
Hadoop:Yarn资源调度
1、Yarn是什么?
Apache Hadoop YARN (Yet Another Resource Negotiator 另一种资源协调者)是一种新的Hadoop资源管理器,提供一个通用资源管理系统和调度平台,可为上层应用提供统一的资源管理和调度。可以把Hadoop YARN理解为相当于一个分布式的操作系统平台,而MapReduce等计算程序则相当于运行于操作系统之上的应用程序,YARN为这些程序提供运算所需的资源(内存,CPU等,磁盘由HDFS管理)。Yarn支持各种计算框架,不关心你干是干什么的,只关心你要的资源。
2、Yarn架构
YARN 的基本思想是将资源管理和作业调度/监控的功能拆分为单独的守护进程。包括一个全局的 ResourceManager ( RM ) 和每个应用程序的ApplicationMaster ( AM )。Yarn的整体架构图如下:
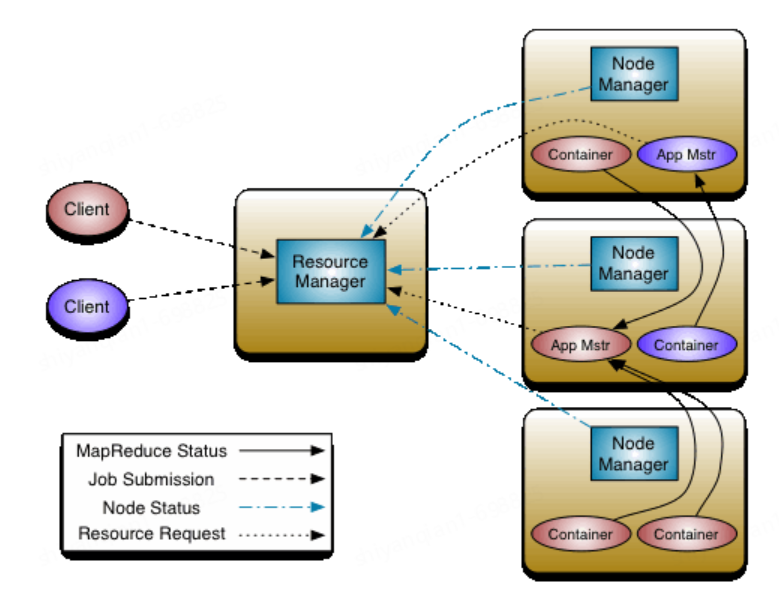
2.1、ResourceManager
包括两个主要组件:Scheduler 和ApplicationsManager。Scheduler负责资源的分配与调度(内存、CPU、磁盘、网络等)。ApplicationsManager 负责处理客户端请求,接受作业提交、启动或监控 ApplicationMaster。每个应用程序的 ApplicationMaster 负责与 Scheduler 协商适当的资源容器,跟踪其状态并监控进度。
2.2、NodeManager
YARN中的从角色,一台机器上一个,负责管理本机器上的计算资源。根据RM命令,启动Container容器,监视容器的资源使用功能情况,并且项RM主角色汇报资源使用情况。
2.3、ApplicationMaster
负责数据的切分,为应用程序申请资源并分配给内部的任务;
2.4、Container
封装某个节点的资源(内存、CPU、磁盘、网络等)
3、Yarn工作原理

(1)MR程序提交到客户端所在的节点。
(2)YarnRunner向ResourceManager申请一个Application。
(3)RM将该应用程序的资源路径返回给YarnRunner。RM给Client返回该job资源的提交路径(公共的资源提交路径,保证其他NM都能访问到)和作业id
(4)该程序将运行所需资源提交到HDFS上。
(5)程序资源提交完毕后,申请运行mrAppMaster。
(6)RM将用户的请求初始化成一个Task,会有一个节点来运行这个Task.
(7)其中一个NodeManager领取到Task任务。
(8)该NodeManager创建容器Container,并产生MRAppmaster。
(9)Container从HDFS上拷贝资源到本地。
(10)MRAppmaster向RM 申请运行MapTask资源。
(11)RM将运行MapTask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务并创建容器。
(12)MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序。
(13)MrAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask。
(14)NodeManager领取到ReduceTask任务
(15)ReduceTask向MapTask获取相应分区的数据。
(16)程序运行完毕后,MR会向RM申请注销自己。
4、Yarn资源调度
YARN支持多种调度算法,包括FIFO Scheduler、Capacity Scheduler和Fair Scheduler
4.1 先进先出FIFO Scheduler
FIFO Scheduler把应用按提交的顺序排成一个队列,这是一个先进先出队列,在进行资源分配的时候,先给队列中最先到达的应用进行分配资源。待最前面的应用需求满足后再给下一个分配,以此类推。FIFO Scheduler是最简单也是最容易理解的调度器,也不需要任何配置,但它并不适用于共享集群。并且在FIFO 调度器中,小任务会被大任务阻塞。

4.2 容量调度器(Capacity Scheduler) -Apache默认的调度策略
该调度策略基于一个思想:每个用户都可以使用特定量的资源,但集群空闲时,也可以使用整个集群的资源。多队列:每个队列可配置一定的资源量,每个队列内部采用FIFO调度策略。

容器调度资源分配算法为:
1、队列资源分配:从root开始,使用深度优先算法,优先选择资源占用率最低队列分配资源。
2、作业资源分配:默认按照提交作业的优先级和提交时间顺序分配资源。
3、容器资源分配:按照容器的优先级分配资源,如果优先级相同,按照数据本地性原则
(1)任务和数据在同一节点
(2)任务和数据在同一机架
(3)任务和数据不在同一节点也不在同一机架

4.3 Fair Scheduler
Fair调度器的设计目标是为所有的应用分配公平的资源。同队列的所有任务共享资源,在时间尺度上获得公平的资源。每个用户只有特定数量的资源可以使用,不可以超出这个限制,即使集群整体很空闲。

Fair Scheduler资源分配算法来保证公平,常用的是:max-min fairness 算法。这种策略会最大化系统中的一个用户收到的最小分配。如果每个用户都有足够的请求,会给予每个用户一份相等的资源。
4.3.1 max-min fairness 算法
(1)资源按照需求递增的顺序进行分配
(2)不存在用户得到的资源超过自己的需求
(3)未得到满足的用户等价的分享资源
在执行资源分配时,算法按照上述 3 条原则进行多次迭代,每次迭代中资源均平均分配,如果还有剩余资源,就进入下一次迭代,一直到所有用户资源得到满足或集群资源分配完毕。
假设系统总资源为100,需要分配的用户有A、B、C、D四位,资源需求为:30,15, 20, 50,分配流程为:
(1)资源按照需求递增的顺序进行排列:B:15, C:20, A:30, D:50
(2)不存在用户得到的资源超过自己的需求:平均空闲资源为:100/4=25,按照(1)进行分配之后,用户资源需求量为:B:0, C:0, A:5, D:25,但是用户不会得到超过需求的资源,因此B剩余10,C剩余5,总剩余15;
(3)未得到满足的用户等价的分享资源:还有两位用户有资源需求,平均空闲资源为:15/2=7.5,分配之后,用户的需求量为:A:0, D:17.5,剩余资源:2.5
(4)继续重复,只剩一位用户有资源需求,平均资源空闲为:2.5/1=2.5,分配之后D:15,资源剩余0
(5)资源分配完成,结束。

4.3.2 Weighted max-mmin fairness
max-min fairness 算法假设每个用户获得资源的权重一样,因此对资源进行等分处理。但是如果用户的权重不同,需要按照权重来切分资源。
假设系统资源总数为32,用户A,B,C,D需要的资源为:8,4,15,8,权重分别为:5,8,1,2。分配流程为:
(1)将总资源按照权重进行切分:10, 16, 2, 4
(2)遍历可以满足需求的用户:需求为:A:8,B:4, C:15, D: 8。可得到为:A:10, B: 16, C:2, D: 4,分配之后,需求为:A:0, B:0, C:13, D: 4。剩余资源为:2+12=14;
(3)继续下一次迭代:需求为:C:13, D: 4,权重为C:1, D:2,总资源按照权重分配为(4.666,9.333),分配后需求为:C:8.34,D:0,剩余资源为:5.33
(4)继续下次迭代为:需求:C:8.34,总资源5.33,分配后:C:3.01,剩余资源0
(5)迭代结束
4.3.3 DRF(Dominant Resource Fairness)算法
max-min fairness解决了单一资源的公平分配,但是现在的资源管理中往往不止一种资源,多种资源的分配问题,Berkeley等提出了DRF算法。

A用户的资源占比为1/9 CPU, 4/18=2/9 RAM,则A的Dominant Resource 就是 RAM
B用户资源占比为:3/9=1/3 CPU. 1/18 RAM,则B的Dominant Resource 为 CPU;

计算方法为:假设A用户需要的资源为:<x CPU, 4x GB>, B用户需要<3y CPU, y GB>
A的Dominant Resource为4x/18 = 2x/9, B的Dominant Resource为3y/9 = y/3 要保证两个用户的Dominant Resource相同,则需要2x/9=y/3,因此

得到x = 3,y = 2.因此DRF均衡用户的Dominant Resource ,A用户运行3个任务<3CPUs, 12GB RAM>,B运行两个任务<6 CPUs, 2GB RAM>。这种分配保证了每个用户拥有相同的Dominant Resource,A占用2/3的RAM,B占用2/3的CPU。
4.4 Yarn资源调度器配置
yarn资源调度器是在yarn-site.xml中配置。
FIFO
<property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.fifo.FifoScheduler</value> </property>
Capacity Scheduler
<property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.capacity.CapacityScheduler</value> </property>
假如层次队列为:
root
├── prod 40%
└── dev 60%
├── eng 50%
└── science 50%
配置为:
<configuration> <property> <name>yarn.scheduler.capacity.root.queues</name> <value>prod,dev</value> </property> <property> <name>yarn.scheduler.capacity.root.dev.queues</name> <value>eng,science</value> </property> <property> <name>yarn.scheduler.capacity.root.prod.capacity</name> <value>40</value> </property> <property> <name>yarn.scheduler.capacity.root.dev.capacity</name> <value >60</value> </property> <property> <name>yarn.scheduler.capacity.root.dev.maximuin-capacity</name> <value>75</value> </property> <property> <name>yarn.scheduler.capacity.root.dev.eng.capacity</name> <value >50</value> </property> <property> <name>yarn.scheduler.capacity.root.dev.science.capacity</name> <value >50</value> </property> </configuration>
Fair Scheduler
<property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value> <description>配置Yarn使用的调度器插件类名;Fair Scheduler对应的是:org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</description> </property> <property> <name>yarn.scheduler.fair.allocation.file</name> <value>/etc/hadoop/conf/fair-scheduler.xml</value> <description>配置资源池以及其属性配额的XML文件路径(本地路径)</description> </property> <property> <name>yarn.scheduler.fair.preemption</name> <value>true</value> <description>开启资源抢占,default is True</description> </property> <property> <name>yarn.scheduler.fair.user-as-default-queue</name> <value>true</value> <description>设置成true,当任务中未指定资源池的时候,将以用户名作为资源池名。这个配置就实现了根据用户名自动分配资源池。default is True</description> </property> <property> <name>yarn.scheduler.fair.allow-undeclared-pools</name> <value>false</value> <description>是否允许创建未定义的资源池。如果设置成true,yarn将会自动创建任务中指定的未定义过的资源池。设置成false之后,任务中指定的未定义的资源池将无效,该任务会被分配到default资源池中。,default is True</description> </property> <!– scheduler end –>

