MongoDB学习笔记2:分片集群
高可用性 HA(High Availability)指的是缩短因正常运维或者非预期故障而导致的停机时间,提高系统可用性。
无论是数据的高可用,还是组件的高可用全都是一个解决方案:冗余。通过多个组件和备份对外提供一致性和不中断的服务。
MongoDB中提供了几种高可用模式。
1 MongoDB主从模式
1.1 master-slave模式简介
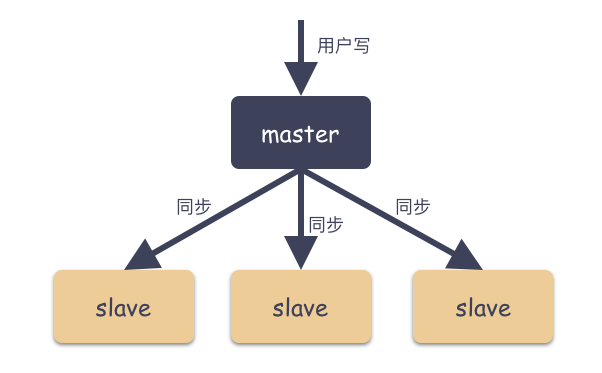
Mongodb 提供的第一种冗余策略就是 Master-Slave 策略,这个也是分布式系统最开始的冗余策略,这种是一种热备策略。
Master-Slave 一般用于做备份或者读写分离,通常是一主一从或者一主多从架构。
主从模式有master角色和slave角色,这两种角色说明如下:
master
可读可写,当有数据修改时,会将Oplog(类似mysql的binlog日志)同步到所有连接的slave上。
slave
只读,所有的slave从master同步数据,从节点与从节点之间从不感知,互相不知道对方的存在。
具体架构如下所示:
1.2 master-slave原理
在主从结构中,主节点的操作记录成为oplog(operation log)。oplog存储在一个系统数据库local的集合 oplog.$main 中,这个集合的每个文档都代表主节点上执行的一个操作。
从节点会定期从主节点中获取oplog记录,然后在本机上执行!对于存储oplog的集合,MongoDB采用的是固定集合,也就是说随着操作过多,新的操作会覆盖旧的操作!
1.3 master-slave缺点
读写分离数据不一致
MongoDB 中 Master 对外提供读写服务,有多个 Slave 节点的话,可以用 Slave 节点来提供读服务的节点。
其中,只有master节点可写,slave只能同步master数据并对外提供读服务,这是一个异步的过程。虽然最终数据会被 Slave 同步到,在数据完全一致之前,数据是不一致的,这个时候去 Slave 节点读就会读到旧的数据。所以,总结来说:读写分离的结构只适合特定场景,对于必须需要数据强一致的场景是不合适这种读写分离的。
容灾能力差
由于 master-slave的角色是静态配置的,不能自动切换角色,所以当master发生故障时,需要人为操作,把slave指定为新的master节点。这样在master发生故障时,需要较多的停服务时间。
目前,MongoDB 3.6 起已不推荐使用主从模式,自 MongoDB 3.2 起,分片群集组件已弃用主从复制。因为 Master-Slave 其中 Master 宕机后不能自动恢复,只能靠人为操作,可靠性也差,操作不当就存在丢数据的风险。
2 MongoDB 副本集模式 Replica Set
2.1 Replica Set 简介
Replica Set 是一组 Mongodb 的副本集,就是一组mongod进程,这些进程维护同一个数据集合。副本集提供了数据冗余,提高了数据的可用性。在多台服务器保存数据可以避免因为一台服务器故障导致服务不可用或者数据丢失。
2.2 Replica Set 优点
- 数据多副本,在故障的时候,可以使用完的副本恢复服务。注意:这里是故障自动恢复;
- 读写分离,读的请求分流到副本上,减轻主(Primary)的读压力;
- 节点直接互有心跳,可以感知集群的整体状态;
2.3 Replica Set 角色
在副本集模式中,每个副本都是一个MongoDB实例,包含三类成员:
Primary主节点
- 只有 Primary 主节点是可读可写的,Primary 负责接收客户端所有的写请求,然后把操作记录到 oplog,再把数据同步到所有 Secondary 。
- 一个 Replica Set 只有一个 Primary 节点,当 Primary 挂掉后,其他 Secondary 或者 Arbiter 节点会重新选举出来一个 Primary 节点,这样就又可以提供服务了。
- 读请求默认是发到 Primary 节点处理,如果需要故意转发到 Secondary 需要客户端修改一下配置(注意:是客户端配置,决策权在客户端)。
- 副本集模式与Master-Slave 模式的最大区别在于,Primary 角色是通过整个集群共同选举出来的,人人都可能成为 Primary ,人人最开始只是 Secondary ,而这个选举过程完全自动,不需要人为参与。
Secondary副本节点
- 副本节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证副本节点的数据与主节点一致。
- 默认情况下,副本节点不支持外部读取,但可以设置。副本集的机制在于主节点出现故障的时候,余下的节点会选举出一个新的主节点,从而保证系统可以正常运行。(自动切换的,无需人工参与)
- Secondary 和 Master-Slave 模式的 Slave 角色的区别:最根本的一个不同在于:Secondary 相互有心跳,Secondary 可以作为数据源,Replica 可以是一种链式的复制模式。
Arbiter仲裁者
- 仲裁节点不复制数据,仅参与投票。由于它没有访问的压力,比较空闲,因此不容易出故障。
- 由于副本集出现故障的时候,存活的节点必须大于副本集节点总数的一半,否则无法选举主节点,或者主节点会自动降级为从节点,整个副本集变为只读。
- 因此,增加一个不容易出故障的仲裁节点,可以增加有效选票,降低整个副本集不可用的风险。仲裁节点可多于一个。也就是说只参与投票,不接收复制的数据,也不能成为活跃节点。
副本集模式的架构图如下:

注意:在副本集模式中,由于节点相互之间都有心跳,导致节点之间的心跳书以倍数增大,所以单个Replica Set集群的节点数不宜过大,否则会影响集群的整体性能。
2.4 Primary选举
复制集通过 replSetInitiate 命令(或mongo shell的rs.initiate())进行初始化,初始化后各个成员间开始发送心跳消息,并发起Priamry选举操作,获得『大多数』成员投票支持的节点,会成为Primary,其余节点成为Secondary。
因此,在副本集成员数上,一般设置为奇数最佳,否则可能会在投票时出现脑裂的问题。因为偶数个数的副本集,可能出现投票数相等的情况,这样无法选出 Primary节点。
2.5 部署 replica set 集群
2.5.1 环境准备
配置MongoDB副本集集群需要多个服务器环境或者多个实例,由于环境问题,这里使用多实例方式部署。在一台服务器上部署3个实例,
服务器环境如下:
[root@web01 ~]# cat /etc/redhat-release
CentOS Linux release 7.9.2009 (Core)
[root@web01 ~]# uname -a
Linux web01 3.10.0-1160.el7.x86_64 #1 SMP Mon Oct 19 16:18:59 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
[root@web01 ~]# hostname -I
192.168.5.50
[root@web01 ~]# getenforce
Disabled
[root@web01 ~]# systemctl status firewalld
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Docs: man:firewalld(1)
软件版本:mongodb-linux-x86_64-rhel70-4.2.17.tgz
2.5.2 安装mongodb
具体安装步骤参考之前的博文:https://www.cnblogs.com/syushin/p/15598624.html
# 下载软件包
$ cd /usr/local/src && wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-4.2.17.tgz
# 解压
$ tar -xvf mongodb-linux-x86_64-rhel70-4.2.17.tgz
# 移动指定目录
$ mv mongodb-linux-x86_64-rhel70-4.2.17 /usr/local/mongodb
# 创建用户和组,并设置用户密码
$ useradd mongod
$ echo '123qwe321' | passwd --stdin mongod
# 创建mongodb的配置文件目录,日志目录和数据目录
$ mkdir -p /mongodb/
# 设置目录权限
$ chown -R mongod:mongod /mongodb/
# 设置用户环境变量
$ su - mongod
# 编辑.bashrc配置文件,添加mongo的环境变量
$ echo 'export PATH=/usr/local/mongodb/bin:$PATH' >> .bashrc
$ source .bashrc
2.5.2 创建目录
这里创建了3个目录,分别是28017、28018、28019,这三个数字是MongoDB多实例的3个端口。
$ su - mongod
$ for port in 28017 28018 28019;do mkdir -p /mongodb/${port}/{conf,data,log};done
$ tree /mongodb/
/mongodb/
├── 28017
│ ├── conf
│ ├── data
│ └── log
├── 28018
│ ├── conf
│ ├── data
│ └── log
└── 28019
├── conf
├── data
└── log
12 directories, 0 files
2.5.3 准备配置文件
先准备一个配置文件:
$ cat > /mongodb/28017/conf/mongod.conf <<EOF
systemLog:
destination: file
path: /mongodb/28017/log/mongodb.log
logAppend: true
storage:
journal:
enabled: true
dbPath: /mongodb/28017/data
directoryPerDB: true
#engine: wiredTiger
wiredTiger:
engineConfig:
cacheSizeGB: 1
directoryForIndexes: true
collectionConfig:
blockCompressor: zlib
indexConfig:
prefixCompression: true
processManagement:
fork: true
net:
bindIp: 127.0.0.1
port: 28017
replication:
oplogSizeMB: 2048
replSetName: my_repl
EOF
然后拷贝到其他两个目录,再替换掉端口号:
# 拷贝
$ cp /mongodb/28017/conf/mongod.conf /mongodb/28018/conf/
$ cp /mongodb/28017/conf/mongod.conf /mongodb/28019/conf/
# 替换
$ sed -i 's/28017/28018/g' /mongodb/28018/conf/mongod.conf
$ sed -i 's/28017/28019/g' /mongodb/28018/conf/mongod.conf
2.5.4 启动多实例MongoDB
$ for num in 28017 28018 28019;do mongod -f /mongodb/$num/conf/mongod.conf ;done
# 检查是否启动
$ netstat -lntp | grep mongod
tcp 0 0 127.0.0.1:28017 0.0.0.0:* LISTEN 4804/mongod
tcp 0 0 127.0.0.1:28018 0.0.0.0:* LISTEN 4846/mongod
tcp 0 0 127.0.0.1:28019 0.0.0.0:* LISTEN 4888/mongod
2.5.5 配置MongoDB副本集
首先,进入28017的admin库,然后配置副本集集群:
$ mongo --port 28017 admin
# 配置副本集集群
> config = {_id: 'my_repl', members: [
{_id: 0, host: '127.0.0.1:28017'},
{_id: 1, host: '127.0.0.1:28018'},
{_id: 2, host: '127.0.0.1:28019', 'arbiterOnly': true},
]}
# 初始化集群,至此副本集集群的配置完成
> rs.initiate(config)
{ "ok" : 1 }
查询副本集集群状态:
# 查询副本集集群状态使用,注意,初始化集群完成后,左边提示符变成了my_repl:primary,表明当前节点是主节点
my_repl:PRIMARY> rs.status()
# 同样,连接到28018实例,显示是secondary副本节点
$ mongo --port 28018 admin
my_repl:SECONDARY>
# 28019是仲裁者节点
$ mongo --port 28019 admin
my_repl:ARBITER>
rs.status()命令主要关注以下成员的信息,如果集群有报错会在这里显示:
"members" : [
{
"_id" : 0,
"name" : "127.0.0.1:28017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 1028,
"optime" : {
"ts" : Timestamp(1638151167, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2021-11-29T01:59:27Z"),
"syncingTo" : "",
"syncSourceHost" : "",
"syncSourceId" : -1,
"infoMessage" : "",
"electionTime" : Timestamp(1638150676, 1),
"electionDate" : ISODate("2021-11-29T01:51:16Z"),
"configVersion" : 1,
"self" : true,
"lastHeartbeatMessage" : ""
},
省略.........
]
除此之外,也有一些其他命令用于查询副本集集群信息:
rs.status():查看整个复制集状态rs.isMaster():查看当前节点是否是主节点rs.conf():查看复制集配置信息db.printReplicationInfo():查看 oplog 的信息db.printSlaveReplicationInfo():查看副本节点的同步状态
my_repl:PRIMARY> db.printReplicationInfo()
configured oplog size: 2048MB # 文件大小
log length start to end: 21776secs (6.05hrs) # oplog 日志的启用时间段
oplog first event time: Mon Nov 29 2021 09:51:06 GMT+0800 (CST) # 第一个事务日志的产生时间
oplog last event time: Mon Nov 29 2021 15:54:02 GMT+0800 (CST) # 最后一个事务日志的产生时间
now: Mon Nov 29 2021 15:54:06 GMT+0800 (CST) # 现在的时间
2.5.6 增加和删除节点
- 添加节点:
rs.add("ip:端口) - 删除节点:
rs.remove("ip:端口") - 添加仲裁节点:
rs.addArb("ip:端口")
2.5.7 测试数据同步
在主节点插入数据:
my_repl:PRIMARY> use test
switched to db test
my_repl:PRIMARY> db.student.insert({"name": "ZhangSan", "age": 18})
WriteResult({ "nInserted" : 1 })
在副本节点读取数据,默认副本节点是不能读写数据的,如果直接查看会报错:
# 登录到副本节点
$ mongo --port 28018
my_repl:SECONDARY> db
test
my_repl:SECONDARY> show tables;
2021-11-29T15:16:12.158+0800 E QUERY [js] uncaught exception: Error: listCollections failed: {
"operationTime" : Timestamp(1638170172, 1),
"ok" : 0,
"errmsg" : "not master and slaveOk=false",
"code" : 13435,
"codeName" : "NotPrimaryNoSecondaryOk",
"$clusterTime" : {
"clusterTime" : Timestamp(1638170172, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
} :
_getErrorWithCode@src/mongo/shell/utils.js:25:13
DB.prototype._getCollectionInfosCommand@src/mongo/shell/db.js:835:15
DB.prototype.getCollectionInfos@src/mongo/shell/db.js:883:16
shellHelper.show@src/mongo/shell/utils.js:893:9
shellHelper@src/mongo/shell/utils.js:790:15
@(shellhelp2):1:1
如果要在副本节点开启读,需要将slaveOK开启:
my_repl:SECONDARY> rs.slaveOk()
# 因为这里我的版本较新,提示slaveOk即将过时了,建议使用新的命令secondaryOk()
WARNING: slaveOk() is deprecated and may be removed in the next major release. Please use secondaryOk() instead.
# 所以直接用secondaryOk()
my_repl:SECONDARY> rs.secondaryOk()
# 可以看到副本节点可以正确读取数据了
my_repl:SECONDARY> show tables;
student
my_repl:SECONDARY> db.student.find().pretty()
{
"_id" : ObjectId("61a47e0b387b76631e58fcc0"),
"name" : "ZhangSan",
"age" : 18
}
可以看到副本节点的数据跟我们在主节点插入的数据是一致的,说明数据已经同步过来了。
注意:禁止在副本节点上做任何修改数据的操作。
2.5.8 replica set 扩展
- 副本集角色人为切换:
rs.stepDown() - 锁定副本节点,使其在指定时间内不会转变为主节点:
rs.freeze(300),300的单位是秒 - 设置副本节点可读:
rs.slaveOK()或rs.secondaryOk()
3 MongoDB 分片集群 Sharding 模式
3.1 Sharding 模式简介
Replica Set 模式已经非常好的解决了MongoDB可用性的问题,但是为什么还会有分片集群呢?是因为数据量的问题。
一旦数据多,搞数据量和吞吐量的应用会对单机的性能造成较大的压力,大的查询量会影响到单机的CPU、内存等。这个时候 Replica Set 就不太管用了。为了解决这个问题,有两个基本的优化办法:
- 纵向优化(垂直扩展):增加更多的CPU和存储资源来扩展容量。
- 横向优化(水平扩展):将数据集分布在多个服务器上,水平扩展即分片,通俗来讲就是加节点。
纵向优化 通过不断提高机器的配置来解决问题,但始终追不上数据的增加。
横向优化 是业务上划分系统数据集,并在多台服务器上处理,做到容量和能力跟机器数量成正比。单台计算机的整体速度或容量可能不高,但是每台计算机只能处理全部工作量的一部分,因此与单台高速大容量服务器相比,可能提供更高的效率。缺点是软件的基础结构要支持,部署维护比较复杂。
在实际生产中,自然是使用横向优化会更好,如现在的分布式技术。MongoDB 的 Sharding 模式就是 MongoDB 横向扩容的一个架构实现。
Sharding cluster是一种可以水平扩展的模式,在数据量很大时特给力,实际大规模应用一般会采用这种架构去构建。sharding分片很好的解决了单台服务器磁盘空间、内存、cpu等硬件资源的限制问题,把数据水平拆分出去,降低单节点的访问压力。每个分片都是一个独立的数据库,所有的分片组合起来构成一个逻辑上的完整的数据库。因此,分片机制降低了每个分片的数据操作量及需要存储的数据量,达到多台服务器来应对不断增加的负载和数据的效果。
3.2 Sharding 集群架构
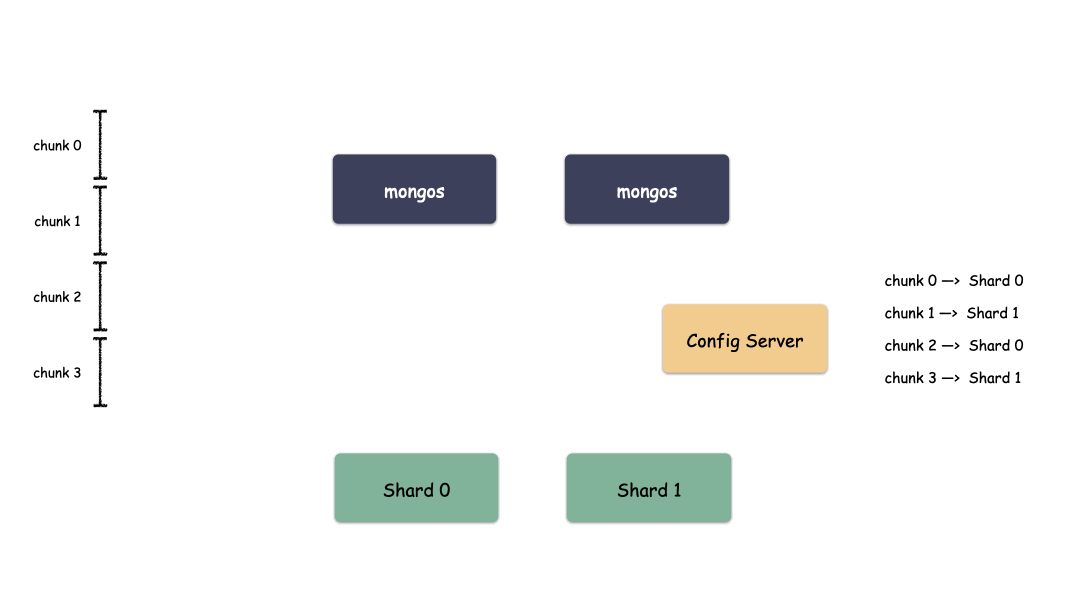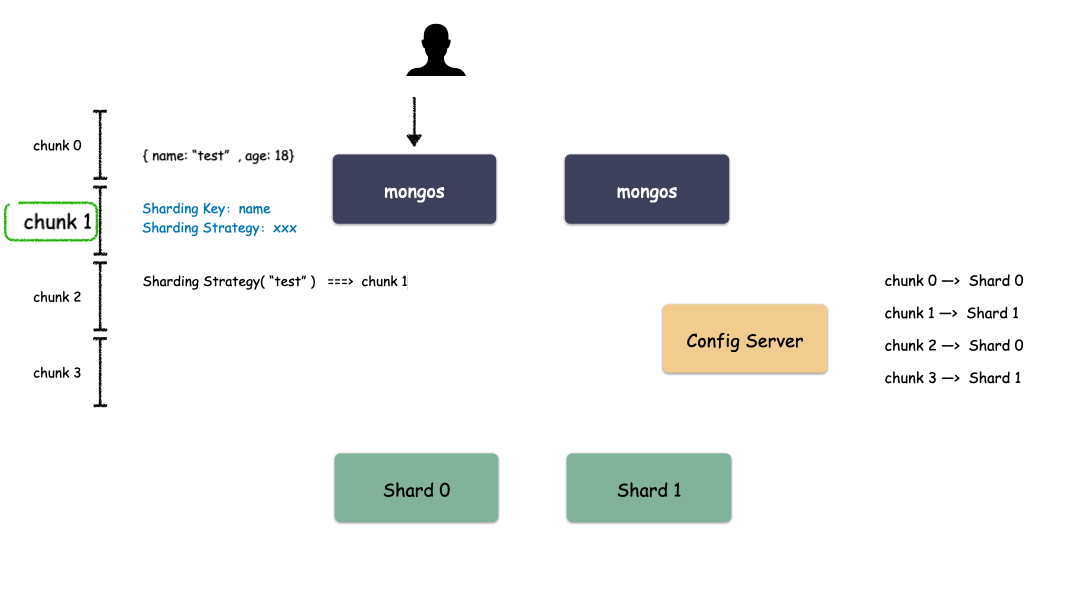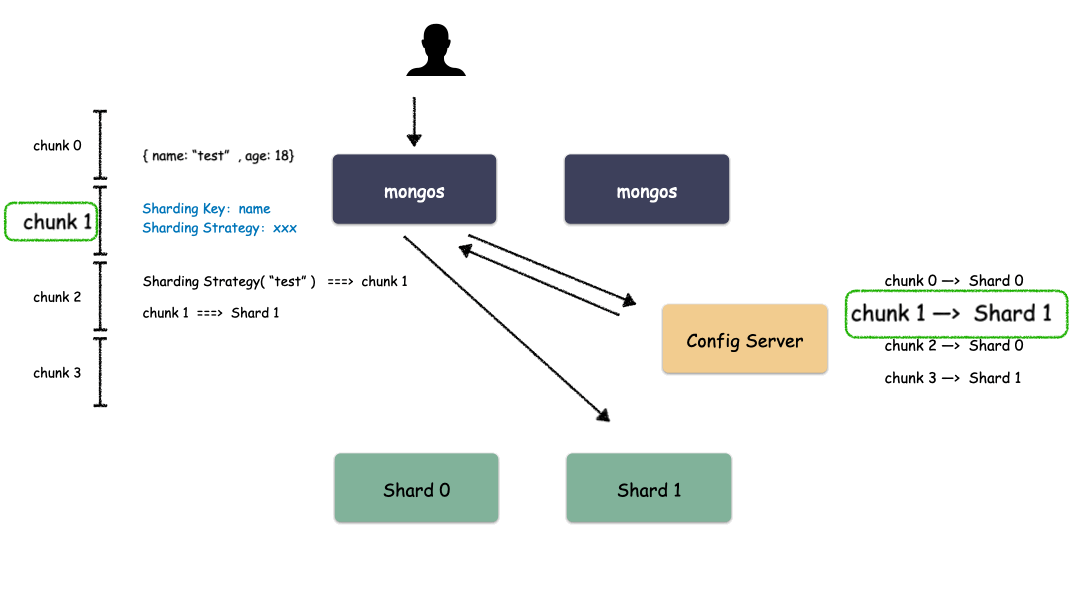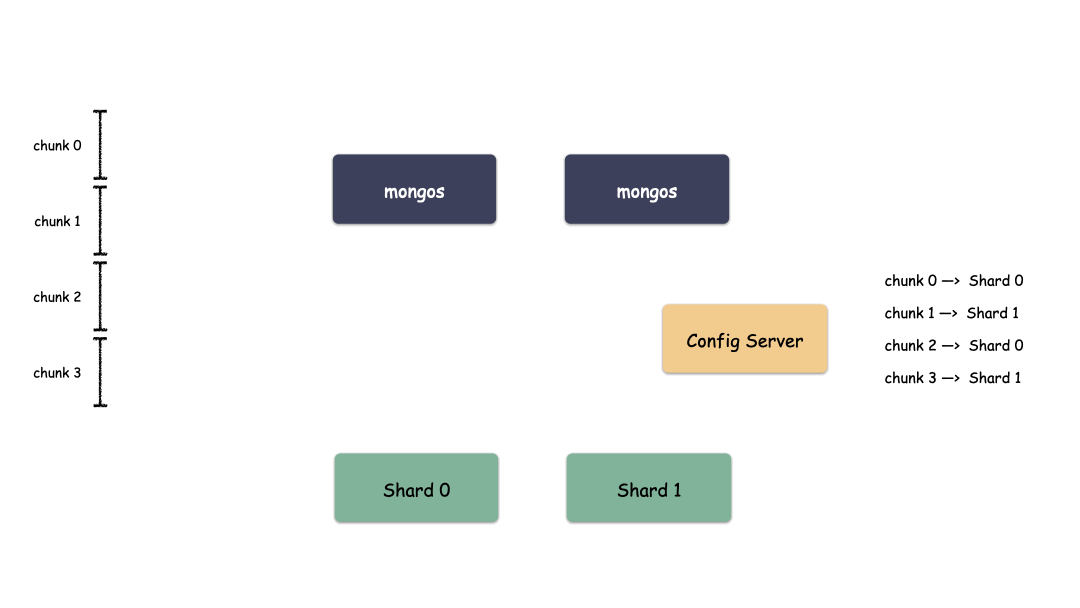
首先,Sharding 集群中以下三大模块:
Config Server:配置中心,存储集群所有节点、分片数据路由信息。默认需要配置3个Config Server节点。Mongos路由:代理层,提供对外应用访问,所有操作均通过mongos执行。一般有多个mongos节点。数据迁移和数据自动平衡。sharding分片:数据层, 存储应用数据记录。一般有多个Mongod节点,达到数据分片目的。

代理层
代理层的组件也就是 mongos ,这是个无状态的组件,纯粹是路由功能。向上对接 Client ,收到 Client 写请求的时候,按照特定算法均衡散列到某一个 Shard 集群,然后数据就写到 Shard 集群了。收到读请求的时候,定位找到这个要读的对象在哪个 Shard 上,就把请求转发到这个 Shard 上,就能读到数据了。
数据层
是存储数据的地方,每个shard(分片)包含被分片的数据集中的一个子集。每个分片可以被部署为 Replica Set 架构。
配置中心
代理层是无状态的模块,数据层的每一个 Shard 是各自独立的,那么就需要有一个集群统配管理的地方,这个地方就是配置中心。
配置中心记录的是集群所有节点、分片数据路由信息。这些信息也非常重要,不能单点存储,所以配置中心也是一个 Replica Set集群。
详细架构图:
 0
0
3.3 Sharding 读写数据原理
单 Shard 集群是有限的,但 Shard 数量是无限的,Mongo 理论上能够提供近乎无限的空间,能够不断的横向扩容。那么现在唯一要解决的就是怎么去把用户数据存到这些 Shard 里?MongDB 是怎么做的?
首先,要选一个字段(或者多个字段组合也可以)用来做 Key,这个 Key 可以是你任意指定的一个字段。我们现在就是要使用这个 Key 来,通过某种策略算出发往哪个 Shard 上。这个策略叫做:Sharding Strategy ,也就是分片策略。
我们把 Sharding Key 作为输入,按照特点的分片策略计算出一个值,值的集合形成了一个值域,我们按照固定步长去切分这个值域,每一个片叫做 Chunk ,每个 Chunk 出生的时候就和某个 Shard 绑定起来,这个绑定关系存储在配置中心里。
所以,我们看到 MongoDB 的用 Chunk 再做了一层抽象层,隔离了用户数据和 Shard 的位置,用户数据先按照分片策略算出落在哪个 Chunk 上,由于 Chunk 某一时刻只属于某一个 Shard,所以自然就知道用户数据存到哪个 Shard 了。
Sharding 模式下数据写入过程:
 Sharding 模式下数据读取过程:
Sharding 模式下数据读取过程:
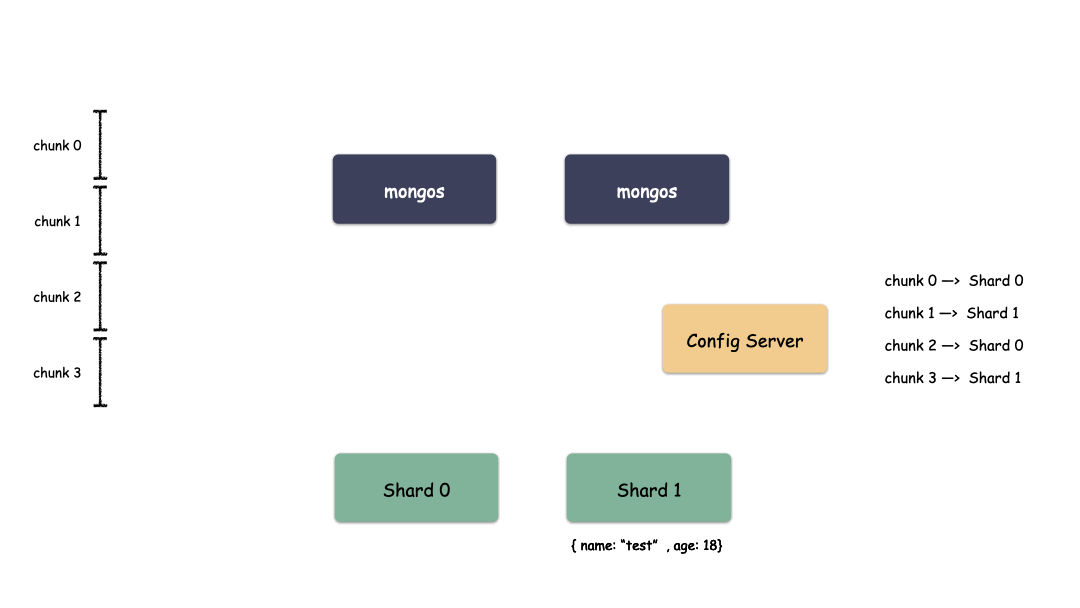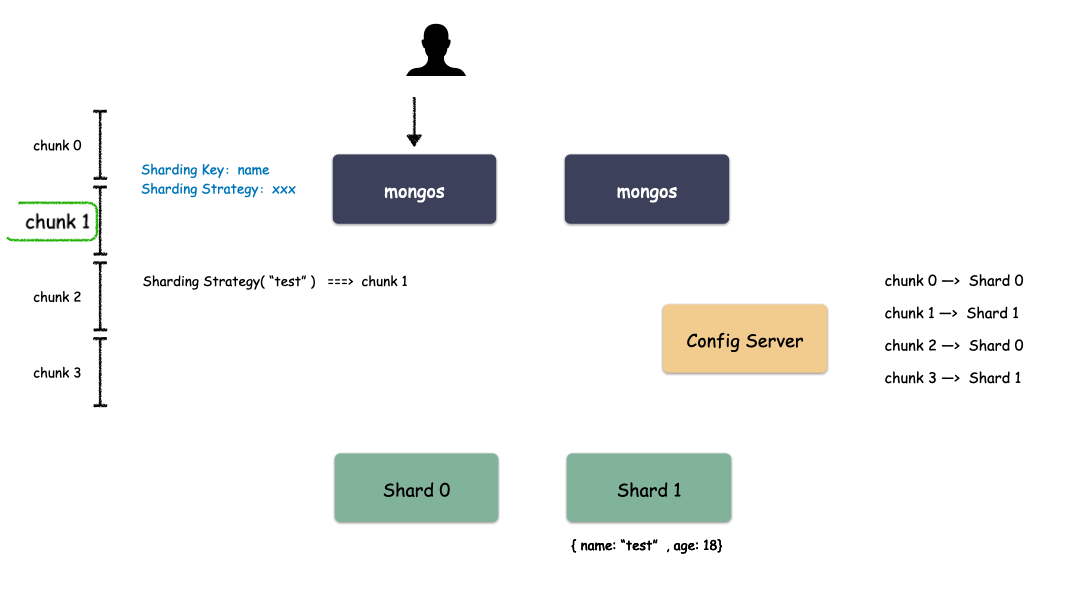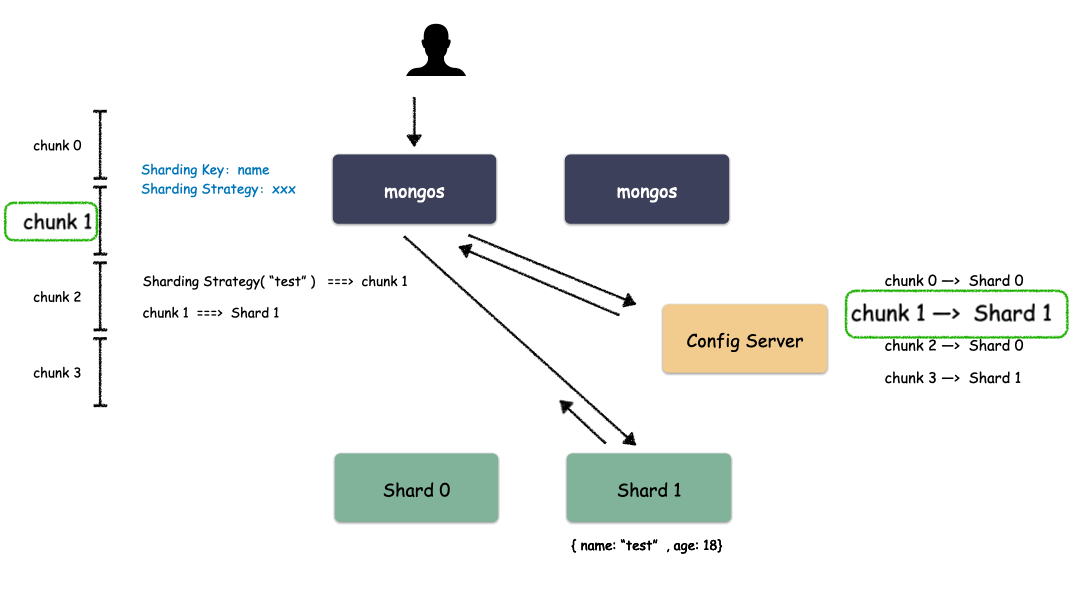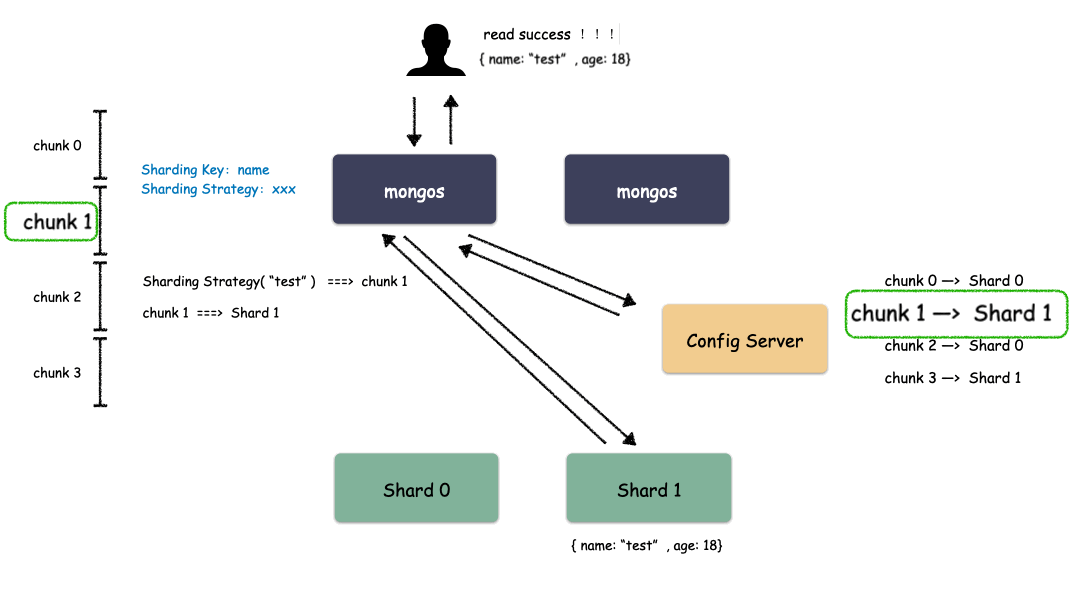
通过上图我们也看出来了,mongos 作为路由模块其实就是寻路的组件,写的时候先算出用户 key 属于哪个 Chunk,然后找出这个 Chunk 属于哪个 Shard,最后把请求发给这个 Shard ,就能把数据写下去。读的时候也是类似,先算出用户 key 属于哪个 Chunk,然后找出这个 Chunk 属于哪个 Shard,最后把请求发给这个 Shard ,就能把数据读上来。
实际情况下,mongos 不需要每次都和 Config Server 交互,大部分情况下只需要把 Chunk 的映射表 cache 一份在 mongos 的内存,就能减少一次网络交互,提高性能。
3.4 Sharding 的 Chunk 是什么
Chunk是指一个集合数据中的子集,可以简单理解为一个数据块,每个chunk都是基于片键(Shard Key)的范围取值,区间是左闭右开。chunk的产生,有以下用途:
- splitting:当一个chunk的大小超过了配置中的chunk size时,MongoDB的后台进程会把这个chunk切分成更小的chunk,从而避免chunk过大的情况;
- Balancing:在 MongoDB 中,balancer是一个后台进程,负责chunk的迁移,从而均衡各个shard server的负载,系统初始1个chunk,chunk size默认值是64M,生产库上选择适合业务的chunk size是最好的。MongoDB会自动拆分和迁移chunks。
分片集群的数据分布:
- 使用chunk来存储数据
- 集群搭建完成之后,默认会开启一个chunk,大小是64M
- 当一个chunk的存储数据大小超过64M,chunk会进行分裂
- 当存储需求变大,集群上服务器的chunk数量变多,每个服务器的chunk数据严重失衡时,就会进行chunk的迁移
Chunk的大小:
-
chunk的大小需要结合业务来进行选择是最好的。
-
chunk的大小不宜过小,如果chunk过小,好处是可以让数据更加均匀的分布,但是会导致chunk之间频繁的迁移,有一定的性能开销;如果chunk的大小过大,会导致数据分布不均匀。
3.5 数据区分
MongoDB的分片是以集合为基本单位的,集合中的数据是通过片键被分成多个多个部分。这个片键其实就是在集合中选一个Key,用该Key的值作为数据拆分的依。上面提到的分片策略就是基于片键的。本质上 Sharding Strategy 是形成值域的策略而已,MongoDB 支持两种 Sharding Strategy:
- Hashed Sharding (哈希分片)
- Range Sharding (以范围为基础的分片)
哈希分片
对于基于哈希的分片,MongoDB计算一个Key的哈希值,并用这个哈希值来创建chunk。在使用基于哈希分片的系统中,拥有”相近”片键的文档很可能不会存储在同一个数据块中,因此数据的分离性更好一些。

基于范围的分片
基于范围的分片本质上是直接用 Key 本身来做值,形成的 Key Space 。
假设有一个数字的片键:想象一个从负无穷到正无穷的直线,每一个片键的值都在直线上画了一个点。MongoDB 把这条直线划分为更短的不重叠的片段,并称之为数据块,每个数据块包含了片键在一定范围内的数据。在使用片键做范围划分的系统中,拥有”相近”片键的文档很可能存储在同一个数据块中,因此也会存储在同一个分片中。
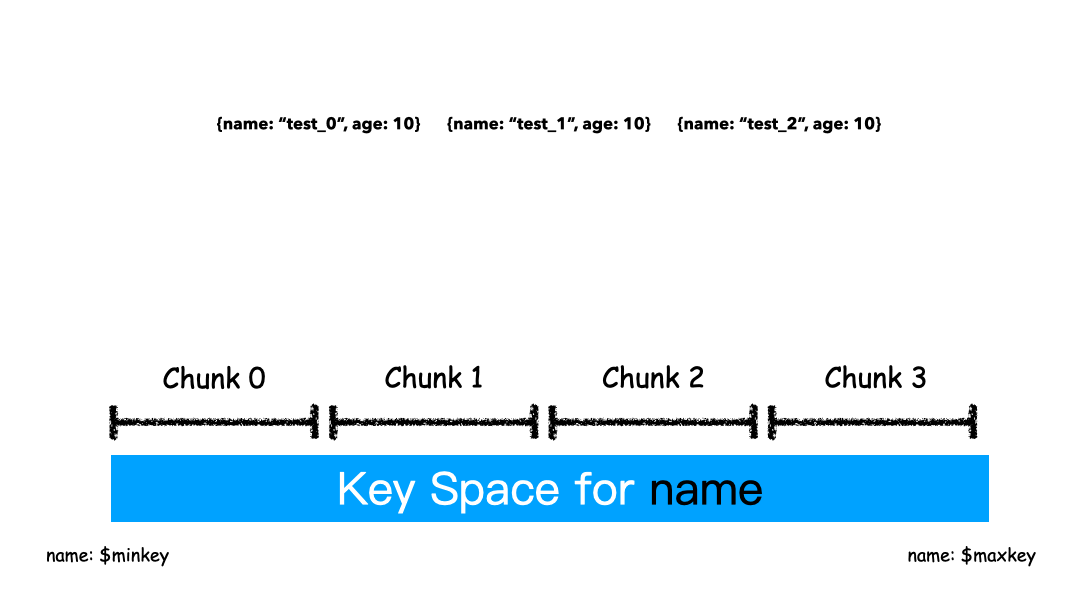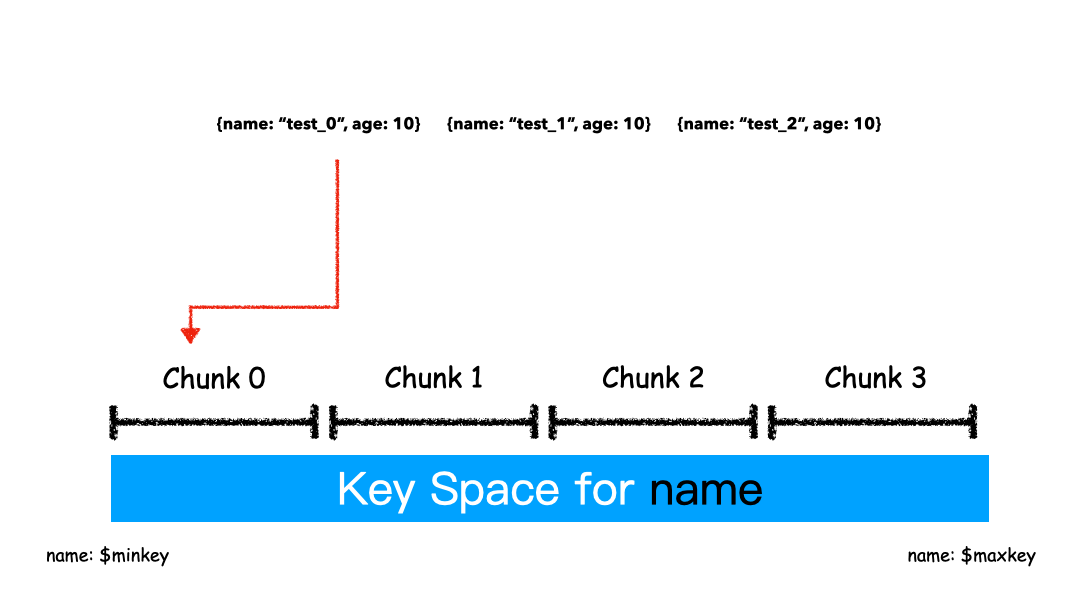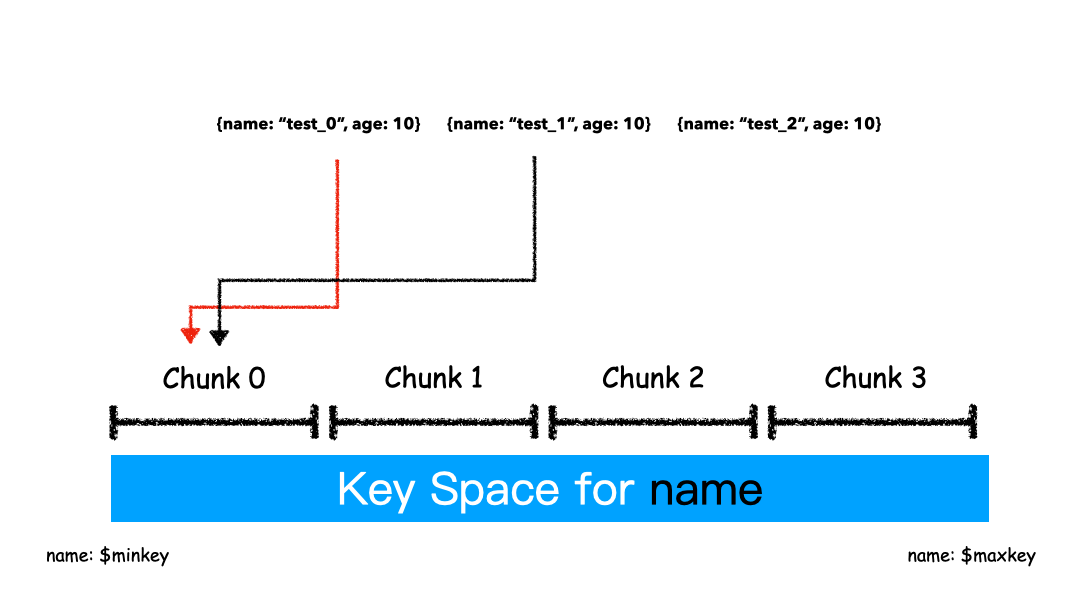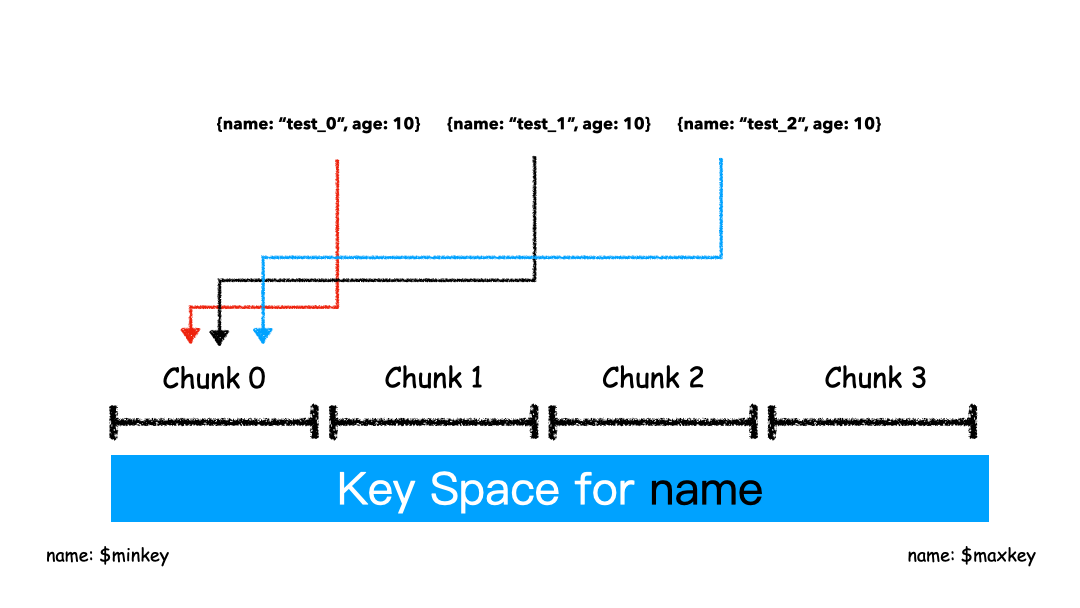
如上图这个例子,片键是name字段,对于片键的值“test_0","test_1","test_2",这样的key是紧挨着的,那么这些数据大概率就会被分到同一个chunk里面。
总结
哈希分片和范围分片都有各自的优缺点:
- 哈希分片
- 优点:计算速度快,均衡性好,纯随机
- 缺点:排序列举性能差
- 范围分片
- 优点:排序列举性能高
- 缺点:容易导致热点,如果片键的值都在一个范围内,那么大概率会被分配到同一个shard里,只盯着这一个shard读写,那么其他的shard就很空闲,浪费资源。
Hash分片与范围分片互补,能将文档随机的分散到各个chunk,充分的扩展写能力,弥补了范围分片的不足,但不能高效的服务范围查询,所有的范围查询要分发到后端所有的Shard才能找出满足条件的文档。
3.6 部署分片集群
3.6.1 环境说明
同样,基于centos7操作系统,安装的软件版本是 mongodb-4.2.17,安装 MongoDB 的步骤就不在叙述了。
参考:https://www.cnblogs.com/syushin/p/15598624.html
此次安装分片集群使用了10个 MongoDB 实例,端口规划是 28017~28026
28017:mongos代理28018~28020:Config Server 配置中心(一主、两从,config server 使用复制集不用有arbiter节点。3.4版本以后config必须为复制集)28021~28023:shard集群(一主、一从、一仲裁,副本集名称sh1)28024~28026:shard集群(一主、一从、一仲裁,副本集名称sh2)
创建多实例目录:
# 切换到mongod用户
$ su - mongod
# 删除原先目录下的数据
$ rm -rf /mongodb/*
# 创建数据目录
$ for num in `seq 17 26`;do mkdir -p /mongodb/280$num/{conf,data,log};done
3.6.2 部署Shard集群
部署第一个shard集群28021~28023:
# 创建配置文件
$ cat > /mongodb/28021/conf/mongodb.conf <<EOF
systemLog:
destination: file
path: /mongodb/28021/log/mongodb.log
logAppend: true
storage:
journal:
enabled: true
dbPath: /mongodb/28021/data
directoryPerDB: true
#engine: wiredTiger
wiredTiger:
engineConfig:
cacheSizeGB: 1
directoryForIndexes: true
collectionConfig:
blockCompressor: zlib
indexConfig:
prefixCompression: true
net:
bindIp: 127.0.0.1
port: 28021
replication:
oplogSizeMB: 2048
replSetName: sh1
sharding:
clusterRole: shardsvr
processManagement:
fork: true
EOF
# 拷贝配置文件并替换端口
$ cp /mongodb/28021/conf/mongodb.conf /mongodb/28022/conf/
$ cp /mongodb/28021/conf/mongodb.conf /mongodb/28023/conf/
$ sed -i 's/28021/28022/g' /mongodb/28022/conf/mongodb.conf
$ sed -i 's/28021/28023/g' /mongodb/28023/conf/mongodb.conf
部署第二个shard集群28024~28026:
$ cat > /mongodb/28024/conf/mongodb.conf <<EOF
systemLog:
destination: file
path: /mongodb/28024/log/mongodb.log
logAppend: true
storage:
journal:
enabled: true
dbPath: /mongodb/28024/data
directoryPerDB: true
wiredTiger:
engineConfig:
cacheSizeGB: 1
directoryForIndexes: true
collectionConfig:
blockCompressor: zlib
indexConfig:
prefixCompression: true
net:
bindIp: 127.0.0.1
port: 28024
replication:
oplogSizeMB: 2048
replSetName: sh2
sharding:
clusterRole: shardsvr
processManagement:
fork: true
EOF
# 拷贝配置文件并替换端口
$ cp /mongodb/28024/conf/mongodb.conf /mongodb/28025/conf/
$ cp /mongodb/28024/conf/mongodb.conf /mongodb/28026/conf/
$ sed -i 's/28024/28025/g' /mongodb/28025/conf/mongodb.conf
$ sed -i 's/28024/28026/g' /mongodb/28026/conf/mongodb.conf
启动所有实例:
$ for num in `seq 21 26`;do mongod -f /mongodb/280$num/conf/mongodb.conf;done
配置副本集:
# 配置第一个副本集
$ mongo --port 28021 admin
> config = {_id: 'sh1', members: [
{_id: 0, host: '127.0.0.1:28021'},
{_id: 1, host: '127.0.0.1:28022'},
{_id: 2, host: '127.0.0.1:28023',"arbiterOnly":true}]
}
> rs.initiate(config)
{ "ok" : 1 }
sh1:SECONDARY> exit
bye
# 配置第二个副本集
$ mongo --port 28024 admin
> config = {_id: 'sh2', members: [
{_id: 0, host: '127.0.0.1:28024'},
{_id: 1, host: '127.0.0.1:28025'},
{_id: 2, host: '127.0.0.1:28026',"arbiterOnly":true}]
}
> rs.initiate(config)
{ "ok" : 1 }
sh2:SECONDARY> exit
bye
3.6.3 部署Config Server
创建配置文件
$ cat > /mongodb/28018/conf/mongodb.conf <<EOF
systemLog:
destination: file
path: /mongodb/28018/log/mongodb.conf
logAppend: true
storage:
journal:
enabled: true
dbPath: /mongodb/28018/data
directoryPerDB: true
#engine: wiredTiger
wiredTiger:
engineConfig:
cacheSizeGB: 1
directoryForIndexes: true
collectionConfig:
blockCompressor: zlib
indexConfig:
prefixCompression: true
net:
bindIp: 127.0.0.1
port: 28018
replication:
oplogSizeMB: 2048
replSetName: configReplSet
sharding:
clusterRole: configsvr
processManagement:
fork: true
EOF
$ cp /mongodb/28018/conf/mongodb.conf /mongodb/28019/conf/
$ cp /mongodb/28018/conf/mongodb.conf /mongodb/28020/conf/
$ sed -i 's/28018/28019/g' /mongodb/28019/conf/mongodb.conf
$ sed -i 's/28018/28020/g' /mongodb/28020/conf/mongodb.conf
启动实例
$ for num in `seq 18 20`;do mongod -f /mongodb/280$num/conf/mongodb.conf;done
配置副本集:
$ mongo --port 28018 admin
> config = {_id: 'configReplSet', members: [
{_id: 0, host: '127.0.0.1:28018'},
{_id: 1, host: '127.0.0.1:28019'},
{_id: 2, host: '127.0.0.1:28020'}]
}
> rs.initiate(config)
3.6.4 部署mongos
创建配置文件
$ cat > /mongodb/28017/conf/mongos.conf <<EOF
systemLog:
destination: file
path: /mongodb/28017/log/mongos.log
logAppend: true
net:
bindIp: 127.0.0.1
port: 28017
sharding:
configDB: configReplSet/127.0.0.1:28018,127.0.0.1:28019,127.0.0.1:28020
processManagement:
fork: true
EOF
启动mongos:
$ mongos -f /mongodb/28017/conf/mongos.conf
将sh1和sh2节点加入集群中:
# 登录mongos
$ mongo --port 28017 admin
# 添加分片
mongos> db.runCommand( { addshard : "sh1/127.0.0.1:28021,127.0.0.1:28022,127.0.0.1:28023",name:"shard1"} )
{
"shardAdded" : "shard1",
"ok" : 1,
"operationTime" : Timestamp(1638349820, 6),
"$clusterTime" : {
"clusterTime" : Timestamp(1638349820, 6),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
mongos> db.runCommand( { addshard : "sh2/127.0.0.1:28024,127.0.0.1:28025,127.0.0.1:28026",name:"shard2"} )
{
"shardAdded" : "shard2",
"ok" : 1,
"operationTime" : Timestamp(1638349827, 5),
"$clusterTime" : {
"clusterTime" : Timestamp(1638349827, 5),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
查看分片节点
mongos> db.runCommand( { listshards : 1 } )
{
"shards" : [
{
"_id" : "shard1",
"host" : "sh1/127.0.0.1:28021,127.0.0.1:28022",
"state" : 1
},
{
"_id" : "shard2",
"host" : "sh2/127.0.0.1:28024,127.0.0.1:28025",
"state" : 1
}
],
"ok" : 1,
"operationTime" : Timestamp(1638349873, 1),
"$clusterTime" : {
"clusterTime" : Timestamp(1638349873, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
查看分片集群状态:
mongos> sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"minCompatibleVersion" : 5,
"currentVersion" : 6,
"clusterId" : ObjectId("61a739b06c896ba6a5903cac")
}
shards:
{ "_id" : "shard1", "host" : "sh1/127.0.0.1:28021,127.0.0.1:28022", "state" : 1 }
{ "_id" : "shard2", "host" : "sh2/127.0.0.1:28024,127.0.0.1:28025", "state" : 1 }
active mongoses:
"4.2.17" : 1
autosplit:
Currently enabled: yes
balancer:
Currently enabled: yes
Currently running: no
Failed balancer rounds in last 5 attempts: 0
Migration Results for the last 24 hours:
No recent migrations
databases:
{ "_id" : "config", "primary" : "config", "partitioned" : true }
至此,MongoDB分片集群搭建完毕。
3.7 分片集群的使用
- 激活数据库的分片功能,需要登录到mongos:
# 语法:
mongos> db.runCommand({enablesharding: '数据库名称'})
#比如对test数据库开启分片功能:
mongos> db.runCommand({enablesharding: 'test'})
{
"ok" : 1,
"operationTime" : Timestamp(1638350573, 31),
"$clusterTime" : {
"clusterTime" : Timestamp(1638350573, 31),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
- 给数据库的某个表指定分片键,范围分片
# 切换到test库
mongos> use test
# 给表添加一个索引
mongos> db.testRange.ensureIndex({id: 1})
#切换到admin库
mongos> use admin
# 指定片键,开启分片功能,范围分片
mongos> db.runCommand({shardcollection: "test.testRange", key: {id: 1}})
测试:
mongos> use test
mongos> for(i=1;i<1000000;i++){ db.testRange.insert({"id":i,"name":"shenzheng","age":70,"date":new Date()}); }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号