lats = [] for city in selected_cities: if city in cities_dict: selected_cities_with_lats.append((city, cities_dict[city])) else: print(f"警告:城市 '{city}' 不在字典中。") sorted_cities = sorted(selected_cities_with_lats, key=lambda x: x[1]) for city, latitude in sorted_cities: print(f"{city}: {latitude}")
爬虫
import requests from bs4 import BeautifulSoup for page in range(1, 3): url = f'https://search.bilibili.com/all?keyword=%E5%8A%A8%E7%94%BB%E7%89%87&from_source=webtop_search&spm_id_from=333.1073&search_source=5&page={page}' headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0'} response = requests.get(url, headers=headers) soup = BeautifulSoup(response.text, 'html.parser') video_cards = soup.find_all('div', class_='bili-video-card') for card in video_cards: video_title = card.find('h3', class_='bili-video-card__info--tit').get_text() video_duration = card.find('span', class_='bili-video-card__stats__duration').get_text() video_author = card.find('span', class_='bili-video-card__info--author').get_text() print("视频标题:", video_title) print("视频时长:", video_duration) print("作者:", video_author)
两个表的内容按行绑定
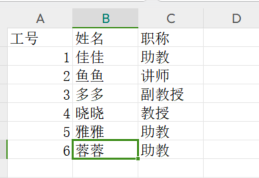
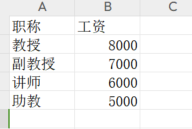
import pandas as pd df1 = pd.read_csv('工作簿1(1).csv') df2 = pd.read_csv('工作簿2.csv') merged_df = pd.merge(df1, df2, on='职称') print(merged_df[['姓名', '工资']])
工作簿1(1).xlsx
工作簿2.xlsx
实现扫描文件夹中的.TXT文件,为每一个不同的学生建一个文件夹,把同一学号和姓名的文件移到对应文件夹中
import os import shutil score_folder_path = "E:\成绩1" if not os.path.exists(score_folder_path): print(f"文件夹 {score_folder_path} 不存在!") exit(1) for filename in os.listdir(score_folder_path): if filename.endswith('.txt'): base, ext = os.path.splitext(filename) parts = base.split(' ') if len(parts) == 2 and len(parts[0]) == 8: student_id = parts[0] student_name = parts[1] folder_name = student_name target_folder_path = os.path.join(score_folder_path, folder_name) if not os.path.exists(target_folder_path): os.makedirs(target_folder_path) source_file_path = os.path.join(score_folder_path, filename) target_file_path = os.path.join(target_folder_path, filename) shutil.move(source_file_path, target_file_path) print("文件已按姓名或学号分类到各自的文件夹中。")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号