

ElasticSeasrch
一、简介

Elasticsearch 是一个非常强大的搜索引擎,Elasticsearch 是一个分布式、免费和开放的搜索和分析引擎,适用于所有类型的数据,包括文本、数字、地理空间、结构化和非结构化数据。
Elasticsearch 可用于多种用例:
- 应用搜索
- 网站搜索
- 企业搜索
- 日志记录和日志分析
- 基础设施指标和容器监控
- 应用性能监控
- 地理空间数据分析和可视化
- 安全分析
- 商业分析
Elasticsearch 不仅仅是 Lucene 和全文搜索引擎,它还提供:
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 实时分析的分布式搜索引擎
- 可以扩展到上百台服务器,处理 PB 级结构化或非结构化数据
二、重要概念
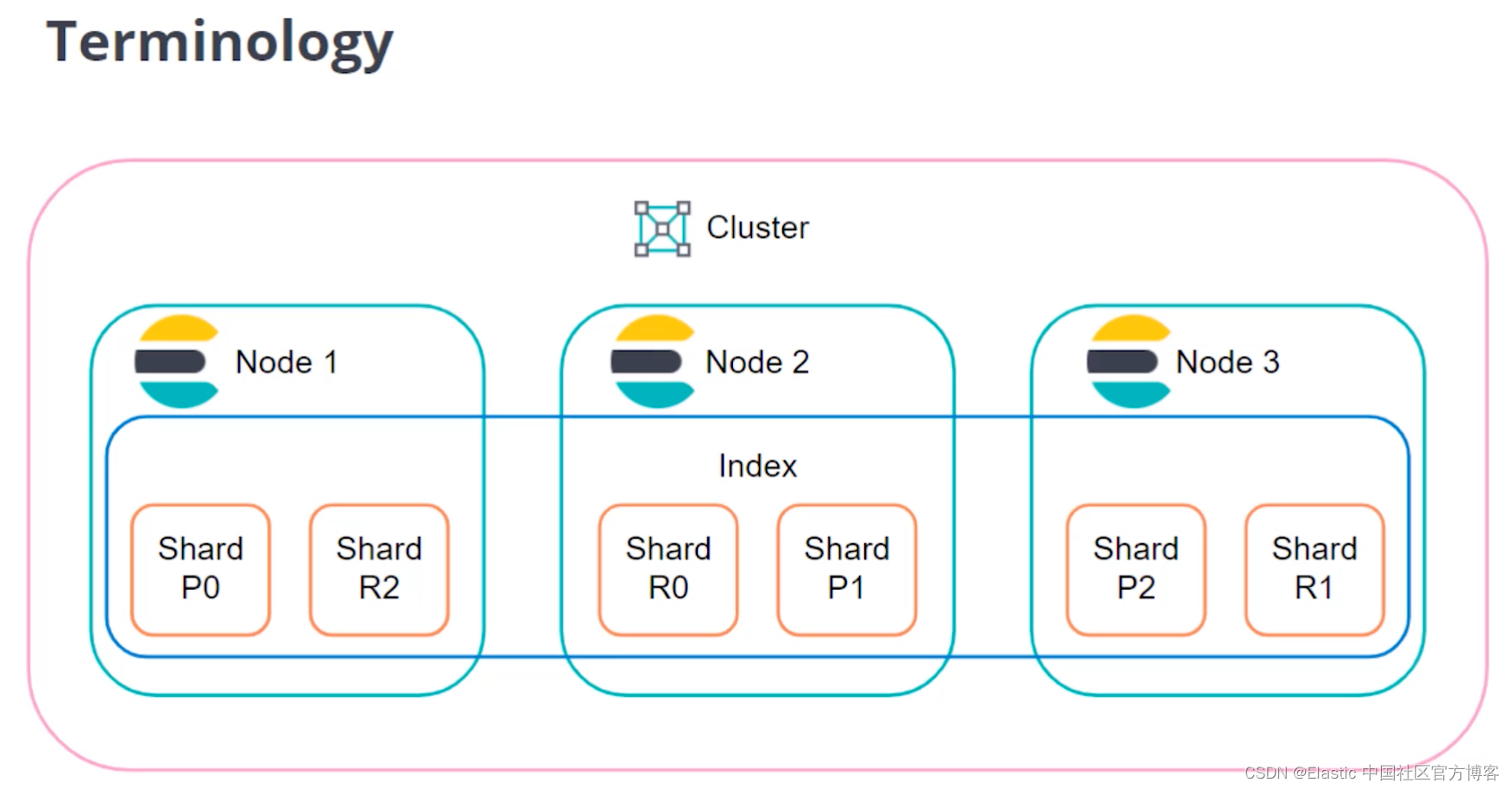
1、Cluster
Cluster 也就是集群的意思。Elasticsearch 集群由一个或多个节点组成,可通过其集群名称进行标识。可以在 config/elasticsearch.yml 里定制我们的集群的名字,当其他节点启动时,只要 cluster.name 属性相同,它们就可以加入与现有节点相同的集群。
2、Node
单个 Elasticsearch 实例。 在大多数环境中,每个节点都在单独的盒子或虚拟机上运行。一个集群由一个或多个 node 组成。Node可以分为:
- master-eligible:可以作为主 node。一旦成为主 node,它可以管理整个 cluster 的设置及变化:创建,更新,删除 index;添加或删除 node;为 node 分配 shard,应用的集群设置;
- data:数据 node。数据节点是实际的索引、搜索、删除和其他与文档相关的操作发生的地方。这些节点托管索引文档。
- ingest: 数据接入,预处理日志字符串以提取有意义的数据,使用 NLP 工具丰富文本字段的内容,使用 ML 计算字段丰富内容
- machine learning:机器学习节点执行 ML 算法并检测异常。
- Transform node:它用于数据的汇总。
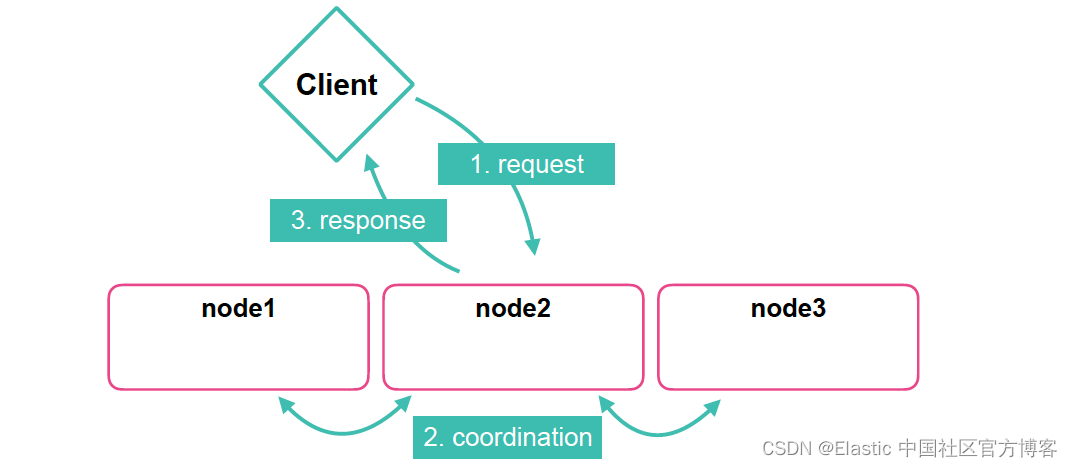
- coordinating node:调节点负责端到端地处理客户端的请求。这种节点通常是接受客户端的 HTTP 请求的。当向 Elasticsearch 提出请求时,协调节点会接收该请求。 在接受请求后,协调器请求集群中的其他节点处理请求。 它在收集和整理结果并将它们发送回客户端之前等待响应。 它本质上充当工作管理器,将传入的请求分发到适当的节点并响应客户端。
3、Doucument
文档通常是数据的 JSON 表示形式。
当文档被 Elasticsearch 索引时,它存储在 _source 字段中。 每个文档中还添加了以下附加系统字段:
- 存储文档的索引名称由 _index 字段指示。
- 文档的索引范围的唯一标识符存储在 _id 字段中。
4、Type
类型是文档的逻辑容器,类似于表是行的容器。
5、Index
在 Elasticsearch 中,索引是文档的集合。一个 Elasticsearch 的 index 分布于一个或多个 shard 之中,每个 Index 一个或许多的 documents 组成,并且这些 document 可以分布于不同的 shard 之中。
6、Shard
Shard 也被称作为分片。分片是保存数据、创建支持的数据结构(如倒排索引)、管理查询和分析 Elasticsearch 中的数据的软件组件。
- Primary shard: 每个文档都存储在一个 primary shard。 索引文档时,它首先在 primary shard上编制索引,然后在此分片的所有副本上(replica)编制索引。索引可以包含一个或多个主分片。Primary 可以同时出来读和写操作。
- Replica shard: 每个主分片可以具有零个或多个副本。 replica 是主分片的副本。replica 只能是只读的,不可以进行写入操作。
- Primary 及 replica shards 一直是分配在不同的 node 上的,这样既提供了冗余度,也同时提供了可扩展性。
- 增加副本 shard 的数量,可以提高搜索的速度,这是因为更多的 shard 可以帮我们进行同时进行搜索。但是副本 shard 数量的增多,也会影响数据写入的速度。增加 primary shard 的数量可以提高数据的写入速度,这是因为有更多的 shard 可以帮我们同时写入数据。
Shard 健康:
红色:集群中未分配至少一个主分片。这表明缺少一些主分片,并且这些索引处于红色状态。
黄色:已分配所有主副本,但未分配至少一个副本。这意味着缺少一些节点或分片,但它们不会损害集群的功能。
绿色:分配所有分片
7、Replia
默认情况下,Elasticsearch 为每个索引创建一个主分片和一个副本。主副本和副本分片之间的主要区别在于只有主分片可以接受索引请求。副本和主分片都可以提供查询请求。
三、安装
1、下载
https://www.elastic.co/cn/downloads/elasticsearch
2、修改配置文件
config/elasticsearch.yml
node.name: node1
path.data: /data/elasticsearch
xpack.security.enabled: false
xpack.security.enrollment.enabled: false
discovery.type: single-node
3、启动
bin/elasticsearch
4、访问 localhost:9200

4、下载kibana https://www.elastic.co/cn/downloads/kibana
5、修改配置文件
config/kibana.yml
elasticsearch.hosts: ["http://localhost:9200"]
i18n.locale: "zh-CN"
6、访问 localhost:5601

7、控制台发送get 请求

四、创建
1、创建文档
创建一个叫做 test 的索引(index),并插入一个文档(document)。
PUT test/_doc/1 { "user": "GB", "uid": 1, "city": "Beijing", "province": "Beijing", "country": "China" }

在通常的情况下,新写入的文档并不能马上被用于搜索。新增的索引必须写入到 Segment 后才能被搜索到。需要等到 refresh 操作才可以。在默认的情况下每隔一秒的时间 refresh 一次。
2、查看每个字段schema
在 Elasticsearch 的术语中,mapping 被称作为 Elasticsearch 的数据 schema。文档中的所有字段都需要映射到 Elasticsearch 中的数据类型。 mapping 指定每个字段的数据类型,并确定应如何索引和分析字段以进行搜索

3、Elasticsearch 的数据类型:
- text:全文搜索字符串
- keyword:用于精确字符串匹配和聚合
- date 及 date_nanos:格式化为日期或数字日期的字符串
- byte, short, integer, long:整数类型
- boolean:布尔类型
- float,double,half_float:浮点数类型
- 分级的类型:object 及 nested。
4、创建一个索引 test,并且含有 id 及 message 字段
id 字段为 keyword 类型,而 message 字段为 text 类型

5、追加字段:age

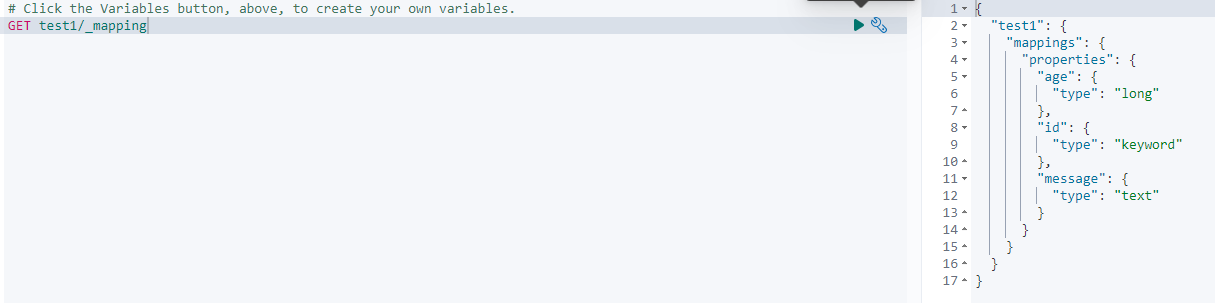
6、查看test1的mapping
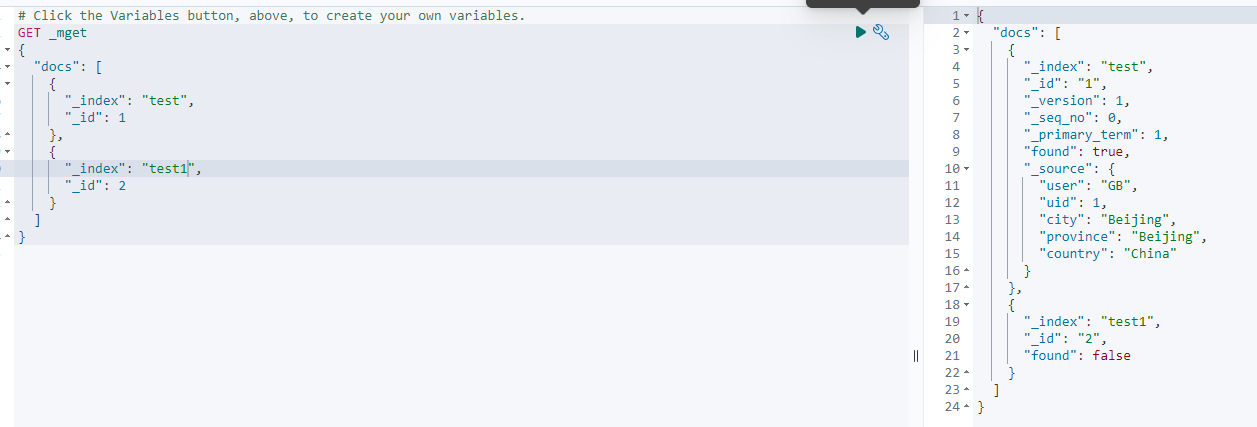
7、获取多个
8、修改
可以使用 POST 的命令来修改改一个文档。通常使用 POST 来创建一个新的文档。在使用 POST 的时候,不用去指定特定的 id,系统会自动生成。
但是修改一个文档时,通常会使用 PUT 来进行操作,并且需要指定一个特定的 id 来进行修改

修改成功

修改部分字段

修改成功

查询并修改

查看修改结果
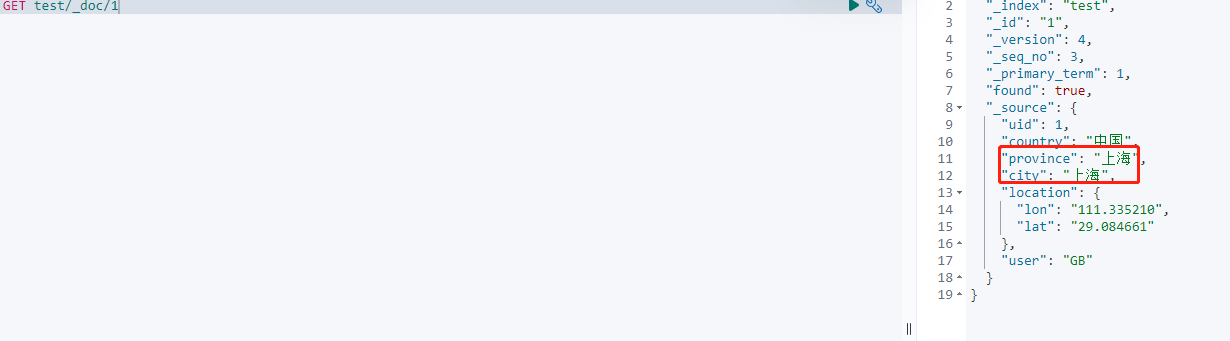
使用script更新
POST twitter/_update/1 { "script" : { "source": "ctx._source.city=params.city", "lang": "painless", "params": { "city": "长沙" } } }
9、更新或插入(upsert)
“upsert” 宽松地表示更新或插入,即更新文档(如果存在),否则,插入新文档。


10、检查一个文档是否存在

11、删除一个文档

查询并删除

12、批处理命令(_bulk)
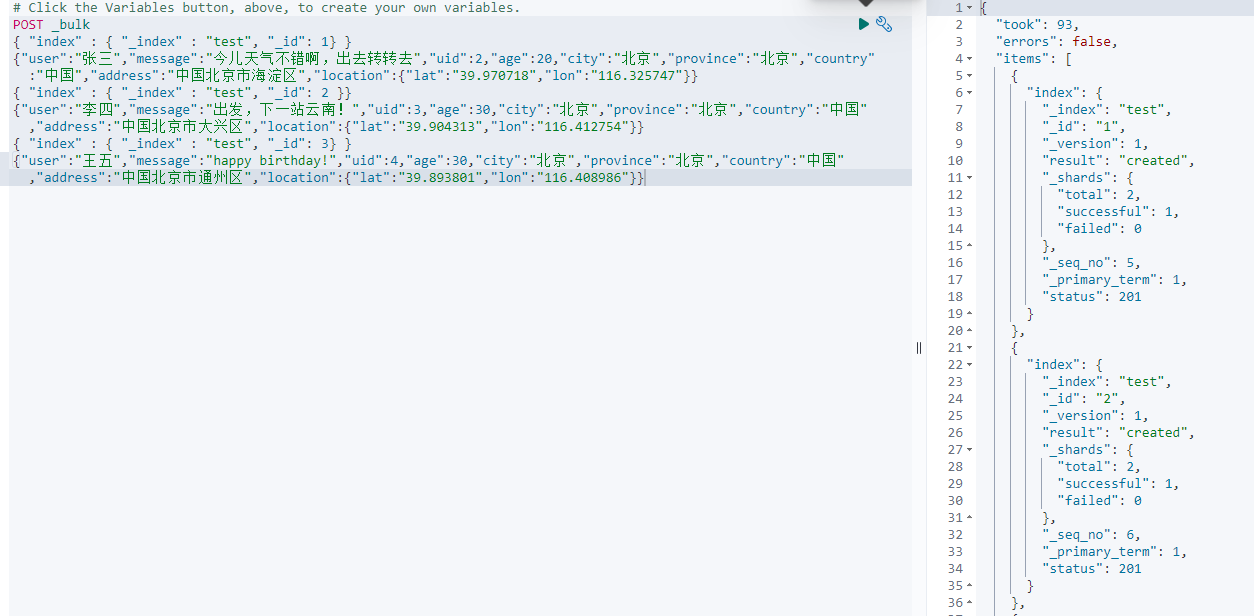
在输入命令时,需要特别的注意:千万不要添加除了换行以外的空格,否则会导致错误。在上面使用的 index 用来创建一个文档。
13、查看数据条数

14、索引统计
GET twitter/_stats
每个索引都会生成统计信息,例如它拥有的文档总数、已删除文档的计数、分片的内存、获取和搜索请求数据等。_stats API 帮助检索索引的统计信息,包括主分片和副本分片。
15、打开关闭索引
Elasticsearch 支持索引的在线/离线模式。 使用脱机模式时,在群集上几乎没有任何开销地维护数据。 关闭索引后,将阻止读/写操作。
POST test/_close
POST test/_open
16、冻结/解冻索引
冻结索引(freeze index)在群集上几乎没有开销(除了将其元数据保留在内存中),并且是只读的。 只读索引被阻止进行写操作.
冻结索引受到限制,以限制每个节点的内存消耗。 默认情况下,即使已明确命名冻结索引,也不会针对冻结索引执行搜索请求。如果要包含冻结索引做搜索,必须使用查询参数 ignore_throttled = false 来执行搜索请求。
POST twitter/_freeze
POST twitter/_unfreeze
五、搜索
在 Elasticsearch 中的搜索中,有两类搜索:
- queries
- aggregations
query 可以进行全文搜索,而 aggregation 可以对数据进行统计及分析。
Profile API 是调试工具。 它添加了有关执行的详细信息搜索请求中的每个组件。
1、可以使用SQL查询
GET /_sql? { "query": """ SELECT * FROM test WHERE age = 30 """ }
2、match查询
GET test/_search { "query": { "match": { "city": "北京" } } }
3、前缀查询
返回在提供的字段中包含特定前缀的文档。
GET test/_search { "query": { "prefix": { "user": { "value": "朝" } } } }
4、精确查询
GET test/_search { "query": { "terms": { "user.keyword": [ "张三", "李四 ] } } }
5、复合查询

GET test/_search { "query": { "bool": { "must": [ { "match": { "city": "北京" } }, { "match": { "age": "30" } } ] } } }
6、位置查询
GET test/_search { "query": { "bool": { "must": [ { "match": { "address": "北京" } } ] } }, "post_filter": { "geo_distance": { "distance": "3km", "location": { "lat": 39.920086, "lon": 116.454182 } } } }
7、范围查找
GET test/_search { "query": { "range": { "age": { "gte": 30, "lte": 40 } } } }
8、存在查询
GET twitter/_search { "query": { "exists": { "field": "city" } } }
9、匹配短语
GET twitter/_search { "query": { "match": { "message": "happy birthday" } } }
10、Multi Search
使用单个 API 请求执行几次搜索。这个 API 的好处是节省 API 的请求个数,把多个请求放到一个 API 请求中来实现。
POST _bulk {"index":{"_index":"twitter1","_id":1}} {"user":"张庆","message":"今儿天气不错啊,出去转转去","uid":2,"age":20,"city":"重庆","province":"重庆","country":"中国","address":"中国重庆地区","location":{"lat":"39.970718","lon":"116.325747"}}
11、查询多个索引
GET test*/_search
GET /test,test1/_search
在写上面的查询的时候,在两个索引之间不能加入空格
六、聚合
https://blog.csdn.net/UbuntuTouch/article/details/99621105
Elasticsearch 中的 aggregation 聚合将你的数据汇总为指标、统计数据或其他分析。
聚合框架有助于基于搜索查询提供聚合数据。它基于称为聚合的简单构建块,可以组合以构建复杂的数据摘要。
聚合可以被视为在一组文档上构建分析信息的工作单元。执行的上下文定义了该文档集的内容
1、语法
"aggregations" : { "<aggregation_name>" : { "<aggregation_type>" : { <aggregation_body> } [,"meta" : { [<meta_data_body>] } ]? [,"aggregations" : { [<sub_aggregation>]+ } ]? } [,"<aggregation_name_2>" : { ... } ]* }
2、range聚合
把用户进行年龄分段,查出来在不同的年龄段的用户
GET twitter/_search { "size": 0, "aggs": { "age": { "range": { "field": "age", "ranges": [ { "from": 20, "to": 22 }, { "from": 22, "to": 25 }, { "from": 25, "to": 30 } ] } } } }
