[论文笔记] Conversing with Copilot: Exploring Prompt Engineering for Solving CS1 Problems Using Natural Language
Abstract: Copilot 及其他辅助编程的人工智能模型被广泛使用,这篇文章探索了 Copilot 在哪些任务上表现不佳,prompt 在过程中的作用等几个问题。
Introduction:
- Question 1: Copilot 在 CS1 programming problems 上的表现如何?
- Question 2: 当 Copilot 最初失败后,prompt 的修改如何影响修复成功率?
- Question 3: 排除 prompt 的影响,Copilot 表现不好的问题具有哪些共性?
Motivating Example:
以 CodeCheck 上的一道练习为例:
# Given a list of strings and a string 's',
# return the average length of all strings
# containing s
def averageContainingStringS(strings, s):
# Your code here...
现在的 Copilot 倒是蛮正确的,我在本机上结果如下:
# Given a list of strings and a string 's',
# return the average length of all strings
# containing s
def averageContainingStringS(strings, s):
# Initialize the total length and count
totalLength = 0
count = 0
# Iterate through each string in the list
for string in strings:
# If the string contains s
if s in string:
# Increment the count
count += 1
# Increment the total length by the length of the string
totalLength += len(string)
# If there are no strings containing s
if count == 0:
return 0
# Return the average length of all strings containing s
return totalLength / count
论文中更新后的 prompt 如下:
# Given a list of strings and a string 's',
# return the average length of all strings
# containing s
# Also, sum the length of all strings containing s
# Finally, divide the total length by the count
论文通过这个例子指出,更好的 prompt 可以提升 Copilot 的表现
Related Work:
在计算机教育方面,Codex 表现出了一定潜力:做题能力排名学生中 75 位;还可以生成一些练习,80% 的练习有标准答案,但这些标准答案只有大约 30% 可以运行
近期一些工作还探索了 Copilot 对于计算机工程师的影响:一方面,将大问题切分成子问题,并利用一定的 pattern 给出具备完善定义的 prompt 会帮助工程师更好使用 Copilot;另一方面,他们更倾向于使用自然语言与 Copilot 交流
Method:
文章给出了测试 Copilot 性能的一种(朴素)方法,有意思的是他们对于问题的分类方式:Branch, Strings, Lists, Two-Dimensional Arrays 以及他们对错误的分类方式:Conceptual(Copilot 不能理解特定的概念词组), Poor Prompts(提示不足以支持 Copilot 完成所有片段),Verbose Prompts(提示太长,超过了 Copilot 处理长文本的能力),Ambiguous(提示本身具备二义性)
Results And Discussion:

直接给出正确答案的有 79 个,经过提示给出正确答案的有 53 个,解决不了的 34 个
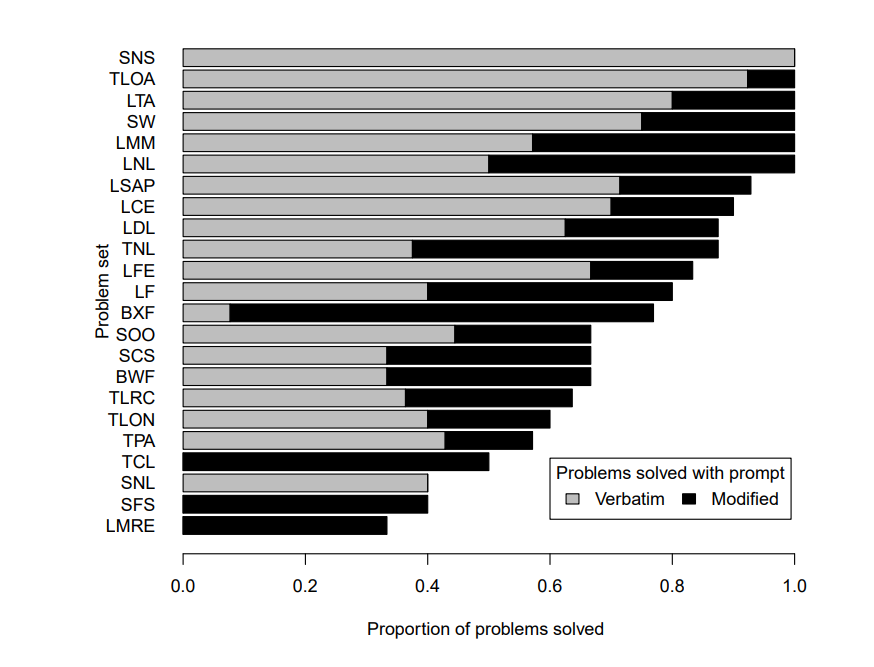
这个图就展示了对于不同的问题分类,Copilot “初见杀” 能力的不同
文章指出,给出逐步的策略(类似于伪代码描述)的 prompt 最有效
When Prompt Engineering Fails:
Copilot 发生 Conceptual 和 Verbose Prompts 的错误最多。文章用两个例子分析了 Verbose Prompts 和 Poor Prompts 是如何发生的。
总结一下:怎么翻到计算机教育界的文章来了,不过文章提出的分类方法(尤其是过长的提示链这个东西)很有意思,或许在 Prompt Engineering 和 Software Engineering 上也可以有很好的应用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号