吴恩达深度学习第2课第1周(下)
1.6其它防止过拟合方法
1.扩增数据,(如果不能获取更多的新数据时,你可以将图片水平翻转,任意裁剪图片,对于光学字符,可以扭曲旋转)
2.early stop
即在测试误差小的一个点时,就停止继续迭代下去,如在下图标记的地方就停止迭代
原理:一开始W很小,接近0,神经网络简单,

early stop的缺点,过早的停止迭代,造成训练误差很大
纠正一个点:训练数据集是找到一个合适的算法,以及神经网络架构
验证集也要重新跑一片学习,从b=0开始跑,所以找出验证集也会有cost的函数,只不过一般都会先下降,后增加
1.7 初始化输入(归一化输入)
如果输入的特征之间数据的范围差别很大(如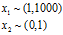 ),这样会造成成本函数非常的狭长,非常不利于梯度下降来趋向最优值
),这样会造成成本函数非常的狭长,非常不利于梯度下降来趋向最优值
归一化方法:
- 均值化
![]()
- 归一化方差
![]()

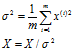
注意:验证集,训练集的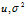 必须是要一样的,
必须是要一样的,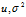 有训练集计算出来,验证集不要再算,用训练集得到的
有训练集计算出来,验证集不要再算,用训练集得到的
1.8 梯度消失或梯度爆炸
先从正向传播来看W
假设b=0,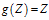 ,则
,则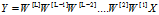
如果层数够深。即使,一开始初始化的W很小,传递到后面A的输出也会产生巨大的变化,A随着层数的增加呈指数式增长/减小
同理应用到反向传播,梯度就会消亡或者爆炸
1.9 随机初始化权重
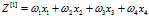
当然是希望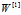 的和为1好一点,(x经过归一化处理后,是均值为0,方差为1的矩阵,这样非常有利于抵消梯度消失或者梯度爆炸)所以对于每一个特征分配的权重希望在
的和为1好一点,(x经过归一化处理后,是均值为0,方差为1的矩阵,这样非常有利于抵消梯度消失或者梯度爆炸)所以对于每一个特征分配的权重希望在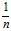 左右,即W随机出来的值均值为0,方差为
左右,即W随机出来的值均值为0,方差为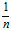
还需要明白一点的是np.random.randn 随机出来的矩阵的元素遵循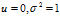 的高斯分布,根据W的方差要为
的高斯分布,根据W的方差要为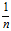 ,所以初始化时有这样一个骚操作(改变方差,不知道为什么是乘以一个标准差,有点小不懂)
,所以初始化时有这样一个骚操作(改变方差,不知道为什么是乘以一个标准差,有点小不懂)
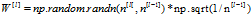
 的维度是与上一层的输入a对应的,所以后面*的是第l-1层的特征
的维度是与上一层的输入a对应的,所以后面*的是第l-1层的特征
注意:当使用relu作为激活函数时,由于会去掉负半轴的数据,所以输入想要维持输出的a还在1附近,就在W上动动手,将它的希望值提高一倍,即方差变成
所以对于当第一层的激活函数为relu时,初始化
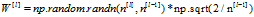
1.10 梯度检验
使用双边求差
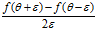 它测出来的值与实际导数值误差为遵循
它测出来的值与实际导数值误差为遵循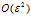 ,即误差值会小于等于选取的
,即误差值会小于等于选取的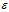 的平方函数,亲测真理(也可以去翻一片高数)
的平方函数,亲测真理(也可以去翻一片高数)
如果是单边预测,那么误差会遵循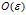 ,选取的
,选取的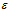 肯定是一个很小的值,在小数范围类,
肯定是一个很小的值,在小数范围类,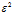 肯定更小
肯定更小
梯度检验作用:验证你的写反向传播时,是否哪里写错了
具体方法:1. 将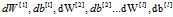 喝到一个矩阵里面去,称作
喝到一个矩阵里面去,称作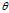
2 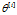 表示第i层的参数
表示第i层的参数
for each i:
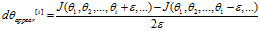
即对于每一个参数都来一个双边求差,并添加到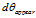 数组中
数组中
然后在于你建立的反向传播算法的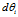 比较
比较
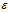 取
取 值,
值,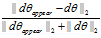 在
在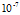 左右最好
左右最好
上式:分子是两个矩阵的距离,还要除以一个数,是防止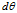 它们本身很大
它们本身很大
梯度验证执行建议:
- 训练的时候不要使用它,是当你程序跑偏需要调试的时候在来用梯度验证,应为梯度验证运行速度太慢了
- 如果差值太大,请确认到时哪一个参数
- 记得有一个正则项的存在
- 当有dropout在时,不要使用梯度验证,应为随机失活,是的J根本不确定。使用梯度验证,请关闭随机失活,
- 小概率事件,W,b在小值运行时,是正确的,但W,b大了之后,就有误差了。
可以在随机初始化时运行梯度检验(不知所云….)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号