NCCL 前言
NCCL 的原理
NCCL是专为NVIDIA GPU设计的集合通信库,它和 MPI 一样支持多种高效的集体通信操作,如广播、归约、全收集等。通信的实现方式分为两种类型:机器内通信与机器间通信。
机器内通信:
-
GPU Direct Shared Memory(2010年6月引入):共享内存(QPI/UPI),比如:CPU与CPU之间的通信可以通过共享内存。
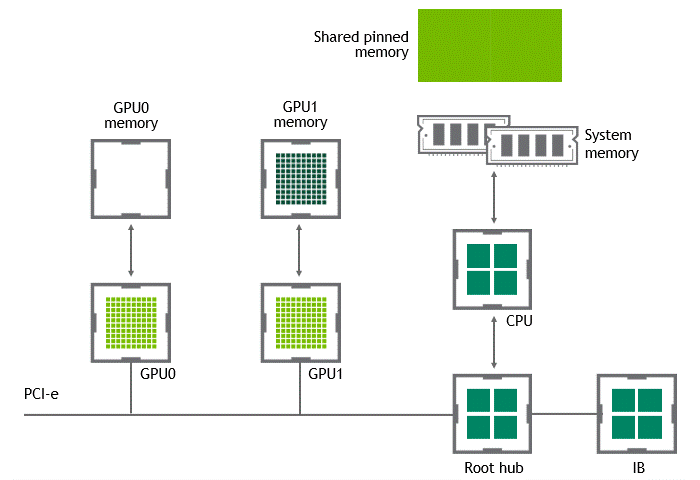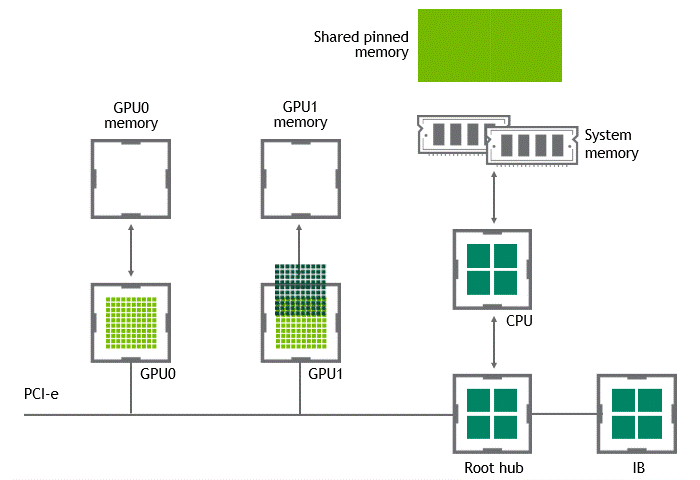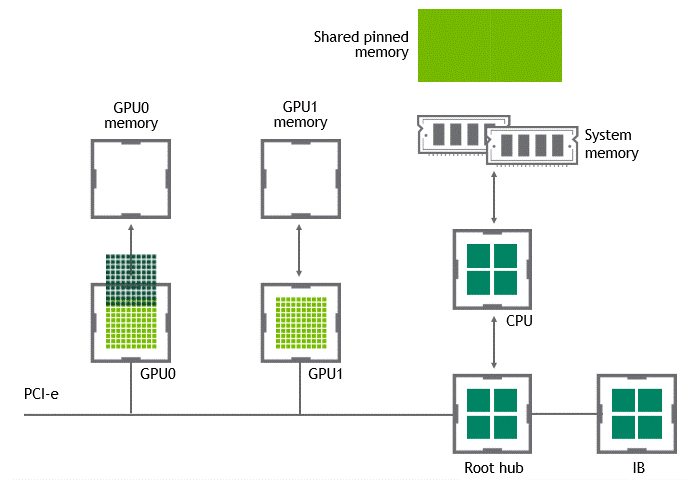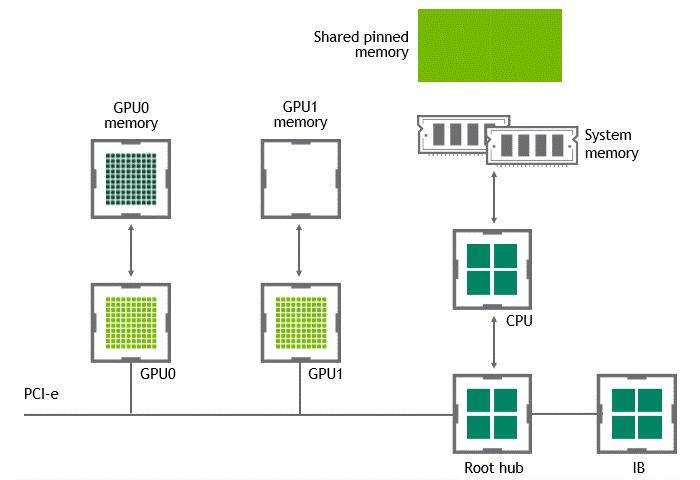
某些工作负载需要位于同一服务器中的两个或多个 GPU 之间进行数据交换,来自 GPU 的数据将首先通过 CPU 和 PCIe 总线复制到主机固定的共享内存。然后,数据将通过 CPU 和 PCIe 总线从主机固定的共享内存复制到目标 GPU,数据在到达目的地之前需要被复制两次。
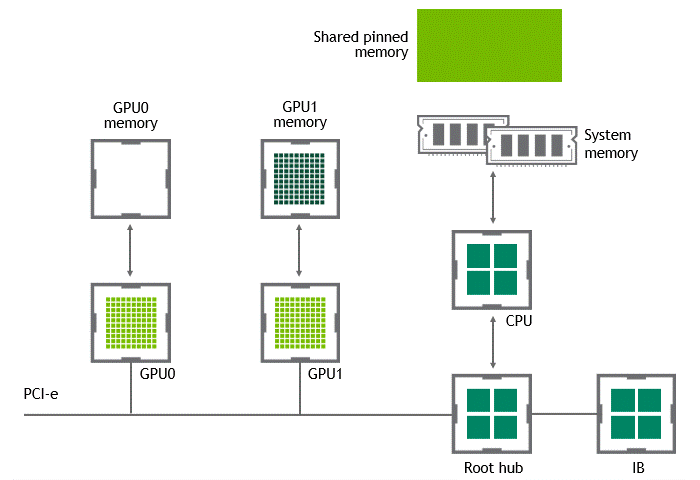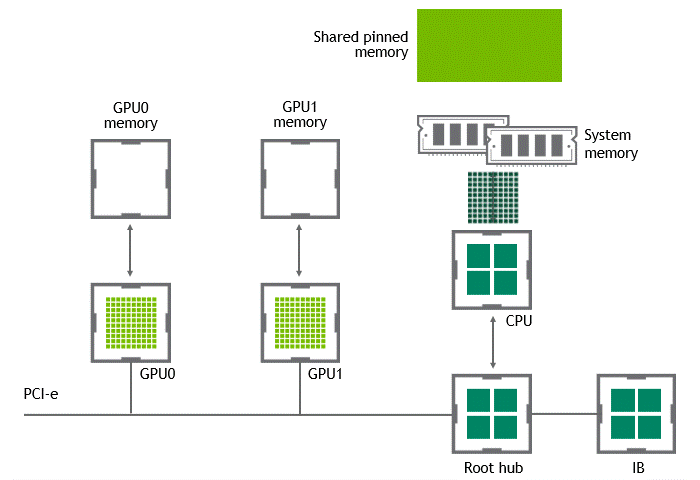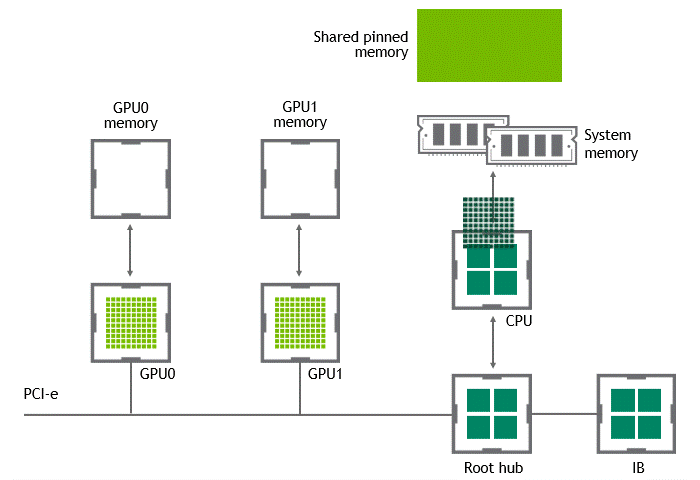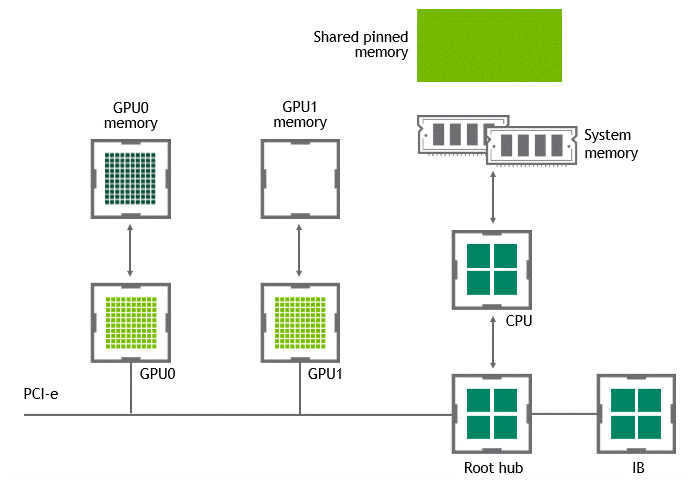
-
GPU Direct P2P(2011年)
有了 GPU Direct P2P 通信技术后,将数据从源 GPU 复制到同一节点中的另一个 GPU 不再需要将数据临时暂存到主机内存中。如果两个 GPU 连接到同一 PCIe 总线,GPUDirect P2P 允许访问其相应的内存,而无需 CPU 参与。前者将执行相同任务所需的复制操作数量减半。
-
NVLink
NVLink是NVIDIA开发的一种高速互连技术,它提供了比传统PCIe更高的带宽和更低的延迟。通过NVLink,GPU之间的数据传输不再通过PCIe总线,而是直接通过NVLink连接。NVLink通过NVSwitch设备实现多GPU之间的全互联,这对于高性能计算和深度学习应用中的大规模并行处理尤为重要。通常是GPU与GPU之间的通信,也可以用于CPU与GPU之间的通信。
-
PCIe
通常是CPU与GPU之间的通信。
机器间通信:
-
GPU Direct Storage
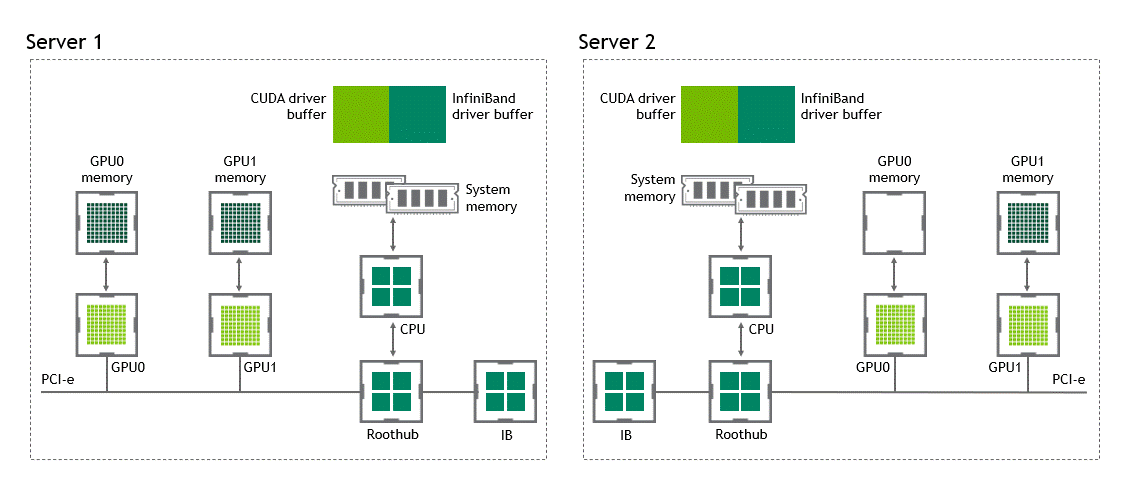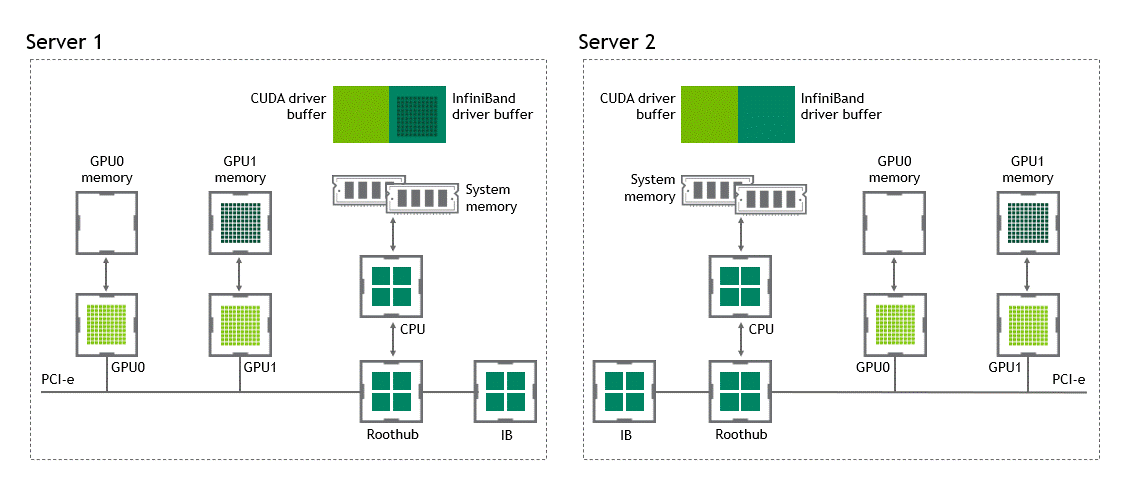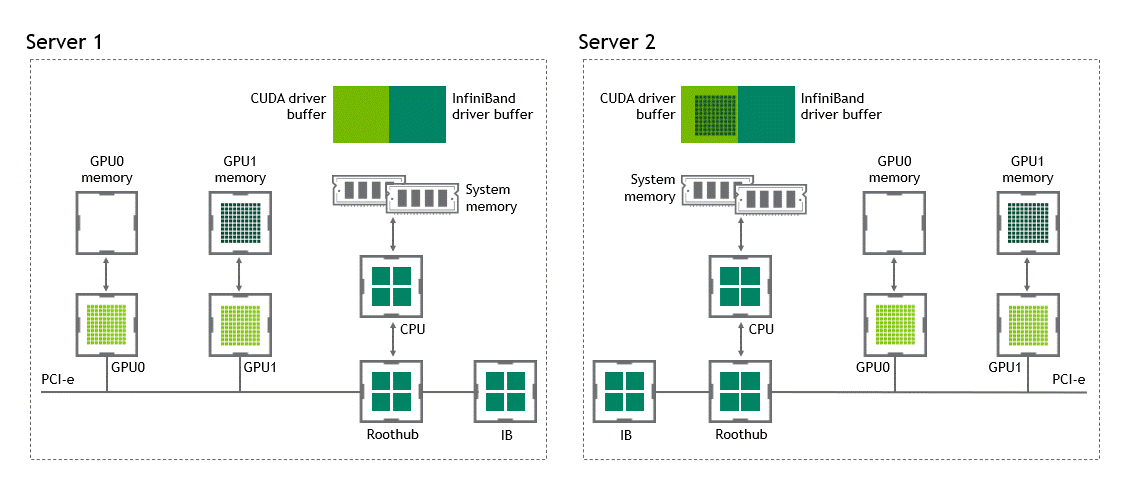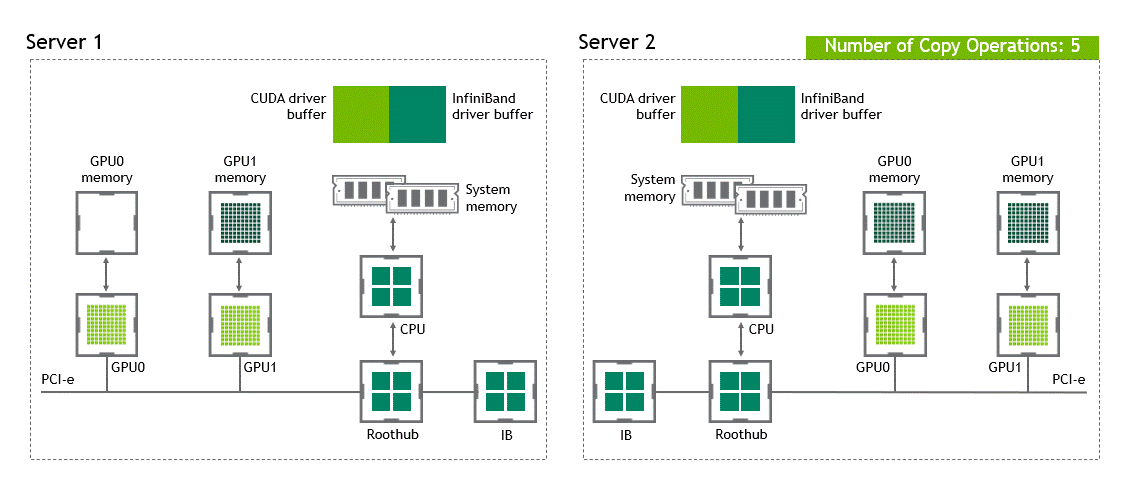
在 NVIDIA GPU Direct 远程直接内存访问技术不可用的多节点环境中,在不同节点的两个 GPU 之间传输数据需要 5 次复制操作:
-
将数据从源 GPU 传输到源节点中的主机固定内存缓冲区时,将发生第一个副本。
-
然后,该数据将复制到源节点的 NIC 驱动程序缓冲区。
-
在第三步中,数据通过网络传输到目标节点的 NIC 驱动程序缓冲区。
-
将数据从目标节点 NIC 的驱动程序缓冲区复制到目标节点中的主机固定内存缓冲区时,会发生第四次复制。
-
最后一步需要使用 PCIe 总线将数据复制到目标 GPU。
-
-
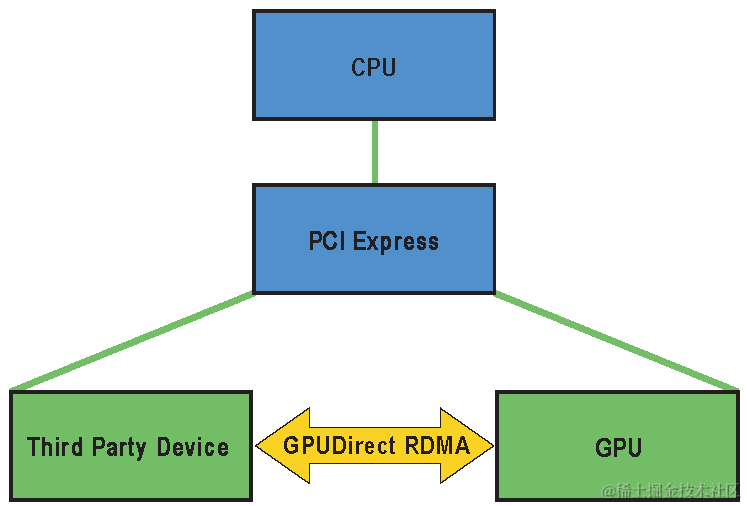
GPU Direct RDMA (2014年)
下面以InfiniBand为例:
GPU Direct RDMA 结合了 GPU 加速计算和 RDMA(Remote Direct Memory Access)技术,实现了在 GPU 和 RDMA 网络设备之间直接进行数据传输和通信的能力。它允许 GPU 直接访问 RDMA 网络设备中的数据,无需通过主机内存或 CPU 的中介。
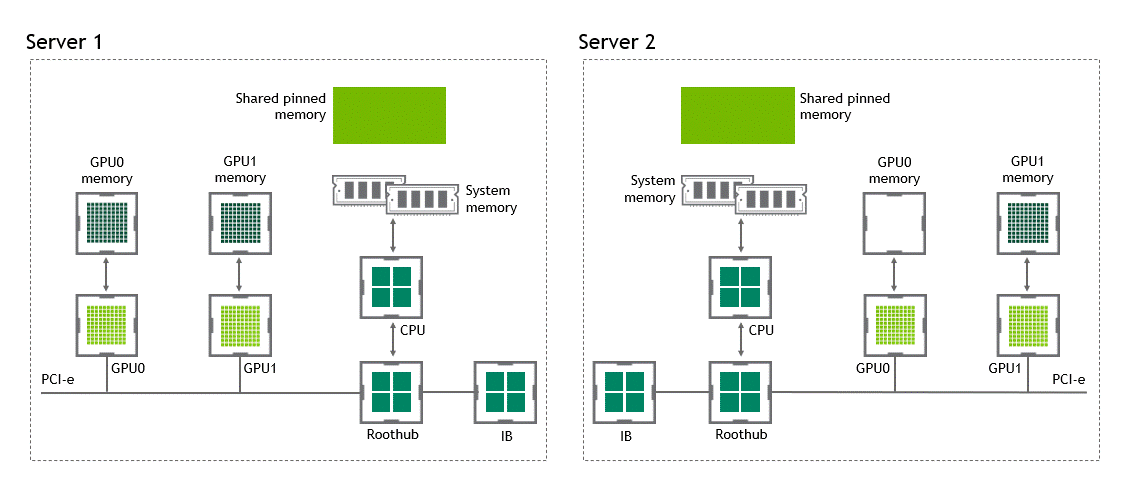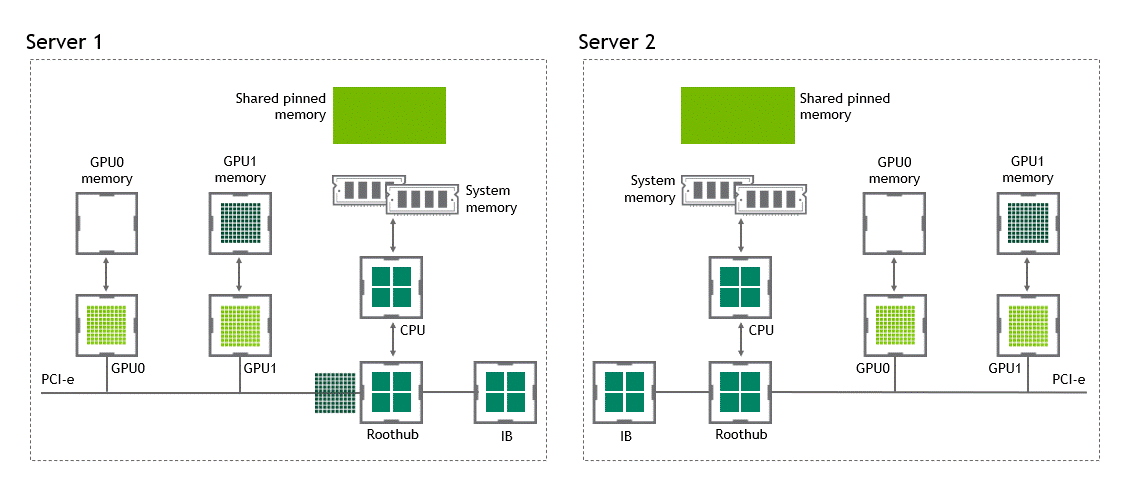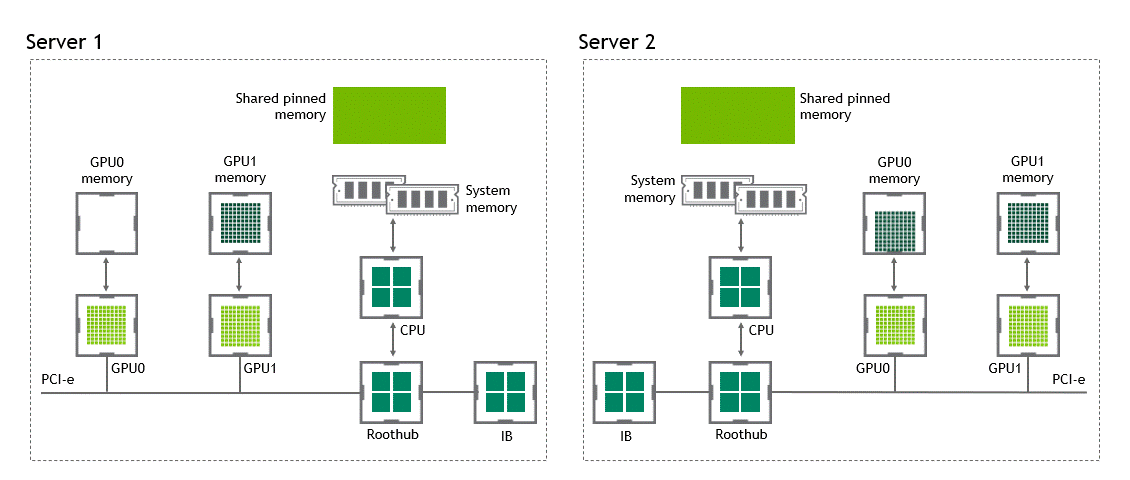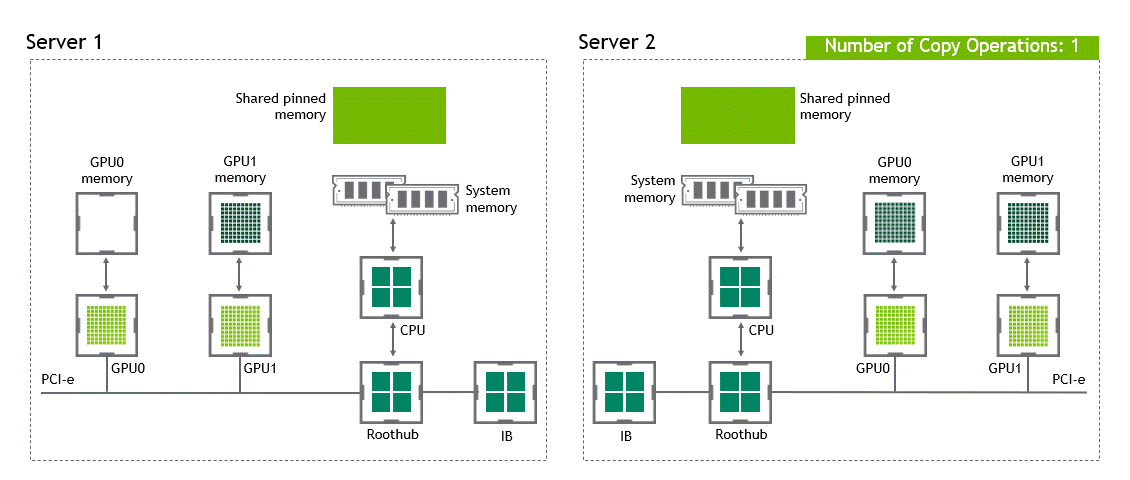
使用 GPU Direct RDMA 两个 GPU 设备必须共享相同的上游 PCI Express root complex。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号