


数据标注质量&算法效果评估的要点解读
算法质量保障要点解读
算法质量保障流程
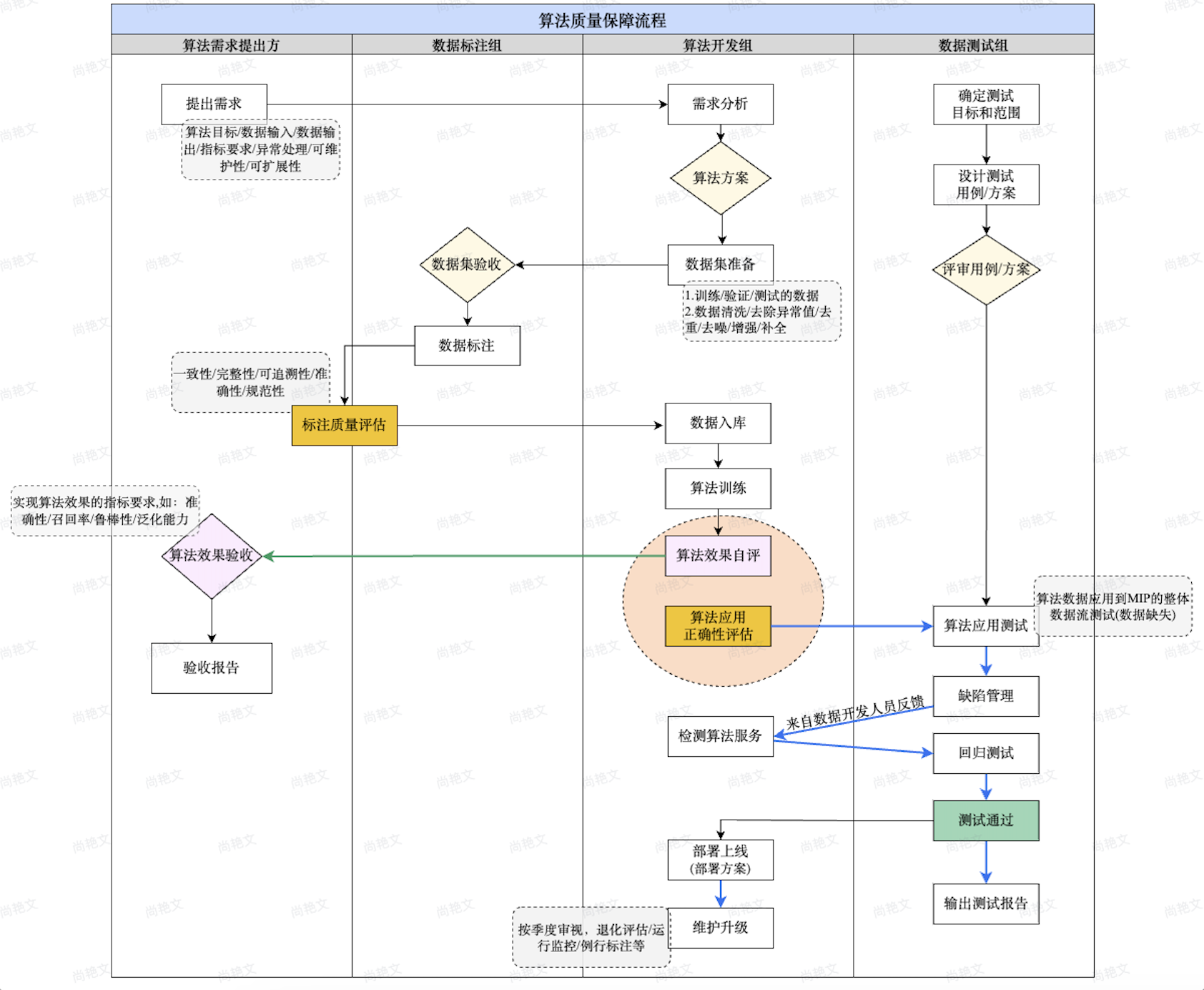
数据标注事项
● 明确数据标注目的和需求:如明确是训练模型、测试模型、评估模型等
● 制定标注计划:范围、进度、人员、工具等
● 选择合适的标注人员:专业知识、背景、能力等
● 提供标注培训/指导:标注目的/需求的介绍、标注标准的讲解、标注方法的演示、练习
● 实施质量控制:抽样检查、一致性检查、错误率分析等
数据集准备
● 数据用途:训练、验证、测试
● 明确数据集的质量要求与数据量
● 数据要求:
- ○ 代表性:数据集应尽可能代表实际应用场景中的数据
- ○ 多样性:数据集应尽可能多样化,确保算法能够处理各种类型的数据。
- ○ 清晰性:数据应清晰准确,避免出现错误或歧义。
- ○ 完整性:数据应完整,避免出现缺失值或异常值。
● 数据标注开始的前置条件:
○ 收集足够的数据:数据集的规模越大,覆盖足够的范围。
○ 对数据进行预处理:对数据进行清洗、去重、格式化、补齐等,确保数据的质量
- 数据清洗:去除数据中的错误、异常值、缺失值等
- 方法:正则表达式快速匹配与替换数据错误等、缺失值填充/插值等
- ■ 数据格式化:将数据转换为统一的格式,方便标注
- 方法:格式转换、类型转换
- ■ 数据标准化:可以使用归一化、标准化等方法来将数据转换为统一的量纲
- 方法:归一化/标准化,如将数据值转换到[-1,1]区间内
- ■ 数据降维(不常用):将高维数据降维到低维,减少数据的复杂性
- 方法:主成分分析、线性判别分析
- ■ 数据增强:增加数据的数量和多样性
- 方法:词替换、句子重排、句子插入、句子删除
- 示例:句子插入,将“这铅笔好用”改为“这铅笔好用,而且价格实惠”。
- ■ 数据去重:去除数据中的重复数据
- 方法:布隆过滤器
- ■ 数据去噪:去除数据中的噪声,避免影响标注结果的准确性
- 方法:滤波、降噪
- ■ 数据抽样:根据特定的比例或条件对数据进行抽样,以减少数据处理的负担
- ■ 数据聚类:将数据聚合到具有相似特征的组中,以便进行更有效的处理
- 方法:层次聚类
- ■ 数据关联分析:发现数据中存在的关联关系,以便进行更深入的分析
- 方法:关联规则挖掘、因果关系分析
- ■ 数据隐私保护:对数据进行隐私保护处理,以避免数据泄露
- 方法:加密、假名化、去标识化
- ■ 数据安全性:对数据进行安全性处理,以防止数据被恶意攻击
- 方法:数据加密
标注质量评估
评估维度
● 多样性:指数据标注的范围是否足够广泛,能够涵盖各种可能的场景
● 准确性:指数据标注的结果是否符合实际情况
● 一致性:指不同标注人员对同一数据的标注结果是否一致
● 可解释性:指数据标注结果是否能够被理解和解释
● 有用性:指数据标注结果是否能够有效地用于训练机器学习模型
评估方法
● 人工检查:人工专家对数据标注结果进行检查
● 自动评估:通过算法来计算数据标注的准确性
● 一致性检查:检查不同标注人员对同一数据的标注结果是否一致
算法效果评估
评估指标
● 准确率:表示算法正确预测的样本数占总样本数的比例。
● 召回率:表示算法正确预测为正类的样本数占实际正类样本数的比例。
● F1值:综合考虑了准确率和召回率的指标。
● AUC:表示 ROC 曲线下的面积。
● ROC 曲线:表示真阳率(TPR)和假阳率(FPR)之间的关系
评估注意事项
1. 明确评估目标
a. 在进行算法效果评估之前,首先要明确评估目标,评估目标可以是算法的准确率、召回率、F1值等,也可以是算法的效率、可解释性等,明确评估目标可以帮助我们选择合适的评估指标和方法
2. 选择合适的评估指标
a. 不同的评估目标需要使用不同的评估指标。例如,如果评估目标是算法的准确率,那么可以使用准确率、召回率、F1值等指标。如果评估目标是算法的效率,那么可以使用算法运行时间、内存消耗等指标。
3. 使用合适的评估方法
a. 例评估:准确率、召回率、F1值的指标可以使用人工检查、自动评估等方法进行评估,或者使用交叉验证方法
4. 考虑评估指标的局限性
a. 准确率可以反映算法对训练数据的拟合程度,但不能反映算法对未知数据的泛化能力。因此,在进行算法效果评估时,需要考虑评估指标的局限性,并结合多个评估指标进行综合评估
5. 重复评估
a. 算法效果评估结果可能存在一定的随机性。因此,在进行算法效果评估时,建议重复评估多次,并取平均值作为最终结果。
大模型数据标注
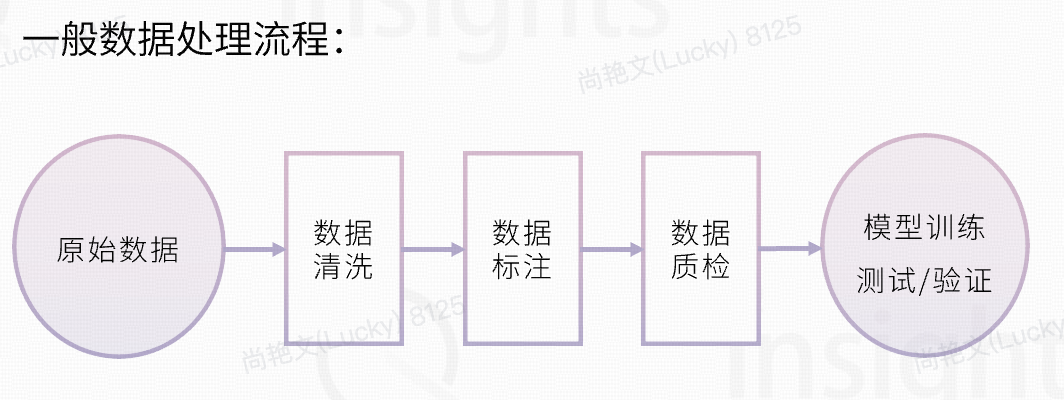
数据标注从劳动密集朝着知识密集型转变

|
1.作者:Syw 2.出处:http://www.cnblogs.com/syw20170419/ 3.本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。 4.如果文中有什么错误,欢迎指出。以免更多的人被误导。 |

