哔哩哔哩面试题1---系统相关
ISO/OSI的七层网络模型
ISO国际标准化组织
OSI开放系统互连
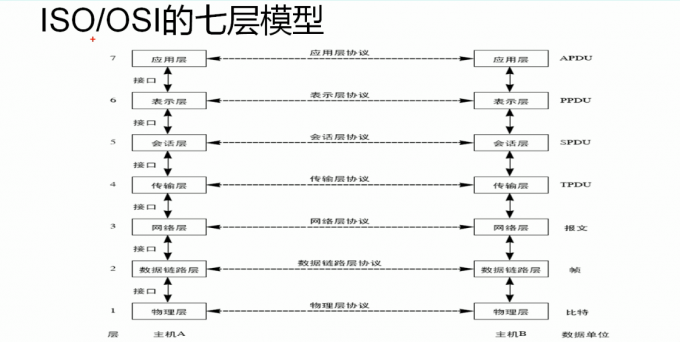
1.应用层
给用户提供一个操作界面
2.表示层
表示数据(0101)
加密(MD5sum)
压缩(tar、zip)
3.会话层
判断数据是否进行网络传递
4.传输层
对报文进行分组(发送时)、组装(接收时)
选择传输协议:
TCP(传输控制协议):可靠的,面向连接的传输协议(可靠准确,慢),相当于打电话
UDP(用户数据包协议):不可靠的、面向无连接的传输协议(不可靠,快),相当于发短信
端口封装(访问server的哪个端口,TCP或者UDP)
差错校验(数据包的发送有可能会出错)
5.网络层
ip地址编址(查找)
路由选择
静态路由,不需要路由器做任何运算,指定路由路径,但是配置复杂
动态路由,路由器自动选择路由路径(自动选择路由节点最少的路径),但是会消耗CPU
6.数据链路层
MAC地址编址
MAC地址寻址
差错校验
7.物理层
数据实际传输
硬件
#数据包
ipv4协议中,数据包的大小不能超过2*16字节,所以一条数据在传输层,对以上层的数据进行拆包,同理,server端接收的时候对数据包进行组装
#ip是全球唯一的
#ip地址与MAC地址
ip地址是用来不用网段的数据传输
MAC地址是用来相同网段的数据传输
在同一个广播域中,通过MAC地址通讯
不同网段的主机通讯,ip、MAC、端口号缺一不可(端口是用来区分不同的服务的)
#TCP与UDP
数据的传输基本使用的是TCP协议,一般考虑实时性的话才会选择UDP
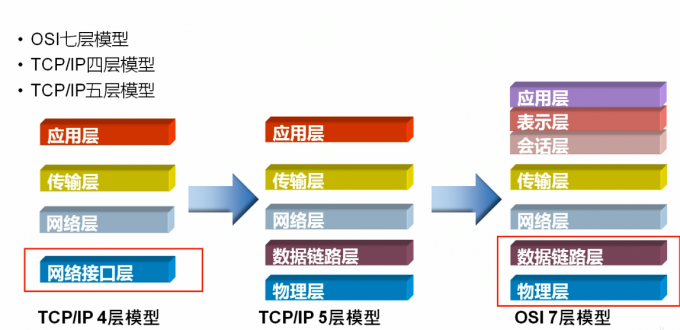
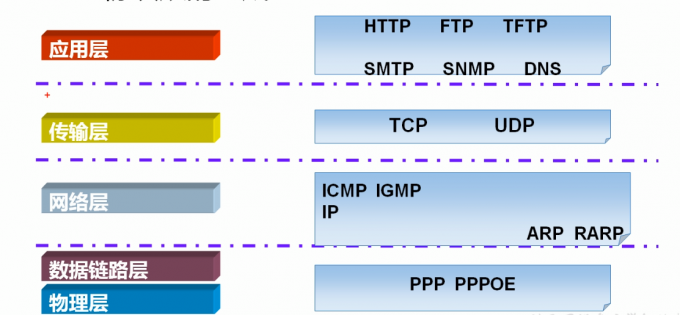
TCP/IP四层模型
TCP/IP协议族
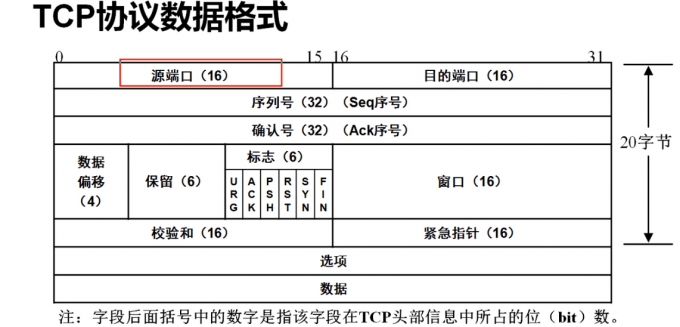
TCP包头内容
数据包的组成
1.断开
源端口随机生成
目的端口指定
2.要发送的序列号
3.要接收的确认号
4.标志信号
5.标志校验
6.可选
TCP三次握手
2**16 = 65535
#序号
seq序号,占32位二进制数,用来表示从TCP端向目的端发送的字节流,发起方发送数据时对此进行标记
#确认号
ACK序号 ,占32位二进制数,只有ACK标记为1时,确认序号才有效(ACK=seq+1)
#标志位
一共6个,即URG、ACK、ACK、PSH、RST、SYN、FIN等
URD:紧急指针有效
ACK:确认序号有效 #
PSH:接收方应该尽快将这个报文交给应用层
RST:重置连接
SYN:发起一个新连接 #
FIN:释放一个连接(断开连接) #
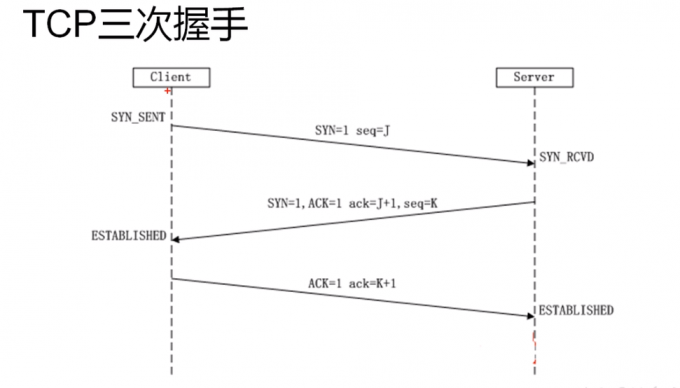
最后,通讯双方都进入established状态
TCP四次挥手
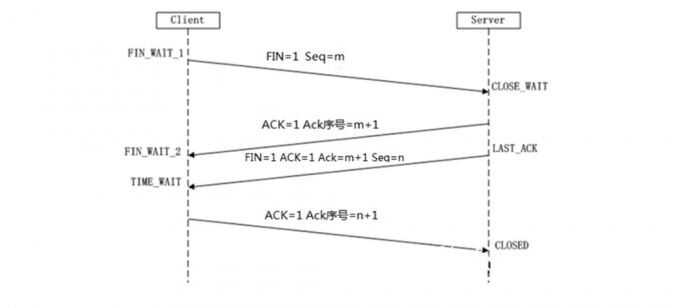
#可以针对 TIME_WAIT进行洪水攻击
网段、IP、广播地址
1.ip
确定网络位、主机位的ip才有意义
2.子网掩码
标准的表达方式,8、16、24 (表示二进制中子网掩码中1的个数)
网段表示,255.255.255.192
二进制表示方法,11111111.11111111.11111111.11000000
子网掩码的作用
1.ip和子网掩码同时表示才有意义,单独的ip和子网掩码没有任何意义(标准的子网表达方式可以省略(8/16/24))
2.子网掩码是用来给ip地址划分网络地址与主机地址的
3.和子网掩码1对应的ip地址,代表网络位,和子网掩码0对应的ip地址,代表主机位(二进制表示子网掩码)
4.子网中只要1是连续的,就是合理子网掩码
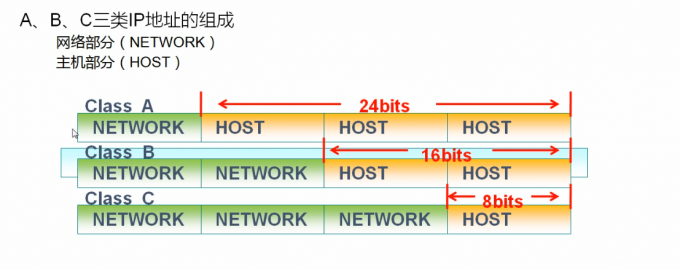
ABC三类ip地址的组成
#
10.0.0.0 - 10.0.0.255 一共256个ip地址,0代表网络本身,不能使用,255是广播地址,不能使用
根据子网掩码判断ip属于哪一类地址

1.子网掩码中,1必须是连续的,否则无意义

网络地址
ip 172.22.141.231 10101100.00010110.10001101.11100111
子网掩码 255.255.255.192 11111111.11111111.11111111.11000000
逻辑与运算 10101100.00010110.10001101.11000000
网络地址 172.22.141.192
广播地址
ip 172.22.141.231 10101100.00010110.10001101.11100111
子网掩码 255.255.255.192 11111111.11111111.11111111.11000000
#有效子网掩码,也就是0和1抢的那一段
公式运算 10101100.00010110.10001101.11111111
广播地址 172.22.141.255
画图理解计算公式

子网个数 2**2
主机个数 2**6 -2=62
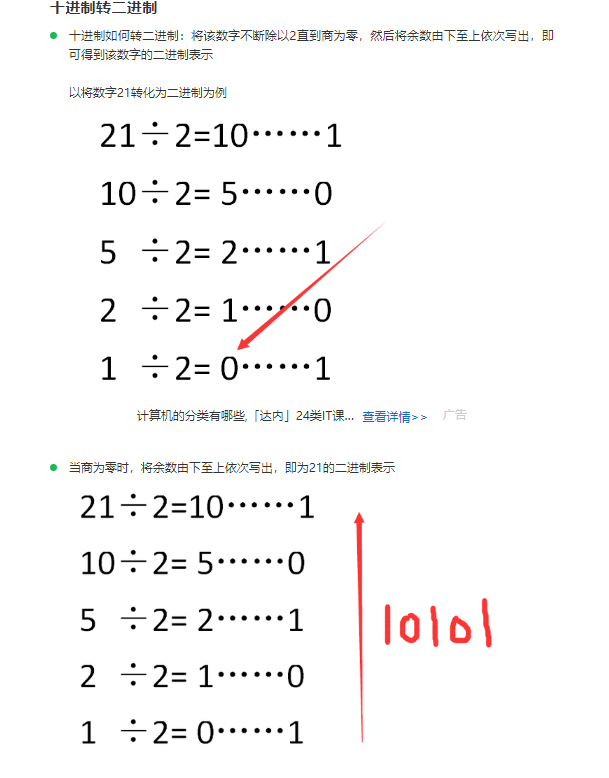
进制转换


私有ip免费使用
linux权限划分
文件基本权限
-rw-r--r-- 1 root root 247 Jun 30 03:48 xiugaizhuji.sh
#文件身份,属主属组
#文件权限
#目录权限
#权限分配
1.给文件或目录分配权限,先考虑属主和属组
2.遵循最小权限规则
3.注意递归授权目录,一般递归属主和属组
#特殊权限(SUID、SGID、SBIT)
1.特殊权限是为了让特定命令可以拥有足够的权限运行
2.SUID只针对可执行文件,SGID只针对可执行文件和目录,SBIT只针对可执行目录
作用在
判断方法
作用
#ACL权限
作用于系统权限分配不足的时候
#sudo权限
#系统文件锁
lsattr
chattr
#企业权限的使用
1.linux系统权限、数据库权限不要掌握在同一个部门
2.满足使用,权限最小
3.尽量不要使用root用户,使用 普通用户 + sodu提权
4.使用Chattr锁定重要的系统权限
5.使用脚本检测系统中新增的SUID、SGID、SBIT文件
6.使用秘钥登录,修改SSH服务端口
备份方案
---------------------------- 备份对象
1.备份系统重要文件
2.备份数据库
全备+增备
3.备份Apache服务配置文件
4.备份其他服务
日志备份
使用日志切割工具logrotate
日志轮替(轮替删除)
使用Apache服务配置文件自带日志切割功能,但是需要使用脚本进行轮替
---------------------------- 备份方式
#全量备份
cp、tar、dump、xfsdump、Veeam、commvault
#增量备份,基于上一次备份,然后进行的备份
C6:dump工具
C7:xfsdump工具
#差异备份,基于上一次全备,然后进行的备份
C6:dump工具
C7:xfsdump工具
---------------------------- 备份频率
1.实时备份
mysql的主从同步
sersync
2.定时备份
脚本 + 定时任务,如每天、每周备份
---------------------------- 备份的存储位置
1.本地备份
2.异地备份
服务器配置
lb、web 8核,16G,3x1T raid5
mysql、elk、redis 16核,32G,6x1T raid5
磁盘阵列
raid 0
1.必须使用两块或两块以上的硬盘组成
2.每块硬盘的大小必须一致
3.raid0 是所有动态磁盘中,数据读写最快的
4.损坏几率相对最高
5.没有磁盘容错功能
#数据分开存储,CPU对数据的读取最快(同时读取)
#磁盘的损坏率是单块盘的多倍
#没有磁盘的冗余功能(一块磁盘坏了的话,那么数据就丢了)
raid 1
1.由2块或2的倍数硬盘组成
2.每块硬盘大小必须一致
3.磁盘利用率只有50%,写入速度最慢
4.拥有磁盘容错功能
#磁盘另外50%使用率做了备份,同一条数据写2遍,所以速度慢
#优点是磁盘容错
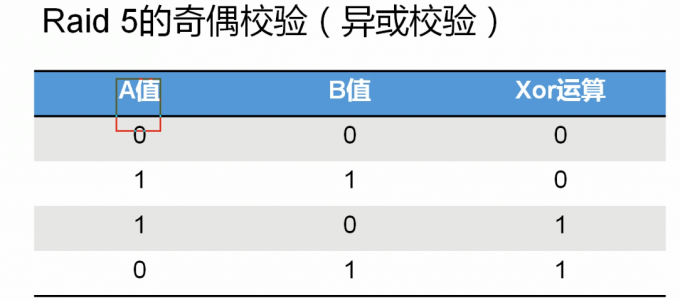
raid 5
1.由三块或三块以上的硬盘组成
2.每块硬盘大小必须一致
3.磁盘利用率是n-1块盘
4.利用奇偶校验,拥有磁盘容错功能
#磁盘个数越多,利用率越高
#注意只支持一块硬盘同时损坏
raid 6
1.raid6是raid5的增强版
2.由4块或以上硬盘组成
3.每块硬盘大小必须一致
4.磁盘利用率是n-2块盘
5.支持磁盘容错,可以支持2块硬盘损坏
#支持同时坏2块盘损坏
raid 10
1.必须由4块等大小的硬盘组成
2.两两硬盘先组成raid1,再组成raid0
3.兼顾raid0 和raid1 的特点,中和两种raid的缺点
软raid与硬raid的区别
#软raid
是由操作系统模拟的raid,一旦硬盘损坏,操作系统就会损坏,raid就会丧失作用
#硬raid
是由独立于硬盘之外的,硬件raid卡组成,就算硬盘损坏,也不会导致raid卡损坏,磁盘容错才能起作用
1.软raid的作用就是模拟read,用来学习
2.硬件read有独立的操作系统,进而可以修复磁盘损坏
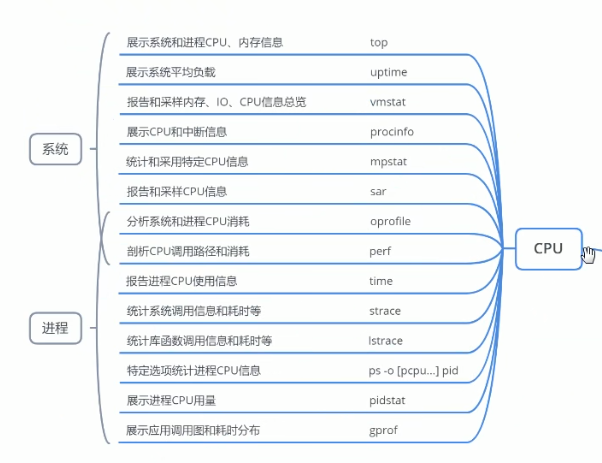
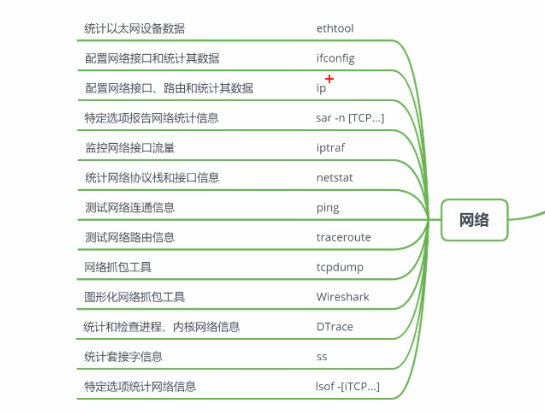
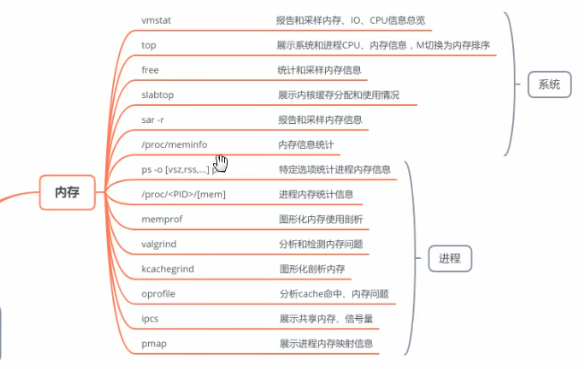
linux资源查看
CPU
网络
磁盘

内存
综合监控工具
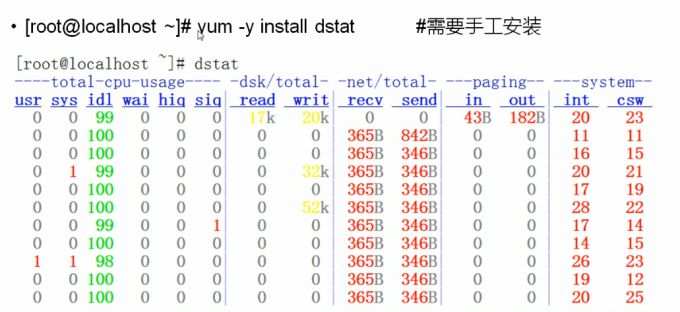




启动流程
C6
1.服务器加电自检(滴滴滴),加载BIOS信息,BIOS进行系统检测
2.加载grub菜单(进行多系统选择)
3.系统内核
4.加载硬件驱动
5.由内核启动系统第一个进程 /sbin/init
6.由/etc/init/rcS.conf调用 /etc/inittab,确定系统的默认运行级别
7.调用/etc/init/rc.conf配置文件
8.运行相应的运行级别目录 /etc/rc[0-6].d/中的脚本
9.执行 /etc/rc.d/rc.local中的程序(进程串行启动)
10.登录界面
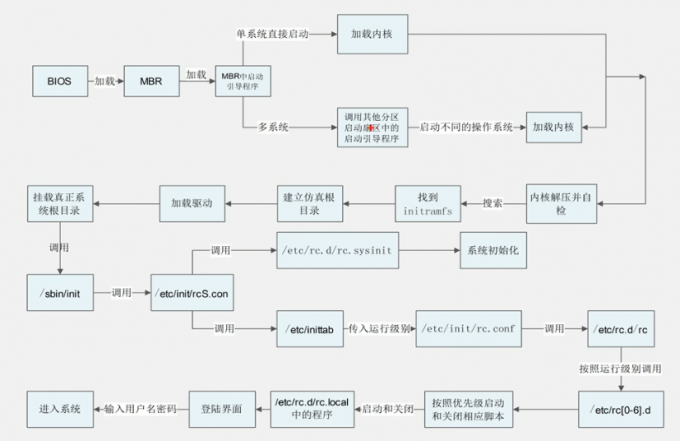
C7
1.服务器加电自检(滴滴滴),加载BIOS信息,BIOS进行系统检测
2.加载grub2菜单
3.grub2加载系统内核
4.grub2加载inintamfs虚拟文件系统
5.内核初始化,加载硬件的驱动
6.内核启动系统的第一个进程systemd
7.进程并行启动
8.systemd进程调用default.target

linux系统优化
1.禁用不需要的端口
linux使用ntsysv命令
禁用Samba服务的默认端口445
2.避免直接使用root用户,普通用户通过sudo授权操作
3.通过Chattr锁定重要系统文件
/etc/passwd
4.配置国内yum源,加快下载速度
5.配置系统同时打开的最大文件数
ulimit -SHn 65535
6.服务器同步时间
ntpdate time1.aliyun.com
定时任务 + ntpdate
7.更改ssh服务的默认端口22,配置ssh密匙对登录
8.配置合理的iptables/firewalld 规则
9.配置selinux
10.监控文件、带宽、端口
11.定时备份系统重要的文件
本地 + 异地
文本截取、排序、过滤
1. cut -d '/' -f 3
2. sort -t '/' -k 3 -n -r
3. uniq -c 显示重复次数
4. awk
5. sed
6.监控连接的状态
netstat -an| grep ESTABLISHED| awk '{print $5}' |cut -d ':' -f 1 |sort -n |uniq -c |sort -nr
随机字符串
面试题

工具

tr

[root@jenkins01 ~]# echo " aa...,+1 b2c /* $dd 3 ls 4" |tr -dc '0-9 \n'
1 2 3 4
#!/bin/bash
if [ ! -d /syy ];then
mkdir /syy
fi
cd /syy
for ((i=1;i<=10;i++));do
filename=$(tr -dc 'A-Za-z0-9' < /dev/urandom| head -c 6)
touch "$filename"_gg.txt
#rm -rf /syy/*
done
生成随机数
# $RANDOM 这个系统变量可以默认随机生成 0-32767的数字(包括0,不包括32767)
[root@jenkins01 syy]# echo $RANDOM
12844
[root@jenkins01 syy]# echo $(($RANDOM%1000)) #生成1000内的随机数
890




网站监测

1.ping 监测目标主机是否宕机
2.curl 监测网站是否正常
#curl命令
开源的用于数据传输的命令行工具,可以用与http访问,用于上传和下载、用户认证、代理访问等
选项:
-o :将命令输出保存在指定文件
-s :静默输出
-w :按指定格式输出内容,例如:-w %{http_code} #输出http状态码
--connect-timeout :指定超时时间

#!bin/bash
web = (
www.qq.com
10.0.0.90
10.0.0.91
)
for i in ${web[*]};do
code = $(curl -o /dev/null -s --connect-timeout 5 -w '%{http_code}' $i |grep -E '200|302')
if [ "$code" != "" ];then
echo "$i is ok" >> /root/ok.log
else
sleep 10
code = $(curl -o /dev/null -s --connect-timeout 5 -w '%{http_code}' $i |grep -E '200|302')
if [ "$code" != "" ];then
echo "$i is ok" >> /root/ok.log
else
echo "$i is error" >> /root/error.log
fi
fi
done
提升ssh服务远程管理的安全等级
1.ssh服务的登录验证方式(口令、密钥对)
2.ssh服务的登录端口的监听(端口)
3.ssh服务的登录用户个数限制
4.ssh服务的登录超时设置
5.ssh服务的登录失败次数限制(防止损耗CPU)
密钥对

端口设置

配置文件
[root@jenkins02 ~]# ll /etc/ssh/ssh*
-rw-r--r--. 1 root root 2276 Apr 11 2018 /etc/ssh/ssh_config #客户端
-rw------- 1 root root 3905 Jun 30 03:30 /etc/ssh/sshd_config #服务端
FTP
FTP服务器主动模式
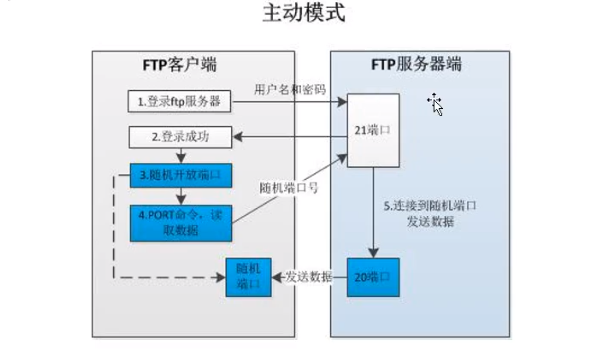
1.FTP服务端21号端口一致保持连接
2.FTP服务端22端口只有在数据传输的时候才会开启
3.FTP服务器只会使用22号端口提供服务
FTP服务器被动模式
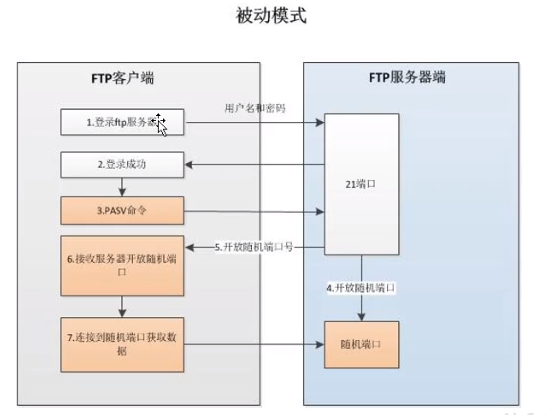
1.FTP服务器提供服务的端口是随机的,所以此时不会因为端口问题导致FTP服务停止运行
时间同步
手动同步
ntpdate 实际服务器IP地址
自动同步
crontab -e
通过DHCP服务获取IP地址的过程
DHCP协议又叫动态主机分配协议
作用是分配ip资源
类型:
DHCP租约
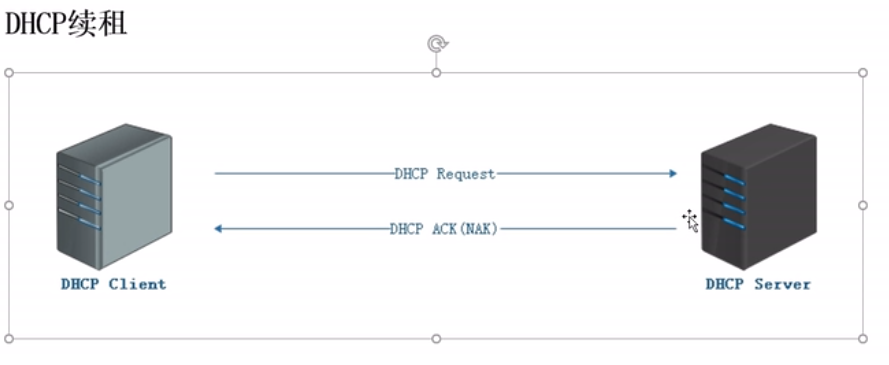
DHCP续租
资源池:
ip资源池
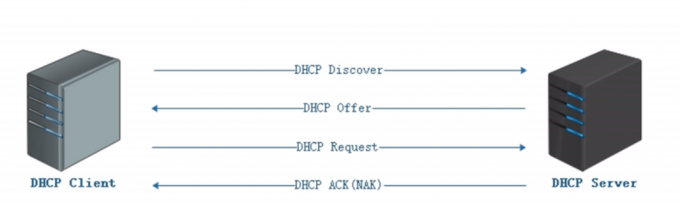
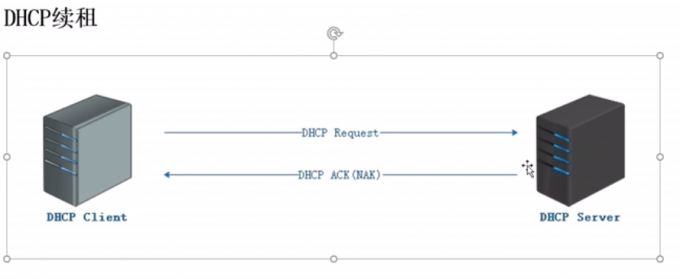
#租约
discover、offer、request、ACK数据的传输为广播
ACK/NAK 是/否
#续租
数据的传输使用ip地址,直接传输数据包
#取消VMVARE网卡的DHCP功能
#下载
[root@jenkins01 syy]# yum install -y dhcp
#配置
[root@jenkins01 syy]# vim /etc/dhcp/dhcpd.conf
subnet 10.0.0.0 netmask 255.255.255.0 {
range 10.0.0.100 10.0.0.254;
option domain name-servers 114.114.114.114;
option routers 10.0.0.2;
default-lease-time 600;
max-lease-time 7200;
}
DNS (域名解析服务)

域名: 表示一个网站或一组服务器的专有的一个字符串,为了人去记忆ip地址
ip: 为每一个网络设备来设置一个ip地址,为了资源定位
DNS服务器原理及解析流程
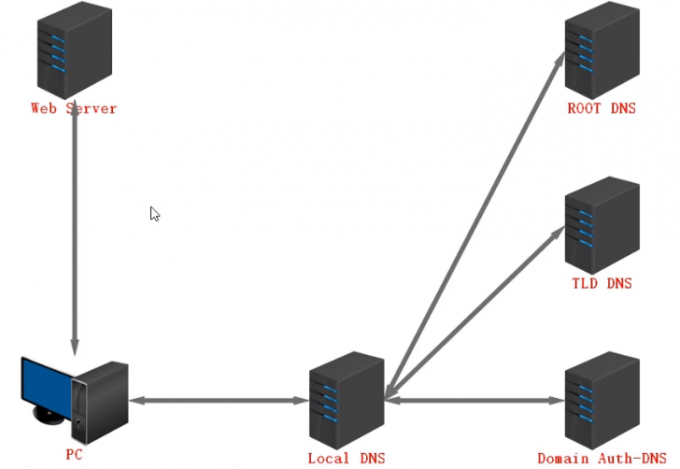
本地DNS
# local DNS
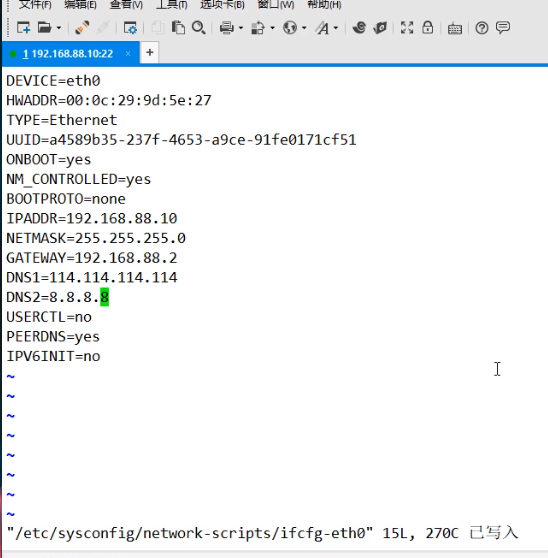
[root@hass-11 ku]# vim /etc/hosts
#IPV4本地回环地址 别名 别名
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#IPV6本地回环地址
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
#缺点
维护压力大
#local DNS 递归服务器
DNS服务器(递归查询)
#GATEWAY
数据传输必须要有网关
#DNS1
首选DNS
#DNS2
备选DNS
#本地解析的优先级大于DNS服务器解析
迭代查询
#ROOT DNS(根域服务器)
只负责接收local DNS的请求
#TLD DNS
只负责接收根域传来的顶级域
#ROOOT DNS、TLD DNS、Domain Auth-DNS迭代服务器,根域、顶级域、二级域服务器
#二级DNS又叫权威DNS
#local DNS帮助PC第一次解析,还可以记录迭代查询的结果
文字解析

权威DNS 和递归DNS的定义

智能DNS

Apache虚拟主机
1.基于IP的虚拟主机
~]# ifconfig eth0:0 10.0.0.3/24 #设置网卡子接口,临时生效
2.基于IP+端口的虚拟主机
3.基于域名的虚拟主机
基于域名的 多虚拟主机
#编辑多虚拟主机
~]# vim /etc/httpd/conf.d/test.conf
<VirtualHost 10.0.0.3:80>
DocumentRoot /var/www/html/a.com
ServerName www.a.com
#管理员信息
#ServerAdmin xinxi
#日志
#Errorlog log_dir
</VirtualHost>
<VirtualHost 10.0.0.4:80>
DocumentRoot /var/www/html/b.com
ServerName www.b.com
</VirtualHost>
#添加虚拟网卡
~]# ifconfig eth0:0 10.0.0.3/24
~]# ifconfig eth0:1 10.0.0.4/24
#本地解析
~]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.0.0.3 www.a.com
10.0.0.4 www.b.com
~]# mkdir /var/www/html/{a,b}.com
~]# echo "www.a.com..." >> /var/www/html/a.com/index.html
~]# echo "www.b.com..." >> /var/www/html/b.com/index.html
#重启httpd
~]# service httpd restart
基于ip和端口的 多虚拟主机
#配置域名解析
~]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.0.0.3 www.a.com
10.0.0.3 www.b.com
#关闭多余的网卡
~]# ifconfig eth0:1 10.0.0.4 down
~]# ip a|grep 10.0.0.3
inet 10.0.0.3/24 brd 10.0.0.255 scope global secondary eth0:0
#配置httpd 多虚拟主机
~]# vim /etc/httpd/conf.d/test.conf
<VirtualHost 10.0.0.3:80>
DocumentRoot /var/www/html/a.com
ServerName www.a.com
</VirtualHost>
<VirtualHost 10.0.0.3:8080>
DocumentRoot /var/www/html/b.com
ServerName www.b.com
</VirtualHost>
#使httpd监听多个端口
~]# vim /etc/httpd/conf/httpd.conf
Listen 80
Listen 8888
#curl
[root@jenkins01 ~]# curl www.a.com:80
www.a.com...
[root@jenkins01 ~]# curl www.b.com:80
www.a.com...
[root@jenkins01 ~]# curl www.a.com:8888
www.b.com...
[root@jenkins01 ~]# curl www.b.com:8888
www.b.com...
域名跳转
#本地解析
~]# vim /etc/hosts
10.0.0.3 www.a.com
10.0.0.4 www.b.com
#配置子网卡
~]# ifconfig eth0:0 10.0.0.3/24
~]# ifconfig eth0:1 10.0.0.4/24
#
~]# vim /etc/httpd/conf.d/test.conf
<VirtualHost 10.0.0.3:80>
DocumentRoot /var/www/html/a.com
ServerName www.a.com
</VirtualHost>
<VirtualHost 10.0.0.4:80>
DocumentRoot /var/www/html/b.com
ServerName www.b.com
<IfModule mod_rewrite.c>
RewriteEngine on
#开启rewrite功能
RewriteCond %{HTTP_HOST} ^www.b.com
#把以www.a.com开头的内容复制给HTTP_HOST变量
RewriteRule ^(.*)$ http://www.a.com/$1 [R=301,L]
#^(.*)$指客户端要访问的资源
#$1 把 .* 所指的内容赋值给$1
#R=permanent 永久重定向 = 301
#L 指生效的最后一条规则,以后的不再生效
</IfModule>
</VirtualHost>
#curl
~]# curl www.a.com:80
www.a.com...
~]# !c
curl www.b.com:80
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
<title>301 Moved Permanently</title>
</head><body>
<h1>Moved Permanently</h1>
<p>The document has moved <a href="http://www.a.com//">here</a>.</p>
</body></html>
Apache的三种工作模式
prefork模式
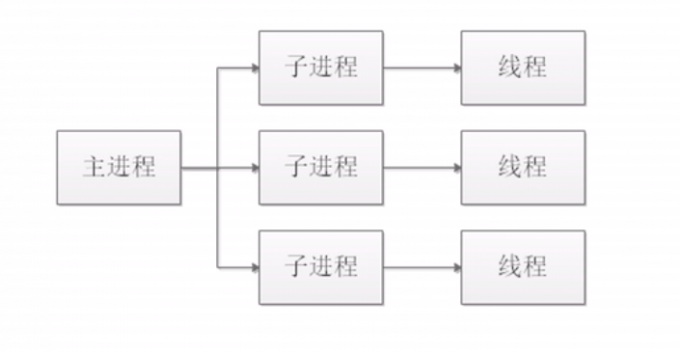
#该模式下,Apache会开启多个子进程,在处理请求之前
#一个子进程下面有一个线程,一个线程只处理一个请求
#优点
对请求的处理稳定
#缺点
进程独占资源,不适合高并发
worker模式
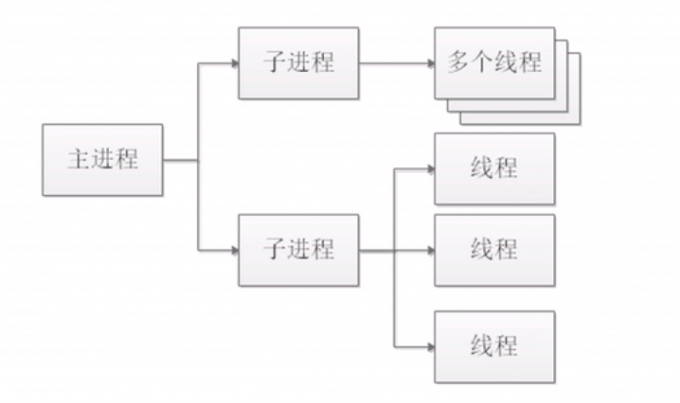
#一个子进程下面有多个线程,一个线程只处理一个请求
#优点
资源利用率高,适合高并发
#缺点
一个线程不能工作,会导致该子进程下的所有线程都不能工作(线程安全)
event模式
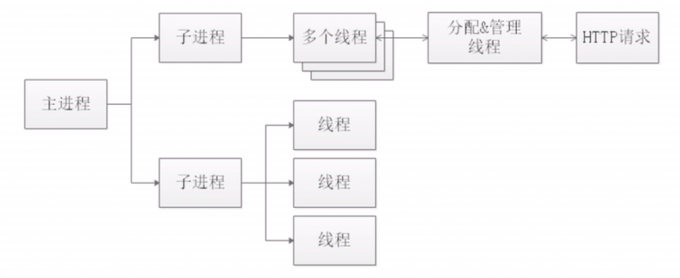
#同一个用户在同一个网站进行多次访问,为了防止系统重复的进行TCP/IP连接和断开,存在一个连接超时时间T,在时间T范围内,该用户可以直接访问该网站,不需要再进行TCP/IP连接
#event模式新增了'分配管理线程'
#该线程的作用就是查找所有进程中处于等待时间T的进程,停止该进程的等待,让其处理别的请求
#优点
该模式下,要比worker模式更擅长处理高并发
#查看Apache的工作模式
~]# httpd -V |grep -i 'server mpm'
Server MPM: prefork
#指定Apache的工作模式
在编译时,在选项中指定 --with-mpm=xxx
Apache优化
#apache服务器的安全
#apache服务器的效率
日志优化
#查看Apache日志路径
~]# cat /etc/httpd/conf/httpd.conf |grep CustomLog
CustomLog "logs/access_log" combined
~]# ll /var/log/httpd/
total 12
-rw-r--r-- 1 root root 1021 Sep 23 20:18 access_log #其他日志
-rw-r--r-- 1 root root 7842 Sep 23 20:13 error_log #报错日志
#查看日志切割工具
[root@jenkins01 ~]# rpm -q logrotate
logrotate-3.8.6-17.el7.x86_64
[root@jenkins01 ~]# rpm -ql logrotate |grep bin
/usr/sbin/logrotate
[root@jenkins01 ~]# rpm -ql logrotate |grep sbin #logrotate安装包含的命令
/usr/sbin/logrotate
[root@jenkins01 ~]# which rotatelogs
/usr/sbin/rotatelogs
[root@jenkins01 ~]# rpm -qf /usr/sbin/rotatelogs #查看命令属于哪个包
httpd-2.4.6-93.el7.centos.x86_64
[root@jenkins01 ~]# rpm -qf /usr/bin/cd
bash-4.2.46-31.el7.x86_64
#配置Apache日志(在配置文件使用httpd自带的日志切割工具,指定日志切割)
~]# /etc/httpd/conf/httpd.conf
CustomLog "|/usr/sbin/rotatelogs -l /tmp/httpd_access_%Y%m%d.log 86400" combined
#检测
~]# tailf /tmp/systemd-private-61d9106934ca4074a160dbe4ac63987a-httpd.service-5txtFo/tmp/httpd_access_20200923.log
10.0.0.91 - - [23/Sep/2020:21:19:51 +0800] "GET / HTTP/1.1" 200 13 "-" "curl/7.29.0"
错误页面的美化
#可以将 404 500等错误信息页面重定向到网站首页或其他页面,提升用户体验
#编辑虚拟主机
~]# vim /etc/httpd/conf.d/test.conf
<VirtualHost 10.0.0.3:80>
DocumentRoot /var/www/html/a.com
ServerName www.a.com
ErrorDocument 404 httpd://www.b.com
</VirtualHost>
<VirtualHost 10.0.0.4:80>
DocumentRoot /var/www/html/b.com
ServerName www.b.com
</VirtualHost>
#编辑美化页面
~]# echo '我是美化页面' > /var/www/html/b.com/index.html
屏蔽Apache版本等敏感信息
#子文件调用
~]# vim /etc/httpd/conf/httpd.conf
Include conf/extra/httpd-default.conf
#修改配置文件中默认显示的信息
~]# vim /etc/httpd/conf.d/httpd-default.conf
ServerTokens Prod
ServerTokens Major
ServerTokens Minor
ServerTokens Min
ServerTokens OS
ServerTokens Full
配置Apache缓存

#缓存对象
.gif、jpeg、png、css等文件,不能缓存视频等较大的文件
#该模块一定要在网站的标签里面声明
<VirtualHost IdModule 10.0.0.x mod_expires.c>
<IdModule></IdModule>
禁止PHP解析代码
~]# vim /etc/httpd/conf.d/httpd-default.conf
<Directory "/www.a.com/uploads">
Options FollowSymLinks
AllowOverride None
Order allow,deny
Allow from all
php_flag engine off
</Directory>
优化总结

#对故障进行预测,解决对应问题的策略/方案都叫优化
提高网站的安全和效率
- 杀毒软件可以提高网站的安全
- CDN
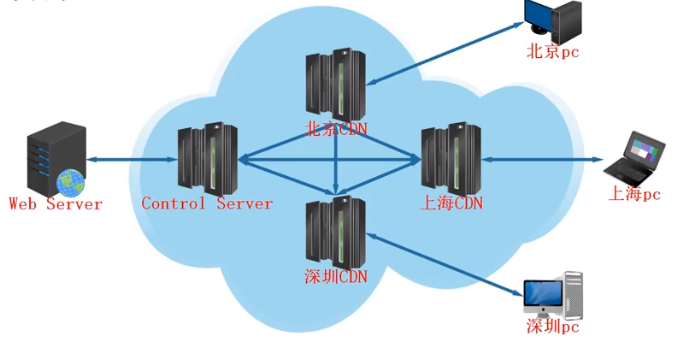
#CDN又叫内容分发网络,可以加快用户对静态资源的访问
#CDN的作用就是减轻网站服务器的压力,还有保护服务器的真实身份
就是web通过CDN把变化频率较低的文件(图片文件、文本文件),分发到各个城市的CDN服务器上
这样各个城市的用户要访问资源,通过智能DNS会直接把域名解析成'离当前位置最近'的DNS的ip
#这时的CDN相当于一个缓存服务器
3.常见的服务器攻击
#DHCP安全威胁
1.饿死攻击(DHCP服务器没有ip分配)
黑客可以使用chadder来不断的向DHCP服务器请求ip,chadder相当于MAC,不同的chadder代表不同的主机,从而别的服务器无法上网
2.仿冒服务器攻击
私接路由器
安装DHCP server
3.中间人攻击
ARP中间人攻击(双向欺骗),使用非对称加密可以避免
#使用snooping可以解决饿死攻击、仿冒服务器攻击、中间人攻击
4.饱死攻击
DDOS攻击,黑客一直向服务器发送请求
Apache的优缺点
优点
1.Apache的rewrite功能比nginx的要强大 (域名、关键词)
2.Apache模块非常多,基本想要的功能都能找到模块 (模块化)
3.存在时间较长,相关文档多,bug相对较少
4.静态解析很稳定(html)
5.动态解析也很稳定(解析需要连接数据库的文件,比如 .php文件)
缺点
1.由于工作模式是'同步阻塞型',导致资源的消耗较高,并发能力较差
nginx的优缺点
优点
1.轻量级服务,比Apache占用更少的内存及资源
2.并发能力强,nginx处理请求是异步非阻塞型的,而Apache则是同步阻塞型,在高并发下nginx能保持'低资源、低消耗、高性能'
3.高度模块化的设计,编写模块相对简单
4.社区活跃,各种高性能模块产出迅速
缺点
1.动态处理上需要使用fastcgi连接PHP的fpm服务,相比apace不占优势
nginx的动态解析解析
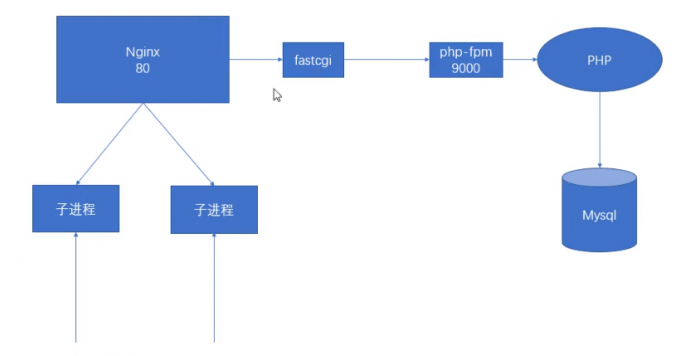
Apache和nginx的选择
1.nginx 适合做静态处理,简单,效率高,并发高
2.Apache 适合做动态处理(连接PHP更方便),稳定,功能强
3.并发较高的情况下优先选择nginx,并发要求不高的情况下,两者都可以。
4.可以使用nginx作为反向代理,然后将动态请求负载均衡到后端Apache上
nginx反向代理、负载均衡、动静分离
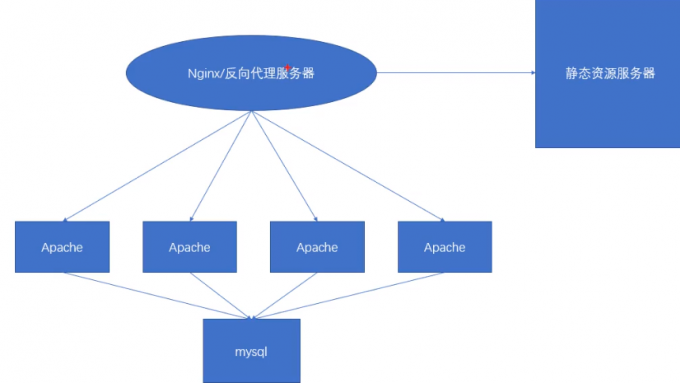
#企业常用
nginx处理请求的原理

同步
关键在于等,效率低,但是可以保持数据的一致性
异步
效率高,数据有偏差
#同步或者异步是相对于数据来说的

阻塞
线程的使用效率低
非阻塞
线程的使用效率高
#阻塞非阻塞是相对于进程来说的
nginx以异步非阻塞的方式进行工作的

nginx常用模块
http_ssl_module模块

1.http_ssl_module模块在nginx编译安装的时候需要指定
2.http 使用80端口,HTTPS使用443端口
3.使用rewrite或return,可以实现nginx的请求转发
http_image_filter_module模块

1.直接在配置文件中图片的宽和高
http_rewrite_module模块

http_proxy_module模块

http_upstream_module模块

#负载均衡的算法
RR轮询
lnmp、lamp、lnmTJ总结
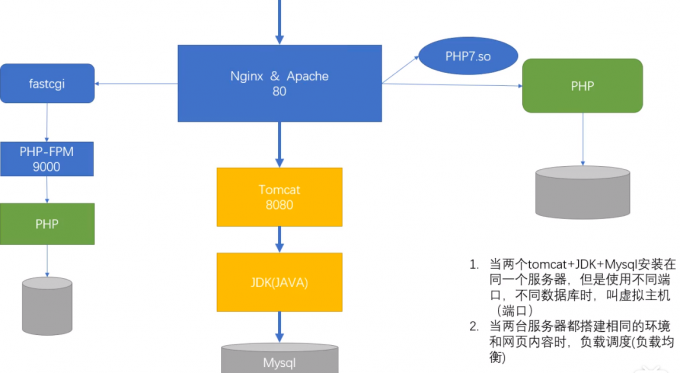
静态资源直接访问静态资源服务器,CDN
lnmp
nginx通过fast_cgi模块,代理PHP-FPM,访问数据库,并发量高
lamp
Apache直接连接PHP,访问数据库
lnmTJ
nginx通过fast_cgi模块,反向代理后端的Tomcat服务器,Tomcat服务器使用JDK,访问数据库
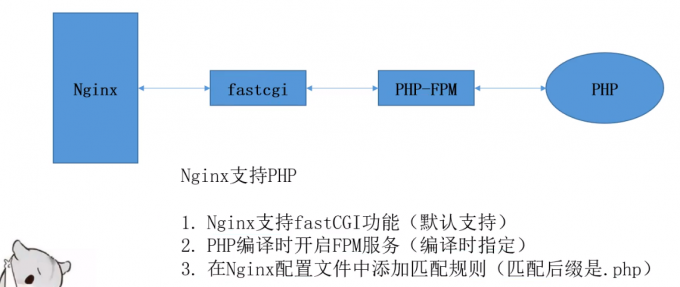
nginx调用PHP的过程
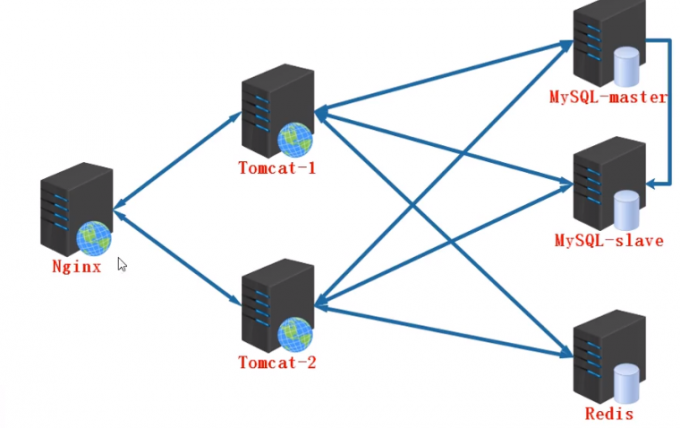
nginx调用Tomcat的过程
http状态码
1** :信息,服务器收到请求,需要请求者继续执行操作(客户端看不到)
2** :成功,操作被成功接收并处理(客户端看不到)
3** :重定向,需要进一步的操作以完成请求(客户端看不到)
4** :客户端错误,请求包含语法错误或无法完成请求
5** :服务端错误,服务端在处理请求的过程中发生了错误
#五个类别的响应代码的第一个数字是'唯一代表'
成功响应

重定向

客户端错误
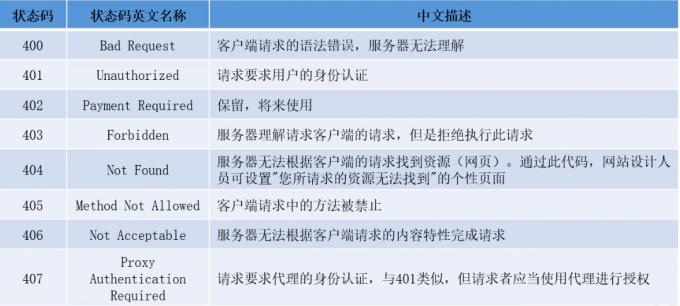
服务器错误(生成中应该避免)

SQL语句
select count(*) from student.report where Nmae like '李%';
select Result from student.report order by result desc limit 2;
#函数count(*),显示匹配的数据的数量
#order by 升序排列
#order by desc 降序排列
#limit 步长
增
创建用户
create user user_name@'%' identified by '123';
创建数据库
create database db_name;
创建数据表
create table tb_name(id int,name char(30),age int);
插入数据
insert tb_name(id,name,age) values(1,'zhangsan',21);
#数据库用户登录方式有2种
1.本地,使用localhost授权
2.远程,使用 %授权
删
删除用户
drop user user_name@'%';
删除数据库
drop database db_name;
删除数据表
drop table tb_name;
删除数据
delete from sj1 where id=5;
delete from sj1 where age between 23 and 25;
改
修改表中的数据
update tb_name set age=21 where id=30;
修改数据表的名称
alter table tb_name1 rename tb_name2;
修改数据表的字段类型
describe tb_name;
alter table tb_name modify name char(50);
describe tb_name;
修改数据表的字段类型
alter table tb_name change name username char(50) not null default '';
添加删除字段
alter table tb_name add time datetime;
alter table tb_name drop time;
#change 既可以修改表名(rename),又可以修改字段类型(modify)
查
查看所有数据库
show databases;
查看指定库内所有的数据表
show tables;
查看指定数据表的字段
desc tb_name;
查看所有mysql用户密码和登录方式
select User,Password,Host from mysql.user;
数据数量
select count(*) from db_name.tb_name;
授权
授权用户全部权限(除了grant)
grant all on *.* to username@'%';
创建用户,并授权,或者给已存在的用户授权
grant all on *.* to username@'%' identified by '123';
回收权限
revoke drop,delete on *.* from username@'%';
数据库的启动、关闭
启动
service mysqld start
/etc/init.d/mysqld start
mysqld_safe &
关闭
service mysqld stop
/etc/init.d/mysqld stop
mysqladmin -uroot -p123 shutdown
心灵鸡汤
数据库这方面的知识对我们运维工程师来说是非常重要的技能
但是作为运维来说,我们学习数据库主要学习数据库架构的搭建,以及中间件的部署等
我们运维不用过多的去关注数据库数据的结构、语法结构,因为,数据库里面的所有的库、表、数据结构都是需要开发工程师切合他们的开发项目的
我们运维要做的就是为他们提供一个安全稳定的运行环境、数据库环境
数据库集群
mysql主从复制,一主二从
#主库
接收用户的写入
接收用户的查询
#从库
从服务器的作用只是用来备份主服务器上的数据的
#主从复制原理
bin-log日志(二进制日志),要先开启主服务器上的bin-log日志记录功能,将主服务器的bin-log日志传到从服务器,从服务器根据日志内容将数据换源到本地
#bin-log日志是一种特殊的日志,二进制日志,记录用户对数据库的操作,但是bin-log日志只会记录对数据进行修改的操作 (增删改 授权)
#主从复制就是对master的一种备份,而且比普通的备份效率高得多,消耗的资源更少一些
#主从复制中,主库宕机,从库将会来不及同步主库上的数据,少量的数据丢失是在所难免的
#mysql的master-slave读写分离,是为了分摊主库的读压力
#mysql的master-master,是为了分摊主库的写压力
#mysql的master-master-slave,即一台主机作为两个master的从库,原理是虚拟主机
MHA(自动故障恢复)
主从复制中,主库宕机,然后登陆所有的从库查看POST信息,使用最大POST的从库作为新的主库,然后将它提升为新的主库,登陆从库(新的主库)执行 stop slave
新的主库修改my.cnf配置文件,开启bin-log并重新启动数据库服务,登陆数据库执行reset master
登陆其它从库,执行change master to操作
解决单台mysql的性能瓶颈
#纵向扩展
提升单台服务器的性能,增加CPU、内存、硬盘
小心短板效应
#横向扩展(mysql集群)
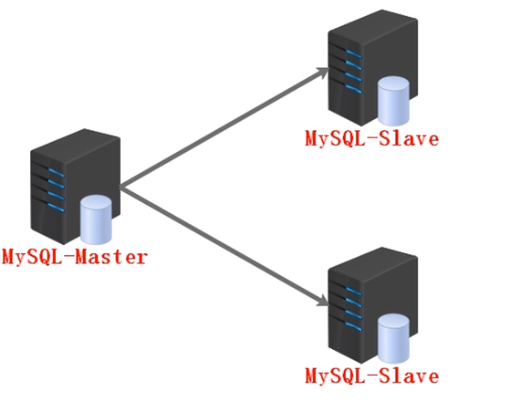
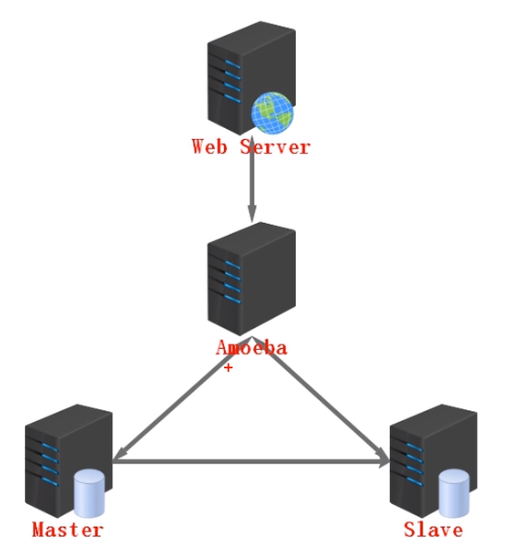
数据库代理工具:Amoeba
Amoeba是致力于mysql的分布式数据库前端代理层(代理服务器),
它主要在应用层(web服务器)访问mysql的时候充当'SQL路由功能',专注于分布式数据库代理层开发,
具有负载均衡、高可用性、SQL过滤、读写分离、可路由相关的'请求'到'目标数据库'、可并发请求多台数据库、合并结果。通过Amoeba,
你能够完成多数据源的高可用、负载均衡、数据切片的功能
#Amoeba 就是mysql集群中反向代理的中间件工具
#生产中,可以使用2台Amoeba做成高可用
atlas -- mycat -- amoeba
数据库索引
#索引也算是对数据库的一种优化
1.什么是索引
索引本质是一种排好序的可以快速查找的数据的结构,可以提高查找的效率
可以理解为数据的分身
数据库这种满足特定查找算法的数据结构,再次基础上实现高级的查找算法
2.索引的分类
主键索引,创建主键的时候自动为该字段创建主键索引
单值索引(单列索引),如果某个字段经常用来检索,就可以为该列创建单只索引
复合索引,一个索引包含多个列,如电话簿上 姓+名,注意复合索引最好不要超过5个字段
唯一键索引,注意该列所有的值必须唯一,允许有空值
辅助索引,普通索引和唯一键索引可以称为辅助索引
3.优点
使数据的查询效率更高
避免了查询数据的时候对数据进行的排序操作
使随机的IO查询变成有顺序的IO查询
3.缺点
索引实际上也是一张表,该表保存了主键与索引字段,并指向实体表的数据,索引需要占用额外的磁盘空间
索引虽然大大的提高了数据的查询速度,但是会降低更新表的速度(insert、update、delete)
因为mysql不仅要保存数据,还要保存索引文件
每次更新添加了索引列的字段,都会调整因为更新所带来的键值对变化后的索引信息
4.什么时候需要创建索引
频繁作为查询条件的字段应该创建索引
查询中与其它表关联的字段,外键关系的列建立索引
数据本身就有顺序,通过索引将大大提高排序速度
统计或分组字段
5.什么时候不需要创建索引
频繁更新的字段不适合创建索引,因为没猜错更新不单单是更新了数据,还会更新索引
where里用不到的字段不创建索引
对单列数据,不要创建多种索引(减少资源消耗)
表数据太少不需要创建索引,一个表中的数据在三百万左右才需要创建索引
性别,国籍字段
#创建索引的时候,系统自动创建了2个空间,索引空间,数据空间
数据库备份

1.查看binlog日志,记录drop之前的位置点m
2.查看全备,找到mysql数据库的数据备份到了哪个位置点n
3.通过binlog日志,使用mysqldump命令,导出n到m的binlog信息,a.txt
4.拷贝全备文件和a.txt 到新库所在主机
5.使用mysqldump命令导入binlog日志,数据恢复
6.根据数据库数据量的大小,选择
切换前端web对数据库的指向
将新恢复的数据库的数据导出、拷贝到旧库所在主机、导入
#数据库binlog需要手动开启
#binlog记录了用户,对数据库所有的增删改操作
redis
#redis是一种非关系型数据库
#redis中的数据是保存在内存中的,将redis中的数据实时保存到磁盘,叫做redis的持久化
#原子性,指的是一次完整的事务,与事务的commit、rollback有关
#redis中的交集,和mysql的连表查询类似
redis是一个key-value的存储系统,它支持value(数据)类型相对较多,包括string、list、set、zset,这些数据都支持push、pop、add、remove和交集、并集、补集等操作
redis致辞各种不同方式的排序
为了保证效率,redis中的数据是缓存在内存中的
redis会周期性的把数据从内存写入磁盘,或者把修改等操作追加写入记录文件(持久化)
redis支持master-slave,即主从复制
redis持久化--RDB
在redis运行时,RDB程序将当前内存中的数据库快照 保存到磁盘中,当redis需要重启时,RDB程序会通过重载RDB文件来还原数据库
#保存(RDBsave)
RDBsave负责将内存中的数据库数据'以RDB格式'保存到磁盘中,如果RDB文件已经存在,将会替换已有的RDB文件,保存文件期间会阻塞主进程,这段时间期间将'不能处理新的客户端请求',直到保存完成为止
#读取(RDBload)
当redis启动时,会根据配置的持久化模式,决定是否读取RDB文件,并将其中的对象加载到内存中
redis持久化-AOF
以'协议文本'的方式,将所有对数据库进行的写入命令记录到AOF文件,达到记录数据库状态的目的
#redis的AOF持久化,相当于mysql数据库的binlog日志
#保存
1,将客户端请求的命令转化为网络协议格式
2.将协议内容字符串追加到变量server.aof 中
3.当AOF系统达到设定的条件时,会调用aof_fsync(文件描述符号)将数据写入到磁盘
#读取
1.AOF保存的是网络协议格式的数据,所以只要将AOF中的数据转换为命令,模拟客户端重新执行一遍,就可以还原所有数据库的状态
2.读取AOF保存的文本,还原数据为原命令和原参数,然后使用模拟的客户端执行这个目录请求
3.一条一条的执行第二步,直到,读取完
#AOF重写
1.把AOF文件从磁盘读取到内存中
2.有条件的合并AOF中的redis语句(只保留最新的修改)
3.用新的AOF文件,覆盖原有的AOF文件
使用redis对mysql进行性能优化
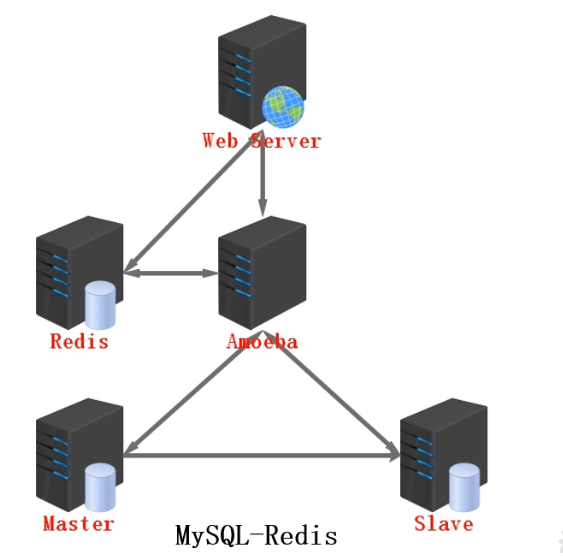
#用户请求与集群的响应
1.web服务器先对redis服务器发出请求,查找数据,如果redis服务器中没有对应的数据
2.web服务器再对amoeba服务器发出请求
3.amoeba对请求进行负载均衡、读写分离,将用户的请求分配到mysql服务器上
4.mysql服务器进行请求反馈
5.linux系统以key-value的形式,将查询结果保存到redis服务器
#注意要设置redis数据库数据的生存时间TTL(缓存时间),使用redis数据库中的数据与mysql数据库中的数据一致
#redis sitinel模式来实现缓存
jenkins
#什么是持续集成
持续集成( Continuous integration , 简称 CI )指的是,频繁地(一天多次)将代码集成到主干。
持续集成的目的,就是让产品可以快速迭代,同时还能保持高质量。
它的核心措施是,代码集成到主干
之前,必须通过自动化测试。只要有一个测试用例失败,就不能集成。
持续交付CD
1.gitlab
1.组的概念
创建组,创建用户,将用户添加到组里(5种权限),组中创建项目
2.IDE工具的使用
安装Windows git
绑定IDE工具和git
git推送代码到gitlab
2.jenkins,Role-based Authorization Strategy插件,用户权限管理
#role-base插件有角色的概念
角色的使用
1.创建角色、创建用户
2.用户绑定角色、角色绑定项目,实现jenkins用户权限的管理
#Credentials Binding插件,凭证管理
Username with password:用户名和密码
SSH Username with private key: 使用SSH用户和密钥
Secret file:需要保密的文本文件,使用时Jenkins会将文件复制到一个临时目录中,再将文件路径
设置到一个变量中,等构建结束后,所复制的Secret file就会被删除。
Secret text:需要保存的一个加密的文本串,如钉钉机器人或Github的api token
Certificate:通过上传证书文件的方式
#git,jenkins从gitlab拉取代码
添加凭证
jenkins进行项目构建,代码目录/var/lib/jenkins/workspace/
#Jenkins中自动构建项目的类型有很多,常用的有以下三种:
自由风格软件项目(FreeStyle Project)
使用Executor Shell构建
Maven项目(Maven Project)
流水线项目(Pipeline Project)
#maven
安装maven
jenkins关联JDK和Maven
maven打包代码
#Maven Integration插件,Maven项目构建
创建maven项目
使用pom.xml文件,进行构建
#Pipeline插件,Pipeline流水线项目构建
Pipeline 支持两种语法:Declarative(声明式)和 Scripted Pipeline(脚本式)语法
声明式Pipeline
脚本式Pipeline
轮询SCM,把Pipeline脚本放在项目中(一起进行版本控制)
是指定时扫描本地代码仓库的代码是否有变更,如果代码有变更就触发项目构建
自动触发构建,Git hook,需要安装两个插件,Gitlab Hook和GitLab
#Deploy to container,把项目部署到远程的Tomcat里面
添加Tomcat凭证
添加项目构建后的操作
#Jenkins内置4种构建触发器:
远程触发构建
其他工程构建后触发(Build after other projects are build)
定时构建(Build periodically)
轮询SCM(Poll SCM)
#参数化构建
#Email Extension插,配置邮箱服务器发送构建结果
对email.html进行版本控制
项目添加构建后发送邮件
#SonarQube是一个用于管理代码质量的开放平台,可以快速的定位代码中潜在的或者明显的错误。
下载、配置SonarQube
安装SonarQube Scanner插件,jenkins调用SonarQube
添加SonarQube凭证
在项目添加SonaQube代码审查
SonarQube的UI界面查看审查结果
nexus
kafka
常用的消息队列message queue
#RabbitMQ
开源免费
它非常重量级,更适合于企业级的开发。同时实现了Broker构架
#redis
基于redis的setinue模式
10K以下数据的入队和出队
#zeroMQ
ZeroMQ号称最快的消息队列系统,尤其针对大吞吐量的需求场景
#ActiveMQ
类似于ZeroMQ,它能够以代理人和点对点的技术实现队列。同时类似于RabbitMQ,它少量代码就可以高效地实现高级应用场景。
#Kafka/Jafka
Kafka是Apache下的一个子项目,是一个高性能跨语言分布式发布/订阅消息队列系统,而Jafka是在Kafka之上孵化而来的,即Kafka的一个升级版。
#kafka注意应用场景是:日志收集系统和消息系统。
#Kafka主要设计目标如下:
以时间复杂度为O(1)的方式提供消息持久化能力,'即使对TB级以上数据也能保证常数时间的访问性能'。
高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。
同时支持离线数据处理和实时数据处理。
Scale out:支持在线水平扩展
#消息传递模式
一个消息系统负责将数据从一个应用传递到另外一个应用,应用只需关注于数据,无需关注数据在两个或多个应用间是如何传递的。
分布式消息传递基于可靠的消息队列,在客户端应用和消息系统之间异步传递消息。
有两种主要的消息传递模式:点对点传递模式、发布-订阅模式。大部分的消息系统选用发布-订阅模式。
Kafka就是一种发布-订阅模式
#每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic
#Kafka 集群包含一个或多个服务器,服务器节点称为broker。
点对点

发布订阅

memchached
Memcached 官网:https://memcached.org/
Memcached是一个自由开源的,高性能,分布式内存对象缓存系统。memcached是一种高速运行的分布式缓存服务器
Memcached是一种基于内存的key-value存储
解决了大数据量缓存的很多问题
#作用
通过缓存数据库查询结果,减少数据库访问次数,以提高动态Web应用的速度、提高可扩展性。
#优点
memcached是多线程工作,而redis是单线程工作。
服务器并不具有分布式功能,分布式部署取决于memcache客户端
CPU使用率低
#缺点
内存使用率高
各个memcached服务器之间互不通信,各自独立存取数据,不共享任何信息。
#集群和分布式有什么区别?
集群可以在单机或者多台机子上部署多个相同配置的服务
分布式在多台机子上部署多个不同服务。
memcached与普通缓存对比

由于Memcached缓存实例是独立于各个应用服务器实例运行的,因此应用服务实例可以访问任意的缓存实例。
而传统的缓存则与特定的应用实例绑定,因此每个应用实例将只能访问特定的缓存。这种绑定一方面会导致整个应用所能够访问的缓存容量变得很小,另一方面也可能导致不同的缓存实例中存在着冗余的数据,从而降低了缓存系统的整体效率。
memcached的集群方案有哪些?
答:因为memcached的服务器并不支持集群,所以有两种方案支持,一种是客户端支持集群,一种是代理端支持集群(性能会有所损耗,大概20%)。推荐使用客户端。
客户端

中间件

缓存架构的演化
-
并发量低的时候

-
并发量1000~1w的时候

-
并发量1w~5w的时候

openstack
OpenStack既是一个社区,也是一个项目和一个开源软件,提供开放源码软件,建立公共和私有云,
它提供了一个部署云的操作平台或工具集,其宗旨在于:帮助组织运行为虚拟计算或存储服务的云,为公有云、私有云,也为大云、小云提供可扩展的、灵活的云计算。
OpenStackd开源项目由社区维护,包括OpenStack计算(代号为Nova),OpenStack对象存储(代号为Swift),并OpenStack镜像服务(代号Glance)的集合。 OpenStack提供了一个操作平台,或工具包,用于编排云。
下面列出Openstack的详细构架图
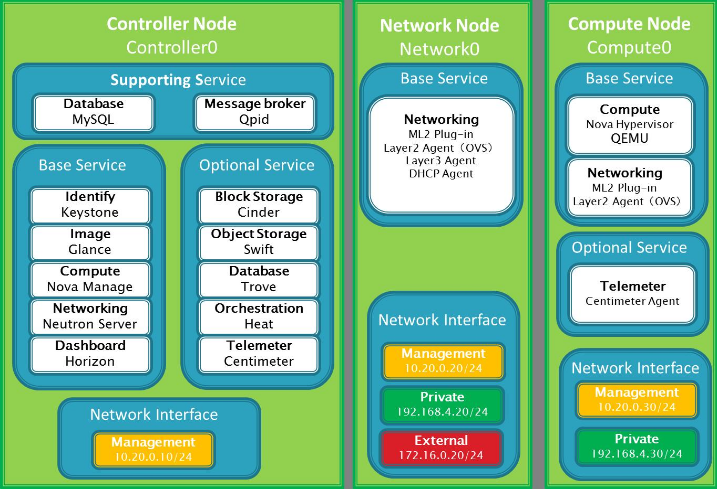
LVS负载均衡
LVS(Linux Virtual Server)即Linux虚拟服务器,是由章文嵩博士主导的开源负载均衡项目,目前LVS已经被集成到Linux内核模块中。
用户请求 -- LVS调度器 -- 根据自己预设的算法决定将该请求发送给后端的某台Web服务器
web服务器 -- 真实服务器会选择不同的方式将用户需要的数据发送到终端用户
#LVS有工作模式,分为NAT模式、TUN模式、以及DR模式
#LVS负载均衡算法,轮询调度(简称'RR'),加权轮询(简称'WRR'),最小连接调度(简称'LC'),加权最少连接(简称'WLC'),最少队列调度
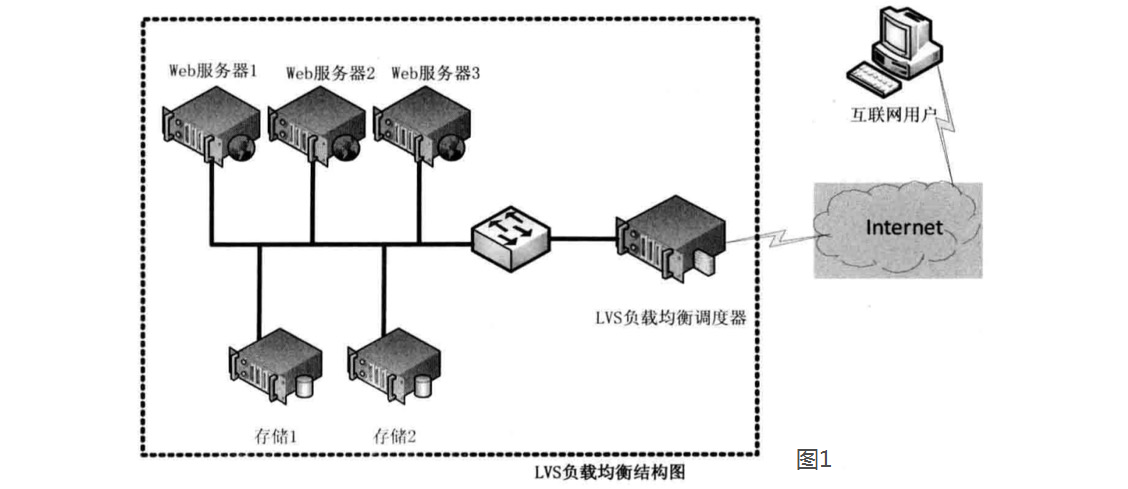
#基于NAT的LVS负载均衡,动态网络地址转换模式
LVS负载调度器可以使用两块网卡配置不同的IP地址,eth0设置为私钥IP与内部网络通过交换设备相互连接,eth1设备为外网IP与外部网络联通。
调度器在得到响应的数据包后会将源地址和源端口修改为VIP及调度器相应的端口
由于LVS调度器有一个连接Hash表,该表中会记录连接请求及转发信息,当同一个连接的下一个数据包发送给调度器时,从该Hash表中可以直接找到之前的连接记录,并根据记录信息选出相同的真实服务器及端口信息。
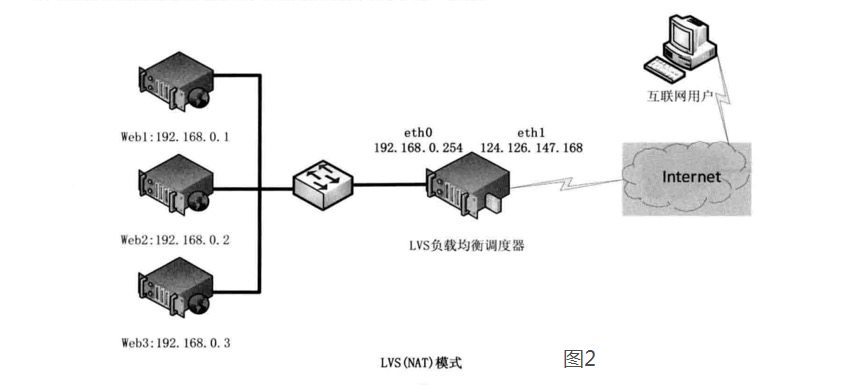
#基于TUN的LVS负载均衡,ip隧道模式
如果后端服务器的数量大于10台,则调度器就会成为整个集群环境的瓶颈
LVS(TUN)的思路就是将请求与响应数据分离,让调度器仅处理数据请求,而让真实服务器响应数据包直接返回给客户端
IP隧道(IP tunning)是一种数据包封装技术,它可以将原始数据包封装并添加新的包头(内容包括新的源地址及端口、目标地址及端口),从而实现将一个目标为调度器的VIP地址的数据包封装

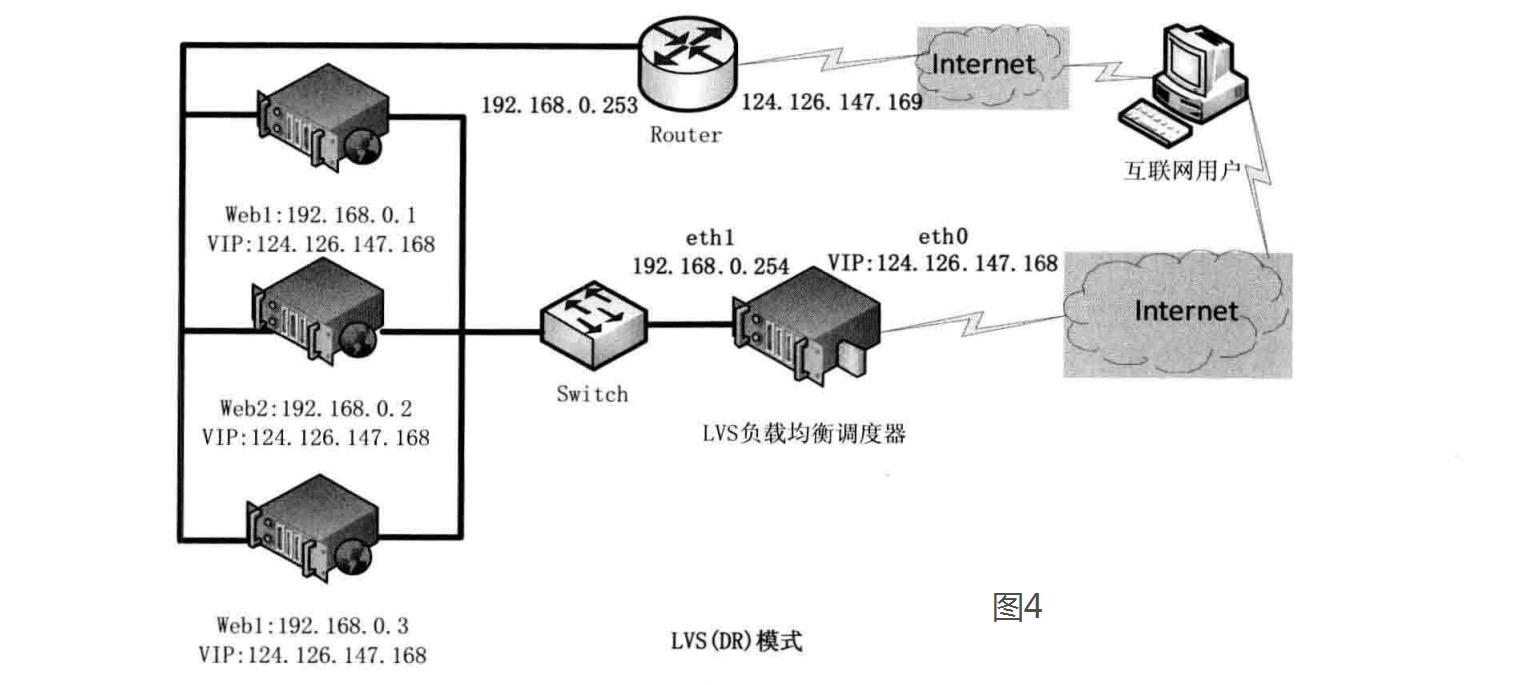
#基于DR的LVS负载均衡,DR模式也叫直接路由模式
在LVS(TUN)模式下,由于需要在LVS调度器与真实服务器之间创建隧道连接,这会增加服务器的负担
LVS依然仅承担数据的入站请求以及根据算法选出合理的真实服务器,最终由后端真实服务器负责将响应数据包发送返回给客户端
与隧道模式不同的是,直接路由模式(DR模式)要求'调度器与后端服务器'必须在'同一个局域网内',VIP地址需要在调度器与后端所有的服务器间'共享'
这样客户端访问的是调度器的VIP地址,回应的源地址也依然是该VIP地址(真实服务器上的VIP),客户端是感觉不到后端服务器存在的
大数据
大数据与云计算的关系就像一枚硬币的正反面一样密不可分。
大数据必然无法用单台的计算机进行处理,必须采用分布式计算架构。
大数据常用组件
CDH
hive
hadoop
flick
spark
storm
hbase
