数据库考试
MySQL综合考试题
- 请写出什么是事务?
事务主要'针对' updataa selete insert语句
一组数据执行的'步骤',这些步骤被视为'事务的一个工作单元'
事务中'所有'的步骤都成功,那么这个工作单元才会被提交,如果步骤中有失败的语句,那么事务执行失败
mysql的innoDB存储引擎才支持事务,pyisam不支持事务
- 事务的特性是什么?
1.原子性
所有SQL语句作为'一个单元'全部执行或全部取消
2.一致性
如果数据库在'事务开始'是处于一致状态,则在执行,'事务期间'将保留一致状态
3.隔离性
事务之间不'相互影响'
4.持久性
事务成功完成后,所做的所有更改都将会准确的记录在数据库中(磁盘),所做的更改不会丢失
- MySQL事务的隔离级别有几种,分别是什么?
1.RU级别:
未提交就读取,允许事务查看其它事务所进行的未提交的更改
2.RC级别:
允许其它事务所进行的已经提交的更改,查看不需要重新进入数据库
3.RR级别:
允许事务查看其它事务所进行的已提交的更改,查看数据需要重新进入数据库,这是innoDB的默认级别
4.串行化,将一个事务的结果与其它事务完全隔离
- 什么是脏读,幻读,不可重复读?
RU级别会出现脏读:
RU级别执行事务修改数据,还没有commit就被别的事务读取,但是最后原事务rollback,那么查询到的数据就是脏读
幻读:
当我们删除所有表数据的时候有人插入数据,查询数据时以为是数据没有删除干净,那么这种现象就是幻读
不可重复读:
修改数据后被读取,被读取后再次修改数据,两次数据不一致(比如访问次数)
- 如何解决脏读,幻读,不可重复读的问题?
1.RU:最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
2.RC:允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
3.RR:对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
4.串行化:最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
- MySQL中索引的分类有几种?分别是什么?
1.普通索引
2.唯一键索引
3.主键索引
4.前缀索引
5.联合索引
- 请写出如下慢查询SQL语句的排查过程?及解决办法
Select * from world.city where population>100;
#排查过程
1.查询语句的条件population是否有索引
2.有索引是否使用了索引
3.如果有看看是什么级别(explain)
4.看看为什么没有走索引
5.查看数据量(count(*))
#解决方式
1.建立索引
2.提高索引级别
3.优化sql语句
4.使用limit进行分批查询数据
- MySQL 存储引擎,innodb与myisam的区别?
#MyISAM:
不支持事务,但是每次查询都是原子的;
支持表级锁,即每次操作是对整个表加锁;
物理文件有三个,一个表被分为三个文件.frm .MYD .MYI
不支持热备
#InnoDb:
支持ACID的事务,支持事务的四种隔离级别;
支持行级锁及外键约束:因此可以支持写并发;
物理文件有两个,一个表被分为两个文件 .frm .iba
支持热备
- 数据类型,varchar和char的区别?
#长度不同
1.char类型:char类型的长度是固定的。
2.varchar类型:varchar类型的长度是可变的。
#效率不同
1.char类型:char类型每次修改的数据长度相同,效率更高。
2.varchar类型:varchar类型每次修改的数据长度不同,效率更低。
#存储不同
1.char类型:char类型存储的时候是初始预计字符串再加上一个记录字符串长度的字节,占用空间较大。
2.varchar类型:varchar类型存储的时候是实际字符串再加上一个记录字符串长度的字节,占用空间较小。
#总结:
char的长度是不可变的,而varchar的长度是可变的,定义一个char(10)和varchar(10),如果存进去的是'linux',那么char所占的长度依然为10,除'linux'外,后面跟5个空格,而varchar就立马把长度变为5了,取数据的时候,char类型的要用trim()去掉多余的空格,而varchar是不需要的,char的存取速度要比varchar要快得多,因为其长度固定,方便程序的存储与查找;但是char存储空间要耗费更多。
- Int类型的范围是多少?
整数,取值范围为 -2^31 - 2^31
即-2147483648~2147483647;
- 请写出以下锁的功能?
共享锁、
保证在多事务工作期间,数据的查询被阻塞
排它锁、
在我修改时,别人不能修改
乐观锁、
多事务操作时,数据可以同时修改,谁先提交,以谁为准
悲观锁
多事务操作时,数据只有一个人可以修改
- 请写出innodb存储引擎锁粒度是什么?
InnoDB支持行级锁,而MyISAM支持表级锁
- 请写出,delete、drop、truncate的区别
1.1.delete是DML语句,可以选择删除部分数据,也可以选择删除全部数据;删除的数据可以'回滚';不会释放空间(使用delete删除可以通过binlog找回来)
delete from student;
2.drop是DDL语句,删除表结构和所有数据,同时删除表结构所依赖的约束、触发器和索引;删除的数据无法回滚;会释放空间
trancate table student;
3.truncate是DDL语句,删除表的所有数据,不能删除表的部分数据,也不能删除表的结构;删除的数据无法回滚;会释放空间,由于 TRUNCATE TABLE 不记录在日志中,所以它不能激活触发器。
drop table student;
'执行速度':drop > truncate > delete
一般使用场景:如果一张表确定不再使用,我们使用drop来操作;如果只是删表中的全部数据,一般使用truncate;如果删除的是表中的部分数据,一般使用delete
- 如何使用update代替delete?
#创建库
mysql> create database ceshi;
Query OK, 1 row affected (0.00 sec)
#进入库
mysql> use ceshi
Database changed
#创建表
mysql> create table cs(id int,status enum('1','0'));
Query OK, 0 rows affected (0.00 sec)
#插入数据
mysql> insert cs values(1,'0'),(2,'0');
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
#查看表
mysql> select * from cs;
+------+--------+
| id | status |
+------+--------+
| 1 | 0 |
| 2 | 0 |
+------+--------+
#修改表数据
mysql> update cs set status='1' where id=2;
Query OK, 1 row affected (0.04 sec)
Rows matched: 1 Changed: 1 Warnings: 0
#查看表
mysql> select * from cs;
+------+--------+
| id | status |
+------+--------+
| 1 | 0 |
| 2 | 1 |
+------+--------+
#这样就可以通过表中一列枚举类型数据的变化,实现一条数据的'状态',表示数据是否存在,也就是删除
- 请写出MySQL主从复制原理,画图+文字描述
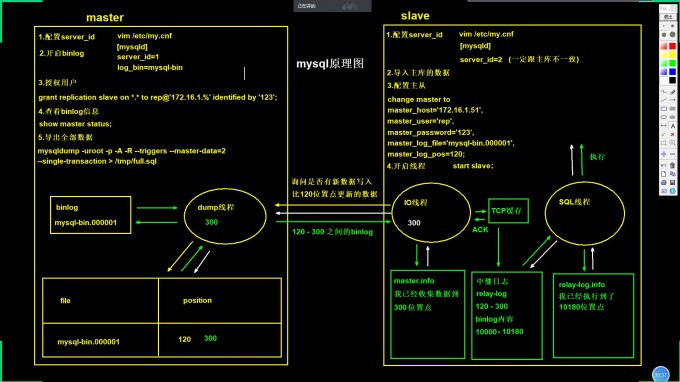
1.主库配置server_id 开启binlog
[mysqld]
server_id=1
log_bin=/usr/local/mysql/data/mysql-bin
2.主库授权从库连接的用户
grant replication slave on *.* to rep@'172.16.1.%' identified by '123';
3.主库查看binlog
show master status;
4.主库导出所有数据
mysqldump -uroot -p -A -R --triggers --master-data=2 --single-transaction > /tmp/full.sql
head -22 /tmp/full.sql | tail -1
5.从库配置跟主库不一样的server_id
[mysqld]
server_id=2
6.配置主从
change master to
master_host='172.16.1.52',
master_user='rep',
master_port='3306'
master_password='123',
master_log_file='mysql-bin.00000x',
master_log_pos=xx;
7.从库开启IO线程和SQL线程
start slave;
8.从库开启IO线程以后,IO线程会向主库的dump线程发起询问,询问是否有新数据
9.dump被询问,去查找新数据,并将新数据返回给IO线程
10.IO线程拿到数据先写入TCP缓存
11.TCP缓存将数据写入中继日志relay-log,并返回给IO线程一个ACK
12.IO线程收到ACK会记录当前位置点到master.info
13.SQL线程会读取relay-log,执行从库获取的SQL语句
14.执行完以后,将位置点记录到relay-log.info
- 请写出半同步复制和延时从库的原理?
1、当Slave主机连接到Master时,能够查看其是否处于半同步复制的机制。
2、当Master上'开启'半同步复制的功能时,至少应该有一个Slave开启其功能。此时,一个线程在Master上提交事务将受到'阻塞',直到得知一个已开启半同步复制功能的Slave已收到此事务的所有事件,'或'等待超时。
3、当一个事务的事件都已写入其relay-log中且已'刷新到磁盘'上,Slave才会告知已收到。
4、如果'等待超时',也就是Master没被告知已收到,此时Master会'自动转换'为异步复制的机制。当至少一个半同步的Slave赶上了,Master与其Slave自动转换为'半同步复制'的机制。
5、半同步复制的功能要在Master,Slave都开启,半同步复制才会起作用;否则,只开启一边,它依然为异步复制。
同步复制:Master提交事务,直到事务在所有的Slave'都已提交',此时才会'返回'客户端,事务执行完毕。缺点:完成一个事务可能会有很大的延迟。
异步复制:当Slave准备好才会向Master请求binlog。缺点:不能保证一些事件都能够被所有的Slave所接收。
半同步复制:半同步复制工作的机制处于同步和异步之间,Master的事务提交阻塞,只要一个Slave已收到该事务的事件且已记录。它不会等待所有的Slave都告知已收到,且它只是接收,并不用等其完全执行且提交。
- 请写出MySQL主从复制的相关文件和线程名
#主库
1.主库的binlog:记录主库发变化的过程
2.dump线程:对比binlog是否更新,并将新数据的binlog发送给主库
#从库
1.IO线程:连接主库,接收主库发送过来新数据的binlog日志
2.SQL线程:执行主库传过来的新数据的binlog日志
3.relay-log(中继日志):存储所有主库传过来的binlog日志
4.master.info:记录上一次请求到主库的binlog名字和位置点
5.relay-log.info:记录上一次执行relay-log的位置点,下一次从该点执行后面的内容
- MySQL如何保证数据的安全性(scr)和一致性(acid)?
1.master配置
。。。
innodb_flush_log_at_trx_commit = 1
sync_binlog = 1
上述两个选项的作用是:保证每次事务提交后,都能'实时刷新到磁盘中',尤其是确保每次事务对应的binlog都能及时刷新到磁盘中,只要有了binlog,InnoDB就有办法做数据恢复,不至于导致主从复制的数据丢失。
2.slave配置
master_info_repository = "TABLE"
relay_log_info_repository = "TABLE"
relay_log_recovery = 1
上述前两个选项的作用是:确保在slave上和复制相关的元数据表也'采用InnoDB引擎',受到InnoDB事务安全的保护,而后一个选项的作用是'开启relay log自动修复机制',发生crash时,会自动判断哪些relay log需要重新从master上抓取回来再次应用,以此避免部分数据丢失的可能性。
- 请写出MySQL二进制日志的工作模式有几种?区别是什么?
1.statement 语句模式(mysql5.6的默认模式),记录数据库中所有操作过的的'SQL语句'(create insert alter drop)
优点:易读,相对于行级模式,占用磁盘空间小
缺点:不安全
2.row 行级模式
优点:安全
缺点:'不易读',相对于语句模式,占用磁盘大
3.mixed 混合模式
#配置文件设置
binlog_format="ROW"
binlog_format="MIXED"
binlog_format="STATEMENT"
- 请写出mysqldump常用参数及含义
1.不加参数:用于备份单个表
1)备份库
[root@db02 ~]# mysqldump ku > /tmp/ku.sql
2)备份表
[root@db02 ~]# mysqldump ku test > /tmp/ku.sql
3)备份多个表
[root@db02 ~]# mysqldump ku test test2 test3 > /tmp/ku.sql
#注意:当不加参数时命令后面跟的是库名,库的后面全都是必须是该库下面的表名
2.连接服务端参数(基本参数):-u -p -h -P -S
3.-A, --all-databases:全库备份
4.-B:指定库备份
[root@db01 ~]# mysqldump -uroot -p123 -B db1 > /backup/db1.sql
[root@db01 ~]# mysqldump -uroot -p123 -B db1 db2 > /backup/db1_db2.sql
5.-F:flush logs在备份时自动刷新binlog(不怎么常用)
[root@db01 backup]# mysqldump -uroot -p123 -A -F > /backup/full_2.sql
6.--master-data=2:备份时加入change master语句,在文件的22行,记录binlog的位置点
1)等于2:记录binlog信息,并注释(使用最多)
2)等于1:记录binlog信息,不注释(扩展多个从库的时候使用,不需要再指定位置点)
0)等于0:不记录binlog信息
[root@db01 backup]# mysqldump -uroot -p123 --master-data=2 >/backup/full.sql
7.--single-transaction:快照备份(该参数与 --master-data=2 一起,组成热备)
8.-d:仅表结构(x)
9.-t:仅数据(x)
10.-R, --routines:备份存储过程和函数数据
11.--triggers:备份触发器数据,也是个表(相当于外键)
12.gzip:压缩备份(备份库较大的时候使用)
#备份成压缩包
[root@db01 ~]# mysqldump -uroot -p123 -A | gzip > /backup/full.sql.gz
#恢复压缩包中的数据
[root@db03 ~]# zcat /tmp/full.sql.gz | mysql -uroot -p123
[root@db03 ~]# mysql -uroot -p123 < zcat /tmp/full.sql.gz
- 请写出如何截取二进制日志和中继日志?
#查看二进制日志找到位置点
[root@db02 data]# mysqlbinlog mysql-bin.000002
...
...
# at 4
...
...
# at 120 (位置点)
create database bl
/*!*/;
# at 208
use `bl`/*!*/;
SET TIMESTAMP=1595361536/*!*/;
create table bbl(id int)
/*!*/;
#将位置点之间的数据取出
[root@db02 data]# mysqlbinlog --start-position=631 --stop-position=978 mysql-bin.000002 > /tmp/hf.sql
- 如何在数据库中只备份单表?
备份单表test
[root@db02 ~]# mysqldump ku test > /tmp/ku.sql
- 如何在已运行在生产环境中的集群,添加一台从库?
1.主库查看binlog
mysql> show master status;
2.主库导出所有数据
[root@db03 data]# mysqldump -uroot -p -A --master-data=2 --single-transaction > /tmp/full.sql
3.从库配置server_id
[root@db02 ~]# vim /etc/my.cnf
[mysqld]
server_id=2
4.从库导入主库的数据
[root@db02 ~]# mysql -uroot -p123 < /tmp/full.sql
5.配置主从
mysql> change master to
-> master_host='172.16.1.53',
-> master_user='rep',
-> master_password='123',
-> master_log_file='mysql-bin.000003',
-> master_log_pos=326;
6.从库开线程
mysql> start slave;
Query OK, 0 rows affected (0.04 sec)
7.查看
mysql> show slave status\G
- 请写出MHA的工作原理?
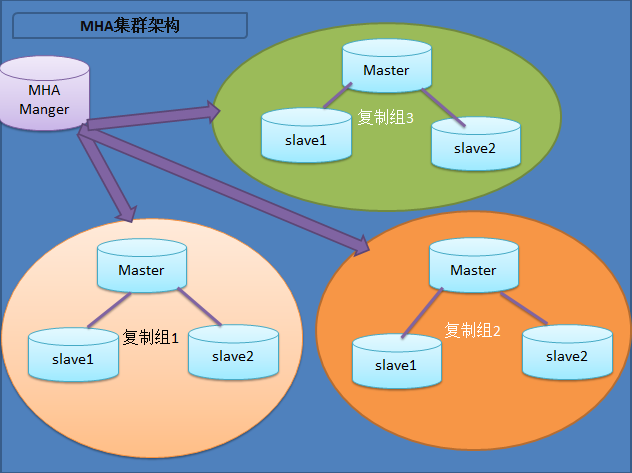
目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库,因为至少需要三台服务器,出于机器成本的考虑,淘宝也在该基础上进行了改造,目前淘宝TMHA已经支持一主一从。
我们自己使用其实也可以使用1主1从,但是master主机宕机后无法切换,以及无法补全binlog。master的mysqld进程crash后,还是可以切换成功,以及补全binlog的。
- 在阿里云中如何使用MHA?
使用弹性网卡作为MHA中的VIP,当数据库挂掉,则解除弹性网卡,绑定到另一台机器上
- 请写出MySQL 主从复制IO线程报错的排查思路?
mysql> show slave status\G
Slave_IO_Running: No
Slave_SQL_Running: Yes
mysql> show slave status\G
Slave_IO_Running: Connecting
Slave_SQL_Running: Yes
#排查思路
1.网络
[root@db02 ~]# ping 172.16.1.53
2.端口
[root@db02 ~]# telnet 172.16.1.53 3306
3.防火墙(Connecting)
4.主从授权的用户错误
5.反向解析
skip-name-resolve
6.UUID或server_id相同
- 请写出MySQL 主从复制SQL线程报错的解决办法?
mysql> show slave status\G
Slave_IO_Running: Yes
Slave_SQL_Running: No
#原因:
1.主库有的数据,从库没有
2.从库有的数据,主库没有
总而言之就是主从才能够数据不一致,create drop insert 导致SQL线程断开连接
#处理方式一:自欺欺人
1.临时停止同步
mysql> stop slave;
2.将同步指针向下移动一个(需要重复操作,断一次跳一次)
mysql> set global sql_slave_skip_counter=1;
3.开启同步
mysql> start slave;
#处理方式二:掩耳盗铃
1.编辑配置文件
[root@db01 ~]# vim /etc/my.cnf
#在[mysqld]标签下添加以下参数
slave-skip-errors=1032,1062,1007
#处理方式三:正解
重新同步数据,重新做主从(重新获取binlog位置点即可)
# mysql主从复制的意义就是主库和从库数据的一致,如果配置好主从之后,主从数据还不一致,那么主从就失去意义了
- 如何设置MySQL的 会话变量及全局变量?
永久设置
[msyqld]
autocommit=1
session autocommit=1;
临时设置
#session变量(会话变量)
set session autocommit=1;
set autocommit=1;
#全局变量
set global autocommit=1;
- 什么是水平分表?什么是垂直分表?表真的分了么分成什么样的了?
1,水平分表:
例:QQ的登录表。假设QQ的用户有100亿,如果只有一张表,每个用户登录的时候数据库都要从这100亿中查找,会很慢很慢。如果将这一张表分成100份,每张表有1亿条,就小了很多,比如qq0,qq1,qq1...qq99表。
用户登录的时候,可以将用户的id%100,那么会得到0-99的数,查询表的时候,将表名qq跟取模的数连接起来,就构建了表名。比如用户id为1000086,除以100取模得86,那么就到qq86表查询,查询的时间将会大大缩短。这就是水平分割。
#利用触发器可以实现水平分表
#
2,垂直分表:
垂直分割指的是:表的记录并不多,但是字段却很长,表占用空间很大,检索表的时候需要执行大量的IO,严重降低了性能。这时需要把大的字段拆分到另一个表,并且该表与原表是一对一的关系。
例如学生答题表aa:有如下字段:
Id name 分数 题目 回答
其中题目和回答是比较大的字段,id name 分数比较小。
如果我们只想查询id为8的学生的分数:select 分数 from aa where id = 8;
虽然知识查询分数,但是题目和回答这两个大字段也是要被扫描的,很消耗性能。
但是我们只关心分数,并不想查询题目和回答。这就可以使用'垂直分割'。
我们可以把题目单独放到一张表中,通过id与aa表建立一对一的关系,同样将回答单独放到一张表中。这样我们插叙tt中的分数的时候就不会扫描题目和回答了。
- 请写出,你在企业中,MySQL遇到主从数据不一致问题时,是如何解决的?
#原因:
1.网络的延迟
2.主从两台机器的负载不一致
3.max_allowed_packet设置不一致
4.自增键不一致
5.双一标准同步参数设置问题
6.版本不一致
#必须重新做主从
#主库
1.配置文件
[root@db03 ~]# vim /etc/my.cnf
[mysqld]
server_id=1
log_bin=/service/mysql/data/mysql-bin
2.授权用户
mysql> grant replication slave on *.* to rep@'172.16.1.%' identified by '123';
3.查看binlog
show master status;
4.主库导出所有数据
[root@db03 data]# mysqldump -uroot -p -A --master-data=2 --single-transaction > /tmp/full.sql
#从库
1.配置文件
[root@db02 ~]# vim /etc/my.cnf
[mysqld]
server_id=2
2.同步主库数据
[root@db02 ~]# mysql -uroot -p123 < /tmp/full.sql
3.配置主从
mysql> change master to
-> master_host='172.16.1.53',
-> master_user='rep',
-> master_password='123',
-> master_log_file='mysql-bin.000003',
-> master_log_pos=326;
4.开启线程
mysql> start slave;
- 什么是存储过程?用什么来调用?
答:存储过程是一个预编译的SQL语句,比如一些场景的sql比较复杂,并且需要经常使用或者多次使用的。
存储过程的优点是说只需创建一次编译一次,以后在该程序中就可以多次直接调用。
如果一个sql是经常需要操作的,并且逻辑不容易改变,使用存储过程比单纯SQL语句执行要快,因为sql每次查询而且都需要编译。而且网络开销也大,
存储过程只需要传一个名字,在数据库调用就行了,而且这样程序可移植高。
#存储过程优缺点
#优点:
1.在生产环境下,可以通过直接修改存储过程的方式修改业务逻辑或bug,而不用重启服务器。
2.执行速度快,存储过程经过编译之后会比单独一条一条编译执行要快很多。
3.减少网络传输流量。
4.便于开发者或DBA使用和维护。
5.在相同数据库语法的情况下,改善了可移植性。
#缺点:
1.过程化编程,复杂业务处理的维护成本高。
2.调试不便。
3.因为不同数据库语法不一致,不同数据库之间可移植性差。
调用:
1)可以用一个命令对象来调用存储过程。
2)可以供外部程序调用,比如:java程序 PHP程序
#编辑存储过程
//创建存储过程
CREATE PROCEDURE userData(
IN id INT
)
BEGIN
SELECT * from userdata WHERE userflag = id;
END;
其中IN是传进去的变量;
drop procedure userData;//销毁这个存储过程
call userData(2) //调用存储过程
- 什么是触发器?触发器的作用是什么?
分类:
rs触发器
jk触发器
d触发器
t触发器
#单个执行条件的触发器
CREATE TRIGGER trigger_name trigger_time trigger_event ON tb_name FOR EACH ROW trigger_stmt;
trigger_name:触发器的名称
tirgger_time:触发时机,为BEFORE或者AFTER
trigger_event:触发事件,为'INSERT、DELETE或者UPDATE'
FOR EACH ROW表示任何一条记录上的操作满足触发事件都会触发该触发器
tb_name:表示建立触发器的表明,就是在'哪张表'上建立触发器
trigger_stmt:触发器的'程序体',可以是一条SQL语句或者是用'BEGIN和END'包含的多条语句
所以可以说MySQL创建以下六种触发器:
BEFORE INSERT,BEFORE DELETE,BEFORE UPDATE
AFTER INSERT,AFTER DELETE,AFTER UPDATE
#实例
mysql> show databases;
进入库,不能是系统库
mysql> use bb;
创建两个要关联的表
mysql> create table tg(id int);
mysql> create table cs(id int);
创建触发器(#单个执行条件)
mysql> CREATE TRIGGER trigger_syy after insert ON tg FOR EACH ROW insert cs values(233);
验证触发器
mysql> insert tg values(111);
mysql> select * from tg;
+------+
| id |
+------+
| 111 |
+------+
mysql> select * from cs;
+------+
| id |
+------+
| 233 |
+------+
#多个执行事务的触发器
\d ||;
CREATE TRIGGER 触发器名 BEFORE|AFTER 触发事件
ON 表名 FOR EACH ROW
BEGIN
执行语句列表
END
\d ;
#查看触发器
mysql> SHOW TRIGGERS\G
*************************** 1. row ***************************
Trigger: trigger_syy
Event: INSERT
Table: tg
Statement: insert cs values(233)
Timing: AFTER
Created: NULL
sql_mode: STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION
Definer: root@localhost
character_set_client: utf8
collation_connection: utf8_general_ci
Database Collation: latin1_swedish_ci
#删除触发器
mysql> drop TRIGGER trigger_syy;
#触发器作用
1.安全性。可以基于数据库的值使用户具有操作数据库的某种权利。
可以基于时间限制用户的操作,例如不允许下班后和节假日修改数据库数据。
可以基于数据库中的数据限制用户的操作,例如不允许股票的价格的升幅一次超过10%。
2.审计。可以跟踪用户对数据库的操作。
审计用户操作数据库的语句。
把用户对数据库的更新写入审计表。
3.实现复杂的数据完整性规则
实现非标准的数据完整性检查和约束。触发器可产生比规则更为复杂的限制。与规则不同,触发器可以引用列或数据库对象。例如,触发器可回退任何企图吃进超过自己保证金的期货。
提供可变的缺省值。
4.实现复杂的非标准的数据库相关完整性规则。触发器可以对数据库中相关的表进行连环更新。例如,在auths表author_code列上的删除触发器可导致相应删除在其它表中的与之匹配的行。
在修改或删除时级联修改或删除其它表中的与之匹配的行。
在修改或删除时把其它表中的与之匹配的行设成NULL值。
在修改或删除时把其它表中的与之匹配的行级联设成缺省值。
触发器能够拒绝或回退那些破坏相关完整性的变化,取消试图进行数据更新的事务。当插入一个与其主健不匹配的外部键时,这种触发器会起作用。例如,可以在books.author_code 列上生成一个插入触发器,如果新值与auths.author_code列中的某值不匹配时,插入被回退。
5.'同步实时'地复制表中的数据。
6.'自动计算数据值',如果数据的值达到了一定的要求,则进行特定的处理。例如,如果公司的帐号上的资金低于5万元则立即给财务人员发送警告数据。
#扩展
replace语句在一般的情况下和insert差不多,但是如果表中存在primary 或者unique索引的时候,如果插入的数据和原来的primary key或者unique相同的时候,会删除原来的数据,然后增加一条新的数据,所以有的时候执行一条replace语句相当于执行了一条delete和insert语句。
- 主键和唯一键还有候选键有什么区别?
主键:一个表只有一个主键,主键是唯一且非空的
唯一键:唯一键在一个表中可以有多个,数据是唯一的,可以为空
候选键:主键也是候选键,按照惯例,候选键可以被指定为主键,并且可以用于任何外键引用。
#数据库中候选键的定义:
候选键是对具有关系键特性的一个或多个属性(组)的统称。
它需要同时满足下列两个条件:
1.这个属性集合始终能够确保在关系中能唯一标识元组。
2.在这个属性集合中找不出合适的子集能够满足条件。
- AUTO_INCREMENT 可不可以设置最大值,可以的话怎么设置
可在建表时可用"AUTO_INCREMENT=n"选项来指定一个自增的初始值
可用alter table table_name AUTO_INCREMENT=n命令来重设自增的起始值
没有最大值上限。
- 查询时运算符都有哪些
#查看数据排序(order by)
升序
mysql> select Name,Population from city order by Population;
降序
mysql> select Name,Population from city order by Population desc;
#查看前十条数据(limit N)
mysql> select population from city order by population limit 10;
mysql> select Name,Population from city order by Population desc limit 10;
#按照步长查询数据,起始,步长(n+1--N)(#翻页)
select Name,Population from city order by xx desc limit 10,50;
select id,Name,Population from city order by xx desc limit 10,50;
#命令行查看(脚本使用)
mysql -uroot -p123 -e 'use world;select id,name from city limit 0,100'
mysql -uroot -p123 -e 'select * from world.city'
#2.查询中国的城市人口
mysql> select name,population from city where CountryCode='CHN';
#3.查询黑龙江人口数量
mysql> select name,population from city where countrycode='CHN' and District='heilongjiang';
#4.查询中国人口数量小于100000的城市
mysql> select name,population from city where countrycode='CHN' and population < 100000;
#5.模糊匹配(值:like %)(like速度慢)
#匹配以N结尾的数据
mysql> select name,countrycode from city where countrycode like '%N';
#匹配以N开头的数据
mysql> select name,countrycode from city where countrycode like 'N%';
#匹配包含N的数据
mysql> select name,countrycode from city where countrycode like '%N%';
#6.查询中国或美国的人口数量
#使用 ...or...
mysql> select name,population from city where countrycode = 'CHN' or countrycode = 'USA';
#使用in(...)
mysql> select name,population from city where countrycode in ('CHN','USA');
#使用(select ...union all ...select ...)(查询速度最快)
mysql> select name,population from city where countrycode = 'CHN' union all select name,population from city where countrycode = 'USA';
- 列出我们用过的函数(最少4个)
1.数据数量
mysql> select count(*) from css;
+----------+
| count(*) |
+----------+
| 2 |
+----------+
2.数据库版本号
mysql> select version();
+------------+
| version() |
+------------+
| 5.6.46-log |
+------------+
3.开机到现在为止MySQL服务的连接次数
mysql> select connection_id();
+-----------------+
| connection_id() |
+-----------------+
| 3 |
+-----------------+
4.查看当前数据库名
mysql> select database();
+------------+
| database() |
+------------+
| cs |
+------------+
5.查看当前连接数据库的用户
mysql> select user();
+----------------+
| user() |
+----------------+
| root@localhost |
+----------------+
6.查看当前字符集
mysql> show charset;
+----------+-----------------------------+---------------------+--------+
| Charset | Description | Default collation | Maxlen |
+----------+-----------------------------+---------------------+--------+
| big5 | Big5 Traditional Chinese | big5_chinese_ci | 2 |
| dec8 | DEC West European | dec8_swedish_ci | 1 |
+----------+-----------------------------+---------------------+--------+
查看字符集是否支持大小写
mysql> show collation;
+--------------------------+----------+-----+---------+----------+---------+
| Collation | Charset | Id | Default | Compiled | Sortlen |
+--------------------------+----------+-----+---------+----------+---------+
| big5_chinese_ci | big5 | 1 | Yes | Yes | 1 |
| big5_bin | big5 | 84 | | Yes | 1 |
+--------------------------+----------+-----+---------+----------+---------+
7.查看最后自动生成的id的值
mysql> select * from css;
+-----+------+
| id | name |
+-----+------+
| 1 | NULL |
| 100 | NULL |
| 111 | ccc |
+-----+------+
3 rows in set (0.00 sec)
mysql> insert css(name) values('bbb');
Query OK, 1 row affected (0.00 sec)
mysql> select last_insert_id();
+------------------+
| last_insert_id() |
+------------------+
| 112 |
+------------------+
password() #密码加密
database() #当前数据库
mysql> select database();
now() #当前时间
mysql> insert tt values(now());
count() #统计数量
mysql> select distinct(Population) from city;
distinct() #数据去重后数量
mysql> select distinct(Population) from city;
max() #最大值
mysql> select max(Population) from city;
min() #最小值
mysql> select min(Population) from city;
sum() #求和
mysql> select sum(Population) from city;
avg() #求平均值
mysql> select avg(Population) from city;
CONCAT(A, B) #连接两个字符串值以创建单个字符串输出。通常用于将两个或多个字段合并为一个字段。
mysql> select concat(id,name) from city;
FORMAT(X, D) #格式化数字X到D有效数字。
CURRDATE(), CURRTIME() #返回当前日期或时间。
MONTH(),DAY(),YEAR(),WEEK(),WEEKDAY() #从日期值中提取给定数据。
HOUR(),MINUTE(),SECOND() #从时间值中提取给定数据。
DATEDIFF(A,B) #确定两个日期之间的差异,通常用于计算年龄
SUBTIMES(A,B) #确定两次之间的差异。
FROMDAYS(INT) #将整数天数转换为日期值。
- 怎么查看一个表的字符集(最少两种方法)
| 语言 | 字符集 | 正式名称 |
|---|---|---|
| 英语、西欧语 | ASCII,ISO-8859-1 | MBCS 多字节 |
| 简体中文 | GB2312 | MBCS 多字节 |
| 繁体中文 | BIG5 | MBCS 多字节 |
| 简繁中文 | GBK | MBCS 多字节 |
| 中文、日文及朝鲜语 | GB18030 | MBCS 多字节 |
| 各国语言 | UNICODE,UCS | DBCS 宽字节 |
mysql> show create table css;
| css | CREATE TABLE `css` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(10) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=113 DEFAULT CHARSET=latin1 |
mysql> desc css;
+-------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(10) | YES | | NULL | |
+-------+-------------+------+-----+---------+----------------+
#字符集常用的种类:
1.ascii:共收录128个字符,包括空格、标点符号、数字、大小写字母和一些不可见字符。由于总共才128个字符,所以可以使用'1个字节'来进行编码
2.latin1:共收录256个字符,是在ASCII字符集的基础上又扩充了128个西欧常用字符(包括德法两国的字母),也可以使用'1个字节'来进行编码。,'兼容ASCII字符集'
3.gb2312: 收录了汉字以及拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母。其中收录汉字6763个,其他文字符号682个,'兼容ASCII字符集'。这是一个变长字符集,如果该字符在ascii字符集中,则采用1字节编码,否则采用两字节。
4.gbk: GBK是在gb2312基础上扩容后的标准。收录了所有的中文字符。同样的,这是一个变长字符集,如果该字符在ascii字符集中,则采用1字节编码,否则采用两字节。
5.utf8和utf8mb4: 收录地球上能想到的所有字符,而且还在不断扩充。这种字符集兼容ASCII字符集,采用变长编码方式,编码一个字符需要使用'1~4个字节'。MySQL为了节省空间,其中的'utf8是标准 UTF8 阉割后的',只有1~3字节编码的字符集,基本包含了所有常用的字符。如果还要'使用 emoji 表情,那么需要使用utf8mb4',这个是完整的 UTF8 字符集。
6.utf16: 不同于utf8,utf16用两个字节或者四个字节编码字符,可以理解为utf8的不节省空间的一种形式
7.utf32: 固定用四个字节编码字符,可以理解为utf8的不节省空间的一种形式
#兼容关系
iso8859 > ASCII
gbk > GB12345-90 > GB2312 > ASCII
- B+tree索引对比Btree索引在哪里进行了优化
#索引
1.索引就好比一本书的目录,它能让你更快的找到自己想要的内容。
2.索引让获取的数据更有目的性,从而'提高数据库检索数据的性能'。
#索引的种类
1.BTREE:
B+tree 叶节点有快速通道,速度更快一点
B*tree 枝节点叶节点都有快速通道,速度更快
2.HASH HASH索引(memery存储引擎才支持)
3.FULLTEXT: 全文索引(myisam存储引擎才支持)速度较慢
4.RTREE R树索引
#根据磁盘吞吐量(IO)判断索引检索速度
select * from table where id=38;
#BTREE
根节点
枝节点
叶节点 #存储真实数据
- Mysql优化该怎么做?
1. 为查询缓存优化你的查询
// 查询缓存不开启
$r = mysql_query("SELECT username FROM user WHERE signup_date >= CURDATE()");
// 开启查询缓存
$today = date("Y-m-d");
$r = mysql_query("SELECT username FROM user WHERE signup_date >= '$today'");
2. EXPLAIN 你的 SELECT 查询,使用 EXPLAIN 关键字可以让你知道MySQL是如何处理你的SQL语句的。这可以帮你分析你的查询语句或是表结构的性能瓶颈。
EXPLAIN 的查询结果还会告诉你你的索引主键被如何利用的,你的数据表是如何被搜索和排序的
mysql> mysql> explain select * from css;
+----+-------------+-------+------+---------------+------+---------+------+------+----
| id | select_type | table | type | possible_keys |'key' | key_len | ref |'rows'| Ext
+----+-------------+-------+------+---------------+------+---------+------+------+----
| 1 | SIMPLE | css | ALL | NULL | NULL | NULL | NULL | 4 | NUL
+----+-------------+-------+------+---------------+------+---------+------+------+----
1 row in set (0.00 sec)
3. 当只要一行数据时使用 LIMIT 1
当你查询表的有些时候,你已经知道结果只会有一条结果,在这种情况下,加上 LIMIT 1 可以增加性能。这样一样,MySQL数据库引擎会在找到一条数据后停止搜索,而不是继续往后查找下一条符合记录的数据。
SELECT * FROM user WHERE country = 'China' LIMIT 1;
4. 为搜索字段建索引
索引并不一定就是给主键或是唯一的字段。如果在你的表中,有某个字段你总要会经常用来做搜索,那么,请为其建立索引吧。
#已存在的表才能创建普通索引
alter table city add index in_name(name);
5. 在Join表的时候使用相当类型的例,并将其索引
如果你的应用程序有很多 JOIN 查询,你应该确认两个表中Join的字段是被建过索引的。这样,MySQL内部会启动为你'优化'Join的SQL语句的机制。
而且,这些被用来Join的字段,应该是相同的类型的。例如:如果你要把 DECIMAL 字段和一个 INT 字段Join在一起,MySQL就无法使用它们的索引。对于那些STRING类型,还需要有'相同的字符集'才行。(两个表的字符集有可能不一样)
6. 千万不要 ORDER BY RAND(),如果你真的想把返回的数据行打乱了,你有N种方法可以达到这个目的。这样使用只让你的数据库的性能呈指数级的下降。这里的问题是:MySQL会不得不去执行RAND()函数(很耗CPU时间),而且这是为了每一行记录去记行,然后再对其排序。就算是你用了Limit 1也无济于事(因为要排序)
mysql> select * from user order by rand();
7. 避免 SELECT *
从数据库里读出越多的数据,那么查询就会变得越慢。并且,如果你的数据库服务器和WEB服务器是两台独立的服务器的话,这还会增加网络传输的负载
8. 永远为每张表设置一个ID
我们应该为数据库里的每张表都设置一个ID做为其主键,
11. 尽可能的使用 NOT NULL
除非你有一个很特别的原因去使用 NULL 值,你应该总是让你的字段保持 NOT NULL
15. 固定长度的表会更快
固定长度的表会提高性能,因为MySQL搜寻得会更快一些,因为这些固定的长度是很容易计算下一个数据的偏移量的,所以读取的自然也会很快。而如果字段不是定长的,那么,每一次要找下一条的话,需要程序找到主键。
并且,固定长度的表也更容易被缓存和重建。不过,唯一的副作用是,固定长度的字段会浪费一些空间,因为定长的字段无论你用不用,他都是要分配那么多的空间
16. 垂直分割
“垂直分割”是一种把数据库中的表按列变成几张表的方法,这样可以降低表的复杂度和字段的数目,从而达到优化的目的
17. 拆分大的 DELETE 或 INSERT 语句
如果你需要在一个在线的网站上去执行一个大的 DELETE 或 INSERT 查询,你需要非常小心,要避免你的操作让你的整个网站停止相应。因为这两个操作是会锁表的,表一锁住了,别的操作都进不来了。
Apache 会有很多的子进程或线程。所以,其工作起来相当有效率,而我们的服务器也不希望有太多的子进程,线程和数据库链接,这是极大的占服务器资源的事情,尤其是内存。
如果你把你的表锁上一段时间,比如30秒钟,那么对于一个有很高访问量的站点来说,这30秒所积累的访问进程/线程,数据库链接,打开的文件数,可能不仅仅会让你泊WEB服务Crash,还可能会让你的整台服务器马上掛了。
所以,如果你有一个大的处理,你定你一定把其拆分,使用 LIMIT 条件是一个好的方法。
- SQL语言包括哪几部分?每部分都有哪些命令?
DDL: 数据定义语言 Data Definition Language (create drop)
DCL: 数据控制语言 Data Control Language (grant revoke)
DML: 数据操作语言 Data Manipulate Language (insert delete...)
DQL: 数据查询语言 Data Query Language (select)
-
请说明主键、外键和索引的区别?
主键、外键和索引的区别?
主键 外键 索引 定义: 唯一标识一条记录,不能有重复的,不允许为空 表的外键是另一表的主键, 外键可以有重复的, 可以是空值 该字段没有重复值,但可以有一个空值 作用: 用来保证数据完整性 用来和其他表建立联系用的 是提高查询排序的速度 个数: 主键只能有一个 一个表可以有多个外键 一个表可以有多个惟一索引
#主键
关系型数据库中的一条记录中有若干个属性,若其中某一个属性组(注意是组)能唯一标识一条记录,该属性组就可以成为一个主键
#外键
外键用于与另一张表的关联。是能确定另一张表记录的字段,用于保持数据的一致性。
比如,A表中的一个字段,是B表的主键,那他就可以是A表的外键。
主键和外键是把多个表组织为一个有效的关系数据库的粘合剂。'主键和外键'的设计对物理数据库的性能和可用性都有着决定性的影响。
#索引
唯一地确定数据表中的一条记录的字段或者字段组合表达式
前提
1. 表类型必须为 InnoDB 俩个表都要是 InnoDB
2.外键必须建立索引 如果 4.1.2 以后得版本 建立外键自动创建索引
3..外键关系的两个表的列必须是数据类型相似,也就是可以相互转换类型的列,比如int和tinyint可以,而int和char则不可以
alter table OrderInfo
add constraint 外键名称
foreign key (userID)
references UserInfo;
#应用范畴不同:
主键是用来标记数据唯一性的,而索引是加快查询速度的,外键是为了关联两个表的
#种类不同:
根据数据库的功能,可以在数据库设计器中创建三种索引:唯一索引、主键索引和聚集索引。而主键只是其中的一种。外键与他们都不同
#创建方式不同
主键只能创建一个,索引有多种类型可以创建多种,外键不能在自己当前表创建
1.主键:是一种特殊的唯一索引,在一张表中只能定义一个主键索引,主键用于唯一标识一条记录,使用关键字 PRIMARY KEY 来创建。对于关系表,有个很重要的约束,就是任意两条记录不能重复。不能重复不是指两条记录不完全相同,而是指能够通过某个字段唯一区分出不同的记录,这个字段被称为主键。
2.索引:是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。可以对一张表创建多个索引。索引的优点是提高了查询效率,缺点是在插入、更新和删除记录时,需要同时修改索引,因此,索引越多,插入、更新和删除记录的速度就越慢。
3.外键:在students表中,通过class_id的字段,可以把数据与另一张表关联起来,这种列称为外键;外键约束会降低数据库的性能,大部分互联网应用程序为了追求速度,并不设置外键,而是仅靠应用程序自身来保证逻辑的正确性
- 索引有哪些优缺点?
索引的优缺点?
1、优点:
a)可以保证数据库表中每一行的数据的'唯一性'
b)可以大大加快数据的'索引速度'
c)'加速表与表之间的连接',物别是在实现数据的参考完事性方面特别有意义
d)在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间
f)通过使用索引,可以在时间查询的过程中,使用优化隐藏器,提高系统的性能
2、 缺点:
a) '创建索引和维护索引'要耗费时间,这种时间随着数据量的增加而增加
b) 索引需要'占物理空间',除了数据表占用数据空间之外,每一个索引还要占用一定的物理空间,如果需要建立聚簇索引,那么需要占用的空间会更大
c) 以表中的数据进行增、删、改的时候,'索引也要动态的维护',这就降低了整数的维护速度
建立索引的原则
e) 在'经常需要搜索的列'上,可以加快搜索的速度
f) 在作为主键的列上,强制该列的'唯一性'和组织表中数据的排列结构
g) 在经常用在连接的列上,这些列主要是一'外键',可以加快连接的速度
h) 在经常需要根据范围进行搜索的列上创建索引,国为索引已经排序,其指定的范围是连续的
i) 在经常需要排序的列上,因为索引已经排序,这样井底可以利用索引的排序,加快排序井底时间
j) 在经常使用在'where子句'中的列上,加快条件的判断速度
- 索引有哪几种类型?
#常见的索引扫描类型,前提条件,查询的条件必须有索引
1.index 全索引扫描
2.range 范围查询
3.ref 精确查找
4.eq_ref 类似于ref,使用join on的时候
5.const 查询的条件的列是唯一索引或主键索引
6.system 跟const同级别
7.null 执行过程中不访问表或者索引
- 请写出给table表id字段添加索引和删除索引的命令?
#主键索引
alter table test1 add primary key pri_id(id);
#唯一键索引
create table test2(id int unique key not null auto_increment comment '学号');
alter table test2 add unique key uni_key(name);
#已存在的表才能创建普通索引
alter table city add index in_name(name);
create index innn_a4 on test3(a6);
#删除主键索引
mysql> alter table test3 drop primary key;
#删除唯一键索引,普通索引
mysql> alter table city drop index index_name;
- 一般创建索引你会考虑到那些?
#主键索引 > 唯一键索引 > 普通索引优先级(优先级高的有效 显示)
#主键索引只能创建一个,唯一键索引能创建多个
#唯一键索引速度最快,能创建唯一键索引就创建 唯一键索引
#不经常用的字段,不要创建索引
#删除索引的时候按照索引的名字删除
#索引的名字不用指定,索引名=字段名 == 索引名_n
1.选择唯一性索引
2.为经常需要排序、分组和联合操作的字段建立索引
3.对于查询操作中频繁使用的列建立索引,不对很少或从来不作为查询条件的列建立索引
4.限制索引的数目
5.尽量使用数据量少的索引
6.对于数据较长的列,尽量使用前缀索引
7.删除不再使用或者很少使用的索引
8.尽量的扩展索引,不要新建索引
9.当单个索引字段查询数据很多,区分度都不是很大时,则需要考虑建立联合索引来提高查询效率
10.先存数据,再建索引
11.不要对规模小的数据表建立索引,数据量超过300的表应该有索引;
12.在不同值较少的字段上不必要建立索引,如性别字段
13.经常出现在Where子句中的字段,特别是大表的字段,应该建立索引;
14.索引应该建在选择性高的字段上;
15.在SQL语句中经常进行GROUP BY、ORDER BY的字段上建立索引
- 什么是临时表
MySQL 临时表在我们需要保存一些临时数据时是非常有用的。临时表只在当前连接可见,当关闭连接时,Mysql会自动删除表并释放所有空间。
MySQL临时表只在当前连接可见,如果你使用PHP脚本来创建MySQL临时表,那每当PHP脚本执行完成后,该临时表也会'自动销毁'。
如果你使用了其他MySQL客户端程序连接MySQL数据库服务器来创建临时表,那么只有在关闭客户端程序时才会销毁临时表,当然你也可以'手动销毁'。
- 数据库分几种?分别都有哪些?
关系型数据库和非关系型数据库
#关系型数据库
MySQL、Oracle、mariadb
#非关系型数据库
1.键值存储数据库(key-value)
Memcached、Redis
2.列存储(Column-oriented)数据库
HBase
3.面向文档(Document-Oriented)数据库
MongoDB
4.搜索引擎式数据库
Elasticsearch
-oracle: 1.数据库安全性很高,很适合做大型数据库
-mysql: MySQL是一个开放源码的小型关系型数据库管理系统
Access是一种桌面数据库,只适合数据量少的应用,在处理少量数据和单机访问的数据库时是很好的,效率也很高。 但是它的同时访问客户端不能多于4个。
- 什么情况下索引会不生效
1.没有查询条件,或者查询条件没有建索引
2.查询的结果集是原表中的大部分数据,25%以上
3.索引本身失效
4.查询条件使用函数在索引列上或者对索引列进行运算,运算包括(+,-,*等)
5.隐式转换,会导致索引失效
6.<> 和 not in 和 or 也不走索引
7.like模糊查询 % 位置决定走不走索引
8.联合索引查询的条件不是按照顺序排列的,或者条件没有联合索引的第一个列
mysql> show status like 'handler_read%';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| Handler_read_first | 5 |
| Handler_read_key | 6 | #这个值越高越好
| Handler_read_last | 0 |
| Handler_read_next | 6 |
| Handler_read_prev | 0 |
| Handler_read_rnd | 18 |
| Handler_read_rnd_next | 712 | #这个值越低越好
+-----------------------+-------+
- 一条sql语句执行时间过长你会优化?
存储引擎层:
从 MySQL 5.5.5 版本开始InnoDB成为了默认存储引擎(架构模式是插件式的,所以一个数据库可能有多个引擎)
Server 层:
1)连接器:连接器负责跟客户端建立连接、获取权限、维持和管理连接,客户端如果太长时间没动静,连接器就会自动将它断开。这个时间是由参数 wait_timeout 控制的,默认值是8小时,连接时存在长连接和短连接模式
短连接:是指在执行完几个语句过后便断开连接,之后要进行操作会重新连接
长连接:是指在执行语句时一直共用一个通道也就是一个连接(建议定期断开,否则内存占用过大会导致异常重启)
2)查询缓存:在拿到一条语句之后会先到查询缓存看看,之前知否执行过这条语句,之前执行过的语句和结果会以key-value 对的形式,被直接缓存在内存中,如果存在则会直接返回
但是大多数情况下不要使用查询缓存,因为查询缓存往往弊大于利。只要有对一个表的更新,这个表上所有的查询缓存都会被清空,所以MySQL 8.0 版本直接将查询缓存的整块功能删掉,也就是没有了
3)分析器:对SQL语句进行 词法(关键字判断) 语法(是否符合标准) 语义(整体语句意思)分析 这样机器就是你要做什么
4)优化器:选择适合索引(你得建立索引) 选择执行效率高的方案 该怎么做
5)执行器:先判断是否拥有相应的权限(在优化器之前也会调用 precheck 验证权限) 然后就开始执行 流程如下:
例:select * from T where ID=10;
调用 InnoDB 引擎接口取这个表的第一行,判断 ID 值是不是 10,如果不是则跳过,如果是则将这行存在结果集中;
调用引擎接口取“下一行”,重复相同的判断逻辑,直到取到这个表的最后一行。
执行器 将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端。
- 你们数据库不支持emoji表情,你该怎么办?怎么操作?
#项目背景
公司原有的架构:一个展示型的网站,LAMT,MySQL5.1.77版本(MYISAM),50M数据量。
#问题
1、表级锁:对表中任意一行数据修改类操作时,整个表都会锁定,对其他行的操作都不能同时进行。
2、不支持故障自动恢复(CSR):当断电时有可能会出现数据损坏或丢失的问题。
#解决方案
提建议将现有的MYISAM引擎替换为Innodb,将mysql数据库版本替换为5.6.38
1.如果使用MYISAM会产生'小问题',性能安全不能得到保证,使用innodb可以解决这个问题。
2.mysql数据库5.1.77版本对于innodb引擎支持不够完善,5.6.38版本对innodb支持非常完善了。
-------------------------------------------------------------------------
#计划
1.准备一台新的数据库,版本为5.6.38
2.对数据库备份数据(使用-B可以导出指定库)(打点:--master-data=2)
[root@db01 ~]# mysqldump -uroot -p123 --triggers -R --master-data=2 -B xx >/tmp/full.sql
3.将备份的数据库传到新数据库
scp、rsync、NFS、导出导入、sftp
4.修改sql中的存储引擎
sed -i 's#MyISAM#InnoDB#g' /tmp/full.sql
5.将修改后的sql文件导入新数据(要保证新库中没有该重名的库)
mysql < /tmp/full.sql
source
\.
6.将代码中的数据库地址修改为新的数据库地址
7.通过binlog将数据迁移过程中新生成的数据也倒入新库
#数据库更新的思路
1.数据迁移
2.让开发做新老数据可以一起访问的功能
#指定--master-data=2,配置文件必须开启bin-log
- 当服务器出现问题,你该如何入手排查问题,排查思路是什么?
一、尽可能搞清楚问题的前因后果
不要一下子就扎到服务器前面,你需要先搞明白对'这台服务器有多少已知的情况',还有故障的具体情况。不然你很可能就是在无的放矢
必须搞清楚的问题有:
'故障的表现'是什么?无响应?报错?
故障是'什么时候发现的'?
故障是否可重现?
有没有出现的'规律'(比如每小时出现一次)
'最后一次'对整个平台进行更新的内容是什么(代码、服务器等)?
'故障影响'的特定用户群是什么样的(已登录的, 退出的, 某个地域的…)?
基础架构(物理的、逻辑的)的文档是否能找到?
是否有'监控'平台可用? (比如Munin、Zabbix、 Nagios、 New Relic… 什么都可以)
是否有'日志'可以查看?. (比如Loggly、Airbrake、 Graylog…)
最后两个是最方便的信息来源,不过别抱太大希望,基本上它们都不会有。只能再继续摸索了。
二、有谁在?
$ w
$ last
用这两个命令看看都有谁在线,有哪些用户访问过。这不是什么关键步骤,不过最好别在其他用户正干活的时候来调试系统。有道是一山不容二虎嘛。(ne cook in the kitchen is enough.)
三、之前发生了什么?
$ history
查看一下之前服务器上执行过的命令。看一下总是没错的,加上前面看的谁登录过的信息,应该有点用。另外作为admin要注意,不要利用自己的权限去侵犯别人的隐私哦。
到这里先提醒一下,等会你可能会需要更新 HISTTIMEFORMAT 环境变量来显示这些命令被执行的时间。对要不然光看到一堆不知道啥时候执行的命令,同样会令人抓狂的。
四、现在在运行的'进程'是啥?
$ pstree -a
$ ps aux
这都是查看现有进程的。 ps aux 的结果比较杂乱, pstree -a 的结果比较简单明了,可以看到正在运行的进程及相关用户。
五、'监听'的网络服务
$ netstat -ntlp
$ netstat -nulp
$ netstat -nxlp
我一般都分开运行这三个命令,不想一下子看到列出一大堆所有的服务。netstat -nalp倒也可以。不过我绝不会用 numeric 选项 (鄙人一点浅薄的看法:IP 地址看起来更方便)。
找到所有正在运行的服务,检查它们是否应该运行。查看各个监听端口。在netstat显示的服务列表中的PID 和 ps aux 进程列表中的是一样的。
如果服务器上有好几个Java或者Erlang什么的进程在同时运行,能够按PID分别找到每个进程就很重要了。
通常我们建议每台服务器上运行的服务少一点,必要时可以增加服务器。如果你看到一台服务器上有三四十个监听端口开着,那还是做个记录,回头有空的时候清理一下,重新组织一下服务器。
六、'CPU 和内存'
$ free -m
$ uptime
$ top
$ htop
注意以下问题:
还有空余的内存吗? 服务器是否正在内存和硬盘之间进行swap?
还有剩余的CPU吗? 服务器是几核的? 是否有某些CPU核负载过多了?
服务器最大的负载来自什么地方? '平均负载'是多少?
七、硬件
$ lspci
$ dmidecode
$ ethtool
有很多服务器还是裸机状态,可以看一下:
找到RAID 卡 (是否带BBU备用电池?)、 CPU、空余的内存插槽。根据这些情况可以大致了解硬件问题的来源和性能改进的办法。
'网卡是否设置好'? 是否正运行在半双工状态? 速度是10MBps? 有没有 TX/RX 报错?
八、IO 性能
$ iostat -kx 2
$ vmstat 2 10
$ mpstat 2 10
$ dstat --top-io --top-bio
这些命令对于调试后端性能非常有用。
检查磁盘使用量:服务器硬盘是否已满?
是否开启了swap交换模式 (si/so)?
CPU被谁占用:系统进程? 用户进程? 虚拟机?
dstat 是我的最爱。用它可以看到谁在进行 IO: 是不是MySQL吃掉了所有的系统资源? 还是你的PHP进程?
九、挂载点和文件系统
$ mount
$ cat /etc/fstab
$ vgs
$ pvs
$ lvs
$ df -h
$ lsof +D / /* beware not to kill your box */
一共挂载了多少文件系统?
有没有某个服务专用的文件系统? (比如MySQL?)
文件系统的挂载选项是什么: noatime? default? 有没有文件系统被重新挂载为只读模式了?
磁盘空间是否还有剩余?
是否有大文件被删除但没有清空?
如果磁盘空间有问题,你是否还有空间来扩展一个分区?
十、内核、中断和网络
$ sysctl -a | grep ...
$ cat /proc/interrupts
$ cat /proc/net/ip_conntrack /* may take some time on busy servers */
$ netstat
$ ss -s
你的中断请求是否是均衡地分配给CPU处理,还是会有某个CPU的核因为大量的网络中断请求或者RAID请求而过载了?
SWAP交换的设置是什么?对于工作站来说swappinness 设为 60 就很好, 不过对于服务器就太糟了:你最好永远不要让服务器做SWAP交换,不然对磁盘的读写会锁死SWAP进程。
conntrack_max 是否设的足够大,能应付你服务器的流量?
在不同状态下(TIME_WAIT, …)TCP连接时间的设置是怎样的?
如果要显示所有存在的连接,netstat 会比较慢, 你可以先用 ss 看一下总体情况。
你还可以看一下 Linux TCP tuning 了解网络性能调优的一些要点。
十一、系统日志和内核消息
$ dmesg
$ less /var/log/messages
$ less /var/log/secure
$ less /var/log/auth
查看错误和警告消息,比如看看是不是很多关于连接数过多导致?
看看是否有硬件错误或文件系统错误?
分析是否能将这些错误事件和前面发现的疑点进行时间上的比对。
十二、定时任务
$ ls /etc/cron* + cat
$ for user in $(cat /etc/passwd | cut -f1 -d:); do crontab -l -u $user; done
是否有某个定时任务运行过于频繁?
是否有些用户提交了隐藏的定时任务?
在出现故障的时候,是否正好有某个备份任务在执行?
十三、应用系统日志
这里边可分析的东西就多了, 不过恐怕你作为运维人员是没功夫去仔细研究它的。关注那些明显的问题,比如在一个典型的LAMP(Linux+Apache+Mysql+Perl)应用环境里:
Apache & Nginx; 查找访问和错误日志, 直接找 5xx 错误, 再看看是否有 limit_zone 错误。
MySQL; 在mysql.log找错误消息,看看有没有结构损坏的表, 是否有innodb修复进程在运行,是否有disk/index/query 问题.
PHP-FPM; 如果设定了 php-slow 日志, 直接找错误信息 (php, mysql, memcache, …),如果没设定,赶紧设定。
Varnish; 在varnishlog 和 varnishstat 里, 检查 hit/miss比. 看看配置信息里是否遗漏了什么规则,使最终用户可以直接攻击你的后端?
HA-Proxy; 后端的状况如何?健康状况检查是否成功?是前端还是后端的队列大小达到最大值了?

