datax大数据了同步工具
安装插件datax wget http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
需要基础环境
jdk8以上
python2或者3
1.数据量少推荐使用streamset 界面化 配置简单
配置数据源和写入渊和源数据表和写入表即可,之间的字段关系streamsets自动匹配,区分大小写。
2.最近做OTC项目 底层的一些资料需要同步 涉及量比较大 目前最多一次是1.3亿,同步只能在晚上同步 用streamset同步耗时在15小时左右。
服务器配置64g内存。单线程单task所以比较慢。
每个工具都有适用的场景。
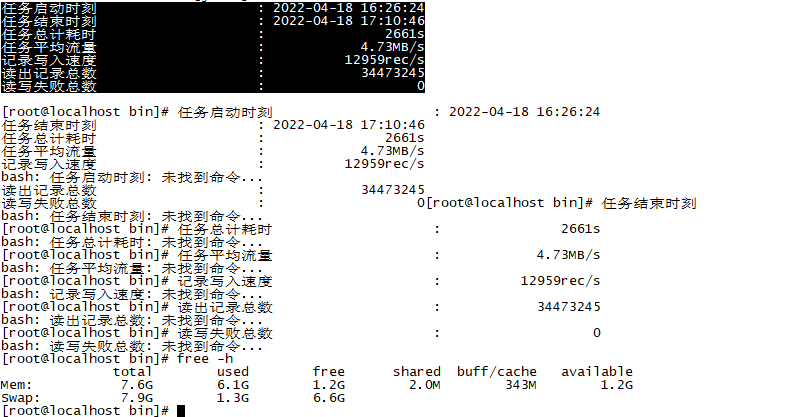
这个是我在我们公司服务器做的测试结果,执行任务的时候没有加内存配置,应该服务器硬件算是低了了。虽然是8G可是可用内存也就没多少。
可以看到效果还是可观的。3400万在44分钟。如果部署到64内存,启动任务再配置8G内存,速度应该可以在半小时内。
{ "job": { "content": [ { "reader": { "name": "sqlserverreader", "parameter": { "connection": [ { "jdbcUrl": ["jdbc:sqlserver://ip;DatabaseName=JNJ_SelfCare_Test"], "querySql": ["select * from T_JNJ_SalesData_RPD_Month"] } ], "password": "", "username": "" } }, "writer": { "name": "sqlserverwriter", "parameter": { "column": ["*"], "connection": [ { "jdbcUrl": "jdbc:sqlserver://ip;DatabaseName=JNJ_SelfCare_Test", "table": ["T_JNJ_SalesData_RPD_Month_0418"] } ], "password": "", "username": "" } } } ], "setting": { "speed": { "channel": "30" } } } }
上面是配置SqlServer到SqlServer同步的配置文件
执行任务
python datax.py ../job/sqlserverTosqlserver.json

 浙公网安备 33010602011771号
浙公网安备 33010602011771号