
插入排序、简单选择排序、堆选择排序、交换排序之冒泡
排序算法的稳定性与适应性
稳定性:评判一个排序算法是否稳定,在于给定一个排序序列K时,其中存在关键码相等的两个或多个值,比如Ki与Kj的关键码相等,在K中Ki排列在Kj之前,那么排序结束后,保证Ki仍然排序在Kj之前,就称此算法为稳定的。
适应性:评判一个排序算法是否具有适应性,在于给定一个排序序列K时,将随着K的自身序列的好坏情况,算法的复杂度随着变化,比如K已经是一个接近于排序好的序列,那么算法就应该工作的更快,这时就称为此算法具有适应性。
稳定的与不稳定的排序算法分类
具有稳定性的:插入排序、冒泡排序、归并排序、基数排序、桶排序
不具备稳定性的:简单选择排序、堆选择排序、快速排序
插入排序
插入排序的思想:给定一个列表L,以列表中的首元素(一般是首元素)维护一个有序的序列S,从列表L的第二个元素开始,与S中的元素进行比较,找到插入的位置,不断维持S的有序,直到列表遍历结束。
插入排序的性能:好的情况下,算法的复杂度为O(n),坏的情况下,算法的复杂度为O(n^2)
稳定性与适应性:插入排序的算法具有稳定性(一般情况下,除非修改算法使得不具备稳定性)与适应性。稳定性:当L中元素与S中元素比较时,在发现有相同的key元素时,将不会移动元素,保持元素原有的顺序;适应性:如上述描述插入算法的性能可看出,好的坏的情况下,算法的性能是不同的,这就是适应性的表现。
插入排序的Python代码实现
点击查看代码
def insert_sort(self, lst):
"""
插入排序:不断把一个个元素插入一个序列中,最终得到排序序列
:param lst: 需要排序的列表
:return:
"""
# 遍历列表元素,从第二个元素开始,第一个元素自身已经是排序好的序列了
for i in range(1, len(lst)):
# 找到新元素的插入位置,如果需要后移元素,则循环后移
x = lst[i]
j = i
# 将已经排序好的序列的元素,逐个往后比较,大于当前元素的key的都往后移动一位,
# 将坑位让出来,直到找到小于当前元素的key时停止,这时待插入元素的坑就构造出来了
while j > 0 and lst[j-1].key > x.key:
lst[j] = lst[j-1]
j = j - 1
# 将当前元素插入具体的坑位
lst[j] = x
简单选择排序
简单选择排序的思想:
1、维护需要考虑的所有记录中最小的i个元素的有序序列
2、每次从剩余未排序的记录中选择一个关键码最小的元素,将其放在1中的有序序列的后面,作为序列的i+1个记录
3、以空序列作为排序工作的开始,作为尚未排序的序列里只剩一个元素时,放在1中的有序序列后面,则排序结束
简单选择排序的性能:任何情况下,算法的复杂度为O(n^2)
稳定性与适应性:稳定性:不稳定,比如(5 8 5 2 3)的序列,在第一次选择时,2是最小元素,会被选择,于是会将2替换到第一个5的位置,变成(2 8 5 5 3),但此时相同的key之间的原始顺序就被改变了,第一个元素5排在了第三个元素5后面,破坏了稳定性;适应性:同上面性能,不具备适应性。
直接选择排序的Python代码实现
点击查看代码
def select_sort(self, lst):
"""
选择排序:不断取出lst中的最小元素,然后顺序插入一个序列中即可
:param lst:
:return:
"""
for i in range(len(lst) - 1):
# 1 取出序列中的最小元素
min_index = i
for j in range(i, len(lst)):
if lst[j].key < lst[min_index].key:
min_index = j
# 2 将最小元素与当前i位置的元素调换
if i != min_index:
temp_e = lst[i]
lst[i] = lst[min_index]
lst[min_index] = temp_e
堆选择排序
堆选择排序与简单选择排序都是选择排序,选择排序就是在待排序列表中,逐步选择最小或最大的元素,然后顺序放入一个序列中,这是选择排序的统一思路。堆排序与简单选择的不同在于堆排序构建的是一个树形结构,此树形结构为小顶堆或大顶堆,小顶堆:根结点元素的关键码不大于其左右子树,其左右子树亦是如此。其树顶元素是所有结点中最小元素。大顶堆:根结点元素的关键码不小于其左右子树,其左右子树亦是如此。其树顶元素是所有结点中最大元素。堆排序利用每次弹出堆顶元素,并重新构造大或小顶堆即可从大到小或从小到大对列表排序。
堆选择排序的思想(同简单选择排序):
1、维护需要考虑的所有记录中最小的i个元素的有序序列
2、每次弹出堆顶元素并重新构造堆,将其放在1中的有序序列的后面,作为序列的i+1个记录
3、以空序列作为排序工作的开始,作为尚未排序的序列里只剩一个元素时,放在1中的有序序列后面,则排序结束
堆选择排序的性能:任何情况下,算法的时间复杂度为O(nlogn)
稳定性与适应性:
稳定性:如下图,堆排序在将尾端元素推入堆顶,做向下筛选时,会将元素原有的顺序改变,于是不具备稳定性。
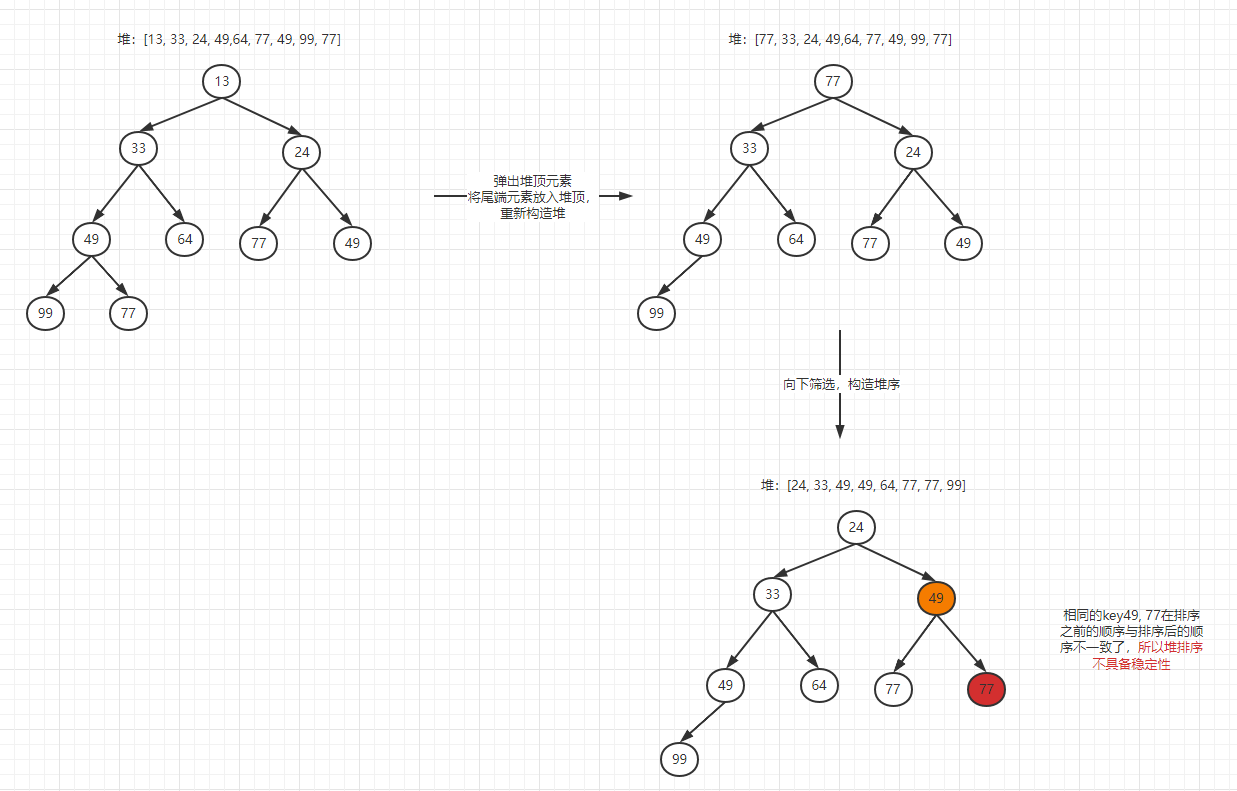
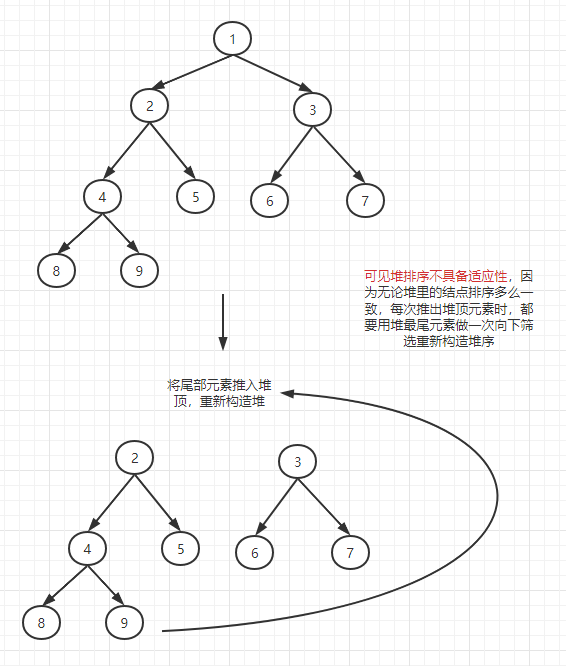
适应性:如下图,堆排序不具备适应性,在排序过程中,每次都是向下筛选的过程。
堆选择排序的Python代码实现
点击查看代码
def heap_sort(self, lst):
"""
堆排序:不停弹出堆顶元素,直至堆中只剩一个元素为止
:param lst:
:return:
"""
sorted_lst = []
while len(lst) > 1:
e0 = lst[0]
sorted_lst.append(e0)
e = lst.pop()
self.siftdown(lst, e, 0, len(lst))
# 当lst只剩一个元素时,将此元素直接放入排序序列中,堆排序结束
sorted_lst.append(lst[0])
return sorted_lst
def siftdown(self, lst, e, begin, end):
"""
重新构造堆, e为堆尾元素,或者称为数组尾端元素,当从堆顶推出一个元素后,将堆尾元素推到堆顶,然后重新构造堆
:param lst: 堆序数组
:param e: 堆尾元素
:param begin: 向下筛选时的起始位置,(此位置为初始坑位,默认不存在元素)
:param end: 向下筛选时的截止位置
:return:
"""
# 从坑位开始,比较坑位的孩子结点,将最小的一个放入坑位,如果当前e为最小,则函数结束,工作完成
i, j = begin, begin * 2 + 1
# 比较的时候需要判断j是否已经超过了范围,范围截止点为‘end’
while j < end:
# 如果存在j+1,或者说如果存在右子结点,那么右子结点也需要在end范围内
if j + 1 < end and lst[j + 1] < lst[j]:
j = j + 1
# 将e与j、j+1中最小的进行比较,如果e为最小,则比较结束,工作完成
if e < lst[j]:
break
# 如果e不为最小,则将j、j+1中最小的放入当前坑位
lst[i] = lst[j]
# 继续往下找e的坑位,更新新的坑位
i, j = j, j * 2 + 1
# 循环结束,找到e的坑位了,将e的值填进坑位
lst[i] = e
交换排序之冒泡排序
交换排序最典型的排序算法就是:冒泡排序,冒泡这个词形象上的描述了此算法的操作过程,在不停的对比元素中,就好像一个个浮起的水泡。
交换排序的思想:存在一个待排序序列,在遍历序列的过程中,不断交换逆序的序列,直至序列中不存在逆序的序列为止。
冒泡排序的性能:好的情况下,算法的复杂度为O(n),坏的情况下,算法的复杂度为O(n^2)
稳定性与适应性:冒泡排序的算法具有稳定性(取决于算法中相等key的元素不进行交换)与适应性。稳定性:不断交换逆序序列,当发现相同key时不交换元素;适应性:如上述描述冒泡算法的性能可看出,好的坏的情况下,算法的性能是不同的,这就是适应性的表现。
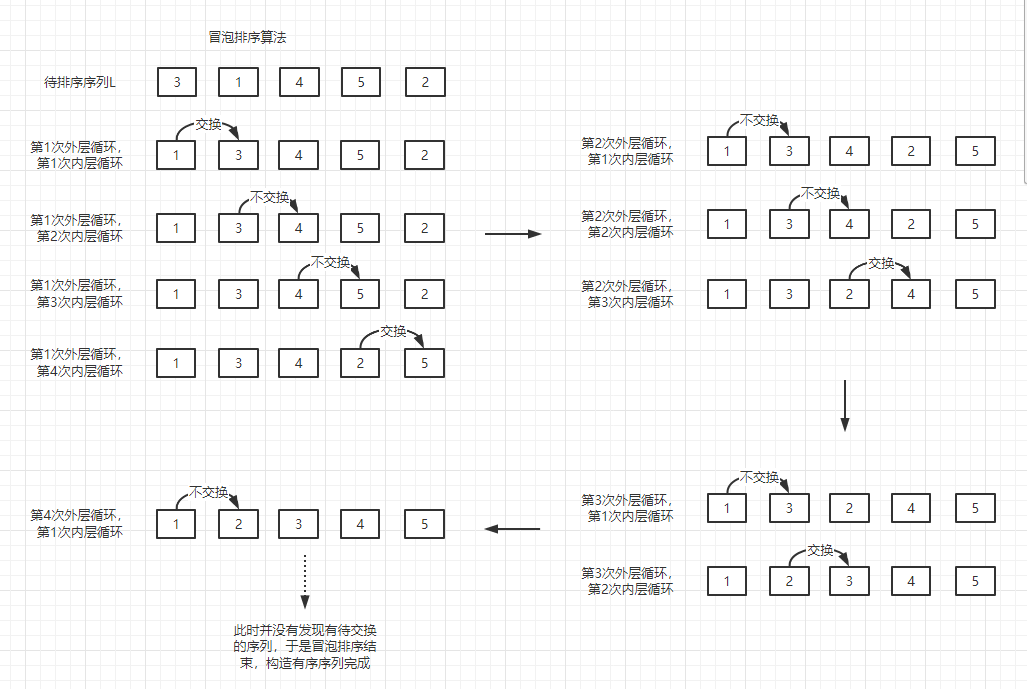
下图为冒泡排序算法过程简析,可发现如果小元素在末尾,排序过程将会复杂,因为每次只能将小元素往首部移动一位。此过程中每次外层循环都会将列表中的较大值推到列表的尾部。
冒泡排序的Python代码实现
点击查看代码
def bubble_sort(self, lst):
"""
冒泡排序:不停交换存在逆序的序列,直至lst中不存在逆序序列为止
:param lst:
:return:
"""
# 需要循环len(lst)次
for i in range(len(lst)):
# 定义一个标志,如果在内层循环中,
# 没有发现有逆序的情况,那么此序列已经排好序了
found = False
# 每次循环中,都在不停的比较并交换
for j in range(1, len(lst)-i):
# 从下标1开始比较,下标0的首元素不用比较,
# 且每次循环后,都能将最大的一个元素交换到序列末尾,
# 于是内层比较次数每次都会减少=len(lst)-i
if lst[j-1].key > lst[j].key:
temp = lst[j-1]
lst[j-1] = lst[j]
lst[j] = temp
found = True
if not found:
break
总结
1、排序算法有稳定性与适应性的区分,具体此算法是否具有稳定性或适应性跟算法本身没有关系,跟算法的实现有关系。
2、插入排序算法记忆方式,插入这词代表了算法的操作过程,维护一个有序序列,以首元素开始,然后遍历列表与当前有序序列进行比较,找到合适的坑位并插入。插入排序用待排序列表L去不停的完善新的有序列表K,将L中元素找到K中坑位后插入,直到L中不存在元素为止,此时K也成为了一个有序列表。
3、简单选择排序,关键词——>“选择”,选择排序在于从待排序列表L中选择一个最大或最小元素加入新的列表K,不断重复此过程,直至L中已无元素。简单选择排序为了节省空间使用,直接在L中维护已排序序列K,核心在于如果在某个下标j中找到了最小元素,那么将会交换len(K)+1下标与j下标的元素,此种方式可称为“坑位交换”。
4、堆选择排序,用树形结构来实现的排序算法,算法实现复杂,但是效率很高,缺点就是不具备稳定性与适应性。之所以也称为“选择”排序,此算法也是在不停的从待排序列表L中选择一个最大或最小元素加入新的列表K,不断重复此过程,直至L中已无元素。
5、交换排序之冒泡排序,关键词——>“冒泡”或“交换”,冒泡这个词是更形象的表述,此算法效率比较低,适合使用在一些小记录都在序列首部的待排序序列中。对于小记录在序列尾部的一些列表,可以使用“双向冒泡”的方式来进行优化冒泡排序算法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号