

倒排索引
每种数据库都有自己要解决的问题(或者说擅长的领域),对应的就有自己的数据结构,而不同的使用场景和数据结构,需要用不同的索引,才能起到最大化加快查询的目的。
对 Mysql 来说,是 B+ 树,对Elasticsearch/Lucene 来说,是倒排索引。
与正排索引区别
在没有搜索引擎时,我们是直接输入一个网址,然后获取网站内容,这时我们的行为是:
document -> to -> words
通过文章,获取里面的单词,此谓「正向索引」,forward index.
后来,我们希望能够输入一个单词,找到含有这个单词,或者和这个单词有关系的文章:
word -> to -> documents
单词-文档矩阵
一种表达单词和文档之间所具有的包含关系的概念模型。
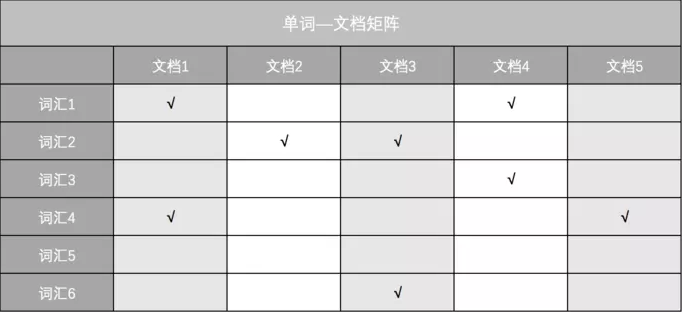
实例
假设文档集合包含五个文档,每个文档内容如下图所示,在图中最左端一栏是每个文档对应的文档编号。我们的任务就是对这个文档集合建立倒排索引。

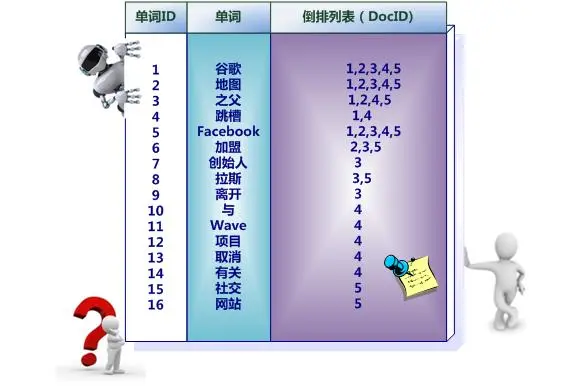
- 用分词系统将文档自动切分成单词序列。这样每个文档就转换为由单词序列构成的数据流,为了系统后续处理方便,需要对每个不同的单词赋予唯一的单词编号,同时记录下哪些文档包含这个单词,在如此处理结束后,我们可以得到最简单的倒排索引。
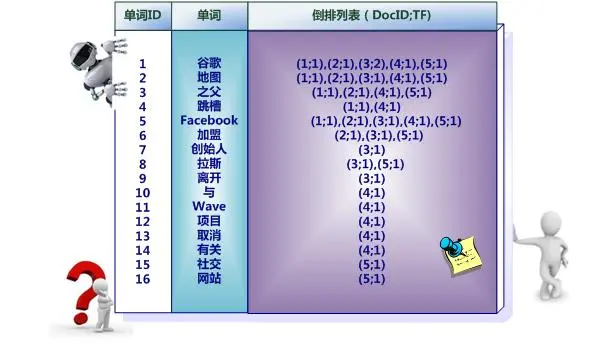
- 记录单词在文件中出现的位置
-
唯有热爱方能抵御岁月漫长。
