spark学习---hello world
《spark入门学习》
1. 下载spark
http://archive.apache.org/dist/spark/spark-2.4.4/

2. 解压spark-2.4.4-bin-hadoop2.7.tgz 到 /Users/yyc121/software/
3. 配置pyspark全局变量
3.1 vim ~/.bash_profile
3.2 增加:alias pyspark="/Users/yyc121/software/spark-2.4.4-bin-hadoop2.7/bin/pyspark"
4. 验证pyspark安装完成,输入pyspark

5. 将/Users/yyc121/software/spark-2.4.4-bin-hadoop2.7/bin/目录下的pyspark,拷贝到python 的site-packages目录下
6. 配置pycharm python解释器,运行环境配置
6.1 python解释器配置

6.2 运行环境配置
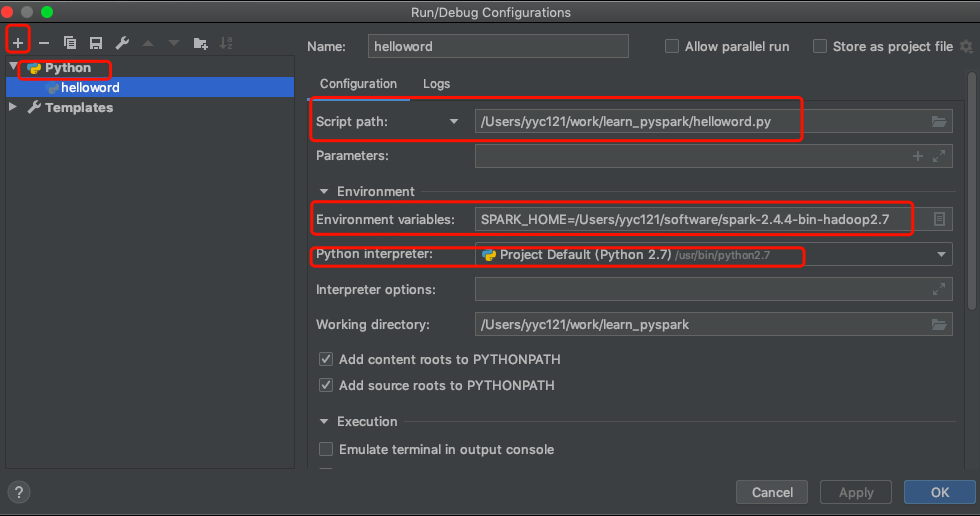
7. 写个统计词频脚本,测试
helloword.py
# -*- coding: utf-8 -*- import sys from pyspark import SparkContext from operator import add import re def main(): sc = SparkContext(appName= "wordsCount") lines = sc.textFile('words.txt') counts = lines.flatMap(lambda x: x.split(' '))\ .map( lambda x : (x, 1))\ .reduceByKey(add) output = counts.collect() print(output) for (word, count) in output: print ("%s: %i" %(word, count)) sc.stop() if __name__ =="__main__": main()
words.txt
The dynamic lifestyle people lead nowadays causes many reactions in our bodies and the one that is the most frequent of all is the headache
7. pycharm直接运行
8. 结果展示

