mysql事务总结
面试官上来就问MySQL事物,瑟瑟发抖...
什么是事务
事物是独立的工作单元,在这个独立工作单元中所有操作要么全部成功,要么全部失败。
也就是说如果有任何一条语句因为崩溃或者其它原因导致执行失败,那么未执行的语句都不会再执行,已经执行的语句会进行回滚操作,这个过程被称之为事务。
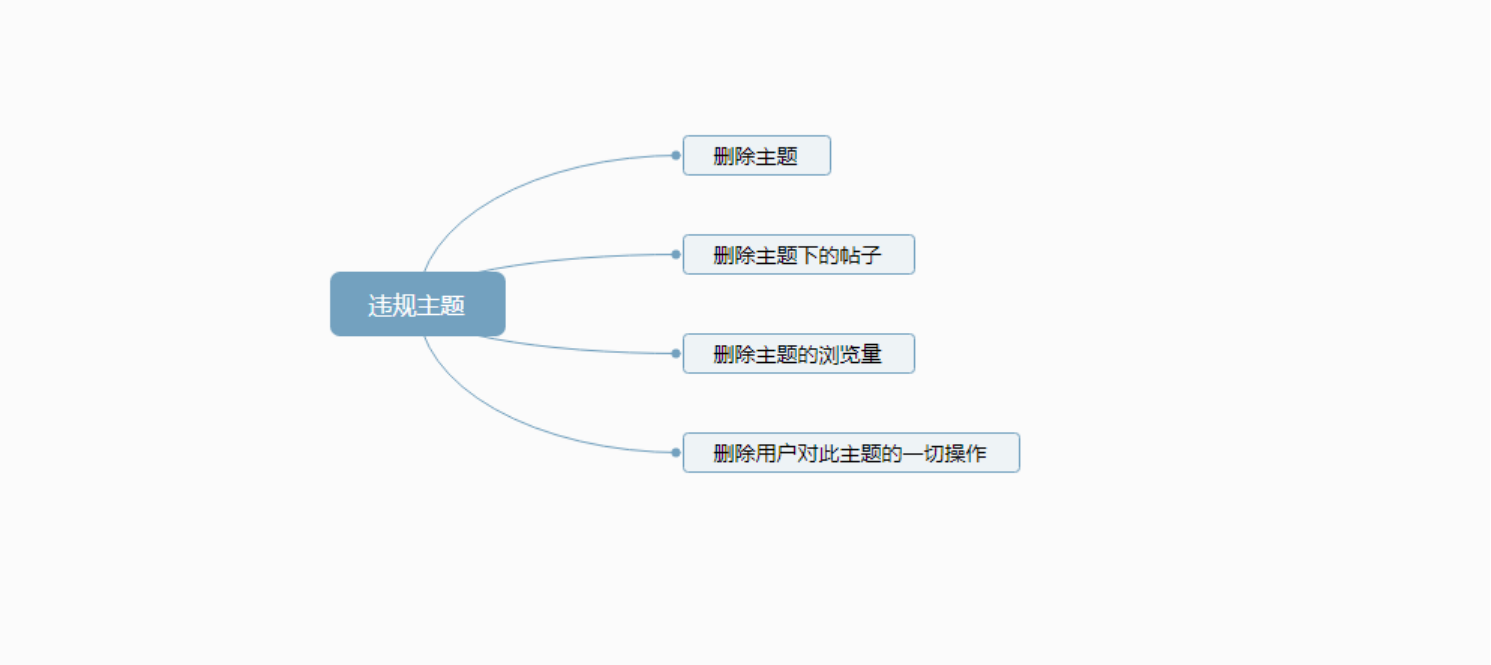
例:最近在写一个论坛系统,当发布的主题被其它用户举报后,后台会对举报内容进行审核。
一经审核为违规主题,则进行删除主题的操作,但不仅仅要删除主题还要删除主题下的帖子、浏览量,关于这个主题的一切信息都需要进行清理。
删除流程如下,用上边概念来说,以下执行的四个流程,每个流程都必须成功否则事务回滚返回删除失败。
假设执行到了第三步后 SQL 执行失败了,那么第一二步都会进行回滚,第四步则不会在执行。
事务四大特征
事物的四大特征:
-
**原子性
**
-
**一致性
**
-
**隔离性
**
-
持久性
①原子性
事务中所有操作要么全部成功,要么全部失败,不会存在一部分成功,一部分失败。
这个概念也是事物最核心的特性,事务概念本身就是使用原子性进行定义的。
原子性的实现是基于回滚日志实现(undo log),当事物需要回滚时就会调用回滚日志进行 SQL 语句回滚操作,实现数据还原。
②一致性
一致性,字面意思就是前后一致呗!在数据库中不管进行任何操作,都是从一个一致性转移到另一个一致性。
当事物结束后,数据库的完整性约束不被破坏。当你了解完事物的四大特征之后就会发现,都是保证数据一致性为最终目标存在的。
在学习事物的过程中大家看到最多的案例就是转账,假设用户 A 与用户 B 余额共计 1000,那么不管怎么转俩人的余额自始至终也就只有 1000。
③隔离性
保证事务执行尽可能的不受其它事物影响,这个是隔离级别可以自行设置,在 innodb 中默认的隔离级别为可重复读(Repeatable Read)。
这种隔离级别有可能造成的问题就是出现幻读,但是使用间隙锁可以解决幻读问题。
学习了隔离性你需要知道原子性和持久性是针对单个事务,而隔离性是针对事物与事物之间的关系。
④持久性
持久性是指当事务提交之后,数据的状态就是永久的,不会因为系统崩溃而丢失。事物持久性是基于重做日志(redo log)实现的。
事务并发会出现的问题
①脏读
读取了另一个事务没有提交的数据。
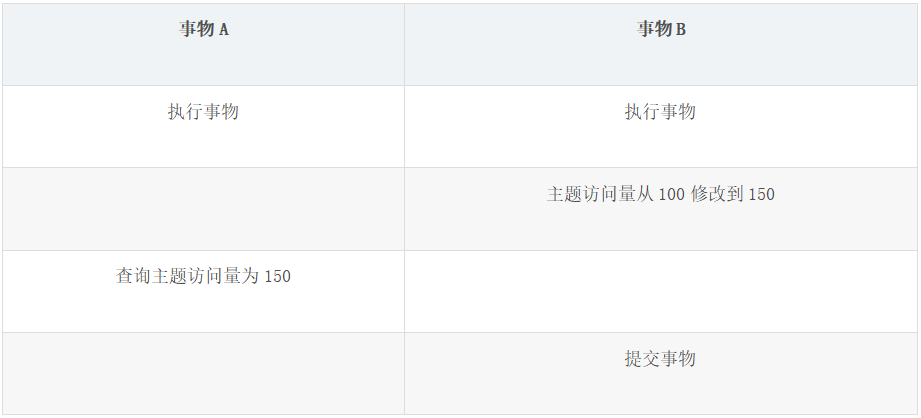
以上表为例,事物 A 读取主题访问量时读取到了事物B没有提交的数据 150。
如果事物 B 失败进行回滚,那么修改后的值还是会回到 100。然而事物 A 获取的数据是修改后的数据,这就有问题了。
②不可重复读
事务读取同一个数据,返回结果先后不一致问题。
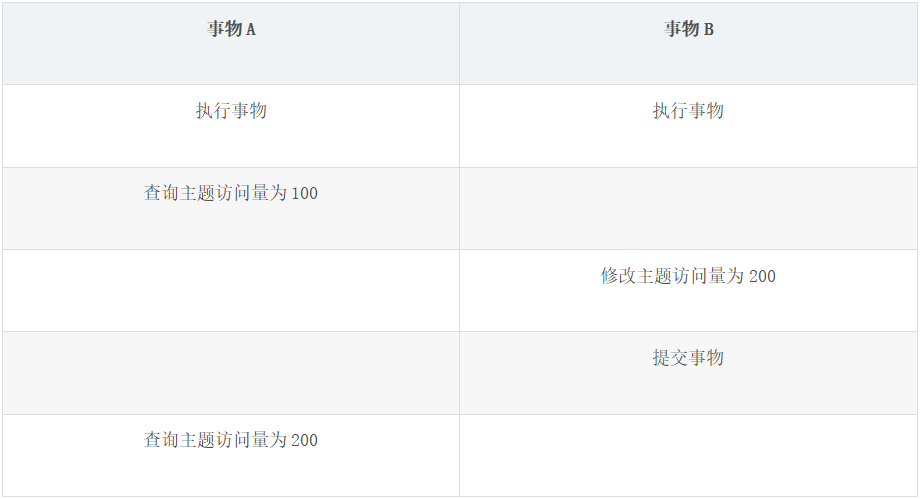
上表格中,事物 A 在先后获取主题访问量时,返回的数据不一致。也就是说在事物 A 执行的过程中,访问量被其它事物修改,那么事物 A 查询到的结果就是不可靠的。
脏读与不可重复读的区别:脏读读取的是另一个事物没有提交的数据,而不可重复读读取的是另一个事务已经提交的数据。
③幻读
事务按照范围查询,俩次返回结果不同。
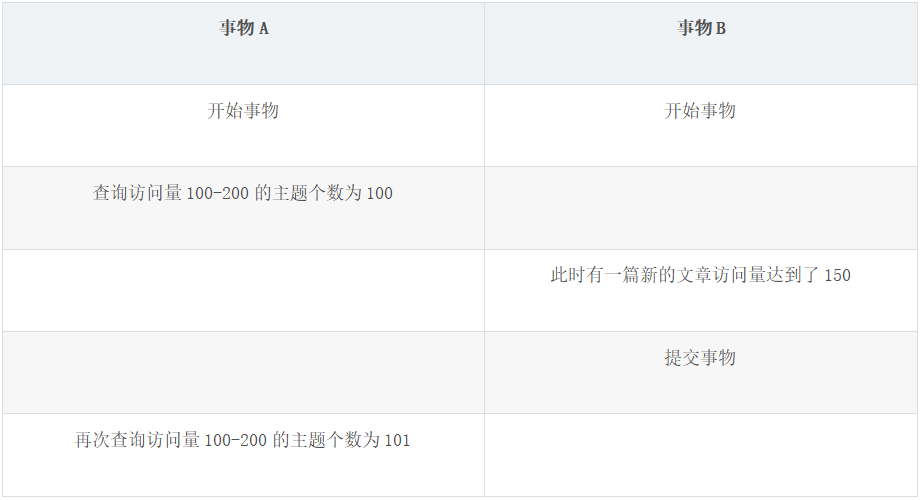
以上表为例,当对 100-200 访问量的主题做统计时,第一次找到了 100 个,第二次找到了 101 个。
④区别
脏读读取的是另一个事务没有提交的数据,而不可重复读读取的是另一个事物已经提交的数据。
幻读和不可重复读都是读取了另一条已经提交的事务(这点与脏读不同),所不同的是不可重复读查询的都是同一个数据项,而幻读针对的是一批数据整体(比如数据的个数)。
针对以上的三个问题,产生了四种隔离级别。在第二节中对隔离性进行了简单的概念解释,实际上的隔离性是很复杂的。
在 MySQL 中定义了四种隔离级别,分别为:
- 未提交读 (Read Uncommitted):俩个事物同时运行,有一个事物修改了数据,但未提交,另一个事物是可以读取到没有提交的数据。这种情况被称之为脏读。
- 提交读(Read committed):一个事物在未提交之前,所做的任何操作其它事物不可见。这种隔离级别也被称之为不可重复读。因为会存在俩次同样的查询,返回的数据可能会得到不一样的结果。
- 可重复读(Repeatable Read):这种隔离级别解决了脏读问题,但是还是存在幻读问题,这种隔离界别在 MySQL 的 innodb 引擎中是默认级别。MySQL 在解决幻读问题使用间隙锁来解决幻读问题。
- 可串行化 (Serializable):这种级别是最高的,强制事物进行串行执行,解决了可重复读的幻读问题。
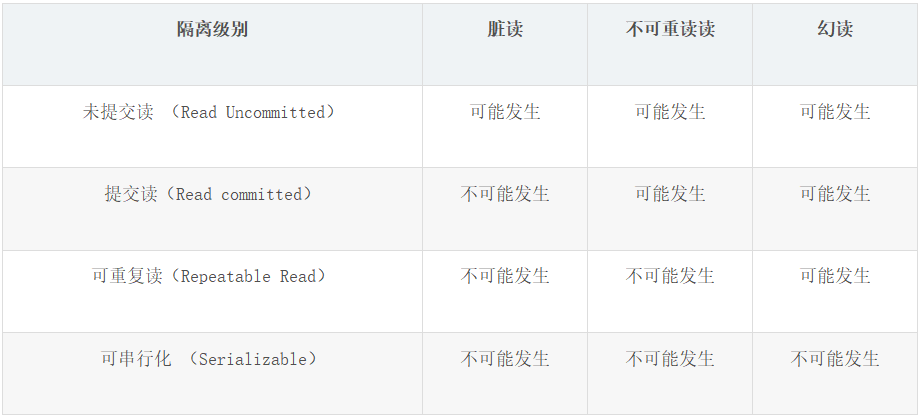
对于隔离级别,级别越高并发就越低,而级别越低会引发脏读、不可重复读、幻读的问题。
因此在 MySQL 中使用可重复读(Repeatable Read)作为默认级别。
作为默认级别是如何解决并处理相应问题的呢?那么针对这一问题,是一个难啃的骨头,我将在下一期 MVCC 文章专门来介绍这块。
事务日志以及事物异常如何应对
在 Innodb 中事物的日志分为俩种,回滚日志、重做日志。
先来看一下俩个日志的存放位置吧!MySQL 的版本号为 8.0。
在 Linux 下的 MySQL 事物日志存放在 /var/lib/mysql 这个位置中:
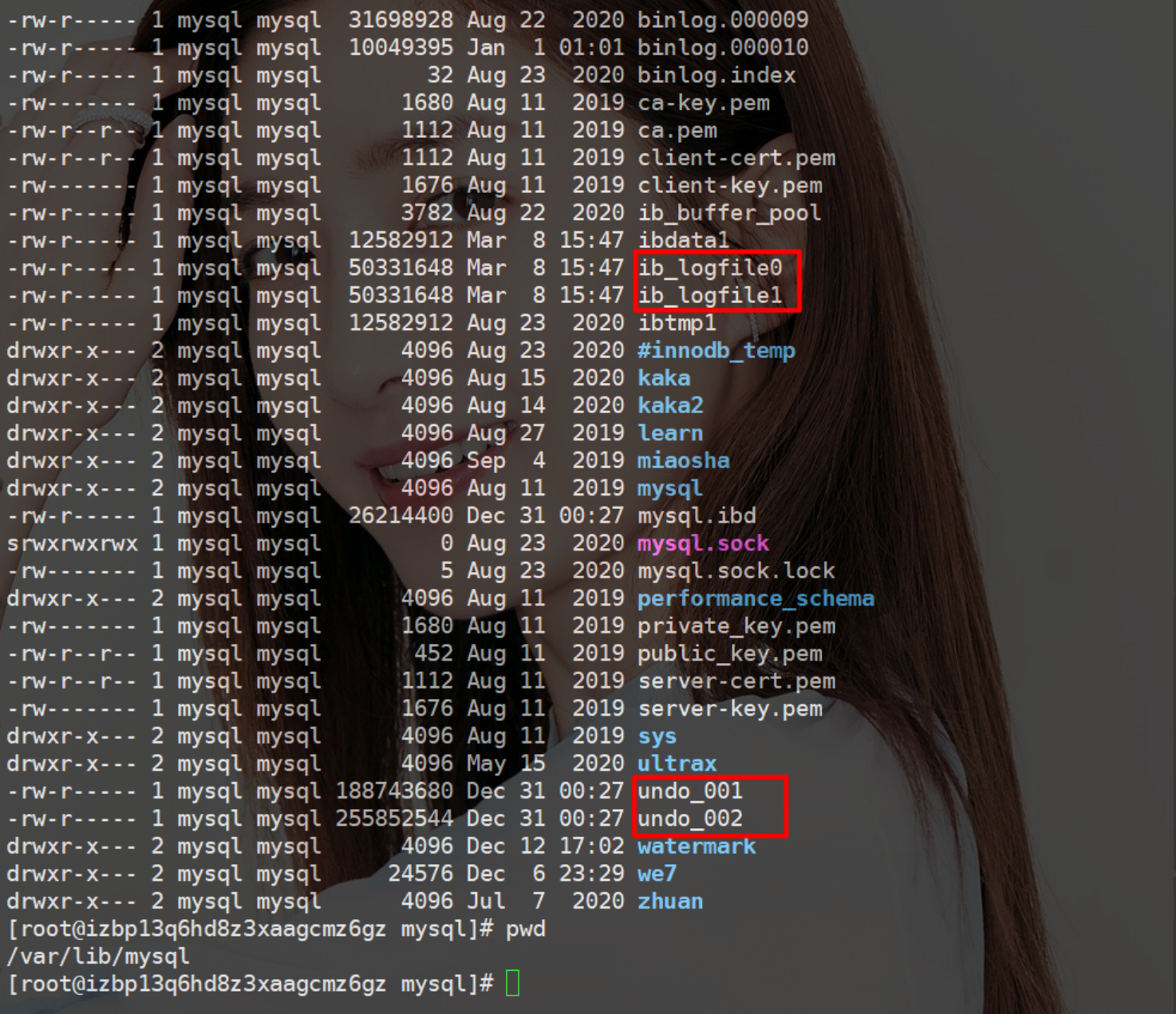
从上图中可以看到分别为 ib_logfile、undo_ 俩个文件:
- ib_logfile 文件为重做日志
- undo_ 文件为回滚日志
在这里估计有点小伙伴会有点迷糊这个回滚日志。那是因为在 MySQL 5.6 默认回滚日志没有进行独立表空间存储,而是存放到了 ibdata 文件中。
独立表空间存储从 MySQL 5.6 后就已经支持了,但是需要自行配置。
在 MySQL 8.0 是由 innodb_undo_tablespaces 这个参数来设置回滚日志独立空间个数,这个参数的范围为 0-128。
默认值为 0 表示不开启独立的回滚日志,且回滚日志存储在 ibdata 文件中。
这个参数是在初始化数据库时指定的,实例一旦创建这个参数是不能改动的。
如果设置的 innodb_undo_tablespaces 值大于实例创建时的个数,则会启动失败。
①重做日志(redo log)(持久性实现原理)
事物的持久性就是通过重做日志来实现的。
当提交事物之后,并不是直接修改数据库的数据的,而是先保证将相关的操作记录到 redo 日志中。
数据库会根据相应的机制将内存的中的脏页数据刷新到磁盘中。
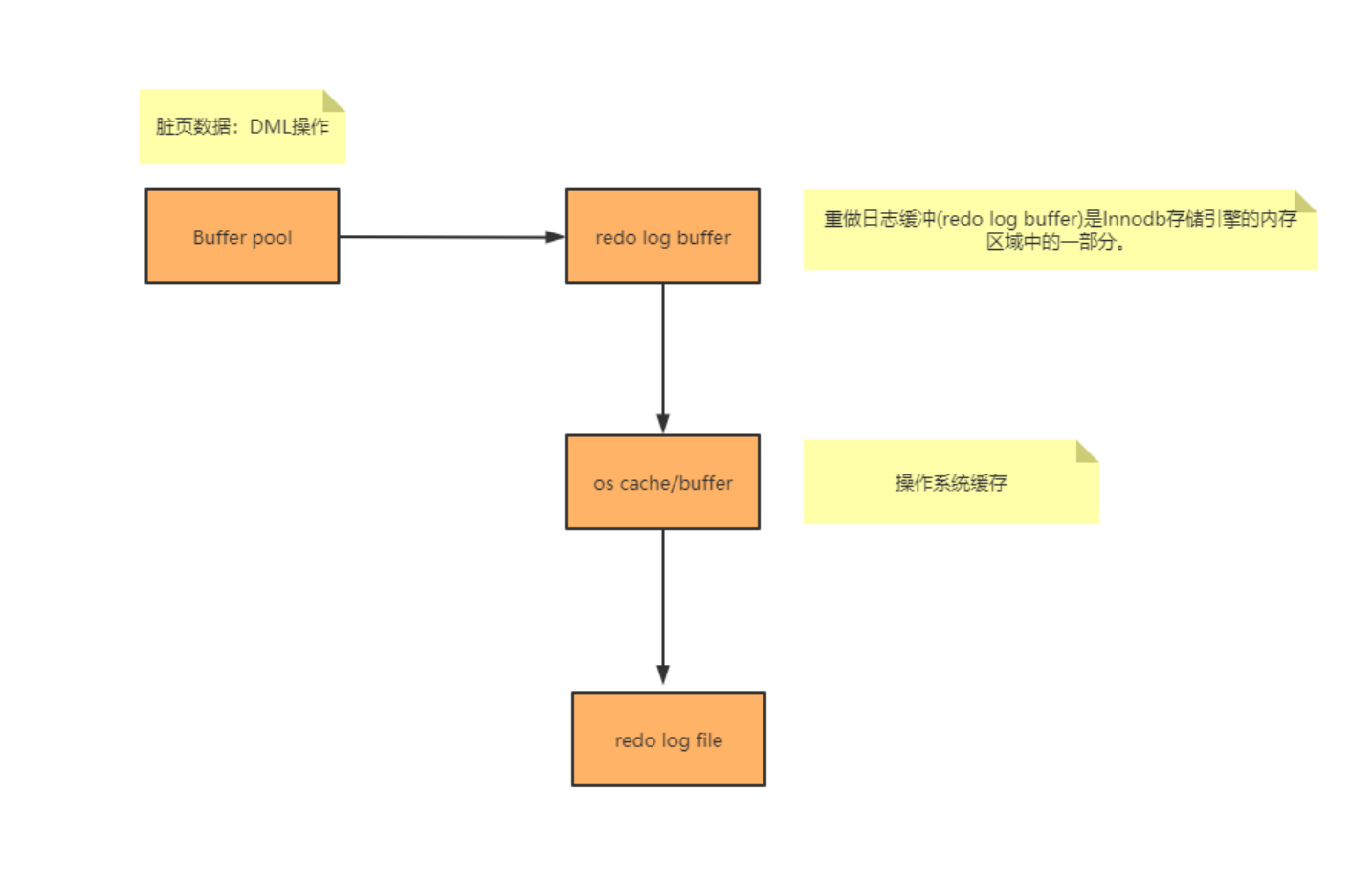
上图是一个简单的重做日志写入流程。
在上图中提到俩个陌生概念,Buffer pool、redo log buffer,这个俩个都是 Innodb 存储引擎的内存区域的一部分。
而 redo log file 是位于磁盘位置。也就说当有 DML(insert、update、delete)操作时,数据会先写入 Buffer pool,然后在写到重做日志缓冲区。
重做日志缓冲区会根据刷盘机制来进行写入重做日志中。
这个机制的设置参数为 innodb_flush_log_at_trx_commit,参数分别为 0,1,2。
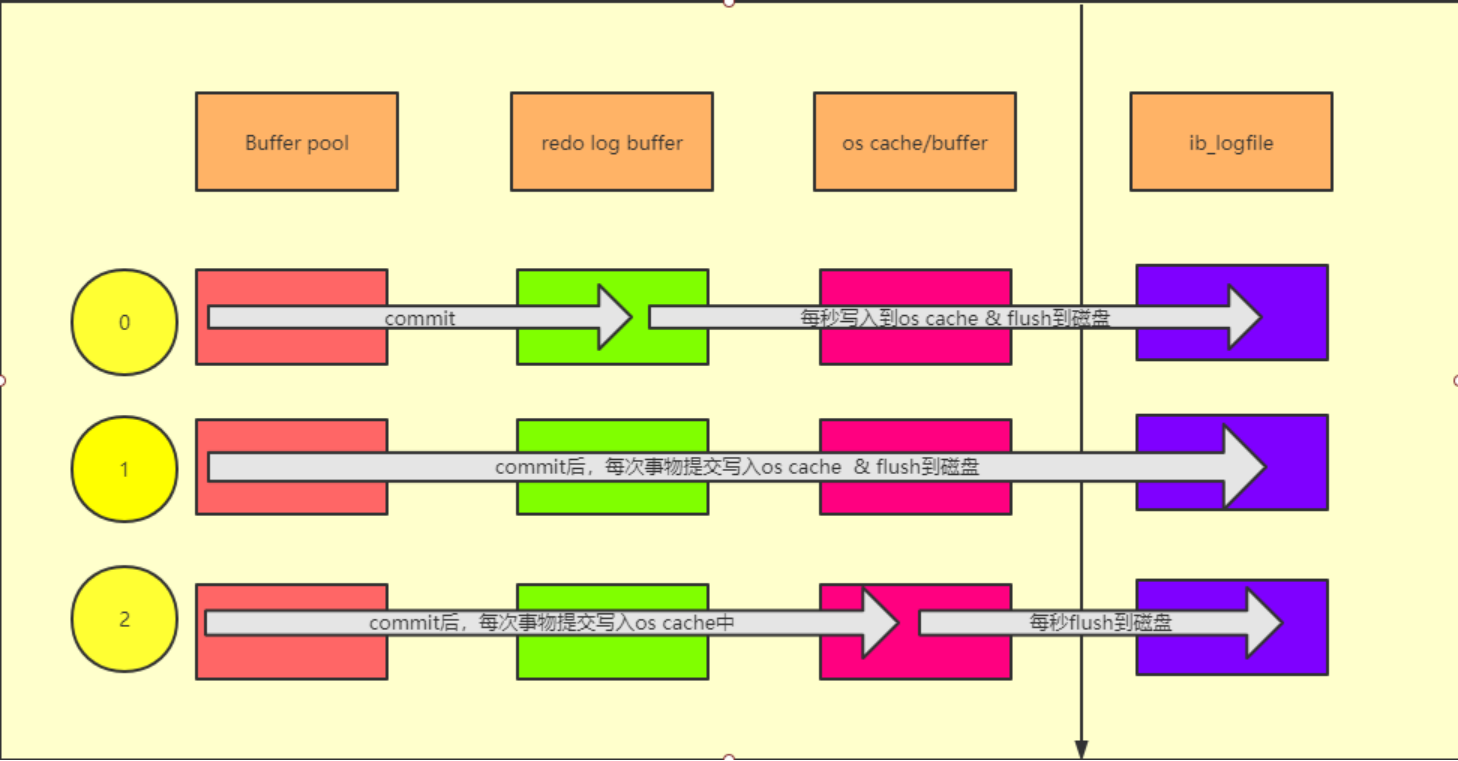
上图即为重做日志的写入策略:
- 当这个参数的值为 0 的时,提交事务之后,会把数据存放到 redo log buffer 中,然后每秒将数据写进磁盘文件。
- 当这个参数的值为 1 的时,提交事务之后,就必须把 redo log buffer 从内存刷入到磁盘文件里去,只要事务提交成功,那么 redo log 就必然在磁盘里了。
- 当这个参数的值为 2 的情况,提交事务之后,把 redo log buffer 日志写入磁盘文件对应的 os cache 缓存里去,而不是直接进入磁盘文件,1 秒后才会把 os cache 里的数据写入到磁盘文件里去。
②服务器异常停止对事物如何应对(事物写入过程)
事物写入过程如下:
- 当参数为 0 时,前一秒的日志都保存在日志缓冲区,也就是内存上,如果机器宕掉,可能丢失 1 秒的事务数据。
- 当参数为 1 时,数据库对 IO 的要求就非常高了,如果底层的硬件提供的 IOPS 比较差,那么 MySQL 数据库的并发很快就会由于硬件 IO 的问题而无法提升。
- 当参数为 2 时,数据是直接写进了 os cache 缓存,这部分属于操作系统部分,如果操作系统部分损坏或者断电的情况会丢失 1 秒内的事物数据,这种策略相对于第一种就安全了很多,并且对 IO 要求也没有那么高。
小结:
- 关于性能:0>2>1
- 关于安全:1>2>0
根据以上结论,所以说在 MySQL 数据库中,刷盘策略默认值为 1,保证事物提交之后,数据绝对不会丢失。
③回滚日志(undo log)(原子性实现原理)
回滚日志保证了事物的原子性。回滚日志相对重做日志来说没有那么复杂的流程。
当事物对数据库进行修改时,Innodb 引擎不仅会记录 redo log 日志,还会记录 undo log 日志。
如果事物失败,或者执行了 rollback,为了保证事物的原子性,就必须利用 undo log 日志来进行回滚操作。
回滚日志的存储形式如下:在 undo log 日志文件,事物中使用的每条 insert 都对应了一条 delete,每条 update 也都对应一条相反的 update 语句。
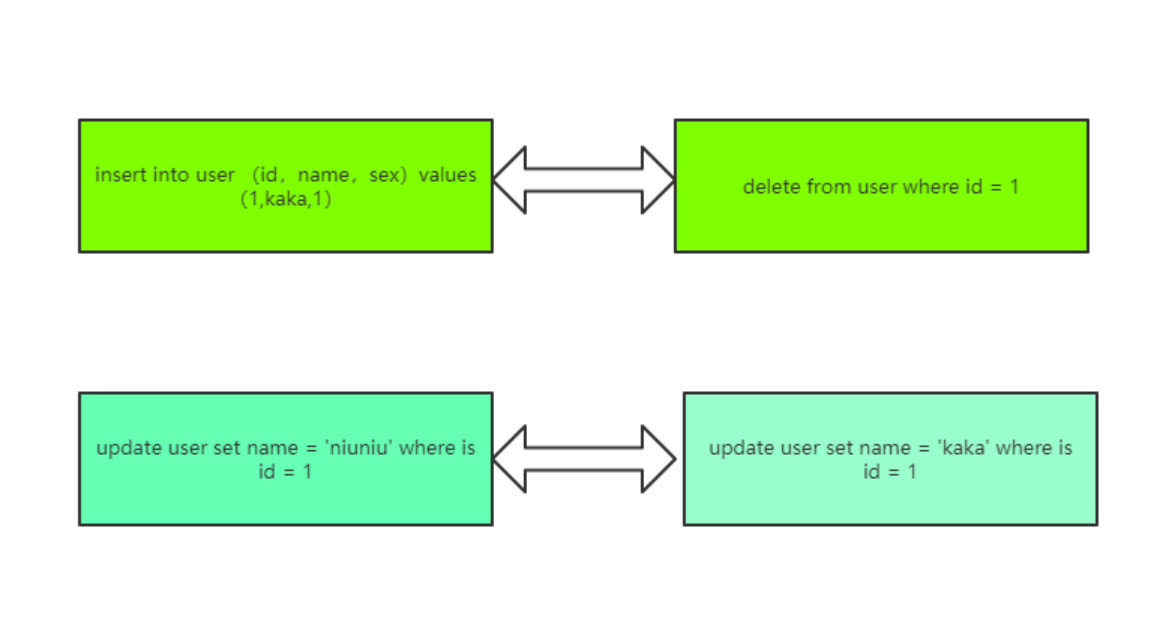
注意:系统发生宕机或者数据库进程直接被杀死。当用户再次启动数据库进程时,还能够立刻通过查询回滚日志将之前未完成的事物进程回滚。
这也就需要回滚日志必须先于数据持久化到磁盘上,是需要先写日志后写数据库的主要原因。回滚日志不仅仅可以保证事物的原子性,还是实现 mvcc 的重要因素。
以上就是关于事物的俩大日志,重做日志、回滚日志的理解。
锁机制
锁在 MySQL 中是是非常重要的一部分,锁对 MySQL 数据访问并发有着举足轻重的作用。
所以说锁的内容以及细节是十分繁琐的,本节只是对 Innodb 锁的一个大概整理。
MySQL中有三类锁,分别为行锁、表锁、页锁。首先需要明确的是这三类锁是是归属于那种存储引擎的:
- 行锁:Innodb 存储引擎
- 表锁:Myisam、MEMORY 存储引擎
- 页锁:BDB 存储引擎
①行锁
行锁又分为共享锁、排它锁,也被称之为读锁、写锁,Innodb 存储引擎的默认锁。
共享锁(S):假设一个事物对数据 A 加了共享锁(S),则这个事物只能读 A 的数据。
其他事物只能再对数据 A 添加共享锁(S),而不能添加排它锁(X),直到这个事物释放了数据 A 的共享锁(S)。
这就保证了其他事物也可以读取 A 的数据,但是在这个事物没有释放在 A 数据上的共享锁(S)之前不能对 A 做任何修改。
排它锁(X):假设一个事物对数据 A 添加了排它锁(X),则只允许这个事物读取和修改数据 A。
其他任何事物都不能在对数据A添加任何类型的锁,直至这个事物释放了数据 A 上的锁。
排它锁阻止其它事物获取相同数据的共享锁(S)、排它锁(X),直至释放排它锁(X)。
特点如下:
- 只针对单一数据进行加锁
- 开销大
- 加锁慢
- 会出现死锁
- 锁粒度最小,发生锁冲突的概率越低,并发越高
还记得在上文中提到的事物并发带来的问题、脏读、不可重读读、幻读。
学习到了这里,应该就明白可重复读(Repeatable Read)如何解决脏读、不可重读读了。
脏读、和不可重复读的解决方案很简单,写前加排它锁(X),事务结束才释放,读前加共享锁(S),事务结束就释放。
②表锁
表锁又分为表共享读锁、表独占写锁,也被称之为读锁、写锁,Myisam 存储引擎的默认锁。
表共享读锁:针对同一个份数据,可以同时读取互不影响,但不允许写操作。
表独占写锁:当写操作没有结束时,会阻塞所有读和写。
特点如下:
- 对整张表加锁
- 开销小
- 加锁快
- 无死锁
- 锁粒度最大,发生锁冲突的概率越大,并发越小
本文主要说明 Innodb 和 Myisam 的锁,页锁不就不做详细说明了。
③如何加锁
表锁:
- 隐式加锁:默认自动加锁释放锁,select 加读锁、update、insert、delete 加写锁。
- 手动加锁:lock table tableName read;(添加读锁)、lock table tableName write(添加写锁)。
- 手动解锁:unlock table tableName(释放单表)、unlock table(释放所有表)。
行锁:
- 隐式加锁:默认自动加锁释放锁,只有 select 不会加锁,update、insert、delete 加排它锁。
- 手动加共享锁:select id name from user lock in share mode。
- 手动加排它锁:select id name form user for update。
- 解锁:正常提交事物(commit)、事物回滚(rollback)、kill 进程。
总结
本文主要对事务的重点知识点进行解读,内容总结。
事物四大特征实现原理:
- 原子性:使用事务日志的回滚日志(undo log)实现
- 隔离性:使用 mvcc 实现(幻读问题除外)
- 持久性:使用事物日志的重做日志(redo log)实现
- 一致性:是事物追求的最终目标,原子性、隔离性、持久性都是为了保证数据库一致性而存在
事物并发出现问题的区别:
- 脏读与不可重复读的区别:脏读是读取没有提交事务的数据、不可重复读读取的是已提交事物的数据。
- 幻读与不可重复读的区别:都是读取的已提交事物的数据(与脏读不同),幻读针对的是一批数据,例如个数。不可重复读针对的是单一数据。
事物日志:
- 重做日志(redo log):实现了事务的持久性,提交事物后不是直接修改数据库,而是保证每次事物操作读写入 redo log 中。并且落盘会有三种策略(详细看四-1节)。
- 回滚日志(undo log):实现了事物的原子性,针对 DML 的操作,都会有记录相反的 DML 操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号