python基础一:python列表基础和一些经典使用案例
1. 写在前面
好久没有更新python这一块的内容了, 所以今天整理一块python的内容。今天整理的内容是python里面的列表, 作为在python中非常常见的数据类型, 尝试用一篇文章来整理其常用的操作,方便以后查看使用。 目前可能不全,以后遇到列表相关的操作都放到这篇文章里面来。
首先从列表的基础操作开始, 看一下什么是python列表, 列表背后的内存组织, 然后介绍列表里面的常用操作, 像列表的添加, 删除,切片等。 接下来会介绍点深浅拷贝的知识和可变不可变对象。 最后整理常用的列表使用案例。
这次整理列表, 会从纯使用的角度去整理, 关于列表的理论知识和细节知识, 这里不做整理。
知识框架:
- 列表的基础操作(添加, 删除, 切片, 索引, 遍历等)
- 深浅拷贝和可变不可变
- 列表常用的使用小例子
ok, let’s go!
2. 列表的基础操作
关于list, 它是python中非常重要的一种数据类型, 常用的创建方式会有两种: []和list(), 下面我们先尝试创建一个列表:
lst = [1, 3, 5] # lst就是一个列表 # lst = list((1, 3, 5))
我们看看这行代码在内存中是什么样子的:
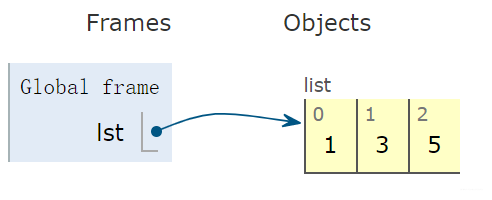
是有一块内存空间存放[1, 3, 5], 然后把这块内存空间的首地址给了list。注意,这个地方右边是开着的, 和(1,3,5)还不一样, 后者表示元组, 在内存里面是这样:
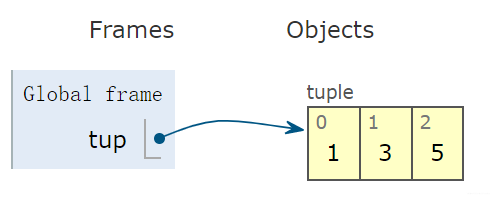
元组也是python中容器型的一种, 和list不同的是, list是一种可变对象, 而元组是一种不可变对象。
2.1 列表的常用操作
创建完列表之后,我们要会使用,这里介绍一些基本的使用,比如查看列表的元素个数, 遍历列表看元素和及其类型, 列表的添加, 删除, 切片,索引。 下面就来看看:
1 # 创建一个列表 2 lst = [1, 'xiaoming', 29.5, '17382348927'] # 列表里面元素类型不一定一样 3 4 print(len(lst)) # len函数返回列表的元素个数, 非常常用 5 6 # 列表的索引 由于下标是0-len(st)-1, 所以通过下标就可以访问某个元素 7 lst[2] # 这个就是29.5 8 9 10 # 遍历列表 11 for _ in lst: # 这行代码就可以遍历列表查看每个元素的类型 12 print(f"{_}的类型为{type(_)}") 13 14 ## 结果 15 1的类型为<class 'int'> 16 xiaoming的类型为<class 'str'> 17 29.5的类型为<class 'float'> 18 17382348927的类型为<class 'str'>
列表作为一种可变对象, 我们是可以在里面添加和删除元素的, 关于列表的添加, 常用的方式有三种: append, extend, insert。
1 # append方式从列表的尾部添加元素 2 lst = [1, 'xiaoming', 29.5, '17382348927'] 3 lst.append('hello') #[1, 'xiaoming', 29.5, '17382348927', 'hello'] 4 lst.append(['hello', 'world']) # #[1, 'xiaoming', 29.5, '17382348927', 'hello', ['hello', 'world']] 5 # 上面的第二个是列表里面又加了个列表元素 6 7 # extend也是从列表尾部添加元素, 但是和append又有些区别 8 lst.extend(['hello', 'world']) # [1, 'xiaoming', 29.5, '17382348927', 'hello', 'world] 9 # 注意看区别, extend的时候,是只要后面列表里面的元素, 不是把列表加进去 10 11 # insert 在指定位置添加元素 12 lst.insert(1, 10) 13 # [1, 10, 'xiaoming', 29.5, '17382348927']
上面的都比较简单, 做简单回顾。
关于列表的删除常用的方式: pop和remove
1 lst = [1, 'xiaoming', 29.5, '17382348927'] 2 3 # pop 默认是从尾部删除元素并返回 4 lst.pop() # 这个是'17382348927' 5 # 执行了上面这句代码之后, lst变成了[1, 'xiaoming', 29.5], 当然pop也可以指定位置删除元素 6 lst.pop(1) 7 8 # remove()删除指定元素 9 lst.remove('xiaoming')
关于索引的切片, 这里不多说, 简单演示:
1 a = [i for i in range(1, 10)] 2 print(a) 3 print(a[::-1]) # 列表翻转 这个很实用 4 print(a[:-1]) 5 print(a[1:5:2]) 6 print(a[::-3]) 7 8 ## 结果 9 [1, 2, 3, 4, 5, 6, 7, 8, 9] 10 [9, 8, 7, 6, 5, 4, 3, 2, 1] 11 [1, 2, 3, 4, 5, 6, 7, 8] 12 [2, 4] 13 [9, 6, 3]
3. 关于深浅拷贝和可变不可变
先抛开深浅拷贝, 我们先来看一个列表的例子:
1 # 列表的创建 2 lst2 = ['001','2019-11-11',['三文鱼','电烤箱']]
这个列表看起来很简单, 但是内部怎么组织的呢?

现在就知道了, 列表里面套列表的时候, 在内存的角度到底是如何组织的。 这时候,我们把里面那个列表给赋值到一个新的变量上面去:
1 # 索引 2 sku = lst2[2] # ['三文鱼', '电烤箱']
这时候内存是这样子的:
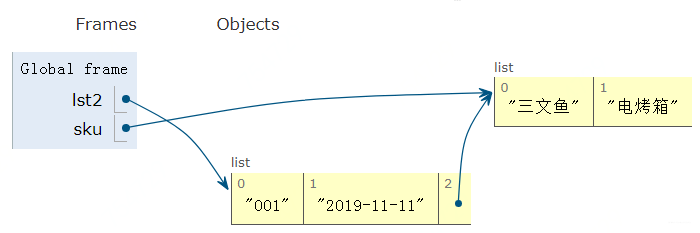
就是sku也指向到了里面的这个列表中。 这时候, 很明显,我们尝试修改sku指向的列表, 那么lst[2]肯定也会变:
1 sku.append('烤鸭') 2 3 # 这时候 4 sku ['三文鱼', '电烤箱', '烤鸭'] 5 lst2 ['001','2019-11-11',['三文鱼','电烤箱', '烤鸭']]
也就是这种情况下, 修改sku会导致lst2本身也会改变。 看内部原理图就非常容易理解, 那么有没有一种方式,我改sku的时候,不改变lst2本身呢?
3.1 深浅拷贝
浅拷贝可以帮助我们完成上面的要求, 浅拷贝.copy(), 把lst2[2]进行拷贝一份, 这时候就发现sku变量与lst2[2]指向的对象就不是一个了。
1 sku_deep = lst2[2].copy() 2 sku_deep # ['三文鱼', '电烤箱']
虽然内容是一样, 但看内存:
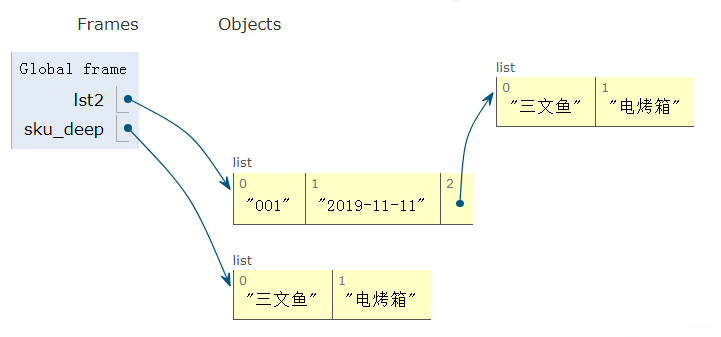
这时候很显然, 修改sku_keep就不会影响lst2的内容了。 那么浅拷贝和深拷贝有啥区别呢?
上面这个例子可能还看不出区别, 但是下面这个例子就非常看出事情:
1 # 再创建一个新的列表,也是列表套列表 2 a = [1, 2, [3, 4, 5]] 3 ac = a.copy() # ac是a的一个浅拷贝 4 5 # 我们改一下ac的值 6 ac[0] = 10 7 print(a[0], ac[0]) # 1 10 确实实现了拷贝, a和ac分开了 8 9 # 但是真的分的彻底吗? 我们改一下ac的值,但这次该里面那个列表 10 ac[2][1] = 40 11 print(a[2][1], ac[2][1]) # 40 40 我们发现了啥? 竟然改ac里面列表的时候a里面的列表也跟着变了
上面例子就说明了浅拷贝,并没有拷贝的那么彻底, 像这种列表套列表的情况, 浅拷贝仅仅拷贝了第一层而已, 看个图就明白了:
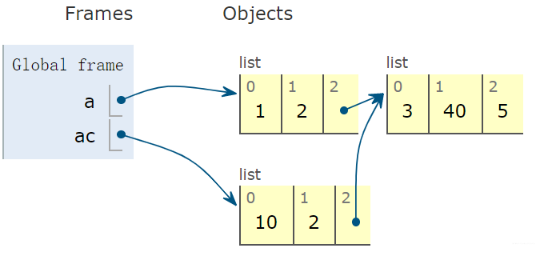
这个图很清晰的说明了上面的那两个变化情况。 原来浅拷贝之后, a[2]和ac[2]依然指向了同一块空间。 类似于藕断丝连。 浅拷贝之后, 我弄一块新内存放外面的列表, 但是列表里面再有列表的话, 我不管
那么深拷贝是怎么回事呢? 可能你也想到了, 那就是断的彻底。 即使列表里面套列表, 当我深拷贝之后, 我弄一块内存放外面的表, 同时如果列表里面有列表, 我也会弄一块新内存放里面的表。看下面的例子和图:
1 from copy import deepcopy 2 3 a = [1, 2, [3, 4, 5]] 4 ac = deepcopy(a) 5 ac[0] = 10 6 ac[2][1] = 40 7 print(a[0], ac[0]) # 1 10 8 print(ac[2][1], a[2][1]) # 40 4
深拷贝是deepcopy(), 深拷贝之后我们发现a和ac就完全没有关系了。
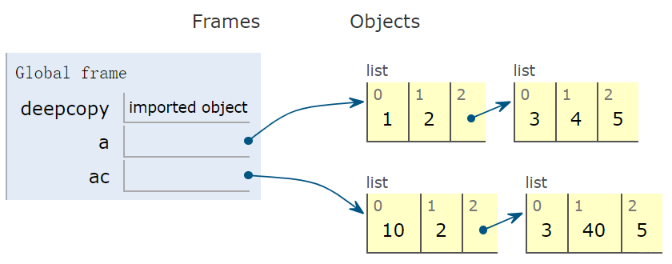
3.2 关于可变与不可变
这个话题其实在python那里尝试整理了一下, 这里再用内部图的方式重新理解一下, 就拿列表和元组来看即可, 看看这个可变和不可变到底啥意思?可变和不可变是一对很微妙的概念
我们知道,列表是可变对象, 那么这个可变是啥意思呢? 我们建立一个列表看一下:
1 # 创建一个列表 2 a = [1, 3, [5, 7], 9, 11, 13]
上面的a是一个普通列表, 但是又不算一个很普通的列表,因为里面还有一个列表, 我们看看这个的内部图:
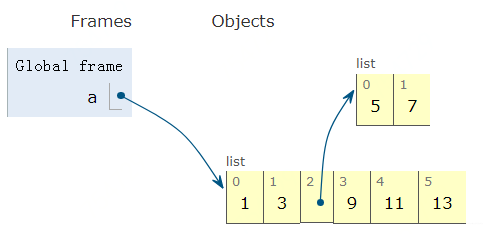
那么什么是可变呢? 这个意思是a指向的对象本身是可以变得, 比如我们在a中删除元素: a.pop()
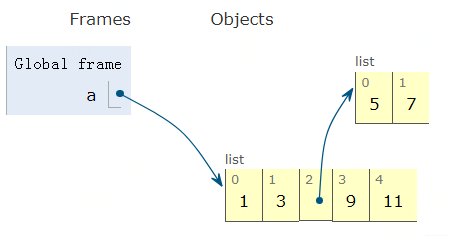
是不是a指向的对象本身变了? 如果没看清楚, 我们再像a里面添加元素, a.insert(3, 8)
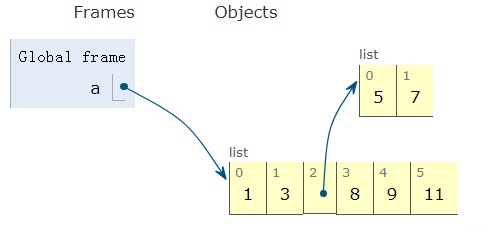
所以对于列表而言, 它能添加和删除元素, 所以是可变的。 但注意是本身可变。 如果我执行这一步操作:a[2].insert(1, 6)
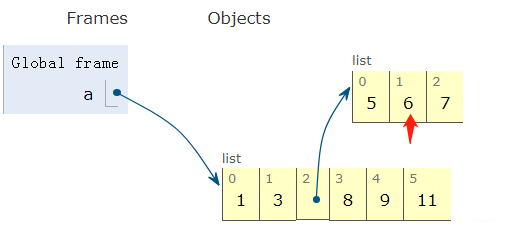
这个如果我们打印a的话, 也会发现a变了, 但是,这个要注意, 这个不能说明a是可变的, 因为a指向的对象本身并没有变, 变得只是a[2]指向的对象, 只能说a里面的元素有可变的, 理解这一点非常重要, 为啥呢? 我们下面看看元组吧。
我们知道,元组是不可变对象, 但是有时候, 我们也能看似改变它的元素:
1 a =(1,3,[5,7],9,11,13)
依然是上面的那些元素, 只是把[]换成(), 这时候a就是一个元组了。 我们看看内部结构:
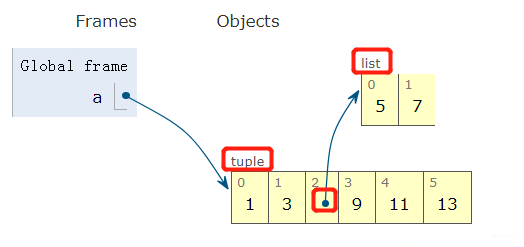
其实, 看元组本身会发现右边是封闭的了。 这时候我们依然a[2].insert(1, 6), 这个时候我们同样也会观察到a里面的元素有变化。
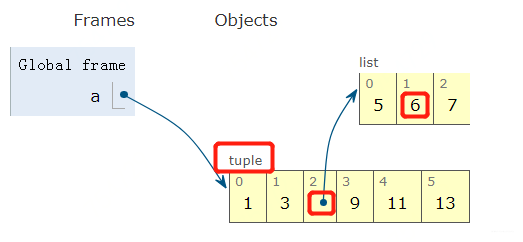
但是, 我们看a指向的对象本身, 其实没有变, a内元素也没有发生增减, 长度还是6, 所以对于不可变对象而言, 一旦创建后,长度就不能发生改变, 但是允许里面的元素有可变对象。
所以对于list而言, 列表长度有增有减,对象本身会发生改变, 所以它是可变的, 而tuple而言, 允许里面的元素可变,但是它本身不会发生改变。 所以它是不可变对象。
说了这么多,不知道听懂了没有。
4. list的经典使用案例
下面的这些例子非常经典实用, 不管是刷题还是应用中其实很常见, 顺序不分先后。
-
判断list里面有无重复元素
1 def is_duplicated(lst): 2 return len(set(lst)) != len(lst) 3 4 a = [1, 2, 3, 3] 5 is_duplicated(a)
-
列表的逆序
1 def reverse(lst): 2 return lst[::-1]
-
找出列表中重复的元素
这个就是count计数, 遍历一遍,看看有重复的,加入新的数组1 def find_duplicated(l): 2 ret = [] 3 for item in l: 4 if l.count(item) > 1 and item not in ret: 5 ret.append(item) 6 return ret 7 8 a = [1, 2, 3, 2, 1] 9 b = find_duplicated(a) # [1, 2]
-
去掉列表中最大值最小值,然后计算剩余元素平均值
1 def score_mean(lst): 2 lst.sort() 3 lst2 = lst[1:-1] 4 return round((sum(lst2)/len(lst2)), 1) 5 6 lst=[9.1, 9.0,8.1, 9.7, 19,8.2, 8.6,9.8] 7 score_mean(lst) # 9.1
这个像不像去掉最高分和最低分取平均, 看一下动画演示过程:
![]()
-
获得列表的表头和表尾
1 def head(lst): 2 return lst[0] if len(lst) > 0 else None # 这个判断形式要会 3 print(head([])) 4 print(head([1, 2, 3])) 5 6 def tail(lst): 7 return lst[-1] if len(lst) > 0 else None
-
获得列表中出现次数最多的元素
这个还是很实用的, 寻找众数有没有? 如果列表里面只有一个元素出现的次数最多, 那么可以用max内置函数, 里面的key设置为元素的个数比较。1 def mode(lst): 2 if not lst: 3 return None 4 return max(lst, key=lambda v: lst.count(v)) # v 在 lst 的出现次数作为大小比较的依据 5 6 a = [1, 2, 3,4, 2] 7 mode(a) # 2
如果众数不止一个, 那么这时候就需要获得这个众数之后, 得到它出现的次数, 遍历列表,把次数相同的返回:
1 # 如果是有多个元素的时候 2 def mode(lst): 3 if not lst: 4 return None 5 6 max_freq_elem = max(lst, key=lambda v: lst.count(v)) 7 max_freq = lst.count(max_freq_elem) # 出现最多的次数 8 ret = [] 9 for i in lst: 10 if lst.count(i) == max_freq and i not in ret: 11 ret.append(i) 12 13 return ret 14 15 a = [1, 2, 3, 4, 3, 2] 16 mode(a) # [3, 2]
-
返回更长的列表
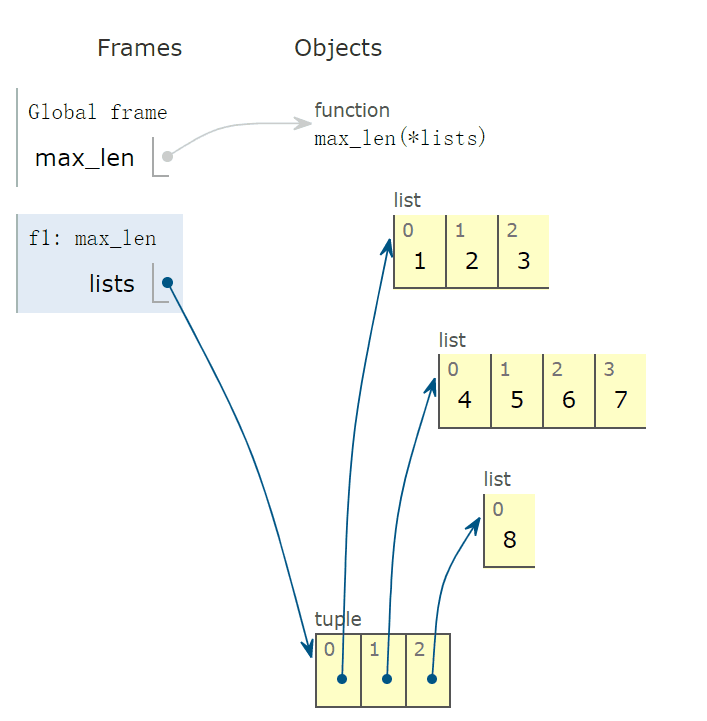
就是多个列表, 得到长度最长的那个。 在这里我们看一下max内部到底是咋工作的。1 def max_len(*lists): 2 return max(*lists, key=lambda v: len(v)) # v 代表一个 list,其长度作为大小比较的依据 3 4 r = max_len([1, 2, 3], [4,5], [5]) 5 r # [1, 2, 3]
这个*可以匹配多个参数, 记不记得函数的可变参数? 在python基础里面整理过的。 这里就是把列表都传进去, 然后根据max函数,返回最长的列表, 可以看到这个地方的key表示的list的长度。 看一下内部是怎么实现的:
![]()
-
洗牌数据shuffle
1 from random import shuffle, randint 2 lst = [1, 2, 3] 3 shuffle(lst) 4 lst
shuffle可以打乱列表, 当然如果是数组的话, 可以用permutation:
1 index = np.random.permutation(3) # 这个是数组的随机洗牌 2 a = np.array(lst) 3 a = a[index] 4 a
这些在打乱样本的时候非常实用。
-
生成元素对
1 a = [i for i in range(10)] 2 list(zip(a[:-1], a[1:])) 3 4 # 5 [(0, 1), (1, 2), (2, 3), (3, 4), (4, 5), (5, 6), (6, 7), (7, 8), (8, 9)]
这个在取样的时候也有时候会用到
-
斐波那契数列
1 def fibonacci(n): 2 if n <= 1: 3 return [1] 4 fib = [1, 1] 5 while len(fib) < n: 6 fib.append(fib[len(fib)-1] + fib[len(fib)-2]) 7 8 return fib 9 10 fibonacci(5)
当然,这个方法耗费内存,也不高效, 所以还可以更高效。 用生成器。
1 # 上面的方法不高效, 生成器会更简洁和节省内存 2 def fibonacci(n): 3 a, b = 1, 1 4 for _ in range(n): 5 yield a # 遇到yield之后, 返回,下次再进入函数体, 从yield中的下一句执行 6 a, b = b, a+b 7 8 list(fibonacci(5))

今天的内容就先整理这么多, 后期会把列表中的一些实用操作都整理到一块来, 便于学习和查找。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号