Redis基础命令和多实例03
二、redis管理命令
1.info命令
#查看redis相关信息
127.0.0.1:6379> info
#服务端信息
# Server
#版本号
redis_version:3.2.12
#redis版本控制安全hash算法
redis_git_sha1:00000000
#redis版本控制脏数据
redis_git_dirty:0
#redis建立id
redis_build_id:3b947b91b7c31389
#运行模式:单机(如果是集群:cluster)
redis_mode:standalone
#redis所在宿主机的操作系统
os:Linux 2.6.32-431.el6.x86_64 x86_64
#架构(64位)
arch_bits:64
#redis事件循环机制
multiplexing_api:epoll
#GCC的版本
gcc_version:4.4.7
#redis进程的pid
process_id:33007
#redis服务器的随机标识符(用于sentinel和集群)
run_id:46b07234cf763cab04d1b31433b94e31b68c6e26
#redis的端口
tcp_port:6379
#redis服务器的运行时间(单位秒)
uptime_in_seconds:318283
#redis服务器的运行时间(单位天)
uptime_in_days:3
#redis内部调度(进行关闭timeout的客户端,删除过期key等等)频率,程序规定serverCron每秒运行10次
hz:10
#自增的时钟,用于LRU管理,该时钟100ms(hz=10,因此每1000ms/10=100ms执行一次定时任务)更新一次
lru_clock:13601047
#服务端运行命令路径
executable:/application/redis-3.2.12/redis-server
#配置文件路径
config_file:/etc/redis/6379/redis.conf
#客户端信息
# Clients
#已连接客户端的数量(不包括通过slave的数量)
connected_clients:2
##当前连接的客户端当中,最长的输出列表,用client list命令观察omem字段最大值
client_longest_output_list:0
#当前连接的客户端当中,最大输入缓存,用client list命令观察qbuf和qbuf-free两个字段最大值
client_biggest_input_buf:0
#正在等待阻塞命令(BLPOP、BRPOP、BRPOPLPUSH)的客户端的数量
blocked_clients:0
#内存信息
# Memory
#由redis分配器分配的内存总量,以字节为单位
used_memory:845336
#以人类可读的格式返回redis分配的内存总量
used_memory_human:825.52K
#从操作系统的角度,返回redis已分配的内存总量(俗称常驻集大小)。这个值和top命令的输出一致
used_memory_rss:1654784
#以人类可读方式,返回redis已分配的内存总量
used_memory_rss_human:1.58M
#redis的内存消耗峰值(以字节为单位)
used_memory_peak:845336
#以人类可读的格式返回redis的内存消耗峰值
used_memory_peak_human:825.52K
#整个系统内存
total_system_memory:1028517888
#以人类可读的格式,显示整个系统内存
total_system_memory_human:980.87M
#Lua脚本存储占用的内存
used_memory_lua:37888
#以人类可读的格式,显示Lua脚本存储占用的内存
used_memory_lua_human:37.00K
#Redis实例的最大内存配置
maxmemory:0
#以人类可读的格式,显示Redis实例的最大内存配置
maxmemory_human:0B
#当达到maxmemory时的淘汰策略
maxmemory_policy:noeviction
#内存分裂比例(used_memory_rss/ used_memory)
mem_fragmentation_ratio:1.96
#内存分配器
mem_allocator:jemalloc-4.0.3
#持久化信息
# Persistence
#服务器是否正在载入持久化文件
loading:0
#离最近一次成功生成rdb文件,写入命令的个数,即有多少个写入命令没有持久化
rdb_changes_since_last_save:131
#服务器是否正在创建rdb文件
rdb_bgsave_in_progress:0
#最近一次rdb持久化保存时间
rdb_last_save_time:1540009420
#最近一次rdb持久化是否成功
rdb_last_bgsave_status:ok
#最近一次成功生成rdb文件耗时秒数
rdb_last_bgsave_time_sec:-1
#如果服务器正在创建rdb文件,那么这个域记录的就是当前的创建操作已经耗费的秒数
rdb_current_bgsave_time_sec:-1
#是否开启了aof
aof_enabled:0
#标识aof的rewrite操作是否在进行中
aof_rewrite_in_progress:0
#rewrite任务计划,当客户端发送bgrewriteaof指令,如果当前rewrite子进程正在执行,那么将客户端请求的bgrewriteaof变为计划任务,待aof子进程结束后执行rewrite
aof_rewrite_scheduled:0
#最近一次aof rewrite耗费的时长
aof_last_rewrite_time_sec:-1
#如果rewrite操作正在进行,则记录所使用的时间,单位秒
aof_current_rewrite_time_sec:-1
#上次bgrewriteaof操作的状态
aof_last_bgrewrite_status:ok
#上次aof写入状态
aof_last_write_status:ok
#统计信息
# Stats
#新创建连接个数,如果新创建连接过多,过度地创建和销毁连接对性能有影响,说明短连接严重或连接池使用有问题,需调研代码的连接设置
total_connections_received:19
#redis处理的命令数
total_commands_processed:299
#redis当前的qps,redis内部较实时的每秒执行的命令数
instantaneous_ops_per_sec:0
#redis网络入口流量字节数
total_net_input_bytes:10773
#redis网络出口流量字节数
total_net_output_bytes:97146
#redis网络入口kps
instantaneous_input_kbps:0.00
#redis网络出口kps
instantaneous_output_kbps:0.00
#拒绝的连接个数,redis连接个数达到maxclients限制,拒绝新连接的个数
rejected_connections:0
#主从完全同步次数
sync_full:0
#主从完全同步成功次数
sync_partial_ok:0
#主从完全同步失败次数
sync_partial_err:0
#运行以来过期的key的数量
expired_keys:5
#过期的比率
evicted_keys:0
#命中次数
keyspace_hits:85
#没命中次数
keyspace_misses:17
#当前使用中的频道数量
pubsub_channels:0
#当前使用的模式的数量
pubsub_patterns:0
#最近一次fork操作阻塞redis进程的耗时数,单位微秒
latest_fork_usec:0
#是否已经缓存了到该地址的连接
migrate_cached_sockets:0
#主从复制信息
# Replication
#角色主库
role:master
#连接slave的个数
connected_slaves:0
#主从同步偏移量,此值如果和上面的offset相同说明主从一致没延迟,与master_replid可被用来标识主实例复制流中的位置
master_repl_offset:0
#复制积压缓冲区是否开启
repl_backlog_active:0
#复制积压缓冲大小
repl_backlog_size:1048576
#复制缓冲区里偏移量的大小
repl_backlog_first_byte_offset:0
#此值等于 master_repl_offset - repl_backlog_first_byte_offset,该值不会超过repl_backlog_size的大小
repl_backlog_histlen:0
#CPU信息
# CPU
#将所有redis主进程在内核态所占用的CPU时求和累计起来
used_cpu_sys:203.44
#将所有redis主进程在用户态所占用的CPU时求和累计起来
used_cpu_user:114.57
#将后台进程在内核态所占用的CPU时求和累计起来
used_cpu_sys_children:0.00
#将后台进程在用户态所占用的CPU时求和累计起来
used_cpu_user_children:0.00
#集群信息
# Cluster
#实例是否启用集群模式
cluster_enabled:0
#库相关统计信息
# Keyspace
#db0的key的数量,以及带有生存期的key的数,平均存活时间
db0:keys=17,expires=0,avg_ttl=0
#单独查看某一个信息(例:查看CPU信息)
127.0.0.1:6379> info cpu
# CPU
used_cpu_sys:203.45
used_cpu_user:114.58
used_cpu_sys_children:0.00
used_cpu_user_children:0.00
2.client命令
#查看该实例有几个连接,id递增,重启后才刷新
#38988为随机端口,age连接的时间(秒),
127.0.0.1:6379> CLIENT LIST
id=2 addr=127.0.0.1:38988 fd=7 name= age=86036 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=32768 obl=0 oll=0 omem=0 events=r cmd=client
id=4 addr=127.0.0.1:38992 fd=8 name= age=52 idle=52 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=command
3.config命令
#查看redis所有的配置,没有配置就走默认
127.0.0.1:6379> CONFIG GET *
1) "dbfilename"
2) "dump.rdb"
3) "requirepass"
4) ""
.......
4.dbsize命令
#查看当前redis有多少数据
127.0.0.1:6379> DBSIZE
(integer) 18
5.select命令
在Redis中也是有库这个概念的,不过不同于MySQL,Redis的库是默认的,并不是我们手动去创建的,在Redis中一共有16(0-15)个库。在MySQL中进入某一个库,我们需要使用use dbname,在Redis中,只需要select即可。'默认情况下,我们是在0库中进行操作',每个库之间都是隔离的。
#切换1库
127.0.0.1:6379> select 1
OK
#查看1库数据
127.0.0.1:6379[1]> DBSIZE
(integer) 0
6.flush命令(flushdb、flushall)
1.flushdb(清空当前库)
127.0.0.1:6379[1]> keys *
1) "k2"
2) "k1"
127.0.0.1:6379[1]> FLUSHDB
OK
127.0.0.1:6379[1]> keys *
(empty list or set)
2.flushall(清空所有库数据)
127.0.0.1:6379[1]> FLUSHALL
OK
127.0.0.1:6379[1]> keys *
(empty list or set)
127.0.0.1:6379[1]> select 0
OK
127.0.0.1:6379> keys *
(empty list or set)
7.monitor监控命令
#窗口1执行,监控所有库
127.0.0.1:6379> MONITOR
OK
#窗口2执行命令
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> set k2 v2
OK
127.0.0.1:6379> set k3 v3
OK
127.0.0.1:6379> del k1
(integer) 1
#窗口1查看
1596591822.059876 [0 127.0.0.1:38988] "set" "k1" "v1"
1596591827.003306 [0 127.0.0.1:38988] "set" "k2" "v2"
1596591830.524161 [0 127.0.0.1:38988] "set" "k3" "v3"
1596591833.501550 [0 127.0.0.1:38988] "del" "k1"
#将监控的内容写到文件方法(类似于MySQL的一般查询日志)
[root@db01 ~]# redis-cli MONITOR >> /tmp/caozuo.log &
[1] 15333
[root@db01 ~]# tail -f /tmp/caozuo.log
三、redis消息队列
1、问:什么是消息队列?
答:是一个消息的链表,是一个'异步处理'的'数据处理引擎'。
2、问:有什么好处?
答:不仅能够提高系统的负荷能力,还能够'改善因网络阻塞'导致的数据缺失。
3、问:用途有哪些?
答:邮件发送、手机短信发送,数据表单提交、图片生成、视频转换、日志储存等。
4、问:有哪些软件?
答:ZeroMQ、Posix、SquirrelMQ、'Redis'、QDBM、Tokyo Tyrant、HTTPSQS等(linux平台下)。
5、问:怎么实现?
答:顾名思义,先入队,后出队;先把数据丢到消息队列(入队),后根据相应的key来获取数据(出队)。
队列,先进先出
堆栈,先进后出
6、问:Redis可以做消息队列?
答:首先,redis设计用来做'缓存'的,
但是由于它自身的某种特性使得它可以用来做'消息队列',它有几个阻塞式的API可以使用,正是这些阻塞式的API让其有能力做消息队列;另外,做消息队列的其他特性例如FIFO(先入先出)也很容易实现,只需要一个list对象从头取数据,从尾部塞数据即可;
redis能做消息队列还得益于其list对象blpop brpop接口以及Pub/Sub(发布/订阅)的某些接口,它们都是阻塞版的,所以可以用来做消息队列
#一般Redis结合ELK做消息队列
1.什么是消息队列
在生活中,其实有很多的例子,都类似消息队列。
比如:工厂生产出来的面包,交给超市,商场来出售,客户通过超市,商场来买面包,客户不会针对某一个工厂去选择,只管从超市买出来,工厂也不会管是哪一个客户买了面包,只管生产出来之后,交给超市,商场来处理。
消息队列(Message Queue)是一种应用间的'通信方式',消息发送后可以立即返回,有消息系统来确保信息的可靠传递,消息生产者只管把消息发布到消息队列中而不管谁来取,消息消费者只管从消息队列中取消息而不管谁发布的,这样'发布者和使用者都不用知道对方的存在。'
2.为什么使用消息队列
首先,我们可以知道,消息队列是一种'异步的工作机制',
比如说日志收集系统,为了'避免数据在传输过程中丢失',
还有订单系统,下单后,会生成对应的单据,库存的扣减,消费信息的发送,一个下单,产生这么多的消息,都是通过一个操作的触发,然后将其他的消息放入消息队列中,依次产生。
再就是很多网站的,秒杀活动之类的,前多少名用户会便宜,都是通过消息队列来实现的。
这些例子,都是通过消息队列,来实现,业务的解耦,最终数据的一致性,广播,错峰流控等等,从而完成业务的逻辑。
3.消息队列产品
1)rabbit-MQ(最初起源于金融系统,用于分布式系统中存储转发消息。OpenStack)
2)Zero-MQ(SaltStack)
3)Kafka(JAVA)
4)redis(key:value数据库,缓存,消息队列)
4.Redis发布消息-任务队列模式(queuing)
任务队列:顾名思义,就是“传递消息的队列”。与任务队列进行交互的实体有两类,一类是生产者(producer),另一类则是消费者(consumer)。生产者将需要处理的任务放入任务队列中,而消费者则不断地从任务队列中读入任务信息并执行。
任务队列的好处
1)松耦合。
生产者和消费者只需'按照约定'的任务描述格式,进行编写代码。
2)易于扩展。
多消费者模式下,消费者可以分布在多个不同的服务器中,由此降低单台服务器的负载。
5.Redis发布消息-发布-订阅模式(publish-subscribe)
其实从Pub/Sub的机制来看,它更像是一个广播系统,多个订阅者(Subscriber)可以订阅多个频道(Channel),多个发布者(Publisher)可以往多个频道(Channel)中发布消息。
可以这么简单的理解:
1)Subscriber:收音机,可以收到多个频道,并以队列方式显示
2)Publisher:电台,可以往不同的FM频道中发消息
3)Channel:不同频率的FM频道
6.订阅模式实践
1)订阅单个频道
#第一个窗口,订阅一个频道
127.0.0.1:6379> SUBSCRIBE gongsiqun
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "gongsiqun"
3) (integer) 1
#第二个窗口向频道发布消息
127.0.0.1:6379> PUBLISH gongsiqun 今晚大保健
(integer) 1
#回到第一个频道查看
1) "message"
2) "gongsiqun"
3) "\xe4\xbb\x8a\xe6\x99\x9a\xe5\xa4\xa7\xe4\xbf\x9d\xe5\x81\xa5"
2)订阅多个频道
#第一个窗口订阅多个频道
127.0.0.1:6379> SUBSCRIBE gongsiqun jiatingqun
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "gongsiqun"
3) (integer) 1
1) "subscribe"
2) "jiatingqun"
3) (integer) 2
#第二个窗口向频道发布消息
127.0.0.1:6379> PUBLISH gongsiqun jiwnandabaojian
(integer) 1
127.0.0.1:6379> PUBLISH jiatingqun jinwanjiaban
(integer) 1
#回到第一个窗口查看
1) "message"
2) "gongsiqun"
3) "jiwnandabaojian"
1) "message"
2) "jiatingqun"
3) "jinwanjiaban"
四、Redis事务
[
](https://imgchr.com/i/aynz6A)
1.MySQL事务
#成功的事务
begin;
sql1;
sql2;
...
commit;
#失败的事务
begin;
sql1;
sql2;
...
rollback;
2.redis事务命令
#1.开启事务
MULTI
#2.结束事务(执行所有事务块内的命令)
EXEC
#3.取消事务(放弃执行事务块内的所有命令)
DISCARD
#4.watch只能监控一次事务,可以一次监视一个(或多个) key,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断。(多个key有一个被打断则全部被打断)
WATCH
#5.取消监控
UNWATCH
#如果用Redis做存储,一定要使用watch+事务,先x先x
3.事务的示例
#使用事务执行
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> set k100 v100
QUEUED
127.0.0.1:6379> set k200 v200
QUEUED
127.0.0.1:6379> get k200
QUEUED
127.0.0.1:6379> EXEC
1) OK
2) OK
3) "v200"
#事务取消
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> get k1
QUEUED
127.0.0.1:6379> DISCARD
OK
127.0.0.1:6379> keys *
(empty list or set)
#监控一个key
127.0.0.1:6379> WATCH k1
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> set k1 v1000000
QUEUED
#另一个窗口修改k1
127.0.0.1:6379> set k1 00000
OK
#回到第一个窗口提交事务
127.0.0.1:6379> EXEC
(nil)
127.0.0.1:6379> get k1
"00000"
4.注意
1.redis只支持乐观锁
2.事务在'不使用watch'监控时,'谁后提交谁为准'
3.事务在'使用watch'监控时,'谁先提交谁为准'
4.watch只监控一次事务并且是当前连接的事务
五、redis多实例
1.创建多实例目录
[root@db01 ~]# mkdir /service/redis/{6380,6381}
2.配置多实例配置文件
#第一台多实例配置
[root@db01 ~]# vim /service/redis/6379/redis.conf
bind 172.16.1.51 127.0.0.1
port 6379
daemonize yes
pidfile /service/redis/6379/redis_6379.pid
loglevel notice
logfile /service/redis/6379/redis_6379.log
dir /service/redis/6379
dbfilename dump.rdb
save 900 1
save 300 10
save 60 10000
#第二台多实例配置
[root@db01 ~]# vim /service/redis/6380/redis.conf
bind 172.16.1.51 127.0.0.1
port 6380
daemonize yes
pidfile /service/redis/6380/redis_6380.pid
loglevel notice
logfile /service/redis/6380/redis_6380.log
dir /service/redis/6380
dbfilename dump.rdb
save 900 1
save 300 10
save 60 10000
#第三台多实例配置
[root@db01 ~]# vim /service/redis/6381/redis.conf
bind 172.16.1.51 127.0.0.1
port 6381
daemonize yes
pidfile /service/redis/6381/redis_6381.pid
loglevel notice
logfile /service/redis/6381/redis_6381.log
dir /service/redis/6381
dbfilename dump.rdb
save 900 1
save 300 10
save 60 10000
3.启动多实例
[root@db01 ~]# redis-server /service/redis/6379/redis.conf
[root@db01 ~]# redis-server /service/redis/6380/redis.conf
[root@db01 ~]# redis-server /service/redis/6381/redis.conf
4.检测启动
[root@db01 ~]# netstat -lntp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 14002/redis-server
tcp 0 0 172.16.1.51:6379 0.0.0.0:* LISTEN 14002/redis-server
tcp 0 0 127.0.0.1:6380 0.0.0.0:* LISTEN 15541/redis-server
tcp 0 0 172.16.1.51:6380 0.0.0.0:* LISTEN 15541/redis-server
tcp 0 0 127.0.0.1:6381 0.0.0.0:* LISTEN 15545/redis-server
tcp 0 0 172.16.1.51:6381 0.0.0.0:* LISTEN 15545/redis-server
[root@db01 ~]# ps -ef | grep redis
root 14002 1 0 Aug04 ? 00:01:34 redis-server 172.16.1.51:6379
root 15541 1 0 11:50 ? 00:00:00 redis-server 172.16.1.51:6380
root 15545 1 0 11:50 ? 00:00:00 redis-server 172.16.1.51:6381
5.连接多实例
[root@db01 ~]# redis-cli -p 6379
127.0.0.1:6379> quit
[root@db01 ~]# redis-cli -p 6380
127.0.0.1:6380> quit
[root@db01 ~]# redis-cli -p 6381
127.0.0.1:6381> quit
六、redis主从
1.主从复制特点
1.使用异步复制。
2.一个主服务器可以有多个从服务器。
3.从服务器也可以有自己的从服务器。(#级联复制)
4.复制功能不会'阻塞'主服务器。
5.可以通过复制功能来'让主服务器免于执行持久化操作',由从服务器去执行持久化操作即可。但是一般配置主库开启持久化
#详细版本
1)Redis 使用异步复制。从 Redis2.8开始,从服务器会以'每秒一次'的频率向主服务器报告复制流(replication stream)的处理进度。
2)一个主服务器可以有多个从服务器。
3)不仅主服务器可以有从服务器,从服务器也可以有自己的从服务器,多个从服务器之间可以构成一个图状结构。(#级联结构)
4)复制功能不会阻塞主服务器:即使有一个或多个从服务器正在进行初次同步, 主服务器也可以继续处理命令请求。(#bgsave)
5)'复制功能也不会阻塞从服务器':只要在 redis.conf 文件中进行了相应的设置, 即使从服务器正在进行初次同步, 服务器也可以使用旧版本的数据集来处理命令查询。
6)在从服务器删除旧版本数据集并载入新版本数据集的那段时间内',连接请求会被阻塞'。
7)还可以配置从服务器,让它在与主服务器之间的连接断开时,向客户端发送一个错误。(#实时监控主从状态)
8)复制功能可以单纯地用于数据冗余(data redundancy),也可以通过让多个从服务器处理'只读命令'请求来提升扩展性(scalability): 比如说,繁重的SORT命令可以交给附属节点去运行。
级联复制
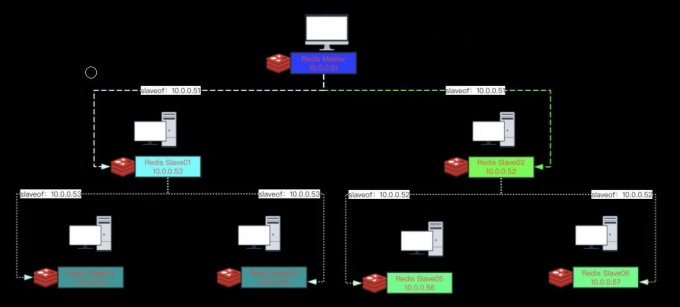
2.主从复制的原理
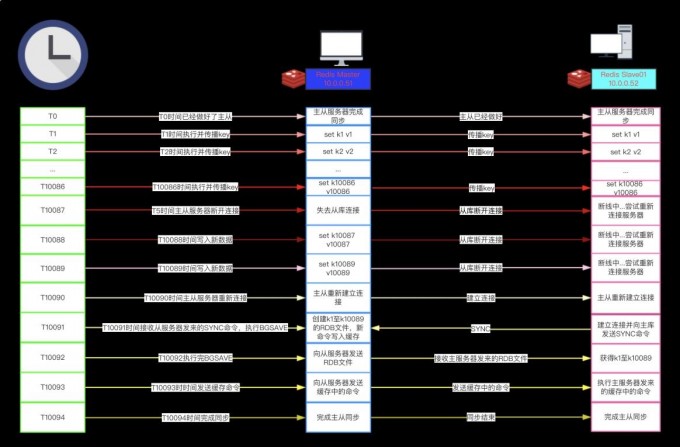
... 上一秒 ...
1.从服务器向主服务器发送 SYNC 命令
2.主库接到 SYNC 命令会调用 BGSAVE 命令创建一个 RDB 文件
3.主库将新的数据'记录到缓冲区'
4.主库将 RDB 文件传输到从库
5.从库拿到 RDB 文件以后,'会清空自己的数据' #小心,相当于flushall
6.从库读取 RDB 文件并导入数据
7.主库将新的数据从'缓冲区传到从库'进行同步
... 下一秒 ...
3.主从复制的机制
#SYNC与PSYNC
1)在 Redis2.8版本之前,'断线之后重连'的从服务器总要执行一次完整重同步(fullresynchronization)操作。
2)从 Redis2.8开始,Redis使用'PSYNC命令代替SYNC命令'。
3)PSYNC比起SYNC的最大改进在于PSYNC实现了部分重同步(partial resync)特性:
在主从服务器断线并且重新连接的时候,只要条件允许,PSYNC可以让主服务器只向从服务器同步断线期间缺失的数据,而不用重新向从服务器同步整个数据库。
PSYNC这个特性需要主服务器为被发送的复制流创建一个'内存缓冲区'(in-memory backlog), 并且主服务器和所有从服务器之间都记录一个'复制偏移量'(replication offset)和一个主服务器 'ID'(master run id),当出现网络连接断开时,从服务器会重新连接,并且向主服务器请求继续执行原来的复制进程:
1)如果从服务器记录的主服务器ID和当前要连接的主服务器的ID相同,并且从服务器记录的偏移量所指定的数据仍然保存在主服务器的复制流缓冲区里面,那么主服务器会向从服务器发送断线时缺失的那部分数据,然后复制工作可以继续执行。
2)否则的话,从服务器就要执行完整重同步操作。
#总结
主从刚刚连接的时候,进行'全量同步';全同步结束后,进行'增量同步'。当然,如果有需要,slave 在任何时候都可以发起全量同步。redis 策略是,'无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。'
#PSYNC优点:
1)PSYNC只会将从服务器断线期间缺失的数据发送给从服务器。两个例子的情况是相同的,但SYNC 需要发送包含整个数据库的 RDB 文件,而PSYNC 只需要发送三个命令。
2)如果主从服务器所处的网络环境并不那么好的话(经常断线),那么请尽量使用 Redis 2.8 或以上版本:#通过使用 PSYNC 而不是 SYNC 来处理断线重连接,可以避免因为重复创建和传输 RDB文件而浪费大量的网络资源、计算资源和内存资源。
注意
1.主服务器开启持久化
在进行主从复制设置时,强烈建议在主服务器上开启持久化,当不能这么做时,比如考虑到延迟的问题,应该将实例配置为'避免自动重启'。
2.主服务器密码
主从服务器之间会定期进行通话,但是如果master上设置了密码,那么如果不给slave设置密码就会导致slave不能跟master进行任何操作,所以如果你的master服务器
上有密码,那么也给slave相应的设置一下密码吧(通过设置配置文件中的'masterauth');
3.用户访问从服务器的'阻塞问题'
主从复制对于从redis服务器来说也是非阻塞的,这意味着,即使从redis在进行主从复制过程中也可以接受外界的查询请求,只不过这时候从redis返回的是'以前老的数据',
如果你不想这样,那么在启动redis时,可以在配置文件中进行设置,那么从redis在复制同步过程中来自外界的查询请求都会'返回错误给客户端';(虽然说主从复制过程中
对于从redis是非阻塞的,但是当从redis从主redis同步过来最新的数据后还需要将新数据加载到内存中,在加载到内存的过程中是阻塞的,在这段时间内的请求将会被阻,
但是即使对于大数据集,加载到内存的时间也是比较多的);
主从复制的方式
1.全部同步
旧的主从中使用SYNC命令
2.部分同步
部分重新同步这个新特性内部使用PSYNC命令,旧的实现中使用SYNC命令
3.无磁盘复制
通常来讲,一个完全重新同步需要'在磁盘上创建一个RDB文件',然后加载这个文件以便为从服务器发送数据。
如果使用比较低速的磁盘,这种操作会给主服务器带来较大的压力。'Redis从2.8.18版本开始尝试支持无磁盘的复制。'
使用这种设置时,子进程直接将RDB通过网络发送给从服务器,不使用磁盘作为中间存储。
使用repl-diskless-sync配置参数来启动无磁盘复制。使用repl-diskless-sync-delay 参数来配置传输开始的延迟时间
3.从服务器只读
从Redis 2.6开始,从服务器支持只读模式,并且是默认模式。这个行为是由Redis.conf文件中的slave-read-only 参数控制的,
可以在运行中通过CONFIG SET来启用或者禁用。
4.配置主从
1)准备环境
| 角色 | 主机 | 端口 |
|---|---|---|
| 主库 | 172.16.1.51 | 6379 |
| 从库 | 172.16.1.51 | 6380 |
| 从库 | 172.16.1.51 | 6381 |
2)连接三台机器
[root@db01 ~]# redis-cli -p 6379
[root@db01 ~]# redis-cli -p 6380
[root@db01 ~]# redis-cli -p 6381
3)查看主从状态
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6380> info replication
# Replication
role:master
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6381> info replication
# Replication
role:master
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
4)配置主从
127.0.0.1:6380> SLAVEOF 172.16.1.51 6379
OK
127.0.0.1:6381> SLAVEOF 172.16.1.51 6379
OK
5)查看主从状态
#查看主库
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=172.16.1.51,port=6380,state=online,offset=263,lag=0
slave1:ip=172.16.1.51,port=6381,state=online,offset=263,lag=1
master_repl_offset:263 #偏移量
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:262
#查看从库
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:172.16.1.51
master_port:6379
master_link_status:up
master_last_io_seconds_ago:9
master_sync_in_progress:0
slave_repl_offset:319 #偏移量
slave_priority:100 #提升为主库的优先级(越低优先级越高)
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
