
kafka简介
消息队列通信的两种模式:
一、点对点模式
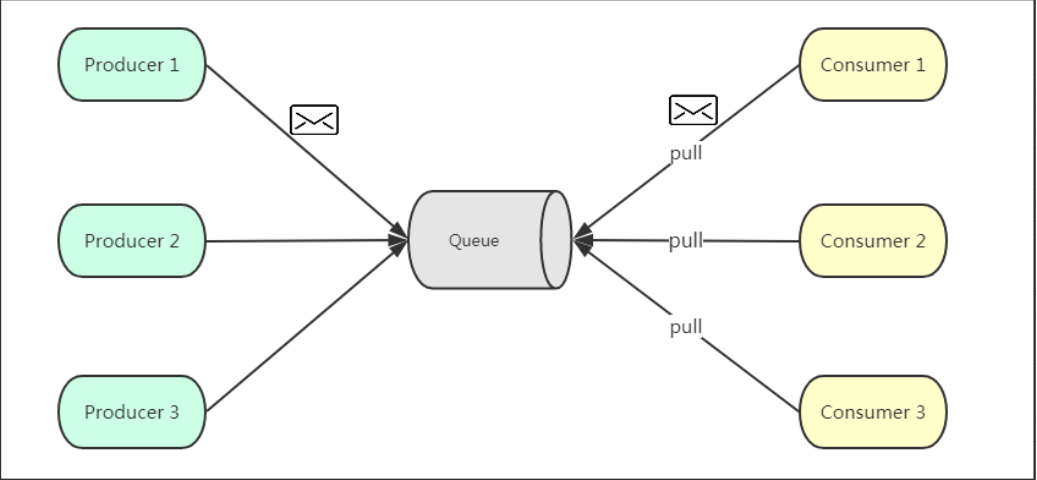
点对点模式通常是基于拉取或者轮询的消息传送模型,这个模型的特点是发送到队列的消息被一个且只有一个消费者进行处理。生产者将消息放入消息队列后,由消费者主动的去拉取消息进行消费。点对点模型的的优点是消费者拉取消息的频率可以由自己控制。但是消息队列是否有消息需要消费,在消费者端无法感知,所以在消费者端需要额外的线程去监控。
二、发布订阅模式:
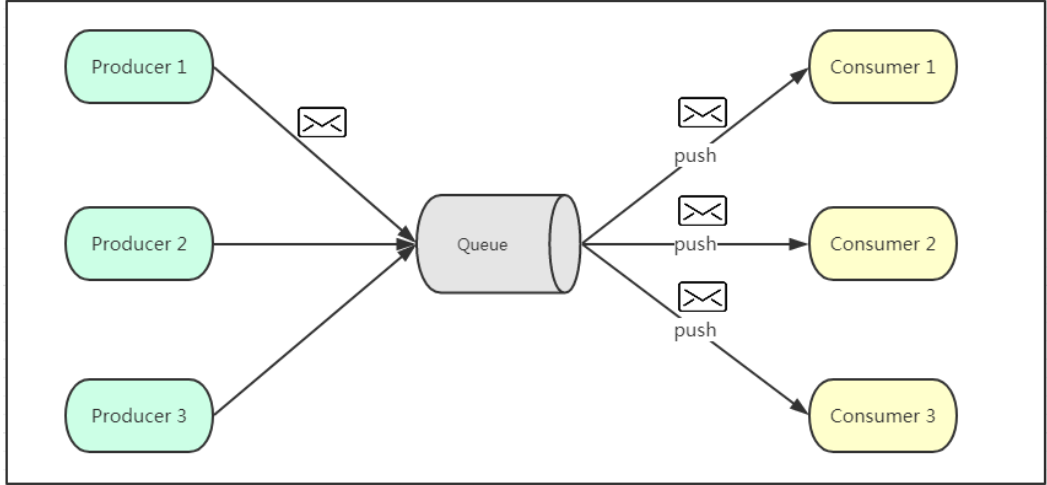
如上图所示,发布订阅模式是一个基于消息传送的消息传送模型,该模型可以有多种不同的订阅者。生产者将消息放入消息队列后,队列会将消息推送给订阅过该类消息的消费者(类似微信公众号)。由于是消费者被动接收推送,所以无需感知消息队列是否有待消费的消息!但是consumer1、consumer2、consumer3由于机器性能不一样,所以处理消息的能力也会不一样,但消息队列却无法感知消费者消费的速度!所以推送的速度成了发布订阅模模式的一个问题!假设三个消费者处理速度分别是8M/s、5M/s、2M/s,如果队列推送的速度为5M/s,则consumer3无法承受!如果队列推送的速度为2M/s,则consumer1、consumer2会出现资源的极大浪费!
Kafka
kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模网站中的所有动作流数据,具有高性能、持久化、多副本复用、横向扩展能力...
基础架构图
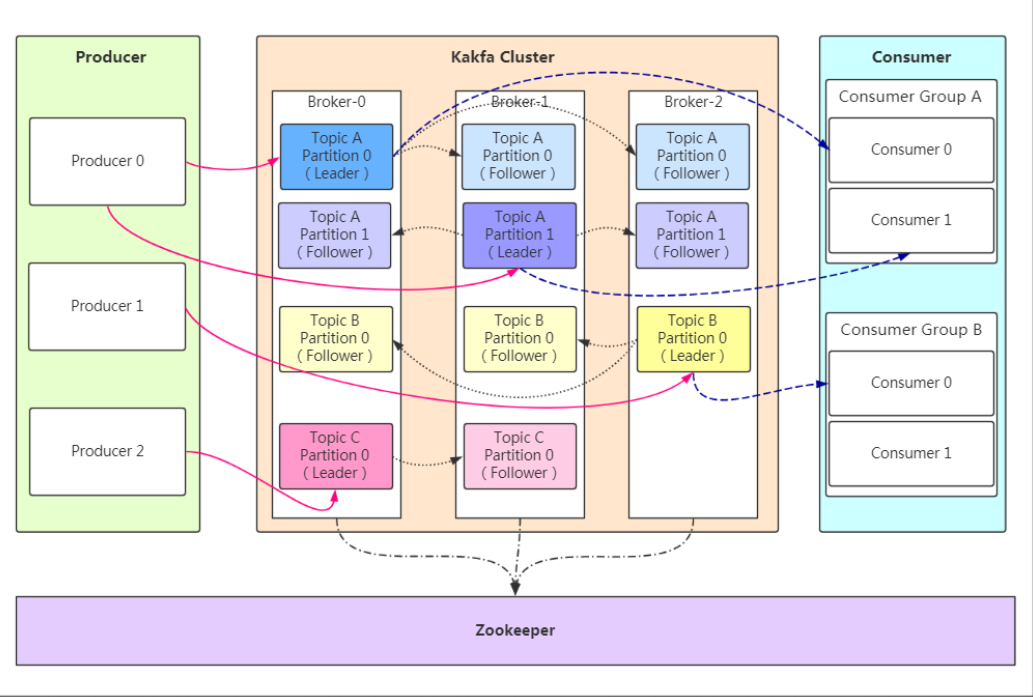
Producer: Producer即生产者,消息的生产者,是消息的入口。
kafka cluster:
Broker:Broker是kafka实例,每个服务器上有一个或者多个kafka的实例,我们姑且认为每个broker对应一台服务器,每个kafka集群内的broker都有一个不重复的编号,如图中的broker-0、broker-1等。。。
Topic:消息的主题,可以理解为消息的分类,kafka的数据就保存在topic,在每个broker上都可以创建多个topic。
Partition:Topic的分区,每个topic可以有多个分区,分区的作用是做负载,提高kafka的吞吐量,同一个topic在不同的分区的数据是不重复的,partition的表现形式就是一个一个的文件夹。
Replication:每一个分区都有多个副本,副本的作用是做备胎,但主分区(Leader)故障的时候会选择一个备胎(Follower)上位。成为Leader
在kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量。follower和leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本(包括自己)
message:每一条发送的消息主体
Consumer:消费者,即消息的消费方,是消息的出口
ConsumerGroup:我们可以将多个消费者组成一个消费者组,在kafka的设计中同一个分区的数据只能被消费者组中的某一个消费者消费,同一个消费者组的消费者可以消费同一个topic的不同分区的数据,这也是为了提高kafka的吞吐量。
Zookeeper: kafka集群依赖zookeeper来保存集群的元信息,来保证系统的可用性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号